
日常 Bug 排查 - 集群逐步失去響應(yīng)
日常 Bug 排查系列都是一些簡單 Bug 排查。筆者將在這里介紹一些排查 Bug 的簡單技巧,同時順便積累素材
Bug 現(xiàn)場最近碰到一個產(chǎn)線問題,表現(xiàn)為某個應(yīng)用集群所有的節(jié)點全部下線了。導(dǎo)致上游調(diào)用全部報錯。而且從時間線分析來看。這個應(yīng)用的節(jié)點是逐步失去響應(yīng)的。因為請求量較小,直到最后一臺也失去響應(yīng)后,才發(fā)現(xiàn)這個集群有問題。 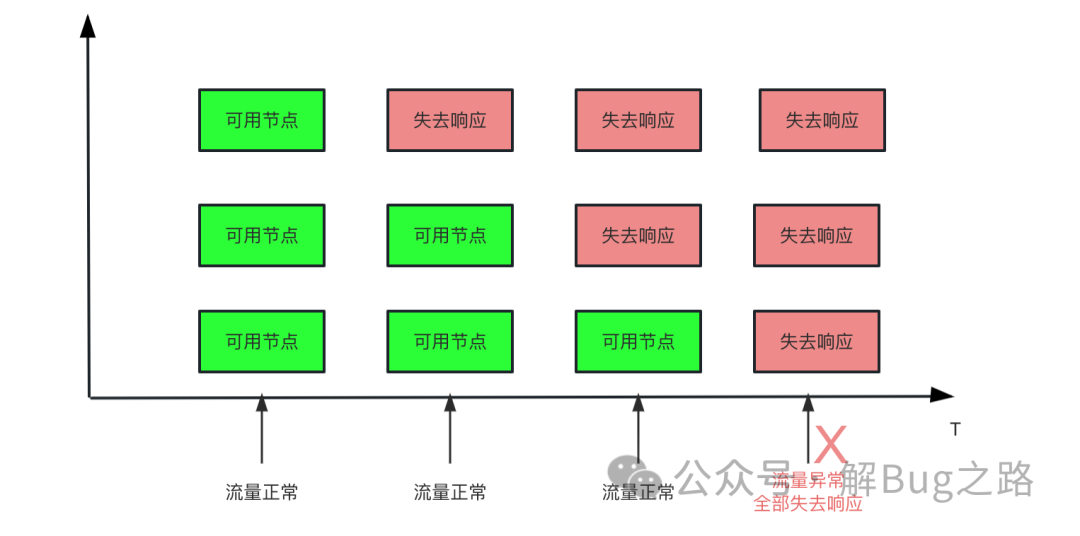
筆者觀察了下監(jiān)控,發(fā)現(xiàn)每臺機器的 BusyThread 從上次發(fā)布開始就逐步增長,一直到 BusyThread 線程數(shù)達到 200 才停止,而這個時間和每臺機器從注冊中心中摘除的時間相同。看了下代碼,其配置的最大處理請求線程數(shù)就是 200。 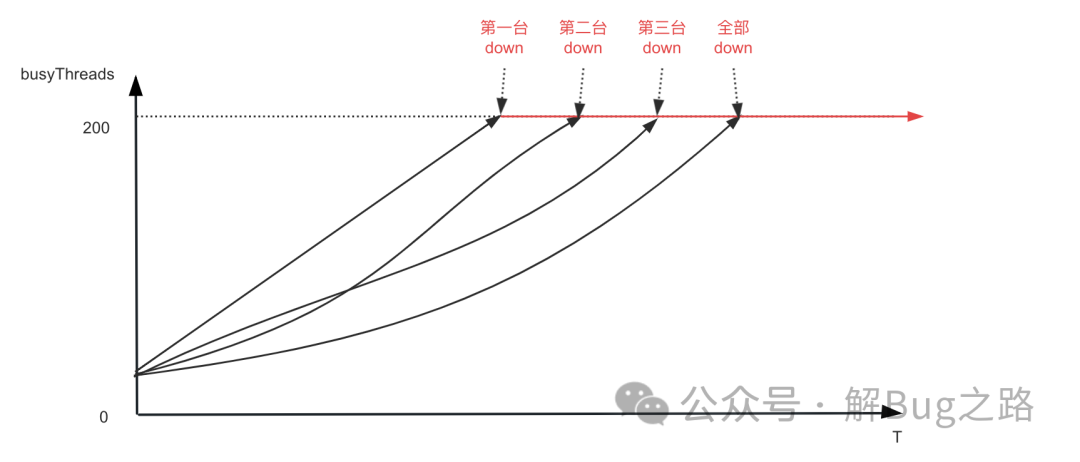
很容易的,我們就想到去觀察相關(guān)機器的線程棧。發(fā)現(xiàn)其所有的的請求處理線程全部 Block 在 com.google.common.util.concurrent.SettableFuture 的不同實例上。卡住的堆棧如下所示:
at sun.misc.Unsafe.park (Native Method: )
at java.util.concurrent.locks.LockSupport.park (LockSupport.java: 175)
at com.google.common.util.concurrent.AbstractFuture.get (AbstractFuture.java: 469)
at com.google.common.util.concurrent.AbstractFuture$TrustedFuture.get (AbstractFuture.java: 76)
at com.google.common.util.concurrent.Uninterruptibles.getUninterruptibly (Uninterruptibles.java: 142)
at com.google.common.cache.LocalCache$LoadingValueReference.waitForValue (LocalCache.java: 3661)
at com.google.common.cache.LocalCache$Segment.waitForLoadingValue (LocalCache.java: 2315)
at com.google.common.cache.LocalCache$Segment.get (LocalCache.java: 2202)
at com.google.common.cache.LocalCache.get (LocalCache.java: 4053)
at com.google.common.cache.LocalCache.getOrLoad (LocalCache.java: 4057)
at com.google.common.cache.LocalCache$LocalLoadingCache.get (LocalCache.java: 4986)
at com.google.common.cache.ForwardingLoadingCache.get (ForwardingLoadingCache.java: 45)
at com.google.common.cache.ForwardingLoadingCache.get (ForwardingLoadingCache.java: 45)
at com.google.common.cache.ForwardingLoadingCache.get
......
at com.XXX.business.getCache
......
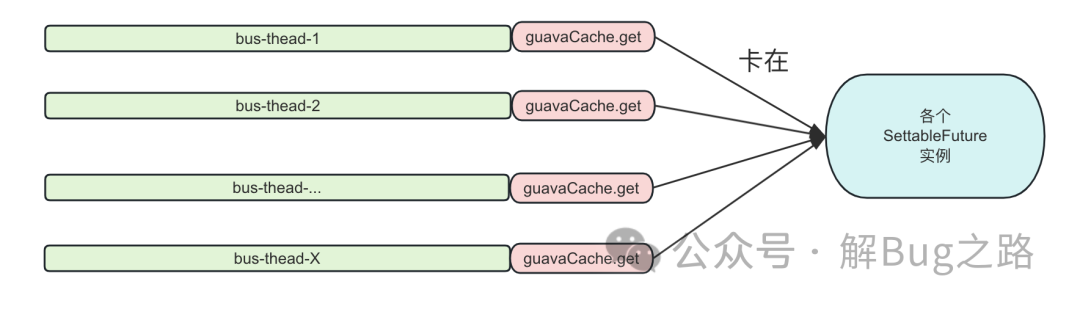
GuavaCache 是一個非常成熟的組件了,為什么會卡住呢?使用的姿勢不對?于是,筆者翻了翻使用 GuavaCache 的源代碼。其簡化如下:
private void initCache() {
ExecutorService executor = new ThreadPoolExecutor(1, 1,
60, TimeUnit.SECONDS,
new ArrayBlockingQueue<>(50), // 注意這個QueueSize
new NamedThreadFactory(String.format("cache-reload-%s")),
(r, e) -> {
log.warn("cache reload rejected by threadpool!"); // 注意這個reject策略
});
this.executorService = MoreExecutors.listeningDecorator(executor);
cache = CacheBuilder.newBuilder().maximumSize(100) // 注意這個最大值
.refreshAfterWrite(1, TimeUnit.DAYS).build(new CacheLoader<K, V>() {
@Override
public V load(K key) throws Exception {
return innerLoad(key);
}
@Override
public ListenableFuture<V> reload(K key, V oldValue) throws Exception {
ListenableFuture<V> task = executorService.submit(() -> {
try {
return innerLoad(key);
} catch (Exception e) {
LogUtils.printErrorLog(e, String.format("重新加載緩存失敗,key:%s", key));
return oldValue;
}
});
return task;
}
});
}
這段代碼事實上寫的還是不錯的,其通過重載 reload 方法并在加載后段緩存出問題的時候使用 old Value。保證了即使獲取緩存的后段存儲出問題了,依舊不會影響到我們緩存的獲取。邏輯如下所示: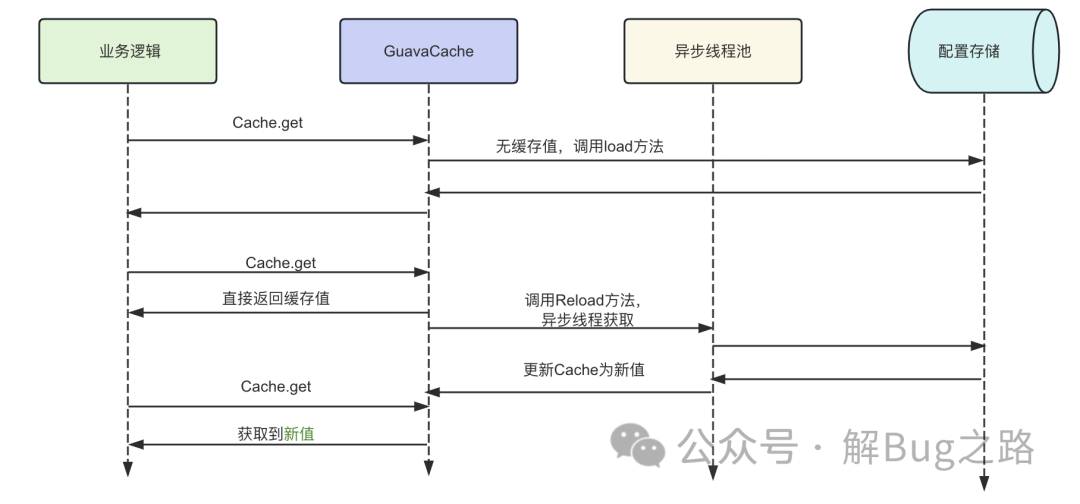
那么為什么會卡住呢?一時間看不出什么問題。那么我們就可以從系統(tǒng)的日志中去尋找蛛絲馬跡。
對應(yīng)時間點日志空空如也
對于這種逐漸失去響應(yīng)的,我們尋找日志的時候一般去尋找源頭。也就是第一次出現(xiàn)卡在 SettableFuture 的時候發(fā)生了什么。由于我們做了定時的線程棧采集,那么很容易的,筆者挑了一臺機器找到了 3 天之前第一次發(fā)生線程卡住的時候,grep 下對應(yīng)的線程名,只發(fā)現(xiàn)了一個請求過來到了這個線程然后卡住了,后面就什么日志都不輸出了。
異步緩存的日志
繼續(xù)回顧上面的代碼,代碼中緩存的刷新是異步執(zhí)行的,很有可能是異步執(zhí)行的時候出錯了。再 grep 異步執(zhí)行的相關(guān)關(guān)鍵詞 “重新加載緩存失敗”,依舊什么都沒有。線索又斷了。
繼續(xù)往前追溯
當所有線索都斷了的情況下,我們可以翻看時間點前后的整體日志,看下有沒有異常的點以獲取靈感。往前多翻了一天的日志,然后一條線程池請求被拒絕的日志進入了筆者的視野。
cache reload rejected by threadpool!
看到這條日志的一瞬間,筆者立馬就想明白了。GuavaCache 的 reload 請求不是出錯了,而是被線程池給丟了。在 reload 請求完成之后,GuavaCache 會對相應(yīng)的 SettableFuture 做 done 的動作以喚醒等待的線程。而由于我們的 Reject 策略只打印了日志,并沒有做 done 的動作,導(dǎo)致我們請求 Cache 的線程一直在卡 waitForValue 上面。如下圖所示,左邊的是正常情況,右邊的是異常情況。 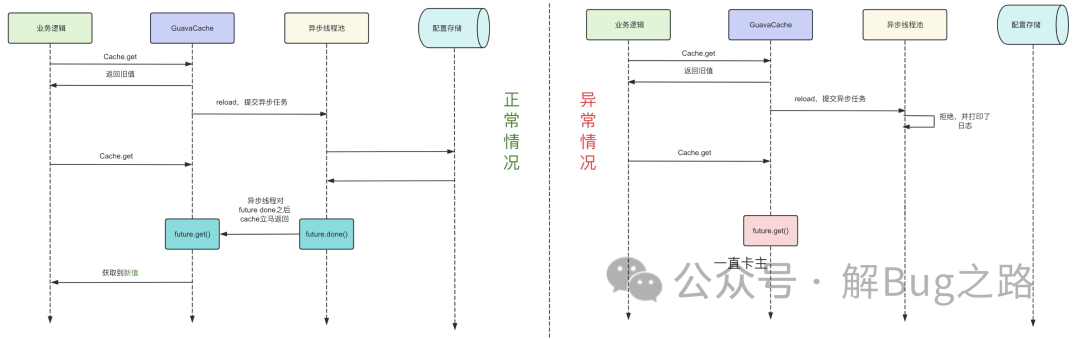
為什么會觸發(fā)線程池拒絕策略
注意我們初始化線程池的源代碼
ExecutorService executor = new ThreadPoolExecutor(1, 1,
60, TimeUnit.SECONDS,
new ArrayBlockingQueue<>(50), // 注意這個QueueSize
new NamedThreadFactory(String.format("cache-reload-%s")),
(r, e) -> {
log.warn("cache reload rejected by threadpool!"); // 注意這個reject策略
});
這個線程池是個單線程線程池,而且 Queue 只有 50,一旦遇到同時過來的請求大于 50 個,就很容易觸發(fā)拒絕策略。
源碼分析好了,這時候我們就可以上一下 GuavaCache 的源代碼了。
V get(K key, int hash, CacheLoader<? super K, V> loader) throws ExecutionException {
checkNotNull(key);
checkNotNull(loader);
try {
if (count != 0) { // read-volatile
// don't call getLiveEntry, which would ignore loading values
ReferenceEntry<K, V> e = getEntry(key, hash);
if (e != null) {
long now = map.ticker.read();
V value = getLiveValue(e, now);
if (value != null) {
recordRead(e, now);
statsCounter.recordHits(1);
// scheduleRefresh中一旦Value不為null,就直接返回舊值
return scheduleRefresh(e, key, hash, value, now, loader);
}
ValueReference<K, V> valueReference = e.getValueReference();
// 如果當前Value還在loading,則等loading完畢
if (valueReference.isLoading()) {
// 這次的Bug就一直卡在loadingValue上
return waitForLoadingValue(e, key, valueReference);
}
}
}
// at this point e is either null or expired;
return lockedGetOrLoad(key, hash, loader);
} catch (ExecutionException ee) {
......
}
為什么沒有直接返回 oldValue 而是卡住
等等,在上面的 GuavaCache 源代碼里面。一旦緩存有值之后,肯定是立馬返回了。對應(yīng)這段代碼。
if (value != null) {
recordRead(e, now);
statsCounter.recordHits(1);
// scheduleRefresh中一旦Value不為null,就直接返回舊值
return scheduleRefresh(e, key, hash, value, now, loader);
}
所以就算異步刷新請求被線程池 Reject 掉了。它也不會講原來緩存中的值給刪掉。業(yè)務(wù)線程也不應(yīng)該卡住。那么這個卡住是什么原因呢?為什么緩存中沒值沒有觸發(fā) load 而是等待 valueReference 有沒有加載完畢呢。
稍加思索之后,筆者就找到了原因,因為上述那段代碼中設(shè)置了緩存的 maxSize。一旦超過 maxSize,一部分數(shù)據(jù)就被驅(qū)逐掉了,而如果這部分數(shù)據(jù)恰好就是線程池 Reject 掉請求的數(shù)據(jù),那么就會進值為空同時需要等待 valueReference loading 的代碼分支,從而造成卡住的現(xiàn)象。讓我們看一下源代碼:
localCache.put //
|->evictEntries
|->removeEntry
|->removeValueFromChain
ReferenceEntry<K,V> removeValueFromChain(...) {
......
if(valueReference.isLoading()){
// 設(shè)置原值為null
valueReference.notifyNewValue(null);
return first;
}else {
removeEntryFromChain(first,entry)
}
}
我們看到,代碼中 valueReference.isLoading () 的判斷,一旦當前 value 還處于加載狀態(tài)中,那么驅(qū)逐的時候只會將對應(yīng)的 entry (key) 項設(shè)置為 null 而不會刪掉。這樣,在下次這個 key 的緩存被訪問的時候自然就走到了 value 為 null 的分支,然后就看到當前的 valueReference 還處于 loading 狀態(tài),最后就會等待那個由于被線程 reject 而永遠不會 done 的 future,最后就會導(dǎo)致這個線程卡住。邏輯如下圖所示: 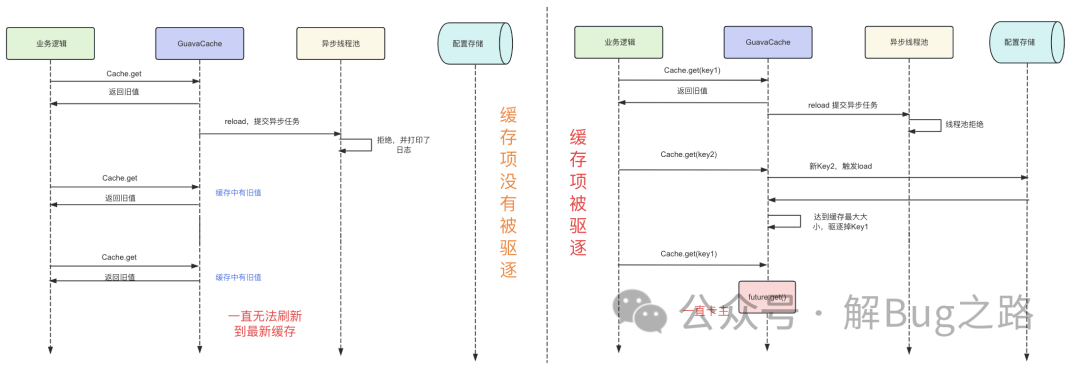
因為業(yè)務(wù)的實際緩存 key 的項目是大于 maxSize 的。而一開始系統(tǒng)啟動后加載的時候緩存的 cache 并沒有達到最大值,所以這時候被線程池 reject 掉相應(yīng)的刷新請求依舊能夠返回舊值。但一旦出現(xiàn)了大于緩存 cache 最大 Size 的數(shù)據(jù)導(dǎo)致一些項被驅(qū)逐后,只要是一個請求去訪問這些緩存項都會被卡住。但很明顯的,能夠被驅(qū)逐出去的舊緩存肯定是不常用的緩存 (默認 LRU 緩存策略),那么就看這個不常用的數(shù)據(jù)的流量到底是在哪臺機器上最多,那么哪臺機器就是最先失去響應(yīng)的了。
總結(jié)雖然這是個較簡單的問題,排查的時候也是需要一定的思路的,尤其是發(fā)生問題的時間點并往前追溯到第一個不同尋常的日志這個點,這個往往是我們破局的手段。GuavaCache 雖然是個使用非常廣泛的緩存工具,但不合理的配置依舊會導(dǎo)致災(zāi)難性的后果。