
超全Spark性能優(yōu)化總結
點擊上方藍色字體,選擇“設為星標”





Spark是大數(shù)據(jù)分析的利器,在工作中用到spark的地方也比較多,這篇總結是希望能將自己使用spark的一些調(diào)優(yōu)經(jīng)驗分享出來。
一、常用參數(shù)說明
--driver-memory 4g : driver內(nèi)存大小,一般沒有廣播變量(broadcast)時,
設置4g足夠,如果有廣播變量,視情況而定,可設置6G,8G,12G等均可
--executor-memory 4g : 每個executor的內(nèi)存,正常情況下是4g足夠,但有時
處理大批量數(shù)據(jù)時容易內(nèi)存不足,再多申請一點,如6G
--num-executors 15 : 總共申請的executor數(shù)目,普通任務十幾個或者幾十個
足夠了,若是處理海量數(shù)據(jù)如百G上T的數(shù)據(jù)時可以申請多一些,100,200等
--executor-cores 2 : 每個executor內(nèi)的核數(shù),即每個executor中的任務
task數(shù)目,此處設置為2,即2個task共享上面設置的6g內(nèi)存,每個map或reduce
任務的并行度是executor數(shù)目*executor中的任務數(shù)
yarn集群中一般有資源申請上限,如,executor-memory*num-executors
< 400G 等,所以調(diào)試參數(shù)時要注意這一點
—-spark.default.parallelism 200 :Spark作業(yè)的默認為500~1000個比較
合適,如果不設置,spark會根據(jù)底層HDFS的block數(shù)量設置task的數(shù)量,這樣
會導致并行度偏少,資源利用不充分。該參數(shù)設為num-executors *
executor-cores的2~3倍比較合適。
-- spark.storage.memoryFraction 0.6 : 設置RDD持久化數(shù)據(jù)在Executor
內(nèi)存中能占的最大比例。默認值是0.6
—-spark.shuffle.memoryFraction 0.2 :設置shuffle過程中一個task拉取
到上個stage的task的輸出后,進行聚合操作時能夠使用的Executor內(nèi)存的比例,
默認是0.2,如果shuffle聚合時使用的內(nèi)存超出了這個20%的限制,多余數(shù)據(jù)會
被溢寫到磁盤文件中去,降低shuffle性能
—-spark.yarn.executor.memoryOverhead 1G :executor執(zhí)行的時候,用的
內(nèi)存可能會超過executor-memory,所以會為executor額外預留一部分內(nèi)存,
spark.yarn.executor.memoryOverhead即代表這部分內(nèi)存二、Spark常用編程建議
避免創(chuàng)建重復的RDD,盡量復用同一份數(shù)據(jù)。
盡量避免使用shuffle類算子,因為shuffle操作是spark中最消耗性能的地方,reduceByKey、join、distinct、repartition等算子都會觸發(fā)shuffle操作,盡量使用map類的非shuffle算子
用aggregateByKey和reduceByKey替代groupByKey,因為前兩個是預聚合操作,會在每個節(jié)點本地對相同的key做聚合,等其他節(jié)點拉取所有節(jié)點上相同的key時,會大大減少磁盤IO以及網(wǎng)絡開銷。
repartition適用于RDD[V], partitionBy適用于RDD[K, V]
mapPartitions操作替代普通map,foreachPartitions替代foreach
filter操作之后進行coalesce操作,可以減少RDD的partition數(shù)量
如果有RDD復用,尤其是該RDD需要花費比較長的時間,建議對該RDD做cache,若該RDD每個partition需要消耗很多內(nèi)存,建議開啟Kryo序列化機制(據(jù)說可節(jié)省2到5倍空間),若還是有比較大的內(nèi)存開銷,可將storage_level設置為MEMORY_AND_DISK_SER
盡量避免在一個Transformation中處理所有的邏輯,盡量分解成map、filter之類的操作
多個RDD進行union操作時,避免使用rdd.union(rdd).union(rdd).union(rdd)這種多重union,rdd.union只適合2個RDD合并,合并多個時采用SparkContext.union(Array(RDD)),避免union嵌套層數(shù)太多,導致的調(diào)用鏈路太長,耗時太久,且容易引發(fā)StackOverFlow
spark中的Group/join/XXXByKey等操作,都可以指定partition的個數(shù),不需要額外使用repartition和partitionBy函數(shù)
盡量保證每輪Stage里每個task處理的數(shù)據(jù)量>128M
如果2個RDD做join,其中一個數(shù)據(jù)量很小,可以采用Broadcast Join,將小的RDD數(shù)據(jù)collect到driver內(nèi)存中,將其BroadCast到另外以RDD中,其他場景想優(yōu)化后面會講
2個RDD做笛卡爾積時,把小的RDD作為參數(shù)傳入,如BigRDD.certesian(smallRDD)
若需要Broadcast一個大的對象到遠端作為字典查詢,可使用多executor-cores,大executor-memory。若將該占用內(nèi)存較大的對象存儲到外部系統(tǒng),executor-cores=1, executor-memory=m(默認值2g),可以正常運行,那么當大字典占用空間為size(g)時,executor-memory為2*size,executor-cores=size/m(向上取整)
15.如果對象太大無法BroadCast到遠端,且需求是根據(jù)大的RDD中的key去索引小RDD中的key,可使用zipPartitions以hash join的方式實現(xiàn),具體原理參考下一節(jié)的shuffle過程
如果需要在repartition重分區(qū)之后還要進行排序,可直接使用repartitionAndSortWithinPartitions,比分解操作效率高,因為它可以一邊shuffle一邊排序
三、shuffle性能優(yōu)化
3.1 什么是shuffle操作 spark中的shuffle操作功能:將分布在集群中多個節(jié)點上的同一個key,拉取到同一個節(jié)點上,進行聚合或join操作,類似洗牌的操作。這些分布在各個存儲節(jié)點上的數(shù)據(jù)重新打亂然后匯聚到不同節(jié)點的過程就是shuffle過程。
3.2 哪些操作中包含shuffle操作
RDD的特性是不可變的帶分區(qū)的記錄集合,Spark提供了Transformation和Action兩種操作RDD的方式。Transformation是生成新的RDD,包括map, flatMap, filter, union, sample, join, groupByKey, cogroup, ReduceByKey, cros, sortByKey, mapValues等;Action只是返回一個結果,包括collect,reduce,count,save,lookupKey等
Spark所有的算子操作中是否使用shuffle過程要看計算后對應多少分區(qū):
若一個操作執(zhí)行過程中,結果RDD的每個分區(qū)只依賴上一個RDD的同一個分區(qū),即屬于窄依賴,如map、filter、union等操作,這種情況是不需要進行shuffle的,同時還可以按照pipeline的方式,把一個分區(qū)上的多個操作放在同一個Task中進行
若結果RDD的每個分區(qū)需要依賴上一個RDD的全部分區(qū),即屬于寬依賴,如repartition相關操作(repartition,coalesce)、 * ByKey操作(groupByKey,ReduceByKey,combineByKey、aggregateByKey等)、join相關操作(cogroup,join)、distinct操作,這種依賴是需要進行shuffle操作的
3.3 shuffle操作過程
shuffle過程分為shuffle write和shuffle read兩部分
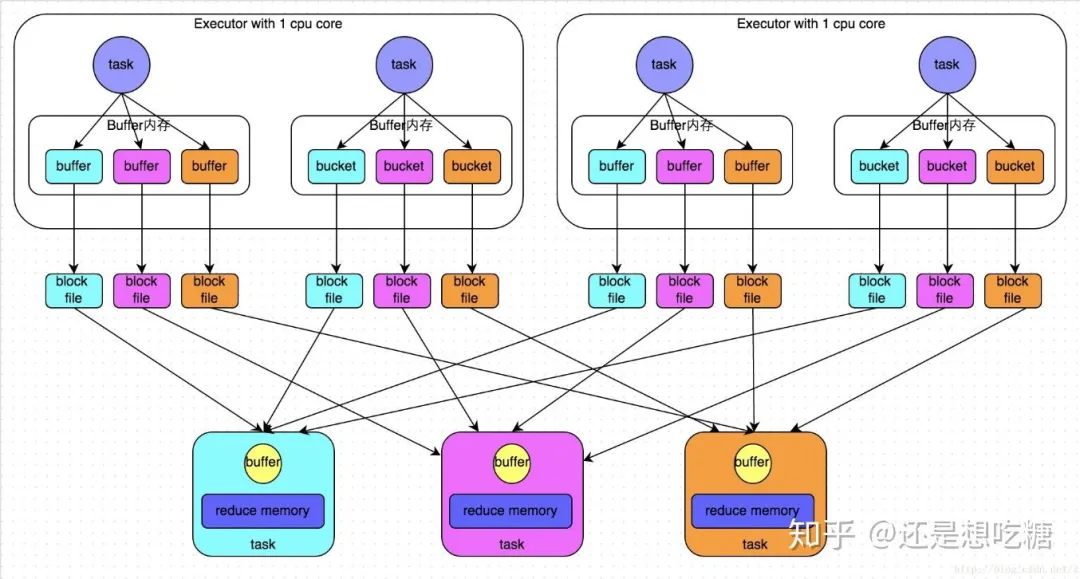
shuffle write:分區(qū)數(shù)由上一階段的RDD分區(qū)數(shù)控制,shuffle write過程主要是將計算的中間結果按某種規(guī)則臨時放到各個executor所在的本地磁盤上(當前stage結束之后,每個task處理的數(shù)據(jù)按key進行分類,數(shù)據(jù)先寫入內(nèi)存緩沖區(qū),緩沖區(qū)滿,溢寫spill到磁盤文件,最終相同key被寫入同一個磁盤文件)創(chuàng)建的磁盤文件數(shù)量=當前stage中task數(shù)量 * 下一個stage的task數(shù)量
shuffle read:從上游stage的所有task節(jié)點上拉取屬于自己的磁盤文件,每個read task會有自己的buffer緩沖,每次只能拉取與buffer緩沖相同大小的數(shù)據(jù),然后聚合,聚合完一批后拉取下一批,邊拉取邊聚合。分區(qū)數(shù)由Spark提供的一些參數(shù)控制,如果這個參數(shù)值設置的很小,同時shuffle read的數(shù)據(jù)量很大,會導致一個task需要處理的數(shù)據(jù)非常大,容易發(fā)生JVM crash,從而導致shuffle數(shù)據(jù)失敗,同時executor也丟失了,就會看到Failed to connect to host 的錯誤(即executor lost)。
shuffle過程中,各個節(jié)點會通過shuffle write過程將相同key都會先寫入本地磁盤文件中,然后其他節(jié)點的shuffle read過程通過網(wǎng)絡傳輸拉取各個節(jié)點上的磁盤文件中的相同key。這其中大量數(shù)據(jù)交換涉及到的網(wǎng)絡傳輸和文件讀寫操作是shuffle操作十分耗時的根本原因
3.4 spark的shuffle類型
參數(shù)spark.shuffle.manager用于設置ShuffleManager的類型。Spark1.5以后,該參數(shù)有三個可選項:hash、sort和tungsten-sort。
HashShuffleManager是Spark1.2以前的默認值,Spark1.2之后的默認值都是SortShuffleManager。tungsten-sort與sort類似,但是使用了tungsten計劃中的堆外內(nèi)存管理機制,內(nèi)存使用效率更高。
由于SortShuffleManager默認會對數(shù)據(jù)進行排序,因此如果業(yè)務需求中需要排序的話,使用默認的SortShuffleManager就可以;但如果不需要排序,可以通過bypass機制或設置HashShuffleManager避免排序,同時也能提供較好的磁盤讀寫性能。
HashShuffleManager流程:
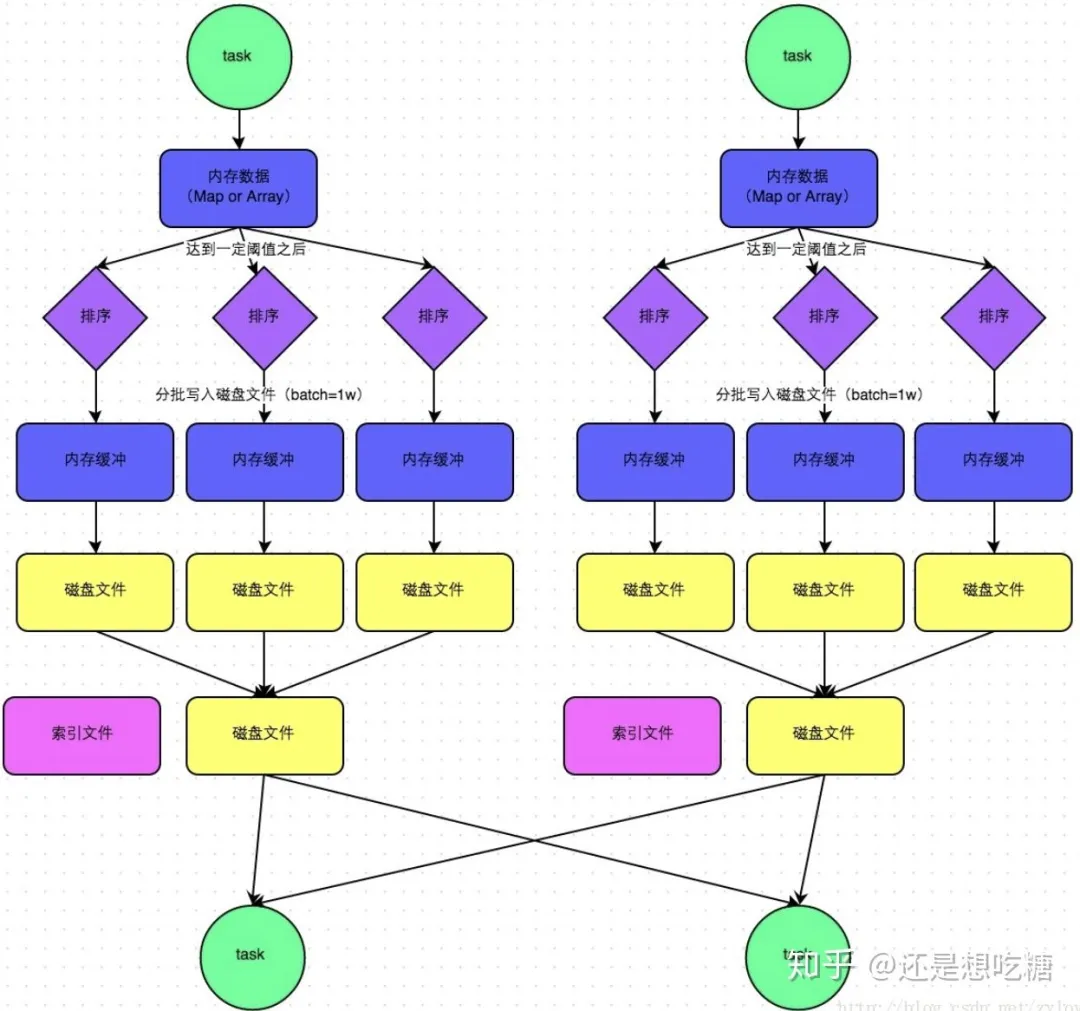
SortShuffleManager流程:
3.5 如何開啟bypass機制
bypass機制通過參數(shù)spark.shuffle.sort.bypassMergeThreshold設置,默認值是200,表示當ShuffleManager是SortShuffleManager時,若shuffle read task的數(shù)量小于這個閾值(默認200)時,則shuffle write過程中不會進行排序操作,而是直接按照未經(jīng)優(yōu)化的HashShuffleManager的方式寫數(shù)據(jù),但最后會將每個task產(chǎn)生的所有臨時磁盤文件合并成一個文件,并創(chuàng)建索引文件。
這里給出的調(diào)優(yōu)建議是,當使用SortShuffleManager時,如果的確不需要排序,可以將這個參數(shù)值調(diào)大一些,大于shuffle read task的數(shù)量。那么此時就會自動開啟bypass機制,map-side就不會進行排序了,減少排序的性能開銷,提升shuffle操作效率。但這種方式并沒有減少shuffle write過程產(chǎn)生的磁盤文件數(shù)量,所以寫的性能沒有改變。
3.6 HashShuffleManager優(yōu)化建議
如果使用HashShuffleManager,可以設置spark.shuffle.consolidateFiles參數(shù)。該參數(shù)默認為false,只有當使用HashShuffleManager且該參數(shù)設置為True時,才會開啟consolidate機制,大幅度合并shuffle write過程產(chǎn)生的輸出文件,對于shuffle read task 數(shù)量特別多的情況下,可以極大地減少磁盤IO開銷,提升shuffle性能。參考社區(qū)同學給出的數(shù)據(jù),consolidate性能比開啟bypass機制的SortShuffleManager高出10% ~ 30%。
3.7 shuffle調(diào)優(yōu)建議
除了上述的幾個參數(shù)調(diào)優(yōu),shuffle過程還有一些參數(shù)可以提高性能:
- spark.shuffle.file.buffer : 默認32M,shuffle Write階段寫文件
時的buffer大小,若內(nèi)存資源比較充足,可適當將其值調(diào)大一些(如64M),
減少executor的IO讀寫次數(shù),提高shuffle性能
- spark.shuffle.io.maxRetries :默認3次,Shuffle Read階段取數(shù)據(jù)
的重試次數(shù),若shuffle處理的數(shù)據(jù)量很大,可適當將該參數(shù)調(diào)大。3.8 shuffle操作過程中的常見錯誤
SparkSQL中的shuffle錯誤:
org.apache.spark.shuffle.MetadataFetchFailedException:
Missing an output location for shuffle 0
org.apache.spark.shuffle.FetchFailedException:Failed to
connect to hostname/192.168.xx.xxx:50268RDD中的shuffle錯誤:
WARN TaskSetManager: Lost task 17.1 in stage 4.1
(TID 1386, spark050013): java.io.FileNotFoundException:
/data04/spark/tmp/blockmgr-817d372f-c359-4a00-96dd
-8f6554aa19cd/2f/temp_shuffle_e22e013a-5392-4edb
-9874-a196a1dad97c (沒有那個文件或目錄)
FetchFailed(BlockManagerId(6083b277-119a-49e8-8a49
-3539690a2a3f-S155, spark050013, 8533), shuffleId=1,
mapId=143, reduceId=3, message=
org.apache.spark.shuffle.FetchFailedException: Error
in opening FileSegmentManagedBuffer{file=/data04/spark
/tmp/blockmgr-817d372f-c359-4a00-96dd-8f6554aa19cd/0e/
shuffle_1_143_0.data, offset=997061, length=112503}處理shuffle類操作的注意事項:
減少shuffle數(shù)據(jù)量:在shuffle前過濾掉不必要的數(shù)據(jù),只選取需要的字段處理
針對SparkSQL和DataFrame的join、group by等操作:可以通過 spark.sql.shuffle.partitions控制分區(qū)數(shù),默認設置為200,可根據(jù)shuffle的量以及計算的復雜度提高這個值,如2000等
RDD的join、group by、reduceByKey等操作:通過spark.default.parallelism控制shuffle read與reduce處理的分區(qū)數(shù),默認為運行任務的core總數(shù),官方建議為設置成運行任務的core的2~3倍
提高executor的內(nèi)存:即spark.executor.memory的值
分析數(shù)據(jù)驗證是否存在數(shù)據(jù)傾斜的問題:如空值如何處理,異常數(shù)據(jù)(某個key對應的數(shù)據(jù)量特別大)時是否可以單獨處理,可以考慮自定義數(shù)據(jù)分區(qū)規(guī)則,如何自定義可以參考下面的join優(yōu)化環(huán)節(jié)
四、join性能優(yōu)化
Spark所有的操作中,join操作是最復雜、代價最大的操作,也是大部分業(yè)務場景的性能瓶頸所在。所以針對join操作的優(yōu)化是使用spark必須要學會的技能。
spark的join操作也分為Spark SQL的join和Spark RDD的join。
4.1 Spark SQL 的join操作
4.1.1 Hash Join
Hash Join的執(zhí)行方式是先將小表映射成Hash Table的方式,再將大表使用相同方式映射到Hash Table,在同一個hash分區(qū)內(nèi)做join匹配。
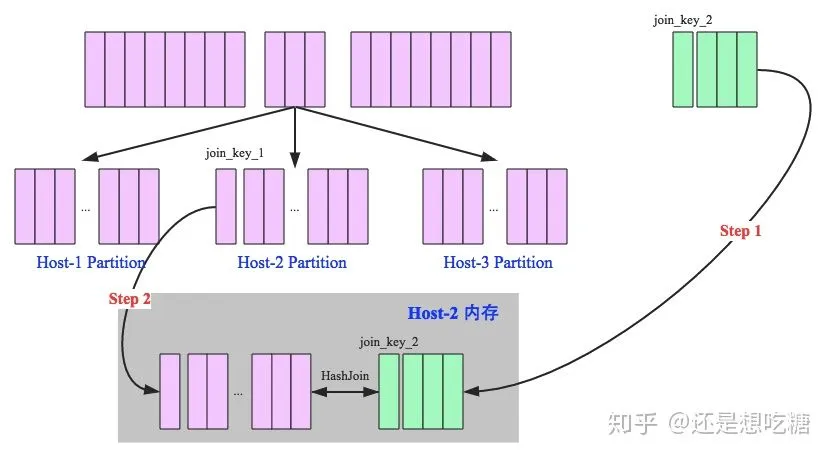
hash join又分為broadcast hash join和shuffle hash join兩種。其中Broadcast hash join,顧名思義,就是把小表廣播到每一個節(jié)點上的內(nèi)存中,大表按Key保存到各個分區(qū)中,小表和每個分區(qū)的大表做join匹配。這種情況適合一個小表和一個大表做join且小表能夠在內(nèi)存中保存的情況。如下圖所示:
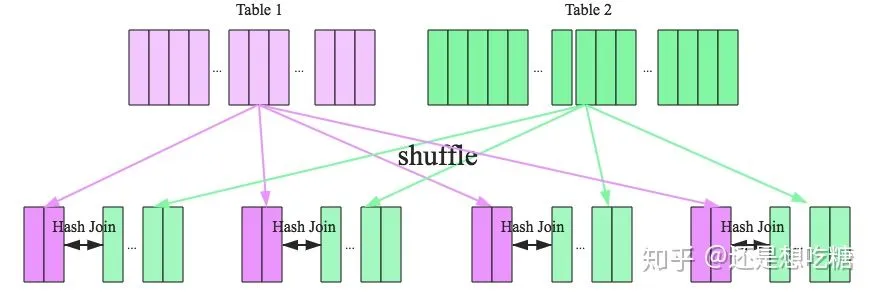
當Hash Join不能適用的場景就需要Shuffle Hash Join了,Shuffle Hash Join的原理是按照join Key分區(qū),key相同的數(shù)據(jù)必然分配到同一分區(qū)中,將大表join分而治之,變成小表的join,可以提高并行度。執(zhí)行過程也分為兩個階段:
shuffle階段:分別將兩個表按照join key進行分區(qū),將相同的join key數(shù)據(jù)重分區(qū)到同一節(jié)點
hash join階段:每個分區(qū)節(jié)點上的數(shù)據(jù)單獨執(zhí)行單機hash join算法
Shuffle Hash Join的過程如下圖所示:
4.1.2 Sort-Merge Join
SparkSQL針對兩張大表join的情況提供了全新的算法——Sort-merge join,整個過程分為三個步驟:
Shuffle階段:將兩張大表根據(jù)join key進行重新分區(qū),兩張表數(shù)據(jù)會分布到整個集群,以便分布式進行處理
sort階段:對單個分區(qū)節(jié)點的兩表數(shù)據(jù),分別進行排序
merge階段:對排好序的兩張分區(qū)表數(shù)據(jù)執(zhí)行join操作。分別遍歷兩個有序序列,遇到相同的join key就merge輸出,否則繼續(xù)取更小一邊的key,即合并兩個有序列表的方式。
sort-merge join流程如下圖所示。
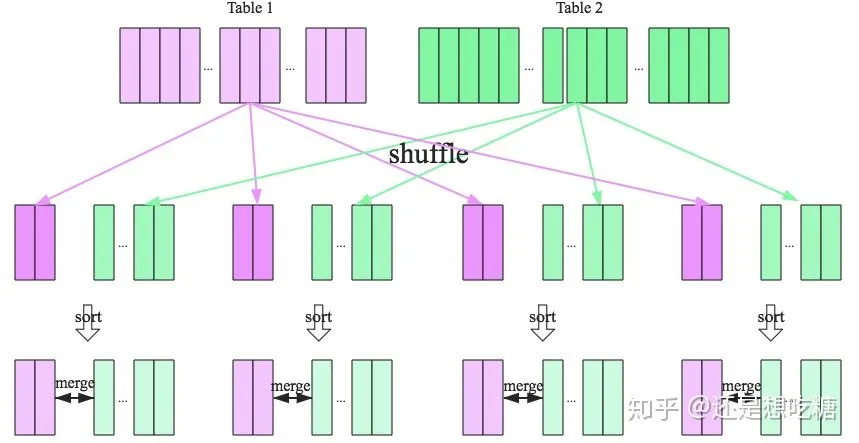
4.2 Spark RDD的join操作
Spark的RDD join沒有上面這么多的分類,但是面臨的業(yè)務需求是一樣的。如果是大表join小表的情況,則可以將小表聲明為broadcast變量,使用map操作快速實現(xiàn)join功能,但又不必執(zhí)行Spark core中的join操作。
如果是兩個大表join,則必須依賴Spark Core中的join操作了。Spark RDD Join的過程可以自行閱讀源碼了解,這里只做一個大概的講解。
spark的join過程中最核心的函數(shù)是cogroup方法,這個方法中會判斷join的兩個RDD所使用的partitioner是否一樣,如果分區(qū)相同,即存在OneToOneDependency依賴,不用進行hash分區(qū),可直接join;如果要關聯(lián)的RDD和當前RDD的分區(qū)不一致時,就要對RDD進行重新hash分區(qū),分到正確的分區(qū)中,即存在ShuffleDependency,需要先進行shuffle操作再join。因此提升join效率的一個思路就是使得兩個RDD具有相同的partitioners。
所以針對Spark RDD的join操作的優(yōu)化建議是:
如果需要join的其中一個RDD比較小,可以直接將其存入內(nèi)存,使用broadcast hash join
在對兩個RDD進行join操作之前,使其使用同一個partitioners,避免join操作的shuffle過程
如果兩個RDD其一存在重復的key也會導致join操作性能變低,因此最好先進行key值的去重處理
4.3 數(shù)據(jù)傾斜優(yōu)化
均勻數(shù)據(jù)分布的情況下,前面所說的優(yōu)化建議就足夠了。但存在數(shù)據(jù)傾斜時,仍然會有性能問題。主要體現(xiàn)在絕大多數(shù)task執(zhí)行得都非常快,個別task執(zhí)行很慢,拖慢整個任務的執(zhí)行進程,甚至可能因為某個task處理的數(shù)據(jù)量過大而爆出OOM錯誤。
4.3.1 分析數(shù)據(jù)分布
如果是Spark SQL中的group by、join語句導致的數(shù)據(jù)傾斜,可以使用SQL分析執(zhí)行SQL中的表的key分布情況;如果是Spark RDD執(zhí)行shuffle算子導致的數(shù)據(jù)傾斜,可以在Spark作業(yè)中加入分析Key分布的代碼,使用countByKey()統(tǒng)計各個key對應的記錄數(shù)。
4.3.2 數(shù)據(jù)傾斜的解決方案
這里參考美團技術博客中給出的幾個方案。
1)針對hive表中的數(shù)據(jù)傾斜,可以嘗試通過hive進行數(shù)據(jù)預處理,如按照key進行聚合,或是和其他表join,Spark作業(yè)中直接使用預處理后的數(shù)據(jù)。
2)如果發(fā)現(xiàn)導致傾斜的key就幾個,而且對計算本身的影響不大,可以考慮過濾掉少數(shù)導致傾斜的key
3)設置參數(shù)spark.sql.shuffle.partitions,提高shuffle操作的并行度,增加shuffle read task的數(shù)量,降低每個task處理的數(shù)據(jù)量
4)針對RDD執(zhí)行reduceByKey等聚合類算子或是在Spark SQL中使用group by語句時,可以考慮兩階段聚合方案,即局部聚合+全局聚合。第一階段局部聚合,先給每個key打上一個隨機數(shù),接著對打上隨機數(shù)的數(shù)據(jù)執(zhí)行reduceByKey等聚合操作,然后將各個key的前綴去掉。第二階段全局聚合即正常的聚合操作。
5)針對兩個數(shù)據(jù)量都比較大的RDD/hive表進行join的情況,如果其中一個RDD/hive表的少數(shù)key對應的數(shù)據(jù)量過大,另一個比較均勻時,可以先分析數(shù)據(jù),將數(shù)據(jù)量過大的幾個key統(tǒng)計并拆分出來形成一個單獨的RDD,得到的兩個RDD/hive表分別和另一個RDD/hive表做join,其中key對應數(shù)據(jù)量較大的那個要進行key值隨機數(shù)打散處理,另一個無數(shù)據(jù)傾斜的RDD/hive表要1對n膨脹擴容n倍,確保隨機化后key值仍然有效。
6)針對join操作的RDD中有大量的key導致數(shù)據(jù)傾斜,對有數(shù)據(jù)傾斜的整個RDD的key值做隨機打散處理,對另一個正常的RDD進行1對n膨脹擴容,每條數(shù)據(jù)都依次打上0~n的前綴。處理完后再執(zhí)行join操作
五、其他錯誤總結
(1) 報錯信息
java.lang.OutOfMemory, unable to create new native thread
Caused by: java.lang.OutOfMemoryError: unable to create new native thread
at java.lang.Thread.start0(Native Method)
at java.lang.Thread.start(Thread.java:640)解決方案:
上面這段錯誤提示的本質(zhì)是Linux操作系統(tǒng)無法創(chuàng)建更多進程,導致出錯,并不是系統(tǒng)的內(nèi)存不足。因此要解決這個問題需要修改Linux允許創(chuàng)建更多的進程,就需要修改Linux最大進程數(shù)
(2)報錯信息
由于Spark在計算的時候會將中間結果存儲到/tmp目錄,而目前l(fā)inux又都支持tmpfs,其實就是將/tmp目錄掛載到內(nèi)存當中, 那么這里就存在一個問題,中間結果過多導致/tmp目錄寫滿而出現(xiàn)如下錯誤 No Space Left on the device(Shuffle臨時文件過多)
解決方案:
修改配置文件spark-env.sh,把臨時文件引入到一個自定義的目錄中去, 即:
export SPARK_LOCAL_DIRS=/home/utoken/datadir/spark/tmp(3)報錯信息 Worker節(jié)點中的work目錄占用許多磁盤空間, 這些是Driver上傳到worker的文件, 會占用許多磁盤空間 需要定時做手工清理work目錄
(4)spark-shell提交Spark Application如何解決依賴庫 解決方案:
(5)內(nèi)存不足或數(shù)據(jù)傾斜導致Executor Lost,shuffle fetch失敗,Task重試失敗等(spark-submit提交)
TaskSetManager: Lost task 1.0 in stage 6.0 (TID 100, 192.168.10.37): java.lang.OutOfMemoryError: Java heap space
INFO BlockManagerInfo: Added broadcast_8_piece0 in memory on 192.168.10.37:57139 (size: 42.0 KB, free: 24.2 MB)
INFO BlockManagerInfo: Added broadcast_8_piece0 in memory on 192.168.10.38:53816 (size: 42.0 KB, free: 24.2 MB)
INFO TaskSetManager: Starting task 3.0 in stage 6.0 (TID 102, 192.168.10.37, ANY, 2152 bytes)解決方案:增加worker內(nèi)存,或者相同資源下增加partition數(shù)目,這樣每個task要處理的數(shù)據(jù)變少,占用內(nèi)存變少
如果存在shuffle過程,設置shuffle read階段的并行數(shù)。


版權聲明:
編輯?《大數(shù)據(jù)技術與架構》
插畫?《大數(shù)據(jù)技術與架構》
文章鏈接?https://blog.csdn.net/kisimple
文章不錯?點個【在看】吧!??