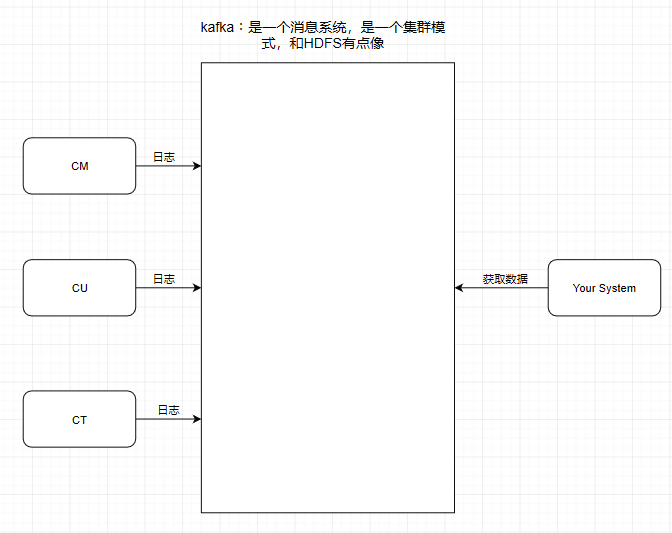
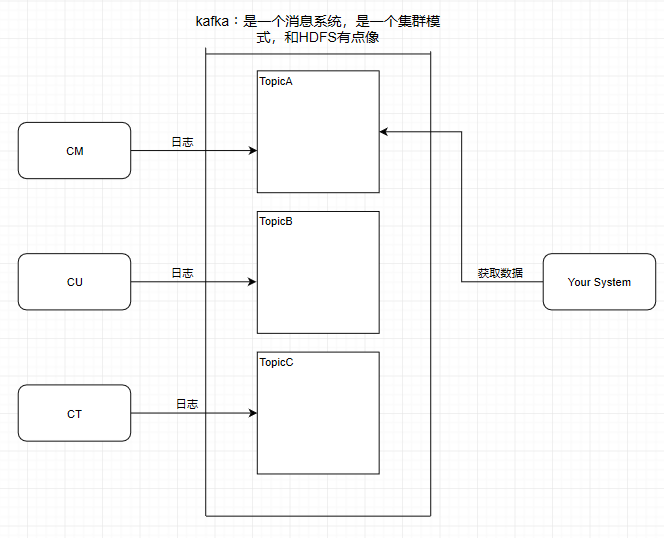
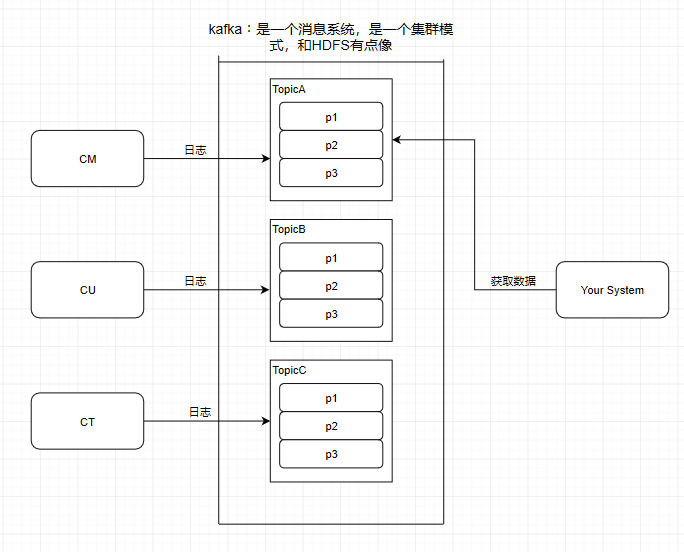
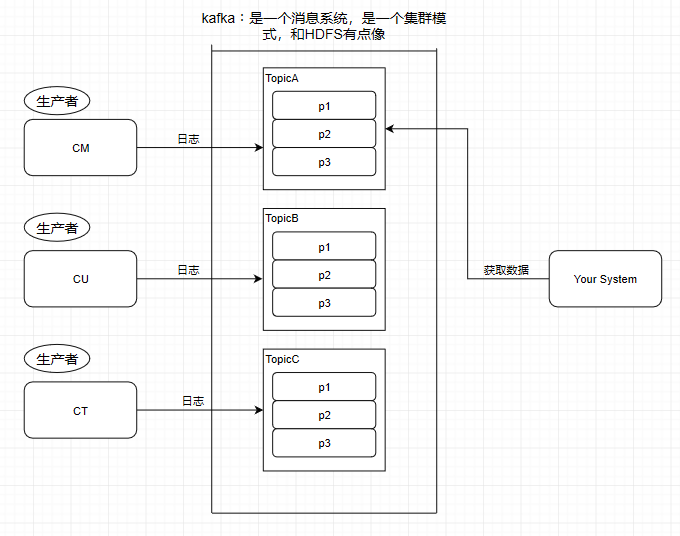
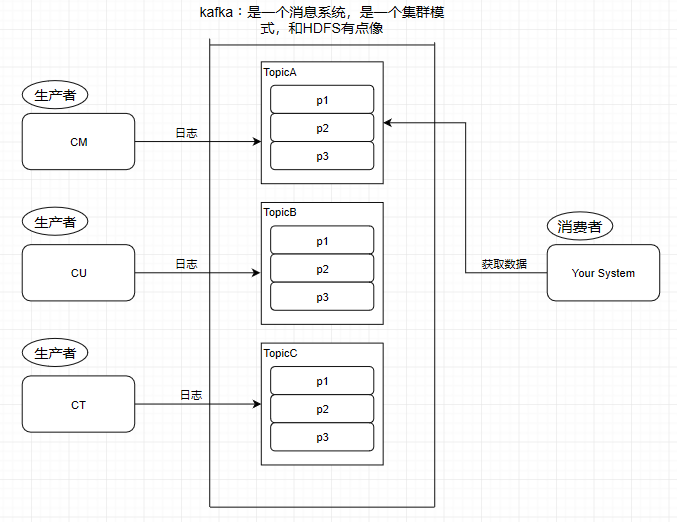
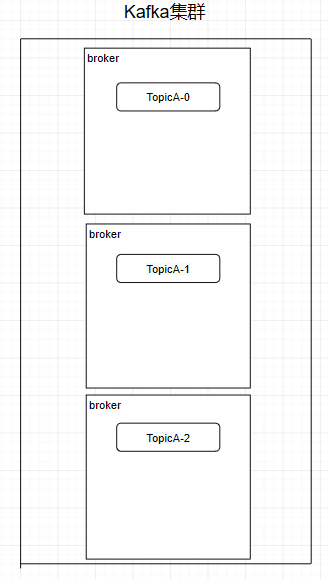
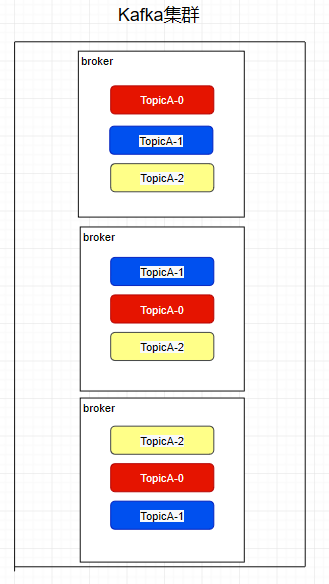
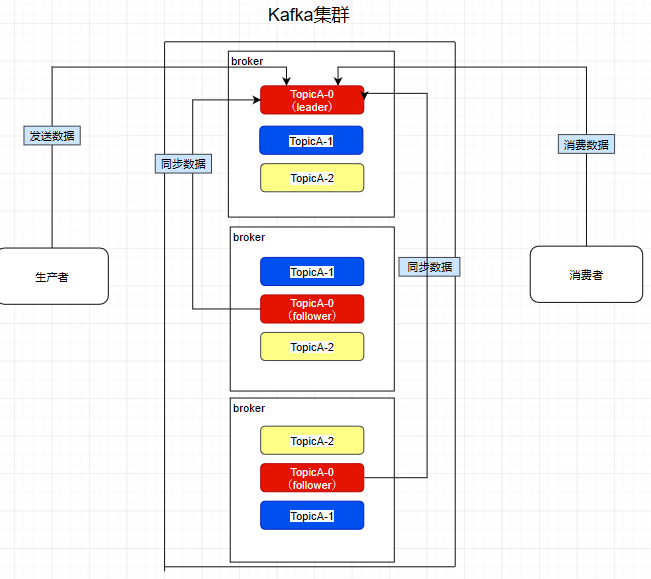
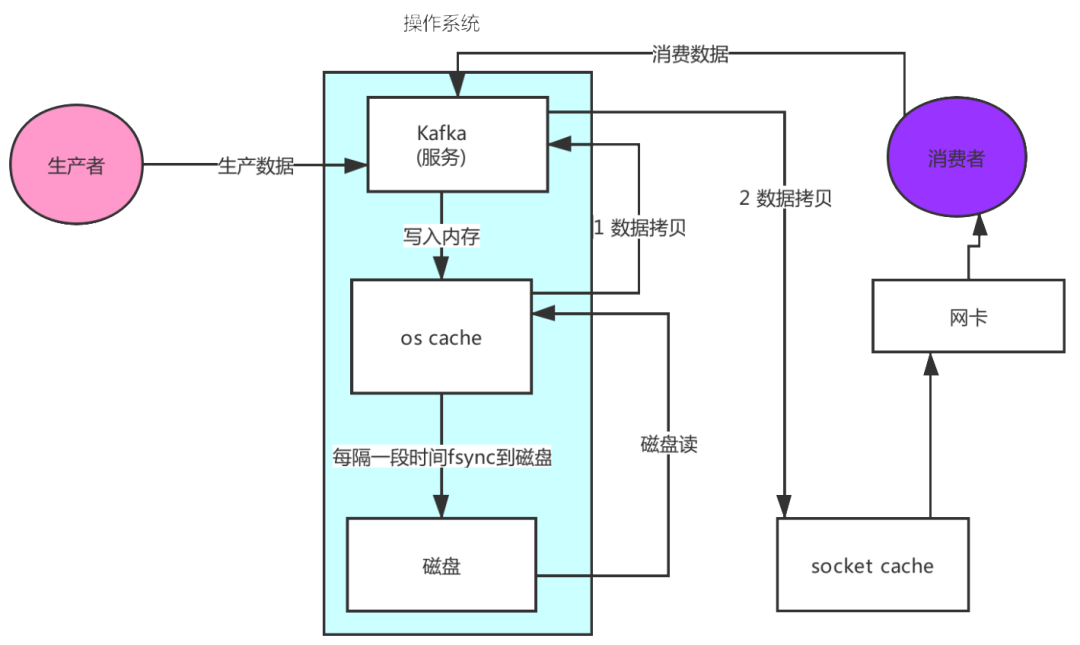
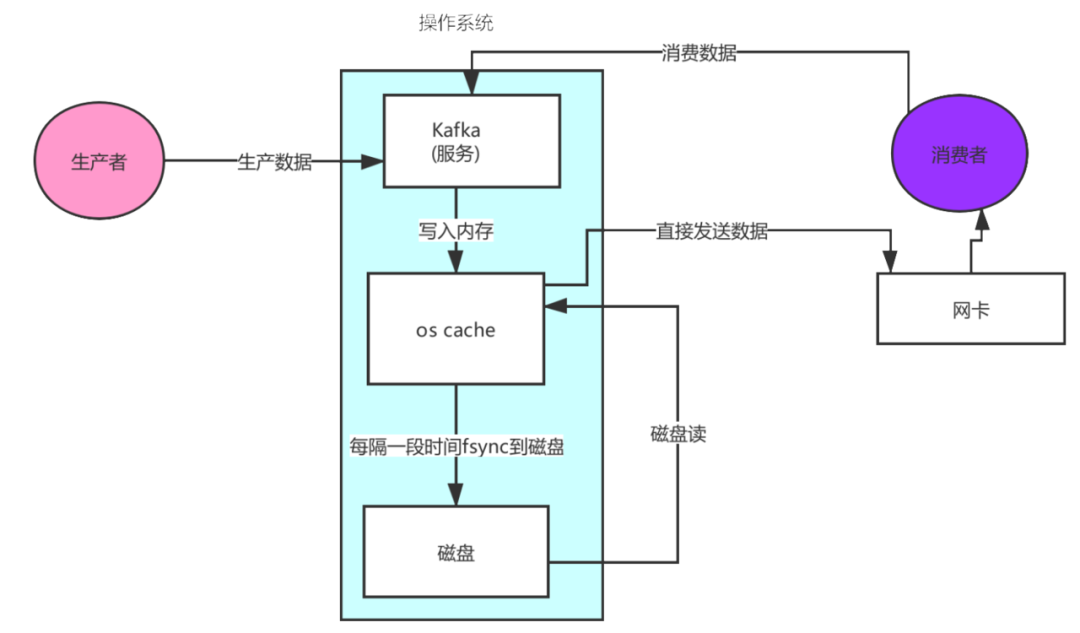
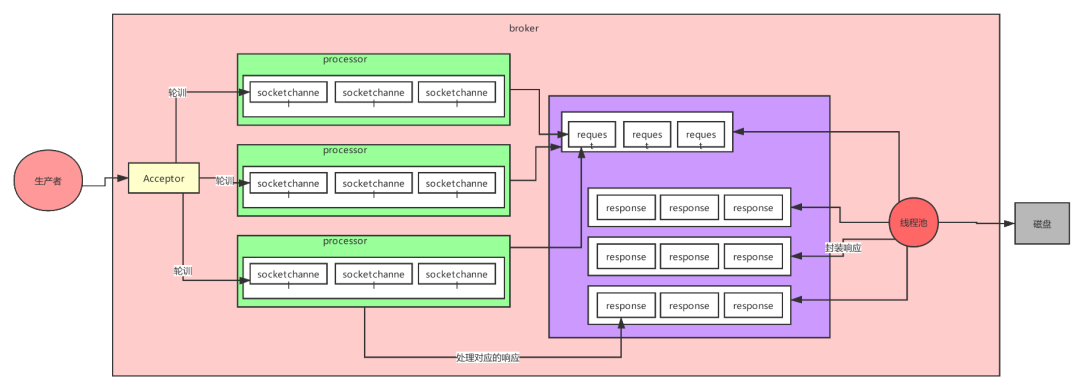
這個9936472之類的數(shù)字,就是代表了這個日志段文件里包含的起始o(jì)ffset,也就說明這個分區(qū)里至少都寫入了接近1000萬條數(shù)據(jù)了。Kafka broker有一個參數(shù),log.segment.bytes,限定了每個日志段文件的大小,最大就是1GB,一個日志段文件滿了,就自動開一個新的日志段文件來寫入,避免單個文件過大,影響文件的讀寫性能,這個過程叫做log rolling,正在被寫入的那個日志段文件,叫做active log segment。如果大家有看前面的兩篇有關(guān)于HDFS的文章時,就會發(fā)現(xiàn)NameNode的edits log也會做出限制,所以這些框架都是會考慮到這些問題。Kafka的網(wǎng)絡(luò)設(shè)計Kafka的網(wǎng)絡(luò)設(shè)計和Kafka的調(diào)優(yōu)有關(guān),這也是為什么它能支持高并發(fā)的原因。首先客戶端發(fā)送請求全部會先發(fā)送給一個Acceptor,broker里面會存在3個線程(默認(rèn)是3個),這3個線程都是叫做processor,Acceptor不會對客戶端的請求做任何的處理,直接封裝成一個個socketChannel發(fā)送給這些processor形成一個隊列,發(fā)送的方式是輪詢,就是先給第一個processor發(fā)送,然后再給第二個,第三個,然后又回到第一個。消費者線程去消費這些socketChannel時,會獲取一個個request請求,這些request請求中就會伴隨著數(shù)據(jù)。線程池里面默認(rèn)有8個線程,這些線程是用來處理request的,解析請求,如果request是寫請求,就寫到磁盤里。讀的話返回結(jié)果。processor會從response中讀取響應(yīng)數(shù)據(jù),然后再返回給客戶端。這就是Kafka的網(wǎng)絡(luò)三層架構(gòu)。所以如果我們需要對Kafka進行增強調(diào)優(yōu),增加processor并增加線程池里面的處理線程,就可以達(dá)到效果。request和response那一塊部分其實就是起到了一個緩存的效果,是考慮到processor們生成請求太快,線程數(shù)不夠不能及時處理的問題。所以這就是一個加強版的reactor網(wǎng)絡(luò)線程模型。

假設(shè)每天集群需要承載10億數(shù)據(jù)。一天24小時,晚上12點到凌晨8點幾乎沒多少數(shù)據(jù)。使用二八法則估計,也就是80%的數(shù)據(jù)(8億)會在16個小時涌入,而且8億的80%的數(shù)據(jù)(6.4億)會在這16個小時的20%時間(3小時)涌入。QPS計算公式:640000000 ÷ (3x60x60) = 60000,也就是說高峰期的時候Kafka集群要扛住每秒6萬的并發(fā)。磁盤空間計算,每天10億數(shù)據(jù),每條50kb,也就是46T的數(shù)據(jù)。保存2個副本(在上一篇中也提到過其實兩個副本會比較好,因為follower需要去leader那里同步數(shù)據(jù),同步數(shù)據(jù)的過程需要耗費網(wǎng)絡(luò),而且需要磁盤空間,但是這個需要根據(jù)實際情況考慮),46 * 2 = 92T,保留最近3天的數(shù)據(jù)。故需要 92 * 3 = 276T。部署Kafka,Hadoop,MySQL……等核心分布式系統(tǒng),一般建議直接采用物理機,拋棄使用一些低配置的虛擬機的想法。高并發(fā)這個東西,不可能是說,你需要支撐6萬QPS,你的集群就剛好把這6萬并發(fā)卡的死死的。假如某一天出一些活動讓數(shù)據(jù)量瘋狂上漲,那整個集群就會垮掉。但是,假如說你只要支撐6w QPS,單臺物理機本身就能扛住4~5萬的并發(fā)。所以這時2臺物理機絕對絕對夠了。但是這里有一個問題,我們通常是建議,公司預(yù)算充足,盡量是讓高峰QPS控制在集群能承載的總QPS的30%左右(也就是集群的處理能力是高峰期的3~4倍這個樣子),所以我們搭建的kafka集群能承載的總QPS為20萬~30萬才是安全的。所以大體上來說,需要5~7臺物理機來部署,基本上就很安全了,每臺物理機要求吞吐量在每秒4~5萬條數(shù)據(jù)就可以了,物理機的配置和性能也不需要特別高。需要5臺物理機的情況,需要存儲276T的數(shù)據(jù),平均下來差不多一臺56T的數(shù)據(jù)。這個具體看磁盤數(shù)和盤的大小。現(xiàn)在我們需要考慮一個問題:是需要SSD固態(tài)硬盤,還是普通機械硬盤?SSD就是固態(tài)硬盤,比機械硬盤要快,那么到底是快在哪里呢?其實SSD的快主要是快在磁盤隨機讀寫,就要對磁盤上的隨機位置來讀寫的時候,SSD比機械硬盤要快。比如說MySQL這種就應(yīng)該使用SSD了(MySQL需要隨機讀寫)。比如說我們在規(guī)劃和部署線上系統(tǒng)的MySQL集群的時候,一般來說必須用SSD,性能可以提高很多,這樣MySQL可以承載的并發(fā)請求量也會高很多,而且SQL語句執(zhí)行的性能也會提高很多。因為寫磁盤的時候Kafka是順序?qū)懙摹C械硬盤順序?qū)懙男阅軝C會跟內(nèi)存讀寫的性能是差不多的,所以對于Kafka集群來說其實使用機械硬盤就可以了。如果是需要自己創(chuàng)業(yè)或者是在公司成本不足的情況下,經(jīng)費是能夠縮減就盡量縮減的。JVM非常怕出現(xiàn)full gc的情況。Kafka自身的JVM是用不了過多堆內(nèi)存的,因為Kafka設(shè)計就是規(guī)避掉用JVM對象來保存數(shù)據(jù),避免頻繁full gc導(dǎo)致的問題,所以一般Kafka自身的JVM堆內(nèi)存,分配個10G左右就夠了,剩下的內(nèi)存全部留給OS cache。那服務(wù)器需要多少內(nèi)存呢。我們估算一下,大概有100個topic,所以要保證有100個topic的leader partition的數(shù)據(jù)在操作系統(tǒng)的內(nèi)存里。100個topic,一個topic有5個partition。那么總共會有500個partition。每個partition的大小是1G(在上一篇中的日志分段存儲中規(guī)定了.log文件不能超過1個G),我們有2個副本,也就是說要把100個topic的leader partition數(shù)據(jù)都駐留在內(nèi)存里需要1000G的內(nèi)存。我們現(xiàn)在有5臺服務(wù)器,所以平均下來每天服務(wù)器需要200G的內(nèi)存,但是其實partition的數(shù)據(jù)我們沒必要所有的都要駐留在內(nèi)存里面,只需要25%的數(shù)據(jù)在內(nèi)存就行,200G * 0.25 = 50G就可以了(因為在集群中的生產(chǎn)者和消費者幾乎也算是實時的,基本不會出現(xiàn)消息積壓太多的情況)。所以一共需要60G(附帶上剛剛的10G Kafka服務(wù))的內(nèi)存,故我們可以挑選64G內(nèi)存的服務(wù)器也行,大不了partition的數(shù)據(jù)再少一點在內(nèi)存,當(dāng)然如果能夠提供128G內(nèi)存那就更好。CPU規(guī)劃,主要是看你的這個進程里會有多少個線程,線程主要是依托多核CPU來執(zhí)行的,如果你的線程特別多,但是CPU核很少,就會導(dǎo)致你的CPU負(fù)載很高,會導(dǎo)致整體工作線程執(zhí)行的效率不太高,上一篇的Kafka的網(wǎng)絡(luò)設(shè)計中講過Kafka的Broker的模型。acceptor線程負(fù)責(zé)去接入客戶端的連接請求,但是他接入了之后其實就會把連接分配給多個processor,默認(rèn)是3個,但是一般生產(chǎn)環(huán)境建議大家還是多加幾個,整體可以提升kafka的吞吐量比如說你可以增加到6個,或者是9個。另外就是負(fù)責(zé)處理請求的線程,是一個線程池,默認(rèn)是8個線程,在生產(chǎn)集群里,建議大家可以把這塊的線程數(shù)量稍微多加個2倍~3倍,其實都正常,比如說搞個16個工作線程,24個工作線程。后臺會有很多的其他的一些線程,比如說定期清理7天前數(shù)據(jù)的線程,Controller負(fù)責(zé)感知和管控整個集群的線程,副本同步拉取數(shù)據(jù)的線程,這樣算下來每個broker起碼會有上百個線程。根據(jù)經(jīng)驗4個CPU core,一般來說幾十個線程,在高峰期CPU幾乎都快打滿了。8個CPU core,也就能夠比較寬裕的支撐幾十個線程繁忙的工作。所以Kafka的服務(wù)器一般是建議16核,基本上可以hold住一兩百線程的工作。當(dāng)然如果可以給到32 CPU core那就最好不過了。現(xiàn)在的網(wǎng)基本就是千兆網(wǎng)卡(1GB / s),還有萬兆網(wǎng)卡(10GB / s)。kafka集群之間,broker和broker之間是會做數(shù)據(jù)同步的,因為leader要同步數(shù)據(jù)到follower上去,他們是在不同的broker機器上的,broker機器之間會進行頻繁的數(shù)據(jù)同步,傳輸大量的數(shù)據(jù)。那每秒兩臺broker機器之間大概會傳輸多大的數(shù)據(jù)量?高峰期每秒大概會涌入6萬條數(shù)據(jù),約每天處理10000個請求,每個請求50kb,故每秒約進來488M數(shù)據(jù),我們還有副本同步數(shù)據(jù),故高峰期的時候需要488M * 2 = 976M/s的網(wǎng)絡(luò)帶寬,所以在高峰期的時候,使用千兆帶寬,網(wǎng)絡(luò)還是非常有壓力的。10億數(shù)據(jù),6w/s的吞吐量,276T的數(shù)據(jù),5臺物理機
硬盤:11(SAS)?* 7T,7200轉(zhuǎn)
內(nèi)存:64GB/128GB,JVM分配10G,剩余的給os cache
CPU:16核/32核
網(wǎng)絡(luò):千兆網(wǎng)卡,萬兆更好
進到Kafka的config文件夾下,會發(fā)現(xiàn)有很多很多的配置文件,可是都不需要你來修改,你僅僅需要點開一個叫作server.properties的文件就夠了。【broker.id】
每個broker都必須自己設(shè)置的一個唯一id,可以在0~255之間
【log.dirs】
這個極為重要,Kafka的所有數(shù)據(jù)就是寫入這個目錄下的磁盤文件中的,如果說機器上有多塊物理硬盤,那么可以把多個目錄掛載到不同的物理硬盤上,然后這里可以設(shè)置多個目錄,這樣Kafka可以數(shù)據(jù)分散到多塊物理硬盤,多個硬盤的磁頭可以并行寫,這樣可以提升吞吐量。ps:多個目錄用英文逗號分隔
【zookeeper.connect】
連接Kafka底層的ZooKeeper集群的
【Listeners】
broker監(jiān)聽客戶端發(fā)起請求的端口號,默認(rèn)是9092
【num.network.threads】默認(rèn)值為3
【num.io.threads】默認(rèn)值為8
細(xì)心的朋友們應(yīng)該已經(jīng)發(fā)現(xiàn)了,這就是上一篇我們在網(wǎng)絡(luò)架構(gòu)上提到的processor和處理線程池的線程數(shù)目。
所以說掌握Kafka網(wǎng)絡(luò)架構(gòu)顯得尤為重要。
現(xiàn)在你看到這兩個參數(shù),就知道這就是Kafka集群性能的關(guān)鍵參數(shù)了
【unclean.leader.election.enable】
默認(rèn)是false,意思就是只能選舉ISR列表里的follower成為新的leader,1.0版本后才設(shè)為false,之前都是true,允許非ISR列表的follower選舉為新的leader
【delete.topic.enable】
默認(rèn)true,允許刪除topic
【log.retention.hours】
可以設(shè)置一下,要保留數(shù)據(jù)多少個小時,這個就是底層的磁盤文件,默認(rèn)保留7天的數(shù)據(jù),根據(jù)自己的需求來就行了
【min.insync.replicas】
acks=-1(一條數(shù)據(jù)必須寫入ISR里所有副本才算成功),你寫一條數(shù)據(jù)只要寫入leader就算成功了,不需要等待同步到follower才算寫成功。但是此時如果一個follower宕機了,你寫一條數(shù)據(jù)到leader之后,leader也宕機,會導(dǎo)致數(shù)據(jù)的丟失。
因為實際的集群搭建說真的沒有太大難度,所以搭建的過程就不詳細(xì)展開了,網(wǎng)上應(yīng)該很多相關(guān)資料。
在操作Kafka集群的時候,不同的Kafka版本命令的寫法是不一樣的,所以其實如果需要了解一下,推薦直接到官網(wǎng)去查看。上一篇時也有提到說Kafka在0.8版本以前存在比較大的問題,1.x的算是目前生產(chǎn)環(huán)境中使用較多的版本。在quickStart就能看到相關(guān)的命令,比如:
bin/kafka-topics.sh?--create?--zookeeper?localhost:2181?--replication-factor?1?--partitions?1?--topic?test
將該命令修改一下
zookeeper?localhost:2181?--replication-factor?2?--partitions?2?--topic?tellYourDream
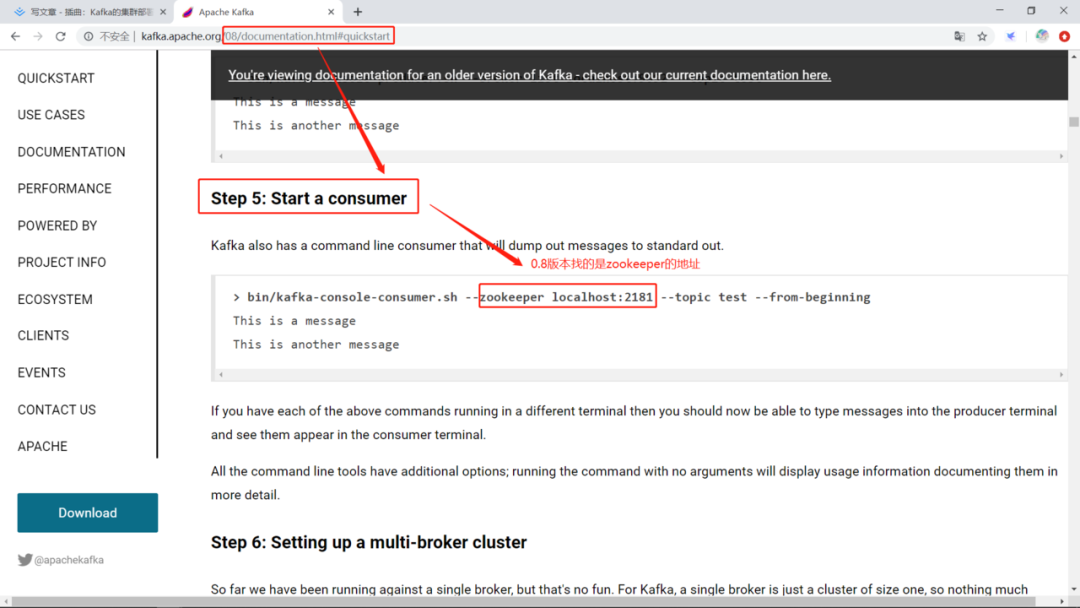
這時候就是zookeeper的地址為localhost:2181
兩個分區(qū),兩個副本,一共4個副本,topic名稱為“tellYourDream”了
還得注意,一般來說設(shè)置分區(qū)數(shù)建議是節(jié)點的倍數(shù),這是為了讓服務(wù)節(jié)點分配均衡的舉措。bin/kafka-topics.sh?--list?--zookeeper?localhost:2181
bin/kafka-console-producer.sh?--broker-list?localhost:9092?--topic?test
This?is?a?message
This?is?another?message
bin/kafka-console-consumer.sh?--bootstrap-server?localhost:9092?--topic?test?--from-beginning
This?is?a?message
This?is?another?message
這里有個細(xì)節(jié)需要提及一下,就是我們0.8版本的Kafka找的是ZooKeeper,ZooKeeper上確實是也存在著元數(shù)據(jù)信息。不過這存在著一些問題,ZooKeeper本身有一個過半服務(wù)的特性,這是一個限制,過半服務(wù)是指任何的請求都需要半數(shù)節(jié)點同意才能執(zhí)行。每次有寫請求,它都要投票,因為它要保持?jǐn)?shù)據(jù)的強一致性,做到節(jié)點狀態(tài)同步,所以高并發(fā)寫的性能不好。不適合做高并發(fā)的事。ZooKeeper是Kafka存儲元數(shù)據(jù)和交換集群信息的工具,主要是處理分布式一致性的問題。下面的命令就是生產(chǎn)50W條數(shù)據(jù),每條數(shù)據(jù)200字節(jié),這條命令一運行就會產(chǎn)生一條報告,可以很直觀的看到集群性能,看不懂的情況搜索引擎也可以很好地幫助你解決問題。測試生產(chǎn)數(shù)據(jù)
bin/kafka-producer-perf-test.sh?--topic?test-topic?--num-records?500000?--record-size?200?--throughput?-1?--producer-props?bootstrap.servers=hadoop03:9092,hadoop04:9092,hadoop05:9092?acks=-1
每次消費2000條,集群沒跑掛那就穩(wěn)妥了。測試消費數(shù)據(jù)
bin/kafka-consumer-perf-test.sh?--broker-list?hadoop03:9092,hadoop04:9092,hadoop53:9092?--fetch-size?2000?--messages?500000?--topic?test-topic
KafkaManager使用scala寫的項目,非常不錯。使用方法可以通過搜索引擎查找。
安裝步驟可以參考:https://www.cnblogs.com/dadonggg/p/8205302.html安裝好了之后可以使用jps命令查看一下,會多出一個名字叫做ProdServerStart的服務(wù)。管理多個Kafka集群
便捷的檢查Kafka集群狀態(tài)(topics,brokers,備份分布情況,分區(qū)分布情況)
選擇你要運行的副本
基于當(dāng)前分區(qū)狀況進行
可以選擇topic配置并創(chuàng)建topic(0.8.1.1和0.8.2的配置不同)
刪除topic(只支持0.8.2以上的版本并且要在broker配置中設(shè)置delete.topic.enable=true)
Topic list會指明哪些topic被刪除(在0.8.2以上版本適用)
為已存在的topic增加分區(qū)
為已存在的topic更新配置
在多個topic上批量重分區(qū)
在多個topic上批量重分區(qū)(可選partition broker位置)
KafkaOffsetMonitor就是一個jar包而已,是一個針對于消費者的工具。它可以用于監(jiān)控消費延遲的問題,不過對于重復(fù)消費和消息丟失等就無法解決,因為之后如果需要講解SparkStreaming,flink這些用于消費者的實踐的話,會使用到這個工具,所以現(xiàn)在先不展開,了解一下即可。java?-cp?KafkaOffsetMonitor-assembly-0.3.0-SNAPSHOT.jar?\
?com.quantifind.kafka.offsetapp.OffsetGetterWeb?\
?--offsetStorage?kafka?\
?--zk?xx:2181,xx:2181,xx:2181/kafka_cluster?\
?--port?8088?\
?--refresh?60.seconds?\
?--retain?2.days
還有一些跨機房同步數(shù)據(jù)的像MirrorMaker這些,酌情使用。
原文鏈接:https://juejin.cn/post/6844904001989771278