
視頻中的目標(biāo)檢測與圖像中的目標(biāo)檢測具體有什么區(qū)別?
點(diǎn)擊左上方藍(lán)字關(guān)注我們

作者:Naiyan Wang
簡單來說,視頻檢測是比單張圖片檢測多了Temporal Context(時(shí)間上下文)的信息。不同方法想利用這些Context來解決的問題并不相同。一類方法是關(guān)注如何使用這部分信息來加速Video Detection。因?yàn)橄噜弾g存在大量冗余,如果可以通過一些廉價(jià)的辦法來加速不損害性能,在實(shí)際應(yīng)用中還是很有意義的。另一類方法是關(guān)注這部分信息可以有效減輕單幀圖片檢測中由于運(yùn)動(dòng)模糊,物體面積過小導(dǎo)致的困難,從而來提升性能。當(dāng)然最理想的方法是能又快又好啦:)
當(dāng)然,這里有一些很簡單的baseline方法,例如直接使用tracking關(guān)聯(lián)。這類方法其實(shí)并沒有深入到模型本身,一般僅僅局限于后處理步驟,雖然也可以取得一定的結(jié)果提升,但是個(gè)人覺得并不是很優(yōu)美。比較關(guān)注的是來自以下兩個(gè)組的工作吧。
1.CUHK: Xiaogang Wang 這面我了解到的有三篇文章,最開始 (TPAMI Short)是通過Motion的信息以及多類之間的Correlation來對(duì)單幀圖像detector的輸出進(jìn)行后處理,算是在前面提到的Baseline方法上的小改進(jìn)。后續(xù)的文章(CVPR 16)在這個(gè)基礎(chǔ)上,引入了一個(gè)Temporal CNN對(duì)每一個(gè)Tubelet進(jìn)行rescore。這樣通過Temporal的信息來重新評(píng)估每個(gè)proposal的置信度。最近的工作(CVPR17)將Proposal生成這個(gè)步驟,也從靜態(tài)圖片拿到了時(shí)序上來做。除此之外,對(duì)于每個(gè)Tubelet的分類,也采取了流行的LSTM。
2. MSRA: Jifeng Dai 相對(duì)來講,這面的工作更干凈,思路更清晰一些。個(gè)人來說更喜歡。這面的兩個(gè)工作其實(shí)思想類似,但是恰好對(duì)應(yīng)于前文提到的加速和性能提升兩個(gè)目的。其核心都在于通過快速計(jì)算Optical Flow來捕捉視頻中的Motion信息,然后通過這個(gè)Flow的信息使用Bilinear Sampling對(duì)之前的Feature Map進(jìn)行Warp(也就是通過Optical Flow來預(yù)測當(dāng)前幀的Feature Map)。有了這樣的信息之后,如果我們想加速,那么可以直接使用預(yù)測的Feature Map來輸出結(jié)果;如果想得到更好的結(jié)果,可以將預(yù)測的Feature Map和當(dāng)前幀計(jì)算出來的Feature Map融合起來一起輸出結(jié)果。值得一提的是,后者也是目前唯一一個(gè)End to End的Video Detection方法。
另外有一些零碎一些的工作,基本都是在后處理過程中,處理rescore detection的問題,例如Seq-NMS等等。
最后呢,想來拋磚引玉,提出一個(gè)我們觀察到在Video Detection中的問題,我們也寫了一篇paper來講這個(gè)事情([1611.06467] On The Stability of Video Detection and Tracking) 也就是在Video Detection中的穩(wěn)定性(Stability)的問題。見下面這個(gè)Video,其實(shí)兩個(gè)Detector如果論準(zhǔn)確性來講,差別并不大,然而對(duì)于人眼來看,孰優(yōu)孰劣一目了然。
視頻鏈接:https://v.youku.com/v_show/id_XMjY5MTM4MTI5Mg==.html?spm=a2hzp.8253869.0.0&from=y1.7-2
這樣的穩(wěn)定性的問題,在實(shí)際的應(yīng)用中其實(shí)也會(huì)帶來很多困擾。例如在自動(dòng)駕駛中,需要穩(wěn)定的2D檢測框來進(jìn)行車輛距離和速度的估計(jì)。不穩(wěn)定的檢測都會(huì)極大影響后續(xù)任務(wù)的準(zhǔn)確性。所以呢,我們?cè)谖恼轮惺紫忍岢隽艘粋€(gè)定量的指標(biāo)來衡量這種穩(wěn)定性,然后評(píng)測了幾種簡單的Baseline。我們還計(jì)算了這個(gè)Stability指標(biāo)和常用的Accuracy指標(biāo)之間的Correlation,發(fā)現(xiàn)其實(shí)這兩種指標(biāo)其實(shí)相關(guān)性并不大,也就是說分別捕捉到了Video Detection中兩方面的一個(gè)質(zhì)量。希望這個(gè)工作能給大家一些啟發(fā),在改進(jìn)準(zhǔn)確性之余,也考慮一下同等重要的穩(wěn)定性如何改進(jìn)。
在這里想從自己的角度解答一下兩者的機(jī)理與區(qū)別。因?yàn)槭乔皟赡暝谧龌谝曨l的目標(biāo)檢測和跟蹤,所用的方法相對(duì)于現(xiàn)行的Long Short-Term Memory (LSTM)可能相對(duì)老套,但是我覺得題主該是新手,了解一下過去的經(jīng)典還是有意義的,可以作為前期補(bǔ)充。
研究問題
無論是基于視頻還是圖像,我們研究的核心是目標(biāo)檢測問題,即在圖像中(或視頻的圖像中)識(shí)別出目標(biāo),并且實(shí)現(xiàn)定位。
基于單幀圖像的目標(biāo)檢測
在靜態(tài)圖像上實(shí)現(xiàn)目標(biāo)檢測,本身是一個(gè)滑窗+分類的過程,前者是幫助鎖定目標(biāo)可能存在的局部區(qū)域,后者則是通過分類器打分,判斷鎖定的區(qū)域是否有(是)我們要尋找的目標(biāo)。研究的核心多集中于后者,選什么樣的特征表示來描述你鎖定的區(qū)域(HOG, C-SIFT, Haar, LBP, CNN, Deformable Part Models (DPM) and etc.),將這些特征輸入到什么樣的分類器(SVM,Adaboost and etc.)進(jìn)行打分,判斷是否是我們要找的目標(biāo)。
盡管我們要檢測的目標(biāo)可能外形變化多端(由于品種,形變,光照,角度等等),通過大量數(shù)據(jù)訓(xùn)練CNN得到的特征表示還是能很好地幫助實(shí)現(xiàn)識(shí)別和判定的過程。但是有些極端情況下,如目標(biāo)特別小,或者目標(biāo)和背景太相似,或者在這一幀圖像中因?yàn)槟:蛘咂渌颍繕?biāo)確實(shí)扭曲的不成樣子,CNN也會(huì)覺得力不從心,認(rèn)不出來它原來是我們要找的目標(biāo)呢。另外一種情況是拍攝場景混入了其他和目標(biāo)外觀很像的東西 (比如飛機(jī)和展翅大鳥),這時(shí)候也可能存在誤判。
也就是在這幾種情況下,我們可能無法憑借單幀的外觀信息,完成對(duì)目標(biāo)魯棒的檢測。
基于視頻的目標(biāo)檢測
單幀不夠,多幀來湊。在視頻中目標(biāo)往往具有運(yùn)動(dòng)特性,這些特性來源有目標(biāo)本身的形變,目標(biāo)本身的運(yùn)動(dòng),以及相機(jī)的運(yùn)動(dòng)。所以引入多幀之后,我們不僅可以獲得好多幀目標(biāo)的外觀信息,還能獲得目標(biāo)在幀間的運(yùn)動(dòng)信息。于是就有了以下的方法:
第一種:側(cè)重于目標(biāo)的運(yùn)動(dòng)信息。先基于motion segmentation 或是 background extraction(光流法和高斯分布等)實(shí)現(xiàn)對(duì)前景和背景的分離,也就是說我們借助運(yùn)動(dòng)信息挑出了很有可能是目標(biāo)的區(qū)域;再考慮連續(xù)幀里目標(biāo)的持續(xù)性(大小,顏色,軌跡的一致性),可以幫助刪去一部分不合格的候選的目標(biāo)區(qū)域;然后對(duì)挑出的區(qū)域打分做判斷,還是利用外觀信息(單幀里提到的)。
第二種:動(dòng)靜結(jié)合,即在第一種的基礎(chǔ)上,加入目標(biāo)的外觀形變。有些目標(biāo)在視頻中會(huì)呈現(xiàn)幅度較大的,有一定規(guī)律的形變,比如行人和鳥。這時(shí)我們可以通過學(xué)習(xí)形變規(guī)律,總結(jié)出目標(biāo)特殊的運(yùn)動(dòng)特征和行為范式,然后看待檢測的目標(biāo)是否滿足這樣的行為變化。常見的行為特征表示有3D descriptors,Markov-based shape dynamics, pose/primtive action-based histogram等等。這種綜合目標(biāo)靜態(tài)和動(dòng)態(tài)信息來判斷是否是特定目標(biāo)的方法,有些偏向action classification。
第三種:頻域特征的利用
在基于視頻的目標(biāo)檢測中,除了可以對(duì)目標(biāo)空間和時(shí)間信息進(jìn)行分析外,目標(biāo)的頻域信息在檢測過程中也能發(fā)揮巨大的作用。比如,在鳥種檢測中,我們可以通過分析翅膀扇動(dòng)頻率實(shí)現(xiàn)鳥種的判別。
值得注意的是這里基于視頻的目標(biāo)檢測(video-based detection)存在兩種情況,一種是你只想知道這個(gè)場景中有沒有這種目標(biāo),如果有,它對(duì)應(yīng)的場景位置是哪; 另一種是這個(gè)場景有沒有這種目標(biāo),它在每一幀中的位置是哪。我們這里介紹的方法側(cè)重的是后一種更復(fù)雜的。
Deep learning 是錢途無量的,也是橫行霸道的。希望視覺特征建模也能繼續(xù)發(fā)展,整個(gè)計(jì)算機(jī)視覺研究領(lǐng)域更加多元化,而非被機(jī)器學(xué)習(xí)邊緣化。
1.與圖像目標(biāo)檢測的區(qū)別

與光流結(jié)合的方法

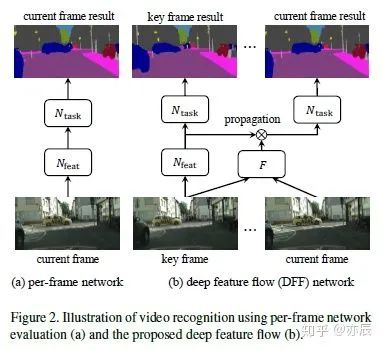
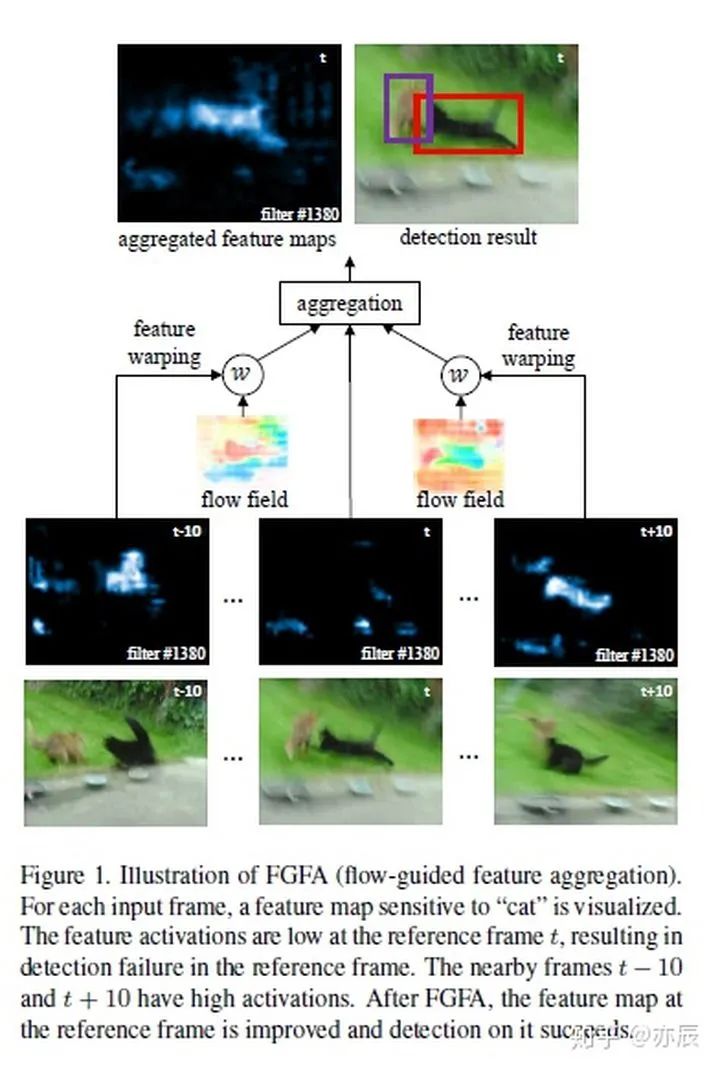
與目標(biāo)跟蹤結(jié)合的方法
鏈接:https://link.zhihu.com/?target=https%3A//arxiv.org/abs/1710.03958
與RNN結(jié)合的方法
鏈接:[1712.06317] Video Object Detection with an Aligned Spatial-Temporal Memory (arxiv.org)
鏈接:[1607.04648] Context Matters: Refining Object Detection in Video with Recurrent Neural Networks (arxiv.org)
其他融合方法
鏈接:[1712.05896] Impression Network for Video Object Detection (arxiv.org)
非端到端方法
鏈接:[1604.02532v4] T-CNN: Tubelets with Convolutional Neural Networks for Object Detection from Videos (arxiv.org)
鏈接:[1602.08465v3] Seq-NMS for Video Object Detection (arxiv.org)
綜上,當(dāng)下視頻目標(biāo)檢測研究相對(duì)于圖像領(lǐng)域還不夠火熱。研究思路多是要么關(guān)注利用冗余信息提高檢測速度,要么融合連續(xù)幀之間上下文信息提高檢測質(zhì)量。減少冗余,提高速度這方面工作不是很多。(也有可能文章看的還不夠多,歡迎指正)而融合上下文信息可以考慮借助行為識(shí)別常用的3D卷積,RNN,注意力模型等方法。
END