
Flink JVM 內(nèi)存超限的分析方法總結(jié)
前段時間,某客戶的大作業(yè)(并行度 200 左右)遇到了 TaskManager JVM 內(nèi)存超限(實際內(nèi)存用量 4.1G > 容器設(shè)定的最大閾值 4.0G),被 YARN 的 pmem-check 機制檢測到并發(fā)送了 SIGTERM(kill)信號終止,最終導(dǎo)致作業(yè)出現(xiàn)崩潰。這個問題近期出現(xiàn)了好幾次,客戶希望能找到解決方案,避免國慶期間線上業(yè)務(wù)受到影響。
在 Flink 配置項中,提供了很多內(nèi)存參數(shù)設(shè)定。我們逐一檢查了客戶作業(yè)的設(shè)置,發(fā)現(xiàn)最大值加起來也只有 3.75GB 左右(不含 ?JVM 自身 Native 內(nèi)存區(qū)),離設(shè)定的 4.0G 閾值還有 256M 的空間。
用戶作業(yè)并沒有用到 RocksDB、GZip 等常見的需要使用 Native 內(nèi)存且容易造成內(nèi)存泄漏的第三方庫,而且從 GC 日志來看,堆內(nèi)各個區(qū)域遠(yuǎn)遠(yuǎn)沒有用滿,說明余量還是比較充足的。
那究竟是什么原因造成實際內(nèi)存用量(RSS)超限了呢?
Flink 內(nèi)存模型
要分析問題,首先要了解 Flink 和 JVM 的內(nèi)存模型。官方文檔 [1] 和很多第三方博客 [2] [3] 都對此有較為詳盡的分析,這里只做流程的簡單說明,不再詳盡描述每個區(qū)域的具體計算過程。
下圖展示了 Flink 內(nèi)存各個區(qū)域的配置參數(shù),其中左邊是 Flink 配置項中的內(nèi)存參數(shù),中間是參數(shù)對應(yīng)的內(nèi)存區(qū)域,右邊是這個作業(yè)配置的參數(shù)值。
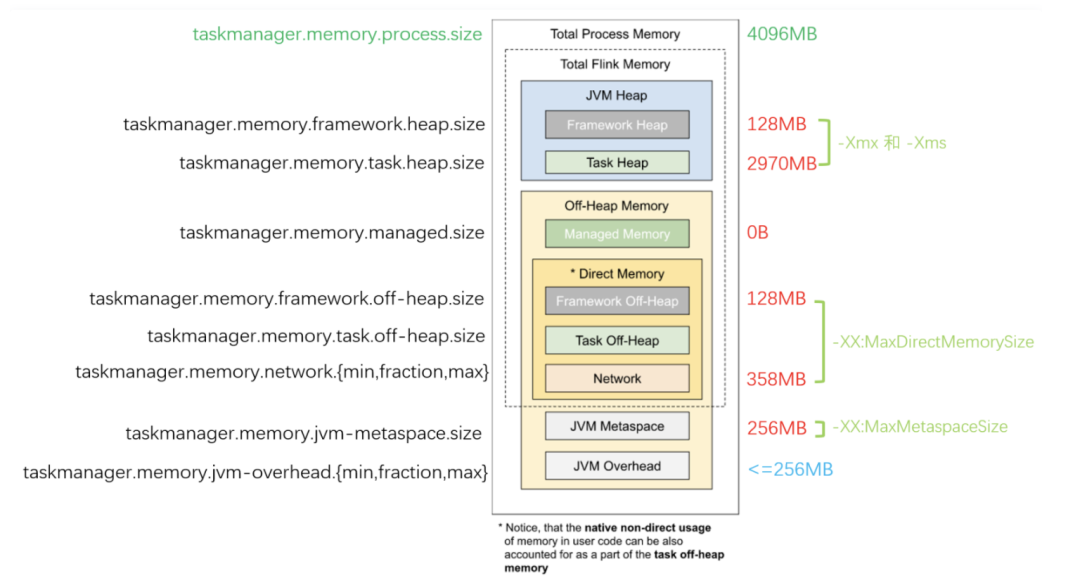
最上面深綠色的(taskmanager.memory.process.size)表示 JVM 所在容器的硬限制,例如 Kubernetes Pod YAML 的 resource limits。它的相關(guān)類為 ClusterSpecification,里面描述了 JobManager、TaskManager 容器所允許的最大內(nèi)存用量,以及每個 TaskManager 的 Slot(運行槽)數(shù)等。
TaskManager 各個區(qū)域的內(nèi)存用量是由 TaskExecutorProcessSpec 類來描述的。首先 Flink 的 ResourceManager 會調(diào)用 TaskExecutorFlinkMemoryUtils 工具類,從用戶和系統(tǒng)的各項配置 Configuration 中獲取各個內(nèi)存區(qū)域的大小( TaskExecutorFlinkMemory 對象,不含 Metaspace 和 Overhead 部分)。這中間要考慮到舊版本參數(shù)的兼容性,所以有很多繞來繞去的封裝代碼。總而言之,優(yōu)先級是 新配置 > 舊配置 > 無配置(計算推導(dǎo) + 默認(rèn)值)。隨后再根據(jù)配置和上述的計算結(jié)果,推導(dǎo)出 JvmMetaspaceAndOverhead,最終封裝為包含各個區(qū)域內(nèi)存大小定義的 TaskExecutorProcessSpec 對象。
最右邊淺綠色文字的表示 Flink 內(nèi)存參數(shù)最終翻譯成的 JVM 參數(shù)(例如堆區(qū)域的 -Xmx、-Xms,Direct 內(nèi)存區(qū)的 -XX:MaxDirectMemorySize 等),這個是 JVM 進程最終運行時的內(nèi)存區(qū)域劃分依據(jù),是 ProcessMemoryUtils 這個工具類從上述的 TaskExecutorProcessSpec 對象中生成的。
堆內(nèi)內(nèi)存的分析
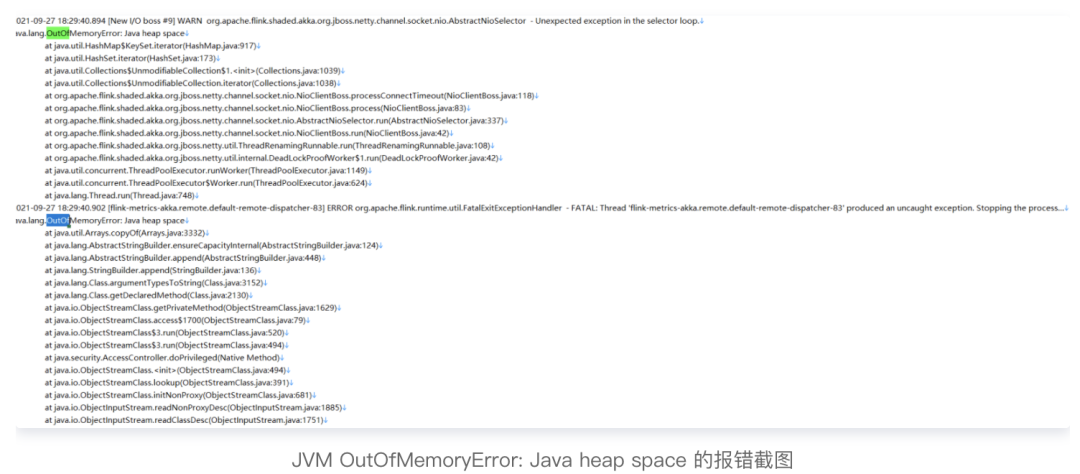
堆內(nèi)內(nèi)存(JVM Heap),指的是上圖的 Framework Heap 和 Task Heap 部分。Task Heap 是 Flink 作業(yè)內(nèi)存分配的重點區(qū)域,也是 JVM OutOfMemoryError: Java heap space 問題的發(fā)生地,當(dāng) OOM 問題發(fā)生時如下圖:
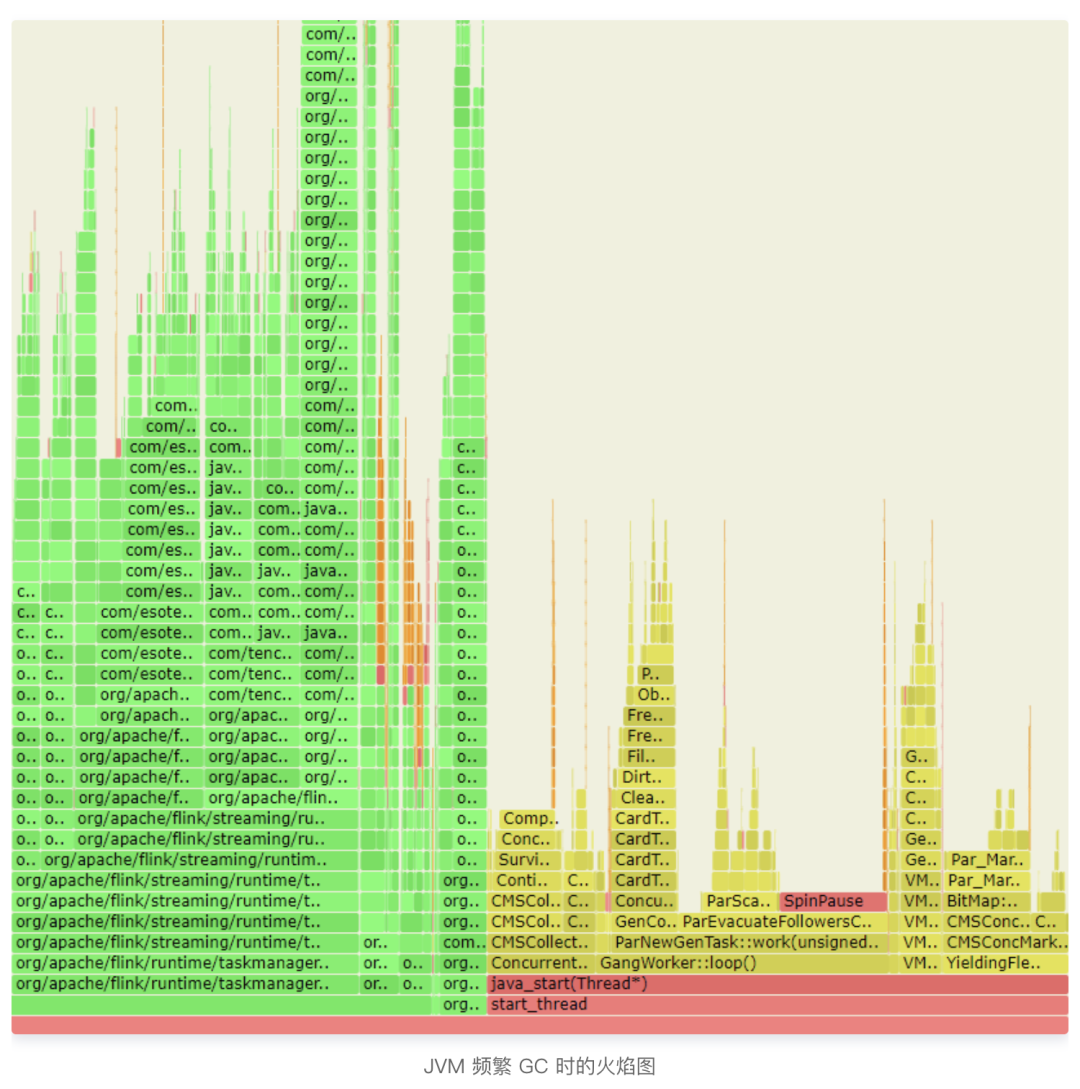
如果這個區(qū)域內(nèi)存占滿了,也會出現(xiàn)不停的 GC,尤其是 Full GC。這些可以從監(jiān)控指標(biāo)面板看到,也可以通過 jstat 等命令查看。如果我們通過 Arthas、async-profiler [4] 等工具對 JVM 進行運行時火焰圖采樣的話,也可以看到類似下面的結(jié)果:GC 相關(guān)的線程占了很大的時間片比例:
對于堆內(nèi)內(nèi)存的泄漏分析,如果進程即將崩潰但是還存活,可以使用 jmap 來獲取一份堆內(nèi)存的 dump:
jmap?-dump:live,format=b,file=/tmp/dump.hprof?JVM進程PID???#?先做一次?Full?GC?再?dump
jmap?-dump:format=b,file=/tmp/dump.hprof?JVM進程PID????????#?直接進行?dump
如果進程崩潰難以捕捉,可以在 Flink 配置的 JVM 啟動參數(shù)中增加:
env.java.opts.taskmanager:?-XX:+HeapDumpOnOutOfMemoryError?-XX:HeapDumpPath=/tmp/taskmanager.hprof
這樣 JVM 在發(fā)生 OOM 的時刻,會將堆內(nèi)存 dump 保存到指定路徑后再退出。
拿到堆內(nèi)存 dump 文件以后,我們可以使用 MAT [5] 這個開源的小工具來分析潛在的內(nèi)存泄漏情況,并輸出報表。
如果 MAT 不能滿足需求,還有 JProfiler 等更全面的工具可以進行堆內(nèi)存的高級分析。
當(dāng)然,很不幸的是,這個出問題的作業(yè)的堆內(nèi)存區(qū)域并沒有用滿,GC 日志看起來一切正常,堆內(nèi)存泄漏的可能性排除。那么還需要進一步涉足堆外內(nèi)存的各個神秘區(qū)域。
堆外內(nèi)存的分析
JVM 堆外內(nèi)存又分為多個區(qū)域,例如 Flink HybridMemorySegment 會用到 Java NIO 的 DirectByteBuffer 使用的 Direct 內(nèi)存區(qū)(MaxDirectMemorySize 參數(shù)限制的區(qū)域),類加載等使用的 Metaspace 區(qū)(MaxMetaspaceSize 參數(shù)限制的區(qū)域,JDK 8 以前叫做 PermGen)。
如果 Direct 內(nèi)存區(qū)發(fā)生了 OOM,JVM 會報出 OutOfMemoryError: Direct buffer memory 錯誤;而 Metaspace 區(qū) OOM 則會報出 OutOfMemoryError: Metaspace 錯誤。但是這個作業(yè)日志中并沒有看到任何 OutOfMemoryError 的錯誤,因此這些地方內(nèi)存泄漏的可能性也不大。
使用 Native Memory Tracking 查看 JVM 的各個內(nèi)存區(qū)域用量 JVM 自帶了一個很有用的詳細(xì)內(nèi)存分配追蹤工具:NMT [6],可以通過配置 JVM 啟動參數(shù)來開啟(可能造成 10% ~ 20% 的性能下降,線上慎用):
-XX:+UnlockDiagnosticVMOptions?-XX:+PrintNMTStatistics?-XX:NativeMemoryTracking=summary
隨后可以對運行中的 JVM 進程執(zhí)行:
jcmd?進程?VM.native_memory?summary
來獲取此時此刻的 JVM 各區(qū)域的內(nèi)存用量報表。
下面是一個典型的返回結(jié)果(// 為本文備注內(nèi)容,標(biāo)出了占用較多內(nèi)存的區(qū)域含義):
Total:?reserved=5249055KB,?committed=3997707KB?//?總物理內(nèi)存申請量為?3.81G
-?????????????????Java?Heap?(reserved=3129344KB,?committed=3129344KB)??//?堆內(nèi)存占了?2.98G?物理內(nèi)存
????????????????????????????(mmap:?reserved=3129344KB,?committed=3129344KB)
-?????????????????????Class?(reserved=1130076KB,?committed=90824KB)??//?類的元數(shù)據(jù)占用了?88.7M?物理內(nèi)存
????????????????????????????(classes?#13501)?//?加載的類數(shù)
????????????????????????????(malloc=1628KB?#17097)
????????????????????????????(mmap:?reserved=1128448KB,?committed=89196KB)
-????????????????????Thread?(reserved=136084KB,?committed=136084KB)??//?線程棧占用了?132.9M?物理內(nèi)存
????????????????????????????(thread?#132)??//?線程數(shù)
????????????????????????????(stack:?reserved=135504KB,?committed=135504KB)
????????????????????????????(malloc=425KB?#692)
????????????????????????????(arena=155KB?#249)
-??????????????????????Code?(reserved=256605KB,?committed=44513KB)
????????????????????????????(malloc=7005KB?#11435)
????????????????????????????(mmap:?reserved=249600KB,?committed=37508KB)
-????????????????????????GC?(reserved=69038KB,?committed=69038KB)
????????????????????????????(malloc=58846KB?#618)
????????????????????????????(mmap:?reserved=10192KB,?committed=10192KB)
-??????????????????Compiler?(reserved=394KB,?committed=394KB)
????????????????????????????(malloc=263KB?#811)
????????????????????????????(arena=131KB?#18)
-??????????????????Internal?(reserved=432708KB,?committed=432704KB)?//?Direct?內(nèi)存等部分占了?422.6M?物理內(nèi)存
????????????????????????????(malloc=432672KB?#31503)
????????????????????????????(mmap:?reserved=36KB,?committed=32KB)
-????????????????????Symbol?(reserved=23801KB,?committed=23801KB)
????????????????????????????(malloc=21875KB?#165235)
????????????????????????????(arena=1926KB?#1)
-????Native?Memory?Tracking?(reserved=3582KB,?committed=3582KB)
????????????????????????????(malloc=20KB?#226)
????????????????????????????(tracking?overhead=3563KB)
-???????????????Arena?Chunk?(reserved=1542KB,?committed=1542KB)
????????????????????????????(malloc=1542KB)
-???????????????????Unknown?(reserved=65880KB,?committed=65880KB)
????????????????????????????(mmap:?reserved=65880KB,?committed=65880KB)
可以看到,堆內(nèi)存、Direct 等部分還是占了大部分,其他部分占用量相對較小。這個 JVM 總共統(tǒng)計到了 3.81G 的實時內(nèi)存申請量。
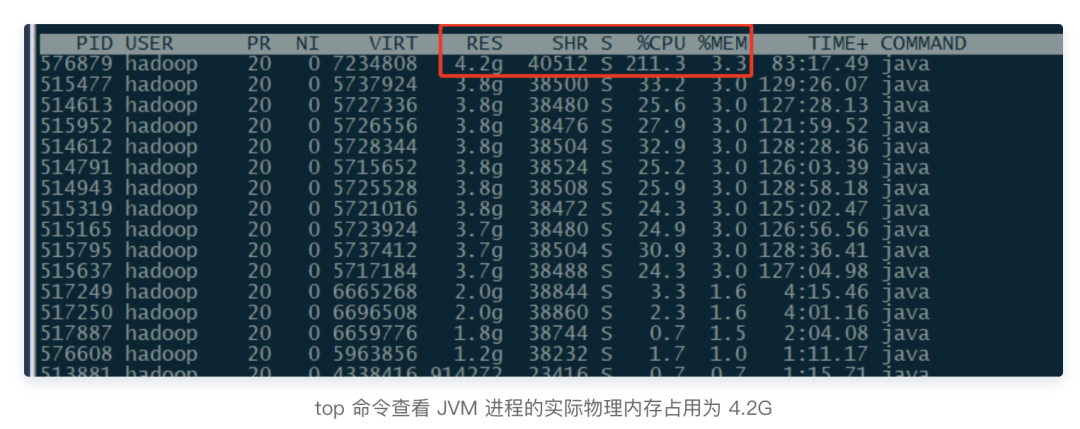
但是,使用 top 命令查看這個 JVM 進程的實時用量時,發(fā)現(xiàn) RSS(物理內(nèi)存占用)已經(jīng)升高到了 4.2G 左右,與上述結(jié)果不符,說明還是有部分內(nèi)存沒有追蹤到:
使用 jemalloc 替代 ptmalloc 并統(tǒng)計內(nèi)存動態(tài)分配
既然 JVM 自己統(tǒng)計的內(nèi)存分配與實際占用仍然有較多偏差,而搜索了網(wǎng)上的各種資料時,經(jīng)常會遇到因為 glibc malloc 64M 緩存造成內(nèi)存超標(biāo)的問題 [7]。
由于 jemalloc 并沒有這個 64M 的問題,而且可以通過 profiler 來統(tǒng)計 malloc 調(diào)用的動態(tài)分配情況,因此決定先使用 jemalloc [8] 來替換 glibc 自帶的分配函數(shù),并進行統(tǒng)計。當(dāng)然,使用 strace 等命令也可以攔截內(nèi)存分配和釋放情況(追蹤 mmap、munmap、brk 等系統(tǒng)調(diào)用),不過結(jié)果太多了,分析起來并不方便。
下載解壓 jemalloc 的發(fā)行包以后,進入相關(guān)目錄,編譯并安裝它:
./configure?--enable-prof?--enable-stats?--enable-debug?--enable-fill?&&?make?&&?make?install
隨后在 Flink 參數(shù)里加上這些內(nèi)容:
containerized.taskmanager.env.LD_PRELOAD:?"/usr/local/lib/libjemalloc.so.2"
containerized.taskmanager.env.MALLOC_CONF:?"prof:true,lg_prof_interval:29,lg_prof_sample:17"
重新運行作業(yè),就可以不斷地采集內(nèi)存分配情況,并輸出 .heap 文件到 JVM 進程的工作目錄(例如 jeprof.951461.7.i7.heap)。
隨后可以安裝 graphviz,再使用 jemalloc 自帶的 jeprof 命令對結(jié)果進行繪圖(盡量在進程退出前繪圖,避免地址無法解析):
yum?install?-y?graphviz
jeprof?--svg?`which?java`?采集的.heap文件名?>?~/result.svg
結(jié)果如下:
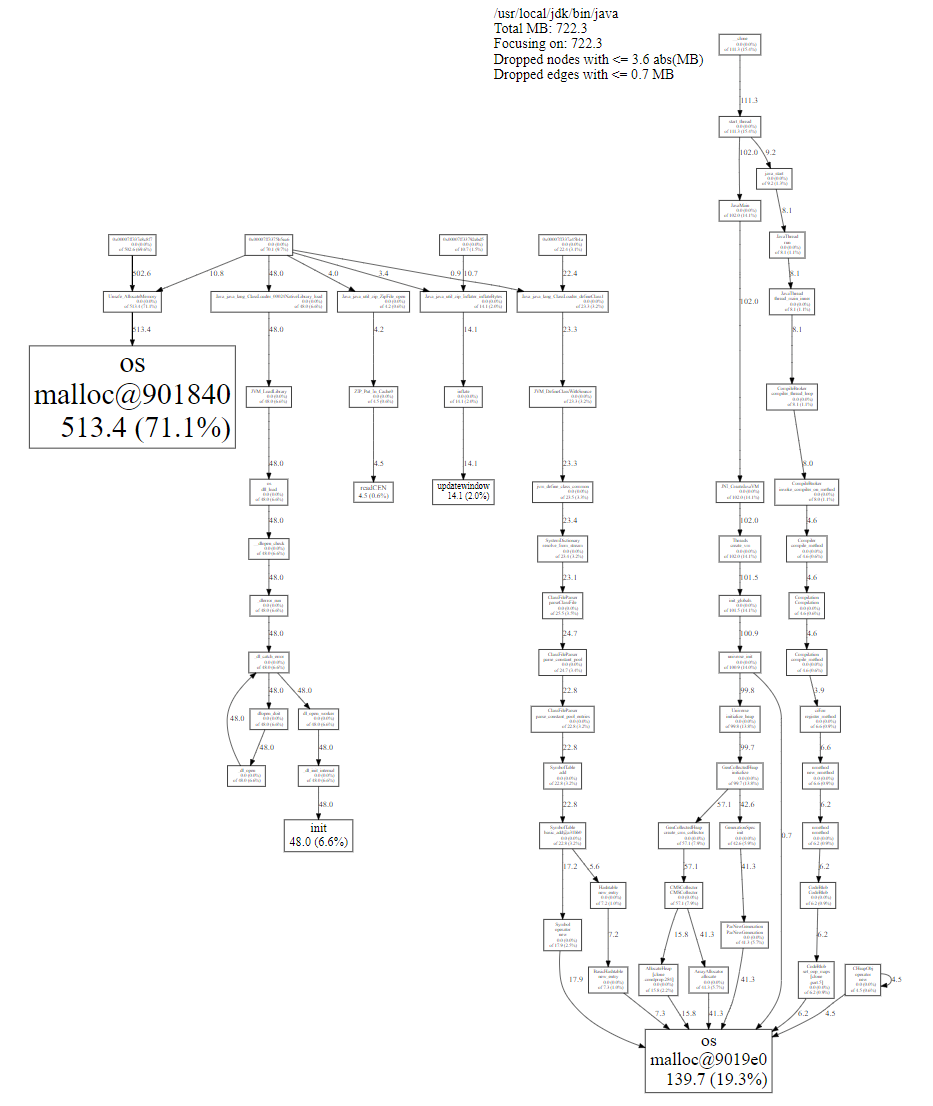
從左邊的分支來看,71.1% 的內(nèi)存分配請求主要由 ?Unsafe.allocateMemory() 調(diào)用的(例如 Flink MemoryManager 分配的堆外 MemorySegments)。
中間分支的 init 是 JVM 啟動期間分配的,也是正常范圍。
右邊分支主要是 JVM 內(nèi)部的 ParNew & CMS GC、Class 解析所需的符號表、代碼緩存所需的內(nèi)存,也是正常的。因此并未觀察到較大的第三方庫造成的內(nèi)存泄漏情況,因此間接引入第三方庫造成內(nèi)存泄漏的可能性也基本排除了。
使用 pmap 命令定期采樣內(nèi)存區(qū)塊分配
既然 JVM NMT 上報的內(nèi)存分區(qū)快照、jemalloc 統(tǒng)計的動態(tài)分配情況都沒有找到準(zhǔn)確的問題根源,我們還可以從底層出發(fā),使用 pmap 命令來查看 JVM 進程的各個內(nèi)存區(qū)域的分配情況,看是否有異常的條目。
可以使用下面的命令,從 Flink TaskManager 啟動開始采樣:
while?true
do
????????pmap?-x?JVM進程的PID?>?/tmp/pmap.`date?+%Y-%m-%d-%H-%M-%S`.log
????????sleep?30s
done
隨后可以使用文件比較工具,對比不同時間點的內(nèi)存分配情況(例如下圖是剛啟動和崩潰前的最后一個記錄),看是否有大塊的不能解釋的分配區(qū)段:
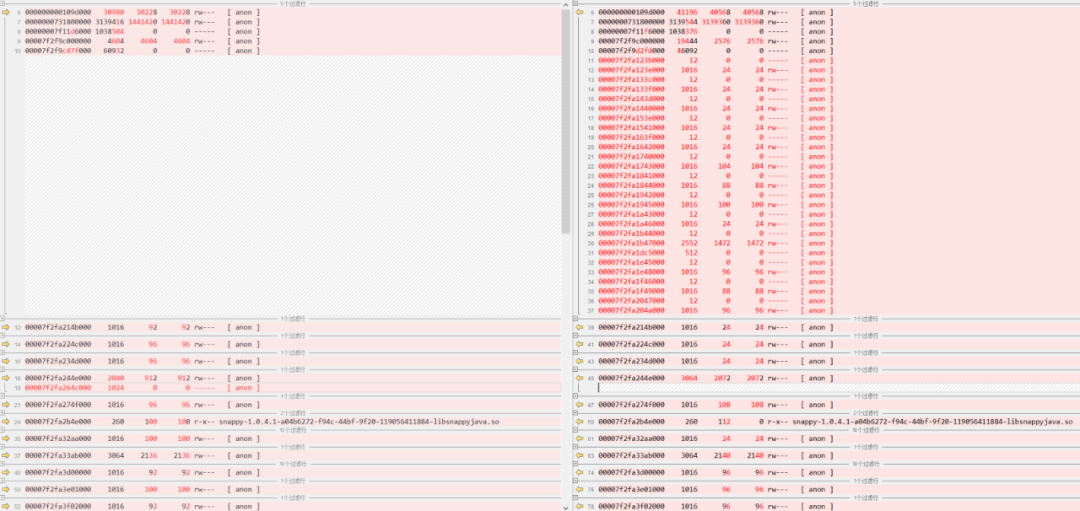
上圖中,除了堆內(nèi)存區(qū)有大幅增長(只是稍微超出一些 Xmx 的限制),其他區(qū)域的增長都比較小,因此說明 JVM 內(nèi)存超限基本上是因為堆內(nèi)存區(qū)域隨著使用自然擴展 + JVM 自身較大的 Overhead(內(nèi)部所需內(nèi)存)造成的。并且這部分內(nèi)存在 NMT 報告里統(tǒng)計的并不準(zhǔn)確,還需要進一步跟進。
初步總結(jié) 在上面的分析中,我們先從最容易分配也是占比最大的堆內(nèi)存區(qū)域開始分析,逐步進入堆外內(nèi)存的深水區(qū)。由于堆外內(nèi)存除了 Java 自帶的 NMT 機制外,并沒有綜合的分析工具可用,因此這里的分析過程往往繁雜而耗時,且較難得到準(zhǔn)確原因。
本次問題的初步結(jié)論是 JVM 自身運行所需的內(nèi)存(Overhead)占用較大,而用戶對 Flink 的參數(shù) taskmanager.memory.jvm-overhead.{min,fraction,max} 設(shè)定值過小(為了給堆內(nèi)存留出更大空間,在這里只設(shè)置了 256MB 的閾值,而實際的內(nèi)存占用不止這些)。
需要注意的是,這個參數(shù)并不意味著 Flink 能“限制”JVM 內(nèi)部的內(nèi)存用量。相反,它的用途是令 Flink 在計算各區(qū)域(Heap、Off-Heap、Network 等)的內(nèi)存空間時,能考慮到 JVM 這部分 Overhead 空間并不能被自己使用,應(yīng)當(dāng)減去這部分不受控的余量后再分配。
特別地,當(dāng)用到了 RocksDB 等 JNI 調(diào)用的原生庫時,請務(wù)必繼續(xù)調(diào)大 taskmanager.memory.jvm-overhead.fraction 和 taskmanager.memory.jvm-overhead.max 參數(shù)的值(例如給到 1~2GB),避免余量不夠而造成的總內(nèi)存用量超標(biāo)的問題。
本文作者:KyleMeow
原文地址:https://cloud.tencent.com/developer/article/1884177