
CK02# ClickHouse分布式表讀寫原理梳理
本文主要梳理了ClickHouse分布式表,也就是是Distributed表引擎基本工作原理。主要內(nèi)容有:
分布式表分片算法規(guī)則 分布式表寫入基本流程 分布式表讀出數(shù)據(jù)流程 非分布式表寫入本地表
使用分布式表時,數(shù)據(jù)應該落到哪個分片節(jié)點上呢?ClickHouse有一套自己的分片算法,下面從概念開始就一探究竟。
分片鍵(sharding_key): 要求返回一個整數(shù)類型的取值,下面語法中sharding_key需整數(shù)類型
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2],
...
) ENGINE = Distributed(cluster, database, table[, sharding_key[, policy_name]])
[SETTINGS name=value, ...]
權重(Weight) :ClickHouse中一個節(jié)點一個分片,可以給分片配置權重,權重越大數(shù)據(jù)分配越多,默認權重為1
槽(Slot): 槽的數(shù)量為集群中所有分片的權重之和
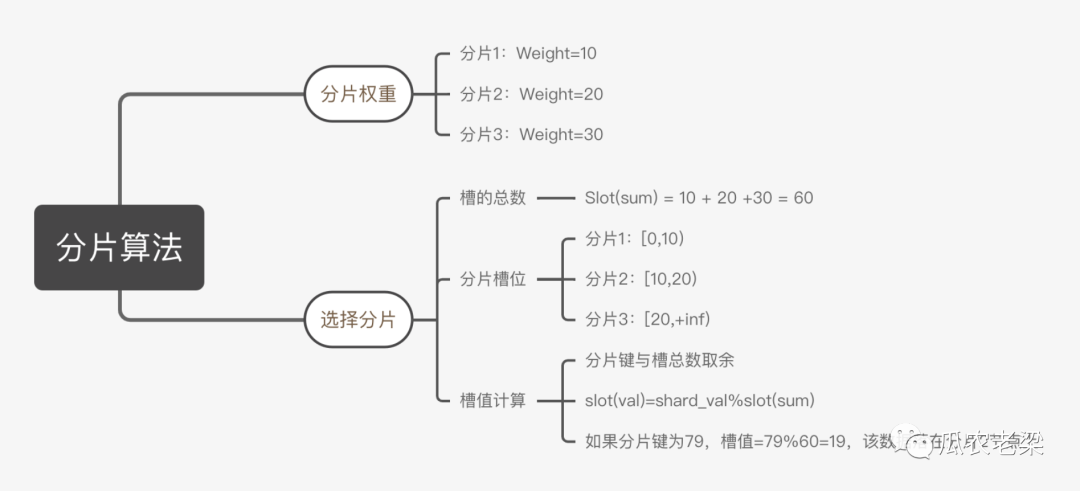
小結:通過權重與槽聯(lián)合使用的一種簡單分片算法。
在使用ClickHouse分布式表寫入數(shù)據(jù)時,大體流程是這樣的。
@1 數(shù)據(jù)先寫入一個分片(例如:分片1)
@2 屬于本分片的數(shù)據(jù)寫入本地表,屬于其他分片的數(shù)據(jù)先寫入本分片的臨時目錄
例如:其他分片的數(shù)據(jù)先寫入分片1的臨時目錄
@3 該分片與集群中其他分片建立連接
例如:分片1與分片2、分片1與分片3建立連接
@4 將寫入本地臨時文件的數(shù)據(jù)異步發(fā)送到其他分片
例如:分片1將臨時目錄數(shù)據(jù)發(fā)送到分片2與分片3
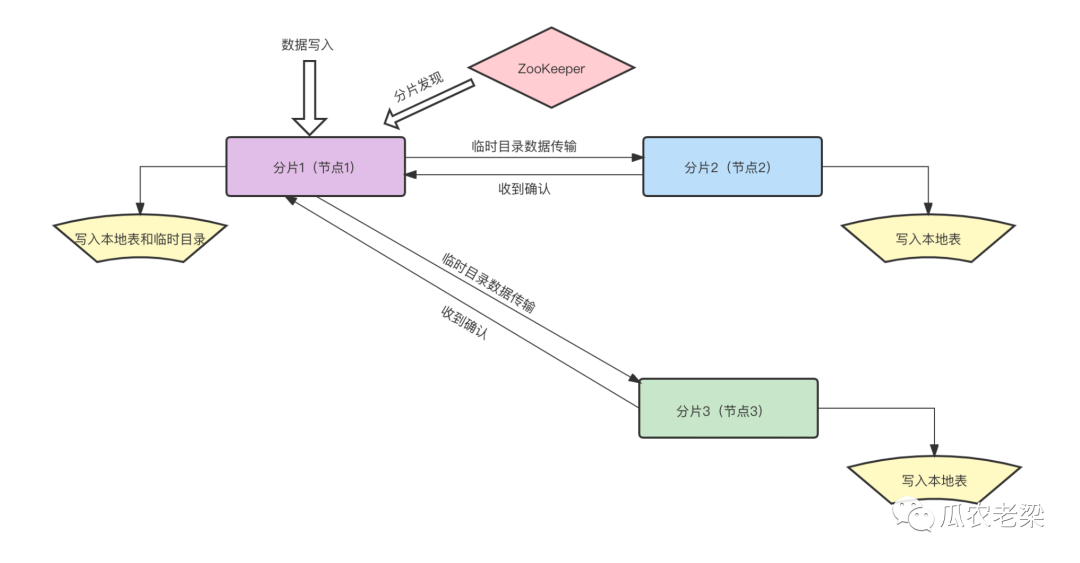
小結:使用分布式表直接寫入數(shù)據(jù)時,集群中各個節(jié)點彼此會建立連接,彼此之間傳輸數(shù)據(jù);性能低于直接寫入本地表。
使用ClickHouse的分布式表查詢,大體流程如下:
集群多副本時根據(jù)負載均衡選擇一個副本,也就是說副本是可以承擔查詢功能的 將分布式查詢語句轉換為本地查詢語句 將本地插敘語句發(fā)送到各個分片節(jié)點執(zhí)行查詢 再將返回的結果執(zhí)行合并
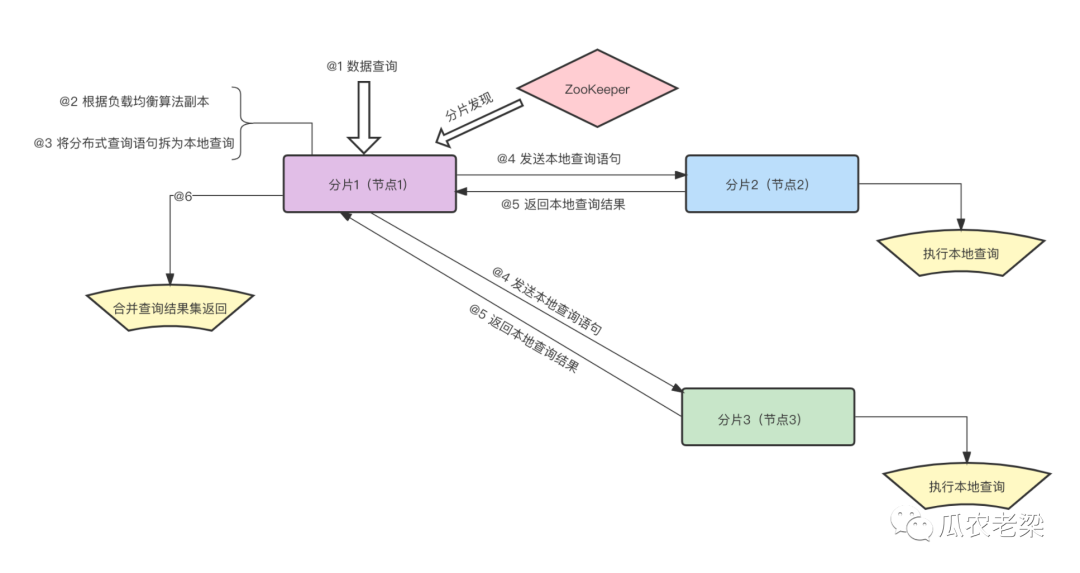
小結:分布式表的查詢類似于分庫分表中間件,邏輯也很類似。
寫入時通過分布式表,由于先寫入本地臨時目錄,集群節(jié)點之間會有數(shù)據(jù)傳輸。那如果再寫入時直接寫入本地表,性能要高于通過分布式表。
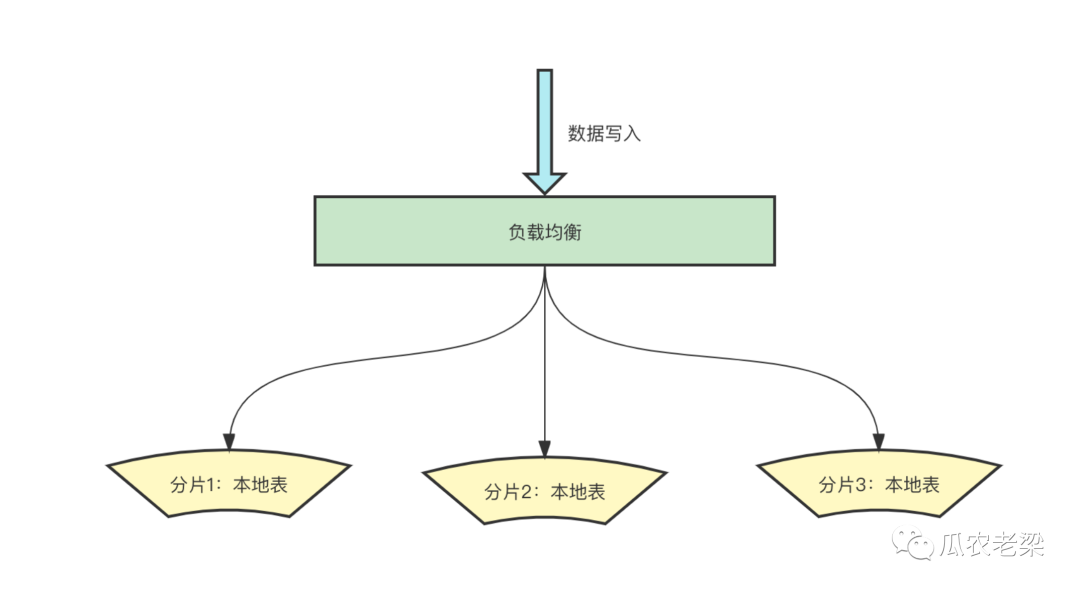
小結:負載均衡的方式:
分片節(jié)點前掛載SLB等負載均衡,注意帶寬限制 客戶端寫入時輪訓與各個分片建立連接,在客戶端進行負載均衡選擇分片