
Echo 技術(shù)選型分析
千呼萬喚始出來,這篇教程拖了一個星期。最近準備暑期實習實在沒時間,因為沒經(jīng)驗,我都不知道三月份暑期實習招聘就開始了 ??,留給我的時間有點短,正好今天復(fù)習 Kafka,所以抽點時間來寫篇教程。
其他的常見技術(shù)棧就不說了,MyBatis、Redis 等,本文只講 Spring Boot 和 Kafka,當然,Kafka 是重中之重,Spring Boot 就簡單分析一下優(yōu)點就完事兒。
為什么選擇 Spring Boot?
1)從字面理解,Boot 是引導(dǎo)的意思,Spring Boot 可以幫助我們迅速的搭建 Spring 框架;
2)“約定大于配置”,一般來說,我們使用 Spring Boot 的時候只需要很少的配置,大部分情況下直接使用默認的配置即可;
3)Spring Boot 內(nèi)嵌了 Web 容器,降低了對環(huán)境的要求,使得我們可以執(zhí)行運行項目主程序的 main 函數(shù);
4)最重要的,對于開發(fā)者來說,那當然是 Spring Boot 不需要編寫大量的 XML 配置;
5)..........
為什么選擇 Kafka?
為什么使用消息隊列
先來說一下為什么要使用消息隊列,六個字總結(jié):解耦、異步、消峰。
1)「解耦」
傳統(tǒng)模式下系統(tǒng)間的耦合性太強。怎么說呢,舉個例子:系統(tǒng) A 通過接口調(diào)用發(fā)送數(shù)據(jù)到 B、C、D 三個系統(tǒng),如果將來 E 系統(tǒng)接入或者 B 系統(tǒng)不需要接入了,那么系統(tǒng) A 還需要修改代碼,非常麻煩。
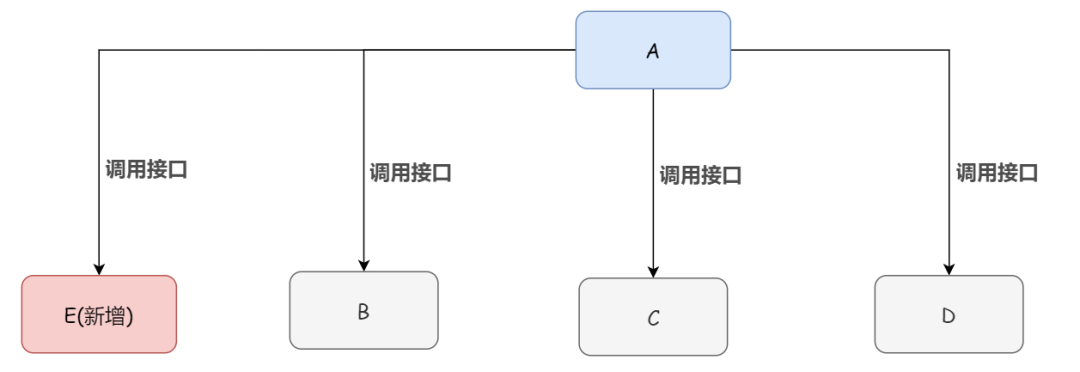
如果系統(tǒng) A 產(chǎn)生了一條比較關(guān)鍵的數(shù)據(jù),那么它就要時時刻刻考慮 B、C、D、E 四個系統(tǒng)如果掛了該咋辦?這條數(shù)據(jù)它們是否都收到了?顯然,系統(tǒng) A 跟其它系統(tǒng)嚴重耦合。
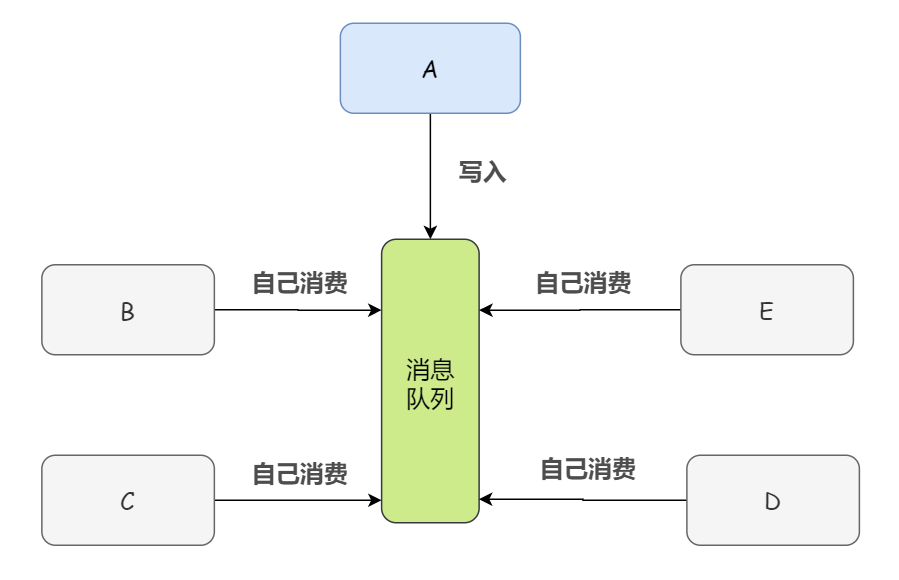
而如果我們將數(shù)據(jù)(消息)寫入消息隊列,需要消息的系統(tǒng)直接自己從消息隊列中消費。這樣下來,系統(tǒng) A 就不需要去考慮要給誰發(fā)送數(shù)據(jù),不需要去維護這個代碼,也不需要考慮其他系統(tǒng)是否調(diào)用成功、失敗超時等情況,反正我只負責生產(chǎn),別的我不管。
2)「異步」
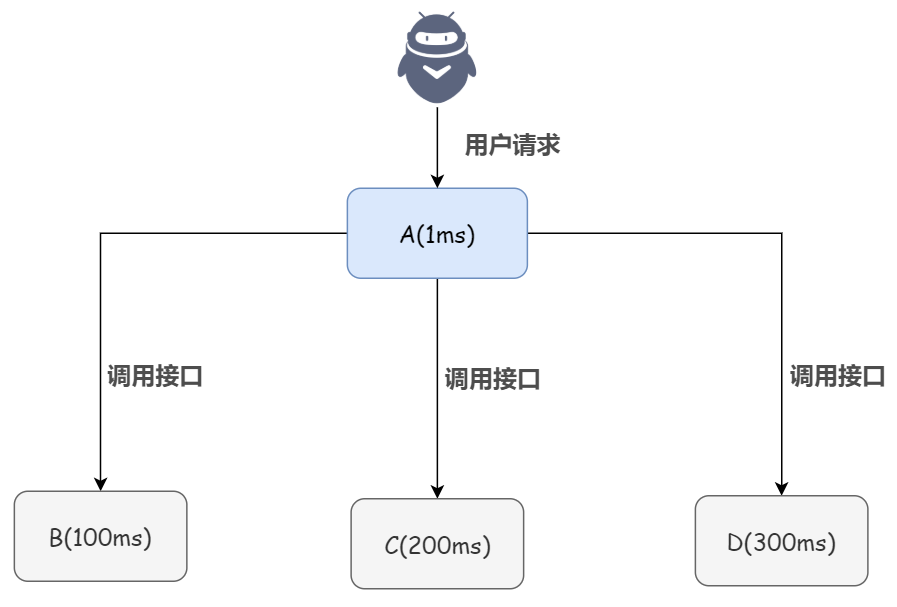
先來看傳統(tǒng)同步的情況,舉個例子:系統(tǒng) A 接收一個用戶請求,需要進行寫庫操作,還需要同樣的在 B、C、D 三個系統(tǒng)中進行寫庫操作。如果 A 自己本地寫庫只要 1ms,而 B、C、D 三個系統(tǒng)寫庫分別要 100ms、200ms、300ms。最終請求總延時是 1 + 100 + 200 + 300 = 601ms,用戶體驗大打折扣。
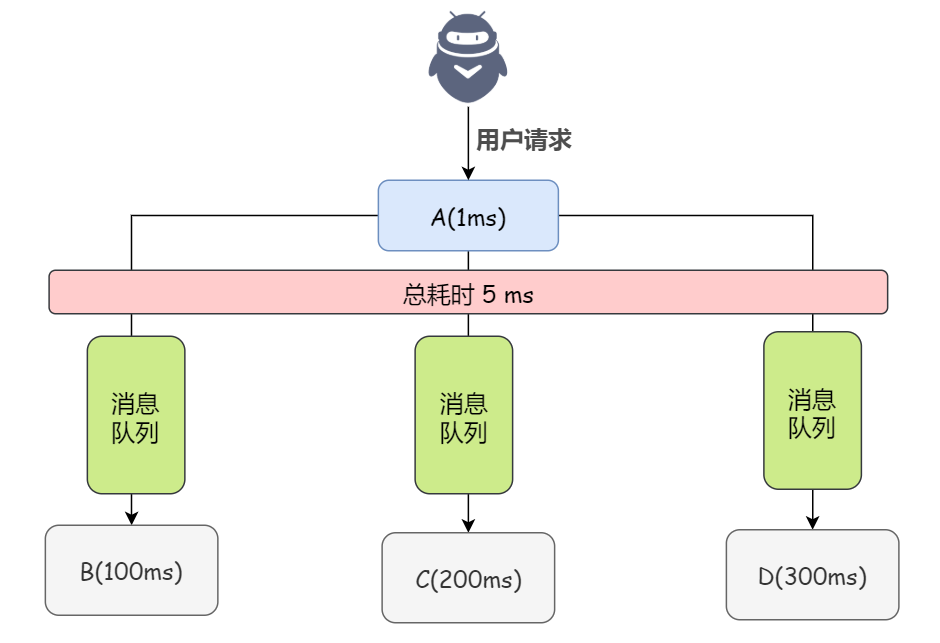
如果使用消息隊列,那么系統(tǒng) A 就只需要發(fā)送 3 條消息到消息隊列中就行了,假如耗時 5ms,A 系統(tǒng)從接受一個請求到返回響應(yīng)給用戶,總時長是 1 + 5 = 6ms,對于用戶而言,體驗好感度直接拉滿。
3)「消峰」
如果沒有使用緩存或者消息隊列,那么系統(tǒng)就是直接基于數(shù)據(jù)庫 MySQL 的,如果有那么一個高峰期,產(chǎn)生了大量的請求涌入 MySQL,毫無疑問,系統(tǒng)將會直接崩潰。
那如果我們使用消息隊列,假設(shè) MySQL 每秒鐘最多處理 1k 條數(shù)據(jù),而高峰期瞬間涌入了 5k 條數(shù)據(jù),不過,這 5k 條數(shù)據(jù)涌入了消息隊列。這樣,我們的系統(tǒng)就可以從消息隊列中根據(jù)數(shù)據(jù)庫的能力慢慢的來拉取請求,不要超過自己每秒能處理的最大請求數(shù)量就行。
也就是說消息隊列每秒鐘 5k 個請求進來,1k 個請求出去,假設(shè)高峰期 1 個小時,那么這段時間就可能有幾十萬甚至幾百萬的請求積壓在消息隊列中。不過這個短暫的高峰期積壓是完全可以的,因為高峰期過了之后,每秒鐘就沒有那么多的請求進入消息隊列了,但是數(shù)據(jù)庫依然會按照每秒 1k 個請求的速度處理。所以只要高峰期一過,系統(tǒng)就會快速的將積壓的消息給處理掉。

為什么選擇 Kafka
再來看看在 Echo 這個項目中,哪些地方使用了消息隊列也就是 Kafka:
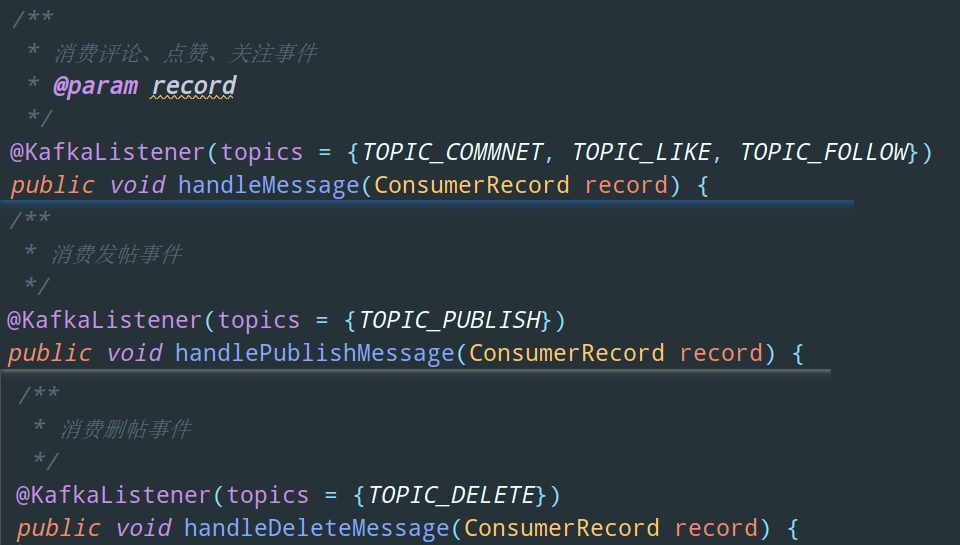
評論、點贊、關(guān)注事件觸發(fā)通知 發(fā)帖事件觸發(fā) Elasticsearch 服務(wù)器中相應(yīng)的數(shù)據(jù)更新 刪帖事件觸發(fā) Elasticsearch 服務(wù)器中相應(yīng)的數(shù)據(jù)更新
實際上在早期的時候 Kafka 并不是一個合格的消息隊列,不過現(xiàn)在已經(jīng)足夠優(yōu)秀。不說我們這個用戶量比較小的論壇,從大體量的論壇項目來考慮,我覺得 Kafka 比較適合的原因有如下:
1)Kafka 天生支持分布式,Broker、Producer 和 Consumer 都原生自動支持分布式;
2)Kafka 擁有多分區(qū)(Partition)和多副本(Replica)機制,能提供比較好的并發(fā)能力(負載均衡)以及較高的可用性和可靠性,理論上支持消息無限堆積;
3)而且,在一眾消息隊列里,Kafka 的性能是比較高的。點贊、關(guān)注、私信等操作都會觸發(fā)通知,在流量巨大的社交論壇網(wǎng)站中,這個系統(tǒng)通知的需求是非常龐大的,為保證系統(tǒng)的高性能,使用消息隊列 Kafka 是個明智的選擇。

由于公眾號開通較晚,沒有留言功能,暫時用小程序代替,各位小伙伴有啥問題請前往留言吧~