
用 Python 批量提取 PDF 的圖片,并存儲到指定文件夾
作者:python與數(shù)據(jù)分析
鏈接:https://www.jianshu.com/p/93d1f3a29dec
公眾號后臺回復(fù):「Python批量提取PDF中的圖片」,即可獲取本文完整數(shù)據(jù)。
本期視頻:用 Python 批量提取 PDF 中的圖片,并保存到指定文件夾中!
上篇《用 Python 批量提取 PDF 的表格數(shù)據(jù),保存為 Excel》文章中,我們利用 Python 的第三方工具庫 pdfplumber 批量提取 PDF 的表格數(shù)據(jù)后,有不少小伙伴們提出,大多數(shù) PDF 都為圖片,如何批量提取出圖片。
今天就來用 Python 來解決這個問題。
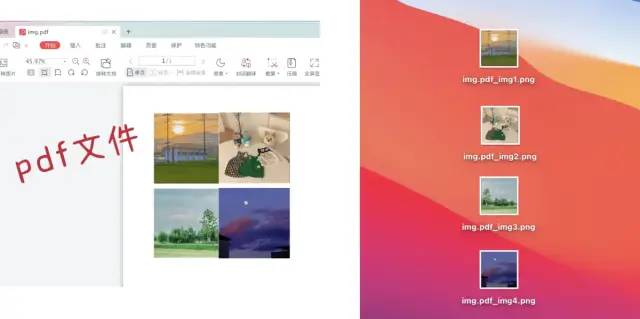
一、實(shí)現(xiàn)效果圖
二、基于 fitz 庫和正則搜索提取圖片
fitz 庫是 pymupdf 中的一個模塊,用它來提取 pdf 里的圖片非常方便。
安裝命令
pip?install?fitz?
pip?install?pymupdf
三、代碼實(shí)現(xiàn)
導(dǎo)入相關(guān)包
import?fitz
import?re
import?os
讀取 pdf 提取圖片,并存儲
def?save_pdf_img(path,save_path):
????'''
????path:?pdf的路徑
????save_path?:?圖片存儲的路徑
????'''
????#?使用正則表達(dá)式來查找圖片
????checkXO?=?r"/Type(?=?*/XObject)"?
????checkIM?=?r"/Subtype(?=?*/Image)"??
????#?打開pdf
????doc?=?fitz.open(path)
????#?圖片計數(shù)
????imgcount?=?0
????#?獲取對象數(shù)量長度
????lenXREF?=?doc.xref_length()
????#?打印PDF的信息
????print("文件名:{},?頁數(shù):?{},?對象:?{}".format(path,?len(doc),?lenXREF?-?1))
????#?遍歷每一個圖片對象
????for?i?in?range(1,?lenXREF):
????????#?定義對象字符串
????????text?=?doc.xref_object(i)
#?????????print(i,text)
????????isXObject?=?re.search(checkXO,?text)
????????#?使用正則表達(dá)式查看是否是圖片
????????isImage?=?re.search(checkIM,?text)
????????#?如果不是對象也不是圖片,則continue
????????if?not?isXObject?or?not?isImage:
????????????continue
????????imgcount?+=?1
????????#?根據(jù)索引生成圖像
????????pix?=?fitz.Pixmap(doc,?i)
????????#?根據(jù)pdf的路徑生成圖片的名稱
????????new_name?=?path.replace('\\',?'_')?+?"_img{}.png".format(imgcount)
????????new_name?=?new_name.replace(':',?'')
????????#?如果pix.n<5,可以直接存為PNG
????????if?pix.n?5:
????????????pix.writePNG(os.path.join(save_path,?new_name))
????????#?否則先轉(zhuǎn)換CMYK
????????else:
????????????pix0?=?fitz.Pixmap(fitz.csRGB,?pix)
????????????pix0.writePNG(os.path.join(save_path,?new_name))
????????????pix0?=?None
????????#?釋放資源
????????pix?=?None
????????print("提取了{(lán)}張圖片".format(imgcount))
#?pdf路徑
path?=?r'/Users/wangwangyuqing/Desktop/data/img.pdf'
save_path?=?r'/Users/wangwangyuqing/Desktop/data'
save_pdf_img(path,save_path)
運(yùn)行結(jié)果

四、小結(jié)
Python 中 pdf2image 庫也可以完成以上需求,它的好處是如果你的 pdf 頁面較多時,pdf2image 可以啟動多線程會大大加快轉(zhuǎn)換速度,具體可參考?pdf2image 官方文檔。
最后,可能會遇到提取的圖片比原本少,或者提取出不想要的圖片。可以通過檢查圖片格式,可能不是常見的格式,提取時再減少或添加過濾條件進(jìn)行嘗試。
推薦閱讀
用 Python 批量提取 PDF 的表格數(shù)據(jù),保存為 Excel

評論
圖片
表情