
綜述:在RGB-D圖像上進(jìn)行目標(biāo)檢測(cè)(Object detection in RGB-D images)

極市導(dǎo)讀
?融合顯著深度特征的RGB-D圖像顯著目標(biāo)檢測(cè)方法是提取基于顏色和深度顯著圖的綜合特征,根據(jù)構(gòu)圖先驗(yàn)和背景先驗(yàn)的方法進(jìn)行顯著目標(biāo)檢測(cè)。本文根據(jù)論文先后發(fā)表的時(shí)間順序,帶大家速覽自2014年以來(lái)的,在RGB-D圖像上進(jìn)行目標(biāo)檢測(cè)的典型論文。>>加入極市CV技術(shù)交流群,走在計(jì)算機(jī)視覺(jué)的最前沿
前言
CNN(convolutional neural network)在目標(biāo)檢測(cè)中大放異彩,R-CNN系列,YOLO,SSD各類優(yōu)秀的方法層出不窮。在2D圖像的目標(biāo)檢測(cè)上,不少學(xué)術(shù)界提出的框架已經(jīng)投入商用。但是,具體落實(shí)到自動(dòng)駕駛、機(jī)器人這類應(yīng)用場(chǎng)景上時(shí),2D場(chǎng)景下的目標(biāo)檢測(cè)對(duì)于3D真實(shí)世界的場(chǎng)景描述依然不夠。
目標(biāo)檢測(cè)問(wèn)題實(shí)際上包含了兩個(gè)任務(wù):定位和分類。3D目標(biāo)檢測(cè)在定位這一任務(wù)上的目標(biāo)是返回3D bounding boxes,而其需要的信息除了2D的RGB圖像以外,還包含了與之對(duì)應(yīng)的深度信息Depth Map:
RGB-D?=?普通的RGB三通道彩色圖像?+?Depth Map
在3D計(jì)算機(jī)圖形中,Depth Map(深度圖)是包含與視點(diǎn)的場(chǎng)景對(duì)象的表面的距離有關(guān)的信息的圖像或圖像通道。其中,Depth Map 類似于灰度圖像,只是它的每個(gè)像素值是傳感器距離物體的實(shí)際距離。通常RGB圖像和Depth圖像是配準(zhǔn)的,因而像素點(diǎn)之間具有一對(duì)一的對(duì)應(yīng)關(guān)系。
本文以時(shí)間為主軸,帶你速覽自2014年以來(lái)的,在RGB-D圖像上進(jìn)行目標(biāo)檢測(cè)的典型論文。
論文
2014年:Learning Rich Features from RGB-D Images for Object Detection and Segmentation(ECCV'14)
本文是rbg大神在berkeley時(shí)的作品。”基于CNN已經(jīng)在圖像分類、對(duì)象檢測(cè)、語(yǔ)義分割、細(xì)粒度分類上表現(xiàn)出了相當(dāng)?shù)膬?yōu)勢(shì),不少工作已經(jīng)將CNN引入在RGB-D圖像上的視覺(jué)任務(wù)上。這些工作中一部分直接采用4-channel的圖像來(lái)進(jìn)行語(yǔ)義分割任務(wù)(not object detetction),一部分只是在非常理想的環(huán)境下對(duì)小物體進(jìn)行目標(biāo)檢測(cè)。“
作者的方法是在2D目標(biāo)檢測(cè)框架R-CNN的基礎(chǔ)上,增加對(duì)Depth Map進(jìn)行利用的module,總體結(jié)構(gòu)如下:
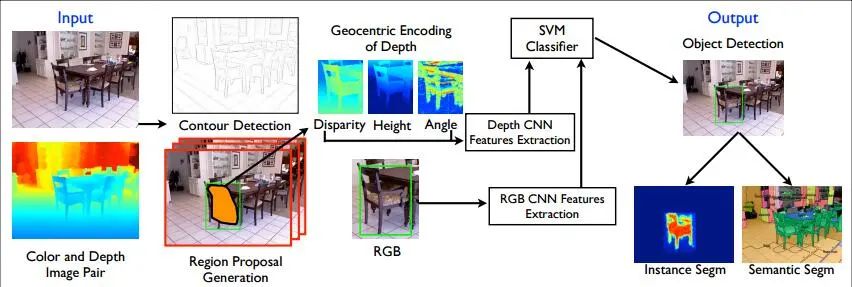
(1)基于RGB圖像和Depth Map,檢測(cè)圖像中的輪廓,并生成2.5D的proposals(從overview上可以看到,所謂的2.5D實(shí)則包括目標(biāo)每個(gè)像素的視差、高度、傾斜角)
(2)利用CNN進(jìn)行特征提取,這里的網(wǎng)絡(luò)包括兩個(gè):Depth CNN學(xué)習(xí)深度圖上的特征,RGB CNN學(xué)習(xí)2D圖像上的特征,最后利用SVM進(jìn)行分類。
在對(duì)Depth Map的利用上,論文所述方法并沒(méi)有直接利用CNN對(duì)其進(jìn)行學(xué)習(xí),而是encode the depth image with three channels at each pixel: horizontal disparity(水平視差), height above ground(高度), and the angle the pixel’s local surface normal makes with the inferred gravity direction(相對(duì)于重力的傾斜角).
2015年:3D Object Proposals for Accurate Object Class Detection(NIPS'15)
來(lái)自Tsing Hua陳曉智大神的作品(大神在同時(shí)也是CVPR17: Multi-View 3D Object Detection Network for Autonomous Driving的一作,給跪了)。
作者首先指出,目前最先進(jìn)的RCNN方法在自動(dòng)駕駛數(shù)據(jù)集KITTI上表現(xiàn)不好,原因之一在于KITTI上的測(cè)試圖像中,包含許多小型物體、遮擋、陰影,使得實(shí)際包含了object的proposals被認(rèn)為是不包含的。此外,KITTI對(duì)區(qū)域的精細(xì)程度要求很高(overlap),而目前的大多數(shù)區(qū)域推薦都基于強(qiáng)度和紋理的grouping super pixels,它們無(wú)法獲得高質(zhì)量的proposals。
文章面向自動(dòng)駕駛場(chǎng)景,提出了一種新的object proposal方法。對(duì)于每一個(gè)3D bounding box(記為y),將其用一個(gè)元組來(lái)表示(x, y, z, θ, c, t),(x, y, z) 表示 3D box的中心,θ 表示其方位角,c代表object是哪一類,t代表相應(yīng)的3d box模板集合。
以x代表點(diǎn)云,y代表proposal,作者認(rèn)為y應(yīng)該有以下特性:
包含點(diǎn)云的高密度區(qū)域
不能與free space重疊
點(diǎn)云不應(yīng)該垂直延伸在3d box之外
box附近的點(diǎn)云高度應(yīng)該比之低
基于這些特性,作者列出了能量方程,目標(biāo)為最小化E(x,y),采用ICML2004上一篇文章中所述的structured SVM進(jìn)行訓(xùn)練。
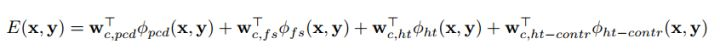
文章中所述方法的效果、代碼、數(shù)據(jù):3D Object Proposals for Accurate Object Class Detection

2016年:Deep Sliding Shapes for Amodal 3D Object Detection in RGB-D Images(CVPR'16)
文章來(lái)自普林斯頓大學(xué),提出的方法為Faster R-CNN的3D版本,側(cè)重于indoor scene下的object detection。
目前關(guān)于3D目標(biāo)檢測(cè)任務(wù)的方法,有采用2D方法來(lái)結(jié)合深度圖的,也有在3D空間內(nèi)進(jìn)行檢測(cè)的。這不禁讓作者發(fā)問(wèn):which representation is better for 3D amodal object detection, 2D or 3D?接著他指出,目前2D方法表現(xiàn)更優(yōu)異的原因,可能是因?yàn)槠銫NN模型更為powerful(well-designed&pre-trained with ImageNet),而不是由于其2D表達(dá)。
作者的方法是設(shè)計(jì)名為Deep Sliding Shapes的3D CNN,輸入3D的立體場(chǎng)景,輸出3D bounding boxes,由此提出了Multi-scale 3D RPN(Region Proposal Network):
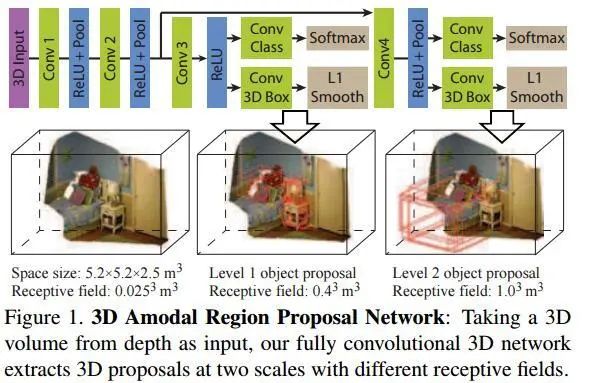
類似于Faster R-CNN中的RPN網(wǎng)絡(luò),對(duì)于每一個(gè)滑動(dòng)窗口,作者定義N=19種anchor boxes:
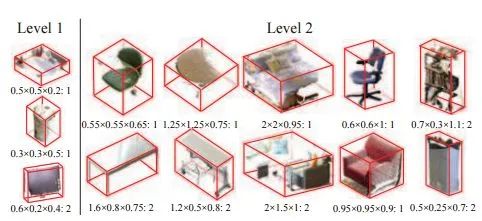
而后,為了檢測(cè)大小不一的目標(biāo),作者增加了多尺度的檢測(cè)手段。具體來(lái)說(shuō),在不同的卷積層上進(jìn)行滑窗。這里的滑窗是3D sliding window,因?yàn)檎麄€(gè)網(wǎng)絡(luò)結(jié)構(gòu)就是接收3Dinput的。為了精修區(qū)域,作者改進(jìn)了bbox regression,提出3D box regression:一個(gè)3D box可以由中心坐標(biāo)[cx, cy, cz],長(zhǎng)寬高[s1, s2, s3]來(lái)表示,最后要得到的是6個(gè)偏移量:
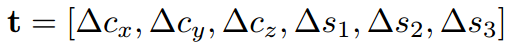
而后采用與2D box regression同樣的smooth L1 loss即可。
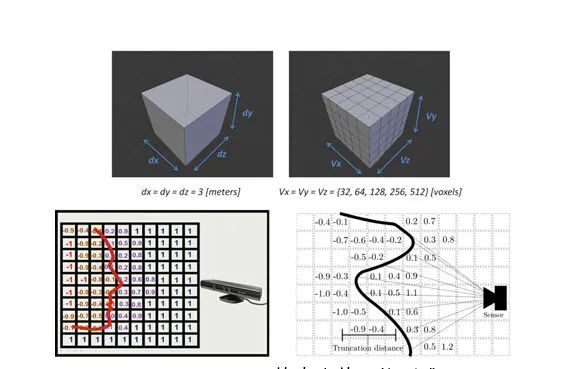
補(bǔ)充:如何從Depth Map得到3D Input?
Encoding 3D Representation:不同于Depth RCNN的disparity+height+angle 表達(dá),作者在這里采用了TSDF方法,可以看如下的引用:
KinectFusion在世界坐標(biāo)系中定義了一個(gè)立方體,并把該立方體按照一定的分辨率切割成小立方體(voxel)。以圖8上為例所示,圖中定義了一個(gè)3x3x3米的立方體,并把立方體分為不同分辨率的小立方體網(wǎng)格。也就是說(shuō),這個(gè)大立方體限制了經(jīng)過(guò)掃描重建的模型的體積。然后,KinectFusion使用了一種稱為“截?cái)嘤蟹?hào)距離函數(shù)”(truncated signed distance function,簡(jiǎn)稱TSDF)的方法來(lái)更新每個(gè)小網(wǎng)格中的一個(gè)數(shù)值,該數(shù)值代表了該網(wǎng)格到模型表面的最近距離,也稱為TSDF值(圖8下)。對(duì)于每個(gè)網(wǎng)格,在每一幀都會(huì)更新并記錄TSDF的值,然后再通過(guò)TSDF值還原出重建模型。例如,通過(guò)圖8下兩幅圖中的網(wǎng)格的TSDF數(shù)值分布,我們可以很快還原出模型表面的形狀和位置。這種方法通常被稱為基于體數(shù)據(jù)的方法(Volumetric-based method)。該方法的核心思想是,通過(guò)不斷更新并“融合”(fusion)TSDF這種類型的測(cè)量值,我們能夠 越來(lái)越接近所需要的真實(shí)值。
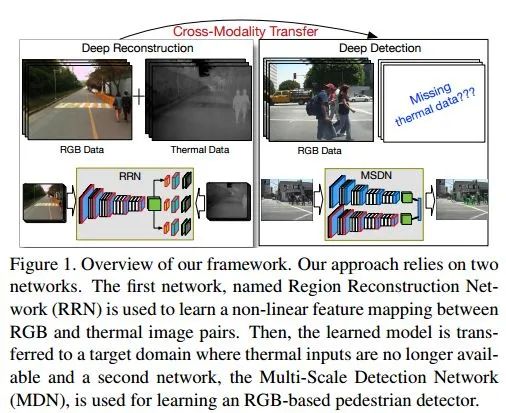
2017:Learning Cross-Modal Deep Representations for Robust Pedestrian Detection(CVPR'17)
這篇文章雖然是針對(duì)于專門的pedestrians detection任務(wù),但是其做法是很具有啟發(fā)性的,所以也貼在這里。
作者指出,“行人檢測(cè)任務(wù)在深度學(xué)習(xí)的幫助下已經(jīng)取得重大突破,同時(shí)新型傳感器(如thermal and depth cameras)也為解決不利照明和遮擋提供了新的機(jī)會(huì)。但是,現(xiàn)有監(jiān)控系統(tǒng)絕大多數(shù)仍然采用傳統(tǒng)的RGB傳感器,因此在illumination variation, shadows, and low external light仍然十分具有挑戰(zhàn)。”
在針對(duì)于照明條件不利環(huán)境下的行人檢測(cè)任務(wù),文章描述了一種依賴于cross-modality learning framework的學(xué)習(xí)框架,由兩個(gè)網(wǎng)絡(luò)組成:
(1)Region Reconstruction Network (RRN)
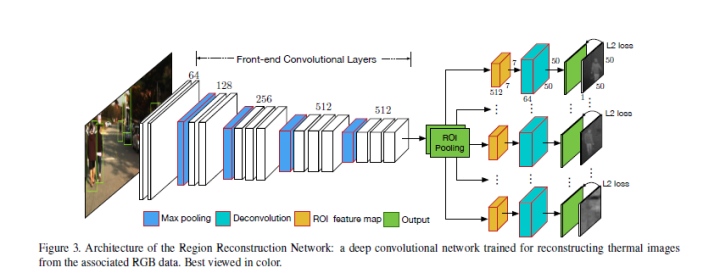
RRN用于學(xué)習(xí)在RGB圖像和thermal image間的映射,而后學(xué)習(xí)得到的模型就可以用于依據(jù)RGB生成thermal image。RRN接收RGB+行人proposals,在ROI Pooling后加了重建網(wǎng)絡(luò)(全卷積)。這里的重建網(wǎng)絡(luò)不重建整幅圖像的thermal image,而是只對(duì)行人區(qū)域進(jìn)行重建。
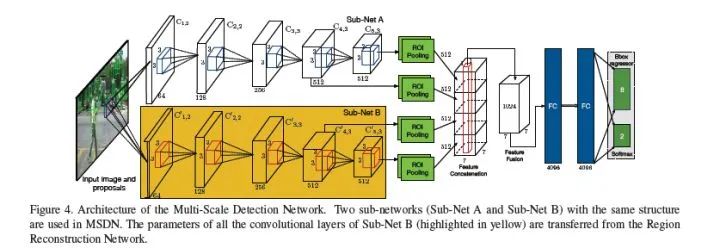
(2)Multi-Scale Detection Network (MSDN)
MSDN利用RRN學(xué)習(xí)的cross-modal representations來(lái)進(jìn)行檢測(cè)。其包含兩個(gè)子網(wǎng)(Sub-Net A和Sub-Net B),其中Sub-Net B中的參數(shù)從RRN中遷移而來(lái),最后的fc分別做multi-task:bbox regression和softmax。
2017:Amodal Detection of 3D Objects: Inferring 3D Bounding Boxes from 2D Ones in RGB-Depth Images(CVPR'17)
來(lái)自坦普爾大學(xué)的文章。作者在這里與2016的Deep Sliding Shapes思路不同,重新回到2.5D方法來(lái)進(jìn)行3D目標(biāo)檢測(cè)。所謂2.5D方法,實(shí)則就是從RGB-D上提取出合適的表達(dá),而后building models to convert 2D results to 3D space。“雖然利用三維幾何特征檢測(cè)前景光明,但在實(shí)踐中,重建的三維形狀往往不完整,由于遮擋、反射等原因而含有各種噪聲。”
整個(gè)系統(tǒng)的overview如下,其基于Fast R-CNN實(shí)現(xiàn):
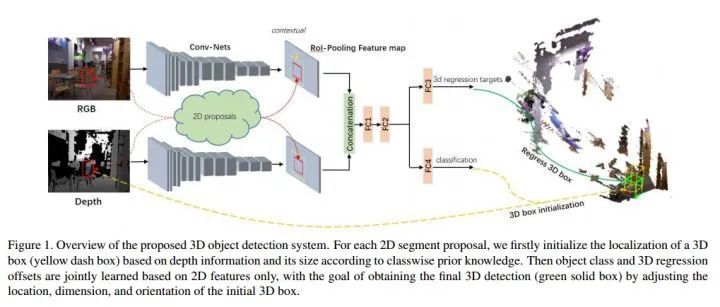
對(duì)于每一個(gè)2D的proposal(這里關(guān)于2D proposals的方法就是用的Depth R-CNN中的方法),由分類結(jié)果和depth information來(lái)初始化一個(gè)3D bounding box(圖中黃色的虛線框),而后也是用一個(gè)3d box regression來(lái)進(jìn)行區(qū)域精修。重點(diǎn)關(guān)注3D box proposal and regression:
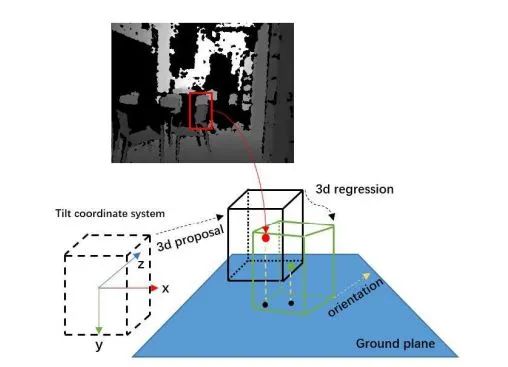
圖中是3D box proposal的一個(gè)實(shí)例。每一個(gè)3d box由向量[xcam, ycam, zcam, l, w, h, θ].來(lái)表達(dá),[xcam, ycam, zcam]表中心位置,[l, w, h]表尺寸,θ∈ [?π/2, π/2]表示方位角,即圖中黃色的箭頭與z軸形成的夾角。在初始化的時(shí)候,關(guān)于尺寸是由某一類物體的類別來(lái)進(jìn)行確定的。最后輸出7個(gè)調(diào)整量[δx, δy, δz, δl, δw, δh, δθ],利用Smooth L1 Loss作為損失函數(shù)。
結(jié)語(yǔ)
3D目標(biāo)檢測(cè)對(duì)于自動(dòng)駕駛與機(jī)器人等領(lǐng)域意義重大。本文以時(shí)間為序,重點(diǎn)關(guān)注和分析了基于RGB-D上的3D Object Detection方法。從Depth R-CNN到3D Faster-RCNN,似乎始終基于2D的目標(biāo)檢測(cè)框架在跟循改進(jìn)。期待在未來(lái),將會(huì)有更為優(yōu)美的方法出現(xiàn)。
感謝您的閱讀,文中的遺漏與錯(cuò)誤,懇請(qǐng)批評(píng)指正。
參考文獻(xiàn)
推薦閱讀
深度學(xué)習(xí)檢測(cè)小目標(biāo)常用方法
目標(biāo)檢測(cè)類算法比賽的經(jīng)驗(yàn)總結(jié)
詳細(xì)記錄u版YOLOv5目標(biāo)檢測(cè)ncnn實(shí)現(xiàn)
