
OLAP 技術(shù)選型:對什么進行選型?
OLAP 技術(shù)架構(gòu)
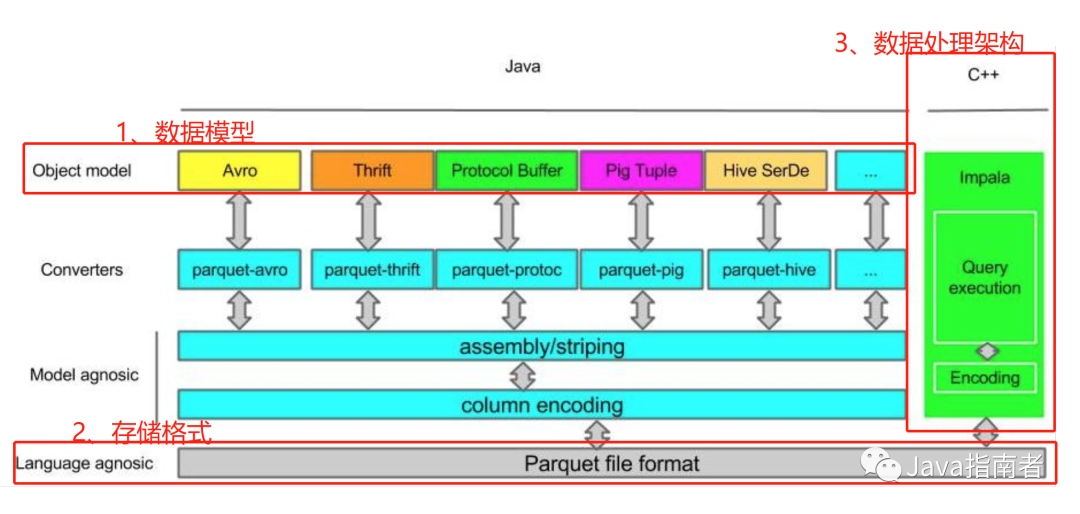
數(shù)據(jù)模型
基于 SOAP 消息格式的 WebService
基于 JSON 消息格式的 RESTful 服務(wù)
Google protobuf
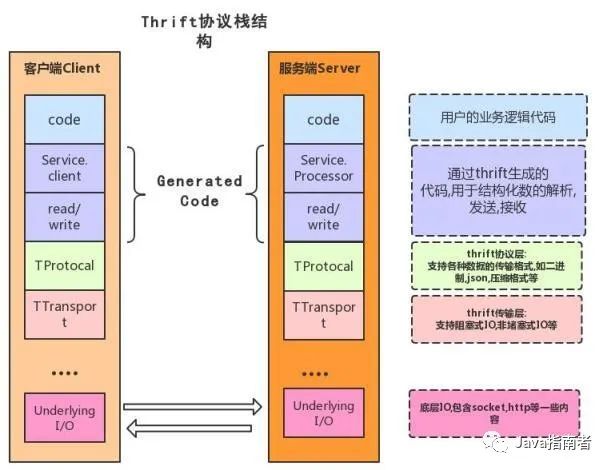
Apache Thrift
Apache Avro
使用編程語言的內(nèi)置序列化,如 Java 序列化、Ruby 的 marshal,或 Python 的 pickle。
然而,你意識到困在一種編程語言中是很糟糕的,所以轉(zhuǎn)而使用一種廣泛支持的、與語言無關(guān)的格式,比如 Json。
然而,你發(fā)現(xiàn) JSON 太過冗余,解析太慢,不能區(qū)分整數(shù)和浮點數(shù),并且你認為自己非常喜歡二進制字符串和 Unicode 字符串。
然后你會發(fā)現(xiàn)人們使用不一致的類型將各種各樣的隨機字段填充到他們的對象中,這時你非常需要一個 schema 以及一些 documentation。也許你還在使用靜態(tài)類型的語言,并從 schema 生成 model 類。你還會意識到,與 JSON 相似的二進制文件實際上不是那么緊湊,因為你在一遍又一遍地存儲字段名。如果你有一個 schema,你可以避免存儲對象的字段名,這樣可以節(jié)省更多字節(jié)。
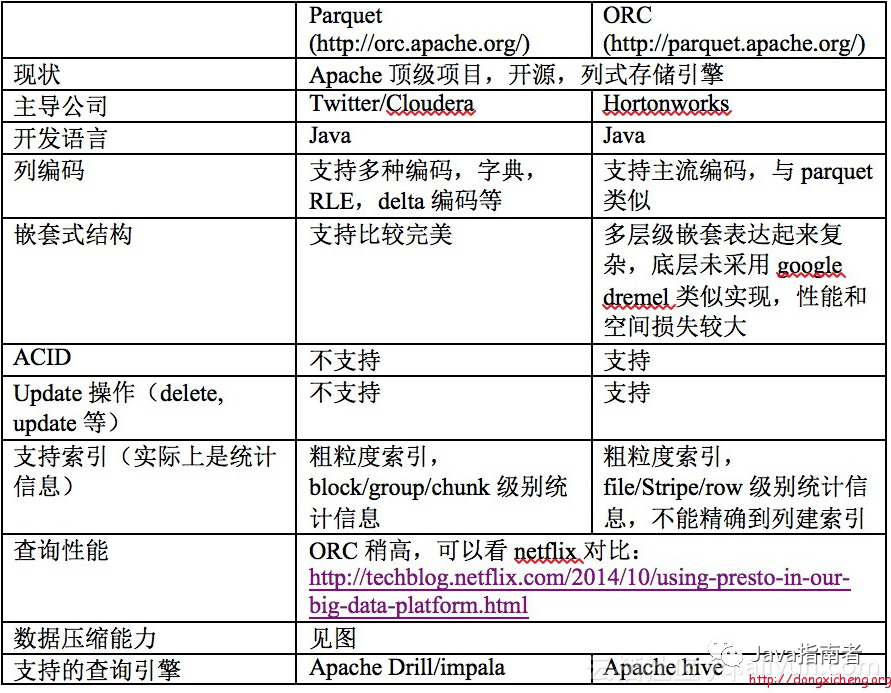
存儲格式
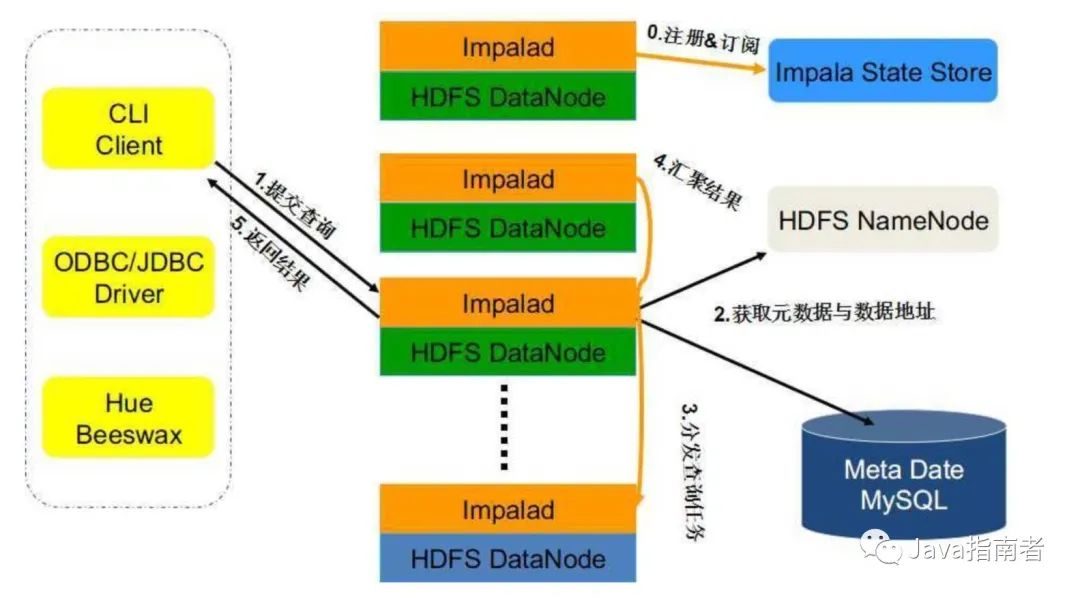
數(shù)據(jù)處理框架
對什么進行選型
但是數(shù)據(jù)處理框架所使用的存儲格式對 OLAP 很多方面起到?jīng)Q定性作用;如下圖,如果我們選型了 impala(使用 Parquet 作為存儲格式),就不能期望對模式演化(schema evolution)有很好支持;再比如,如果選型了 druid(使用作為存儲格式),底層查詢在存儲引擎上的執(zhí)行過程不能向量化執(zhí)行,因此在對大數(shù)據(jù)量、少量列進行聚合計算查詢時性能應(yīng)該是比 impala、presto 差。

通過數(shù)據(jù)處理框架所使用存儲格式,再結(jié)合我們需求可以很大程度縮小選型范圍;哪怎么再在這個小范圍再進一步去選擇符合我們場景的 OLAP 技術(shù)呢?在下篇再跟大家講講 OLAP 技術(shù)分類,通過這些分類我們可以進一步縮小我們選型范圍,最終選擇合適技術(shù)。
Hive計算最大連續(xù)登陸天數(shù)
Hadoop 數(shù)據(jù)遷移用法詳解
Hbase修復工具Hbck
數(shù)倉建模分層理論
一文搞懂Hive的數(shù)據(jù)存儲與壓縮
大數(shù)據(jù)組件重點學習這幾個