
干貨 | 一文讓你了解Pandas數(shù)據(jù)結(jié)構(gòu)

? ???作者:木木
? ? ?來源:Python數(shù)據(jù)分析實戰(zhàn)與AI干貨
1導(dǎo)入相關(guān)的包import?numpy?as?np
import?pandas?as?pd
from?pandas?import?DataFrame
from?pandas?import?Series
obj?=?Series([4,?7,?-5,?3])
print(obj)
print(obj.values)
print(obj.index)

obj2?=?Series([4,?7,?-5,?3],?index=['d',?'b',?'a',?'c'])
print(obj2)
print(obj2['a'])

obj2['d']?=?6
print(obj2[['c',?'a',?'d']])

obj2[obj2?>?0]

obj2?*?2

np.exp(obj2)

print('b'?in?obj2)
print('e'?in?obj2)

#?Dict?->?Series
sdata?=?{'Ohio':?35000,?'Texas':?71000,?'Oregon':?16000,?'Utah':?5000}
obj3?=?Series(sdata)
obj3

states?=?['California',?'Ohio',?'Oregon',?'Texas']
obj4?=?Series(sdata,?index=states)?#?自動與dict的key匹配
obj4

print(pd.isnull(obj4))
print(pd.notnull(obj4))

print(obj3?+?obj4)?#?數(shù)據(jù)自動對齊

obj4.name?=?'人口'
obj4.index.name?=?'州'
obj4
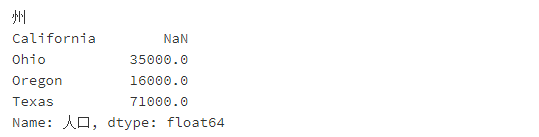
obj?=?Series([4,?7,?-5,?3])
obj.index?=?['Bob',?'Steve',?'Jeff',?'Ryan']?#?更新索引
obj

data?=?{'state':?['Ohio',?'Ohio',?'Ohio',?'Nevada',?'Nevada'],
????????'year':?[2000,?2001,?2002,?2001,?2002],
????????'pop':?[1.5,?1.7,?3.6,?2.4,?2.9]}
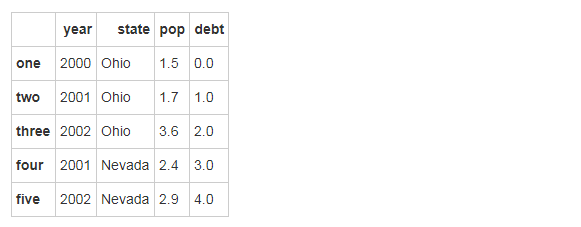
frame?=?DataFrame(data)?#?key對應(yīng)frame的列名
frame

frame?=?DataFrame(data,?columns=['year',?'state',?'pop'])?#?指定列順序
frame

frame2?=?DataFrame(data,
???????????????????columns=['year',?'state',?'pop',?'debt'],
???????????????????index=['one',?'two',?'three',?'four',?'five'])?#?分別指定行列名字,缺失值自動填充,比如debt列。
frame2

print(frame2['state'])?#?通過索引返回指定列,返回類型為Series
print(frame2.year)
print(type(frame.state))

print(frame2.loc['three'])?#?使用loc訪問行,iloc針對默認(rèn)的數(shù)字索引
print(frame2.iloc[0])

frame2['debt']?=?16.5?#?修改整列值
frame2

frame2['debt']?=?np.arange(5.)
frame2
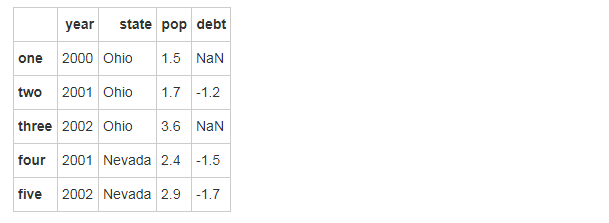
val?=?Series([-1.2,?-1.5,?-1.7],?index=['two',?'four',?'five'])
frame2['debt']?=?val?#?索引不匹配的話自動補NaN
frame2
del?frame2['eastern']?#?刪除指定列
frame2.columns
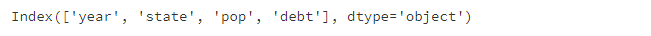
pop?=?{'Nevada':?{2001:?2.4,?2002:?2.9},
???????'Ohio':?{2000:?1.5,?2001:?1.7,?2002:?3.6}}
frame3?=?DataFrame(pop)?#?通過嵌套字典指定列和行索引
frame3.T?#?轉(zhuǎn)置

pop?=?{'Nevada':?{2001:?2.4,?2002:?2.9},
???????'Ohio':?{2000:?1.5,?2001:?1.7,?2002:?3.6}}
frame3?=?DataFrame(pop)?#?通過嵌套字典指定列和行索引
DataFrame(pop,?index=[2001,?2002,?2003])?#?索引2003匹配不到,自動填充NaN

pdata?=?{'Ohio':?frame3['Ohio'][:-1],
?????????'Nevada':?frame3['Nevada'][:2]}?#?使用Series替代普通數(shù)組
DataFrame(pdata)

frame3.index.name?=?'year'?#?設(shè)置索引和列的名字
frame3.columns.name?=?'state'
frame3

print('Ohio'?in?frame3.columns)
print(2003?in?frame3.index)

#?Index的方法和屬性
# append:??????連接另一個Index對象,產(chǎn)生一個新的Index。
# diff:????????計算差集,并得到一個Index。
# intersection:計算交集
# union:???????計算并集
# isin:????????計算一個指示各值是否都包含在參數(shù)集合中的布爾型數(shù)組
# delete:??????刪除索引i處的元素,并得到新的Index。
# drop:????????刪除傳入的值,并得到新的Index。
# insert:??????將元素插入到索引i處,并得到新的Index。
# is_monotonic:如果單調(diào)增長,返回True。
# is_unique:???當(dāng)Index沒有重復(fù)值時,返回True。
# unique:??????計算Index中唯一值得數(shù)組
◆?◆?◆ ?◆?◆
長按二維碼關(guān)注我們
數(shù)據(jù)森麟公眾號的交流群已經(jīng)建立,許多小伙伴已經(jīng)加入其中,感謝大家的支持。大家可以在群里交流關(guān)于數(shù)據(jù)分析&數(shù)據(jù)挖掘的相關(guān)內(nèi)容,還沒有加入的小伙伴可以掃描下方管理員二維碼,進(jìn)群前一定要關(guān)注公眾號奧,關(guān)注后讓管理員幫忙拉進(jìn)群,期待大家的加入。
管理員二維碼:
評論
圖片
表情