
ClickHouse 原理 | ClickHouse 的索引原理

這篇文章來講一講對(duì)ClickHouse性能影響比較大的主題——索引。
如果帶著RDBMS的經(jīng)驗(yàn)來使用ClickHouse的索引的話,一定會(huì)對(duì)ClickHouse創(chuàng)建索引的sql感到有些陌生
ALTER TABLE skip_table ADD INDEX vix my_value TYPE set(100) GRANULARITY 2;
這條sql里面包含了很多在RDBMS的索引里沒有見過的元素:TYPE,set(100),GRANULARITY。之所以在建索引語句上和RDBMS有如此大的差異,正是因?yàn)镃lickHouse的索引和RDBMS的索引有著本質(zhì)的不同。因此兩者建索引需要的參數(shù)不同,就導(dǎo)致了語法上的不同。
接下來就會(huì)講一講ClickHouse的索引的原理,并解釋下上面幾個(gè)參數(shù)的含義。
基本原理
在開始講解ClickHouse的索引之前,先來回憶下RDBMS的secondary index是如何實(shí)現(xiàn)的。
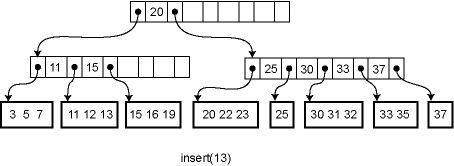
一個(gè)B-tree索引的例子
當(dāng)使用索引進(jìn)行查詢時(shí),最終都會(huì)定位到葉子結(jié)點(diǎn)的一條或多條記錄,因此RDBMS的索引的特點(diǎn)就是——快速找到想要的數(shù)據(jù)。
說完了RDBMS的索引,再來說ClickHouse的。ClickHouse的索引和RDBMS的索引正好相反,不是找到想要的數(shù)據(jù),而是“快速排除不想要的數(shù)據(jù)”,因此被稱為skip index。
舉個(gè)例子,假設(shè)某張表共有1億條數(shù)據(jù),按照默認(rèn)配置,每8192條記錄構(gòu)成一個(gè)granule,則共有12208個(gè)granule。如果不使用索引,我們需要讀取12208個(gè)granule的數(shù)據(jù)。假設(shè)我們通過“某些條件”排除了其中的12200個(gè)granule,那么只需要讀取8個(gè)granule,查詢的數(shù)據(jù)量減到之前的0.07%!(當(dāng)然了,不可能每個(gè)索引都有如此奇效)
那么“某些條件”具體有哪些呢?ClickHouse目前提供了3種索引類型:
minmax set bloomfilter
minmax是最輕量的一種索引類型,就是在索引文件里保存了每個(gè)granule的最大值和最小值(針對(duì)索引列),然后在查詢時(shí),根據(jù)查詢條件是否在最大值和最小值框定的范圍內(nèi)來確定是否排除granule。說它最輕量是因?yàn)?strong style="font-weight: bold;color: black;">索引需要存儲(chǔ)的數(shù)據(jù)量最小的。
set是在索引文件里保存每個(gè)granule的所有唯一值。它的優(yōu)勢(shì)是不存在假陽性,有就是有,沒有就是沒有,查詢效率很高。但有個(gè)缺點(diǎn)是索引的大小不可控,如果數(shù)據(jù)的唯一值比較多,索引就會(huì)變得很大,反而影響查詢性能。所以ClickHouse允許用戶建索引時(shí),設(shè)置索引的max_size,當(dāng)一個(gè)granule的唯一值數(shù)量超過max_size時(shí),就不保存這個(gè)granule的set。例如set(100)設(shè)置max_size是100時(shí),如果一個(gè)granule的唯一值超過了100,那么對(duì)這個(gè)granule就不會(huì)保存對(duì)應(yīng)set,則每次查詢時(shí)都會(huì)讀取這個(gè)granule。
bloomfilter和set的思想類似,只不過用bloomfilter來代替set,因此它的優(yōu)點(diǎn)是索引大小是固定的(遠(yuǎn)比set小),不會(huì)因數(shù)據(jù)的分布發(fā)生變化,缺點(diǎn)則是bloomfilter固有的假陽性問題。
聊完了ClickHouse的索引類型,再來聊一聊GRANULARITY這個(gè)關(guān)鍵字。其實(shí)我上面說的索引針對(duì)每個(gè)granule保存對(duì)應(yīng)的索引信息,如最大最小值,唯一值的集合等,并不準(zhǔn)確,確切地說是GRANULARITY 1時(shí)的情況。如果設(shè)置GRANULARITY 2的話,那么就是“每2個(gè)granule保存對(duì)應(yīng)的索引信息”。所以這個(gè)配置項(xiàng)控制的還是索引體積與索引效率的取舍。
索引實(shí)現(xiàn)
講完了索引的基本原理,接下來我會(huì)循著ClickHouse的讀路徑(read path)講一講ClickHouse如何使用skip index。
ClickHouse和大部分?jǐn)?shù)據(jù)庫系統(tǒng)一樣,使用”SQL解析 -> 生成邏輯執(zhí)行計(jì)劃 -> 生成物理執(zhí)行計(jì)劃 -> 運(yùn)行物理執(zhí)行計(jì)劃“的方式來處理查詢請(qǐng)求。
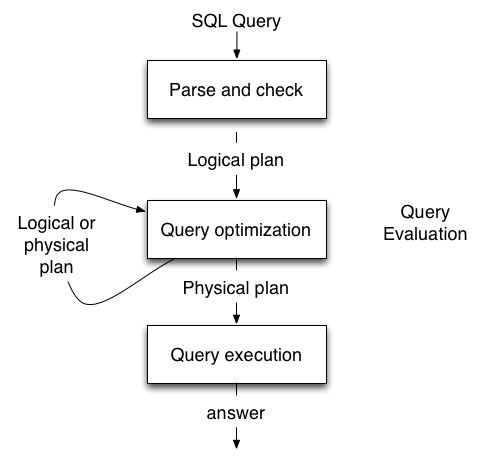
典型的query處理流程
在ClickHouse的源代碼中,QueryPlan對(duì)應(yīng)的是邏輯執(zhí)行計(jì)劃,QueryPipeline對(duì)應(yīng)的是物理執(zhí)行計(jì)劃。而讀取數(shù)據(jù)的代碼都在ReadFromMergeTree這個(gè)類(是邏輯執(zhí)行計(jì)劃的一個(gè)節(jié)點(diǎn))里面。
ReadFromMergeTree的工作整體可分為三個(gè)步驟:
確定需要查詢的part和granule范圍 生成物理執(zhí)行計(jì)劃中負(fù)責(zé)讀取數(shù)據(jù)的 MergeTreeSelectProcessor節(jié)點(diǎn)執(zhí)行計(jì)劃,通過 MergeTreeRangeReader從文件中讀取數(shù)據(jù)
和索引相關(guān)的工作都在第一步里面,所以這里著重介紹第一步。
第一步的工作可以繼續(xù)分為三個(gè)步驟:
首先根據(jù)查詢條件過濾出需要讀取的part 然后根據(jù)primary key進(jìn)一步過濾出需要讀取的granule 最后再使用skip index進(jìn)一步縮小granule的讀取范圍
具體查詢索引的代碼在MergeTreeDataSelectExecutor類的filterPartsByPrimaryKeyAndSkipIndexes方法里面,我在這里不再贅述。不過值得一提的是,ClickHouse即使做索引過濾時(shí)也是并發(fā)處理的(并發(fā)地讀取索引,并發(fā)地對(duì)granule過濾)。
總結(jié)
這篇文章把ClickHouse的skip index原理基本已經(jīng)講完了。相比于RDBMS,ClickHouse的索引對(duì)數(shù)據(jù)分布的要求更加苛刻。如果數(shù)據(jù)比較離散,則無論哪種索引的效果都不是太好,建索引反而拖累性能,所以不能想當(dāng)然地認(rèn)為”多加索引一定能提高性能“。
最后總結(jié)下本文的知識(shí)點(diǎn):
skip index的作用機(jī)制是排除掉不滿足條件的數(shù)據(jù)。 skip index的對(duì)象是granule,保存的是每個(gè)granule的最大最小值、唯一值集合等。 索引并不一定能夠提高查詢性能,必須根據(jù)數(shù)據(jù)分布的特點(diǎn)謹(jǐn)慎地建索引。
如果覺得這篇文章對(duì)你有所幫助,
請(qǐng)點(diǎn)一下贊或在看,是對(duì)我的肯定和支持~