
天天在用Stream,那你知道如此強(qiáng)大的Stream的實(shí)現(xiàn)原理嗎?
github.com/CarpenterLee/JavaLambdaInternals
我們已經(jīng)學(xué)會(huì)如何使用Stream API,用起來(lái)真的很爽,但簡(jiǎn)潔的方法下面似乎隱藏著無(wú)盡的秘密,如此強(qiáng)大的API是如何實(shí)現(xiàn)的呢?
比如Pipeline是怎么執(zhí)行的,每次方法調(diào)用都會(huì)導(dǎo)致一次迭代嗎?自動(dòng)并行又是怎么做到的,線程個(gè)數(shù)是多少?本節(jié)我們學(xué)習(xí)Stream流水線的原理,這是Stream實(shí)現(xiàn)的關(guān)鍵所在。
首先回顧一下容器執(zhí)行Lambda表達(dá)式的方式,以ArrayList.forEach()方法為例,具體代碼如下:
//?ArrayList.forEach()
public?void?forEach(Consumersuper?E>?action)?{
????...
????for?(int?i=0;?modCount?==?expectedModCount?&&?i?????????action.accept(elementData[i]);//?回調(diào)方法
????}
????...
}
我們看到ArrayList.forEach()方法的主要邏輯就是一個(gè)for循環(huán),在該for循環(huán)里不斷調(diào)用action.accept()回調(diào)方法完成對(duì)元素的遍歷。
這完全沒(méi)有什么新奇之處,回調(diào)方法在Java GUI的監(jiān)聽(tīng)器中廣泛使用。Lambda表達(dá)式的作用就是相當(dāng)于一個(gè)回調(diào)方法,這很好理解。
Stream API中大量使用Lambda表達(dá)式作為回調(diào)方法,但這并不是關(guān)鍵。理解Stream我們更關(guān)心的是另外兩個(gè)問(wèn)題:流水線和自動(dòng)并行。使用Stream或許很容易寫(xiě)入如下形式的代碼:
int?longestStringLengthStartingWithA
????????=?strings.stream()
??????????????.filter(s?->?s.startsWith("A"))
??????????????.mapToInt(String::length)
??????????????.max();
上述代碼求出以字母A開(kāi)頭的字符串的最大長(zhǎng)度,一種直白的方式是為每一次函數(shù)調(diào)用都執(zhí)一次迭代,這樣做能夠?qū)崿F(xiàn)功能,但效率上肯定是無(wú)法接受的。
類(lèi)庫(kù)的實(shí)現(xiàn)著使用流水線(Pipeline)的方式巧妙的避免了多次迭代,其基本思想是在一次迭代中盡可能多的執(zhí)行用戶指定的操作。為講解方便我們匯總了Stream的所有操作。
| Stream操作分類(lèi) | ||
| 中間操作(Intermediate operations) | 無(wú)狀態(tài)(Stateless) | unordered() filter() map() mapToInt() mapToLong() mapToDouble() flatMap() flatMapToInt() flatMapToLong() flatMapToDouble() peek() |
| 有狀態(tài)(Stateful) | distinct() sorted() sorted() limit() skip() | |
| 結(jié)束操作(Terminal operations) | 非短路操作 | forEach() forEachOrdered() toArray() reduce() collect() max() min() count() |
| 短路操作(short-circuiting) | anyMatch() allMatch() noneMatch() findFirst() findAny() | |
Stream上的所有操作分為兩類(lèi):中間操作和結(jié)束操作,中間操作只是一種標(biāo)記,只有結(jié)束操作才會(huì)觸發(fā)實(shí)際計(jì)算。中間操作又可以分為無(wú)狀態(tài)的(Stateless)和有狀態(tài)的(Stateful),無(wú)狀態(tài)中間操作是指元素的處理不受前面元素的影響,而有狀態(tài)的中間操作必須等到所有元素處理之后才知道最終結(jié)果。
比如排序是有狀態(tài)操作,在讀取所有元素之前并不能確定排序結(jié)果;結(jié)束操作又可以分為短路操作和非短路操作,短路操作是指不用處理全部元素就可以返回結(jié)果,比如找到第一個(gè)滿足條件的元素。之所以要進(jìn)行如此精細(xì)的劃分,是因?yàn)榈讓訉?duì)每一種情況的處理方式不同。
為了更好的理解流的中間操作和終端操作,可以通過(guò)下面的兩段代碼來(lái)看他們的執(zhí)行過(guò)程。
IntStream.range(1,?10)
???.peek(x?->?System.out.print("\nA"?+?x))
???.limit(3)
???.peek(x?->?System.out.print("B"?+?x))
???.forEach(x?->?System.out.print("C"?+?x));
輸出為:
A1B1C1
A2B2C2
A3B3C3
中間操作是懶惰的,也就是中間操作不會(huì)對(duì)數(shù)據(jù)做任何操作,直到遇到了最終操作。而最終操作,都是比較熱情的。他們會(huì)往前回溯所有的中間操作。也就是當(dāng)執(zhí)行到最后的forEach操作的時(shí)候,它會(huì)回溯到它的上一步中間操作,上一步中間操作,又會(huì)回溯到上上一步的中間操作,...,直到最初的第一步。
第一次forEach執(zhí)行的時(shí)候,會(huì)回溯peek 操作,然后peek會(huì)回溯更上一步的limit操作,然后limit會(huì)回溯更上一步的peek操作,頂層沒(méi)有操作了,開(kāi)始自上向下開(kāi)始執(zhí)行,輸出:A1B1C1 第二次forEach執(zhí)行的時(shí)候,然后會(huì)回溯peek 操作,然后peek會(huì)回溯更上一步的limit操作,然后limit會(huì)回溯更上一步的peek操作,頂層沒(méi)有操作了,開(kāi)始自上向下開(kāi)始執(zhí)行,輸出:A2B2C2
... 當(dāng)?shù)谒拇蝔orEach執(zhí)行的時(shí)候,然后會(huì)回溯peek 操作,然后peek會(huì)回溯更上一步的limit操作,到limit的時(shí)候,發(fā)現(xiàn)limit(3)這個(gè)job已經(jīng)完成,這里就相當(dāng)于循環(huán)里面的break操作,跳出來(lái)終止循環(huán)。
再來(lái)看第二段代碼:
IntStream.range(1,?10)
???.peek(x?->?System.out.print("\nA"?+?x))
???.skip(6)
???.peek(x?->?System.out.print("B"?+?x))
???.forEach(x?->?System.out.print("C"?+?x));
輸出為:
A1
A2
A3
A4
A5
A6
A7B7C7
A8B8C8
A9B9C9
第一次forEach執(zhí)行的時(shí)候,會(huì)回溯peek操作,然后peek會(huì)回溯更上一步的skip操作,skip回溯到上一步的peek操作,頂層沒(méi)有操作了,開(kāi)始自上向下開(kāi)始執(zhí)行,執(zhí)行到skip的時(shí)候,因?yàn)閳?zhí)行到skip,這個(gè)操作的意思就是跳過(guò),下面的都不要執(zhí)行了,也就是就相當(dāng)于循環(huán)里面的continue,結(jié)束本次循環(huán)。輸出:A1
第二次forEach執(zhí)行的時(shí)候,會(huì)回溯peek操作,然后peek會(huì)回溯更上一步的skip操作,skip回溯到上一步的peek操作,頂層沒(méi)有操作了,開(kāi)始自上向下開(kāi)始執(zhí)行,執(zhí)行到skip的時(shí)候,發(fā)現(xiàn)這是第二次skip,結(jié)束本次循環(huán)。輸出:A2
...
第七次forEach執(zhí)行的時(shí)候,會(huì)回溯peek操作,然后peek會(huì)回溯更上一步的skip操作,skip回溯到上一步的peek操作,頂層沒(méi)有操作了,開(kāi)始自上向下開(kāi)始執(zhí)行,執(zhí)行到skip的時(shí)候,發(fā)現(xiàn)這是第七次skip,已經(jīng)大于6了,它已經(jīng)執(zhí)行完了skip(6)的job了。這次skip就直接跳過(guò),繼續(xù)執(zhí)行下面的操作。輸出:A7B7C7
...直到循環(huán)結(jié)束。
面試題推薦:100期面試題匯總
一種直白的實(shí)現(xiàn)方式
仍然考慮上述求最長(zhǎng)字符串的程序,一種直白的流水線實(shí)現(xiàn)方式是為每一次函數(shù)調(diào)用都執(zhí)一次迭代,并將處理中間結(jié)果放到某種數(shù)據(jù)結(jié)構(gòu)中(比如數(shù)組,容器等)。
具體說(shuō)來(lái),就是調(diào)用filter()方法后立即執(zhí)行,選出所有以A開(kāi)頭的字符串并放到一個(gè)列表list1中,之后讓list1傳遞給mapToInt()方法并立即執(zhí)行,生成的結(jié)果放到list2中,最后遍歷list2找出最大的數(shù)字作為最終結(jié)果。程序的執(zhí)行流程如如所示:
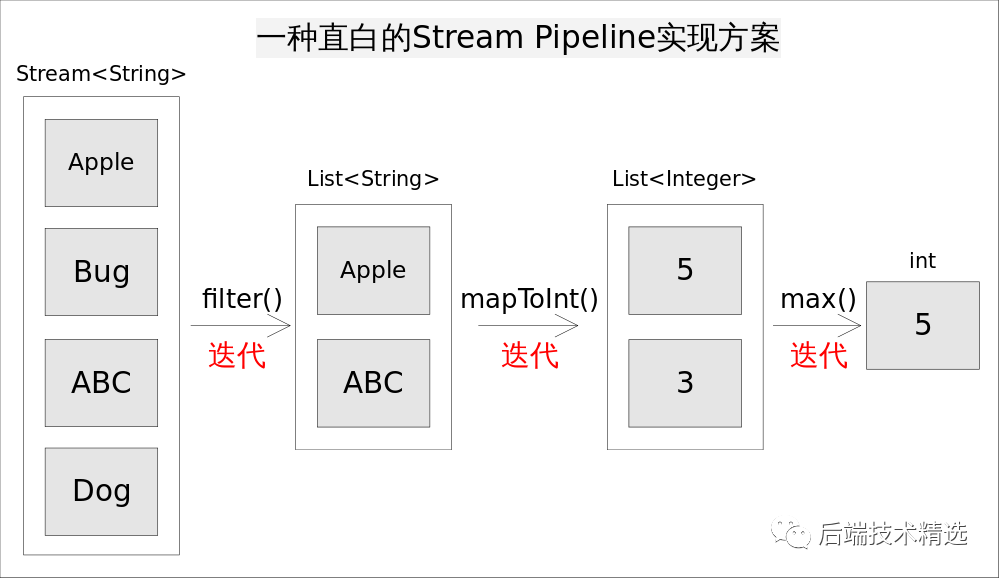
這樣做實(shí)現(xiàn)起來(lái)非常簡(jiǎn)單直觀,但有兩個(gè)明顯的弊端:
迭代次數(shù)多。迭代次數(shù)跟函數(shù)調(diào)用的次數(shù)相等。 頻繁產(chǎn)生中間結(jié)果。每次函數(shù)調(diào)用都產(chǎn)生一次中間結(jié)果,存儲(chǔ)開(kāi)銷(xiāo)無(wú)法接受。
這些弊端使得效率底下,根本無(wú)法接受。如果不使用Stream API我們都知道上述代碼該如何在一次迭代中完成,大致是如下形式:
int?longest?=?0;
for(String?str?:?strings){
????if(str.startsWith("A")){//?1.?filter(),?保留以A開(kāi)頭的字符串
????????int?len?=?str.length();//?2.?mapToInt(),?轉(zhuǎn)換成長(zhǎng)度
????????longest?=?Math.max(len,?longest);//?3.?max(),?保留最長(zhǎng)的長(zhǎng)度
????}
}
采用這種方式我們不但減少了迭代次數(shù),也避免了存儲(chǔ)中間結(jié)果,顯然這就是流水線,因?yàn)槲覀儼讶齻€(gè)操作放在了一次迭代當(dāng)中。只要我們事先知道用戶意圖,總是能夠采用上述方式實(shí)現(xiàn)跟Stream API等價(jià)的功能,但問(wèn)題是Stream類(lèi)庫(kù)的設(shè)計(jì)者并不知道用戶的意圖是什么。
如何在無(wú)法假設(shè)用戶行為的前提下實(shí)現(xiàn)流水線,是類(lèi)庫(kù)的設(shè)計(jì)者要考慮的問(wèn)題。
面試題推薦:100期面試題匯總
Stream流水線解決方案
我們大致能夠想到,應(yīng)該采用某種方式記錄用戶每一步的操作,當(dāng)用戶調(diào)用結(jié)束操作時(shí)將之前記錄的操作疊加到一起在一次迭代中全部執(zhí)行掉。沿著這個(gè)思路,有幾個(gè)問(wèn)題需要解決:
用戶的操作如何記錄? 操作如何疊加? 疊加之后的操作如何執(zhí)行? 執(zhí)行后的結(jié)果(如果有)在哪里?
>> 操作如何記錄
注意這里使用的是“操作(operation)”一詞,指的是“Stream中間操作”的操作,很多Stream操作會(huì)需要一個(gè)回調(diào)函數(shù)(Lambda表達(dá)式),因此一個(gè)完整的操作是<數(shù)據(jù)來(lái)源,操作,回調(diào)函數(shù)>構(gòu)成的三元組。
Stream中使用Stage的概念來(lái)描述一個(gè)完整的操作,并用某種實(shí)例化后的PipelineHelper來(lái)代表Stage,將具有先后順序的各個(gè)Stage連到一起,就構(gòu)成了整個(gè)流水線。跟Stream相關(guān)類(lèi)和接口的繼承關(guān)系圖示。
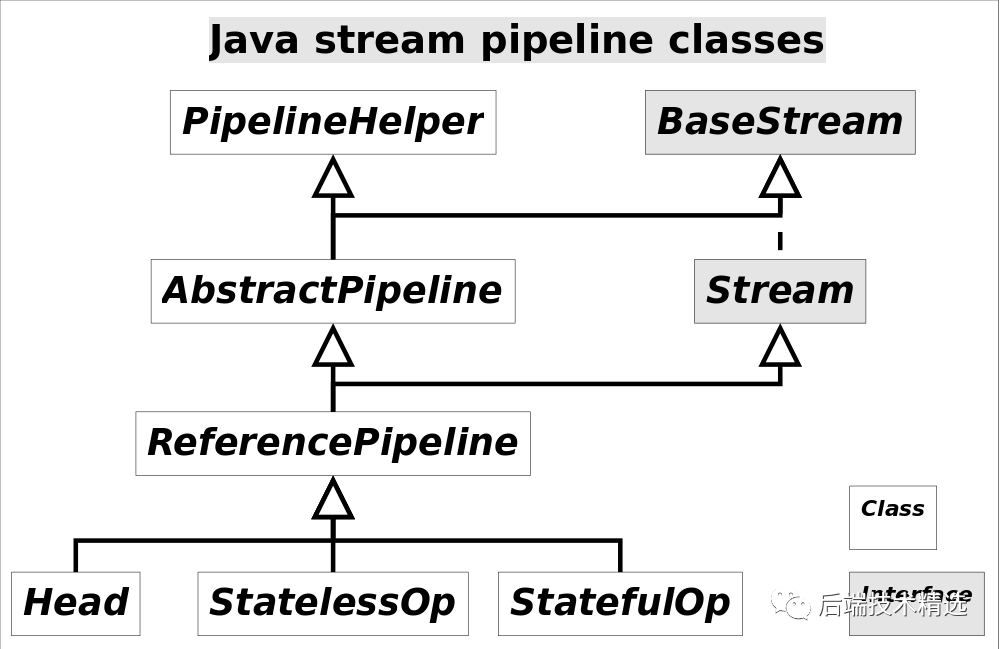
還有IntPipeline, LongPipeline, DoublePipeline沒(méi)在圖中畫(huà)出,這三個(gè)類(lèi)專(zhuān)門(mén)為三種基本類(lèi)型(不是包裝類(lèi)型)而定制的,跟ReferencePipeline是并列關(guān)系。
圖中Head用于表示第一個(gè)Stage,即調(diào)用調(diào)用諸如Collection.stream()方法產(chǎn)生的Stage,很顯然這個(gè)Stage里不包含任何操作;StatelessOp和StatefulOp分別表示無(wú)狀態(tài)和有狀態(tài)的Stage,對(duì)應(yīng)于無(wú)狀態(tài)和有狀態(tài)的中間操作。
Stream流水線組織結(jié)構(gòu)示意圖如下:
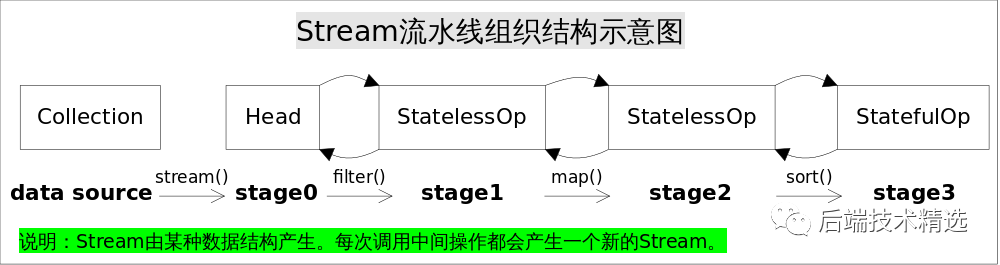
圖中通過(guò)Collection.stream()方法得到Head也就是stage0,緊接著調(diào)用一系列的中間操作,不斷產(chǎn)生新的Stream。這些Stream對(duì)象以雙向鏈表的形式組織在一起,構(gòu)成整個(gè)流水線,由于每個(gè)Stage都記錄了前一個(gè)Stage和本次的操作以及回調(diào)函數(shù),依靠這種結(jié)構(gòu)就能建立起對(duì)數(shù)據(jù)源的所有操作。這就是Stream記錄操作的方式。
>> 操作如何疊加
以上只是解決了操作記錄的問(wèn)題,要想讓流水線起到應(yīng)有的作用我們需要一種將所有操作疊加到一起的方案。你可能會(huì)覺(jué)得這很簡(jiǎn)單,只需要從流水線的head開(kāi)始依次執(zhí)行每一步的操作(包括回調(diào)函數(shù))就行了。
這聽(tīng)起來(lái)似乎是可行的,但是你忽略了前面的Stage并不知道后面Stage到底執(zhí)行了哪種操作,以及回調(diào)函數(shù)是哪種形式。換句話說(shuō),只有當(dāng)前Stage本身才知道該如何執(zhí)行自己包含的動(dòng)作。這就需要有某種協(xié)議來(lái)協(xié)調(diào)相鄰Stage之間的調(diào)用關(guān)系。
這種協(xié)議由Sink接口完成,Sink接口包含的方法如下表所示:
| 方法名 | 作用 |
| void begin(long size) | 開(kāi)始遍歷元素之前調(diào)用該方法,通知Sink做好準(zhǔn)備。 |
| void end() | 所有元素遍歷完成之后調(diào)用,通知Sink沒(méi)有更多的元素了。 |
| boolean cancellationRequested() | 是否可以結(jié)束操作,可以讓短路操作盡早結(jié)束。 |
| void accept(T t) | 遍歷元素時(shí)調(diào)用,接受一個(gè)待處理元素,并對(duì)元素進(jìn)行處理。Stage把自己包含的操作和回調(diào)方法封裝到該方法里,前一個(gè)Stage只需要調(diào)用當(dāng)前Stage.accept(T t)方法就行了。 |
有了上面的協(xié)議,相鄰Stage之間調(diào)用就很方便了,每個(gè)Stage都會(huì)將自己的操作封裝到一個(gè)Sink里,前一個(gè)Stage只需調(diào)用后一個(gè)Stage的accept()方法即可,并不需要知道其內(nèi)部是如何處理的。
當(dāng)然對(duì)于有狀態(tài)的操作,Sink的begin()和end()方法也是必須實(shí)現(xiàn)的。比如Stream.sorted()是一個(gè)有狀態(tài)的中間操作,其對(duì)應(yīng)的Sink.begin()方法可能創(chuàng)建一個(gè)盛放結(jié)果的容器,而accept()方法負(fù)責(zé)將元素添加到該容器,最后end()負(fù)責(zé)對(duì)容器進(jìn)行排序。
對(duì)于短路操作,Sink.cancellationRequested()也是必須實(shí)現(xiàn)的,比如Stream.findFirst()是短路操作,只要找到一個(gè)元素,cancellationRequested()就應(yīng)該返回true,以便調(diào)用者盡快結(jié)束查找。Sink的四個(gè)接口方法常常相互協(xié)作,共同完成計(jì)算任務(wù)。
實(shí)際上Stream API內(nèi)部實(shí)現(xiàn)的的本質(zhì),就是如何重寫(xiě)Sink的這四個(gè)接口方法。
有了Sink對(duì)操作的包裝,Stage之間的調(diào)用問(wèn)題就解決了,執(zhí)行時(shí)只需要從流水線的head開(kāi)始對(duì)數(shù)據(jù)源依次調(diào)用每個(gè)Stage對(duì)應(yīng)的Sink.{begin(), accept(), cancellationRequested(), end()}方法就可以了。一種可能的Sink.accept()方法流程是這樣的:
void?accept(U?u){
????1.?使用當(dāng)前Sink包裝的回調(diào)函數(shù)處理u
????2.?將處理結(jié)果傳遞給流水線下游的Sink
}
Sink接口的其他幾個(gè)方法也是按照這種[處理->轉(zhuǎn)發(fā)]的模型實(shí)現(xiàn)。
下面我們結(jié)合具體例子看看Stream的中間操作是如何將自身的操作包裝成Sink以及Sink是如何將處理結(jié)果轉(zhuǎn)發(fā)給下一個(gè)Sink的。先看Stream.map()方法:
//?Stream.map(),調(diào)用該方法將產(chǎn)生一個(gè)新的Stream
public?final??Stream?map(Functionsuper?P_OUT,???extends?R>?mapper) ?{
????...
????return?new?StatelessOp(this,?StreamShape.REFERENCE,
?????????????????????????????????StreamOpFlag.NOT_SORTED?|?StreamOpFlag.NOT_DISTINCT)?{
????????@Override?/*opWripSink()方法返回由回調(diào)函數(shù)包裝而成Sink*/
????????Sink?opWrapSink(int?flags,?Sink?downstream) ? {
????????????return?new?Sink.ChainedReference(downstream)?{
????????????????@Override
????????????????public?void?accept(P_OUT?u)?{
????????????????????R?r?=?mapper.apply(u);//?1.?使用當(dāng)前Sink包裝的回調(diào)函數(shù)mapper處理u
????????????????????downstream.accept(r);//?2.?將處理結(jié)果傳遞給流水線下游的Sink
????????????????}
????????????};
????????}
????};
}
上述代碼看似復(fù)雜,其實(shí)邏輯很簡(jiǎn)單,就是將回調(diào)函數(shù)mapper包裝到一個(gè)Sink當(dāng)中。由于Stream.map()是一個(gè)無(wú)狀態(tài)的中間操作,所以map()方法返回了一個(gè)StatelessOp內(nèi)部類(lèi)對(duì)象(一個(gè)新的Stream),調(diào)用這個(gè)新Stream的opWripSink()方法將得到一個(gè)包裝了當(dāng)前回調(diào)函數(shù)的Sink。
再來(lái)看一個(gè)復(fù)雜一點(diǎn)的例子。Stream.sorted()方法將對(duì)Stream中的元素進(jìn)行排序,顯然這是一個(gè)有狀態(tài)的中間操作,因?yàn)樽x取所有元素之前是沒(méi)法得到最終順序的。拋開(kāi)模板代碼直接進(jìn)入問(wèn)題本質(zhì),sorted()方法是如何將操作封裝成Sink的呢?sorted()一種可能封裝的Sink代碼如下:
//?Stream.sort()方法用到的Sink實(shí)現(xiàn)
class?RefSortingSink<T>?extends?AbstractRefSortingSink<T>?{
????private?ArrayList?list;//?存放用于排序的元素
????RefSortingSink(Sinksuper?T>?downstream,?Comparatorsuper?T>?comparator)?{
????????super(downstream,?comparator);
????}
????@Override
????public?void?begin(long?size)?{
????????...
????????//?創(chuàng)建一個(gè)存放排序元素的列表
????????list?=?(size?>=?0)???new?ArrayList((int)?size)?:?new?ArrayList();
????}
????@Override
????public?void?end()?{
????????list.sort(comparator);//?只有元素全部接收之后才能開(kāi)始排序
????????downstream.begin(list.size());
????????if?(!cancellationWasRequested)?{//?下游Sink不包含短路操作
????????????list.forEach(downstream::accept);//?2.?將處理結(jié)果傳遞給流水線下游的Sink
????????}
????????else?{//?下游Sink包含短路操作
????????????for?(T?t?:?list)?{//?每次都調(diào)用cancellationRequested()詢問(wèn)是否可以結(jié)束處理。
????????????????if?(downstream.cancellationRequested())?break;
????????????????downstream.accept(t);//?2.?將處理結(jié)果傳遞給流水線下游的Sink
????????????}
????????}
????????downstream.end();
????????list?=?null;
????}
????@Override
????public?void?accept(T?t)?{
????????list.add(t);//?1.?使用當(dāng)前Sink包裝動(dòng)作處理t,只是簡(jiǎn)單的將元素添加到中間列表當(dāng)中
????}
}
上述代碼完美的展現(xiàn)了Sink的四個(gè)接口方法是如何協(xié)同工作的:
首先begin()方法告訴Sink參與排序的元素個(gè)數(shù),方便確定中間結(jié)果容器的的大小; 之后通過(guò)accept()方法將元素添加到中間結(jié)果當(dāng)中,最終執(zhí)行時(shí)調(diào)用者會(huì)不斷調(diào)用該方法,直到遍歷所有元素; 最后end()方法告訴Sink所有元素遍歷完畢,啟動(dòng)排序步驟,排序完成后將結(jié)果傳遞給下游的Sink; 如果下游的Sink是短路操作,將結(jié)果傳遞給下游時(shí)不斷詢問(wèn)下游cancellationRequested()是否可以結(jié)束處理。
>> 疊加之后的操作如何執(zhí)行
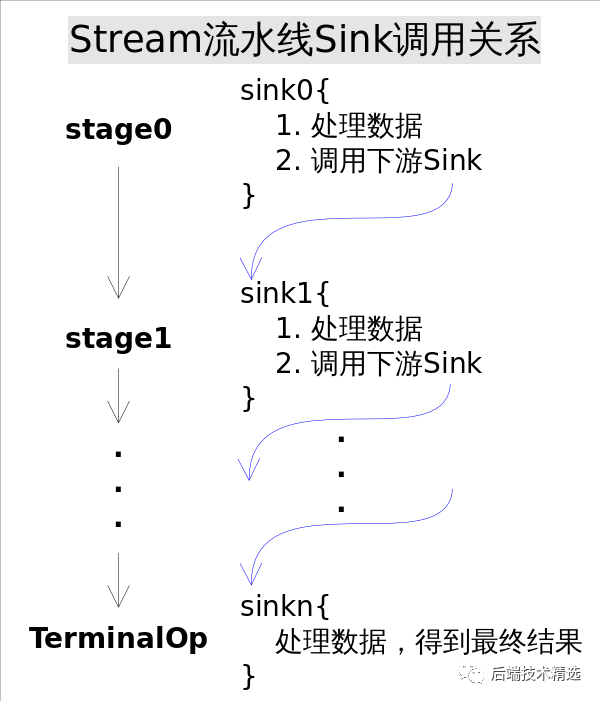
Sink完美封裝了Stream每一步操作,并給出了[處理->轉(zhuǎn)發(fā)]的模式來(lái)疊加操作。這一連串的齒輪已經(jīng)咬合,就差最后一步撥動(dòng)齒輪啟動(dòng)執(zhí)行。
是什么啟動(dòng)這一連串的操作呢?也許你已經(jīng)想到了啟動(dòng)的原始動(dòng)力就是結(jié)束操作(Terminal Operation),一旦調(diào)用某個(gè)結(jié)束操作,就會(huì)觸發(fā)整個(gè)流水線的執(zhí)行。
結(jié)束操作之后不能再有別的操作,所以結(jié)束操作不會(huì)創(chuàng)建新的流水線階段(Stage),直觀的說(shuō)就是流水線的鏈表不會(huì)在往后延伸了。
結(jié)束操作會(huì)創(chuàng)建一個(gè)包裝了自己操作的Sink,這也是流水線中最后一個(gè)Sink,這個(gè)Sink只需要處理數(shù)據(jù)而不需要將結(jié)果傳遞給下游的Sink(因?yàn)闆](méi)有下游)。對(duì)于Sink的[處理->轉(zhuǎn)發(fā)]模型,結(jié)束操作的Sink就是調(diào)用鏈的出口。
我們?cè)賮?lái)考察一下上游的Sink是如何找到下游Sink的。一種可選的方案是在PipelineHelper中設(shè)置一個(gè)Sink字段,在流水線中找到下游Stage并訪問(wèn)Sink字段即可。
但Stream類(lèi)庫(kù)的設(shè)計(jì)者沒(méi)有這么做,而是設(shè)置了一個(gè)Sink AbstractPipeline.opWrapSink(int flags, Sink downstream)方法來(lái)得到Sink,該方法的作用是返回一個(gè)新的包含了當(dāng)前Stage代表的操作以及能夠?qū)⒔Y(jié)果傳遞給downstream的Sink對(duì)象。為什么要產(chǎn)生一個(gè)新對(duì)象而不是返回一個(gè)Sink字段?
這是因?yàn)槭褂胦pWrapSink()可以將當(dāng)前操作與下游Sink(上文中的downstream參數(shù))結(jié)合成新Sink。試想只要從流水線的最后一個(gè)Stage開(kāi)始,不斷調(diào)用上一個(gè)Stage的opWrapSink()方法直到最開(kāi)始(不包括stage0,因?yàn)閟tage0代表數(shù)據(jù)源,不包含操作),就可以得到一個(gè)代表了流水線上所有操作的Sink,用代碼表示就是這樣:
//?AbstractPipeline.wrapSink()
//?從下游向上游不斷包裝Sink。如果最初傳入的sink代表結(jié)束操作,
//?函數(shù)返回時(shí)就可以得到一個(gè)代表了流水線上所有操作的Sink。
final??Sink?wrapSink(Sink?sink) ? {
????...
????for?(AbstractPipeline?p=AbstractPipeline.this;?p.depth?>?0;?p=p.previousStage)?{
????????sink?=?p.opWrapSink(p.previousStage.combinedFlags,?sink);
????}
????return?(Sink)?sink;
}
現(xiàn)在流水線上從開(kāi)始到結(jié)束的所有的操作都被包裝到了一個(gè)Sink里,執(zhí)行這個(gè)Sink就相當(dāng)于執(zhí)行整個(gè)流水線,執(zhí)行Sink的代碼如下:
// AbstractPipeline.copyInto(), 對(duì)spliterator代表的數(shù)據(jù)執(zhí)行wrappedSink代表的操作。
final??void?copyInto(Sink?wrappedSink,?Spliterator?spliterator) ?{
????...
????if?(!StreamOpFlag.SHORT_CIRCUIT.isKnown(getStreamAndOpFlags()))?{
????????wrappedSink.begin(spliterator.getExactSizeIfKnown());//?通知開(kāi)始遍歷
????????spliterator.forEachRemaining(wrappedSink);//?迭代
????????wrappedSink.end();//?通知遍歷結(jié)束
????}
????...
}
上述代碼首先調(diào)用wrappedSink.begin()方法告訴Sink數(shù)據(jù)即將到來(lái),然后調(diào)用spliterator.forEachRemaining()方法對(duì)數(shù)據(jù)進(jìn)行迭代,最后調(diào)用wrappedSink.end()方法通知Sink數(shù)據(jù)處理結(jié)束。邏輯如此清晰。后端技術(shù)精選公眾號(hào)內(nèi)回復(fù)“后端面試”,送你一份Java面試題寶典
>> 執(zhí)行后的結(jié)果在哪里
最后一個(gè)問(wèn)題是流水線上所有操作都執(zhí)行后,用戶所需要的結(jié)果(如果有)在哪里?首先要說(shuō)明的是不是所有的Stream結(jié)束操作都需要返回結(jié)果,有些操作只是為了使用其副作用(Side-effects),比如使用Stream.forEach()方法將結(jié)果打印出來(lái)就是常見(jiàn)的使用副作用的場(chǎng)景(事實(shí)上,除了打印之外其他場(chǎng)景都應(yīng)避免使用副作用),對(duì)于真正需要返回結(jié)果的結(jié)束操作結(jié)果存在哪里呢?
特別說(shuō)明:副作用不應(yīng)該被濫用,也許你會(huì)覺(jué)得在Stream.forEach()里進(jìn)行元素收集是個(gè)不錯(cuò)的選擇,就像下面代碼中那樣,但遺憾的是這樣使用的正確性和效率都無(wú)法保證,因?yàn)镾tream可能會(huì)并行執(zhí)行。大多數(shù)使用副作用的地方都可以使用歸約操作更安全和有效的完成。
//?錯(cuò)誤的收集方式
ArrayList?results?=?new?ArrayList<>();
stream.filter(s?->?pattern.matcher(s).matches())
??????.forEach(s?->?results.add(s));??//?Unnecessary?use?of?side-effects!
//?正確的收集方式
Listresults?=
?????stream.filter(s?->?pattern.matcher(s).matches())
?????????????.collect(Collectors.toList());??//?No?side-effects!
回到流水線執(zhí)行結(jié)果的問(wèn)題上來(lái),需要返回結(jié)果的流水線結(jié)果存在哪里呢?這要分不同的情況討論,下表給出了各種有返回結(jié)果的Stream結(jié)束操作。
| 返回類(lèi)型 | 對(duì)應(yīng)的結(jié)束操作 |
| boolean | anyMatch() allMatch() noneMatch() |
| Optional | findFirst() findAny() |
| 歸約結(jié)果 | reduce() collect() |
| 數(shù)組 | toArray() |
對(duì)于表中返回boolean或者Optional的操作(Optional是存放 一個(gè) 值的容器)的操作,由于值返回一個(gè)值,只需要在對(duì)應(yīng)的Sink中記錄這個(gè)值,等到執(zhí)行結(jié)束時(shí)返回就可以了。 對(duì)于歸約操作,最終結(jié)果放在用戶調(diào)用時(shí)指定的容器中(容器類(lèi)型通過(guò)收集器指定)。collect(), reduce(), max(), min()都是歸約操作,雖然max()和min()也是返回一個(gè)Optional,但事實(shí)上底層是通過(guò)調(diào)用reduce()方法實(shí)現(xiàn)的。 對(duì)于返回是數(shù)組的情況,毫無(wú)疑問(wèn)的結(jié)果會(huì)放在數(shù)組當(dāng)中。這么說(shuō)當(dāng)然是對(duì)的,但在最終返回?cái)?shù)組之前,結(jié)果其實(shí)是存儲(chǔ)在一種叫做Node的數(shù)據(jù)結(jié)構(gòu)中的。Node是一種多叉樹(shù)結(jié)構(gòu),元素存儲(chǔ)在樹(shù)的葉子當(dāng)中,并且一個(gè)葉子節(jié)點(diǎn)可以存放多個(gè)元素。這樣做是為了并行執(zhí)行方便。關(guān)于Node的具體結(jié)構(gòu),我們會(huì)在下一節(jié)探究Stream如何并行執(zhí)行時(shí)給出詳細(xì)說(shuō)明。
結(jié)語(yǔ)
本文詳細(xì)介紹了Stream流水線的組織方式和執(zhí)行過(guò)程,學(xué)習(xí)本文將有助于理解原理并寫(xiě)出正確的Stream代碼,同時(shí)打消你對(duì)Stream API效率方面的顧慮。如你所見(jiàn),Stream API實(shí)現(xiàn)如此巧妙,即使我們使用外部迭代手動(dòng)編寫(xiě)等價(jià)代碼,也未必更加高效。
注:留下本文所用的JDK版本,以便有考究癖的人考證:
$?java?-version
java?version?"1.8.0_101"
Java(TM)?SE?Runtime?Environment?(build?1.8.0_101-b13)
Java?HotSpot(TM)?Server?VM?(build?25.101-b13,?mixed?mode)