
Apache Kafka 快速入門指南
?「寫在前面」:我是「云祁」,一枚熱愛技術(shù)、會寫詩的大數(shù)據(jù)開發(fā)猿。昵稱來源于王安石詩中一句 [ 云之祁祁,或雨于淵 ],甚是喜歡。寫博客一方面是對自己學習的一點點總結(jié)及記錄,另一方面則是希望能夠幫助更多對大數(shù)據(jù)感興趣的朋友。如果你也對 數(shù)據(jù)中臺以及 Hadoop / Flink / Spark 等大數(shù)據(jù)技術(shù)感興趣,可以關(guān)注我的博客, 每天都要進步一點點,生命不是要超越別人,而是要超越自己!(? ?_?)?
?
一、Kafka 是什么?
有人說世界上有三個偉大的發(fā)明:火,輪子,以及 Kafka。
發(fā)展到現(xiàn)在,Apache Kafka 無疑是很成功的,Confluent 公司曾表示世界五百強中有三分之一的企業(yè)在使用 Kafka。在流式計算中,Kafka 一般用來緩存數(shù)據(jù),例如 Flink 通過消費 Kafka 的數(shù)據(jù)進行計算。
關(guān)于Kafka,我們最先需要了解的是以下四點:

Apache Kafka 是一個開源 「消息」 系統(tǒng),由 Scala 寫成。是由 Apache 軟件基金會開發(fā)的 一個開源消息系統(tǒng)項目。
Kafka 最初是由 LinkedIn 公司開發(fā),用作 LinkedIn 的活動流(Activity Stream)和運營數(shù)據(jù)處理管道(Pipeline)的基礎(chǔ),現(xiàn)在它已被多家不同類型的公司作為多種類型的數(shù)據(jù)管道和消息系統(tǒng)使用。
「Kafka 是一個分布式消息隊列」。Kafka 對消息保存時根據(jù) Topic 進行歸類,發(fā)送消息 者稱為 Producer,消息接受者稱為 Consumer,此外 kafka 集群有多個 kafka 實例組成,每個 實例(server)稱為 broker。
無論是 kafka 集群,還是 consumer 都依賴于 「Zookeeper」 集群保存一些 meta 信息, 來保證系統(tǒng)可用性。
二、為什么要有 Kafka?
「kafka」 之所以受到越來越多的青睞,與它所扮演的三大角色是分不開的的:
「消息系統(tǒng)」:kafka與傳統(tǒng)的消息中間件都具備系統(tǒng)解耦、冗余存儲、流量削峰、緩沖、異步通信、擴展性、可恢復性等功能。與此同時,kafka還提供了大多數(shù)消息系統(tǒng)難以實現(xiàn)的消息順序性保障及回溯性消費的功能。 「存儲系統(tǒng)」:kafka把消息持久化到磁盤,相比于其他基于內(nèi)存存儲的系統(tǒng)而言,有效的降低了消息丟失的風險。這得益于其消息持久化和多副本機制。也可以將kafka作為長期的存儲系統(tǒng)來使用,只需要把對應(yīng)的數(shù)據(jù)保留策略設(shè)置為“永久”或啟用主題日志壓縮功能。 「流式處理平臺」:kafka為流行的流式處理框架提供了可靠的數(shù)據(jù)來源,還提供了一個完整的流式處理框架,比如窗口、連接、變換和聚合等各類操作。
| Kafka | 特性 |
|---|---|
| 分布式 | 具備經(jīng)濟、快速、可靠、易擴充、數(shù)據(jù)共享、設(shè)備共享、通訊方便、靈活等,分布式所具備的特性 |
| 高吞吐量 | 同時為數(shù)據(jù)生產(chǎn)者和消費者提高吞吐量 |
| 高可靠性 | 支持多個消費者,當某個消費者失敗的時候,能夠自動負載均衡 |
| 離線 | 能將消息持久化,進行批量處理 |
| 解耦 | 作為各個系統(tǒng)連接的橋梁,避免系統(tǒng)之間的耦合 |
三、Kafka 基本概念
在深入理解 Kafka 之前,可以先了解下 Kafka 的基本概念。
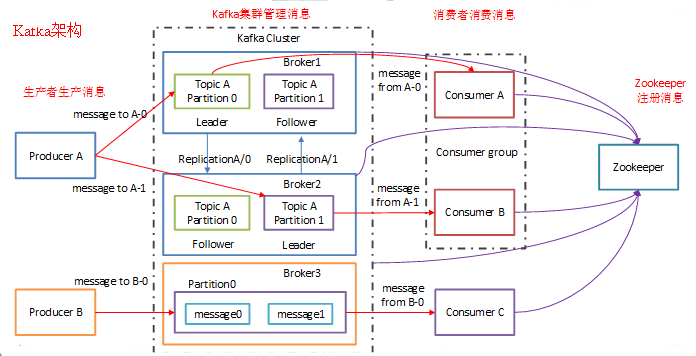
一個典型的 Kafka 包含若干Producer、若干 Broker、若干 Consumer 以及一個 Zookeeper 集群。Zookeeper 是 Kafka 用來負責集群元數(shù)據(jù)管理、控制器選舉等操作的。Producer 是負責將消息發(fā)送到 Broker 的,Broker 負責將消息持久化到磁盤,而 Consumer 是負責從Broker 訂閱并消費消息。Kafka體系結(jié)構(gòu)如下所示:
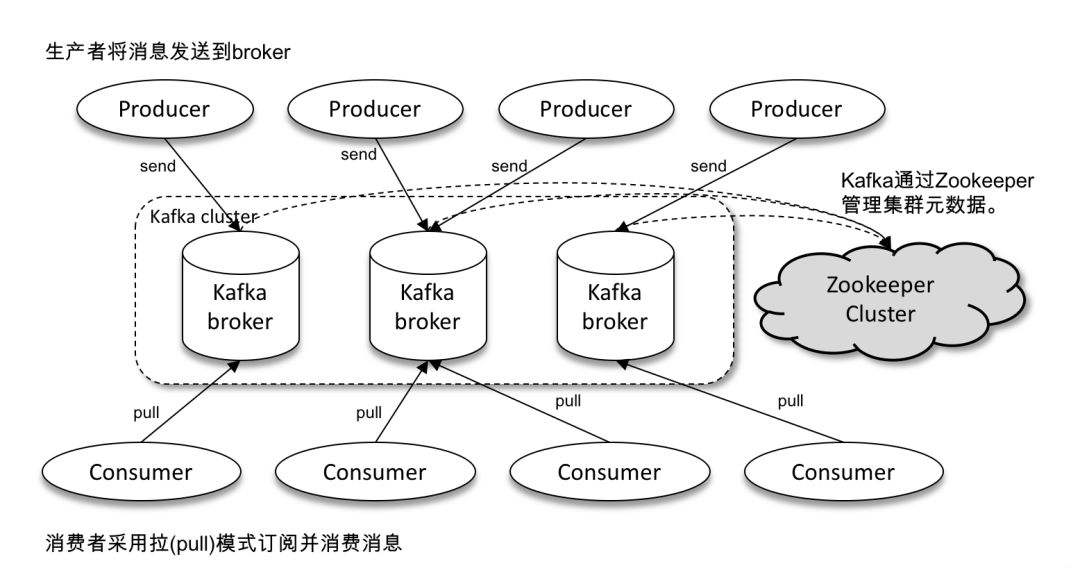
概念一:生產(chǎn)者(Producer)與消費者(Consumer)
對于 Kafka 來說客戶端有兩種基本類型:「生產(chǎn)者」(Producer)和 「消費者」(Consumer)。除此之外,還有用來做數(shù)據(jù)集成的 Kafka Connect API 和流式處理的 「Kafka Streams」 等高階客戶端,但這些高階客戶端底層仍然是生產(chǎn)者和消費者API,只不過是在上層做了封裝。
「Producer」 :消息生產(chǎn)者,就是向 Kafka broker 發(fā)消息的客戶端; 「Consumer」 :消息消費者,向 Kafka broker 取消息的客戶端;
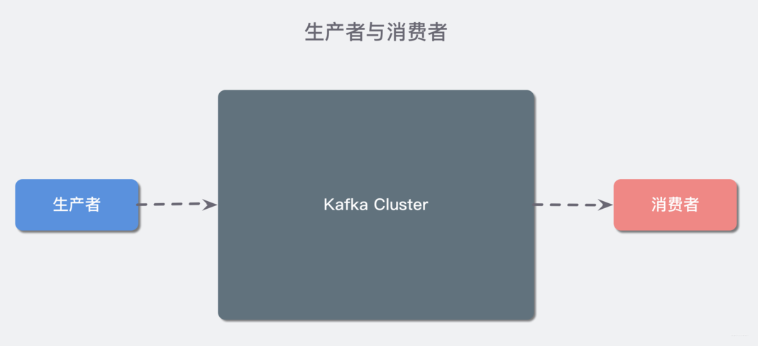
概念二:Broker 和集群(Cluster)
一個 Kafka 服務(wù)器也稱為 「Broker」,它接受生產(chǎn)者發(fā)送的消息并存入磁盤;Broker 同時服務(wù)消費者拉取分區(qū)消息的請求,返回目前已經(jīng)提交的消息。使用特定的機器硬件,一個 Broker 每秒可以處理成千上萬的分區(qū)和百萬量級的消息。
若干個 Broker 組成一個 「集群」(「Cluster」),其中集群內(nèi)某個 Broker 會成為集群控制器(Cluster Controller),它負責管理集群,包括分配分區(qū)到 Broker、監(jiān)控 Broker 故障等。在集群內(nèi),一個分區(qū)由一個 Broker 負責,這個 Broker 也稱為這個分區(qū)的 Leader;當然一個分區(qū)可以被復制到多個 Broker 上來實現(xiàn)冗余,這樣當存在 Broker 故障時可以將其分區(qū)重新分配到其他 Broker 來負責。下圖是一個樣例:
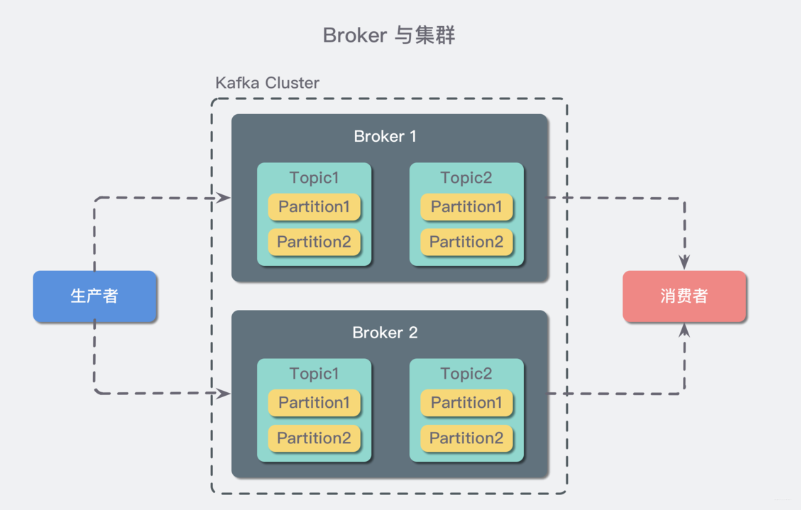
概念三:主題(Topic)與分區(qū)(Partition)
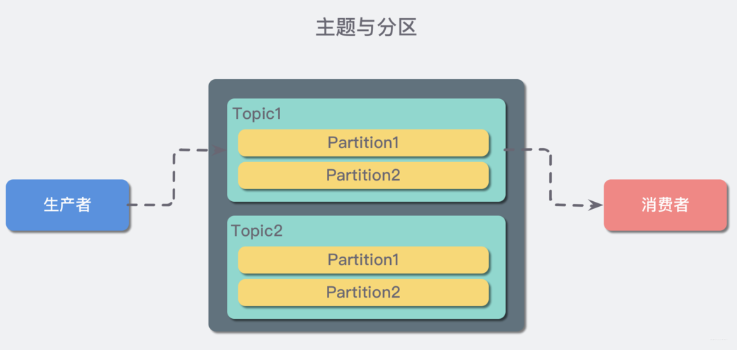
在 Kafka 中,消息以 「主題」(「Topic」)來分類,每一個主題都對應(yīng)一個「「消息隊列」」,這有點兒類似于數(shù)據(jù)庫中的表。但是如果我們把所有同類的消息都塞入到一個“中心”隊列中,勢必缺少可伸縮性,無論是生產(chǎn)者/消費者數(shù)目的增加,還是消息數(shù)量的增加,都可能耗盡系統(tǒng)的性能或存儲。
我們使用一個生活中的例子來說明:現(xiàn)在 A 城市生產(chǎn)的某商品需要運輸?shù)?B 城市,走的是公路,那么單通道的高速公路不論是在「A 城市商品增多」還是「現(xiàn)在 C 城市也要往 B 城市運輸東西」這樣的情況下都會出現(xiàn)「吞吐量不足」的問題。所以我們現(xiàn)在引入 「分區(qū)」(「Partition」)的概念,類似“允許多修幾條道”的方式對我們的主題完成了水平擴展。
四、Kafka 工作流程分析
4.1 Kafka 生產(chǎn)過程分析
4.1.1 寫入方式
producer 采用推(push)模式將消息發(fā)布到 broker,每條消息都被追加(append)到分區(qū)(patition)中,屬于順序?qū)懘疟P(順序?qū)懘疟P效率比隨機寫內(nèi)存要高,保障 kafka 吞吐率)
4.1.2 分區(qū)(Partition)
消息發(fā)送時都被發(fā)送到一個 topic,其本質(zhì)就是一個目錄,而 topic 是由一些 Partition Logs(分區(qū)日志)組成,其組織結(jié)構(gòu)如下圖所示:
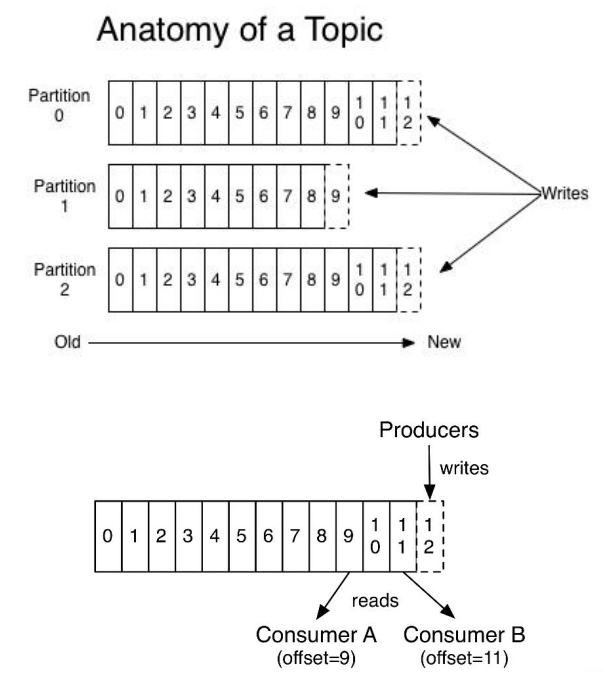 我們可以看到,每個 Partition 中的消息都是 「有序」 的,生產(chǎn)的消息被不斷追加到 Partition log 上,其中的每一個消息都被賦予了一個唯一的 「offset」 值。
我們可以看到,每個 Partition 中的消息都是 「有序」 的,生產(chǎn)的消息被不斷追加到 Partition log 上,其中的每一個消息都被賦予了一個唯一的 「offset」 值。
「1)分區(qū)的原因」
方便在集群中擴展,每個 Partition 可以通過調(diào)整以適應(yīng)它所在的機器,而一個 topic 又可以有多個 Partition 組成,因此整個集群就可以適應(yīng)任意大小的數(shù)據(jù)了; 可以提高并發(fā),因為可以以 Partition 為單位讀寫了。
「2)分區(qū)的原則」
指定了 patition,則直接使用; 未指定 patition 但指定 key,通過對 key 的 value 進行 hash 出一個 patition; patition 和 key 都未指定,使用輪詢選出一個 patition。
DefaultPartitioner?類?
public?int?partition(String?topic,?Object?key,?byte[]?keyBytes,?Object?value,?byte[]?valueBytes,?Cluster?cluster)?{?
?List?partitions?=?cluster.partitionsForTopic(topic);?
?int?numPartitions?=?partitions.size();?
?if?(keyBytes?==?null)?{
???int?nextValue?=?nextValue(topic);?
???List?availablePartitions?=?cluster.availablePartitionsForTopic(topic);
???if?(availablePartitions.size()?>?0)?{?
???int?part?=?Utils.toPositive(nextValue)?%?availablePartitions.size();?
???return?availablePartitions.get(part).partition();
????}?else?{?
????//?no?partitions?are?available,?give?a?non-available?partition?
????return?Utils.toPositive(nextValue)?%?numPartitions;?
????}?
????}?else?{?
????//?hash?the?keyBytes?to?choose?a?partition?
????return?Utils.toPositive(Utils.murmur2(keyBytes))?%?numPartitions;?
????}
?}
4.1.3 副本(Replication)
同 一 個 partition 可 能 會 有 多 個 replication ( 對 應(yīng) server.properties 配 置 中 的 default.replication.factor=N)。沒有 replication 的情況下,一旦 broker 宕機,其上所有 patition 的數(shù)據(jù)都不可被消費,同時 producer 也不能再將數(shù)據(jù)存于其上的 patition。引入 replication 之后,同一個 partition 可能會有多個 replication,而這時需要在這些 replication 之間選出一 個 leader,producer 和 consumer 只與這個 leader 交互,其它 replication 作為 follower 從 leader 中復制數(shù)據(jù)。
4.1.4 寫入流程
producer 寫入消息流程如下:
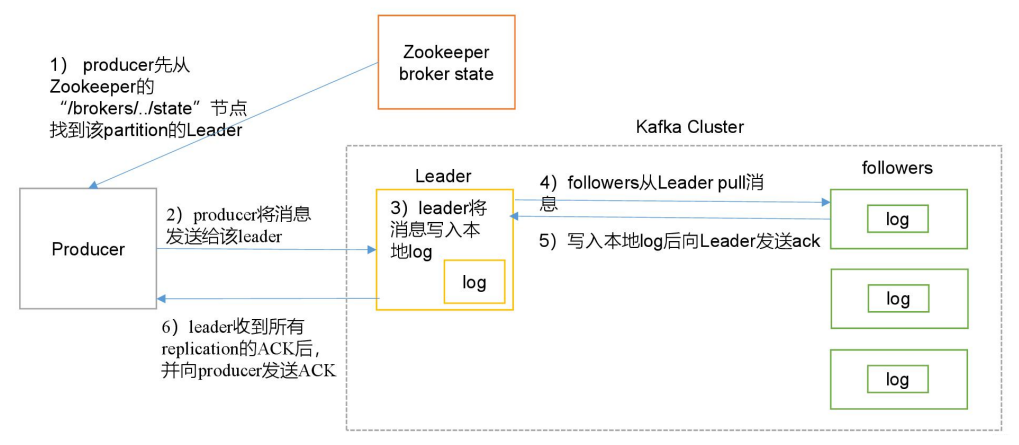 1)producer 先從 zookeeper 的 "/brokers/.../state"節(jié)點找到該 partition 的 leader ;
1)producer 先從 zookeeper 的 "/brokers/.../state"節(jié)點找到該 partition 的 leader ;
2)producer 將消息發(fā)送給該 leader ;
3)leader 將消息寫入本地 log ;
4)followers 從 leader pull 消息,寫入本地 log 后向 leader 發(fā)送 ACK ;
5)leader 收到所有 ISR 中的 replication 的 ACK 后,增加 HW(high watermark,最后 commit 的 offset)并向 producer 發(fā)送 ACK ;
4.2 Broker 保存消息
4.2.1 存儲方式
物理上把 topic 分成一個或多個 patition(對應(yīng) server.properties 中的 num.partitions=3 配 置),每個 patition 物理上對應(yīng)一個文件夾(該文件夾存儲該 patition 的所有消息和索引文 件),如下:
[root@hadoop102?logs]$?ll?
drwxrwxr-x.?2?demo?demo?4096?8?月?6?14:37?first-0?
drwxrwxr-x.?2?demo?demo?4096?8?月?6?14:35?first-1?
drwxrwxr-x.?2?demo?demo?4096?8?月?6?14:37?first-2?
[root@hadoop102?logs]$?cd?first-0?
[root@hadoop102?first-0]$?ll?
-rw-rw-r--.?1?demo?demo?10485760?8?月?6?14:33?00000000000000000000.index?
-rw-rw-r--.?1?demo?demo?219?8?月?6?15:07?00000000000000000000.log?
-rw-rw-r--.?1?demo?demo?10485756?8?月?6?14:33?00000000000000000000.timeindex?
-rw-rw-r--.?1?demo?demo?8?8?月?6?14:37?leader-epoch-checkpoint
4.2.2 ?存儲策略
無論消息是否被消費,kafka 都會保留所有消息。有兩種策略可以刪除舊數(shù)據(jù):
基于時間:log.retention.hours=168 基于大小:log.retention.bytes=1073741824
需要注意的是,因為 Kafka 讀取特定消息的時間復雜度為 O(1),即與文件大小無關(guān), 所以這里刪除過期文件與提高 Kafka 性能無關(guān)。
4.2.3 Zookeeper 存儲結(jié)構(gòu)
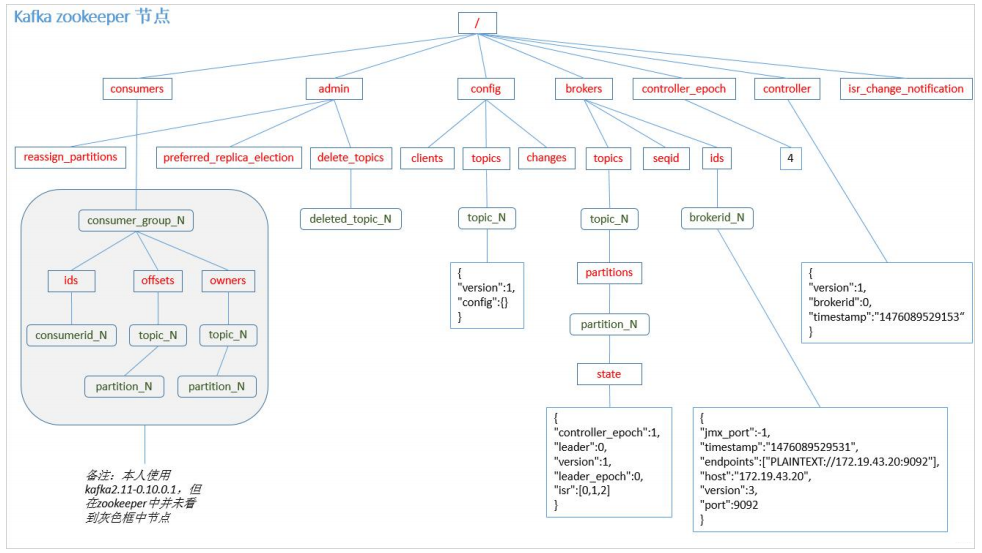 注意:producer 不在 zk 中注冊,消費者在 zk 中注冊。
注意:producer 不在 zk 中注冊,消費者在 zk 中注冊。
4.3 Kafka 消費過程分析
kafka 提供了兩套 consumer API:高級 Consumer API 和低級 Consumer API。
4.3.1 高級 API
「1)高級 API 優(yōu)點」
高級 API 寫起來簡單
不需要自行去管理 offset,系統(tǒng)通過 zookeeper 自行管理。
不需要管理分區(qū),副本等情況,系統(tǒng)自動管理。
消費者斷線會自動根據(jù)上一次記錄在 zookeeper 中的 offset 去接著獲取數(shù)據(jù)(默認設(shè)置 1 分鐘更新一下 zookeeper 中存的 offset)
可以使用 group 來區(qū)分對同一個 topic 的不同程序訪問分離開來(不同的 group 記錄不同的 offset,這樣不同程序讀取同一個 topic 才不會因為 offset 互相影響)
「2)高級 API 缺點」
不能自行控制 offset(對于某些特殊需求來說) 不能細化控制如分區(qū)、副本、zk 等
4.3.2 低級 API
「1)低級 API 優(yōu)點」
能夠讓開發(fā)者自己控制 offset,想從哪里讀取就從哪里讀取。 自行控制連接分區(qū),對分區(qū)自定義進行負載均衡 對 zookeeper 的依賴性降低(如:offset 不一定非要靠 zk 存儲,自行存儲 offset 即可, 比如存在文件或者內(nèi)存中)
「2)低級 API 缺點」
太過復雜,需要自行控制 offset,連接哪個分區(qū),找到分區(qū) leader 等。
4.3.3 消費者組
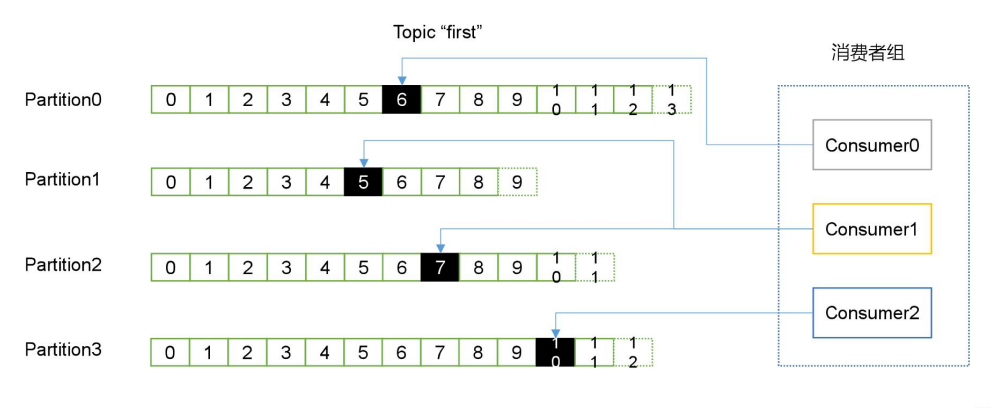 消費者是以 consumer group 消費者組的方式工作,由一個或者多個消費者組成一個組, 共同消費一個 topic。每個分區(qū)在同一時間只能由 group 中的一個消費者讀取,但是多個 group 可以同時消費這個 partition。在圖中,有一個由三個消費者組成的 group,有一個消費者讀取主題中的兩個分區(qū),另外兩個分別讀取一個分區(qū)。某個消費者讀取某個分區(qū),也可以叫做某個消費者是某個分區(qū)的擁有者。
消費者是以 consumer group 消費者組的方式工作,由一個或者多個消費者組成一個組, 共同消費一個 topic。每個分區(qū)在同一時間只能由 group 中的一個消費者讀取,但是多個 group 可以同時消費這個 partition。在圖中,有一個由三個消費者組成的 group,有一個消費者讀取主題中的兩個分區(qū),另外兩個分別讀取一個分區(qū)。某個消費者讀取某個分區(qū),也可以叫做某個消費者是某個分區(qū)的擁有者。
在這種情況下,消費者可以通過水平擴展的方式同時讀取大量的消息。另外,如果一個消費者失敗了,那么其他的 group 成員會自動負載均衡讀取之前失敗的消費者讀取的分區(qū)。
4.3.4 消費方式
consumer 采用 pull(拉)模式從 broker 中讀取數(shù)據(jù)。
push(推)模式很難適應(yīng)消費速率不同的消費者,因為消息發(fā)送速率是由 broker 決定的。它的目標是盡可能以最快速度傳遞消息,但是這樣很容易造成 consumer 來不及處理消息,典型的表現(xiàn)就是拒絕服務(wù)以及網(wǎng)絡(luò)擁塞。而 pull 模式則可以根據(jù) consumer 的消費能力以適當?shù)乃俾氏M消息。
對于 Kafka 而言,pull 模式更合適,它可簡化 broker 的設(shè)計,consumer 可自主控制消費 消息的速率,同時 consumer 可以自己控制消費方式——即可批量消費也可逐條消費,同時還能選擇不同的提交方式從而實現(xiàn)不同的傳輸語義。
pull 模式不足之處是,如果 kafka 沒有數(shù)據(jù),消費者可能會陷入循環(huán)中,一直等待數(shù)據(jù) 到達。為了避免這種情況,我們在我們的拉請求中有參數(shù),允許消費者請求在等待數(shù)據(jù)到達 的“長輪詢”中進行阻塞(并且可選地等待到給定的字節(jié)數(shù),以確保大的傳輸大小)。
五、Kafka 安裝
5.1 安裝環(huán)境與前提條件
安裝環(huán)境:Linux
前提條件:
Linux系統(tǒng)下安裝好jdk 1.8以上版本,正確配置環(huán)境變量 Linux系統(tǒng)下安裝好scala 2.11版本
安裝ZooKeeper(注:kafka自帶一個Zookeeper服務(wù),如果不單獨安裝,也可以使用自帶的ZK)
5.2 安裝步驟
Apache基金會開源的這些軟件基本上安裝都比較方便,只需要下載、解壓、配置環(huán)境變量三步即可完成,kafka也一樣,官網(wǎng)選擇對應(yīng)版本下載后直接解壓到一個安裝目錄下就可以使用了,如果為了方便可以在~/.bashrc里配置一下環(huán)境變量,這樣使用的時候就不需要每次都切換到安裝目錄了。
具體可參考:Kafka 集群安裝與環(huán)境測試
5.3 測試
接下來可以通過簡單的console窗口來測試kafka是否安裝正確。
「(1)首先啟動ZooKeeper服務(wù)」
如果啟動自己安裝的ZooKeeper,使用命令zkServer.sh start即可。
如果使用kafka自帶的ZK服務(wù),啟動命令如下(啟動之后shell不會返回,后續(xù)其他命令需要另開一個Terminal):
$?cd?/opt/tools/kafka?#進入安裝目錄
$?bin/zookeeper-server-start.sh?config/zookeeper.properties
「(2)第二步啟動kafka服務(wù)」
啟動Kafka服務(wù)的命令如下所示:
$?cd?/opt/tools/kafka?#進入安裝目錄
$?bin/kafka-server-start.sh?config/server.properties
「(3)第三步創(chuàng)建一個topic,假設(shè)為“test”」
創(chuàng)建topic的命令如下所示,其參數(shù)也都比較好理解,依次指定了依賴的ZooKeeper,副本數(shù)量,分區(qū)數(shù)量,topic的名字:
$?cd?/opt/tools/kafka?#進入安裝目錄
$?bin/kafka-topics.sh?--create?--zookeeper?localhost:2181?--replication-factor?1?--partitions?1?--topic?test1
創(chuàng)建完成后,可以通過如下所示的命令查看topic列表:
$?bin/kafka-topics.sh?--list?--zookeeper?localhost:2181?
「(4)開啟Producer和Consumer服務(wù)」
kafka提供了生產(chǎn)者和消費者對應(yīng)的console窗口程序,可以先通過這兩個console程序來進行驗證。
首先啟動Producer:
$?cd?/opt/tools/kafka?#進入安裝目錄
$?bin/kafka-console-producer.sh?--broker-list?localhost:9092?--topic?test
然后啟動Consumer:
$?cd?/opt/tools/kafka?#進入安裝目錄
$?bin/kafka-console-consumer.sh?--bootstrap-server?localhost:9092?--topic?test?--from-beginning
在打開生產(chǎn)者服務(wù)的終端輸入一些數(shù)據(jù),回車后,在打開消費者服務(wù)的終端能看到生產(chǎn)者終端輸入的數(shù)據(jù),即說明kafka安裝成功。
六、Apache Kafka 簡單示例
6.1 創(chuàng)建消息隊列
kafka-topics.sh?--create?--zookeeper?192.168.56.137:2181?--topic?test?--replication-factor?1?--partitions?1
6.2 pom.xml
????org.apache.kafka
????kafka-clients
????2.1.1
6.3 生產(chǎn)者
package?com.njbdqn.services;
import?org.apache.kafka.clients.producer.KafkaProducer;
import?org.apache.kafka.clients.producer.ProducerConfig;
import?org.apache.kafka.clients.producer.ProducerRecord;
import?org.apache.kafka.common.serialization.StringSerializer;
import?java.util.Properties;
/**
?*?@author:Tokgo J
?*?@date:2020/9/11
?*?@aim:生產(chǎn)者:往test消息隊列寫入消息
?*/
public?class?MyProducer?{
????public?static?void?main(String[]?args)?{
????????//?定義配置信息
????????Properties?prop?=?new?Properties();
????????//?kafka地址,多個地址用逗號分割??"192.168.23.76:9092,192.168.23.77:9092"
????????prop.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.56.137:9092");
????????prop.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,?StringSerializer.class);
????????prop.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,StringSerializer.class);
????????KafkaProducer?prod?=?new?KafkaProducer(prop);
????????//?發(fā)送消息
????????try?{
????????????for(int?i=0;i<10;i++)?{
????????????????//?生產(chǎn)者記錄消息
????????????????ProducerRecord?pr?=?new?ProducerRecord("test",?"hello?world"+i);
????????????????prod.send(pr);
????????????????Thread.sleep(500);
????????????}
????????}?catch?(InterruptedException?e)?{
????????????e.printStackTrace();
????????}?finally?{
????????????prod.close();
????????}
????}
}
注意:
kafka如果是集群,多個地址用逗號分割 (,);Properties的put方法,第一個參數(shù)可以是字符串,如: p.put("bootstrap.servers","192.168.23.76:9092");kafkaProducer.send(record)可以通過返回的Future來判斷是否已經(jīng)發(fā)送到kafka,增強消息的可靠性。同時也可以使用send的第二個參數(shù)來回調(diào),通過回調(diào)判斷是否發(fā)送成功;p.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);設(shè)置序列化類,可以寫類的全路徑。
6.4 消費者
package?com.njbdqn.services;
import?org.apache.kafka.clients.consumer.ConsumerConfig;
import?org.apache.kafka.clients.consumer.ConsumerRecord;
import?org.apache.kafka.clients.consumer.ConsumerRecords;
import?org.apache.kafka.clients.consumer.KafkaConsumer;
import?org.apache.kafka.common.serialization.StringDeserializer;
import?org.apache.kafka.common.serialization.StringSerializer;
import?java.time.Duration;
import?java.util.Arrays;
import?java.util.Collections;
import?java.util.Properties;
/**
?*?@author:Tokgo J
?*?@date:2020/9/11
?*?@aim:消費者:讀取kafka數(shù)據(jù)
?*/
public?class?MyConsumer?{
????public?static?void?main(String[]?args)?{
????????Properties?prop?=?new?Properties();
????????prop.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,?"192.168.56.137:9092");
????????prop.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,?StringDeserializer.class);
????????prop.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,?StringDeserializer.class);
????????prop.put("session.timeout.ms",?"30000");
????????//消費者是否自動提交偏移量,默認是true?避免出現(xiàn)重復數(shù)據(jù)?設(shè)為false
????????prop.put("enable.auto.commit",?"false");
????????prop.put("auto.commit.interval.ms",?"1000");
????????//auto.offset.reset?消費者在讀取一個沒有偏移量的分區(qū)或者偏移量無效的情況下的處理
????????//earliest?在偏移量無效的情況下?消費者將從起始位置讀取分區(qū)的記錄
????????//latest?在偏移量無效的情況下?消費者將從最新位置讀取分區(qū)的記錄
????????prop.put("auto.offset.reset",?"earliest");
????????//?設(shè)置組名
????????prop.put(ConsumerConfig.GROUP_ID_CONFIG,?"group");
????????KafkaConsumer?con?=?new?KafkaConsumer(prop);
????????con.subscribe(Collections.singletonList("test"));
????????while?(true)?{
????????????ConsumerRecords?records?=?con.poll(Duration.ofSeconds(100));
????????????for?(ConsumerRecord?rec?:?records)?{
????????????????System.out.println(String.format("offset:%d,key:%s,value:%s",?rec.offset(),?rec.key(),?rec.value()));
????????????}
????????}
????}
}
注意:
訂閱消息可以訂閱多個主題; ConsumerConfig.GROUP_ID_CONFIG表示消費者的分組,kafka根據(jù)分組名稱判斷是不是同一組消費者,同一組消費者去消費一個主題的數(shù)據(jù)的時候,數(shù)據(jù)將在這一組消費者上面輪詢;主題涉及到分區(qū)的概念,同一組消費者的個數(shù)不能大于分區(qū)數(shù)。因為:一個分區(qū)只能被同一群組的一個消費者消費。出現(xiàn)分區(qū)小于消費者個數(shù)的時候,可以動態(tài)增加分區(qū); 注意和生產(chǎn)者的對比,Properties中的key和value是反序列化,而生產(chǎn)者是序列化。
七、參考
朱小廝:《深入理解Kafka:核心設(shè)計與實踐原理》
宇宙灣:《Apache Kafka 分布式消息隊列框架》
—?【 THE END 】— 本公眾號全部博文已整理成一個目錄,請在公眾號里回復「m」獲取! 3T技術(shù)資源大放送!包括但不限于:Java、C/C++,Linux,Python,大數(shù)據(jù),人工智能等等。在公眾號內(nèi)回復「1024」,即可免費獲取!!