因為索引下推。如果查詢條件包含在了組合索引中,比如存在組合索引(a,b),查詢到滿足 a 的記錄后會直接在索引內(nèi)部判斷 b 是否滿足,減少回表次數(shù)。同時,如果查詢的列恰好包含在組合索引中,即為覆蓋索引,無需回表。索引規(guī)則估計都知道,實際開發(fā)中也會創(chuàng)建和使用。問題可能更多的是:為什么建了索引還慢?
1.1.1 什么原因?qū)е滤饕?/span>
建了索引還慢,多半是索引失效(未使用),可用 explain 分析。索引失效常見原因有 :
where 中使用 != 或 <> 或 or 或表達式或函數(shù)(左側(cè))
like 語句 % 開頭
字符串未加’’
索引字段區(qū)分度過低,如性別
未匹配最左前綴
(一張嘴就知道老面試題了) 為什么這些做法會導(dǎo)致失效,成熟的 MySQL 也有自己的想法。
1.1.2 這些原因為什么導(dǎo)致索引失效
如果要 MySQL 給一個理由,還是那棵 B+ 樹。
函數(shù)操作
當在 查詢 where = 左側(cè)使用表達式或函數(shù)時,如字段 A 為字符串型且有索引, 有 where length(a) = 6查詢,這時傳遞一個 6 到 A 的索引樹,不難想象在樹的第一層就迷路了。
在 ES 7.0 之前存儲結(jié)構(gòu)是 Index -> Type -> Document,按 MySQL 對比就是 database - table - id(實際這種對比不那么合理)。7.0 之后 Type 被廢棄了,就暫把 index 當做 table 吧。在 Dev Tools 的 Console 可以通過以下命令查看一些基本信息。也可以替換為 crul 命令。
GET /_cat/health?v&pretty:查看集群健康狀態(tài)
GET /_cat/shards?v :查看分片狀態(tài)
GET yourindex/_mapping :index mapping結(jié)構(gòu)
GET yourindex/_settings :index setting結(jié)構(gòu)
GET /_cat/indices?v :查看當前節(jié)點所有索引信息
重點是 mapping 和 setting ,mapping 可以理解為 MySQL 中表的結(jié)構(gòu)定義,setting 負責控制如分片數(shù)量、副本數(shù)量。以下是截取了某日志 index 下的部分 mapping 結(jié)構(gòu),ES 對字符串類型會默認定義成 text ,同時為它定義一個叫做 keyword 的子字段。這兩的區(qū)別是:text 類型會進行分詞, keyword 類型不會進行分詞。
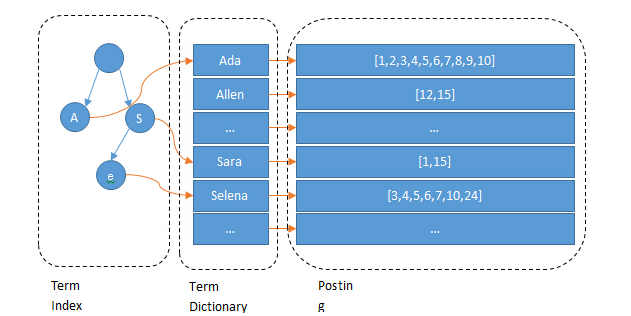
分詞是什么意思?看完 ES 的索引原理你就 get 了。ES 基于倒排索引。嘛意思?傳統(tǒng)索引一般是以文檔 ID 作索引,以內(nèi)容作為記錄。倒排索引相反,根據(jù)已有屬性值,去找到相應(yīng)的行所在的位置,也就是將單詞或內(nèi)容作為索引,將文檔 ID 作為記錄。下圖是 ES 倒排索引的示意圖,由 Term index,Team Dictionary 和 Posting List 組成。圖片圖中的 Ada、Sara 被稱作 term,其實就是分詞后的詞了。如果把圖中的 Term Index 去掉,是不是有點像 MySQL 了?Term Dictionary 就像二級索引,但 MySQL 是保存在磁盤上的,檢索一個 term 需要若干次的 random access 磁盤操作。而 ES 在 Term Dictionary 基礎(chǔ)上多了層 Term Index ,它以 FST 形式保存在內(nèi)存中,保存著 term 的前綴,借此可以快速的定位到 Term dictionary 的本 term 的 offset 。而且 FST 形式和 Term dictionary 的 block 存儲方式都很節(jié)省內(nèi)存和磁盤空間。到這就知道為啥快了,就是因為有了內(nèi)存中的 Term Index , 它為 term 的索引 Term Dictionary 又做了一層索引。不過,也不是說 ES 什么查詢都比 MySQL 快。檢索大致分為兩類。
2.3.1 分詞后檢索
ES 的索引存儲的就是分詞排序后的結(jié)果。比如圖中的 Ada,在 MySQL 中 %da% 就掃全表了,但對 ES 來說可以快速定位2.3.2 精確檢索該情況其實相差是不大的,因為 Term Index 的優(yōu)勢沒了,卻還要借此找到在 term dictionary 中的位置。也許由于 MySQL 覆蓋索引無需回表會更快一點。2.4 什么時候用 ES如前所述,對于業(yè)務(wù)中的查詢場景什么時候適合使用 ES ?我覺得有兩種。2.4.1 全文檢索在 MySQL 中字符串類型根據(jù)關(guān)鍵字模糊查詢就是一場災(zāi)難,對 ES 來說卻是小菜一碟。具體場景,比如消息表對消息內(nèi)容的模糊查詢,即聊天記錄查詢。但要注意,如果需要的是類似廣大搜索引擎的關(guān)鍵字查詢而非日志的短語匹配查詢,就需要對中文進行分詞處理,最廣泛使用的是 ik 。Ik 分詞器的安裝這里不再細說。什么意思呢?分詞開頭對日志的查詢,鍵入 “我可真是個機靈鬼” 時,只會得到完全匹配的信息。而倘若去掉 “”,又會得到按照 “我”、“可”,“真”….分詞匹配到的所有信息,這明顯會返回很多信息,也是不符合中文語義的。實際期望的分詞效果大概是“我”、“可”、“真是”,“機靈鬼”,之后再按照這種分詞結(jié)果去匹配查詢。這是 ES 默認的分詞策略對中文的支持不友善導(dǎo)致的,按照英語單詞字母來了,可英語單詞間是帶有空格的。這也是不少國外軟件中文搜索效果不 nice 的原因之一。對于該問題,你可以在 console 使用下方命令,測試當前 index 的分詞效果。
POST yourindex/_analyze { "field":"yourfield", "text":"我可真是個機靈鬼" }
2.4.2 組合查詢
如果數(shù)據(jù)量夠大,表字段又夠多。把所有字段信息丟到 ES 里創(chuàng)建索引是不合理的。使用 MySQL 的話那就只能按前文提到的分庫分表、讀寫分離來了。何不組合下。
1. ES + MySQL
將要參與查詢的字段信息加上 id,放入 ES,做好分詞。將全量信息放入 MySQL,通過 id 快速檢索。
2. ES + HBASE
如果要省去分庫分表什么的,或許可以拋棄 MySQL ,選擇分布式數(shù)據(jù)庫,比如 HBASE , 對于這種 NOSQL 來說,存儲能力海量,擴容 easy ,根據(jù) rowkey 查詢也很快。以上思路都是經(jīng)典的索引與數(shù)據(jù)存儲隔離的方案了。當然,攤子越大越容易出事,也會面臨更多的問題。使用 ES 作索引層,數(shù)據(jù)同步、時序性、mapping 設(shè)計、高可用等都需要考慮。畢竟和單純做日志系統(tǒng)對比,日志可以等待,用戶不能。2.5 小結(jié)本節(jié)簡單介紹了 ES 為啥快,和這個快能用在哪。現(xiàn)在你可以打開 Kibana 的控制臺試一試了。如果想在 Java 項目中接入的話,有 SpringBoot 加持,在 ES 環(huán)境 OK 的前提下,完全是開箱即用,就差一個依賴了。基本的 CRUD 支持都是完全 OK 的。
3. HBASE
前面有提到 HBASE , 什么是 HBASE ,鑒于篇幅這里簡單說說。3.1 存儲結(jié)構(gòu)關(guān)系型數(shù)據(jù)庫如 MySQL 是按行來的。
HBASE 是按列的(實際是列族)。列式存儲上表就會變成:
下圖是一個 HBASE 實際的表模型結(jié)構(gòu)。
Row key 是主鍵,按照字典序排序。TimeStamp 是版本號。info 和 area 都是列簇(column Family),列簇將表進行橫向切割。name、age 叫做列,屬于某一個列簇,可進行動態(tài)添加。Cell 是具體的 Value 。
個人覺得軟件開發(fā)是循序漸進的,技術(shù)服務(wù)于項目,合適比新穎復(fù)雜更重要。如何完成一次快速的查詢?最該做的還是先找找自己的 Bug,解決了當前問題再創(chuàng)造新問題。本文列舉到的部分方案對于具體實現(xiàn)大多一筆帶過,實際無論是 MySQL 的分表還是 ES 的業(yè)務(wù)融合都會面臨很多細節(jié)和困難的問題,搞工程的總要絕知此事要躬行。