
分布式唯一 ID 生成方案,有點(diǎn)全!
一、前言
分布式系統(tǒng)中我們會對一些數(shù)據(jù)量大的業(yè)務(wù)進(jìn)行分拆,如:用戶表,訂單表。因?yàn)閿?shù)據(jù)量巨大一張表無法承接,就會對其進(jìn)行分庫分表。
但一旦涉及到分庫分表,就會引申出分布式系統(tǒng)中唯一主鍵ID的生成問題,永不遷移數(shù)據(jù)和避免熱點(diǎn)的文章中要求需要唯一ID的特性:
整個系統(tǒng)ID唯一 ID是數(shù)字類型,而且是趨勢遞增的 ID簡短,查詢效率快
什么是遞增? 如:第一次生成的ID為12,下一次生成的ID是13,再下一次生成的ID是14。這個就是生成ID遞增。
什么是趨勢遞增? 如:在一段時間內(nèi),生成的ID是遞增的趨勢。如:再一段時間內(nèi)生成的ID在【0,1000】之間,過段時間生成的ID在【1000,2000】之間。但在【0-1000】區(qū)間內(nèi)的時候,ID生成有可能第一次是12,第二次是10,第三次是14。
那有什么方案呢?往下看!
二、分布式ID的幾種生成方案
2.1、UUID
這個方案是小伙伴們第一個能過考慮到的方案
優(yōu)點(diǎn):
代碼實(shí)現(xiàn)簡單。 本機(jī)生成,沒有性能問題 因?yàn)槭侨蛭ㄒ坏腎D,所以遷移數(shù)據(jù)容易
缺點(diǎn):
每次生成的ID是無序的,無法保證趨勢遞增 UUID的字符串存儲,查詢效率慢 存儲空間大 ID本事無業(yè)務(wù)含義,不可讀
應(yīng)用場景:
類似生成token令牌的場景
不適用一些要求有趨勢遞增的ID場景
這個方案就是利用了MySQL的主鍵自增auto_increment,默認(rèn)每次ID加1。
優(yōu)點(diǎn):
數(shù)字化,id遞增 查詢效率高 具有一定的業(yè)務(wù)可讀
缺點(diǎn):
存在單點(diǎn)問題,如果mysql掛了,就沒法生成iD了 數(shù)據(jù)庫壓力大,高并發(fā)抗不住
2.3、MySQL多實(shí)例主鍵自增
這個方案就是解決mysql的單點(diǎn)問題,在auto_increment基本上面,設(shè)置step步長

每臺的初始值分別為1,2,3...N,步長為N(這個案例步長為4)
優(yōu)點(diǎn):
解決了單點(diǎn)問題
缺點(diǎn):
一旦把步長定好后,就無法擴(kuò)容;而且單個數(shù)據(jù)庫的壓力大,數(shù)據(jù)庫自身性能無法滿足高并發(fā)
應(yīng)用場景:
數(shù)據(jù)不需要擴(kuò)容的場景
2.4、雪花snowflake算法
這個算法網(wǎng)上介紹了很多。雪花算法生成64位的二進(jìn)制正整數(shù),然后轉(zhuǎn)換成10進(jìn)制的數(shù)。64位二進(jìn)制數(shù)由如下部分組成:
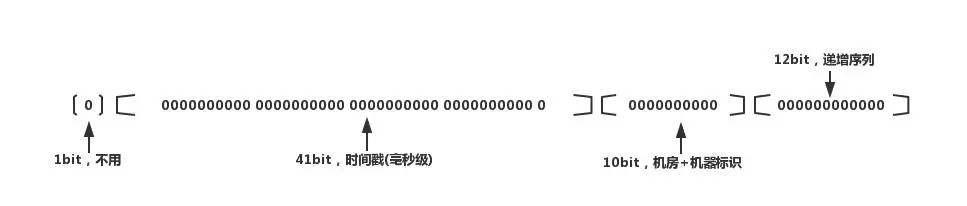
1位標(biāo)識符:始終是0 41位時間戳:41位時間截不是存儲當(dāng)前時間的時間截,而是存儲時間截的差值(當(dāng)前時間截 - 開始時間截 )得到的值,這里的的開始時間截,一般是我們的id生成器開始使用的時間,由我們程序來指定的 10位機(jī)器標(biāo)識碼:可以部署在1024個節(jié)點(diǎn),如果機(jī)器分機(jī)房(IDC)部署,這10位可以由 5位機(jī)房ID + 5位機(jī)器ID 組成 12位序列:毫秒內(nèi)的計(jì)數(shù),12位的計(jì)數(shù)順序號支持每個節(jié)點(diǎn)每毫秒(同一機(jī)器,同一時間截)產(chǎn)生4096個ID序號
優(yōu)點(diǎn):
此方案每秒能夠產(chǎn)生409.6萬個ID,性能快 時間戳在高位,自增序列在低位,整個ID是趨勢遞增的,按照時間有序遞增 靈活度高,可以根據(jù)業(yè)務(wù)需求,調(diào)整bit位的劃分,滿足不同的需求
缺點(diǎn):
依賴機(jī)器的時鐘,如果服務(wù)器時鐘回?fù)埽瑫?dǎo)致重復(fù)ID生成
在分布式場景中,服務(wù)器時鐘回?fù)軙?jīng)常遇到,一般存在10ms之間的回?fù)埽恍』锇閭兙驼f這點(diǎn)10ms,很短可以不考慮吧。但此算法就是建立在毫秒級別的生成方案,一旦回?fù)埽秃苡锌赡艽嬖谥貜?fù)ID。
2.5、Redis生成方案
利用redis的incr原子性操作自增,一般算法為:
年份 + 當(dāng)天距當(dāng)年第多少天 + 天數(shù) + 小時 + redis自增
優(yōu)點(diǎn):
有序遞增,可讀性強(qiáng)
缺點(diǎn):
占用帶寬,每次要向redis進(jìn)行請求
整體測試了這個性能如下:
需求:同時10萬個請求獲取ID1、并發(fā)執(zhí)行完耗時:9s左右
2、單任務(wù)平均耗時:74ms
3、單線程最小耗時:不到1ms
4、單線程最大耗時:4.1s
性能還可以,如果對性能要求不是太高的話,這個方案基本符合要求。
但不完全符合希望id從 1 開始趨勢遞增。(當(dāng)然算法可以調(diào)整為 就一個 redis自增,不需要什么年份,多少天等)。
2.6、小結(jié)
以上介紹了常見的幾種分布式ID生成方案。一線大廠的分布式ID方案絕沒有這個簡單,他們對高并發(fā),高可用的要求很高。
如Redis方案中,每次都要去Redis去請求,有網(wǎng)絡(luò)請求耗時,并發(fā)強(qiáng)依賴了Redis。這個設(shè)計(jì)是有風(fēng)險的,一旦Redis掛了,整個系統(tǒng)不可用。
而且一線大廠也會考慮到ID安全性的問題,如:Redis方案中,用戶是可以預(yù)測下一個ID號是多少,因?yàn)樗惴ㄊ沁f增的。
這樣的話競爭對手第一天中午12點(diǎn)下個訂單,就可以看到平臺的訂單ID是多少,第二天中午12點(diǎn)再下一單,又平臺訂單ID到多少。這樣就可以猜到平臺1天能產(chǎn)生多少訂單了,這個是絕對不允許的,公司絕密啊。
三、一線大廠是如何設(shè)計(jì)的呢?
一線大廠的設(shè)計(jì)思路其實(shí)和小伙伴們思路差不多,只是多想了1~2層,設(shè)計(jì)上面多了1~2個環(huán)節(jié)。
3.1、改造數(shù)據(jù)庫主鍵自增
上述我們介紹了利用數(shù)據(jù)庫的自增主鍵的特性,可以實(shí)現(xiàn)分布式ID;這個ID比較簡短明了,適合做userId,正好符合如何永不遷移數(shù)據(jù)和避免熱點(diǎn)? 根據(jù)服務(wù)器指標(biāo)分配數(shù)據(jù)量(揭秘篇)文章中的ID的需求。但這個方案有嚴(yán)重的問題:
一旦步長定下來,不容易擴(kuò)容 數(shù)據(jù)庫壓力山大
小伙伴們看看怎么優(yōu)化這個方案。先看數(shù)據(jù)庫壓力大,為什么壓力大?是因?yàn)槲覀兠看潍@取ID的時候,都要去數(shù)據(jù)庫請求一次。那我們可以不可以不要每次去取?
思路我們可以請求數(shù)據(jù)庫得到ID的時候,可設(shè)計(jì)成獲得的ID是一個ID區(qū)間段。
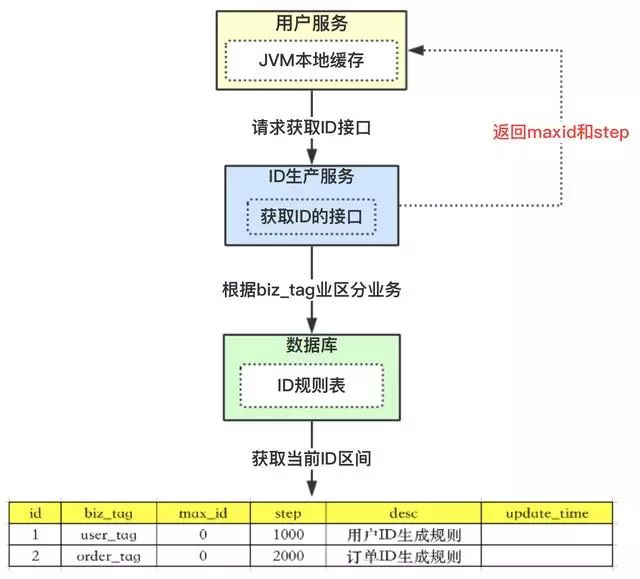
我們看上圖,有張ID規(guī)則表:
1、id表示為主鍵,無業(yè)務(wù)含義。
2、biz_tag為了表示業(yè)務(wù),因?yàn)檎w系統(tǒng)中會有很多業(yè)務(wù)需要生成ID,這樣可以共用一張表維護(hù)
3、max_id表示現(xiàn)在整體系統(tǒng)中已經(jīng)分配的最大ID
4、desc描述
5、update_time表示每次取的ID時間
我們再來看看整體流程:
1、【用戶服務(wù)】在注冊一個用戶時,需要一個用戶ID;會請求【生成ID服務(wù)(是獨(dú)立的應(yīng)用)】的接口
2、【生成ID服務(wù)】會去查詢數(shù)據(jù)庫,找到user_tag的id,現(xiàn)在的max_id為0,step=1000
3、【生成ID服務(wù)】把max_id和step返回給【用戶服務(wù)】;并且把max_id更新為max_id = max_id + step,即更新為1000
4、【用戶服務(wù)】獲得max_id=0,step=1000;
5、 這個用戶服務(wù)可以用ID=【max_id + 1,max_id+step】區(qū)間的ID,即為【1,1000】
6、【用戶服務(wù)】會把這個區(qū)間保存到j(luò)vm中
7、【用戶服務(wù)】需要用到ID的時候,在區(qū)間【1,1000】中依次獲取id,可采用AtomicLong中的getAndIncrement方法。
8、如果把區(qū)間的值用完了,再去請求【生產(chǎn)ID服務(wù)】接口,獲取到max_id為1000,即可以用【max_id + 1,max_id+step】區(qū)間的ID,即為【1001,2000】
這個方案就非常完美的解決了數(shù)據(jù)庫自增的問題,而且可以自行定義max_id的起點(diǎn),和step步長,非常方便擴(kuò)容。
而且也解決了數(shù)據(jù)庫壓力的問題,因?yàn)樵谝欢螀^(qū)間內(nèi),是在jvm內(nèi)存中獲取的,而不需要每次請求數(shù)據(jù)庫。即使數(shù)據(jù)庫宕機(jī)了,系統(tǒng)也不受影響,ID還能維持一段時間。
3.2、競爭問題
以上方案中,如果是多個用戶服務(wù),同時獲取ID,同時去請求【ID服務(wù)】,在獲取max_id的時候會存在并發(fā)問題。
如用戶服務(wù)A,取到的max_id=1000 ;用戶服務(wù)B取到的也是max_id=1000,那就出現(xiàn)了問題,Id重復(fù)了。那怎么解決?
其實(shí)方案很多,加分布式鎖,保證同一時刻只有一個用戶服務(wù)獲取max_id。當(dāng)然也可以用數(shù)據(jù)庫自身的鎖去解決。

利用事務(wù)方式加行鎖,上面的語句,在沒有執(zhí)行完之前,是不允許第二個用戶服務(wù)請求過來的,第二個請求只能阻塞。
3.3、突發(fā)阻塞問題
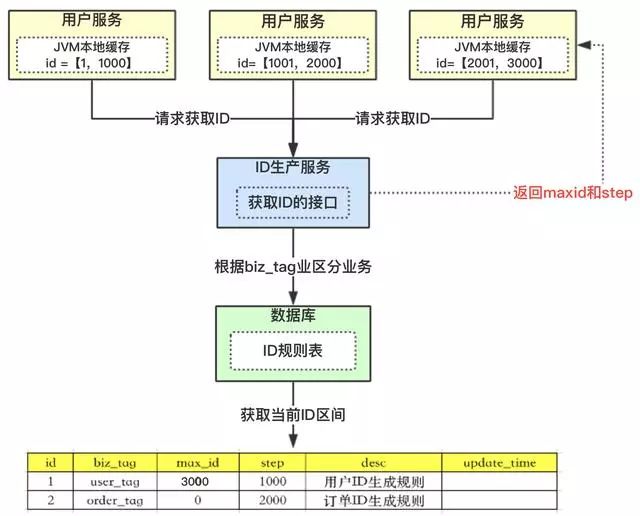
上圖中,多個用戶服務(wù)獲取到了各自的ID區(qū)間,在高并發(fā)場景下,ID用的很快,如果3個用戶服務(wù)在某一時刻都用完了,同時去請求【ID服務(wù)】。因?yàn)樯厦嫣岬降母偁巻栴},所有只有一個用戶服務(wù)去操作數(shù)據(jù)庫,其他二個會被阻塞。
小伙伴就會問,有這么巧嗎?同時ID用完。我們這里舉的是3個用戶服務(wù),感覺概率不大;如果是100個用戶服務(wù)呢?概率是不是一下子大了。
出現(xiàn)的現(xiàn)象就是一會兒突然系統(tǒng)耗時變長,一會兒好了,就是這個原因?qū)е碌模趺慈ソ鉀Q?
3.4、雙buffer方案
在一般的系統(tǒng)設(shè)計(jì)中,雙buffer會經(jīng)常看到,怎么去解決上面的問題也可以采用雙buffer方案。
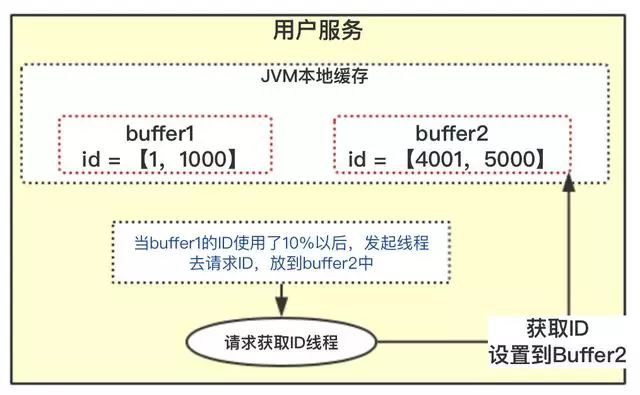
在設(shè)計(jì)的時候,采用雙buffer方案,上圖的流程:
1、當(dāng)前獲取ID在buffer1中,每次獲取ID在buffer1中獲取
2、當(dāng)buffer1中的Id已經(jīng)使用到了100,也就是達(dá)到區(qū)間的10%
3、達(dá)到了10%,先判斷buffer2中有沒有去獲取過,如果沒有就立即發(fā)起請求獲取ID線程,此線程把獲取到的ID,設(shè)置到buffer2中。
4、如果buffer1用完了,會自動切換到buffer2
5、buffer2用到10%了,也會啟動線程再次獲取,設(shè)置到buffer1中
6、依次往返
雙buffer的方案,小伙伴們有沒有感覺很酷,這樣就達(dá)到了業(yè)務(wù)場景用的ID,都是在jvm內(nèi)存中獲得的,從此不需要到數(shù)據(jù)庫中獲取了。允許數(shù)據(jù)庫宕機(jī)時間更長了。
因?yàn)闀幸粋€線程,會觀察什么時候去自動獲取。兩個buffer之間自行切換使用。就解決了突發(fā)阻塞的問題。
四、總結(jié)
此方案是某團(tuán)使用的分布式ID算法,小伙伴們?nèi)绻肓私飧睿梢匀ゾW(wǎng)上搜下,這里應(yīng)該介紹了比較詳細(xì)了。
當(dāng)然此方案美團(tuán)還做了一些別的優(yōu)化,監(jiān)控ID使用頻率,自動設(shè)置步長step,從而達(dá)到對ID節(jié)省使用。
來源:toutiao.com/i6682672464708764174
推薦閱讀:
世界的真實(shí)格局分析,地球人類社會底層運(yùn)行原理
企業(yè)IT技術(shù)架構(gòu)規(guī)劃方案
論數(shù)字化轉(zhuǎn)型——轉(zhuǎn)什么,如何轉(zhuǎn)?
企業(yè)10大管理流程圖,數(shù)字化轉(zhuǎn)型從業(yè)者必備!
【中臺實(shí)踐】華為大數(shù)據(jù)中臺架構(gòu)分享.pdf
數(shù)字化轉(zhuǎn)型的本質(zhì)(10個關(guān)鍵詞)
小米用戶畫像實(shí)戰(zhàn),48頁P(yáng)PT下載
超詳細(xì)280頁Docker實(shí)戰(zhàn)文檔!開放下載