
教程:基于TensorRT完成NanoDet模型部署

極市導(dǎo)讀
本文為大家介紹了一個(gè)TensorRT int8 量化部署 NanoDet 模型的教程,并開(kāi)源了全部代碼。主要包括如何搭建tensorrt環(huán)境,對(duì)pytorch模型做onnx格式轉(zhuǎn)換,onnx模型做tensorrt int8量化,及對(duì)量化后的模型做推理,實(shí)測(cè)在1070顯卡做到了2ms一幀!>>加入極市CV技術(shù)交流群,走在計(jì)算機(jī)視覺(jué)的最前沿
NanoDet簡(jiǎn)介
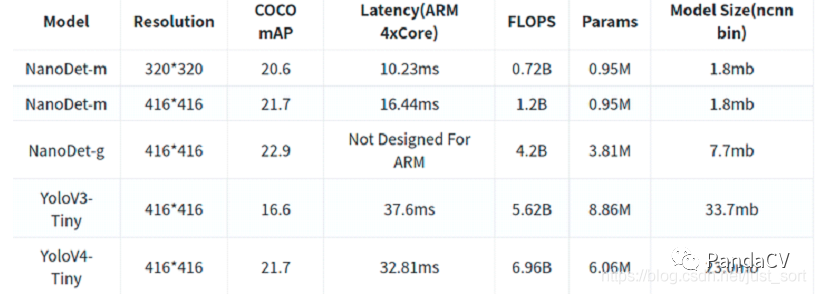
NanoDet (https://github.com/RangiLyu/nanodet)是一個(gè)速度超快和輕量級(jí)的Anchor-free 目標(biāo)檢測(cè)模型;和yolov4 tiny作比較(如下圖),精度相當(dāng),但速度卻快了1倍;對(duì)于速度優(yōu)先的場(chǎng)景,nanodet無(wú)疑是一個(gè)好的選擇。
NanoDet損失函數(shù)GFocal Loss
目前比較強(qiáng)力的one-stage anchor-free的檢測(cè)器(以FCOS,ATSS為代表)基本會(huì)包含3個(gè)表示:
分類表示 檢測(cè)框表示 檢測(cè)框的質(zhì)量估計(jì)(在FCOS/ATSS中,目前采用centerness,當(dāng)然也有一些其他類似的工作會(huì)采用IoU,這些score基本都在0~1之間) 存在問(wèn)題1:classification score 和 IoU/centerness score 訓(xùn)練測(cè)試不一致。存在問(wèn)題2:bbox regression 表示不夠靈活,沒(méi)有辦法建模復(fù)雜場(chǎng)景下的uncertainty 對(duì)于第一個(gè)問(wèn)題,為了保證training和test一致,同時(shí)還能夠兼顧分類score和質(zhì)量預(yù)測(cè)score都能夠訓(xùn)練到所有的正負(fù)樣本,作者提出一個(gè)方案:就是將兩者的表示進(jìn)行聯(lián)合 對(duì)于第二個(gè)問(wèn)題,作者選擇直接回歸一個(gè)任意分布來(lái)建模框的表示。一句話總結(jié):基于任意one-stage 檢測(cè)器上,調(diào)整框本身與框質(zhì)量估計(jì)的表示,同時(shí)用泛化版本的GFocal Loss訓(xùn)練該改進(jìn)的表示,無(wú)cost漲點(diǎn)(一般1個(gè)點(diǎn)出頭)AP
NanoDet 檢測(cè)頭FCOS架構(gòu)
FCOS系列使用了共享權(quán)重的檢測(cè)頭,即對(duì)FPN出來(lái)的多尺度Feature Map使用同一組卷積預(yù)測(cè)檢測(cè)框,然后每一層使用一個(gè)可學(xué)習(xí)的Scale值作為系數(shù),對(duì)預(yù)測(cè)出來(lái)的框進(jìn)行縮放。FCOS的檢測(cè)頭使用了4個(gè)256通道的卷積作為一個(gè)分支,也就是說(shuō)在邊框回歸和分類兩個(gè)分支上一共有8個(gè)c=256的卷積,計(jì)算量非常大。為了將其輕量化,作者首先選擇使用深度可分離卷積替換普通卷積,并且將卷積堆疊的數(shù)量從4個(gè)減少為2組。在通道數(shù)上,將256維壓縮至96維,之所以選擇96,是因?yàn)樾枰獙⑼ǖ罃?shù)保持為8或16的倍數(shù),這樣能夠享受到大部分推理框架的并行加速。最后,借鑒了yolo系列的做法,將邊框回歸和分類使用同一組卷積進(jìn)行計(jì)算,然后split成兩份。
FPN層改進(jìn)PAN
原版的PAN和yolo中的PAN,使用了stride=2的卷積進(jìn)行大尺度Feature Map到小尺度的縮放。作者為了輕量化的原則,選擇完全去掉PAN中的所有卷積,只保留從骨干網(wǎng)絡(luò)特征提取后的1x1卷積來(lái)進(jìn)行特征通道維度的對(duì)齊,上采樣和下采樣均使用插值來(lái)完成。與yolo使用的concatenate操作不同,作者選擇將多尺度的Feature Map直接相加,使得整個(gè)特征融合模塊的計(jì)算量變得非常非常小。
NanoDet 骨干網(wǎng)絡(luò)ShuffleNetV2(原始版本)
作者選擇使用ShuffleNetV2 1.0x作為backbone,去掉了最后一層卷積,并且抽取8、16、32倍下采樣的特征輸入進(jìn)PAN做多尺度的特征融合
環(huán)境配置
環(huán)境配置和之前的文章《基于TensorRT量化部署yolov5 4.0模型》類似 ubuntu:18.04 cuda:11.0 cudnn:8.0 tensorrt:7.2.16 OpenCV:3.4.2 cuda,cudnn,tensorrt和OpenCV安裝包(編譯好了,也可以自己從官網(wǎng)下載編譯)可以從鏈接: https://pan.baidu.com/s/1dpMRyzLivnBAca2c_DIgGw 密碼: 0rct cuda安裝 如果系統(tǒng)有安裝驅(qū)動(dòng),運(yùn)行如下命令卸載 sudo apt-get purge nvidia* 禁用nouveau,運(yùn)行如下命令 sudo vim /etc/modprobe.d/blacklist.conf 在末尾添加 blacklist nouveau 然后執(zhí)行 sudo update-initramfs -u chmod +x cuda_11.0.2_450.51.05_linux.run sudo ./cuda_11.0.2_450.51.05_linux.run 是否接受協(xié)議: accept 然后選擇Install 最后回車 vim ~/.bashrc 添加如下內(nèi)容: export PATH=/usr/local/cuda-11.0/bin:$PATH export LD_LIBRARY_PATH=/usr/local/cuda-11.0/lib64:$LD_LIBRARY_PATH source ~/.bashrc 激活環(huán)境 cudnn 安裝 tar -xzvf cudnn-11.0-linux-x64-v8.0.4.30.tgz cd cuda/include sudo cp *.h /usr/local/cuda-11.0/include cd cuda/lib64 sudo cp libcudnn* /usr/local/cuda-11.0/lib64 tensorrt及OpenCV安裝 定位到用戶根目錄 tar -xzvf TensorRT-7.2.1.6.Ubuntu-18.04.x86_64-gnu.cuda-11.0.cudnn8.0.tar.gz cd TensorRT-7.2.1.6/python,該目錄有4個(gè)python版本的tensorrt安裝包 sudo pip3 install tensorrt-7.2.1.6-cp37-none-linux_x86_64.whl(根據(jù)自己的python版本安裝) pip install pycuda 安裝python版本的cuda 定位到用戶根目錄 tar -xzvf opencv-3.4.2.zip 以備推理調(diào)用
NanoDet 模型轉(zhuǎn)換onnx
pip install onnx pip install onnx-simplifier git clone https://github.com/Wulingtian/nanodet.git cd nanodet cd config 配置模型文件(注意激活函數(shù)要換為relu!tensorrt支持relu量化),訓(xùn)練模型 定位到nanodet目錄,進(jìn)入tools目錄,打開(kāi)export.py文件,配置cfg_path model_path out_path三個(gè)參數(shù) 定位到nanodet目錄,運(yùn)行 python tools/export.py 得到轉(zhuǎn)換后的onnx模型 python3 -m onnxsim onnx模型名稱 nanodet-simple.onnx 得到最終簡(jiǎn)化后的onnx模型
onnx模型轉(zhuǎn)換為 int8 tensorrt引擎
git clone https://github.com/Wulingtian/nanodet_tensorrt_int8_tools.git(求star) cd nanodet_tensorrt_int8_tools vim convert_trt_quant.py 修改如下參數(shù) BATCH_SIZE 模型量化一次輸入多少?gòu)垐D片 BATCH 模型量化次數(shù) height width 輸入圖片寬和高 CALIB_IMG_DIR 訓(xùn)練圖片路徑,用于量化 onnx_model_path onnx模型路徑 python convert_trt_quant.py 量化后的模型存到models_save目錄下
tensorrt模型推理
git clone https://github.com/Wulingtian/nanodet_tensorrt_int8.git(求star)
cd nanodet_tensorrt_int8
vim CMakeLists.txt
修改USER_DIR參數(shù)為自己的用戶根目錄
vim nanodet_infer.cc 修改如下參數(shù)
output_name模型有一個(gè)輸出
我們可以通過(guò)netron查看模型輸出名
pip install netron 安裝netron
vim netron_nanodet.py 把如下內(nèi)容粘貼
import netron netron.start('此處填充簡(jiǎn)化后的onnx模型路徑', port=3344) python netron_nanodet.py 即可查看 模型輸出名
trt_model_path 量化的的tensorrt推理引擎(models_save目錄下trt后綴的文件)
test_img 測(cè)試圖片路徑
INPUT_W INPUT_H 輸入圖片寬高
NUM_CLASS 訓(xùn)練的模型有多少類
NMS_THRESH nms閾值
CONF_THRESH 置信度閾值
參數(shù)配置完畢
mkdir build
cd build
cmake ..
make
./NanoDetEngine 輸出平均推理時(shí)間,以及保存預(yù)測(cè)圖片到當(dāng)前目錄下,至此,部署完成!
預(yù)測(cè)結(jié)果展示

推薦閱讀
2021-01-10
2020-11-21

2020-02-03


# CV技術(shù)社群邀請(qǐng)函 #
備注:姓名-學(xué)校/公司-研究方向-城市(如:小極-北大-目標(biāo)檢測(cè)-深圳)
即可申請(qǐng)加入極市目標(biāo)檢測(cè)/圖像分割/工業(yè)檢測(cè)/人臉/醫(yī)學(xué)影像/3D/SLAM/自動(dòng)駕駛/超分辨率/姿態(tài)估計(jì)/ReID/GAN/圖像增強(qiáng)/OCR/視頻理解等技術(shù)交流群
每月大咖直播分享、真實(shí)項(xiàng)目需求對(duì)接、求職內(nèi)推、算法競(jìng)賽、干貨資訊匯總、與 10000+來(lái)自港科大、北大、清華、中科院、CMU、騰訊、百度等名校名企視覺(jué)開(kāi)發(fā)者互動(dòng)交流~
