
支付對賬系統(tǒng)序章:千萬級數(shù)據(jù)對賬怎么這么難?
支付對賬
很早 ? 之前寫過一篇支付對賬相關文章,那時候負責對賬系統(tǒng)日均處理數(shù)量比較小。
那最近正在接手現(xiàn)在的對賬系統(tǒng),由于當前系統(tǒng)日均數(shù)量都在千萬級,所以對賬系統(tǒng)架構與之前架構完全不一樣。
那就這個話題,聊聊如何實現(xiàn)千萬級數(shù)據(jù)支付的對賬系統(tǒng)。
什么是對賬?
我們先來回顧下什么是對賬?
也許你對對賬這個概念比較模糊,但是這個場景你肯定碰到過。
上班路上買了一個煎餅,加了根里脊與王中王,然后你掃了老板的二維碼付了 10 元錢。
你跟老板說你已經(jīng)付了 10 元錢,老板看了下手機,果然有一條 10 元支付記錄,老板確認收到錢,然后就把煎餅給你。
這個過程,你說你付了 10 元,老板確認收到 10 元,這就是一只簡單的對賬過程。
回到我們支付場景,用戶下單使用微信支付 100 元購買了一個狗頭抱枕,這時我們這邊會生成一條支付記錄,同時微信支付也會生成記錄。
那微信第二天就會生成一個賬單記錄,我們拿到之后把我們的交易記錄跟微信記錄逐筆核對,這就是支付對賬。
為什么需要對賬?
正常支付的情況下,兩邊(我們/第三方支付渠道)都會產(chǎn)生交易數(shù)據(jù),那支付對賬過程,兩邊數(shù)據(jù)一致,大家各自安好,不用處理什么。
但是有些異常情況下,可能由于網(wǎng)絡問題,導致兩邊數(shù)據(jù)存在不一致的情況,支付對賬就可以主動發(fā)現(xiàn)這些交易。
對賬可以說支付系統(tǒng)最后一道安全防線,通過對賬我們可及時的對之前支付進行糾錯,避免訂單差錯越積越多,最后財務盤點變成一筆糊涂賬。
支付對賬系統(tǒng)
開篇先來一張圖,先來看下整體對賬系統(tǒng)架構圖:
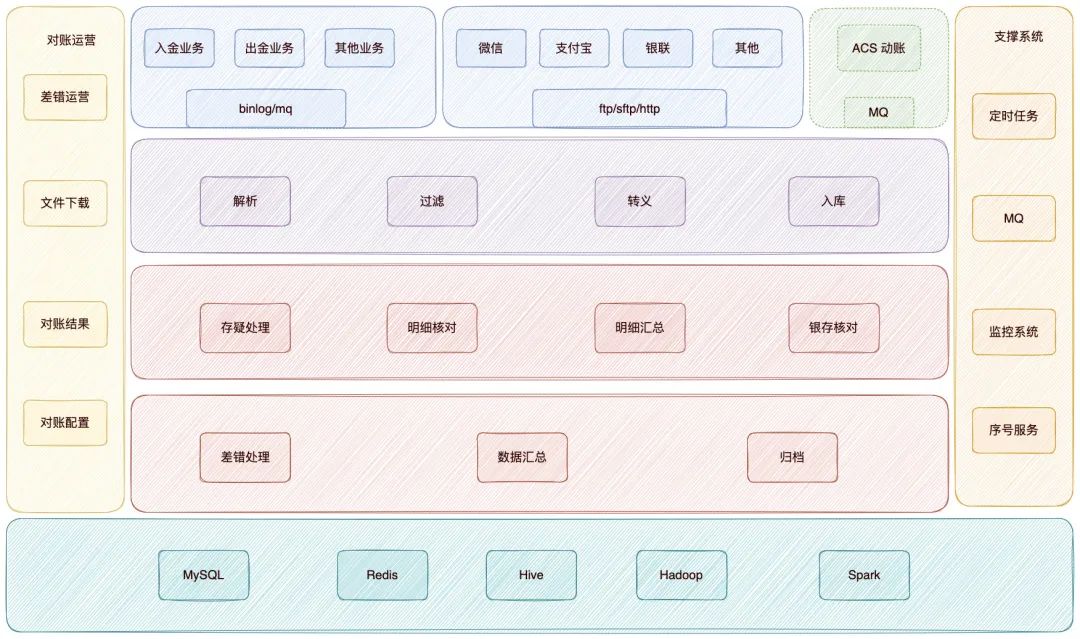
整個對賬系統(tǒng)分為兩個模塊
對賬模塊 差錯模塊
對賬模塊,主要負責對賬文件拉取,數(shù)據(jù)解析,數(shù)據(jù)核對,數(shù)據(jù)匯總等任務。
差錯模塊是對賬模塊后置任務,對賬模塊核對過程產(chǎn)生無法核對成功的數(shù)據(jù),這類數(shù)據(jù)件將會推送給差錯系統(tǒng)。
差錯系統(tǒng)將會根據(jù)規(guī)則生成差錯訂單,運營人員可以在后臺處理這列數(shù)據(jù)。
今天這篇文章先不聊具體的系統(tǒng)設計,先來回顧下之前的對賬系統(tǒng)設計,簡單了解下對賬的整體流程。
對賬系統(tǒng)設計
對賬系統(tǒng)如果從流程上來講,其實非常簡單,引用一下之前文章流程圖:
https://studyidea.cn/articles/2019/08/26/1566790305561.html

整體流程可以簡單分為三個模塊:
本端數(shù)據(jù)處理 對端數(shù)據(jù)處理 本端數(shù)據(jù)與渠道端數(shù)據(jù)核對
本端數(shù)據(jù)指的是我們應用產(chǎn)生的支付記錄,這里根據(jù)賬期(交易日期)與渠道編號獲取單一渠道的所有支付記錄。
對端數(shù)據(jù)指的是第三方支付渠道支付記錄,一般通過下載對賬文件獲取。
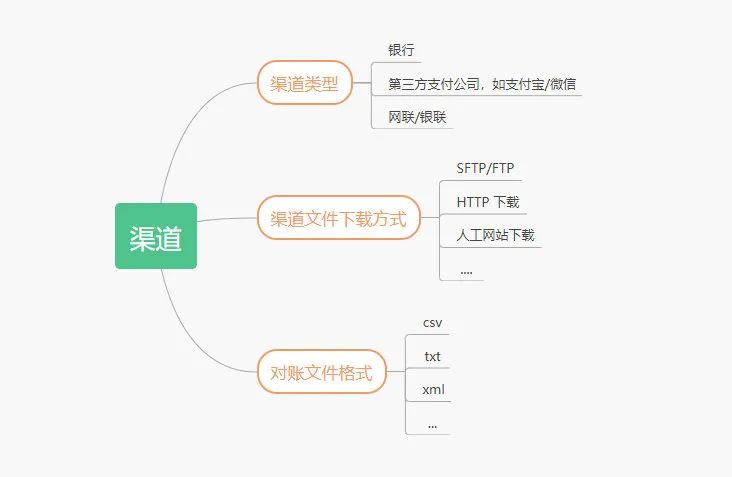
由于每個渠道下載方式,文件格式都不太一樣,對端數(shù)據(jù)處理的時候需要將其轉化統(tǒng)一數(shù)據(jù)格式,標準化在入庫存儲。
網(wǎng)上找了一份通用賬單,可以參考:
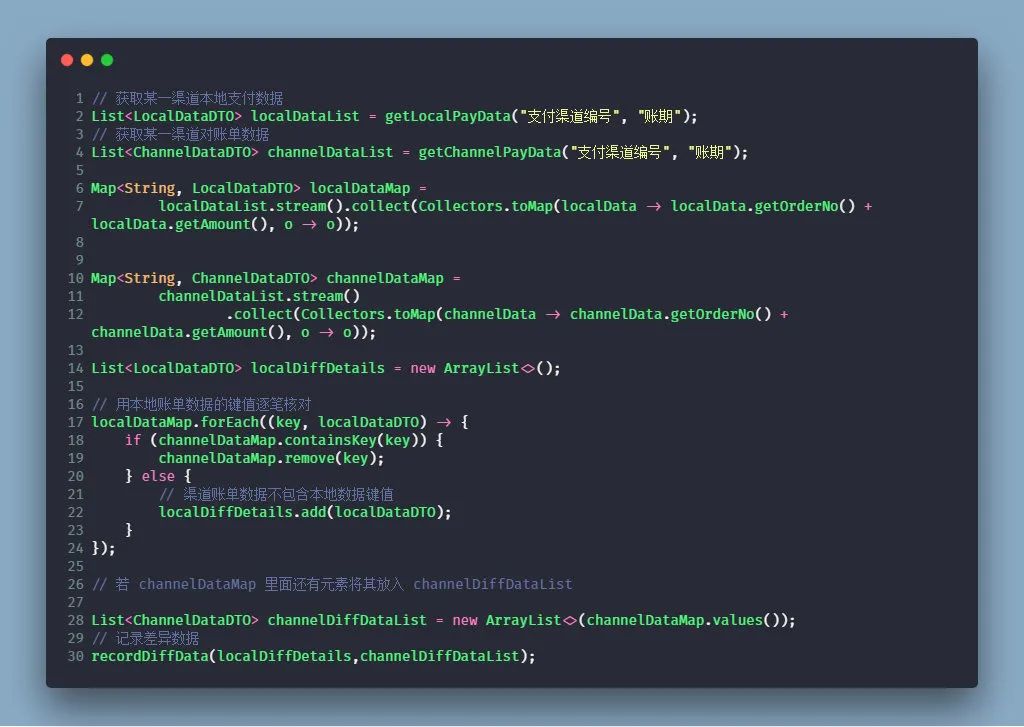
對端數(shù)據(jù)轉化存儲之后,對賬流程中,對端數(shù)據(jù)也需要跟本端數(shù)據(jù)一樣,獲取當前賬期下所有記錄。
兩端數(shù)據(jù)都獲取成功之后,接下來就是本地數(shù)據(jù)逐筆核對。
核對流程可以參考之前寫的流程:
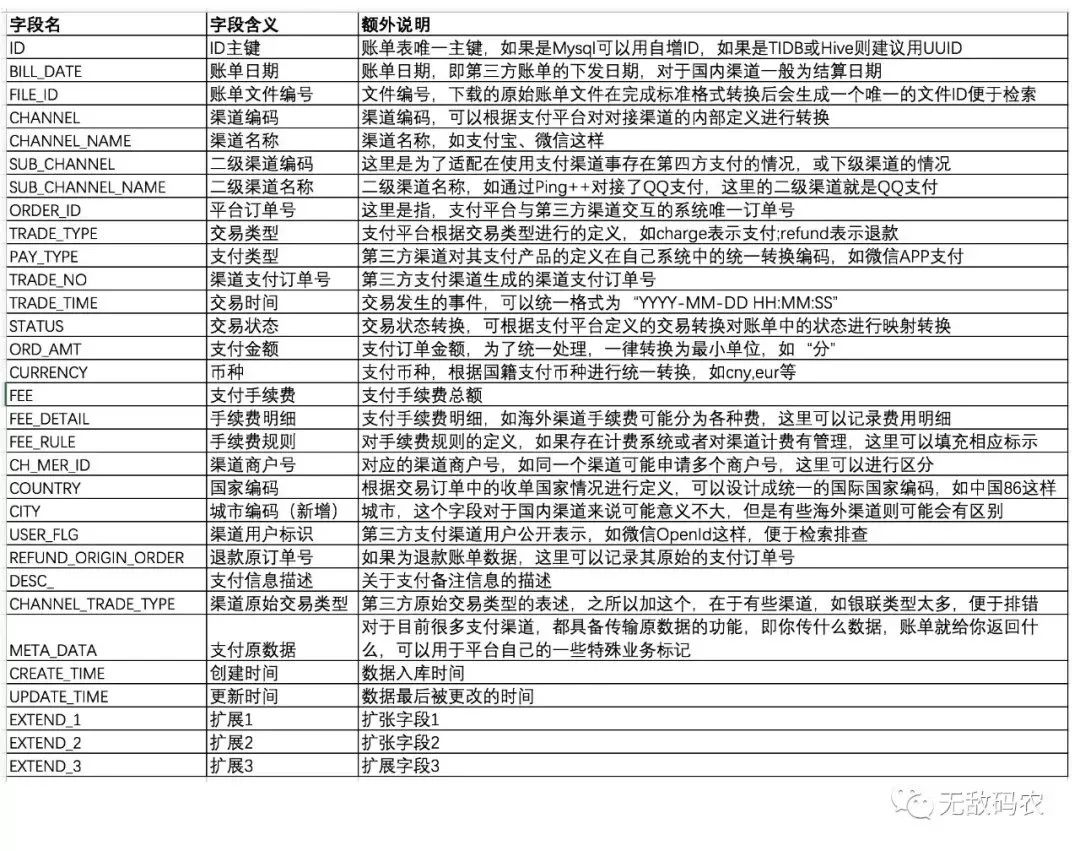
上面流程其實也比較簡單,翻譯一下:
查找本端數(shù)據(jù)/對端數(shù)據(jù),然后轉化存儲到 Map 中,其中 key 為訂單號,value 為本端/對端訂單對象。
然后遍歷本端數(shù)據(jù) Map 對象,依次去對端數(shù)據(jù) Map查找。如果能查找到,說明對端數(shù)據(jù)也有這筆。這筆核對成功,對端數(shù)據(jù)集中移除這筆。
如果查找不到,說明這筆數(shù)據(jù)為差異數(shù)據(jù),它在本端存在,對端不存在 ,將其移動到差異數(shù)據(jù)集中。
最后,本端數(shù)據(jù)遍歷結束,如果對端數(shù)據(jù)集還存在數(shù)據(jù),那就證明這些數(shù)據(jù)也是差異數(shù)據(jù),他們在對端存在,本端不存在 ,將其也移動到差異數(shù)據(jù)集中。
PS:上述流程存在瑕疵,只能核對出兩邊訂單互有缺失的流程 ,但是實際情況下還會碰到兩邊訂單都存在,但是訂單金額卻不一樣的差異數(shù)據(jù)。這種情況有可能發(fā)現(xiàn)在系統(tǒng) Bug,比如渠道端上送金額單位為元,但是實際上送金額單位為分,這就導致對賬兩端金額不一致。
之前對賬系統(tǒng)日均處理的支付數(shù)據(jù)峰值在幾十萬,所以上面的流程沒什么問題,還可以抗住,正常處理。
但是目前的支付數(shù)據(jù)日均在千萬級,如果還是用這種方式對賬,當前系統(tǒng)可能會直接崩了。。。
千萬數(shù)據(jù)級帶來的挑戰(zhàn)
第一個,查詢效率。
本端/對端數(shù)據(jù)通過分頁查詢業(yè)務數(shù)據(jù)表獲取當天所有的數(shù)據(jù)。隨著每天支付數(shù)據(jù)累計,業(yè)務表中數(shù)據(jù)將會越來越多,這就會導致數(shù)據(jù)查詢變慢。
實際過程我們發(fā)現(xiàn),單個渠道數(shù)據(jù)量很大的情況下,對賬完成需要一兩個小時。
雖然說對賬是一個離線流程,允許對賬完成時間可以久一點。但是對賬流程是后續(xù)其他任務的前置流程,整個對賬流程還是需要在中午之前完成,這樣運營同學就可以在下午處理。
第二個問題,OOM。
上面流程中,我們把把全部數(shù)據(jù)加載到內存中,小數(shù)據(jù)量下沒什么問題。
但是在千萬級數(shù)據(jù)情況下,數(shù)據(jù)都加載到內存中,并且還是加載了兩份數(shù)據(jù)(本端、對端),這就很容易吃完整個應用內存,從而導致 Full GC,甚至還有可能導致應用 OOM。
而且這還會導致級聯(lián)反應,一個任務引發(fā) Full GC,導致其他渠道對賬收到影響。
第三個問題,性能問題。
原先系統(tǒng)設計上,單一渠道對賬處理流程只能在單個機器上處理,無法并行處理。
這就導致系統(tǒng)設計伸縮性很差,服務器資源也被大量的浪費。
千萬數(shù)據(jù)級對賬解決辦法
上面系統(tǒng)代碼,實際上還是存在優(yōu)化空間,可以利用單機多線程并行處理,但是大數(shù)據(jù)下其實帶來效果不是很好。
那主要原因是因為發(fā)生在系統(tǒng)架構上,當前系統(tǒng)使用底層使用 MySQL 處理的。
傳統(tǒng)的 MySQL 是 OLTP (on-line transaction processing),這個結構決定它適合用于高并發(fā),小事務 業(yè)務數(shù)據(jù)處理。
但是對賬業(yè)務特性動輒就是百萬級,千萬級數(shù)據(jù),數(shù)據(jù)量處理非常大。但是對賬數(shù)據(jù)處理大多是一次性,不會頻繁更新。
上面業(yè)務特性決定了,MySQL 這種 OLTP 系統(tǒng)不太適合大數(shù)據(jù)級對賬業(yè)務。
那專業(yè)的事應該交給專業(yè)的人去做,對賬業(yè)務也一樣,這種大數(shù)據(jù)級業(yè)務比較適合由 Hive、Spark SQL 等 OLAP去做。
總結
今天本篇文章只是一個序曲,主要聊聊對賬業(yè)務基本流程,聊聊之前系統(tǒng)架構在大數(shù)據(jù)下存在的問題。
后面文章再會介紹下大數(shù)據(jù)下對賬系統(tǒng)如何設計,對賬之后差錯數(shù)據(jù)如何處理,盡請期待。