
實操教程|CUDA WarpReduce 學(xué)習(xí)筆記

極市導(dǎo)讀
?CUDA 編程進(jìn)階分享,希望這篇博客能幫助讀者理解到一些 warp 的使用。?>>加入極市CV技術(shù)交流群,走在計算機(jī)視覺的最前沿
前言
之前看我司的 如何實現(xiàn)一個高效的Softmax CUDA kernel?多少還是有些細(xì)節(jié)沒有理解,恰好最近要做一個類似的 Reduce+Scale Kernel,原理機(jī)制還是比較相似的,所以翻出來重新理解一下。
背景
我們定義這么一個ReduceScale操作:假設(shè)Tensor是(N, C),首先在C這個維度計算出 absMax 值,我們記作scale,然后將每一行除以各自 行的scale,并最終輸出。一段樸素的numpy代碼是這樣:
import?numpy?as?np??
??
??
N?=?1000??
C?=?128??
x?=?np.random.randn(N,?C)??
scale?=?np.expand_dims(np.max(np.abs(x),?axis=1),?1)??
out?=?x?/?scale??
print(out.shape)??
BaseLine
這里我們BaseLine是直接調(diào)用cub庫中的 BlockReduce,一個 threadBlock 處理一行數(shù)據(jù),計算出AbsMaxVal,然后再縮放,代碼如下:
#include?"cuda.h"??
#include?"cub/cub.cuh"??
??
constexpr?int?kReduceBlockSize?=?128;??
??
template??
__device__?T?abs_func(const?T&?a)?{??
??return?abs(a);??
}??
??
??
template??
__device__?T?max_func(const?T?a,?const?T?b)?{??
??return?a?>?b???a?:?b;??
}??
??
template??
struct?AbsMaxOp?{??
??__device__?__forceinline__?T?operator()(const?T&?a,?const?T&?b)?const?{??
????return?max_func(abs_func(a),?abs_func(b));??
??}??
};??
??
template??
__inline__?__device__?T?BlockAllReduceAbsMax(T?val)?{??
??typedef?cub::BlockReduce?BlockReduce;??
??__shared__?typename?BlockReduce::TempStorage?temp_storage;??
??__shared__?T?final_result;??
??T?result?=?BlockReduce(temp_storage).Reduce(val,?AbsMaxOp());??
??if?(threadIdx.x?==?0)?{?final_result?=?result;?}??
??__syncthreads();??
??return?final_result;??
}??
??
template??
__global__?void?ReduceScaleBlockKernel(T*?x,?IDX?row_size,?IDX?col_size)?{??
??for(int32_t?row?=?blockIdx.x,?step=gridDim.x;?row?????T?thread_scale_factor?=?0.0;???
????for(int32_t?col=threadIdx.x;?col???????IDX?idx?=?row?*?col_size?+?col;???
??????T?x_val?=?x[idx];??
??????thread_scale_factor?=?max_func(thread_scale_factor,?abs_func(x_val));???
????}??
????T?row_scale_factor?=?BlockAllReduceAbsMax(thread_scale_factor);???
????for(int32_t?col=threadIdx.x;?col???????IDX?idx?=?row?*?col_size?+?col;???
??????x[idx]?/=?row_scale_factor;??
????}??
??}??
}??
參數(shù)中 x 是輸入數(shù)據(jù),row_size是行的數(shù)量,col_size是列的大小測試機(jī)器是在 A100 40GB,為了讓結(jié)果區(qū)別比較明顯,我們將行數(shù)設(shè)置的比較大,輸入形狀為(55296*8, 128),啟動的線程塊數(shù)目根據(jù) 如何設(shè)置CUDA Kernel中的grid_size和block_size?這篇文章來指定,這里比較粗暴的設(shè)置為(55296, 128),數(shù)據(jù)類型為 Float,然后我們看下ncu的結(jié)果:
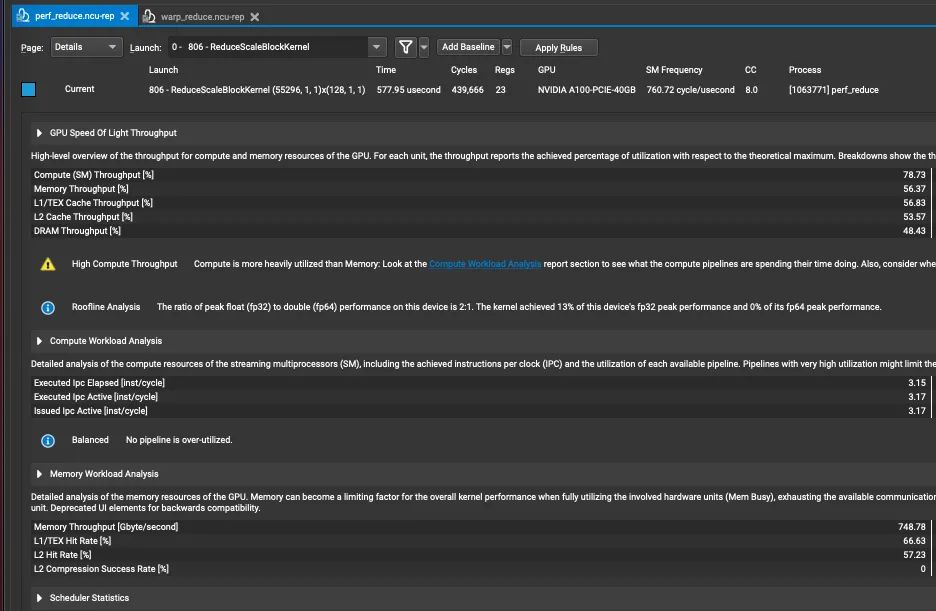
主要有這幾個指標(biāo),耗時為577.95us,吞吐量為 748.78Gb/s下面我們就根據(jù) Softmax 優(yōu)化那篇文章所提及的點來逐步分析:
優(yōu)化1 數(shù)據(jù)Pack
在之前的 高效、易用、可拓展我全都要:OneFlow CUDA Elementwise 模板庫的設(shè)計優(yōu)化思路 里很詳細(xì)的描述了如何做向量化讀寫,cuda里最大支持 128bit的讀寫,那么在數(shù)據(jù)類型為 Float 時,我們即可以將連續(xù)的4個 Float 打包到一起,一次性讀寫,提升吞吐。有了解過這方面的讀者應(yīng)該就反應(yīng)過來,誒 CUDA 里 不是剛好有一個類型叫 float4 就是干這件事的么,沒錯,但是為了更靈活的支持其他數(shù)據(jù)類型的向量化,我們利用union共享空間的特性實現(xiàn)了一個 Pack 類:
template??
struct?GetPackType?{??
??using?type?=?typename?std::aligned_storage::type;??
};??
??
template??
using?PackType?=?typename?GetPackType::type;??
??
template??
union?Pack?{??
??static_assert(sizeof(PackType)?==?sizeof(T)?*?N,?"");??
??__device__?Pack()?{??
????//?do?nothing??
??}??
??PackType?storage;??
??T?elem[N];??
};??
優(yōu)化2 數(shù)據(jù)緩存
整個算子邏輯是需要讀取一遍數(shù)據(jù),計算scale,然后再讀取一遍數(shù)據(jù),用scale進(jìn)行縮放。很顯然這里我們讀取了兩遍數(shù)據(jù),而數(shù)據(jù)是放在 Global Memory,帶寬比較低,會帶來讀取耗時。


一個很自然的想法是緩存到寄存器/Shared Memory中。由于這里我們只實現(xiàn) WarpReduce 版本,所以我們是緩存到寄存器(其他版本可以參考開頭的優(yōu)化 Softmax 文章)中,減少一次對 Global Memory 的讀取。
template??
__global__?void?ReduceScaleWarpKernel(T*?x,?IDX?row_size,?IDX?col_size)?{??
????//?...??
????T?buf[cols_per_thread];??
????//?...??
優(yōu)化3 使用Warp處理一行數(shù)據(jù)
相較 BaseLine,我們這里使用 warp 作為 Reduce 的單位進(jìn)行操作,首先我們簡單看下 WarpReduce 的實現(xiàn)。
template??
struct?AbsMaxOp?{??
??__device__?__forceinline__?T?operator()(const?T&?a,?const?T&?b)?const?{??
????return?max_func(abs_func(a),?abs_func(b));??
??}??
};??
??
template??
__inline__?__device__?T?WarpAbsMaxAllReduce(T?val){??
????for(int?lane_mask?=?kWarpSize/2;?lane_mask?>?0;?lane_mask?/=?2){??
????????val?=?AbsMaxOp()(val,?__shfl_xor_sync(0xffffffff,?val,?lane_mask));???
????}??
????return?val;???
}??
這段代碼在別的 BlockReduce 也經(jīng)常看到,他是借助 __shfl_xor_sync 來實現(xiàn)比較,shuffle 指令允許同一線程束的兩個線程直接讀取對方的寄存器。
T?__shfl_xor_sync(unsigned?mask,?T?var,?int?laneMask,?int?width=warpSize);??
其中 mask 是對線程的一個掩碼,我們一般所有線程都要參與計算,所以 mask 是 0xffffffffvar 則是寄存器值,laneMask 則是用來做按位異或的掩碼
這里引入一個概念叫 Lane,它表示線程束中的第幾號線程
示意圖如下:
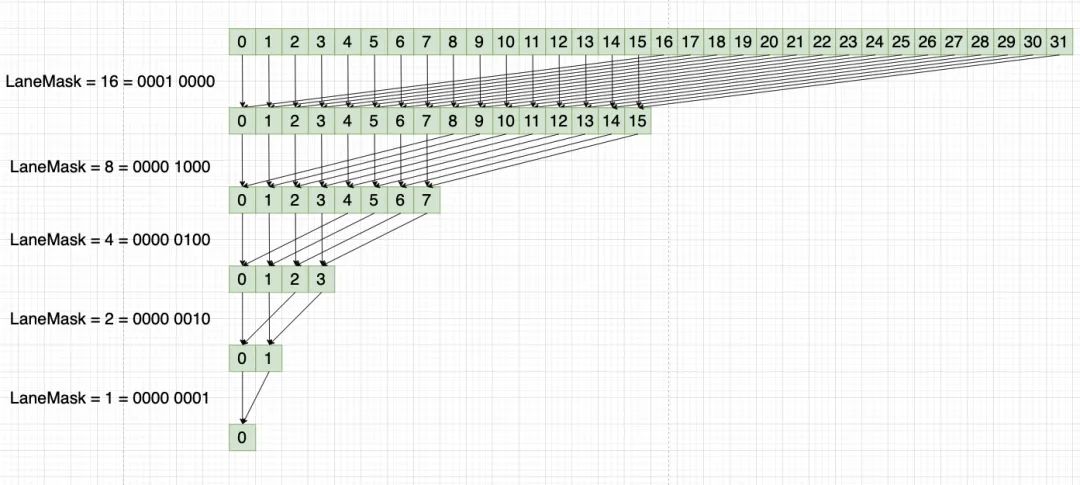
當(dāng) laneMask = 16 時,其二進(jìn)制為 0001 0000,然后線程束每個線程與 laneMask 做異或操作如:
0000 0000 xor 0001 0000 = 0001 0000 = 16 0000 0001 xor 0001 0000 = 0001 0001 = 17 0000 0010 xor 0001 0000 = 0001 0010 = 18
以此類推,最終得到一個 Warp 中的 absmax 值。接下來我們開始寫Kernel,模板參數(shù)分別為:
T 數(shù)據(jù)類型 IDX 索引類型 pack_size pack數(shù),比如float可以pack成4個,那對應(yīng)pack_size=4 cols_per_thread 每個線程需要處理的元素個數(shù),比如一行大小是128,而我們一個warp有32個線程,那么這里就是128/32 = 4
template??
__global__?void?ReduceScaleWarpKernel(T*?x,?IDX?row_size,?IDX?col_size)?{??
????//?...??????
}??
跟BaseLine一樣,我們block大小還是設(shè)置為128個線程,一個warp是32個線程,所以我們一個block可以組織成(32, 4),包含4個warp。
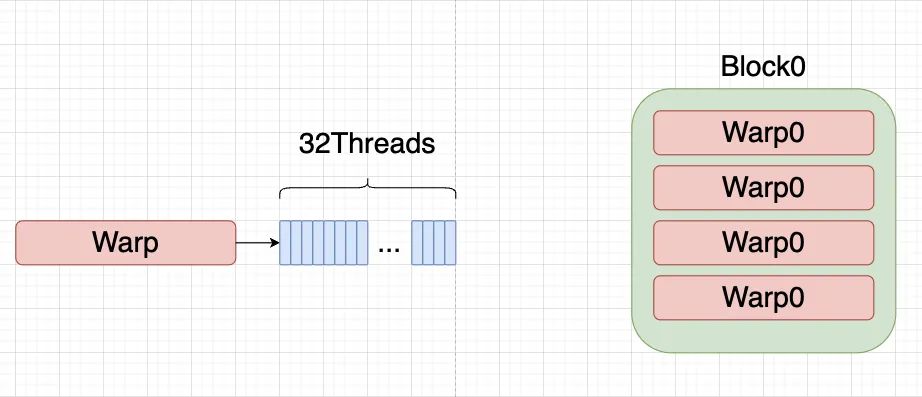
根據(jù)這個層級劃分,我們可以計算出:
global_thread_group_id 當(dāng)前warp的全局index num_total_thread_group warp的總數(shù)量 lane_id 線程束內(nèi)的線程id num_packs pack的數(shù)目,即每個線程需要處理的元素個數(shù) / pack_size
const?int32_t?global_thread_group_id?=?blockIdx.x?*?blockDim.y?+?threadIdx.y;???
????const?int32_t?num_total_thread_group?=?gridDim.x?*?blockDim.y;???
????const?int32_t?lane_id?=?threadIdx.x;???
????using?LoadStoreType?=?PackType;??
????using?LoadStorePack?=?Pack;??
????T?buf[cols_per_thread];???
????constexpr?int?num_packs?=?cols_per_thread?/?pack_size;??
由于存在啟動的warp的數(shù)量小于行的數(shù)量,所以我們要引入一個 for 循環(huán)。假設(shè)我們 cols = 256,那么線程束里的每個線程需要處理 256 /32 = 8個元素,而4個float可以pack到一起,所以我們線程束里的每個線程要處理2個pack,因此也要引入一個關(guān)于 num_packs 的 for 循環(huán),以保證整一行都有被讀取到:
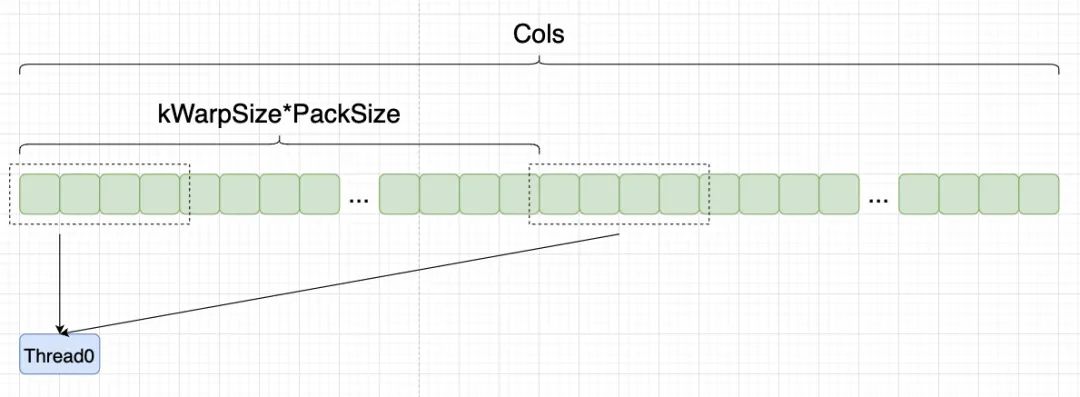
一次性讀取到一個 pack 后,我們再一個個放到寄存器當(dāng)中緩存起來,并計算線程上的 AbsMaxVal。
for(IDX?row_idx?=?global_thread_group_id;?row_idx?????????T?thread_abs_max_val?=?0.0;???
????????for(int?pack_idx?=?0;?pack_idx?????????????const?int32_t?pack_offset?=?pack_idx?*?pack_size;???
????????????const?int32_t?col_offset?=?pack_idx?*?kWarpSize?*?pack_size?+?lane_id?*?pack_size;???
????????????const?int32_t?load_offset?=?(row_idx?*?col_size?+?col_offset)?/?pack_size;???
????????????LoadStorePack?load_pack;???
????????????load_pack.storage?=?*(reinterpret_cast(x)+?load_offset);???
????????????#pragma?unroll???
????????????for(int?i?=?0;?i?????????????????buf[pack_offset]?=?load_pack.elem[i];???
????????????????thread_abs_max_val?=?max_func(thread_abs_max_val,?abs_func(buf[pack_offset]));??
????????????}???
????????}??
接著我們調(diào)用 WarpAbsMaxAllReduce 進(jìn)行reduce,獲得線程束中的 AbsMaxVal,并對緩存的數(shù)據(jù)進(jìn)行數(shù)值縮放。
T?warp_max_val?=?WarpAbsMaxAllReduce(thread_abs_max_val);???
????????#pragma?unroll??
????????for?(int?col?=?0;?col?????????????buf[col]?=?buf[col]?/?warp_max_val;??
????????}??
最后跟一開始讀取類似,我們將寄存器里的值再寫回去,相關(guān)索引的計算邏輯都是一致的:
for(int?pack_idx?=?0;?pack_idx?????????????const?int32_t?pack_offset?=?pack_idx?*?pack_size;???
????????????const?int32_t?col_offset?=?pack_idx?*?pack_size?*?kWarpSize?+?lane_id?*?pack_size;???
????????????const?int32_t?store_offset?=?(row_idx?*?col_size?+?col_offset)?/?pack_size;???
????????????LoadStorePack?store_pack;???
????????????#pragma?unroll???
????????????for(int?i?=?0;?i?????????????????store_pack.elem[i]?=?buf[pack_offset?+?i];???
????????????}???
????????????*(reinterpret_cast(x)+?store_offset)?=?store_pack.storage;???
????????}??
完整代碼如下:
template??
__inline__?__device__?T?WarpAbsMaxAllReduce(T?val){??
????for(int?lane_mask?=?kWarpSize/2;?lane_mask?>?0;?lane_mask?/=?2){??
????????val?=?AbsMaxOp()(val,?__shfl_xor_sync(0xffffffff,?val,?lane_mask));???
????}??
????return?val;???
}??
??
template??
__global__?void?ReduceScaleWarpKernel(T*?x,?IDX?row_size,?IDX?col_size)?{??
????const?int32_t?global_thread_group_id?=?blockIdx.x?*?blockDim.y?+?threadIdx.y;???
????const?int32_t?num_total_thread_group?=?gridDim.x?*?blockDim.y;???
????const?int32_t?lane_id?=?threadIdx.x;???
????using?LoadStoreType?=?PackType;??
????using?LoadStorePack?=?Pack;??
????T?buf[cols_per_thread];???
????constexpr?int?num_packs?=?cols_per_thread?/?pack_size;??
????for(IDX?row_idx?=?global_thread_group_id;?row_idx?????????T?thread_abs_max_val?=?0.0;???
????????for(int?pack_idx?=?0;?pack_idx?????????????const?int32_t?pack_offset?=?pack_idx?*?pack_size;???
????????????const?int32_t?col_offset?=?pack_idx?*?kWarpSize?*?pack_size?+?lane_id?*?pack_size;???
????????????const?int32_t?load_offset?=?(row_idx?*?col_size?+?col_offset)?/?pack_size;???
????????????LoadStorePack?load_pack;???
????????????load_pack.storage?=?*(reinterpret_cast(x)+?load_offset);???
????????????#pragma?unroll???
????????????for(int?i?=?0;?i?????????????????buf[pack_offset]?=?load_pack.elem[i];???
????????????????thread_abs_max_val?=?max_func(thread_abs_max_val,?abs_func(buf[pack_offset]));??
????????????}???
????????}??
????????T?warp_max_val?=?WarpAbsMaxAllReduce(thread_abs_max_val);???
????????#pragma?unroll??
????????for?(int?col?=?0;?col?????????????buf[col]?=?buf[col]?/?warp_max_val;??
????????}??
????????for(int?pack_idx?=?0;?pack_idx?????????????const?int32_t?pack_offset?=?pack_idx?*?pack_size;???
????????????const?int32_t?col_offset?=?pack_idx?*?pack_size?*?kWarpSize?+?lane_id?*?pack_size;???
????????????const?int32_t?store_offset?=?(row_idx?*?col_size?+?col_offset)?/?pack_size;???
????????????LoadStorePack?store_pack;???
????????????#pragma?unroll???
????????????for(int?i?=?0;?i?????????????????store_pack.elem[i]?=?buf[pack_offset?+?i];???
????????????}???
????????????*(reinterpret_cast(x)+?store_offset)?=?store_pack.storage;???
????????}??
????}??
}??
這里我們方便測試,調(diào)用的時候就直接寫死一些模板參數(shù)
constexpr?int?cols_per_thread?=?128?/?kWarpSize;???
ReduceScaleWarpKernel<float,?int32_t,?4,?cols_per_thread><<<55296,?block_dim>>>(device_ptr,?row_size,?col_size);??
最后我們看一下 ncu 的結(jié)果:
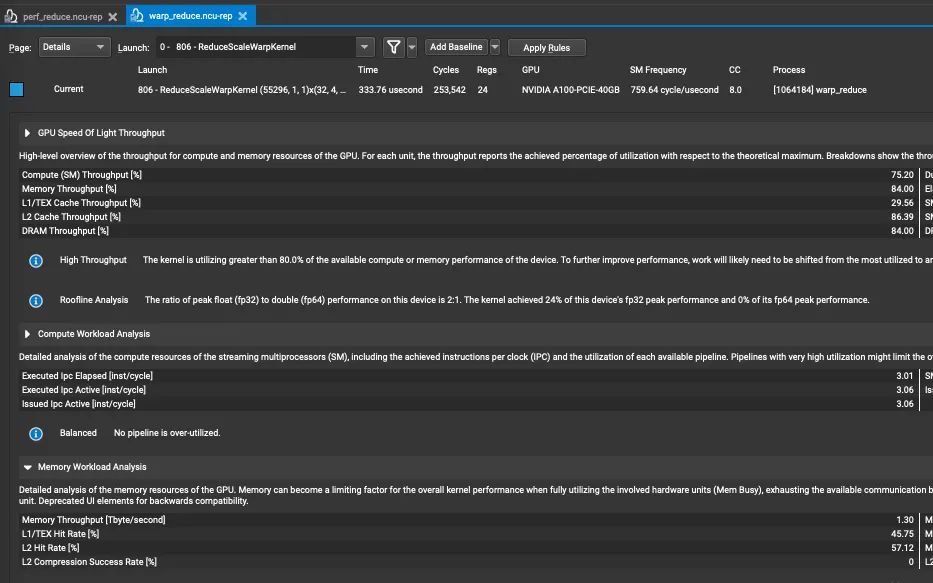
吞吐量達(dá)到了1.3T,時間位333us,相比 BaseLine 快了 73 %。
總結(jié)
還有更多特殊情況可以參考 Softmax 優(yōu)化的代碼,這里僅實現(xiàn)了第一個 Warp 計算方式。我感覺看著還行,真自己寫起來理解還是有點困難的,希望這篇博客能幫助讀者理解到一些 warp 的使用。
公眾號后臺回復(fù)“畫圖模板”獲取90+深度學(xué)習(xí)畫圖模板~

#?CV技術(shù)社群邀請函?#

備注:姓名-學(xué)校/公司-研究方向-城市(如:小極-北大-目標(biāo)檢測-深圳)
即可申請加入極市目標(biāo)檢測/圖像分割/工業(yè)檢測/人臉/醫(yī)學(xué)影像/3D/SLAM/自動駕駛/超分辨率/姿態(tài)估計/ReID/GAN/圖像增強(qiáng)/OCR/視頻理解等技術(shù)交流群
每月大咖直播分享、真實項目需求對接、求職內(nèi)推、算法競賽、干貨資訊匯總、與?10000+來自港科大、北大、清華、中科院、CMU、騰訊、百度等名校名企視覺開發(fā)者互動交流~
