
預(yù)測過去?DeepMind用AI復(fù)原古希臘銘文,登Nature封面

來源:機(jī)器之心 本文約2400字,建議閱讀9分鐘
用深度神經(jīng)網(wǎng)絡(luò)(DNN)修復(fù)受損的古希臘銘文,DeepMind 探索 AI 與古文字學(xué)的融合。

論文地址: https://www.nature.com/articles/s41586-022-04448-z GitHub 地址: https://github.com/deepmind/ithaca

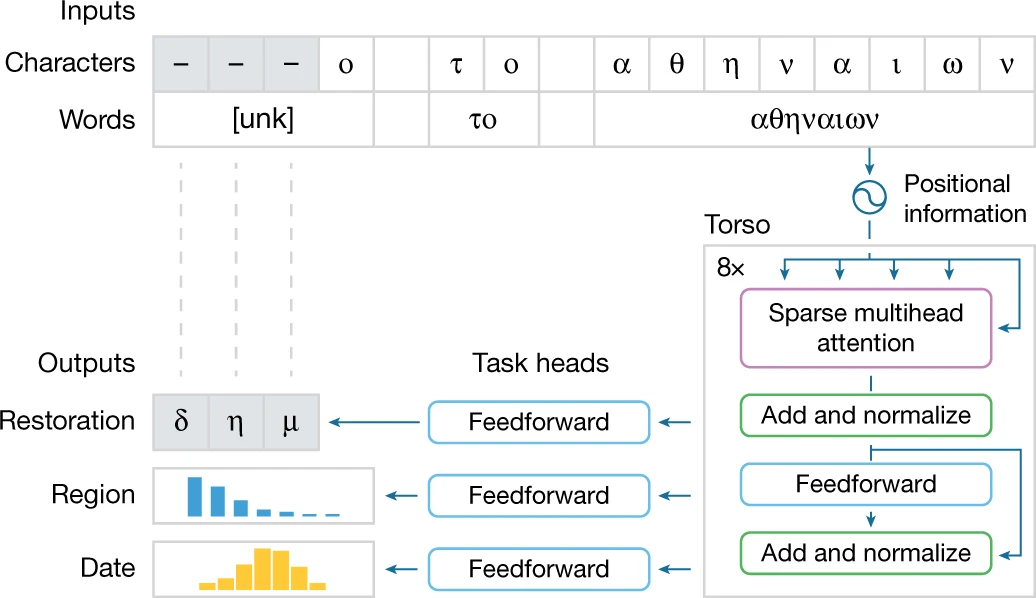
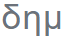 。提供輸入后,Ithaca 恢復(fù)了文本,并識別出文本編寫的時間和地點。
。提供輸入后,Ithaca 恢復(fù)了文本,并識別出文本編寫的時間和地點。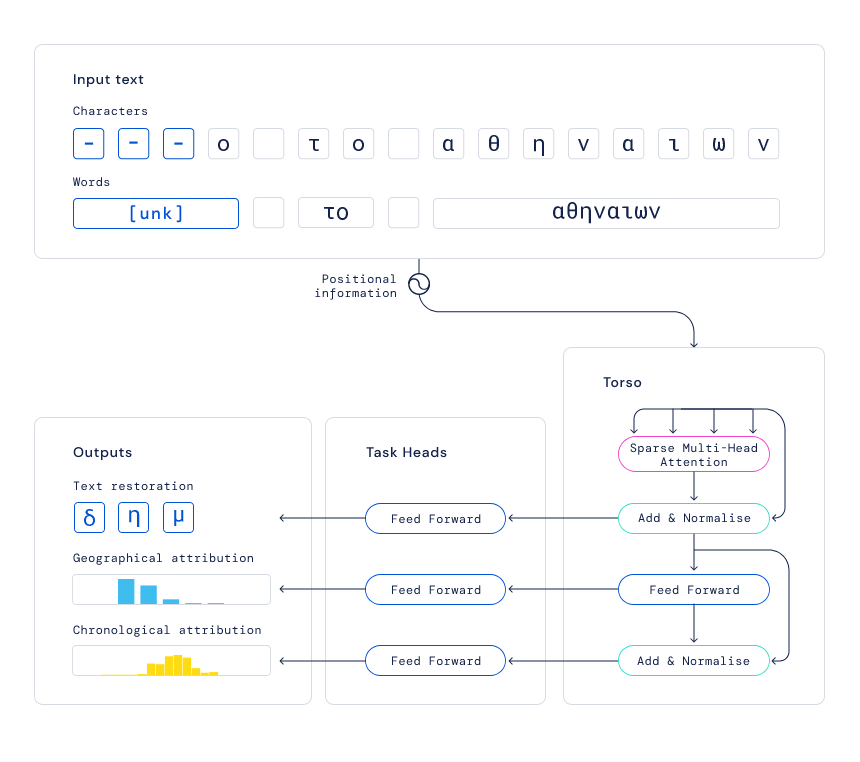
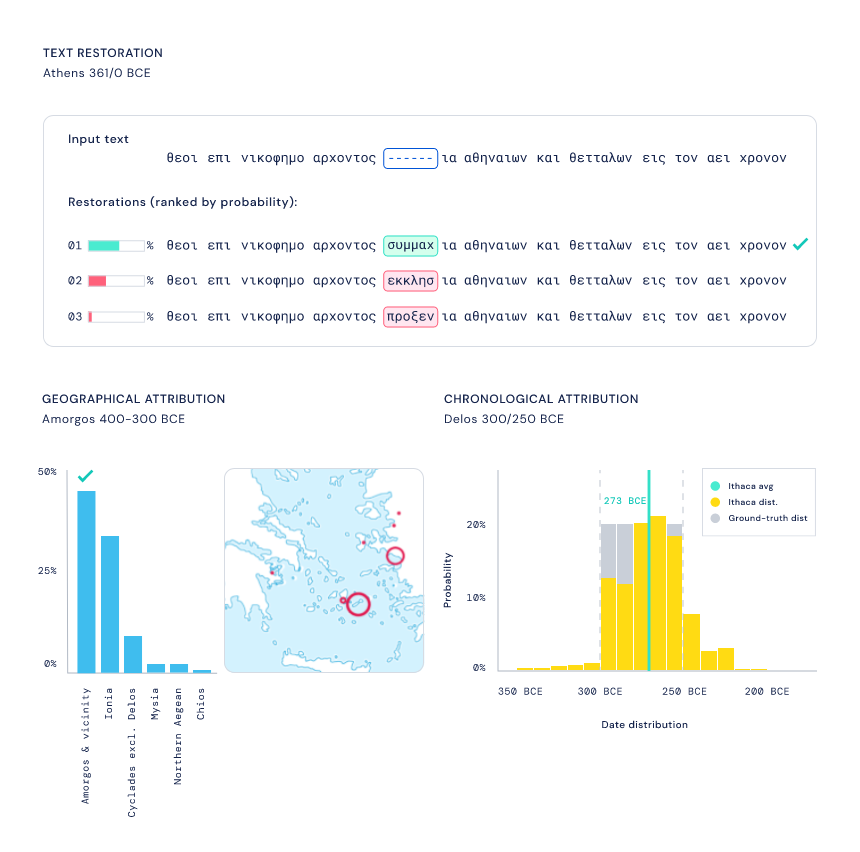
恢復(fù)假設(shè):Ithaca 為文本修復(fù)任務(wù)生成幾個預(yù)測假設(shè),供歷史學(xué)家利用自身專業(yè)知識進(jìn)行選擇; 地理歸屬:Ithaca 通過為歷史學(xué)家提供所有可能預(yù)測的概率分布來顯示其不確定性,而不僅僅是單個輸出。因此,Ithaca 返回代表其確定性水平的 84 個不同古代區(qū)域的概率。可以在地圖上將這些結(jié)果可視化,以闡明古代世界可能存在的潛在地理聯(lián)系; 時間歸屬:當(dāng)需要確定一篇文獻(xiàn)的年代時,Ithaca 會產(chǎn)生從公元前 800 年到公元 800 年預(yù)測日期分布,這可以使歷史學(xué)家了解模型對特定日期范圍的可信度,提供有價值的歷史見解; 顯著圖:為了將結(jié)果傳達(dá)給歷史學(xué)家,Ithaca 使用計算機(jī)視覺中常用的一種技術(shù)來識別哪些輸入序列對預(yù)測的貢獻(xiàn)最大,輸出以不同顏色強(qiáng)度突出 Ithaca 預(yù)測缺失文本、地點和日期的單詞。


評論
圖片
表情