
分布式系統(tǒng)唯一 ID 生成方案匯總
系統(tǒng)唯一ID是我們在設(shè)計(jì)一個系統(tǒng)的時(shí)候常常會遇見的問題,也常常為這個問題而糾結(jié)。生成ID的方法有很多,適應(yīng)不同的場景、需求以及性能要求。所以有些比較復(fù)雜的系統(tǒng)會有多個ID生成的策略。下面就介紹一些常見的ID生成策略。
1. 數(shù)據(jù)庫自增長序列或字段
最常見的方式。利用數(shù)據(jù)庫,全數(shù)據(jù)庫唯一。
優(yōu)點(diǎn):
1)簡單,代碼方便,性能可以接受。
2)數(shù)字ID天然排序,對分頁或者需要排序的結(jié)果很有幫助。
?
缺點(diǎn):
1)不同數(shù)據(jù)庫語法和實(shí)現(xiàn)不同,數(shù)據(jù)庫遷移的時(shí)候或多數(shù)據(jù)庫版本支持的時(shí)候需要處理。
2)在單個數(shù)據(jù)庫或讀寫分離或一主多從的情況下,只有一個主庫可以生成。有單點(diǎn)故障的風(fēng)險(xiǎn)。
3)在性能達(dá)不到要求的情況下,比較難于擴(kuò)展。
4)如果遇見多個系統(tǒng)需要合并或者涉及到數(shù)據(jù)遷移會相當(dāng)痛苦。
5)分表分庫的時(shí)候會有麻煩。
優(yōu)化方案:
1)針對主庫單點(diǎn),如果有多個Master庫,則每個Master庫設(shè)置的起始數(shù)字不一樣,步長一樣,可以是Master的個數(shù)。比如:Master1 生成的是 1,4,7,10,Master2生成的是2,5,8,11 Master3生成的是 3,6,9,12。這樣就可以有效生成集群中的唯一ID,也可以大大降低ID生成數(shù)據(jù)庫操作的負(fù)載。
?
2. UUID
常見的方式。可以利用數(shù)據(jù)庫也可以利用程序生成,一般來說全球唯一。
優(yōu)點(diǎn):
1)簡單,代碼方便。
2)生成ID性能非常好,基本不會有性能問題。
3)全球唯一,在遇見數(shù)據(jù)遷移,系統(tǒng)數(shù)據(jù)合并,或者數(shù)據(jù)庫變更等情況下,可以從容應(yīng)對。
?
缺點(diǎn):
1)沒有排序,無法保證趨勢遞增。
2)UUID往往是使用字符串存儲,查詢的效率比較低。
3)存儲空間比較大,如果是海量數(shù)據(jù)庫,就需要考慮存儲量的問題。
4)傳輸數(shù)據(jù)量大
5)不可讀。
?
3. UUID的變種
1)為了解決UUID不可讀,可以使用UUID to Int64的方法。及
////// 根據(jù)GUID獲取唯一數(shù)字序列 /// public static long GuidToInt64() { byte[] bytes = Guid.NewGuid().ToByteArray(); return BitConverter.ToInt64(bytes, 0); }
2)為了解決UUID無序的問題,NHibernate在其主鍵生成方式中提供了Comb算法(combined guid/timestamp)。保留GUID的10個字節(jié),用另6個字節(jié)表示GUID生成的時(shí)間(DateTime)。
////// Generate a new using the comb algorithm. /// private Guid GenerateComb() { byte[] guidArray = Guid.NewGuid().ToByteArray(); DateTime baseDate = new DateTime(1900, 1, 1); DateTime now = DateTime.Now; // Get the days and milliseconds which will be used to build //the byte string TimeSpan days = new TimeSpan(now.Ticks - baseDate.Ticks); TimeSpan msecs = now.TimeOfDay; // Convert to a byte array // Note that SQL Server is accurate to 1/300th of a // millisecond so we divide by 3.333333 byte[] daysArray = BitConverter.GetBytes(days.Days); byte[] msecsArray = BitConverter.GetBytes((long) (msecs.TotalMilliseconds / 3.333333)); // Reverse the bytes to match SQL Servers ordering Array.Reverse(daysArray); Array.Reverse(msecsArray); // Copy the bytes into the guid Array.Copy(daysArray, daysArray.Length - 2, guidArray, guidArray.Length - 6, 2); Array.Copy(msecsArray, msecsArray.Length - 4, guidArray, guidArray.Length - 4, 4); return new Guid(guidArray); }
用上面的算法測試一下,得到如下的結(jié)果:作為比較,前面3個是使用COMB算法得出的結(jié)果,最后12個字符串是時(shí)間序(統(tǒng)一毫秒生成的3個UUID),過段時(shí)間如果再次生成,則12個字符串會比圖示的要大。后面3個是直接生成的GUID。
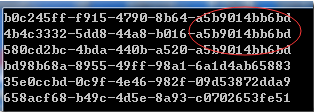
如果想把時(shí)間序放在前面,可以生成后改變12個字符串的位置,也可以修改算法類的最后兩個Array.Copy。
?
4. Redis生成ID
當(dāng)使用數(shù)據(jù)庫來生成ID性能不夠要求的時(shí)候,我們可以嘗試使用Redis來生成ID。這主要依賴于Redis是單線程的,所以也可以用生成全局唯一的ID。可以用Redis的原子操作 INCR和INCRBY來實(shí)現(xiàn)。
可以使用Redis集群來獲取更高的吞吐量。假如一個集群中有5臺Redis。可以初始化每臺Redis的值分別是1,2,3,4,5,然后步長都是5。各個Redis生成的ID為:
A:1,6,11,16,21
B:2,7,12,17,22
C:3,8,13,18,23
D:4,9,14,19,24
E:5,10,15,20,25
這個,隨便負(fù)載到哪個機(jī)確定好,未來很難做修改。但是3-5臺服務(wù)器基本能夠滿足器上,都可以獲得不同的ID。但是步長和初始值一定需要事先需要了。使用Redis集群也可以方式單點(diǎn)故障的問題。
另外,比較適合使用Redis來生成每天從0開始的流水號。比如訂單號=日期+當(dāng)日自增長號。可以每天在Redis中生成一個Key,使用INCR進(jìn)行累加。
?
優(yōu)點(diǎn):
1)不依賴于數(shù)據(jù)庫,靈活方便,且性能優(yōu)于數(shù)據(jù)庫。
2)數(shù)字ID天然排序,對分頁或者需要排序的結(jié)果很有幫助。
缺點(diǎn):
1)如果系統(tǒng)中沒有Redis,還需要引入新的組件,增加系統(tǒng)復(fù)雜度。
2)需要編碼和配置的工作量比較大。
?
5. Twitter的snowflake算法
snowflake是Twitter開源的分布式ID生成算法,結(jié)果是一個long型的ID。其核心思想是:使用41bit作為毫秒數(shù),10bit作為機(jī)器的ID(5個bit是數(shù)據(jù)中心,5個bit的機(jī)器ID),12bit作為毫秒內(nèi)的流水號(意味著每個節(jié)點(diǎn)在每毫秒可以產(chǎn)生 4096 個 ID),最后還有一個符號位,永遠(yuǎn)是0。具體實(shí)現(xiàn)的代碼可以參看https://github.com/twitter/snowflake。
C#代碼如下:
////// From: https://github.com/twitter/snowflake /// An object that generates IDs. /// This is broken into a separate class in case /// we ever want to support multiple worker threads /// per process /// public class IdWorker { private long workerId; private long datacenterId; private long sequence = 0L; private static long twepoch = 1288834974657L; private static long workerIdBits = 5L; private static long datacenterIdBits = 5L; private static long maxWorkerId = -1L ^ (-1L << (int)workerIdBits); private static long maxDatacenterId = -1L ^ (-1L << (int)datacenterIdBits); private static long sequenceBits = 12L; private long workerIdShift = sequenceBits; private long datacenterIdShift = sequenceBits + workerIdBits; private long timestampLeftShift = sequenceBits + workerIdBits + datacenterIdBits; private long sequenceMask = -1L ^ (-1L << (int)sequenceBits); private long lastTimestamp = -1L; private static object syncRoot = new object(); public IdWorker(long workerId, long datacenterId) { // sanity check for workerId if (workerId > maxWorkerId || workerId < 0) { throw new ArgumentException(string.Format("worker Id can't be greater than %d or less than 0", maxWorkerId)); } if (datacenterId > maxDatacenterId || datacenterId < 0) { throw new ArgumentException(string.Format("datacenter Id can't be greater than %d or less than 0", maxDatacenterId)); } this.workerId = workerId; this.datacenterId = datacenterId; } public long nextId() { lock (syncRoot) { long timestamp = timeGen(); if (timestamp < lastTimestamp) { throw new ApplicationException(string.Format("Clock moved backwards. Refusing to generate id for %d milliseconds", lastTimestamp - timestamp)); } if (lastTimestamp == timestamp) { sequence = (sequence + 1) & sequenceMask; if (sequence == 0) { timestamp = tilNextMillis(lastTimestamp); } } else { sequence = 0L; } lastTimestamp = timestamp; return ((timestamp - twepoch) << (int)timestampLeftShift) | (datacenterId << (int)datacenterIdShift) | (workerId << (int)workerIdShift) | sequence; } } protected long tilNextMillis(long lastTimestamp) { long timestamp = timeGen(); while (timestamp <= lastTimestamp) { timestamp = timeGen(); } return timestamp; } protected long timeGen() { return (long)(DateTime.UtcNow - new DateTime(1970, 1, 1, 0, 0, 0, DateTimeKind.Utc)).TotalMilliseconds; } }
測試代碼如下:
private static void TestIdWorker() { HashSet<long> set = new HashSet<long>(); IdWorker idWorker1 = new IdWorker(0, 0); IdWorker idWorker2 = new IdWorker(1, 0); Thread t1 = new Thread(() => DoTestIdWoker(idWorker1, set)); Thread t2 = new Thread(() => DoTestIdWoker(idWorker2, set)); t1.IsBackground = true; t2.IsBackground = true; t1.Start(); t2.Start(); try { Thread.Sleep(30000); t1.Abort(); t2.Abort(); } catch (Exception e) { } Console.WriteLine("done"); } private static void DoTestIdWoker(IdWorker idWorker, HashSet<long> set) { while (true) { long id = idWorker.nextId(); if (!set.Add(id)) { Console.WriteLine("duplicate:" + id); } Thread.Sleep(1); } }
snowflake算法可以根據(jù)自身項(xiàng)目的需要進(jìn)行一定的修改。比如估算未來的數(shù)據(jù)中心個數(shù),每個數(shù)據(jù)中心的機(jī)器數(shù)以及統(tǒng)一毫秒可以能的并發(fā)數(shù)來調(diào)整在算法中所需要的bit數(shù)。
優(yōu)點(diǎn):
1)不依賴于數(shù)據(jù)庫,靈活方便,且性能優(yōu)于數(shù)據(jù)庫。
2)ID按照時(shí)間在單機(jī)上是遞增的。
缺點(diǎn):
1)在單機(jī)上是遞增的,但是由于涉及到分布式環(huán)境,每臺機(jī)器上的時(shí)鐘不可能完全同步,也許有時(shí)候也會出現(xiàn)不是全局遞增的情況。
?
6. 利用zookeeper生成唯一ID
zookeeper主要通過其znode數(shù)據(jù)版本來生成序列號,可以生成32位和64位的數(shù)據(jù)版本號,客戶端可以使用這個版本號來作為唯一的序列號。
很少會使用zookeeper來生成唯一ID。主要是由于需要依賴zookeeper,并且是多步調(diào)用API,如果在競爭較大的情況下,需要考慮使用分布式鎖。因此,性能在高并發(fā)的分布式環(huán)境下,也不甚理想。
?
7. MongoDB的ObjectId
MongoDB的ObjectId和snowflake算法類似。它設(shè)計(jì)成輕量型的,不同的機(jī)器都能用全局唯一的同種方法方便地生成它。MongoDB 從一開始就設(shè)計(jì)用來作為分布式數(shù)據(jù)庫,處理多個節(jié)點(diǎn)是一個核心要求。使其在分片環(huán)境中要容易生成得多。
其格式如下:
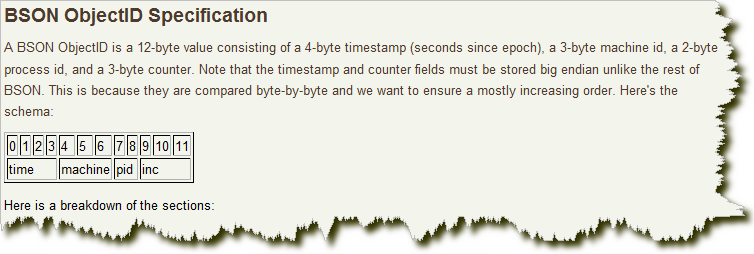
?
前4 個字節(jié)是從標(biāo)準(zhǔn)紀(jì)元開始的時(shí)間戳,單位為秒。時(shí)間戳,與隨后的5 個字節(jié)組合起來,提供了秒級別的唯一性。由于時(shí)間戳在前,這意味著ObjectId 大致會按照插入的順序排列。這對于某些方面很有用,如將其作為索引提高效率。這4 個字節(jié)也隱含了文檔創(chuàng)建的時(shí)間。絕大多數(shù)客戶端類庫都會公開一個方法從ObjectId 獲取這個信息。?
接下來的3 字節(jié)是所在主機(jī)的唯一標(biāo)識符。通常是機(jī)器主機(jī)名的散列值。這樣就可以確保不同主機(jī)生成不同的ObjectId,不產(chǎn)生沖突。?
為了確保在同一臺機(jī)器上并發(fā)的多個進(jìn)程產(chǎn)生的ObjectId 是唯一的,接下來的兩字節(jié)來自產(chǎn)生ObjectId 的進(jìn)程標(biāo)識符(PID)。?
前9 字節(jié)保證了同一秒鐘不同機(jī)器不同進(jìn)程產(chǎn)生的ObjectId 是唯一的。后3 字節(jié)就是一個自動增加的計(jì)數(shù)器,確保相同進(jìn)程同一秒產(chǎn)生的ObjectId 也是不一樣的。同一秒鐘最多允許每個進(jìn)程擁有2563(16 777 216)個不同的ObjectId。
實(shí)現(xiàn)的源碼可以到MongoDB官方網(wǎng)站下載。
作者:nick hao
原文鏈接:https://www.cnblogs.com/haoxinyue/p/5208136.html
本文轉(zhuǎn)自博客園網(wǎng),版權(quán)歸原作者所有。