
前端10大經(jīng)典算法

來源 |?https://segmentfault.com/a/1190000020072884
算法概述
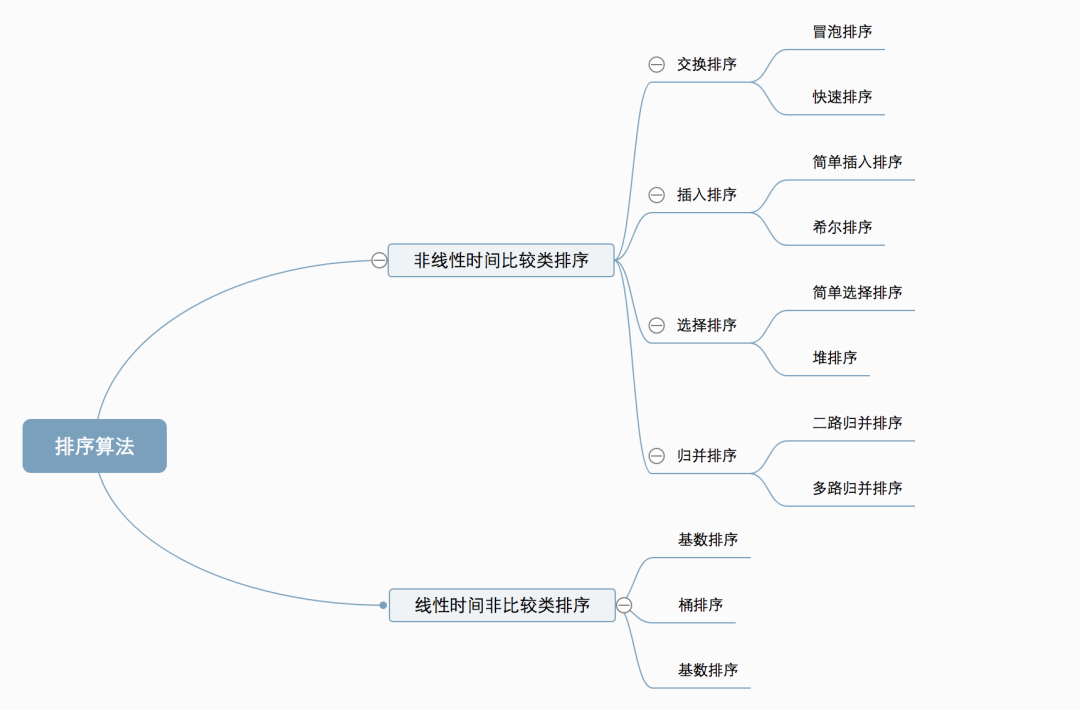
算法分類
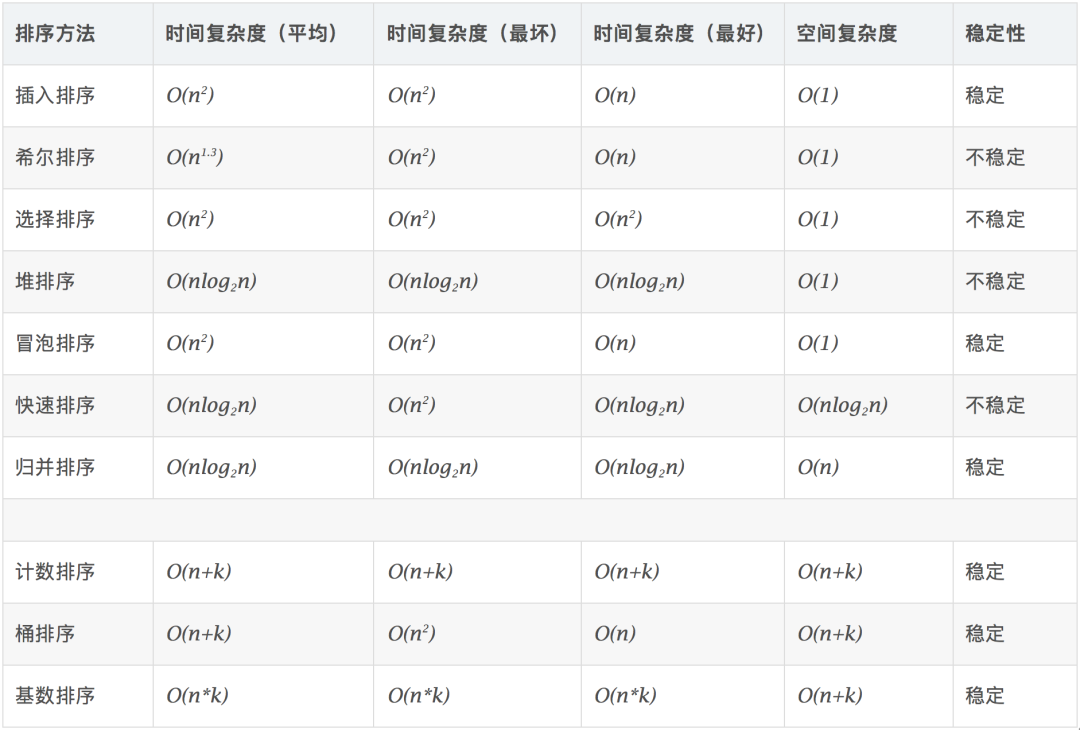
算法復(fù)雜度
相關(guān)概念
穩(wěn)定:如果a原本在b前面,而a=b,排序之后a仍然在b的前面。
不穩(wěn)定:如果a原本在b的前面,而a=b,排序之后 a 可能會出現(xiàn)在 b 的后面。
時間復(fù)雜度:對排序數(shù)據(jù)的總的操作次數(shù)。反映當(dāng)n變化時,操作次數(shù)呈現(xiàn)什么規(guī)律。
空間復(fù)雜度:是指算法在計算機(jī)內(nèi)執(zhí)行時所需存儲空間的度量,它也是數(shù)據(jù)規(guī)模n的函數(shù)。
1、冒泡排序(Bubble Sort)
冒泡排序是一種簡單的排序算法。它重復(fù)地走訪過要排序的數(shù)列,一次比較兩個元素,如果它們的順序錯誤就把它們交換過來。走訪數(shù)列的工作是重復(fù)地進(jìn)行直到?jīng)]有再需要交換,也就是說該數(shù)列已經(jīng)排序完成。這個算法的名字由來是因為越小的元素會經(jīng)由交換慢慢“浮”到數(shù)列的頂端。
1.1 算法描述
比較相鄰的元素。如果第一個比第二個大,就交換它們兩個;
對每一對相鄰元素作同樣的工作,從開始第一對到結(jié)尾的最后一對,這樣在最后的元素應(yīng)該會是最大的數(shù);
針對所有的元素重復(fù)以上的步驟,除了最后一個;
重復(fù)步驟1~3,直到排序完成。
1.2 動圖演示
1.3 代碼實(shí)現(xiàn)
function bubbleSort(arr) {var len = arr.length;for (var i = 0; i < len - 1; i++) {for (var j = 0; j < len - 1 - i; j++) {if (arr[j] > arr[j+1]) { // 相鄰元素兩兩對比var temp = arr[j+1]; // 元素交換arr[j+1] = arr[j];arr[j] = temp;}}}return arr;}
2、選擇排序(Selection Sort)
選擇排序(Selection-sort)是一種簡單直觀的排序算法。它的工作原理:首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置,然后,再從剩余未排序元素中繼續(xù)尋找最小(大)元素,然后放到已排序序列的末尾。以此類推,直到所有元素均排序完畢。
2.1 算法描述
n個記錄的直接選擇排序可經(jīng)過n-1趟直接選擇排序得到有序結(jié)果。具體算法描述如下:
初始狀態(tài):無序區(qū)為R[1..n],有序區(qū)為空;
第i趟排序(i=1,2,3…n-1)開始時,當(dāng)前有序區(qū)和無序區(qū)分別為R[1..i-1]和R(i..n)。該趟排序從當(dāng)前無序區(qū)中-選出關(guān)鍵字最小的記錄 R[k],將它與無序區(qū)的第1個記錄R交換,使R[1..i]和R[i+1..n)分別變?yōu)橛涗泜€數(shù)增加1個的新有序區(qū)和記錄個數(shù)減少1個的新無序區(qū);
n-1趟結(jié)束,數(shù)組有序化了。
2.2?代碼實(shí)現(xiàn)
function selectionSort(arr) {var len = arr.length;var minIndex, temp;for (var i = 0; i < len - 1; i++) {minIndex = i;for (var j = i + 1; j < len; j++) {if (arr[j] < arr[minIndex]) { // 尋找最小的數(shù)minIndex = j; // 將最小數(shù)的索引保存}}temp = arr[i];arr[i] = arr[minIndex];arr[minIndex] = temp;}return arr;}
2.3?算法分析
表現(xiàn)最穩(wěn)定的排序算法之一,因為無論什么數(shù)據(jù)進(jìn)去都是O(n2)的時間復(fù)雜度,所以用到它的時候,數(shù)據(jù)規(guī)模越小越好。唯一的好處可能就是不占用額外的內(nèi)存空間了吧。理論上講,選擇排序可能也是平時排序一般人想到的最多的排序方法了吧。
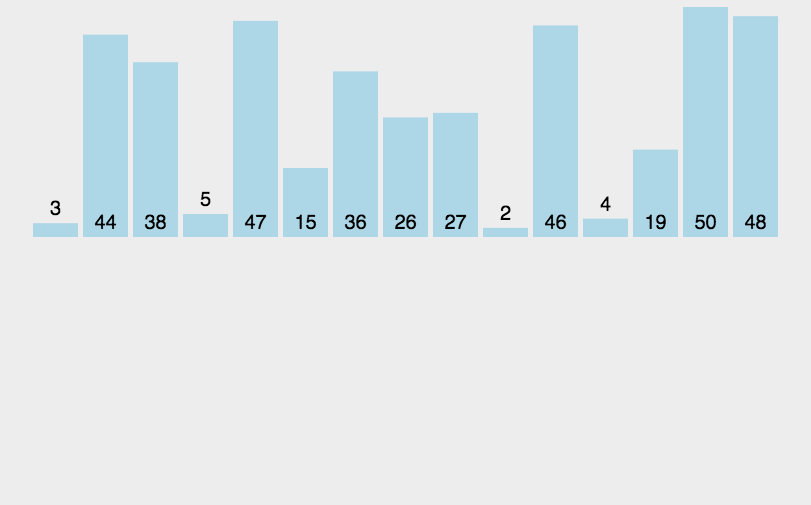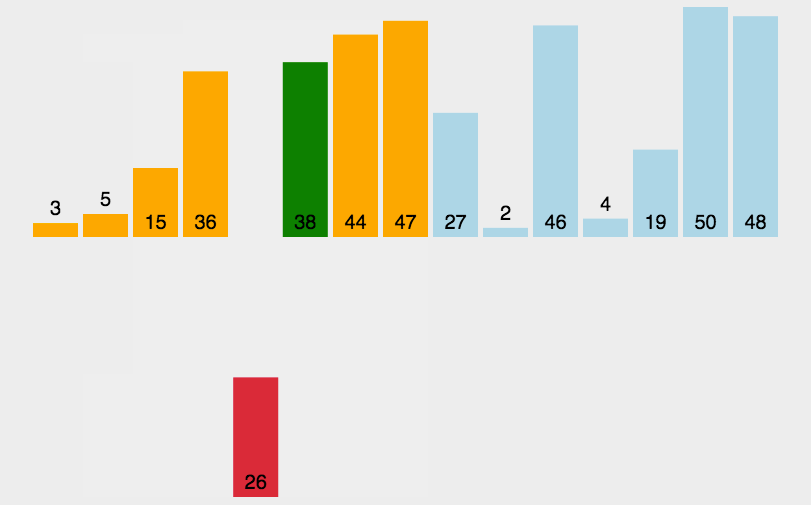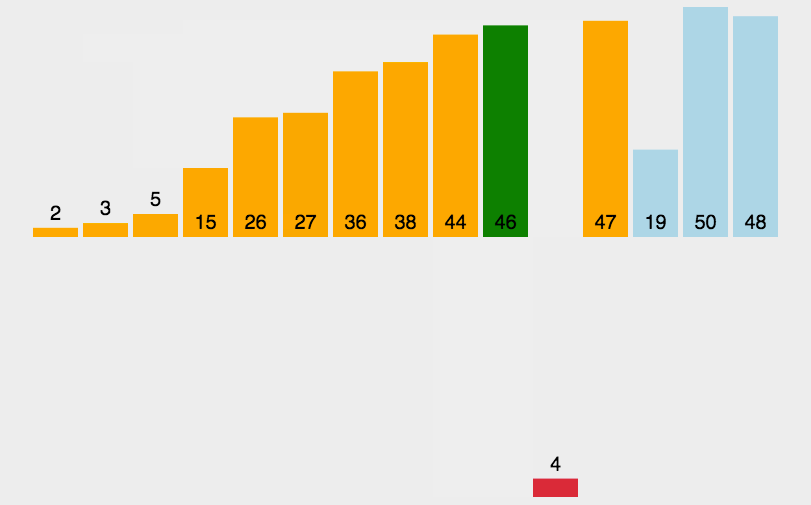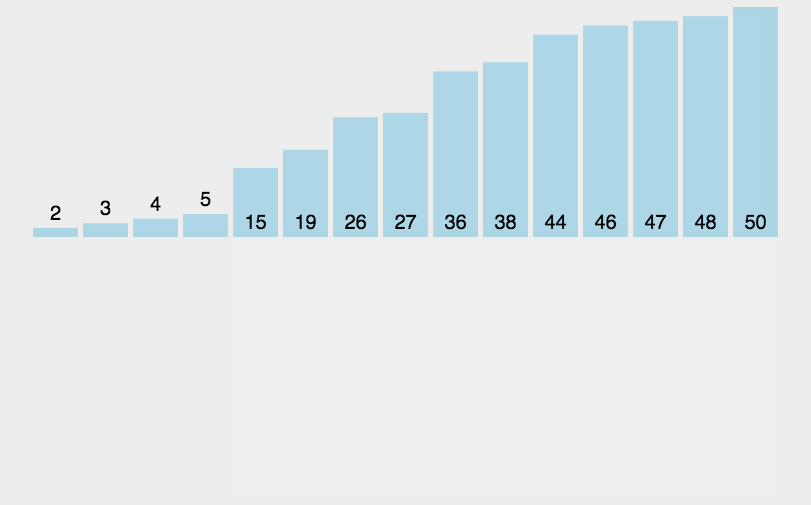
3、插入排序(Insertion Sort)
插入排序(Insertion-Sort)的算法描述是一種簡單直觀的排序算法。它的工作原理是通過構(gòu)建有序序列,對于未排序數(shù)據(jù),在已排序序列中從后向前掃描,找到相應(yīng)位置并插入。
3.1 算法描述
一般來說,插入排序都采用in-place在數(shù)組上實(shí)現(xiàn)。具體算法描述如下:
從第一個元素開始,該元素可以認(rèn)為已經(jīng)被排序;
取出下一個元素,在已經(jīng)排序的元素序列中從后向前掃描;
如果該元素(已排序)大于新元素,將該元素移到下一位置;
重復(fù)步驟3,直到找到已排序的元素小于或者等于新元素的位置;
將新元素插入到該位置后;
重復(fù)步驟2~5。
3.2 動圖演示
3.2 代碼實(shí)現(xiàn)
function insertionSort(arr) {var len = arr.length;var preIndex, current;for (var i = 1; i < len; i++) {preIndex = i - 1;current = arr[i];while (preIndex >= 0 && arr[preIndex] > current) {arr[preIndex + 1] = arr[preIndex];preIndex--;}arr[preIndex + 1] = current;}return arr;}
3.4 算法分析
插入排序在實(shí)現(xiàn)上,通常采用in-place排序(即只需用到O(1)的額外空間的排序),因而在從后向前掃描過程中,需要反復(fù)把已排序元素逐步向后挪位,為最新元素提供插入空間。
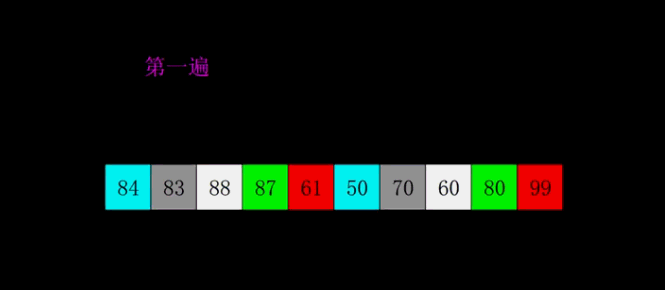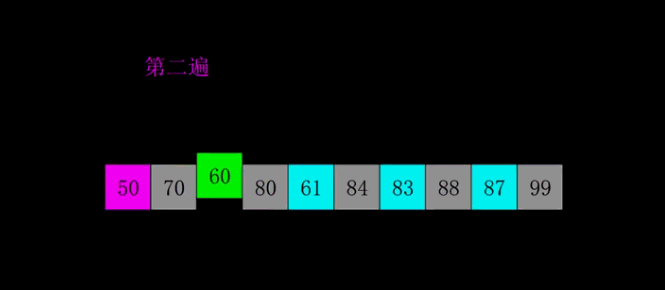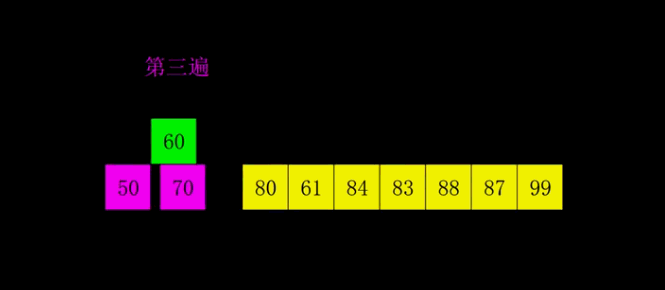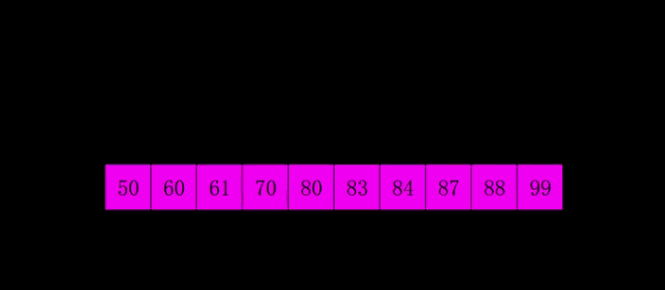
4、希爾排序(Shell Sort)
1959年Shell發(fā)明,第一個突破O(n2)的排序算法,是簡單插入排序的改進(jìn)版。它與插入排序的不同之處在于,它會優(yōu)先比較距離較遠(yuǎn)的元素。希爾排序又叫縮小增量排序。
4.1 算法描述
先將整個待排序的記錄序列分割成為若干子序列分別進(jìn)行直接插入排序,具體算法描述:
選擇一個增量序列t1,t2,…,tk,其中ti>tj,tk=1;
按增量序列個數(shù)k,對序列進(jìn)行k 趟排序;
每趟排序,根據(jù)對應(yīng)的增量ti,將待排序列分割成若干長度為m 的子序列,分別對各子表進(jìn)行直接插入排序。僅增量因子為1 時,整個序列作為一個表來處理,表長度即為整個序列的長度。
4.2 動圖演示
4.3 代碼實(shí)現(xiàn)
function shellSort(arr) {var len = arr.length,temp,gap = 1;while (gap < len / 3) { // 動態(tài)定義間隔序列gap = gap * 3 + 1;}for (gap; gap > 0; gap = Math.floor(gap / 3)) {for (var i = gap; i < len; i++) {temp = arr[i];for (var j = i-gap; j > 0 && arr[j]> temp; j-=gap) {arr[j + gap] = arr[j];}arr[j + gap] = temp;}}return arr;}
4.4 算法分析
希爾排序的核心在于間隔序列的設(shè)定。既可以提前設(shè)定好間隔序列,也可以動態(tài)的定義間隔序列。動態(tài)定義間隔序列的算法是《算法(第4版)》的合著者Robert Sedgewick提出的。
5、歸并排序(Merge Sort)
歸并排序是建立在歸并操作上的一種有效的排序算法。該算法是采用分治法(Divide and Conquer)的一個非常典型的應(yīng)用。將已有序的子序列合并,得到完全有序的序列;即先使每個子序列有序,再使子序列段間有序。若將兩個有序表合并成一個有序表,稱為2-路歸并。
5.1 算法描述
把長度為n的輸入序列分成兩個長度為n/2的子序列;
對這兩個子序列分別采用歸并排序;
將兩個排序好的子序列合并成一個最終的排序序列。
5.2 動圖演示
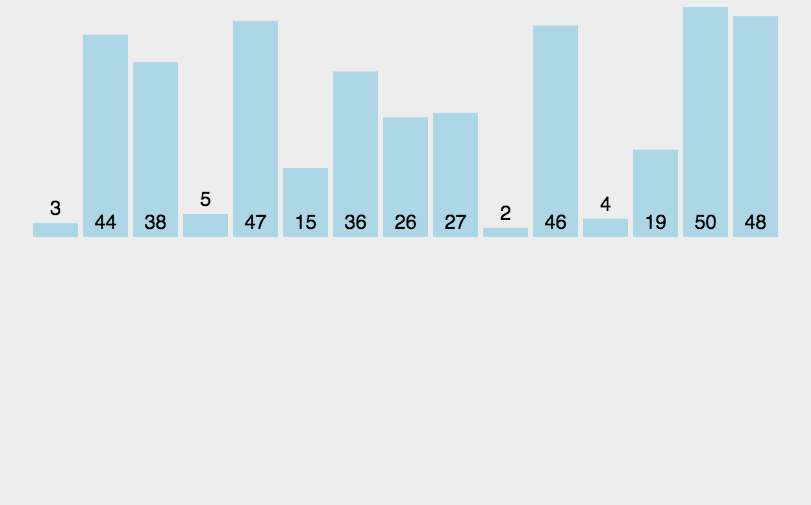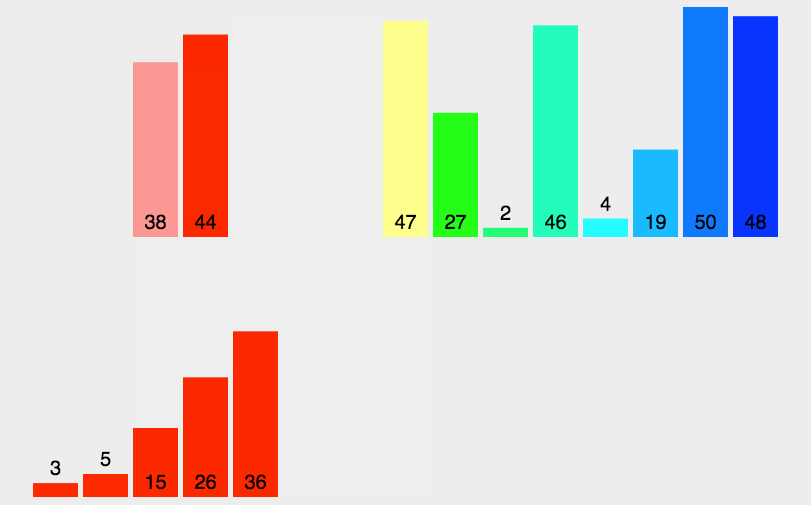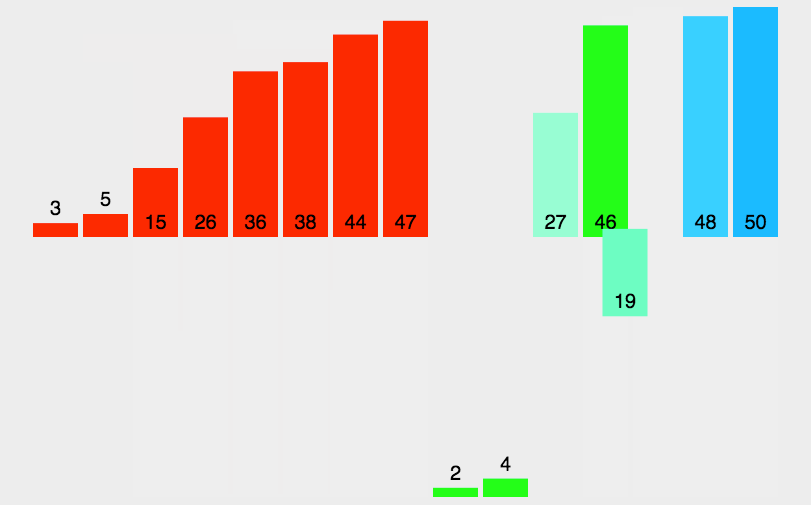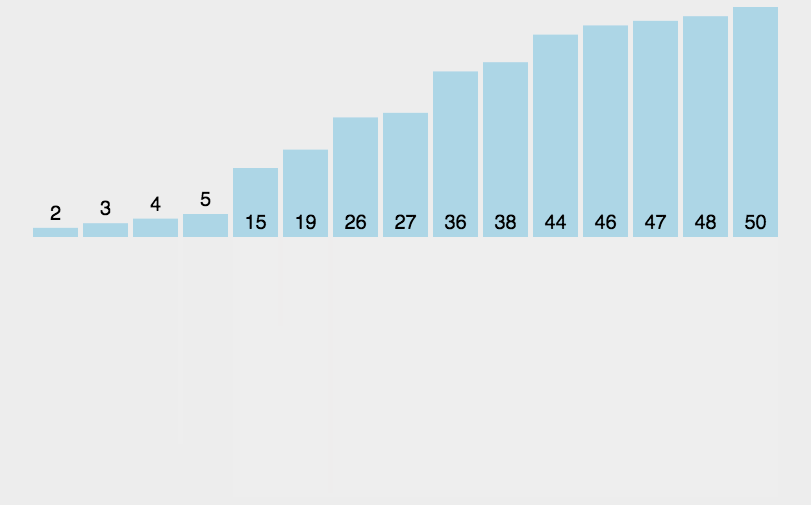
5.3 代碼實(shí)現(xiàn)
function mergeSort(arr) { // 采用自上而下的遞歸方法var len = arr.length;if (len < 2) {return arr;}var middle = Math.floor(len / 2),left = arr.slice(0, middle),right = arr.slice(middle);return merge(mergeSort(left), mergeSort(right));}function merge(left, right) {var result = [];while (left.length>0 && right.length>0) {if (left[0] <= right[0]) {result.push(left.shift());}else {result.push(right.shift());}}while (left.length)result.push(left.shift());while (right.length)result.push(right.shift());return result;}
5.4 算法分析
歸并排序是一種穩(wěn)定的排序方法。和選擇排序一樣,歸并排序的性能不受輸入數(shù)據(jù)的影響,但表現(xiàn)比選擇排序好的多,因為始終都是O(nlogn)的時間復(fù)雜度。代價是需要額外的內(nèi)存空間。
6、快速排序(Quick Sort)
快速排序的基本思想:通過一趟排序?qū)⒋庞涗浄指舫瑟?dú)立的兩部分,其中一部分記錄的關(guān)鍵字均比另一部分的關(guān)鍵字小,則可分別對這兩部分記錄繼續(xù)進(jìn)行排序,以達(dá)到整個序列有序。
6.1 算法描述
快速排序使用分治法來把一個串(list)分為兩個子串(sub-lists)。具體算法描述如下:
從數(shù)列中挑出一個元素,稱為 “基準(zhǔn)”(pivot);
重新排序數(shù)列,所有元素比基準(zhǔn)值小的擺放在基準(zhǔn)前面,所有元素比基準(zhǔn)值大的擺在基準(zhǔn)的后面(相同的數(shù)可以到任一邊)。在這個分區(qū)退出之后,該基準(zhǔn)就處于數(shù)列的中間位置。這個稱為分區(qū)(partition)操作;
遞歸地(recursive)把小于基準(zhǔn)值元素的子數(shù)列和大于基準(zhǔn)值元素的子數(shù)列排序。
6.2 動圖演示
6.3 代碼實(shí)現(xiàn)
function quickSort(arr, left, right) {var len = arr.length,partitionIndex,left =typeof left !='number' ? 0 : left,right =typeof right !='number' ? len - 1 : right;if (left < right) {partitionIndex = partition(arr, left, right);quickSort(arr, left, partitionIndex-1);quickSort(arr, partitionIndex+1, right);}return arr;}function partition(arr, left ,right) { // 分區(qū)操作var pivot = left, // 設(shè)定基準(zhǔn)值(pivot)index = pivot + 1;for (var i = index; i <= right; i++) {if (arr[i] < arr[pivot]) {swap(arr, i, index);index++;}}swap(arr, pivot, index - 1);return index-1;}function swap(arr, i, j) {var temp = arr[i];arr[i] = arr[j];arr[j] = temp;}
7、堆排序(Heap Sort)
堆排序(Heapsort)是指利用堆這種數(shù)據(jù)結(jié)構(gòu)所設(shè)計的一種排序算法。堆積是一個近似完全二叉樹的結(jié)構(gòu),并同時滿足堆積的性質(zhì):即子結(jié)點(diǎn)的鍵值或索引總是小于(或者大于)它的父節(jié)點(diǎn)。
7.1 算法描述
將初始待排序關(guān)鍵字序列(R1,R2….Rn)構(gòu)建成大頂堆,此堆為初始的無序區(qū);
將堆頂元素R[1]與最后一個元素R[n]交換,此時得到新的無序區(qū)(R1,R2,……Rn-1)和新的有序區(qū)(Rn),且滿足R[1,2…n-1]<=R[n];
由于交換后新的堆頂R[1]可能違反堆的性質(zhì),因此需要對當(dāng)前無序區(qū)(R1,R2,……Rn-1)調(diào)整為新堆,然后再次將R[1]與無序區(qū)最后一個元素交換,得到新的無序區(qū)(R1,R2….Rn-2)和新的有序區(qū)(Rn-1,Rn)。不斷重復(fù)此過程直到有序區(qū)的元素個數(shù)為n-1,則整個排序過程完成。
7.2?代碼實(shí)現(xiàn)
var len; // 因為聲明的多個函數(shù)都需要數(shù)據(jù)長度,所以把len設(shè)置成為全局變量function buildMaxHeap(arr) { // 建立大頂堆len = arr.length;for (var i = Math.floor(len/2); i >= 0; i--) {heapify(arr, i);}}function heapify(arr, i) { // 堆調(diào)整var left = 2 * i + 1,right = 2 * i + 2,largest = i;if (left < len && arr[left] > arr[largest]) {largest = left;}if (right < len && arr[right] > arr[largest]) {largest = right;}if (largest != i) {swap(arr, i, largest);heapify(arr, largest);}}function swap(arr, i, j) {var temp = arr[i];arr[i] = arr[j];arr[j] = temp;}function heapSort(arr) {buildMaxHeap(arr);for (var i = arr.length - 1; i > 0; i--) {swap(arr, 0, i);len--;heapify(arr, 0);}return arr;}
8、計數(shù)排序(Counting Sort)
計數(shù)排序不是基于比較的排序算法,其核心在于將輸入的數(shù)據(jù)值轉(zhuǎn)化為鍵存儲在額外開辟的數(shù)組空間中。作為一種線性時間復(fù)雜度的排序,計數(shù)排序要求輸入的數(shù)據(jù)必須是有確定范圍的整數(shù)。
8.1 算法描述
找出待排序的數(shù)組中最大和最小的元素;
統(tǒng)計數(shù)組中每個值為i的元素出現(xiàn)的次數(shù),存入數(shù)組C的第i項;
對所有的計數(shù)累加(從C中的第一個元素開始,每一項和前一項相加);
反向填充目標(biāo)數(shù)組:將每個元素i放在新數(shù)組的第C(i)項,每放一個元素就將C(i)減去1。
8.2 動圖演示
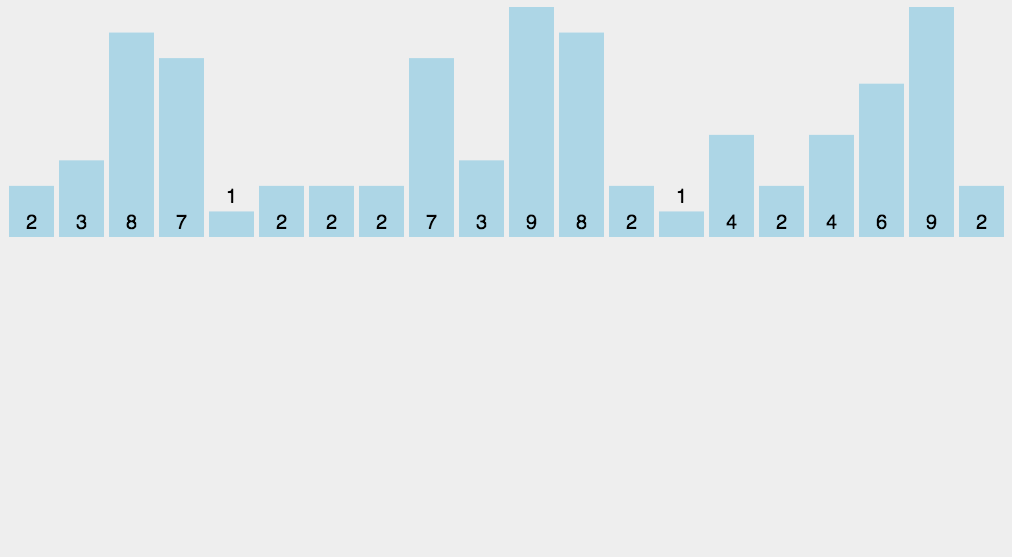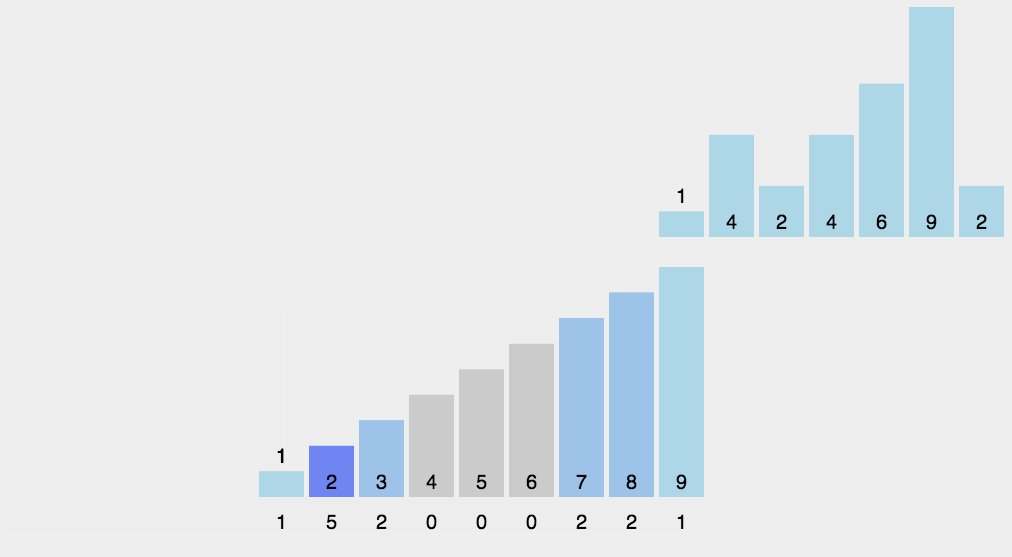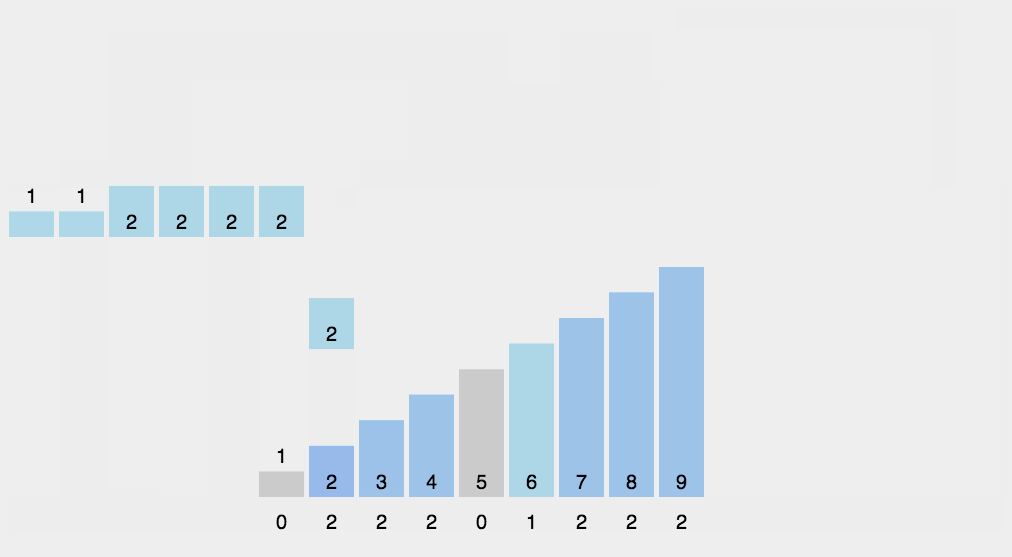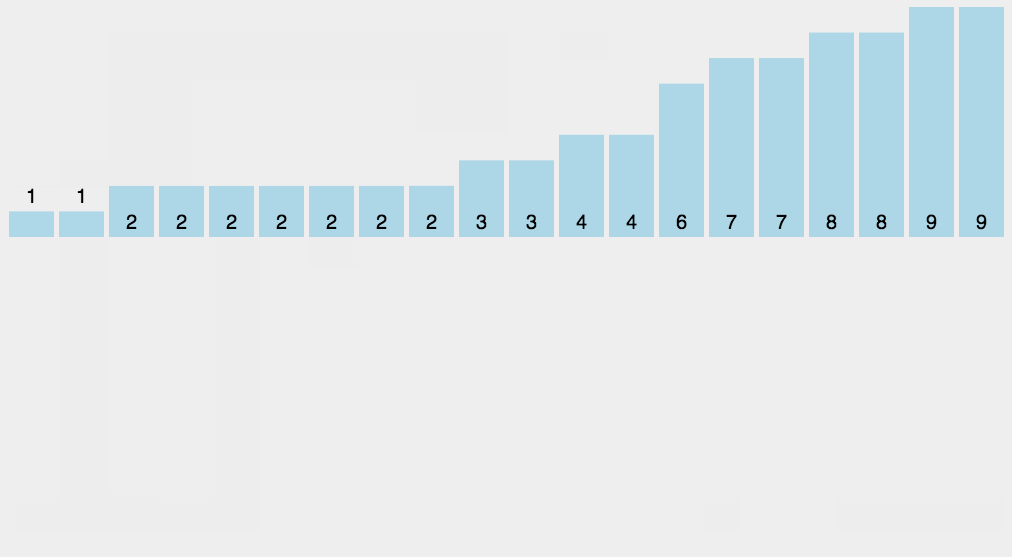
8.3 代碼實(shí)現(xiàn)
function countingSort(arr, maxValue) {var bucket =new Array(maxValue + 1),sortedIndex = 0;arrLen = arr.length,bucketLen = maxValue + 1;for (var i = 0; i < arrLen; i++) {if (!bucket[arr[i]]) {bucket[arr[i]] = 0;}bucket[arr[i]]++;}for (var j = 0; j < bucketLen; j++) {while(bucket[j] > 0) {arr[sortedIndex++] = j;bucket[j]--;}}return arr;}
8.4 算法分析
計數(shù)排序是一個穩(wěn)定的排序算法。當(dāng)輸入的元素是 n 個 0到 k 之間的整數(shù)時,時間復(fù)雜度是O(n+k),空間復(fù)雜度也是O(n+k),其排序速度快于任何比較排序算法。當(dāng)k不是很大并且序列比較集中時,計數(shù)排序是一個很有效的排序算法。
9、桶排序(Bucket Sort)
桶排序是計數(shù)排序的升級版。它利用了函數(shù)的映射關(guān)系,高效與否的關(guān)鍵就在于這個映射函數(shù)的確定。桶排序 (Bucket sort)的工作的原理:假設(shè)輸入數(shù)據(jù)服從均勻分布,將數(shù)據(jù)分到有限數(shù)量的桶里,每個桶再分別排序(有可能再使用別的排序算法或是以遞歸方式繼續(xù)使用桶排序進(jìn)行排)。
9.1 算法描述
設(shè)置一個定量的數(shù)組當(dāng)作空桶;
遍歷輸入數(shù)據(jù),并且把數(shù)據(jù)一個一個放到對應(yīng)的桶里去;
對每個不是空的桶進(jìn)行排序;
從不是空的桶里把排好序的數(shù)據(jù)拼接起來。
9.2 圖片演示
9.3 代碼實(shí)現(xiàn)
unction bucketSort(arr, bucketSize) {if (arr.length === 0) {return arr;}var i;var minValue = arr[0];var maxValue = arr[0];for (i = 1; i < arr.length; i++) {if (arr[i] < minValue) {minValue = arr[i]; // 輸入數(shù)據(jù)的最小值}else if (arr[i] > maxValue) {maxValue = arr[i]; // 輸入數(shù)據(jù)的最大值}}// 桶的初始化var DEFAULT_BUCKET_SIZE = 5; // 設(shè)置桶的默認(rèn)數(shù)量為5bucketSize = bucketSize || DEFAULT_BUCKET_SIZE;var bucketCount = Math.floor((maxValue - minValue) / bucketSize) + 1;var buckets =new Array(bucketCount);for (i = 0; i < buckets.length; i++) {buckets[i] = [];}// 利用映射函數(shù)將數(shù)據(jù)分配到各個桶中for (i = 0; i < arr.length; i++) {buckets[Math.floor((arr[i] - minValue) / bucketSize)].push(arr[i]);}arr.length = 0;for (i = 0; i < buckets.length; i++) {insertionSort(buckets[i]); // 對每個桶進(jìn)行排序,這里使用了插入排序for (var j = 0; j < buckets[i].length; j++) {arr.push(buckets[i][j]);}}return arr;}
9.4 算法分析
桶排序最好情況下使用線性時間O(n),桶排序的時間復(fù)雜度,取決與對各個桶之間數(shù)據(jù)進(jìn)行排序的時間復(fù)雜度,因為其它部分的時間復(fù)雜度都為O(n)。很顯然,桶劃分的越小,各個桶之間的數(shù)據(jù)越少,排序所用的時間也會越少。但相應(yīng)的空間消耗就會增大。
10、基數(shù)排序(Radix Sort)
基數(shù)排序是按照低位先排序,然后收集;再按照高位排序,然后再收集;依次類推,直到最高位。有時候有些屬性是有優(yōu)先級順序的,先按低優(yōu)先級排序,再按高優(yōu)先級排序。最后的次序就是高優(yōu)先級高的在前,高優(yōu)先級相同的低優(yōu)先級高的在前。
10.1 算法描述
取得數(shù)組中的最大數(shù),并取得位數(shù);
arr為原始數(shù)組,從最低位開始取每個位組成radix數(shù)組;
對radix進(jìn)行計數(shù)排序(利用計數(shù)排序適用于小范圍數(shù)的特點(diǎn));
10.2 動圖演示

10.3 代碼實(shí)現(xiàn)
/ LSD Radix Sortvar counter = [];function radixSort(arr, maxDigit) {var mod = 10;var dev = 1;for (var i = 0; i < maxDigit; i++, dev *= 10, mod *= 10) {for(var j = 0; j < arr.length; j++) {var bucket = parseInt((arr[j] % mod) / dev);if(counter[bucket]==null) {counter[bucket] = [];}counter[bucket].push(arr[j]);}var pos = 0;for(var j = 0; j < counter.length; j++) {var value =null;if(counter[j]!=null) {while ((value = counter[j].shift()) !=null) {arr[pos++] = value;}}}}return arr;}
10.4 算法分析
基數(shù)排序基于分別排序,分別收集,所以是穩(wěn)定的。但基數(shù)排序的性能比桶排序要略差,每一次關(guān)鍵字的桶分配都需要O(n)的時間復(fù)雜度,而且分配之后得到新的關(guān)鍵字序列又需要O(n)的時間復(fù)雜度。
假如待排數(shù)據(jù)可以分為d個關(guān)鍵字,則基數(shù)排序的時間復(fù)雜度將是O(d*2n) ,當(dāng)然d要遠(yuǎn)遠(yuǎn)小于n,因此基本上還是線性級別的。
基數(shù)排序的空間復(fù)雜度為O(n+k),其中k為桶的數(shù)量。一般來說n>>k,因此額外空間需要大概n個左右。
