
【BBuf的CUDA筆記】三,reduce優(yōu)化入門學習筆記
reduce優(yōu)化學習筆記
這里記錄學習 NIVDIA 的reduce優(yōu)化官方博客 做的筆記。完整實驗代碼見:https://github.com/BBuf/how-to-optim-algorithm-in-cuda
問題介紹
通俗的來說,Reduce就是要對一個數(shù)組求 sum,min,max,avg 等等。Reduce又被叫作規(guī)約,意思就是遞歸約減,最后獲得的輸出相比于輸入一般維度上會遞減。比如 nvidia 博客上這個 Reduce Sum 問題,一個長度為 8 的數(shù)組求和之后得到的輸出只有一個數(shù),從 1 維數(shù)組變成一個標量。本文就以 Reduce Sum 為例來記錄 Reduce 優(yōu)化。
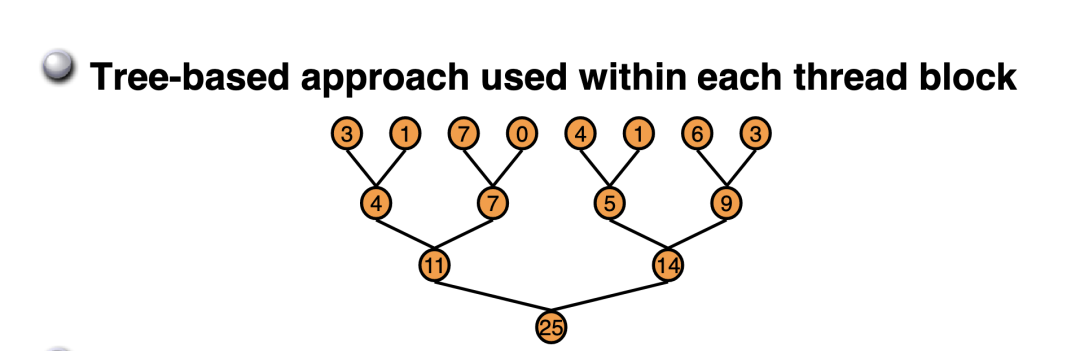
硬件環(huán)境
NVIDIA A100-PCIE-40GB , 峰值帶寬在 1555 GB/s , CUDA版本為11.8.
構(gòu)建BaseLine
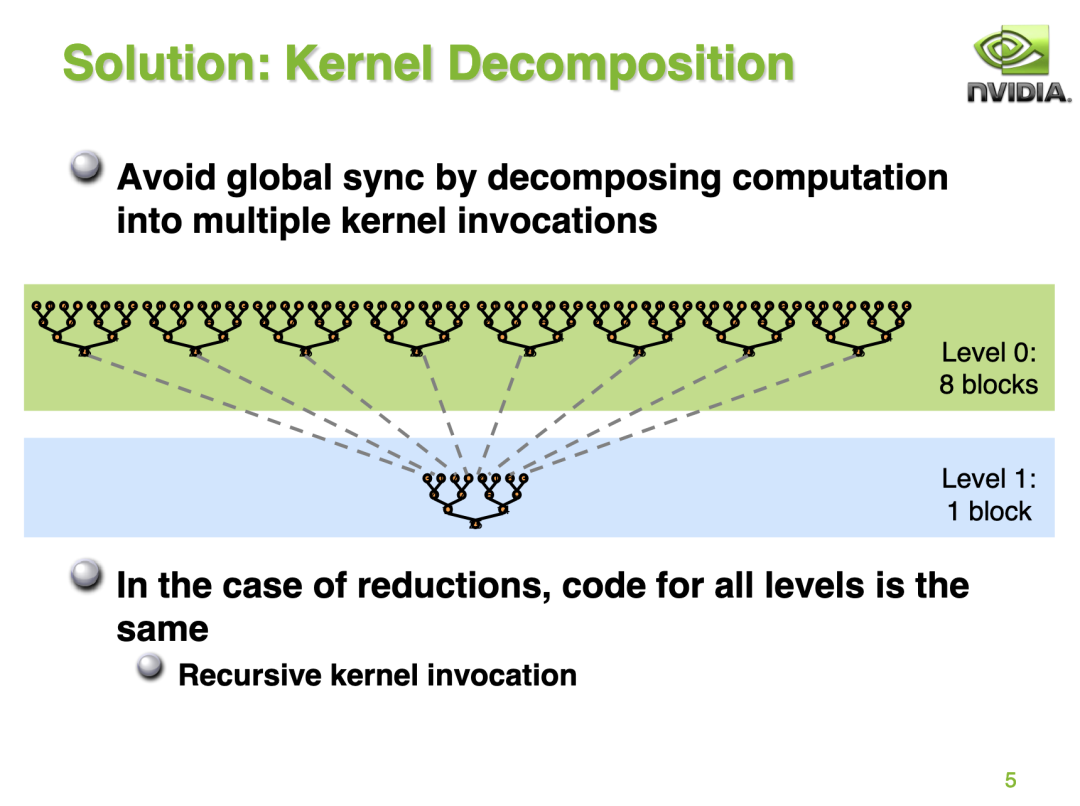
在問題介紹一節(jié)中的 Reduce 求和圖實際上就指出了 BaseLine 的執(zhí)行方式,我們將以樹形圖的方式去執(zhí)行數(shù)據(jù)累加,最終得到總和。但由于GPU沒有針對 global memory 的同步操作,所以博客指出我們可以通過將計算分成多個階段的方式來避免 global memrory 的操作。如下圖所示:
接著 NVIDIA 博客給出了 BaseLine 算法的實現(xiàn):

這里的 g_idata 表示的是輸入數(shù)據(jù)的指針,而 g_odata 則表示輸出數(shù)據(jù)的指針。然后首先把 global memory 數(shù)據(jù) load 到 shared memory 中,接著在 shared memory 中對數(shù)據(jù)進行 Reduce Sum 操作,最后將 Reduce Sum 的結(jié)果寫會 global memory 中。
但接下來的這頁 PPT 指出了 Baseine 實現(xiàn)的低效之處:

這里指出了2個問題,一個是warp divergent,另一個是取模這個操作很昂貴。這里的warp divergent 指的是對于啟動 BaseLine Kernel 的一個 block 的 warp 來說,它所有的 thread 執(zhí)行的指令都是一樣的,而 BaseLine Kernel 里面存在 if 分支語句,一個 warp 的32個 thread 都會執(zhí)行存在的所有分支,但只會保留滿足條件的分支產(chǎn)生的結(jié)果。
我們可以在第8頁PPT里面看到,對于每一次迭代都會有兩個分支,分別是有豎直的黑色箭頭指向的小方塊(有效計算的線程)以及其它沒有箭頭指向的方塊,所以每一輪迭代實際上都有大量線程是空閑的,無法最大程度的利用GPU硬件。
從這個PPT我們可以計算出,對于一個 Block 來說要完成Reduce Sum,一共有8次迭代,并且每次迭代都會產(chǎn)生warp divergent。
接下來我們先把 BaseLine 的代碼抄一下,然后我們設(shè)定好一個 GridSize 和 BlockSize 啟動 Kernel 測試下性能。在PPT的代碼基礎(chǔ)上,我么補充一下內(nèi)存申請以及啟動 Kernel 的代碼。
#include <cuda.h>
#include <cuda_runtime.h>
#include <time.h>
#define N 32*1024*1024
#define BLOCK_SIZE 256
__global__ void reduce_v0(float *g_idata,float *g_odata){
__shared__ float sdata[BLOCK_SIZE];
// each thread loads one element from global to shared mem
unsigned int tid = threadIdx.x;
unsigned int i = blockIdx.x*blockDim.x + threadIdx.x;
sdata[tid] = g_idata[i];
__syncthreads();
// do reduction in shared mem
for(unsigned int s=1; s < blockDim.x; s *= 2) {
if (tid % (2*s) == 0) {
sdata[tid] += sdata[tid + s];
}
__syncthreads();
}
// write result for this block to global mem
if (tid == 0) g_odata[blockIdx.x] = sdata[0];
}
int main() {
float *input_host = (float*)malloc(N*sizeof(float));
float *input_device;
cudaMalloc((void **)&input_device, N*sizeof(float));
for (int i = 0; i < N; i++) input_host[i] = 2.0;
cudaMemcpy(input_device, input_host, N*sizeof(float), cudaMemcpyHostToDevice);
int32_t block_num = (N + BLOCK_SIZE - 1) / BLOCK_SIZE;
float *output_host = (float*)malloc((N / BLOCK_SIZE) * sizeof(float));
float *output_device;
cudaMalloc((void **)&output_device, (N / BLOCK_SIZE) * sizeof(float));
dim3 grid(N / BLOCK_SIZE, 1);
dim3 block(BLOCK_SIZE, 1);
reduce_v0<<<grid, block>>>(input_device, output_device);
cudaMemcpy(output_device, output_host, block_num * sizeof(float), cudaMemcpyDeviceToHost);
return 0;
}
我們這里設(shè)定輸入數(shù)據(jù)的長度是 32*1024*1024 個float數(shù) (也就是PPT中的4M數(shù)據(jù)),然后每個 block 的線程數(shù)我們設(shè)定為 256 (BLOCK_SIZE = 256, 也就是一個 Block 有 8 個 warp)并且每個 Block 要計算的元素個數(shù)也是 256 個,然后當一個 Block 的計算完成后對應(yīng)一個輸出元素。所以對于輸出數(shù)據(jù)來說,它的長度是輸入數(shù)據(jù)長度處以 256 。我們代入 kernel 加載需要的 GridSize(N / 256) 和 BlockSize(256) 再來理解一下 BaseLine 的 Reduce kernel。
首先,第 tid 號線程會把 global memroy 的第 i 號數(shù)據(jù)取出來,然后塞到 shared memroy 中。接下來針對已經(jīng)存儲到 shared memroy 中的 256 個元素展開多輪迭代,迭代的過程如 PPT 的第8頁所示。完成迭代過程之后,這個 block 負責的256個元素的和都放到了 shared memrory 的0號位置,我們只需要將這個元素寫回global memory就做完了。
接下來我們使用 nvcc -o bin/reduce_v0 reduce_v0_baseline.cu 編譯一下這個源文件,并且使用nsight compute去profile一下。
性能和帶寬的測試情況如下:
| 優(yōu)化手段 | 耗時(us) | 帶寬利用率 | 加速比 |
|---|---|---|---|
| reduce_baseline | 990.66us | 39.57% | ~ |
優(yōu)化手段1: 交錯尋址(Interleaved Addressing)
接下來直接NVIDIA的PPT給出了優(yōu)化手段1:

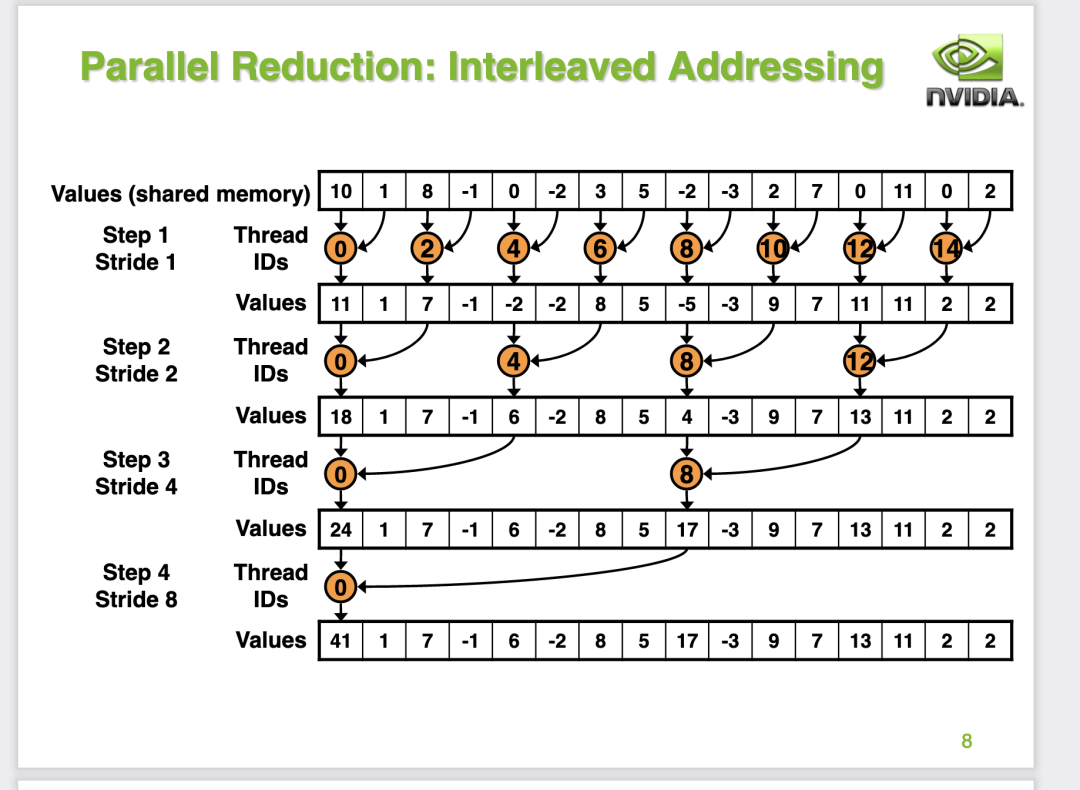
這里是直接針對 BaseLine 中的 warp divergent 問題進行優(yōu)化,通過調(diào)整BaseLine中的分支判斷代碼使得更多的線程可以走到同一個分支里面,降低迭代過程中的線程資源浪費。具體做法就是把 if (tid % (2*s) == 0) 替換成 strided index的方式也就是int index = 2 * s * tid,然后判斷 index 是否在當前的 block 內(nèi)。雖然這份優(yōu)化后的代碼沒有完全消除if語句,但是我們可以來計算一下這個版本的代碼在8次迭代中產(chǎn)生 warp divergent 的次數(shù)。對于第一次迭代,0-3號warp的index都是滿足<blockDim.x的,而4-7號warp的index都是滿足>=blockDim.x的,也就是說這次迭代根本不會出現(xiàn)warp divergent的問題,因為每個warp的32個線程執(zhí)行的都是相同的分支。接下來對于第二代迭代,0,1兩個warp是滿足<blockDim.x的,其它warp則滿足>=blockDim.x,依然不會出現(xiàn)warp divergent,以此類推直到第4次迭代時0號warp的前16個線程和后16線程會進入不同的分支,會產(chǎn)生一次warp divergent,接下來的迭代都分別會產(chǎn)生一次warp divergent。但從整體上看,這個版本的代碼相比于BaseLine的代碼產(chǎn)生的warp divergent次數(shù)會少得多。
我們繼續(xù)抄一下這個代碼然后進行profile一下。
#define N 32*1024*1024
#define BLOCK_SIZE 256
__global__ void reduce_v1(float *g_idata,float *g_odata){
__shared__ float sdata[BLOCK_SIZE];
// each thread loads one element from global to shared mem
unsigned int tid = threadIdx.x;
unsigned int i = blockIdx.x*blockDim.x + threadIdx.x;
sdata[tid] = g_idata[i];
__syncthreads();
// do reduction in shared mem
for(unsigned int s=1; s < blockDim.x; s *= 2) {
// if (tid % (2*s) == 0) {
// sdata[tid] += sdata[tid + s];
// }
int index = 2 * s * tid;
if (index < blockDim.x) {
sdata[tid] += sdata[tid + s];
}
__syncthreads();
}
// write result for this block to global mem
if (tid == 0) g_odata[blockIdx.x] = sdata[0];
}
性能和帶寬的測試情況如下:
| 優(yōu)化手段 | 耗時(us) | 帶寬利用率 | 加速比 |
|---|---|---|---|
| reduce_baseline | 990.66us | 39.57% | ~ |
| reduce_v1_interleaved_addressing | 479.58us | 81.74% | 2.06 |
可以看到這個優(yōu)化還是很有效的,相比于BaseLine的性能有2倍的提升。
優(yōu)化手段2: 解決Bank Conflict
對于 reduce_v1_interleaved_addressing 來說,它最大的問題時產(chǎn)生了 Bank Conflict。使用 shared memory 有以下幾個好處:
更低的延遲(20-40倍) 更高的帶寬(約為15倍) 更細的訪問粒度,shared memory是4byte,global memory是32byte
但是 shared memrory 的使用量存在一定上限,而使用 shared memory 要特別小心 bank conflict 。實際上,shared memory 是由 32 個 bank 組成的,如下面這張 PPT 所示:

而 bank conflict 指的就是在一個 warp 內(nèi),有2個或者以上的線程訪問了同一個 bank 上不同地址的內(nèi)存。比如:
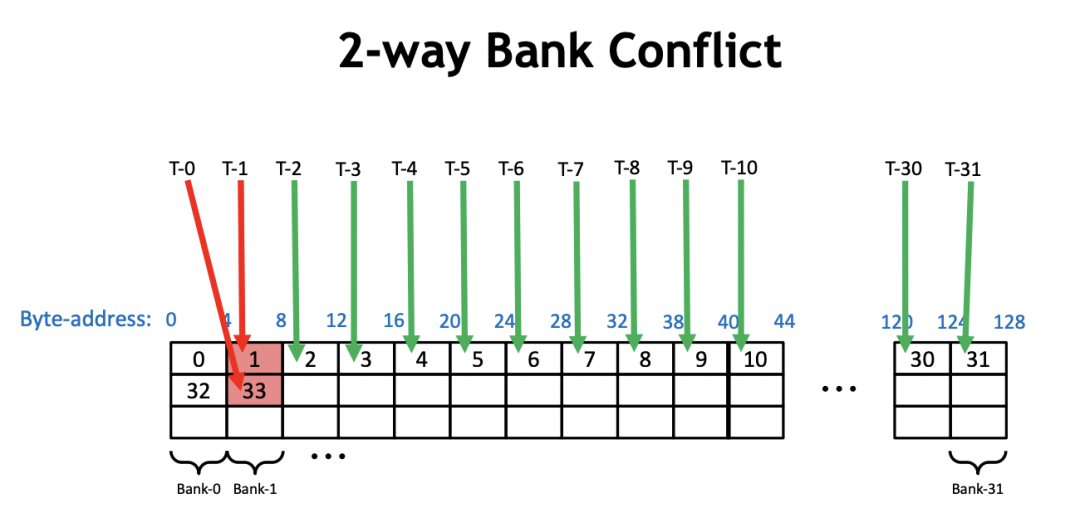
在 reduce_v1_interleaved_addressing 的 Kernel 中,我們以0號warp為例。在第一次迭代中,0號線程需要去加載 shared memory 的0號和1號地址,然后寫回0號地址。此時,0號 warp 的16號線程需要加載 shared memory 的32和33號地址并且寫回32號地址。所以,我們在一個warp內(nèi)同時訪問了一個bank的不同內(nèi)存地址,發(fā)生了2路的 Bank Conflict,如上圖所示。類似地,在第二次迭代過程中,0號warp的0號線程會加載0號和2號地址并寫回0號地址,然后0號warp的8號線程需要加載 shared memory 的32號和34號地址(2*2*8=32, 32+2=34)并寫回32號線程,16號線程會加載64號和68號地址,24號線程會加載96號和100號地址。然后0,32,64,96號地址都在一個bank中,所以這里產(chǎn)生了4路的 Bank Conflict 。以此類推,下一次迭代會產(chǎn)生8路的 Bank Conflict,使得整個 Kernel 一直受到 Bank Conflict 的影響。
接下來PPT為我們指出了避免Bank Conflict的方案,那就是把循環(huán)迭代的順序修改一下:
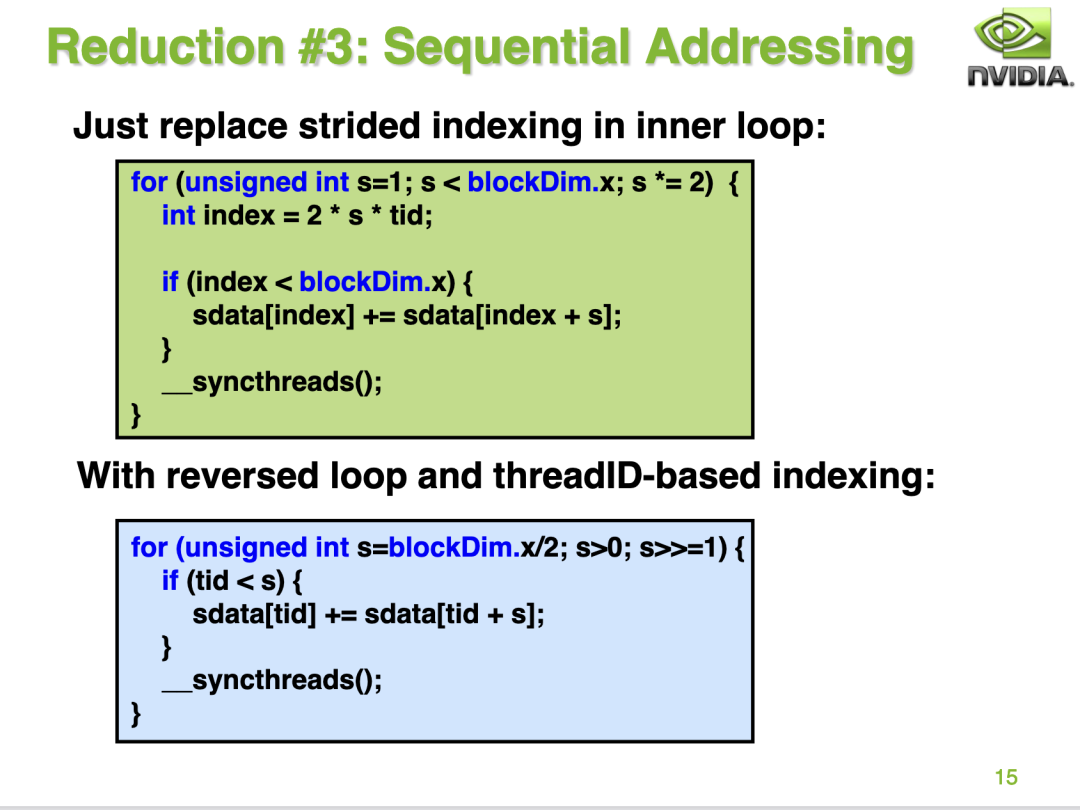
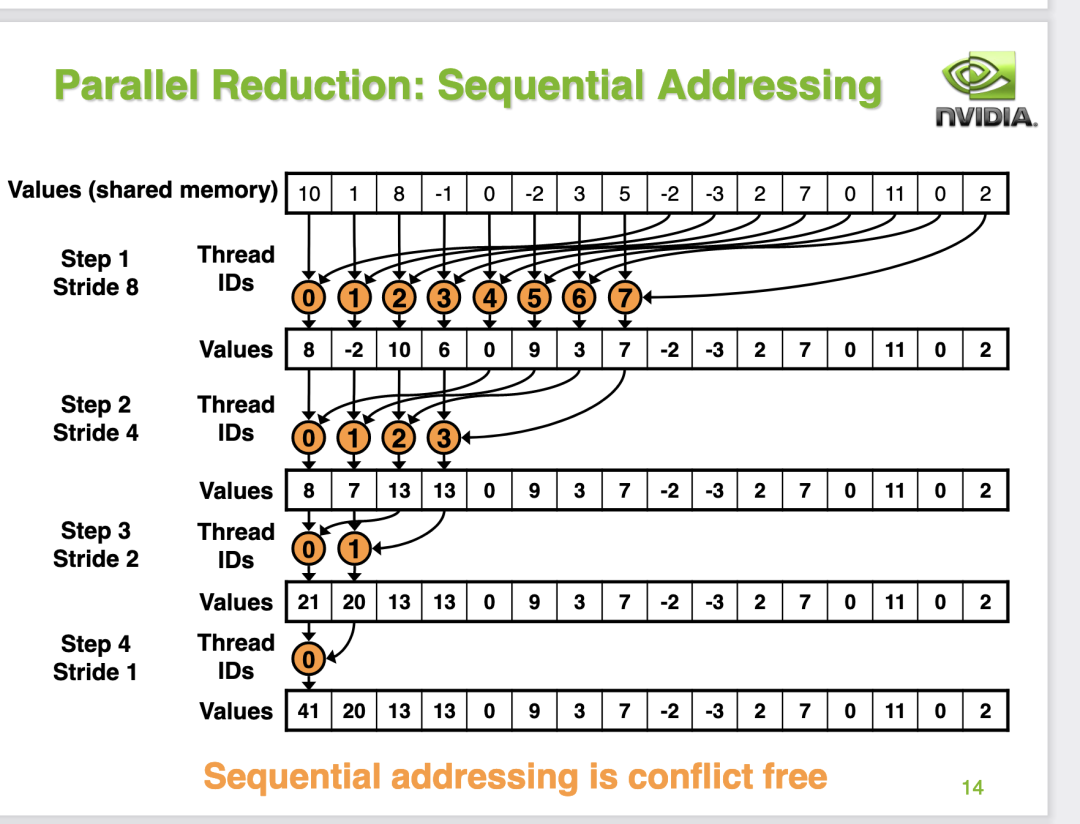
為啥這樣就可以避免Bank Conflict呢?我們繼續(xù)分析一下0號wap的線程,首先在第一輪迭代中,0號線程現(xiàn)在需要加載0號以及128號地址,并且寫回0號地址。而1號線程需要加載1號和129號地址并寫回1號地址。2號線程需要加載2號和130號地址并寫回2號地址。我們可以發(fā)現(xiàn)第0個warp的線程在第一輪迭代中剛好加載shared memory的一行數(shù)據(jù),不會產(chǎn)生 bank conflict。接下來對于第2次迭代,0號warp仍然也是剛好加載shared memory的一行數(shù)據(jù),不會產(chǎn)生 bank conflict 。對于第三次迭代,也是這樣。而對于第4次迭代,0號線程load shared memory 0號和16號地址,而這個時候16號線程什么都不干被跳過了,因為s=16,16-31號線程不滿足if的條件。整體過程如PPT的14頁:
接下來我們修改下代碼再profile一下:
#define N 32*1024*1024
#define BLOCK_SIZE 256
__global__ void reduce_v2(float *g_idata,float *g_odata){
__shared__ float sdata[BLOCK_SIZE];
// each thread loads one element from global to shared mem
unsigned int tid = threadIdx.x;
unsigned int i = blockIdx.x*blockDim.x + threadIdx.x;
sdata[tid] = g_idata[i];
__syncthreads();
// do reduction in shared mem
for(unsigned int s=blockDim.x/2; s>0; s >>= 1) {
if (tid < s){
sdata[tid] += sdata[tid + s];
}
__syncthreads();
}
// write result for this block to global mem
if (tid == 0) g_odata[blockIdx.x] = sdata[0];
}
性能和帶寬的測試情況如下:
| 優(yōu)化手段 | 耗時(us) | 帶寬利用率 | 加速比 |
|---|---|---|---|
| reduce_baseline | 990.66us | 39.57% | ~ |
| reduce_v1_interleaved_addressing | 479.58us | 81.74% | 2.06 |
| reduce_v2_bank_conflict_free | 462.02us | 84.81% | 2.144 |
可以看到相比于優(yōu)化版本1性能和帶寬又提升了一些。
優(yōu)化手段3: 解決 Idle 線程
接下來PPT 17指出,reduce_v2_bank_conflict_free 的 kernel 浪費了大量的線程。對于第一輪迭代只有128個線程在工作,而第二輪迭代只有64個線程工作,第三輪迭代只有32和線程工作,以此類推,在每一輪迭代中都有大量的線程是空閑的。

那么可以如何避免這種情況呢?PPT 18給了一個解決方法:

這里的意思就是我們讓每一輪迭代的空閑的線程也強行做一點工作,除了從global memory中取數(shù)之外再額外做一次加法。但需要注意的是,為了實現(xiàn)這個我們需要把block的數(shù)量調(diào)成之前的一半,因為這個Kernel現(xiàn)在每次需要管512個元素了。我們繼續(xù)組織下代碼并profile一下:
#define N 32*1024*1024
#define BLOCK_SIZE 256
__global__ void reduce_v3(float *g_idata,float *g_odata){
__shared__ float sdata[BLOCK_SIZE];
// each thread loads one element from global to shared mem
unsigned int tid = threadIdx.x;
unsigned int i = blockIdx.x*(blockDim.x*2) + threadIdx.x;
sdata[tid] = g_idata[i] + g_idata[i + blockDim.x];
__syncthreads();
// do reduction in shared mem
for(unsigned int s=blockDim.x/2; s>0; s >>= 1) {
if (tid < s){
sdata[tid] += sdata[tid + s];
}
__syncthreads();
}
// write result for this block to global mem
if (tid == 0) g_odata[blockIdx.x] = sdata[0];
}
性能和帶寬的測試情況如下:
| 優(yōu)化手段 | 耗時(us) | 帶寬利用率 | 加速比 |
|---|---|---|---|
| reduce_baseline | 990.66us | 39.57% | ~ |
| reduce_v1_interleaved_addressing | 479.58us | 81.74% | 2.06 |
| reduce_v2_bank_conflict_free | 462.02us | 84.81% | 2.144 |
| reduce_v3_idle_threads_free | 244.16us | 83.16% | 4.057 |
優(yōu)化手段4: 展開最后一個warp
首先來看 PPT 的第20頁:

這里的意思是,對于 reduce_v3_idle_threads_free 這個 kernel 來說,它的帶寬相比于理論帶寬還差得比較遠,因為 Reduce 操作并不是算術(shù)密集型的算子。因此,一個可能的瓶頸是指令的開銷。這里說的指令不是加載,存儲或者給計算核心用的輔算術(shù)指令。換句話說,這里的指令就是指地址算術(shù)指令和循環(huán)的開銷。
接下來 PPT 21指出了減少指令開銷的優(yōu)化方法:

這里的意思是當reduce_v3_idle_threads_free kernel里面的s<=32時,此時的block中只有一個warp0在干活時,但線程還在進行同步操作。這一條語句造成了極大的指令浪費。由于一個warp的32個線程都是在同一個simd單元上,天然保持了同步的狀態(tài),所以當s<=32時,也即只有一個warp在工作時,完全可以把__syncthreads()這條同步語句去掉,使用手動展開的方式來代替。具體做法就是:

注意 這里的warpReduce函數(shù)的參數(shù)使用了一個volatile修飾符號,volatile的中文意思是“易變的,不穩(wěn)定的”,對于用volatile修飾的變量,編譯器對訪問該變量的代碼不再優(yōu)化,總是從它所在的內(nèi)存讀取數(shù)據(jù)。對于這個例子,如果不使用volatile,對于一個線程來說(假設(shè)線程ID就是tid),它的s_data[tid]可能會被緩存在寄存器里面,且在某個時刻寄存器和shared memory里面s_data[tid]的數(shù)值還是不同的。當另外一個線程讀取s_data[tid]做加法的時候,也許直接就從shared memory里面讀取了舊的數(shù)值,從而導致了錯誤的結(jié)果。詳情請參考:https://stackoverflow.com/questions/21205471/cuda-in-warp-reduction-and-volatile-keyword?noredirect=1&lq=1
我們繼續(xù)整理一下代碼并profile一下:
__device__ void warpReduce(volatile float* cache, unsigned int tid){
cache[tid]+=cache[tid+32];
cache[tid]+=cache[tid+16];
cache[tid]+=cache[tid+8];
cache[tid]+=cache[tid+4];
cache[tid]+=cache[tid+2];
cache[tid]+=cache[tid+1];
}
__global__ void reduce_v4(float *g_idata,float *g_odata){
__shared__ float sdata[BLOCK_SIZE];
// each thread loads one element from global to shared mem
unsigned int tid = threadIdx.x;
unsigned int i = blockIdx.x*(blockDim.x*2) + threadIdx.x;
sdata[tid] = g_idata[i] + g_idata[i + blockDim.x];
__syncthreads();
// do reduction in shared mem
for(unsigned int s=blockDim.x/2; s>32; s >>= 1) {
if (tid < s){
sdata[tid] += sdata[tid + s];
}
__syncthreads();
}
// write result for this block to global mem
if (tid < 32) warpReduce(sdata, tid);
if (tid == 0) g_odata[blockIdx.x] = sdata[0];
}
性能和帶寬的測試情況如下:
| 優(yōu)化手段 | 耗時(us) | 帶寬利用率 | 加速比 |
|---|---|---|---|
| reduce_baseline | 990.66us | 39.57% | ~ |
| reduce_v1_interleaved_addressing | 479.58us | 81.74% | 2.06 |
| reduce_v2_bank_conflict_free | 462.02us | 84.81% | 2.144 |
| reduce_v3_idle_threads_free | 244.16us | 83.16% | 4.057 |
| reduce_v4_unroll_last_warp | 167.10us | 54.10% | 5.928 |
這個地方我目前是有疑問的,nvidia的ppt指出這個kernel會繼續(xù)提升性能和帶寬,但是在我實測的時候發(fā)現(xiàn)性能確實繼續(xù)提升了,但是帶寬的利用率卻下降了,目前想不清楚這個原因是什么?這里唯一的區(qū)別就是我使用的GPU是 A100-PCIE-40GB,而nvidia gpu上使用的gpu是 G80 GPU 。歡迎大佬評論區(qū)指點。

優(yōu)化手段5: 完全展開循環(huán)
在 reduce_v4_unroll_last_warp kernel 的基礎(chǔ)上就很難再繼續(xù)優(yōu)化了,但為了極致的性能NVIDIA的PPT上給出了對for循環(huán)進行完全展開的方案。

這種方案的實現(xiàn)如下:
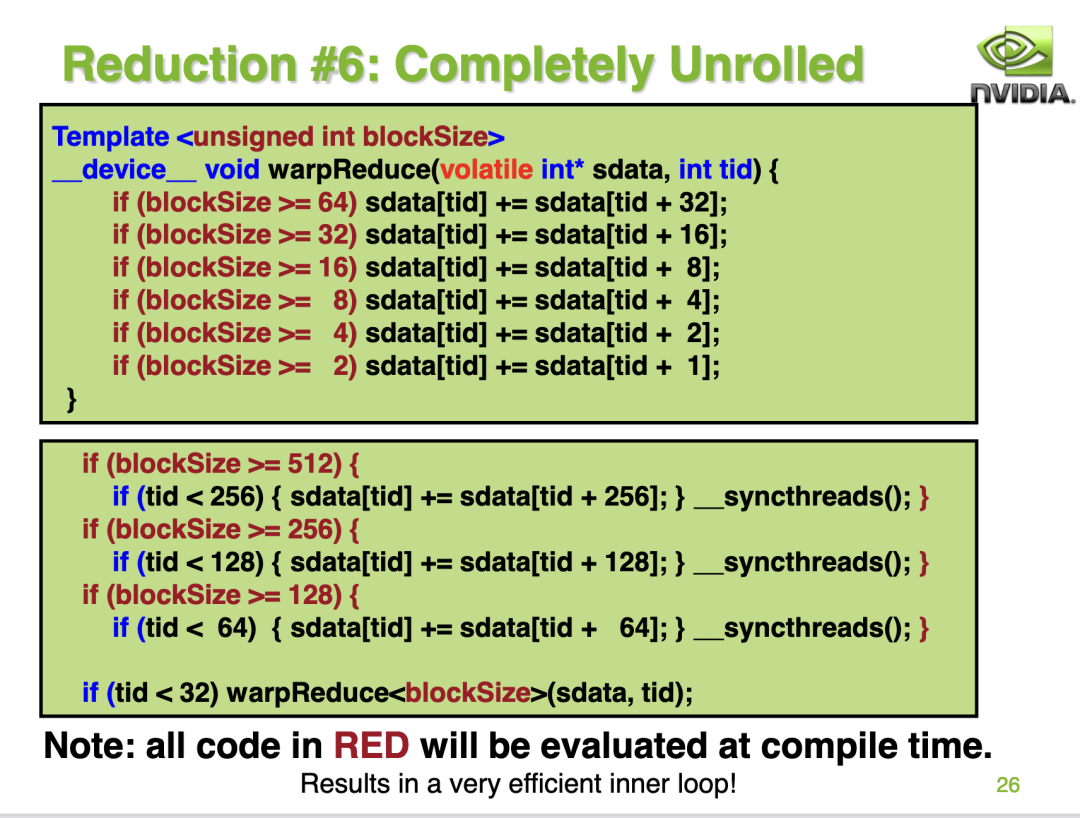
kernel的代碼實現(xiàn)如下:
template <unsigned int blockSize>
__device__ void warpReduce(volatile float* cache,int tid){
if(blockSize >= 64)cache[tid]+=cache[tid+32];
if(blockSize >= 32)cache[tid]+=cache[tid+16];
if(blockSize >= 16)cache[tid]+=cache[tid+8];
if(blockSize >= 8)cache[tid]+=cache[tid+4];
if(blockSize >= 4)cache[tid]+=cache[tid+2];
if(blockSize >= 2)cache[tid]+=cache[tid+1];
}
template <unsigned int blockSize>
__global__ void reduce_v5(float *g_idata,float *g_odata){
__shared__ float sdata[BLOCK_SIZE];
// each thread loads one element from global to shared mem
unsigned int tid = threadIdx.x;
unsigned int i = blockIdx.x*(blockDim.x*2) + threadIdx.x;
sdata[tid] = g_idata[i] + g_idata[i + blockDim.x];
__syncthreads();
// do reduction in shared mem
if(blockSize>=512){
if(tid<256){
sdata[tid]+=sdata[tid+256];
}
__syncthreads();
}
if(blockSize>=256){
if(tid<128){
sdata[tid]+=sdata[tid+128];
}
__syncthreads();
}
if(blockSize>=128){
if(tid<64){
sdata[tid]+=sdata[tid+64];
}
__syncthreads();
}
// write result for this block to global mem
if(tid<32)warpReduce<blockSize>(sdata,tid);
if (tid == 0) g_odata[blockIdx.x] = sdata[0];
}
性能和帶寬的測試情況如下:
| 優(yōu)化手段 | 耗時(us) | 帶寬利用率 | 加速比 |
|---|---|---|---|
| reduce_baseline | 990.66us | 39.57% | ~ |
| reduce_v1_interleaved_addressing | 479.58us | 81.74% | 2.06 |
| reduce_v2_bank_conflict_free | 462.02us | 84.81% | 2.144 |
| reduce_v3_idle_threads_free | 244.16us | 83.16% | 4.057 |
| reduce_v4_unroll_last_warp | 167.10us | 54.10% | 5.928 |
| reduce_v5_completely_unroll | 158.78us | 56.94% | 6.239 |
優(yōu)化手段6: 調(diào)節(jié)BlockSize和GridSize
PPT的第31頁為我們展示了最后一個優(yōu)化技巧:

這里的意思就是我們還可以通過調(diào)整GridSize和BlockSize的方式獲得更好的性能收益,也就是說一個線程負責更多的元素計算。對應(yīng)到代碼的修改就是:

這里再貼一下kernel的代碼:
template <unsigned int blockSize>
__device__ void warpReduce(volatile float* cache,int tid){
if(blockSize >= 64)cache[tid]+=cache[tid+32];
if(blockSize >= 32)cache[tid]+=cache[tid+16];
if(blockSize >= 16)cache[tid]+=cache[tid+8];
if(blockSize >= 8)cache[tid]+=cache[tid+4];
if(blockSize >= 4)cache[tid]+=cache[tid+2];
if(blockSize >= 2)cache[tid]+=cache[tid+1];
}
template <unsigned int blockSize, int NUM_PER_THREAD>
__global__ void reduce_v6(float *g_idata,float *g_odata){
__shared__ float sdata[BLOCK_SIZE];
// each thread loads one element from global to shared mem
unsigned int tid = threadIdx.x;
unsigned int i = blockIdx.x*(blockDim.x * NUM_PER_THREAD) + threadIdx.x;
sdata[tid] = 0;
#pragma unroll
for(int iter=0; iter<NUM_PER_THREAD; iter++){
sdata[tid] += g_idata[i+iter*blockSize];
}
__syncthreads();
// do reduction in shared mem
if(blockSize>=512){
if(tid<256){
sdata[tid]+=sdata[tid+256];
}
__syncthreads();
}
if(blockSize>=256){
if(tid<128){
sdata[tid]+=sdata[tid+128];
}
__syncthreads();
}
if(blockSize>=128){
if(tid<64){
sdata[tid]+=sdata[tid+64];
}
__syncthreads();
}
// write result for this block to global mem
if(tid<32)warpReduce<blockSize>(sdata,tid);
if (tid == 0) g_odata[blockIdx.x] = sdata[0];
}
int main() {
float *input_host = (float*)malloc(N*sizeof(float));
float *input_device;
cudaMalloc((void **)&input_device, N*sizeof(float));
for (int i = 0; i < N; i++) input_host[i] = 2.0;
cudaMemcpy(input_device, input_host, N*sizeof(float), cudaMemcpyHostToDevice);
const int block_num = 1024;
const int NUM_PER_BLOCK = N / block_num;
const int NUM_PER_THREAD = NUM_PER_BLOCK / BLOCK_SIZE;
float *output_host = (float*)malloc((block_num) * sizeof(float));
float *output_device;
cudaMalloc((void **)&output_device, (block_num) * sizeof(float));
dim3 grid(block_num, 1);
dim3 block(BLOCK_SIZE, 1);
reduce_v6<BLOCK_SIZE ,NUM_PER_THREAD><<<grid, block>>>(input_device, output_device);
cudaMemcpy(output_device, output_host, block_num * sizeof(float), cudaMemcpyDeviceToHost);
return 0;
}
profile結(jié)果:
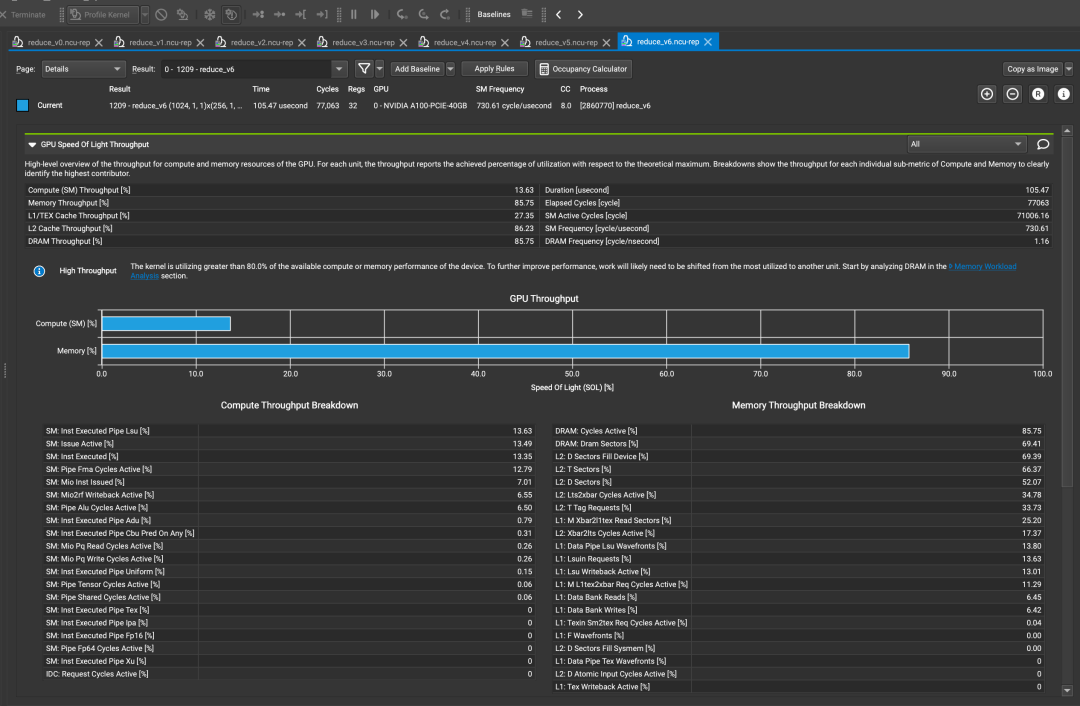
性能和帶寬的測試情況如下:
| 優(yōu)化手段 | 耗時(us) | 帶寬利用率 | 加速比 |
|---|---|---|---|
| reduce_baseline | 990.66us | 39.57% | ~ |
| reduce_v1_interleaved_addressing | 479.58us | 81.74% | 2.06 |
| reduce_v2_bank_conflict_free | 462.02us | 84.81% | 2.144 |
| reduce_v3_idle_threads_free | 244.16us | 83.16% | 4.057 |
| reduce_v4_unroll_last_warp | 167.10us | 54.10% | 5.928 |
| reduce_v5_completely_unroll | 158.78us | 56.94% | 6.239 |
| reduce_v6_multi_add | 105.47us | 85.75% | 9.392 |
在把block_num從65536調(diào)整到1024之后,無論是性能還是帶寬都達到了最強,相比于最初的BaseLine加速了9.4倍。
總結(jié)
我這里的測試結(jié)果和nvidia ppt里提供的結(jié)果有一些出入,nvidia ppt的34頁展示的結(jié)果是對于每一種優(yōu)化相比于前一種無論是性能還是帶寬都是穩(wěn)步提升的。但我這里的測試結(jié)果不完全是這樣,對于 reduce_v4_unroll_last_warp 和 reduce_v5_completely_unroll 這兩個優(yōu)化,雖然耗時近一步減少但是帶寬卻降低了,我也還沒想清楚原因。歡迎大佬評論區(qū)指點。
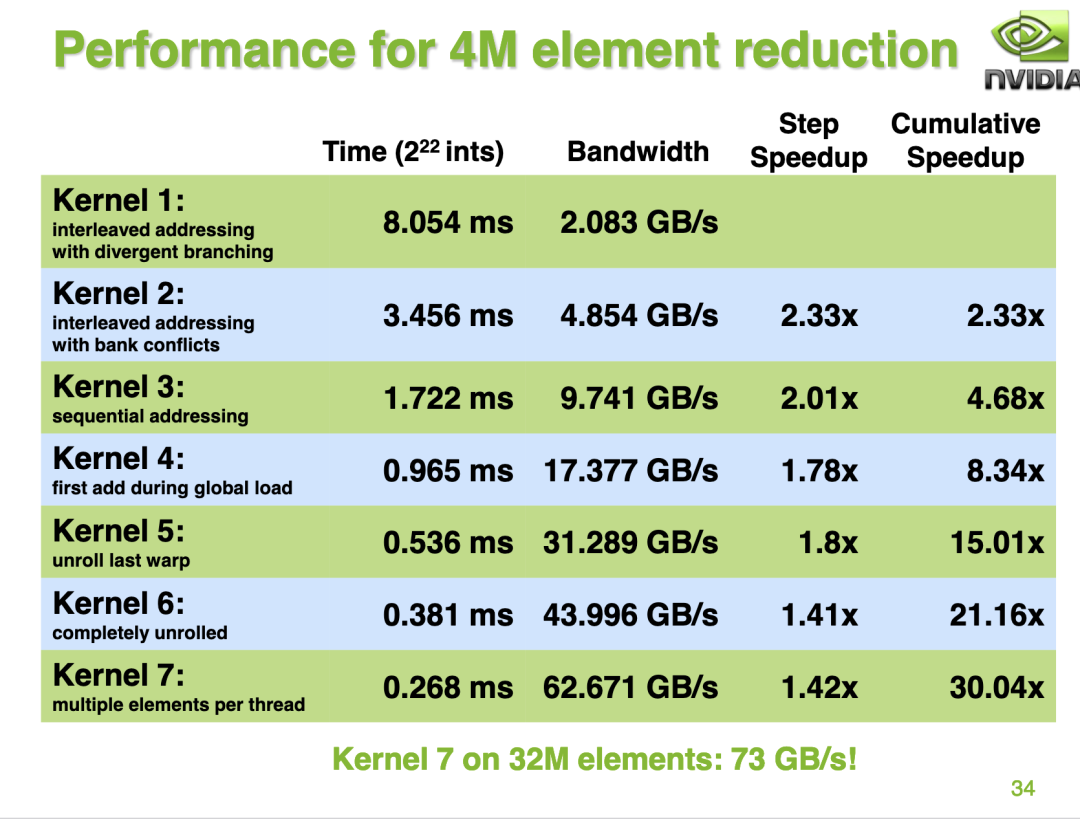
并且最終的Kernel帶寬利用率為 73 / 86.4 = 84.5% ,和我在A100上的reduce_v6_multi_add kernel的測試結(jié)果基本相當。
后續(xù)我再換個gpu試一試,把數(shù)據(jù)同步到這里:https://github.com/BBuf/how-to-optim-algorithm-in-cuda/blob/master/reduce/README.md
參考
https://developer.download.nvidia.com/assets/cuda/files/reduction.pdf https://zhuanlan.zhihu.com/p/426978026 https://mp.weixin.qq.com/s/1_ao9xM6Qk3JaavptChXew