前所未有:用AI控制核聚變,DeepMind再登Nature

大數(shù)據(jù)文摘轉(zhuǎn)載自數(shù)據(jù)實戰(zhàn)派
毫無疑問,DeepMind 正在加速將其 AI 算法應(yīng)用于最前沿的科學問題上。
繼此前振奮業(yè)界的蛋白質(zhì)預(yù)測成果之后,今日,DeepMind 又一個硬核研究亮相,在這篇名為 Magnetic control of tokamak plasmas through deep reinforcement learning的nature 文章,DeepMind 的科學家和來自 Swiss Plasma Center - EPFL 的研究者,共同提出了一種強化學習算法,來控制托卡馬克核聚變反應(yīng)堆內(nèi)的等離子體。
這一進展將可以幫助物理學家更好地了解聚變的工作原理,并有希望加速這種“終極能源”的到來。
“在現(xiàn)實世界系統(tǒng)中最具挑戰(zhàn)性的應(yīng)用之一”
太陽源源不斷的能量來自于原子核的聚合反應(yīng),即核聚變。因此,可控核聚變技術(shù)的實驗裝置,常被稱作“人造太陽”。
但一直以來,人們希望找到有效控制和限制等離子體的方法,只有這樣這種“終極能源”才能為人類所利用。
具體到工程實現(xiàn)上,科學家們正在嘗試借助托卡馬克裝置通過使用磁場限制等離子體。
在托卡馬克裝置中,磁場線圈會限制等離子體粒子,以使等離子體達到聚變所需的條件。如下圖所示,一組磁線圈產(chǎn)生一個強烈的“環(huán)形”場,圍繞環(huán)面進行引導(dǎo)。一個中央螺線管(承載電流的磁體)產(chǎn)生一個沿“極向”方向的第二個磁場,即圍繞環(huán)面的路徑。這兩個場產(chǎn)生了一個扭曲的磁場,將粒子限制在等離子體中。此外,還會有第三組磁線圈產(chǎn)生一個外極向場,用于塑造和定位等離子體。
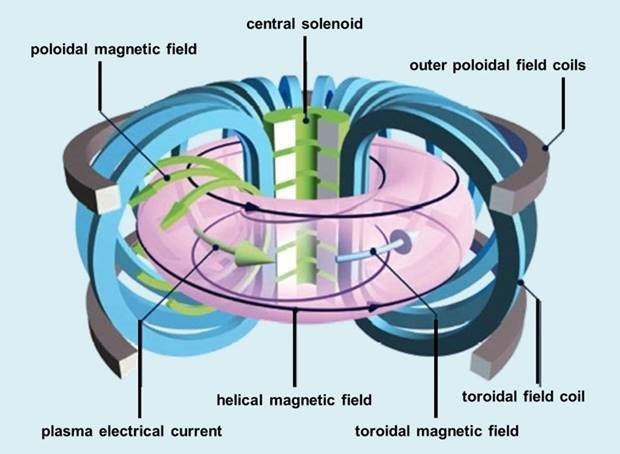
圖丨環(huán)形場線圈(藍色)、中央螺線管(綠色)和極向場線圈(灰色)。環(huán)面周圍的磁場(黑色)限制了帶電等離子體粒子的行進路徑。(來源:EUROfusion)
其中一個困難之處在于,盡管這些控制器通常很有效,但每一次研究人員想要改變等離子體的配置,并嘗試不同的形狀以產(chǎn)生更多的能量或更清潔的等離子體時,都需要基于模型和仔細的模擬,進行大量的工程和設(shè)計工作,并平衡復(fù)雜的實時計算。
在 DeepMind 的這個方案中,通過使用強化學習(RL)生成非線性反饋控制器,一種全新的等離子體控制方法成為可能。DeepMind 的研究員 Martin Riedmiller 表示:“這是強化學習在現(xiàn)實世界系統(tǒng)中最具挑戰(zhàn)性的應(yīng)用之一”。
具體方案細節(jié)
他們開發(fā)了一個深度強化學習系統(tǒng),來控制瑞士等離子體中心的可變配置托卡馬克 內(nèi)的 19 個電磁線圈,設(shè)計架構(gòu)如下圖所示: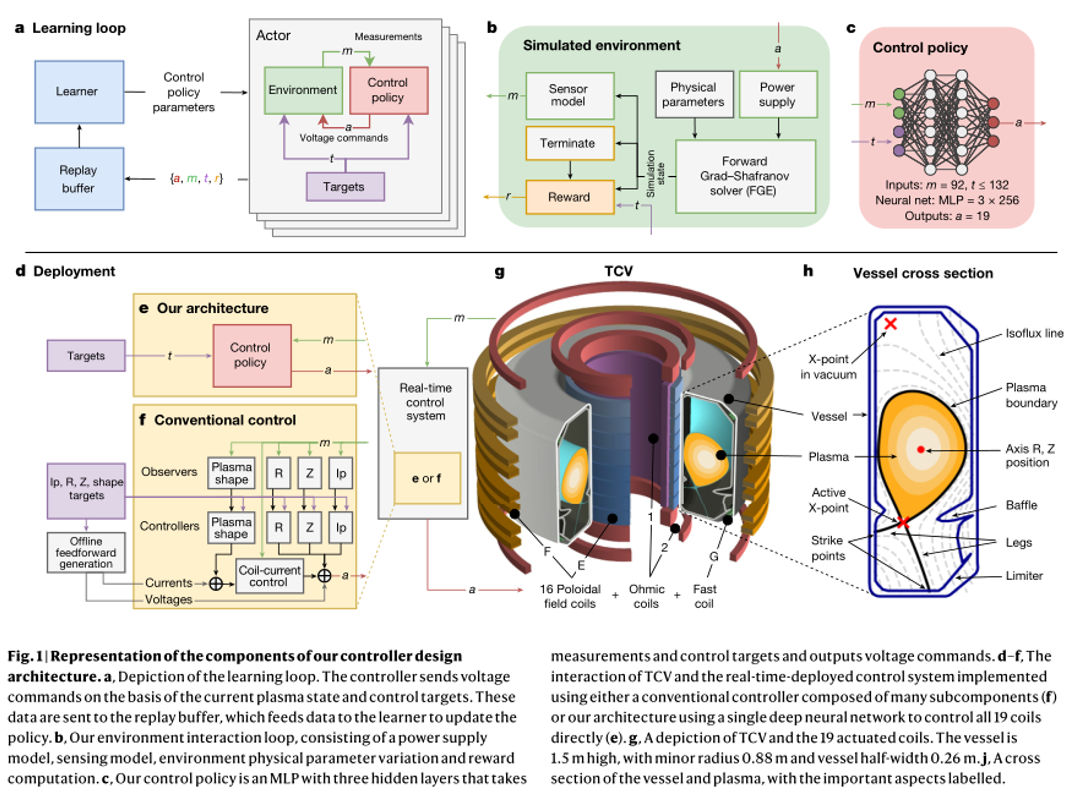
其包含以下三個主要階段:首先,設(shè)計者指定實驗?zāi)繕耍赡馨橛袝r變控制目標。其次,深度 RL 算法與 tokamak 仿真器交互,尋找接近最優(yōu)的控制策略以滿足指定的目標。第三,控制策略以神經(jīng)網(wǎng)絡(luò)的形式直接在 tokamak 硬件上實時運行。
在第一階段,實驗?zāi)繕擞梢唤M目標指定,這些目標可以包含各種各樣的期望屬性。這些屬性范圍從位置和等離子體電流的基本穩(wěn)定到多個時變目標的復(fù)雜組合,包括具有指定延伸率、三角形和 X-點位置的精確形狀輪廓。然后,將這些目標組合為一個“獎勵函數(shù)”,在每個時間步中為狀態(tài)分配標量質(zhì)量度量。這個函數(shù)還懲罰達到不是所期望的終端狀態(tài)的控制策略,如下所述。最重要的是,精心設(shè)計的獎勵函數(shù)將被最小化,以給予學習算法最大的靈活性,進而達到預(yù)期的結(jié)果。
在第二個階段,如圖 1a,b 所示,高性能 RL 算法收集數(shù)據(jù)并通過與環(huán)境交互發(fā)現(xiàn)控制策略。
研究團隊使用具有足夠保真度的仿真器來描述等離子體形狀和電流的演變,同時保持足夠低的學習計算成本。
具體而言,團隊采用了自由邊界等離子體演化模型,以模擬極場線圈電壓影響下等離子體狀態(tài)演化的動力學過程。在該模型中,線圈和無源導(dǎo)體中的電流在電源外部施加的電壓,以及其他導(dǎo)體和等離子體內(nèi)部隨時間變化的電流產(chǎn)生的感應(yīng)電壓的影響下發(fā)生變化。反過來,等離子體由 Grad-Shafranov(G-S)方程模擬。這組方程由 FGE 軟件包進行數(shù)值求解。
RL 算法利用收集到的仿真器數(shù)據(jù),針對指定的獎勵函數(shù)找到一個接近最優(yōu)的策略。
由于等離子體狀態(tài)演化的計算要求,團隊成員采用仿真器的數(shù)據(jù)速率明顯低于典型的 RL 環(huán)境。因此,研究團隊通過使用最大后驗策略優(yōu)化(MPO, maximum a posteriori policy optimization)算法,以克服數(shù)據(jù)缺乏的問題。MPO 支持跨分布式并行流的數(shù)據(jù)收集,并以數(shù)據(jù)高效的方式進行學習。
在第三階段,將控制策略與相關(guān)的實驗控制目標捆綁在一個可執(zhí)行文件中,使用專為 10 khz 實時控制而設(shè)計的編譯器,以最小化依賴并消除不必要的計算。
該可執(zhí)行文件由 TCV 控制框架加載而來(圖 1d)。每個實驗都始于標準的等離子體形成過程,在此過程中,傳統(tǒng)的控制器保持等離子體的位置和總電流。在稱為“移交”(handover)的預(yù)定時間,控制切換到團隊所采用的控制策略,然后啟動 19 個 TCV 控制線圈,將等離子體形狀和電流轉(zhuǎn)換到期望目標。實驗在訓練后不進一步調(diào)整控制策略網(wǎng)絡(luò)權(quán)重,換句話說,從仿真到硬件有“zero-shot”的轉(zhuǎn)移。
控制策略通過學習過程的幾個關(guān)鍵屬性可靠地傳遞到 TCV,如圖 1b 所示。研究團隊確定了一種執(zhí)行器和傳感器模型,該模型包含了影響控制穩(wěn)定性的特性,如延遲、測量噪聲和控制電壓偏移。團隊成員通過分析實驗數(shù)據(jù),在訓練過程中對等離子體壓力、電流密度剖面和等離子體電阻率在適當?shù)姆秶鷥?nèi)應(yīng)用了有針對性的參數(shù)變化,以解釋變化的、不受控制的實驗條件。
這在保證性能的同時,可以提供一定的健壯性。雖然仿真器通常是準確的,但在已知的一些區(qū)域性能表現(xiàn)欠佳。因此,團隊在訓練循環(huán)中建立了“學習區(qū)域回避”(learned-region avoidance),通過使用獎勵和終止條件來避免這些問題,即當遇到特定條件時,立即停止模擬。
能力展示
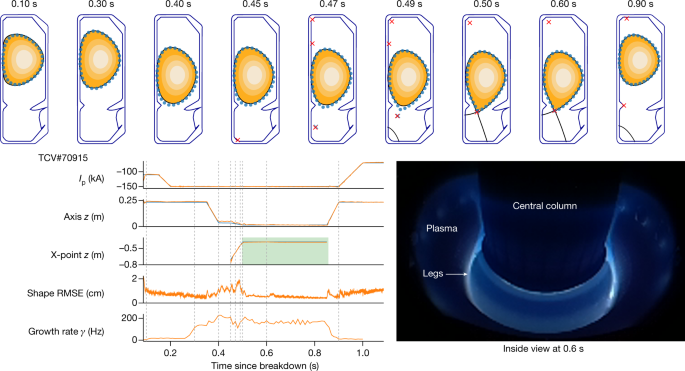
在論文的基礎(chǔ)能力驗證部分,團隊首先展示了這一方案對等離子體平衡基本質(zhì)量的精確控制。然后,通過復(fù)雜的、隨時間變化的目標和物理相關(guān)的等離子體配置,系統(tǒng)對控制范圍進行了廣泛的平衡。最后,實驗展示了對容器中具有多個等離子體“液滴”配置的同步控制。
另一個重要的能力——即為科學研究生成復(fù)雜配置的能力。每個演示都有自己的隨時間變化的目標,但除此之外,使用相同的架構(gòu)設(shè)置來生成控制策略,包括訓練和環(huán)境配置,只需對獎勵函數(shù)進行少量調(diào)整。
此外,RL 方法大大簡化了控制系統(tǒng)。單個計算成本低的控制器取代了嵌套控制架構(gòu),消除了獨立平衡重建的要求。這些綜合優(yōu)勢,縮短了控制器開發(fā)周期,并能加速了更換等離子配置驗證。
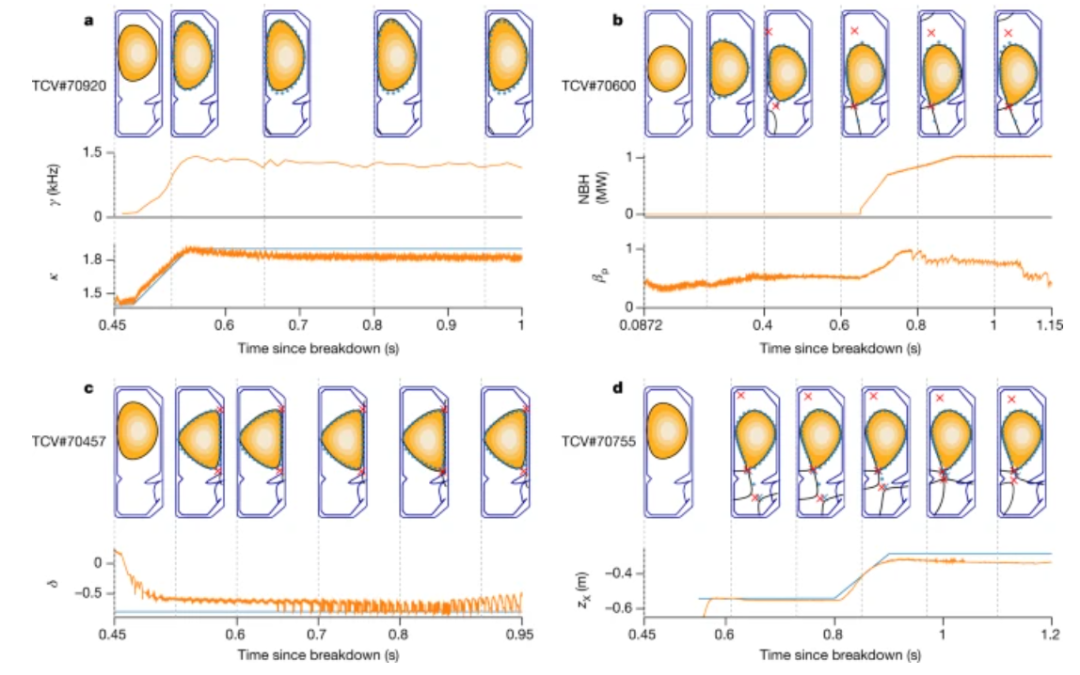
總而言之,研究人員認為,使用 AI 算法控制等離子體,將使在反應(yīng)堆內(nèi)進行不同條件的實驗變得更加容易,幫助他們了解這個過程,并有可能加快商業(yè)核聚變的發(fā)展。AI 還學會了如何通過以人類以前從未嘗試過的方式調(diào)整磁鐵來控制等離子體,這表明可能會有新的反應(yīng)堆配置可供探索。
正如瑞士等離子中心主任 Ambrogio Fasoli 所說:“我們可以通過這種控制系統(tǒng)來冒險,否則我們不敢冒險。” 人類操作員通常不愿意將等離子體推到一定限度之外。
有些事件我們必須避免,因為它們會損壞設(shè)備,如果我們確定有一個控制系統(tǒng)可以接近極限但不會超出極限,那么就可以探索更多的可能性。研究可以繼續(xù)加速。”
參考:
https://www.nature.com/articles/s41586-021-04301-9#Sec4