
聲音,無限可能

by design-ai-lab


eva
(O_O)?
提供某人的一段講話音頻,你可以從兩張人臉圖像中判斷出哪個是說話人嗎?
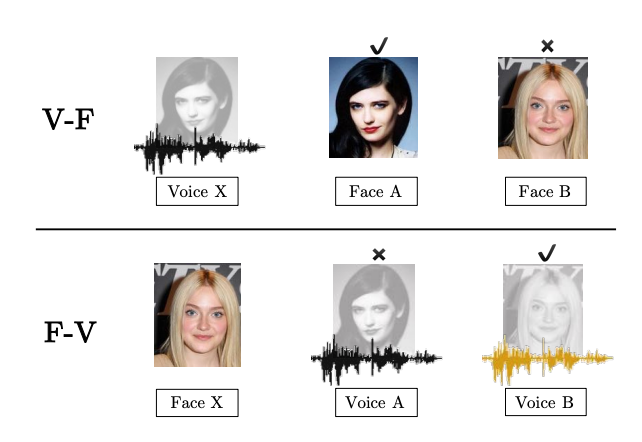
來自論文:
Seeing Voices and Hearing Faces: Cross-modal biometric matching
類似于“相由心生”,聲音也是和面相有相關性的。
聲音和其他模態(tài)信息的關聯(lián)度,或者互動,真的非常有意思~~
@知識庫

shadow

知識庫
來啦~~
我們先從聲音與健康說起~~

國際期刊《柳葉刀》有一篇《通過你的聲音能診斷疾病嗎?》
利用AI技術,可以通過個人設備,如手機、平板電腦等快速診斷疾病。關鍵技術是AI識別和處理人類的各種聲音模式,包括音高、音調(diào)、節(jié)奏,呼吸輕緩、咳嗽等。這將極大改善醫(yī)療健康的服務模式,但在實踐中仍需大量的數(shù)據(jù)驗證。
VoiceWise
準確率高達95%
第一性原理:如果器官生病了,人的聲音就會發(fā)生改變。
羅馬Tor Vergata大學教授Giovanni Saggio開發(fā)了VoiceWise,該系統(tǒng)分析用戶的聲音,通過AI將6300個聲音值與某些病理狀態(tài)的聲音值進行比較,從而診斷所患的病理。
 聽聲把脈!
聽聲把脈!
shadow

無界
 引用我超喜歡程序猿的一句diss用語:
引用我超喜歡程序猿的一句diss用語:
Talk is cheap ,
show me the code
知識庫
還有音樂、互動體驗方面的應用。@無界 這兩個都是開源的。
有代碼……
?? DeepSlayerXL
這是一個音樂專輯,基于Transformer-XL語言模型,學習了3604首俄羅斯MIDI歌曲的特征,自動生成金屬音樂,除了音樂本身,作者還使用了GPT-3來生成各種各樣的點評。
“DeepSlayerXL創(chuàng)作的曲目,聽來還真有點意思,非常符合外行人對搖滾樂的印象”

?? 谷歌Body Synth
Make music just by moving your body
用攝像頭和AI識別人體姿態(tài),然后通過肢體運動產(chǎn)生不同音色的音調(diào),從而生成音樂。

音樂的創(chuàng)作過程其實也有組合:
將一小段音樂想法拼接和混搭起來創(chuàng)造出有趣的結合,并隨著時間的進行變化多樣。
shadow

opus
感謝今天的Mix分享~~
??????
如果對以上話題感興趣
???????????????????????????????
歡迎加入社群,
關注后回復:群聊 ??
