
安利-數(shù)據(jù)質量中心的設計與實現(xiàn)
日常工作中,數(shù)據(jù)開發(fā)工程師開發(fā)上線完一個任務后并不是就可以高枕無憂了,時常會因為上游鏈路數(shù)據(jù)異常或者自身處理邏輯的 BUG 導致產(chǎn)出的數(shù)據(jù)結果不可信。而這個問題的發(fā)現(xiàn)可能會經(jīng)歷一個較長的周期(尤其是離線場景),往往是業(yè)務方通過上層數(shù)據(jù)報表發(fā)現(xiàn)數(shù)據(jù)異常后 push 數(shù)據(jù)方去定位問題(對于一個較冷的報表,這個周期可能會更長)。
同時,由于數(shù)據(jù)加工鏈路較長需要借助數(shù)據(jù)的血緣關系逐個任務排查,也會導致問題的定位難度增大,嚴重影響開發(fā)人員的工作效率。更有甚者,如果數(shù)據(jù)問題沒有被及時發(fā)現(xiàn),可能導致業(yè)務方作出錯誤的決策。此類問題可統(tǒng)一歸屬為大數(shù)據(jù)領域數(shù)據(jù)質量的問題。本文將向大家介紹伴魚基礎架構數(shù)據(jù)團隊在應對該類問題時推出的平臺化產(chǎn)品-數(shù)據(jù)質量中心(Data Quality Center, DQC)的設計與實現(xiàn)。
調(diào)研
業(yè)內(nèi)關于數(shù)據(jù)質量平臺化的產(chǎn)品介紹不多,我們主要對兩個開源產(chǎn)品和一個云平臺產(chǎn)品進行了調(diào)研,下面將一一介紹。
Apache Griffin
Apache Griffin 是 eBay 開源的一款基于 Apache Hadoop 和 Apache Spark 的數(shù)據(jù)質量服務平臺。其架構圖如下:
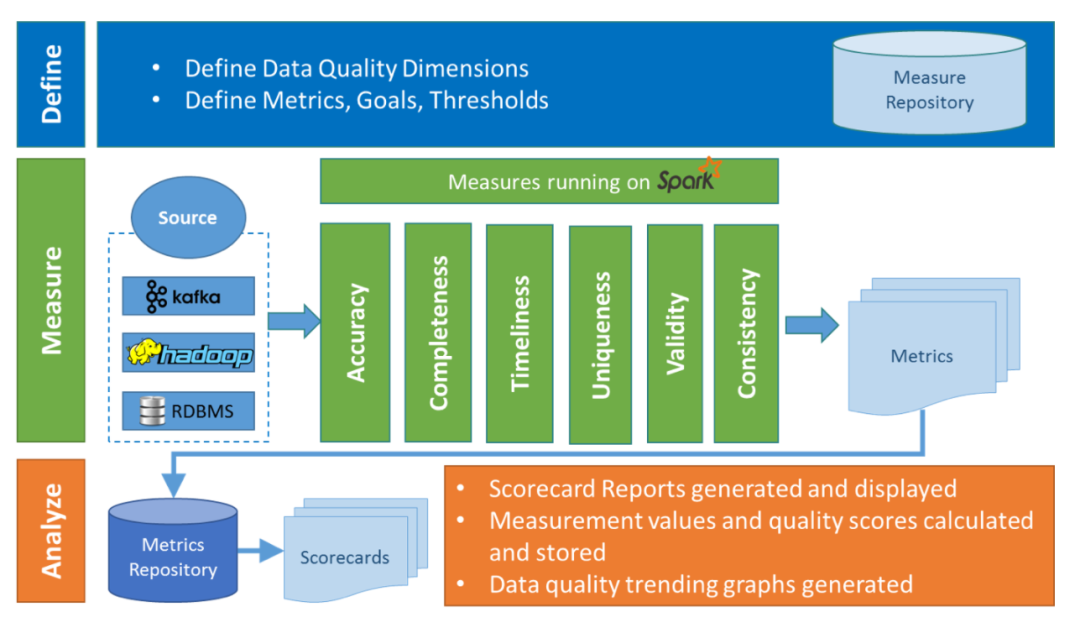
架構圖從 High Level 層面清晰地展示了數(shù)據(jù)質量平臺的三個核心流程:
Define:數(shù)據(jù)質檢規(guī)則(指標)的定義。
Measure:數(shù)據(jù)質檢任務的執(zhí)行,基于 Spark 引擎實現(xiàn)。
Analyze:數(shù)據(jù)質檢結果量化及可視化展示。
同時,平臺對數(shù)據(jù)質檢規(guī)則進行了分類(這也是目前業(yè)內(nèi)普遍認可的數(shù)據(jù)質量的六大標準):
Accuracy:準確性。如是否符合表的加工邏輯。
Completeness:完備性。如數(shù)據(jù)是否存在丟失。
Timeliness:及時性。如表數(shù)據(jù)是否按時產(chǎn)生。
Uniqueness:唯一性。如主鍵字段是否唯一。
Validity:合規(guī)性。如字段長度是否合規(guī)、枚舉值集合是否合規(guī)。
Consistency:一致性。如表與表之間在某些字段上是否存在矛盾。
目前該開源項目僅在 Accuracy 類的規(guī)則上進行了實現(xiàn)。
Griffin 是一個完全閉環(huán)的平臺化產(chǎn)品。其質檢任務的執(zhí)行依賴于內(nèi)置定時調(diào)度器的調(diào)度,調(diào)度執(zhí)行時間由用戶在 UI 上設定。任務將通過 Apache Livy 組件提交至配置的 Spark 集群。這也就意味著質檢的實時性難以保障,我們無法對產(chǎn)出異常數(shù)據(jù)的任務進行強行阻斷,二者不是在同一個調(diào)度平臺被調(diào)度,時序上也不能保持串行。
Qualitis
Qualitis 是微眾銀行開源的一款數(shù)據(jù)質量管理系統(tǒng)。同樣,它提供了一整套統(tǒng)一的流程來定義和檢測數(shù)據(jù)集的質量并及時報告問題。從整個流程上看我們依然可以用 Define、Measure 和 Analyze 描述。它是基于其開源的另一款組件 Linkis 進行計算任務的代理分發(fā),底層依賴 Spark 引擎,同時可以與其開源的 DataSphereStudio 任務開發(fā)平臺無縫銜接,也就實現(xiàn)了在任務執(zhí)行的工作流中嵌入質檢任務,滿足質檢時效性的要求。可見,Qualitis 需要借助微眾銀行開源的一系列產(chǎn)品才能達到滿意的效果。
DataWorks 數(shù)據(jù)質量
DataWorks 是阿里云上提供的一站式大數(shù)據(jù)工場,其中就包括了數(shù)據(jù)質量在內(nèi)的產(chǎn)品解決方案。同樣,它的實現(xiàn)依賴于阿里云上其他產(chǎn)品組件的支持。不過不得不說 DataWorks 數(shù)據(jù)質量部分的使用介紹從產(chǎn)品形態(tài)上給了我們很大的幫助,對于我們的產(chǎn)品設計非常具有指導性的作用。
設計目標
經(jīng)過一番調(diào)研,我們確定了 DQC 的設計目標,主要包括以下幾點:
目前暫且只支持離線部分的數(shù)據(jù)質量管理。
支持通用的規(guī)則描述和規(guī)則管理。
質檢任務由公司內(nèi)部統(tǒng)一的調(diào)度引擎調(diào)度執(zhí)行,可支持對質檢結果異常的任務進行強阻斷。同時,盡量降低質檢功能對調(diào)度引擎的代碼侵入。
支持質檢結果的可視化。
系統(tǒng)設計
背景補充
伴魚離線調(diào)度開發(fā)平臺是基于 Apache Dolphinscheduler(下文簡稱 DS)實現(xiàn)的。它是一個分布式去中心化,易擴展的可視化 DAG 調(diào)度系統(tǒng),支持包括 Shell、Python、Spark、Flink 等多種類型的 Task 任務,并具有很好的擴展性。架構如下圖所示:
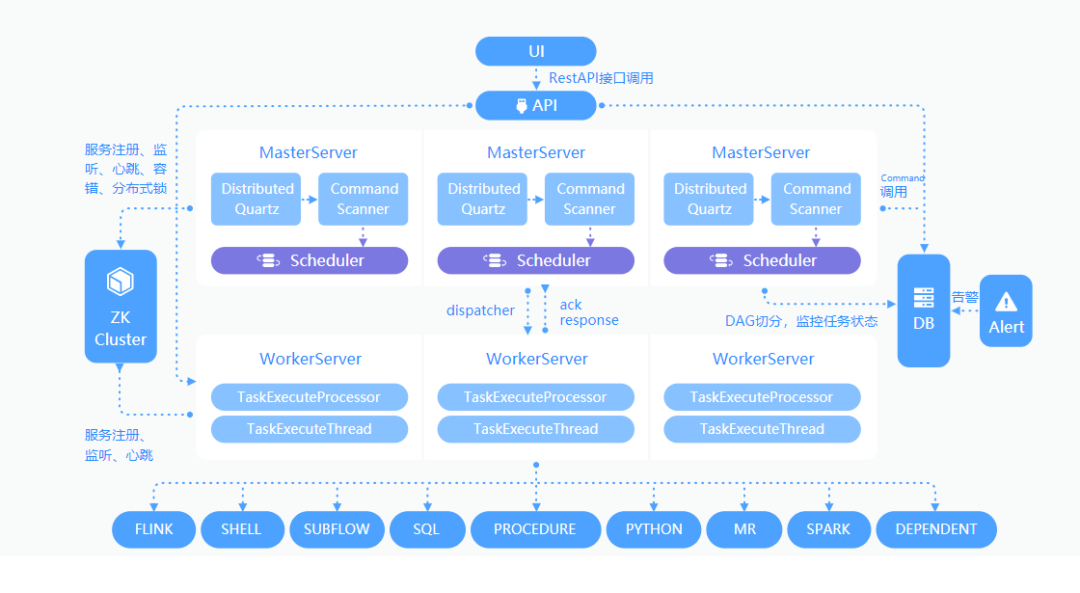
Master 節(jié)點負責任務的監(jiān)聽和調(diào)度,Worker 節(jié)點則負責任務的執(zhí)行。值得注意的是,每一個需要被調(diào)度的任務必然需要設置一個調(diào)度時間的表達式(cron 表達式),由 Quartz 定時為任務生成待執(zhí)行的 DAG Command,有且僅有一個 Master 節(jié)點獲得執(zhí)行權,掌管該 DAG 各任務節(jié)點的調(diào)度執(zhí)行。
整體架構
以下是平臺整體的架構圖:
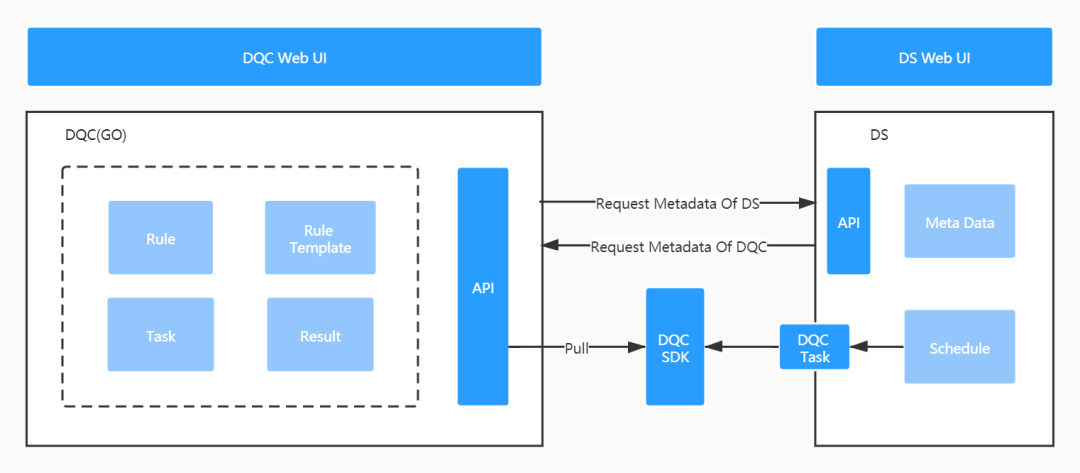
由以下幾部分組成:
DQC Web UI:質檢規(guī)則等前端操作頁面。
DQC(GO):簡單的實體元數(shù)據(jù)管理后臺。主要包括:規(guī)則、規(guī)則模板、質檢任務和質檢結果幾個實體。
DS(數(shù)據(jù)質量部分):質檢任務依賴 DS 調(diào)度執(zhí)行,需要對 DS 進行一定的改造。
DQC SDK(JAR):DS 調(diào)度執(zhí)行任務時,檢測到任務綁定了質檢規(guī)則,將生成一類新的任務 DQC Task (與 DS 中其他類型的 Task 同級,DS 對于 TasK 進行了很好的抽象可以方便擴展),本質上該 Task 將以腳本形式調(diào)用執(zhí)行 DQC SDK 的邏輯。DQC SDK 涵蓋了規(guī)則解析、執(zhí)行的全部邏輯。
下文主要闡述我們在各模塊設計上的一些思考和權衡。
規(guī)則表述
標準與規(guī)則
前文在調(diào)研部分提及了業(yè)內(nèi)普遍認可的數(shù)據(jù)質量的六大標準。那么問題來了:
如何將標準與平臺的規(guī)則對應起來?
標準中涉及到的現(xiàn)實場景是否我們可以一一枚舉?
即便我們可以將標準一一細化,數(shù)據(jù)開發(fā)人員是否可以輕松的理解?
可以將這些問題統(tǒng)一歸類為:平臺在規(guī)則設定上是否需要和業(yè)界數(shù)據(jù)質量標準所抽象出來的概念進行綁定。很遺憾我們并沒有找到有關數(shù)據(jù)質量標準更加細化和指導性的描述,事實上作為一個開發(fā)人員這些概念對于我來說是比較費解的,而更貼近程序員視角的方式是「show me the code」,因此我們決定將這一層概念弱化。未來更深入的實踐過程后再做更細化的思考。
標量化
接下來我們著重討論下另一個問題:
如何對規(guī)則提供一種通用的描述(or maybe a kind of DSL)?
其實當我們跳脫出前文所描述的一切背景和概念,仔細思考下數(shù)據(jù)質檢的過程,會發(fā)現(xiàn)本質上就是通過一次真實的任務執(zhí)行產(chǎn)出結果,然后對比輸出結果與期望是否滿足,以驗證任務邏輯的正確性。這個過程可形象得和 Unit Testing 進行類比,只不過 Unit Testing 是通過模擬數(shù)據(jù)構造的一次代碼邏輯的執(zhí)行。另外數(shù)據(jù)任務執(zhí)行產(chǎn)生的結果是一張二維結構的 Hive 表,需要進行加工方能獲取到想要的統(tǒng)計結果,這也是兩者的區(qū)別之一。
順著這個思路,我們可以利用 Unit Testing 的概念從以下三方面繼續(xù)深入:
Actual Value
數(shù)據(jù)任務執(zhí)行產(chǎn)出的結果是一張 Hive 表,我們需要對這張 Hive 表的數(shù)據(jù)進行加工、提取以獲得需要的 Actual Value。涉及到對 Hive 表的加工,必然想到是以 SQL 的方式來實現(xiàn),通過 Query 和 一系列 Aggregation 操作拿到結果,此結果的結構又可分為以下三類:
二維數(shù)組
單行或者單列的一維數(shù)組
單行且單列的標量
顯然單行且單列的標量是我們期望得到的,因為它更易于結果的比較(事實上就目前我們所能想到的規(guī)則,都可以通過 SQL 方式提取為一個標量結果)。因此,在規(guī)則設計中,需要規(guī)則創(chuàng)建者輸入一段用于結果提取的 SQL,該段 SQL 的執(zhí)行結果需要為一個標量。
Expected Value
既然 Actual Value 是一個標量,那么 Expected Value 同樣也是一個標量,需要規(guī)則創(chuàng)建者在平臺輸入。
Assert
上述標量的類型決定了斷言的比較方式。目前我們只支持了數(shù)值型標量的比較方式,包含「大于」、「等于」及「小于」三種比較算子。如出現(xiàn)其他類型標量,需要擴充比較的方式。
以上三要素即可完整的描述規(guī)則想要表達的核心邏輯。如我們想要表述「字段為空異常」的規(guī)則(潛在含義:字段為空的行數(shù)大于 0 時判定異常),就可以通過以下設定滿足:
Actual Value :出現(xiàn)字段為空的行數(shù)
1count(case when ${field} is null then 1 else null end)Expected Value:0
Assert:「大于」
規(guī)則管理
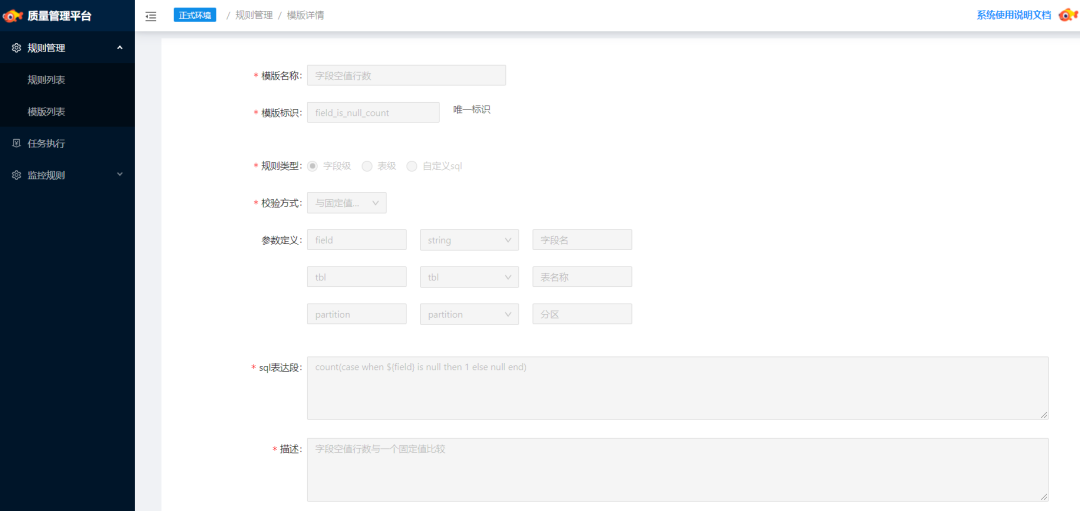
規(guī)則模板
規(guī)則模板是為了規(guī)則復用抽象出的一個概念,模板中包含規(guī)則的 SQL 定義、規(guī)則的比較方式、參數(shù)定義(注:SQL 中包含一些占位符,這些占位符將以參數(shù)的形式被定義,在規(guī)則實體定義時需要用戶明確具體含義)以及其他的一些元信息。下圖為「字段空值的行數(shù)」模板的示例:
規(guī)則實體
規(guī)則實體是基于規(guī)則模板構建的,是規(guī)則的具象表達。在規(guī)則實體中將明確規(guī)則的 Expected Value、比較方式中具體的比較算子、參數(shù)的含義以及其他的一些元信息。基于同一個規(guī)則模板,可以構造多個規(guī)則實體。下圖為「某表 user_id 唯一性校驗」規(guī)則的示例:
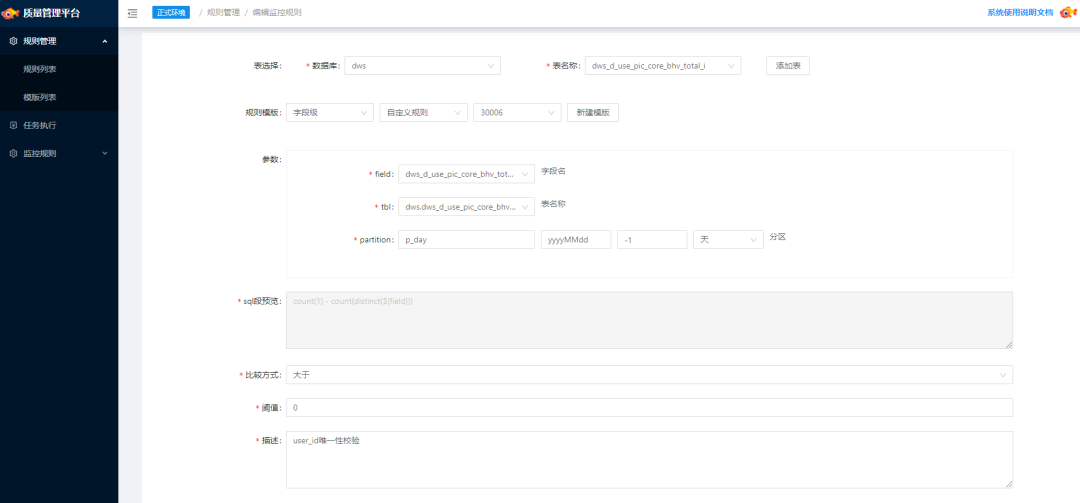
值得一提的是,規(guī)則可能不僅僅只是針對單表的校驗,對于多表的情況我們這套規(guī)則模板同樣是適用的,只要我們可以將邏輯使用 SQL 表達。
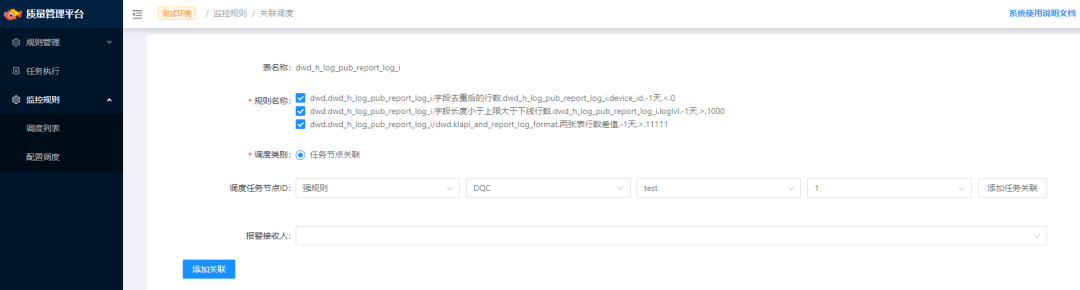
規(guī)則綁定
在 DS 的前端交互上支持為任務直接綁定校驗規(guī)則,規(guī)則列表通過 API 從 DQC 獲取,這種方式在用戶的使用體驗上存在一定的割裂(規(guī)則創(chuàng)建和綁定在兩個平臺完成)。同時,在 DQC 的前端亦可以直接設置關聯(lián)調(diào)度,為已有任務綁定質檢規(guī)則,任務列表通過 API 從 DS 獲取。同一個任務可綁定多個質檢規(guī)則,這些信息將存儲至 DS 的 DAG 元信息中。那么這里需要考慮幾個問題:
規(guī)則的哪些信息應該存儲至 DAG 的元信息中?
規(guī)則的更新 DAG 元信息是否可以實時同步?
主要有兩種方式:
以大 Json 方式將規(guī)則信息打包存儲,計算時解析 Json 逐個執(zhí)行校驗。在規(guī)則更新時,需要同步調(diào)用修改 Json 信息。
以 List 方式存儲規(guī)則 ID,計算時需執(zhí)行一次 Pull 操作獲取規(guī)則具體信息然后執(zhí)行校驗。規(guī)則更新,無須同步更新 List 信息。
我們選擇了后者,ID List 方式可以使對 DS 的侵入降到最低。
規(guī)則執(zhí)行
強規(guī)則和弱規(guī)則
規(guī)則的強弱性質由用戶為任務綁定規(guī)則時設定,此性質決定了規(guī)則執(zhí)行的方式。
強規(guī)則
和當前所執(zhí)行的任務節(jié)點同步執(zhí)行,一旦規(guī)則檢測失敗整個任務節(jié)點將置為執(zhí)行失敗的狀態(tài),后續(xù)任務節(jié)點的執(zhí)行會被阻斷。對應 DS 中的執(zhí)行過程表述如下:
Step1:某一個 Master 節(jié)點獲取 DAG 的執(zhí)行權,將 DAG 拆分成不同的 Job Task 先后下發(fā)給 Worker 節(jié)點執(zhí)行。
Step2:執(zhí)行 Job Task 邏輯,并設置 Job Task 的 ExitStatusCode。
Step3:判斷 Job Task 是否綁定了強規(guī)則。若是,則生成 DQC Task 并觸發(fā)執(zhí)行,最后根據(jù)執(zhí)行結果修正 Job Task 的 ExitStatusCode。
Step4:Master 節(jié)點根據(jù) Job Task 的 ExitStatusCode 判定任務是否成功執(zhí)行,繼續(xù)進入后續(xù)的調(diào)度邏輯。
弱規(guī)則
和當前所執(zhí)行的任務節(jié)點異步執(zhí)行,規(guī)則檢測結果對于原有的任務執(zhí)行狀態(tài)無影響,從而也就不能阻斷后續(xù)任務的執(zhí)行。對應 DS 中的執(zhí)行過程表述如下:
Step1:某一個 Master 節(jié)點獲取 DAG 的執(zhí)行權,將 DAG 拆分成不同的 Job Task 先后下發(fā)給 Worker 節(jié)點執(zhí)行。
Step2:執(zhí)行 Job Task 邏輯,并設置 Job Task 的 ExitStatusCode。
Step3:判斷 Job Task 是否綁定了弱規(guī)則。若是,則在 Job Task 的 Context 中設置弱規(guī)則的標記 。
Step4:Master 節(jié)點根據(jù) Job Task 的 ExitStatusCode 判定任務是否成功執(zhí)行,若成功執(zhí)行再判定是否 Context 中帶有弱規(guī)則標記,若有則生成一個新的 DAG(有且僅有一個 DQC Task,且新生成的 DAG 與 當前執(zhí)行的 DAG 沒有任何的關聯(lián)) 然后繼續(xù)進入后續(xù)的調(diào)度邏輯。
Step5:各 Master 節(jié)點競爭新生成的 DAG 的執(zhí)行權。
可以看出在強弱規(guī)則的執(zhí)行方式上,對 DS 調(diào)度部分的代碼有一定的侵入,但這個改動不大,成本是可以接受的。
DQC Task & DQC SDK
上文提及到一個 Job Task 綁定的規(guī)則(可能有多個)將被轉換為一個 DQC Task 被 DS 調(diào)度執(zhí)行,接下來我們就討論下 DQC Task 的實現(xiàn)細節(jié)以及由此引出的 DQC SDK 的設計和實現(xiàn)。
DQC Task 繼承自 DS 中的抽象類 AbstractTask,只需要實現(xiàn)抽象方法 handle(任務執(zhí)行的具體實現(xiàn))即可。那么對于我們的質檢任務,實際上執(zhí)行邏輯可以拆分成以下幾步:
提取 Job Task 綁定的待執(zhí)行的 Rule ID List。
拉取各個 Rule ID 對應的詳情信息。
構建完整的執(zhí)行 Query 語句(將規(guī)則參數(shù)填充至模板 SQL 中)。
執(zhí)行 Query。
執(zhí)行 Asset。
最核心的步驟為 Query 的執(zhí)行。Query 的實現(xiàn)方式又可分為兩種:
Spark 實現(xiàn)
優(yōu)點:實現(xiàn)可控,靈活性更高。
缺點:配置性要求較高。
Presto SQL 實現(xiàn)
優(yōu)點:不需要額外配置,開發(fā)量少,拼接 SQL 即可。
缺點:速度沒有 Spark 快。
我們選擇了后者,這種方式最易實現(xiàn),離線場景這部分的計算耗時也可以接受。同時由于一個 DQC Task 包含多條規(guī)則,在拼接 SQL 時將同表的規(guī)則聚合以減少 IO 次數(shù)。不同的 SQL 交由不同的線程并行執(zhí)行。
上述執(zhí)行邏輯其實是一個完整且閉環(huán)的功能模塊,因此我們想到將其作為一個單獨的 SDK 對外提供,并以 Jar 包的形式被 DS 依賴,后續(xù)即便是更換調(diào)度引擎,這部分的邏輯可直接遷移使用(當然概率很低)。那么 DS 中 DQC Task 的 handle 邏輯也就變得異常簡單,直接以 Shell 形式調(diào)用 SDK ,進一步降低對 DS 代碼的侵入。
執(zhí)行結果
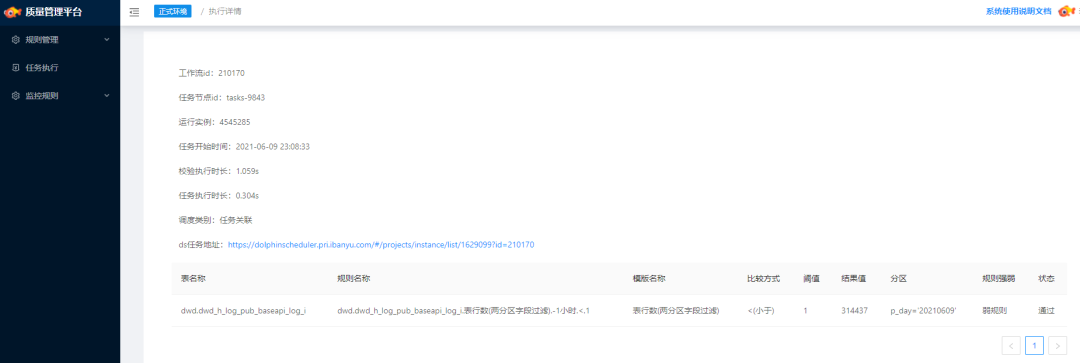
單條規(guī)則的質檢結果將在平臺上直接展現(xiàn),目前我們還未對任務級的規(guī)則進行聚合匯總,這是接下來需要完善的。對于質檢失敗的任務將向報警接收人發(fā)送報警。
實踐中的問題
平臺解決了規(guī)則創(chuàng)建、規(guī)則執(zhí)行的問題,而在實踐過程中,對用戶而言更關心的問題是:
一個任務應該需要涵蓋哪些的規(guī)則才能有效地保證數(shù)據(jù)的質量?
我們不可能對全部的表和字段都添加規(guī)則,那么到底哪些是需要添加的?
這些是很難通過平臺自動實現(xiàn)的,因為平臺理解不了業(yè)務的信息,平臺能做的只能是通過質量檢測報告給與用戶反饋。因此這個事情需要具體的開發(fā)人員對核心場景進行梳理,在充分理解業(yè)務場景后根據(jù)實際情況進行設定。話又說回來,平臺只是工具,每一個數(shù)據(jù)開發(fā)人員應當提升保證數(shù)據(jù)質量的意識,這又涉及到組織內(nèi)規(guī)范落地的問題了。
未來工作
數(shù)據(jù)質量管理是一個長期的過程,未來在平臺化方向我們還有幾個關鍵的部分有待繼續(xù)推進:
基于血緣關系建立全鏈路的數(shù)據(jù)質量監(jiān)控。當前的監(jiān)控粒度是任務級的,如果規(guī)則設置的是弱規(guī)則,下游對于數(shù)據(jù)問題依舊很難感知。
數(shù)據(jù)質量的結果量化。需要建立起一套指標用于定量地衡量數(shù)據(jù)的質量。
支持實時數(shù)據(jù)的質量檢測。