
實(shí)踐教程 | TensorRT部署深度學(xué)習(xí)模型

來(lái)源 | https://zhuanlan.zhihu.com/p/84125533
編輯 | 極市平臺(tái)
極市導(dǎo)讀
對(duì)需要部署模型的同志來(lái)說(shuō),掌握用tensorRT來(lái)部署深度學(xué)習(xí)模型的方法是非常有用的。通過(guò)Nvidia推出的tensorRT工具來(lái)部署主流框架上訓(xùn)練的模型,以便提高模型推斷的速度,占用更少的的設(shè)備內(nèi)存。 >>加入極市CV技術(shù)交流群,走在計(jì)算機(jī)視覺(jué)的最前沿
1.背景
目前主流的深度學(xué)習(xí)框架(caffe,mxnet,tensorflow,pytorch等)進(jìn)行模型推斷的速度都并不優(yōu)秀,在實(shí)際工程中用上述的框架進(jìn)行模型部署往往是比較低效的。而通過(guò)Nvidia推出的tensorRT工具來(lái)部署主流框架上訓(xùn)練的模型能夠極大的提高模型推斷的速度,往往相比與原本的框架能夠有至少1倍以上的速度提升,同時(shí)占用的設(shè)備內(nèi)存也會(huì)更加的少。因此對(duì)是所有需要部署模型的同志來(lái)說(shuō),掌握用tensorRT來(lái)部署深度學(xué)習(xí)模型的方法是非常有用的。
2.相關(guān)技術(shù)
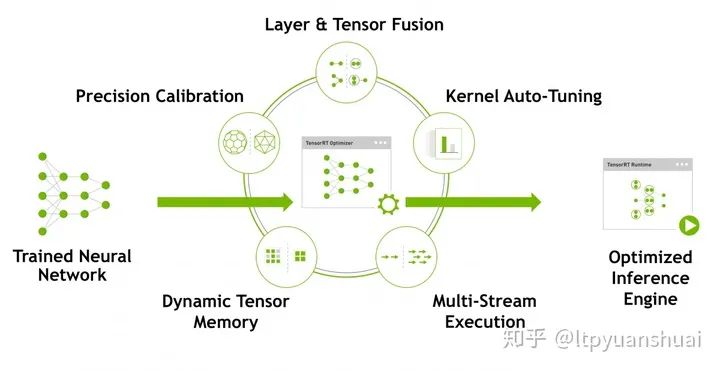
上面的圖片取自TensorRT的官網(wǎng),里面列出了tensorRT使用的一些技術(shù)。可以看到比較成熟的深度學(xué)習(xí)落地技術(shù):模型量化、動(dòng)態(tài)內(nèi)存優(yōu)化、層的融合等技術(shù)均已經(jīng)在tensorRT中集成了,這也是它能夠極大提高模型推斷速度的原因。總體來(lái)說(shuō)tensorRT將訓(xùn)練好的模型通過(guò)一系列的優(yōu)化技術(shù)轉(zhuǎn)化為了能夠在特定平臺(tái)(GPU)上以高性能運(yùn)行的代碼,也就是最后圖中生成的Inference engine。目前也有一些其他的工具能夠?qū)崿F(xiàn)類似tensorRT的功能,例如TVM,TensorComprehensions也能有效的提高模型在特定平臺(tái)上的推斷速度,但是由于目前企業(yè)主流使用的都是Nvidia生產(chǎn)的計(jì)算設(shè)備,在這些設(shè)備上nvidia推出的tensorRT性能相比其他工具會(huì)更有優(yōu)勢(shì)一些。而且tensorRT依賴的代碼庫(kù)僅僅包括C++和cuda,相對(duì)與其他工具要更為精簡(jiǎn)一些。
3. tensorflow模型tensorRT部署教程
實(shí)際工程部署中多采用c++進(jìn)行部署,因此在本教程中也使用的是tensorRT的C++API,tensorRT版本為5.1.5。具體tensorRT安裝可參考教程[深度學(xué)習(xí)] TensorRT安裝,以及官網(wǎng)的安裝說(shuō)明。
模型持久化
部署tensorflow模型的第一步是模型持久化,將模型結(jié)構(gòu)和權(quán)重保存到一個(gè).pb文件當(dāng)中。
pb_graph = tf.graph_util.convert_variables_to_constants(sess, sess.graph.as_graph_def(), [v.op.name for v in outputs])
with tf.gfile.FastGFile('./pbmodel_name.pb', mode='wb') as f:
f.write(pb_graph.SerializeToString())
具體只需在模型定義和權(quán)重讀取之后執(zhí)行以上代碼,調(diào)用tf.graph_util.convert_variables_to_constants函數(shù)將權(quán)重轉(zhuǎn)為常量,其中outputs是需要作為輸出的tensor的列表,最后用pb_graph.SerializeToString()將graph序列化并寫(xiě)入到pb文件當(dāng)中,這樣就生成了pb模型。
生成uff模型
有了pb模型,需要將其轉(zhuǎn)換為tensorRT可用的uff模型,只需調(diào)用uff包自帶的convert腳本即可。
python /usr/lib/python2.7/site-packages/uff/bin/convert_to_uff.py pbmodel_name.pb
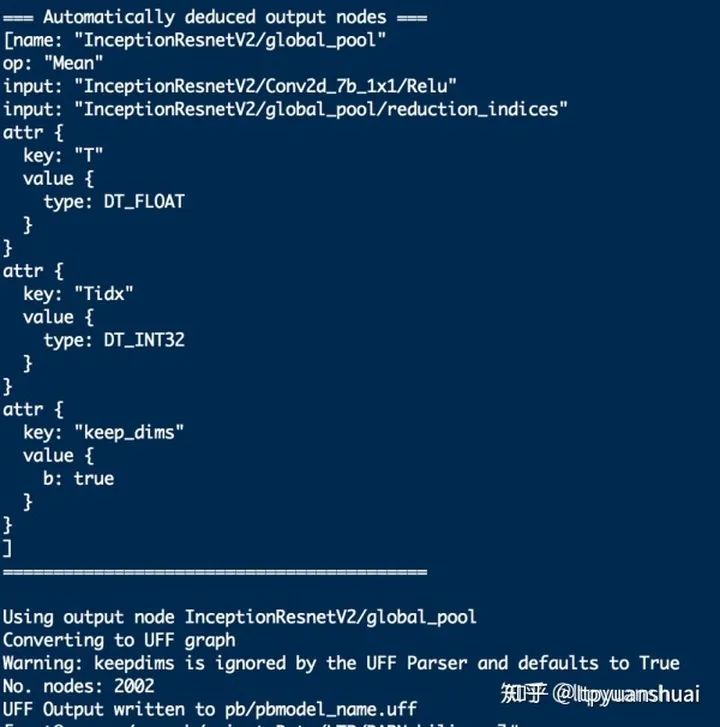
如轉(zhuǎn)換成功會(huì)輸出如下信息,包含圖中總結(jié)點(diǎn)的個(gè)數(shù)以及推斷出的輸入輸出節(jié)點(diǎn)的信息:
tensorRT c++ API部署模型
使用tensorRT部署生成好的uff模型需要先講uff中保存的模型權(quán)值以及網(wǎng)絡(luò)結(jié)構(gòu)導(dǎo)入進(jìn)來(lái),然后執(zhí)行優(yōu)化算法生成對(duì)應(yīng)的inference engine。具體代碼如下,首先需要定義一個(gè)IBuilder* builder,一個(gè)用來(lái)解析uff文件的parser以及builder創(chuàng)建的network,parser會(huì)將uff文件中的模型參數(shù)和網(wǎng)絡(luò)結(jié)構(gòu)解析出來(lái)存到network,解析前要預(yù)先告訴parser網(wǎng)絡(luò)輸入輸出輸出的節(jié)點(diǎn)。解析后builder就能根據(jù)network中定義的網(wǎng)絡(luò)結(jié)構(gòu)創(chuàng)建engine。在創(chuàng)建engine前會(huì)需要指定最大的batchsize大小,之后使用engine時(shí)輸入的batchsize不能超過(guò)這個(gè)數(shù)值否則就會(huì)出錯(cuò)。推斷時(shí)如果batchsize和設(shè)定最大值一樣時(shí)效率最高。舉個(gè)例子,如果設(shè)定最大batchsize為10,實(shí)際推理輸入一個(gè)batch 10張圖的時(shí)候平均每張推斷時(shí)間是4ms的話,輸入一個(gè)batch少于10張圖的時(shí)候平均每張圖推斷時(shí)間會(huì)高于4ms。
IBuilder* builder = createInferBuilder(gLogger.getTRTLogger());
auto parser = createUffParser();
parser->registerInput(inputtensor_name, Dims3(INPUT_C, INPUT_H, INPUT_W), UffInputOrder::kNCHW);
parser->registerOutput(outputtensor_name);
INetworkDefinition* network = builder->createNetwork();
if (!parser->parse(uffFile, *network, nvinfer1::DataType::kFLOAT))
{
gLogError << "Failure while parsing UFF file" << std::endl;
return nullptr;
}
builder->setMaxBatchSize(maxBatchSize);
builder->setMaxWorkspaceSize(MAX_WORKSPACE);
ICudaEngine* engine = builder->buildCudaEngine(*network);
if (!engine)
{
gLogError << "Unable to create engine" << std::endl;
return nullptr;
}
生成engine之后就可以進(jìn)行推斷了,執(zhí)行推斷時(shí)需要有一個(gè)上下文執(zhí)行上下文IExecutionContext* context,可以通過(guò)engine->createExecutionContext()獲得。執(zhí)行推斷的核心代碼是:
context->execute(batchSize, &buffers[0]);
其中buffer是一個(gè)void*數(shù)組對(duì)應(yīng)的是模型輸入輸出tensor的設(shè)備地址,通過(guò)cudaMalloc開(kāi)辟輸入輸出所需要的設(shè)備空間(顯存)將對(duì)應(yīng)指針存到buffer數(shù)組中,在執(zhí)行execute操作前通過(guò)cudaMemcpy把輸入數(shù)據(jù)(輸入圖像)拷貝到對(duì)應(yīng)輸入的設(shè)備空間,執(zhí)行execute之后還是通過(guò)cudaMemcpy把輸出的結(jié)果從設(shè)備上拷貝出來(lái)。
更為詳細(xì)的例程可以參考TensorRT官方的samples中的sampleUffMNIST代碼:https://github.com/NVIDIA/TensorRT/tree/master/samples/opensource/sampleUffMNIST
加速比情況
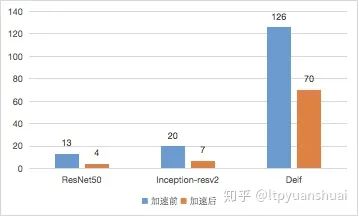
實(shí)際工程中我在Tesla M40上用tensorRT來(lái)加速過(guò)Resnet-50,Inception-resnet-v2,谷歌圖像檢索模型Delf(DEep Local Features),加速前后單張圖推斷用時(shí)比較如下圖(單位ms):
4. Caffe模型tensorRT部署教程
相比與tensorflow模型caffe模型的轉(zhuǎn)換更加簡(jiǎn)單,不需要有tensorflow模型轉(zhuǎn)uff模型這類的操作,tensorRT能夠直接解析prototxt和caffemodel文件獲取模型的網(wǎng)絡(luò)結(jié)構(gòu)和權(quán)重。具體解析流程和上文描述的一致,不同的是caffe模型的parser不需要預(yù)先指定輸入層,這是因?yàn)閜rototxt已經(jīng)進(jìn)行了輸入層的定義,parser能夠自動(dòng)解析出輸入,另外caffeparser解析網(wǎng)絡(luò)后返回一個(gè)IBlobNameToTensor *blobNameToTensor記錄了網(wǎng)絡(luò)中tensor和pototxt中名字的對(duì)應(yīng)關(guān)系,在解析之后就需要通過(guò)這個(gè)對(duì)應(yīng)關(guān)系,按照輸出tensor的名字列表outputs依次找到對(duì)應(yīng)的tensor并通過(guò)network->markOutput函數(shù)將其標(biāo)記為輸出,之后就可以生成engine了。
IBuilder* builder = createInferBuilder(gLogger);
INetworkDefinition* network = builder->createNetwork();
ICaffeParser* parser = createCaffeParser();
DataType modelDataType = DataType::kFLOAT;
const IBlobNameToTensor *blobNameToTensor = parser->parse(deployFile.c_str(),
modelFile.c_str(),
*network,
modelDataType);
assert(blobNameToTensor != nullptr);
for (auto& s : outputs) network->markOutput(*blobNameToTensor->find(s.c_str()));
builder->setMaxBatchSize(maxBatchSize);
builder->setMaxWorkspaceSize(1 << 30);
engine = builder->buildCudaEngine(*network);
生成engine后執(zhí)行的方式和上一節(jié)描述的一致,詳細(xì)的例程可以參考SampleMNIST
加速比情況
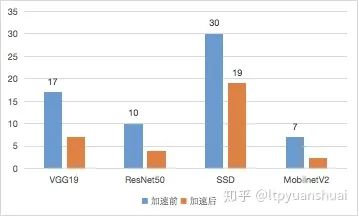
實(shí)際工程中我在Tesla M40上用tensorRT加速過(guò)caffe的VGG19,SSD速度變?yōu)?.6倍,ResNet50,MobileNetV2加速前后單張圖推斷用時(shí)比較如下圖(單位ms)
5.為tensorRT添加自定義層
tensorRT目前只支持一些非常常見(jiàn)的操作,有很多操作它并不支持比如上采樣Upsample操作,這時(shí)候就需要我們自行將其編寫(xiě)為tensorRT的插件層,從而使得這些不能支持的操作能在tensorRT中使用。以定義Upsample層為例,我們首先要定義一個(gè)繼承自tensorRT插件基類的Upsample類
class Upsample: public IPluginExt
然后要實(shí)現(xiàn)該類的一些必要方法,首先是2個(gè)構(gòu)造函數(shù),一個(gè)是傳參數(shù)構(gòu)建,另一個(gè)是從序列化后的比特流構(gòu)建。
Upsample(int scale = 2) : mScale(scale) {
assert(mScale > 0);
}
//定義上采樣倍數(shù)
Upsmaple(const void *data, size_t length) {
const char *d = reinterpret_cast<const char *>(data), *a = d;
mScale = read<int>(d);
mDtype = read<DataType>(d);
mCHW = read<DimsCHW>(d);
assert(mScale > 0);
assert(d == a + length);
}
~Upsample()
{
}
一些定義層輸出信息的方法:
int getNbOutputs() const override {
return 1;
}
//模型的輸出個(gè)數(shù)
Dims getOutputDimensions(int index, const Dims *inputs, int nbInputDims) override {
// std::cout << "Get ouputdims!!!" << std::endl;
assert(nbInputDims == 1);
assert(inputs[0].nbDims == 3);
return DimsCHW(inputs[0].d[0], inputs[0].d[1] * mScale, inputs[0].d[2] * mScale);
}
//獲取模型輸出的形狀。
根據(jù)輸入的形狀個(gè)數(shù)以及采用的數(shù)據(jù)類型檢查合法性以及配置層參數(shù)的方法:
bool supportsFormat(DataType type, PluginFormat format) const override {
return (type == DataType::kFLOAT || type == DataType::kHALF || type == DataType::kINT8)
&& format == PluginFormat::kNCHW;
}
//檢查層是否支持當(dāng)前的數(shù)據(jù)類型和格式
void configureWithFormat(const Dims *inputDims, int nbInputs, const Dims *outputDims, int nbOutputs,
DataType type, PluginFormat format, int maxBatchSize) override
{
mDtype = type;
mCHW.c() = inputDims[0].d[0];
mCHW.h() = inputDims[0].d[1];
mCHW.w() = inputDims[0].d[2];
}
//配置層的參數(shù)
層的序列化方法:
size_t getSerializationSize() override {
return sizeof(mScale) + sizeof(mDtype) + sizeof(mCHW);
}
//輸出序列化層所需的長(zhǎng)度
void serialize(void *buffer) override {
char *d = reinterpret_cast<char *>(buffer), *a = d;
write(d, mScale);
write(d, mDtype);
write(d, mCHW);
assert(d == a + getSerializationSize());
}
//將層參數(shù)序列化為比特流
層的運(yùn)算方法:
size_t getWorkspaceSize(int maxBatchSize) const override {
return 0;
}
//層運(yùn)算需要的臨時(shí)工作空間大小
int enqueue(int batchSize, const void *const *inputs, void **outputs, void *workspace,
cudaStream_t stream) override;
//層執(zhí)行計(jì)算的具體操作
在enqueue中我們調(diào)用編寫(xiě)好的cuda kenerl來(lái)進(jìn)行Upsample的計(jì)算。
完成了Upsample類的定義,我們就可以直接在網(wǎng)絡(luò)中添加我們編寫(xiě)的插件了,通過(guò)如下語(yǔ)句我們就定義一個(gè)上采樣2倍的上采樣層。addPluginExt的第一個(gè)輸入是ITensor**類別,這是為了支持多輸出的情況,第二個(gè)參數(shù)就是輸入個(gè)數(shù),第三個(gè)參數(shù)就是需要?jiǎng)?chuàng)建的插件類對(duì)象。
Upsample up(2);
auto upsamplelayer=network->addPluginExt(inputtensot,1,up)
6.為CaffeParser添加自定義層支持
對(duì)于我們自定義的層如果寫(xiě)到了caffe prototxt中,在部署模型時(shí)調(diào)用caffeparser來(lái)解析就會(huì)報(bào)錯(cuò)。
還是以Upsample為例,如果在prototxt中有下面這段來(lái)添加了一個(gè)upsample的層:
layer {
name: "upsample0"
type: "Upsample"
bottom: "ReLU11"
top: "Upsample1"
}
這時(shí)再調(diào)用:
const IBlobNameToTensor *blobNameToTensor = parser->parse(deployFile.c_str(),
modelFile.c_str(),
*network,
modelDataType);
就會(huì)出現(xiàn)錯(cuò)誤。

之前我們已經(jīng)編寫(xiě)了Upsample的插件,怎么讓tensorRT的caffe parser識(shí)別出prototxt中的upsample層自動(dòng)構(gòu)建我們自己編寫(xiě)的插件呢?這時(shí)我們就需要定義一個(gè)插件工程類繼承基類nvinfer1::IPluginFactory, nvcaffeparser1::IPluginFactoryExt。
class PluginFactory : public nvinfer1::IPluginFactory, public nvcaffeparser1::IPluginFactoryExt
其中必須要的實(shí)現(xiàn)的方法有判斷一個(gè)層是否是plugin的方法,輸入的參數(shù)就是prototxt中l(wèi)ayer的name,通過(guò)name來(lái)判斷一個(gè)層是否注冊(cè)為插件。
bool isPlugin(const char *name) override {
return isPluginExt(name);
}
bool isPluginExt(const char *name) override {
char *aa = new char[6];
memcpy(aa, name, 5);
aa[5] = 0;
int res = !strcmp(aa, "upsam");
return res;
}
//判斷層名字是否是upsample層的名字
根據(jù)名字創(chuàng)建插件的方法,有兩中方式一個(gè)是由權(quán)重構(gòu)建,另一個(gè)是由序列化后的比特流創(chuàng)建,對(duì)應(yīng)了插件的兩種構(gòu)造函數(shù),Upsample沒(méi)有權(quán)重,對(duì)于其他有權(quán)重的插件就能夠用傳入的weights初始化層。mplugin是一個(gè)vector用來(lái)存儲(chǔ)所有創(chuàng)建的插件層。
IPlugin *createPlugin(const char *layerName, const nvinfer1::Weights *weights, int nbWeights) override {
assert(isPlugin(layerName));
mPlugin.push_back(std::unique_ptr<Upsample>(new Upsample(2)));
return mPlugin[mPlugin.size() - 1].get();
}
IPlugin *createPlugin(const char *layerName, const void *serialData, size_t serialLength) override {
assert(isPlugin(layerName));
return new Upsample(serialData, serialLength);
}
std::vector <std::unique_ptr<Upsample>> mPlugin;
最后需要定義一個(gè)destroy方法來(lái)釋放所有創(chuàng)建的插件層。
void destroyPlugin() {
for (unsigned int i = 0; i < mPlugin.size(); i++) {
mPlugin[i].reset();
}
}
對(duì)于prototxt存在多個(gè)多種插件的情況,可以在isPlugin,createPlugin方法中添加新的條件分支,根據(jù)層的名字創(chuàng)建對(duì)應(yīng)的插件層。
實(shí)現(xiàn)了PluginFactory之后在調(diào)用caffeparser的時(shí)候需要設(shè)置使用它,在調(diào)用parser->parser之前加入如下代碼。
PluginFactory pluginFactory;
parser->setPluginFactoryExt(&pluginFactory);
就可以設(shè)置parser按照pluginFactory里面定義的規(guī)則來(lái)創(chuàng)建插件層,這樣之前出現(xiàn)的不能解析Upsample層的錯(cuò)誤就不會(huì)再出現(xiàn)了。
官方添加插件層的樣例samplePlugin:https://github.com/NVIDIA/TensorRT/tree/master/samples/opensource/samplePlugin)可以作為參考。
7.心得體會(huì)(踩坑記錄)
轉(zhuǎn)tensorflow模型時(shí),生成pb模型、轉(zhuǎn)換uff模型以及調(diào)用uffparser時(shí)register Input,output,這三個(gè)過(guò)程中輸入輸出節(jié)點(diǎn)的名字一定要注意保持一致,否則最終在parser進(jìn)行解析時(shí)會(huì)出現(xiàn)錯(cuò)誤,找不到輸入輸出節(jié)點(diǎn)。
除了本文中列舉的pluginExt,tensorRT中插件基類還有IPlugin,IPluginV2,繼承這些基類所需要實(shí)現(xiàn)的類方法有細(xì)微區(qū)別,具體情況可自行查看tensorRT安裝文件夾下的include/NvInfer.h文件。同時(shí)添加自己寫(xiě)的層到網(wǎng)絡(luò)時(shí)的函數(shù)有addPlugin,addPluginExt,addPluginV2這幾種和IPlugin,IPluginExt,IPluginV2一一對(duì)應(yīng),不能夠混用,否則有些默認(rèn)調(diào)用的類方法不會(huì)調(diào)用的,比如用addPlugin添加的PluginExt層是不會(huì)調(diào)用configureWithFormat方法的,因?yàn)镮Plugin類沒(méi)有該方法。同樣的在還有caffeparser的setPluginFactory和setPluginFactoryExt也是不能混用的。
運(yùn)行程序出現(xiàn)cuda failure一般情況下是由于將內(nèi)存數(shù)據(jù)拷貝到磁盤(pán)時(shí)出現(xiàn)了非法內(nèi)存訪問(wèn),注意檢查buffer開(kāi)辟的空間大小和拷貝過(guò)去數(shù)據(jù)的大小是否一致.
有一些操作在tensorRT中不支持但是可以通過(guò)一些支持的操作進(jìn)行組合替代,比如 ,這樣可以省去一些編寫(xiě)自定義層的時(shí)間。
tensorflow中的flatten操作默認(rèn)時(shí)keepdims=False的,但是在轉(zhuǎn)化uff文時(shí)會(huì)默認(rèn)按照keepdims=True轉(zhuǎn)換,因此在tensorflow中對(duì)flatten后的向量進(jìn)行transpose、expanddims等等操作,在轉(zhuǎn)換到uff后用tensorRT解析時(shí)容易出現(xiàn)錯(cuò)誤,比如“Order size is not matching the number dimensions of TensorRT” 。最好設(shè)置tensorflow的reduce,flatten操作的keepdims=True,保持層的輸出始終為4維形式,能夠有效避免轉(zhuǎn)到tensorRT時(shí)出現(xiàn)各種奇怪的錯(cuò)誤。
tensorRT中的slice層存在一定問(wèn)題,我用network->addSlice給網(wǎng)絡(luò)添加slice層后,在執(zhí)行buildengine這一步時(shí)就會(huì)出錯(cuò)nvinfer1::builder::checkSanity(const nvinfer1::builder::Graph&): Assertion `tensors.size() == g.tensors.size()' failed.,構(gòu)建網(wǎng)絡(luò)時(shí)最好避開(kāi)使用slice層,或者自己實(shí)現(xiàn)自定層來(lái)執(zhí)行slice操作。
tensorRT 的github中有著部分的開(kāi)源代碼以及豐富的示例代碼,多多學(xué)習(xí)能夠幫助更快的掌握tensorRT的使用。
8.參考資料
Nvidia TensorRT Samples:https://docs.nvidia.com/deeplearning/tensorrt/sample-support-guide/index.html
tensorrt-developer-guide:https://docs.nvidia.com/deeplearning/tensorrt/api/c_api/index.html
TensorRT API Docs:https://docs.nvidia.com/deeplearning/tensorrt/sample-support-guide/index.html
TensorRT Github:https://github.com/NVIDIA/TensorRT
如果覺(jué)得有用,就請(qǐng)分享到朋友圈吧!
公眾號(hào)后臺(tái)回復(fù)“CVPR21檢測(cè)”獲取CVPR2021目標(biāo)檢測(cè)論文下載~

# CV技術(shù)社群邀請(qǐng)函 #

備注:姓名-學(xué)校/公司-研究方向-城市(如:小極-北大-目標(biāo)檢測(cè)-深圳)
即可申請(qǐng)加入極市目標(biāo)檢測(cè)/圖像分割/工業(yè)檢測(cè)/人臉/醫(yī)學(xué)影像/3D/SLAM/自動(dòng)駕駛/超分辨率/姿態(tài)估計(jì)/ReID/GAN/圖像增強(qiáng)/OCR/視頻理解等技術(shù)交流群
每月大咖直播分享、真實(shí)項(xiàng)目需求對(duì)接、求職內(nèi)推、算法競(jìng)賽、干貨資訊匯總、與 10000+來(lái)自港科大、北大、清華、中科院、CMU、騰訊、百度等名校名企視覺(jué)開(kāi)發(fā)者互動(dòng)交流~
