
使用 Cilium 給 K8s 數(shù)據(jù)平面提供強(qiáng)大的帶寬管理功能
?本文轉(zhuǎn)自趙亞楠的博客,原文:https://arthurchiao.art/blog/better-bandwidth-management-with-ebpf-zh/,版權(quán)歸原作者所有。歡迎投稿,投稿請?zhí)砑游⑿藕糜眩?strong style="color: rgb(50, 108, 229);">cloud-native-yang
本文翻譯自 KubeCon+CloudNativeCon Europe 2022 的一篇分享:Better Bandwidth Management with eBPF[1]。
作者 Daniel Borkmann, Christopher, Nikolay 都來自 Isovalent(Cilium 母公司)。翻譯時(shí)補(bǔ)充了一些背景知識(shí)、代碼片段和鏈接,以方便理解。
由于譯者水平有限,本文不免存在遺漏或錯(cuò)誤之處。如有疑問,請查閱原文。
以下是譯文。
問題描述
容器部署密度與(CPU、內(nèi)存)資源管理
下面兩張圖來自 Sysdig 2022 的一份調(diào)研報(bào)告,
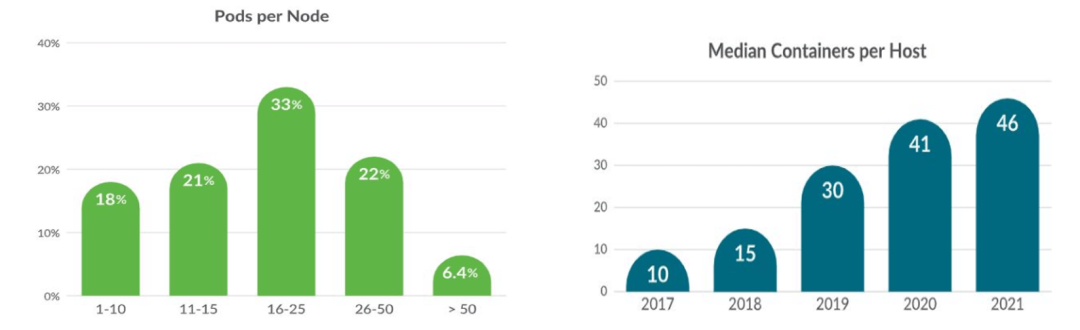
左圖是容器的部署密度分布,比如 33% 的 k8s 用戶中,每個(gè) node 上平均會(huì)部署 16~25 個(gè) Pod; 右圖是每臺(tái)宿主機(jī)上的容器中位數(shù),可以看到過去幾年明顯在不斷增長。
這兩個(gè)圖說明:容器的部署密度越來越高。這導(dǎo)致的 CPU、內(nèi)存等資源競爭將更加激烈, 如何管理資源的分配或配額就越來越重要。具體到 CPU 和 memory 這兩種資源, K8s 提供了 resource requests/limits 機(jī)制,用戶或管理員可以指定一個(gè) Pod 需要用到的資源量(requests)和最大能用的資源量(limits),
apiVersion: v1
kind: Pod
metadata:
name: frontend
spec:
containers:
- name: app
image: nginx-slim:0.8
resources:
requests: ## 容器需要的資源量,kubelet 會(huì)將 pod 調(diào)度到剩余資源大于這些聲明的 node 上去
memory: "64Mi"
cpu: "250m"
limits: ## 容器能使用的硬性上限(hard limit),超過這個(gè)閾值容器就會(huì)被 OOM kill
memory: "128Mi"
cpu: "500m"
kube-scheduler會(huì)將 pod 調(diào)度到能滿足resource.requests聲明的資源需求的 node 上;如果 pod 運(yùn)行之后使用的內(nèi)存超過了 memory limits,就會(huì)被操作系統(tǒng)以 OOM (Out Of Memory)為由干掉。
這種針對 CPU 和 memory 的資源管理機(jī)制還是不錯(cuò)的, 那么,網(wǎng)絡(luò)方面有沒有類似的機(jī)制呢?
網(wǎng)絡(luò)資源管理:帶寬控制模型
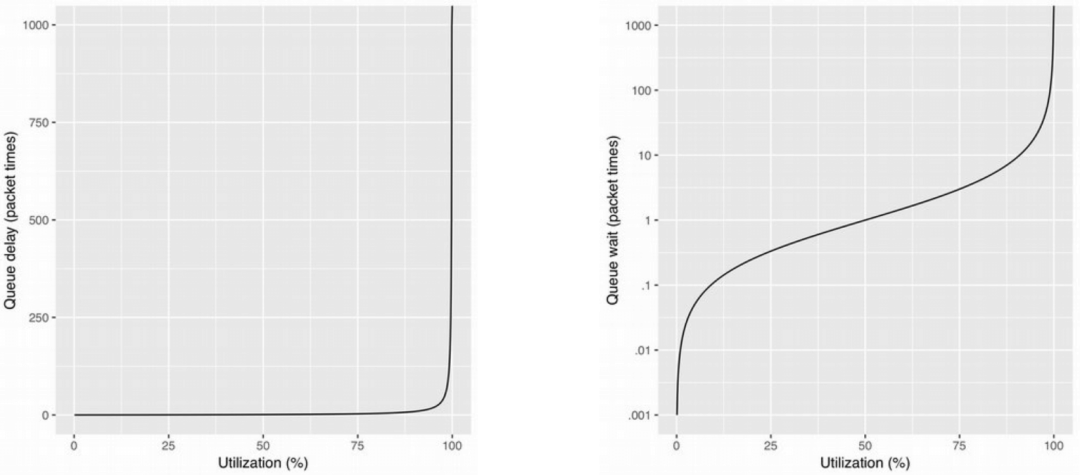
先回顧下基礎(chǔ)的網(wǎng)絡(luò)知識(shí)。下圖是往返時(shí)延(Round-Trip)與 TCP 擁塞控制效果之間的關(guān)系,

結(jié)合 流量控制(TC)五十年:從基于緩沖隊(duì)列(Queue)到基于時(shí)間戳(EDT)的演進(jìn)(Google, 2018)[2], 這里只做幾點(diǎn)說明:
TCP 的發(fā)送模型是盡可能快(As Fast As Possible, AFAP) 網(wǎng)絡(luò)流量主要是靠網(wǎng)絡(luò)設(shè)備上的出向隊(duì)列(device output queue)做整形(shaping) 隊(duì)列長度(queue length)和接收窗口(receive window)決定了傳輸中的數(shù)據(jù)速率(in-flight rate) “多快”(how fast)取決于隊(duì)列的 drain rate
現(xiàn)在回到我們剛才提出的問題(k8s 網(wǎng)絡(luò)資源管理), 在 K8s 中,有什么機(jī)制能限制 pod 的網(wǎng)絡(luò)資源(帶寬)使用量嗎?
K8s 中的 pod 帶寬管理
Bandwidth meta plugin
K8s 自帶了一個(gè)限速(bandwidth enforcement)機(jī)制,但到目前為止還是 experimental 狀態(tài);實(shí)現(xiàn)上是通過第三方的 bandwidth meta plugin,它會(huì)解析特定的 pod annotation,
kubernetes.io/ingress-bandwidth=XXkubernetes.io/egress-bandwidth=XX
然后轉(zhuǎn)化成對 pod 的具體限速規(guī)則,如下圖所示,

bandwidth meta plugin 是一個(gè) CNI plugin,底層利用 Linux TC 子系統(tǒng)中的 TBF, 所以最后轉(zhuǎn)化成的是 TC 限速規(guī)則,加在容器的 veth pair 上(宿主機(jī)端)。
這種方式確實(shí)能實(shí)現(xiàn) pod 的限速功能,但也存在很嚴(yán)重的問題,我們來分別看一下出向和入向的工作機(jī)制。
?在進(jìn)入下文之前,有兩點(diǎn)重要說明:
限速只能在出向(egress)做。為什么?可參考 《Linux 高級(jí)路由與流量控制手冊(2012)》第九章:用 tc qdisc 管理 Linux 網(wǎng)絡(luò)帶寬[3]; veth pair 宿主機(jī)端的流量方向與 pod 的流量方向完全相反,也就是 pod 的 ingress 對應(yīng)宿主機(jī)端 veth 的 egress,反之亦然。 譯注。
入向(ingress)限速存在的問題
對于 pod ingress 限速,需要在宿主機(jī)端 veth 的 egress 路徑上設(shè)置規(guī)則。例如,對于入向 kubernetes.io/ingress-bandwidth="50M" 的聲明,會(huì)落到 veth 上的 TBF qdisc 上:

TBF(Token Bucket Filter)是個(gè)令牌桶,所有連接/流量都要經(jīng)過單個(gè)隊(duì)列排隊(duì)處理,如下圖所示:
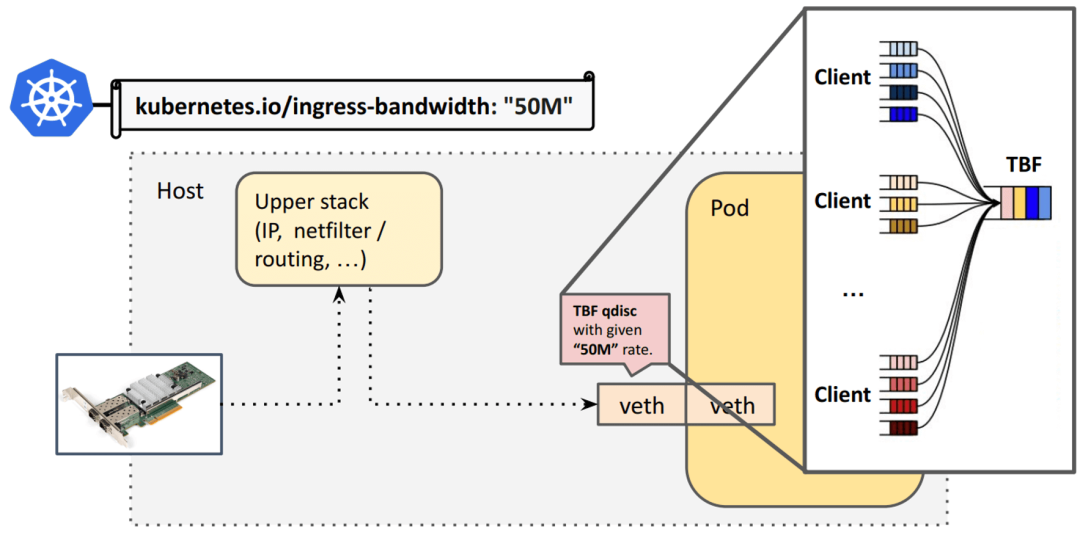
在設(shè)計(jì)上存在的問題:
TBF qdisc 所有 CPU 共享一個(gè)鎖(著名的 qdisc root lock),因此存在鎖競爭;流量越大鎖開銷越大; veth pair 是單隊(duì)列(single queue)虛擬網(wǎng)絡(luò)設(shè)備,因此物理網(wǎng)卡的 多隊(duì)列(multi queue,不同 CPU 處理不同 queue,并發(fā))優(yōu)勢到了這里就沒用了, 大家還是要走到同一個(gè)隊(duì)列才能進(jìn)到 pod; 在入向排隊(duì)是不合適的(no-go),會(huì)占用大量系統(tǒng)資源和緩沖區(qū)開銷(bufferbloat)。
出向(egress)限速存在的問題
出向工作原理:
Pod egress 對應(yīng) veth 主機(jī)端的 ingress,ingress 是不能做整形的,因此加了一個(gè) ifb 設(shè)備; 所有從 veth 出來的流量會(huì)被重定向到 ifb 設(shè)備,通過 ifb TBF qdisc 設(shè)置容器限速。
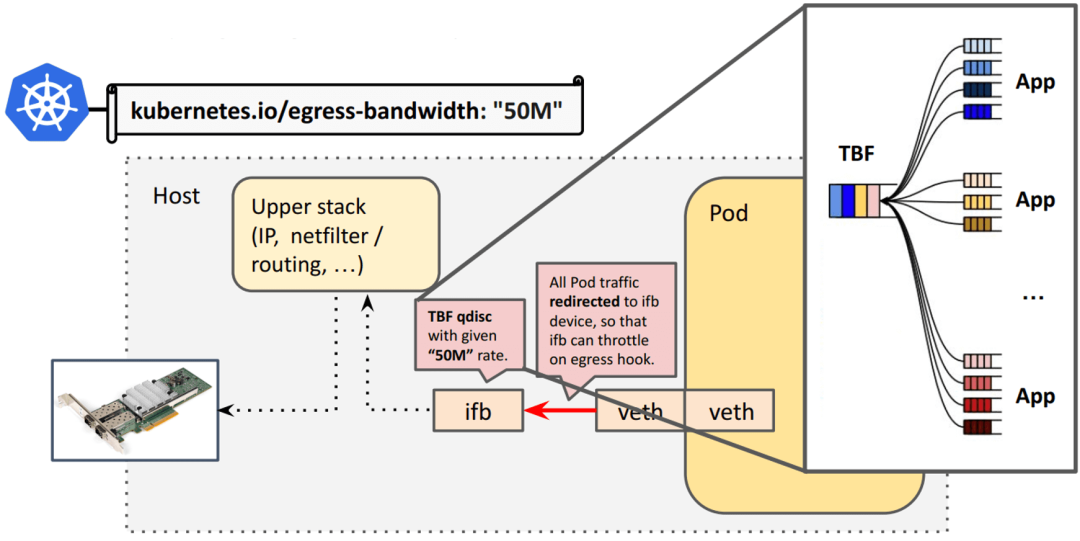
存在的問題:
原來只需要在物理網(wǎng)卡排隊(duì)(一般都會(huì)設(shè)置一個(gè)默認(rèn) qdisc,例如 pfifo_fast/fq_codel/noqueue),現(xiàn)在又多了一層 ifb 設(shè)備排隊(duì),緩沖區(qū)膨脹(bufferbloat);與 ingress 一樣,存在 root qdisc lock 競爭,所有 CPU 共享; 干擾 TCP Small Queues (TSQ) 正常工作;TSQ 作用是減少 bufferbloat, 工作機(jī)制是覺察到發(fā)出去的包還沒有被有效處理之后就減少發(fā)包;ifb 使得包都緩存在 qdisc 中, 使 TSQ 誤以為這些包都已經(jīng)發(fā)出去了,實(shí)際上還在主機(jī)內(nèi)。 延遲顯著增加:每個(gè) pod 原來只需要 2 個(gè)網(wǎng)絡(luò)設(shè)備,現(xiàn)在需要 3 個(gè),增加了大量 queueing 邏輯。

Bandwidth meta plugin 問題總結(jié)
總結(jié)起來:
擴(kuò)展性差,性能無法隨 CPU 線性擴(kuò)展(root qdisc lock 被所有 CPU 共享導(dǎo)致); 導(dǎo)致額外延遲; 占用額外資源,緩沖區(qū)膨脹。
因此不適用于生產(chǎn)環(huán)境;
解決思路
?這一節(jié)是介紹 Google 的基礎(chǔ)性工作,作者引用了 Evolving from AFAP: Teaching NICs about time (Netdev, 2018)[4] 中的一些內(nèi)容;之前我們已翻譯,見 流量控制(TC)五十年:從基于緩沖隊(duì)列(Queue)到基于時(shí)間戳(EDT)的演進(jìn)(Google, 2018)[5], 因此一些內(nèi)容不再贅述,只列一下要點(diǎn)。
譯注。
回歸源頭:TCP “盡可能快”發(fā)送模型存在的缺陷
思路轉(zhuǎn)變:不再基于排隊(duì)(queue),而是基于時(shí)間戳(EDT)
兩點(diǎn)核心轉(zhuǎn)變:
每個(gè)包(skb)打上一個(gè)最早離開時(shí)間(Earliest Departure Time, EDT),也就是最早可以發(fā)送的時(shí)間戳; 用時(shí)間輪調(diào)度器(timing-wheel scheduler)替換原來的出向緩沖隊(duì)列(qdisc queue)
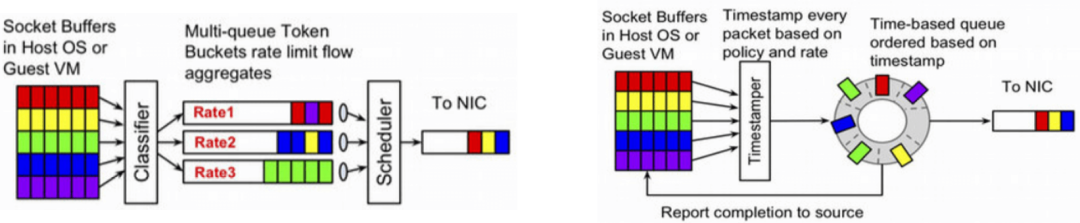
EDT/timing-wheel 應(yīng)用到 K8s
有了這些技術(shù)基礎(chǔ),我們接下來看如何應(yīng)用到 K8s。
Cilium 原生 pod 限速方案
整體設(shè)計(jì):基于 BPF+EDT 實(shí)現(xiàn)容器限速
Cilium 的 bandwidth manager,
基于 eBPF+EDT,實(shí)現(xiàn)了無鎖 的 pod 限速功能; 在物理網(wǎng)卡(或 bond 設(shè)備)而不是 veth 上限速,避免了 bufferbloat,也不會(huì)擾亂 TCP TSQ 功能。 不需要進(jìn)入?yún)f(xié)議棧,Cilium 的 BPF host routing 功能,使得 FIB lookup 等過程完全在 TC eBPF 層完成,并且能直接轉(zhuǎn)發(fā)到網(wǎng)絡(luò)設(shè)備。 在物理網(wǎng)卡(或 bond 設(shè)備)上添加 MQ/FQ,實(shí)現(xiàn)時(shí)間輪調(diào)度。
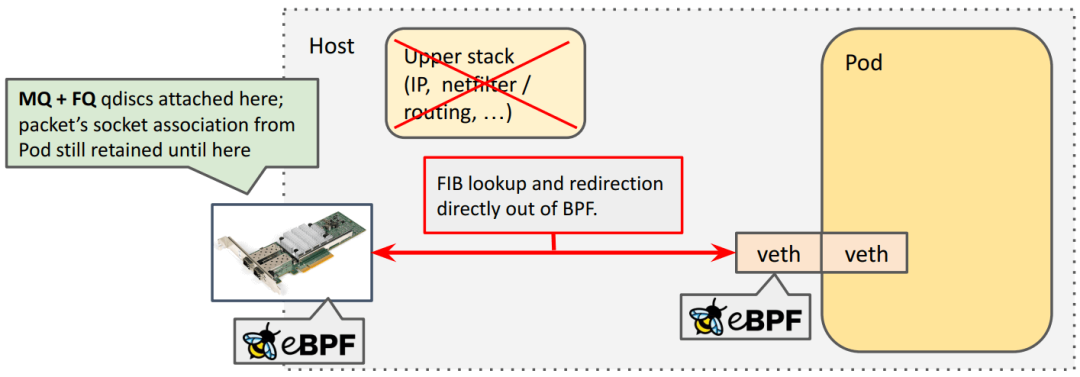
工作流程
在之前的分享 為 K8s workload 引入的一些 BPF datapath 擴(kuò)展(LPC, 2021)[6] 中已經(jīng)有比較詳細(xì)的介紹,這里在重新整理一下。
Cilium attach 到宿主機(jī)的物理網(wǎng)卡(或 bond 設(shè)備),在 BPF 程序中為每個(gè)包設(shè)置 timestamp, 然后通過 earliest departure time 在 fq 中實(shí)現(xiàn)限速,下圖:
?注意:容器限速是在物理網(wǎng)卡上做的,而不是在每個(gè) pod 的 veth 設(shè)備上。這跟之前基于 ifb 的限速方案有很大不同。

從上到下三個(gè)步驟:
BPF 程序:管理(計(jì)算和設(shè)置) skb 的 departure timestamp; TC qdisc (multi-queue) 發(fā)包調(diào)度; 物理網(wǎng)卡的隊(duì)列。
?如果宿主機(jī)使用了 bond,那么根據(jù) bond 實(shí)現(xiàn)方式的不同,F(xiàn)Q 的數(shù)量會(huì)不一樣, 可通過
tc -s -d qdisc show dev {bond}查看實(shí)際狀態(tài)。具體來說,
Linux bond 默認(rèn)支持多隊(duì)列(multi-queue),會(huì)默認(rèn)創(chuàng)建 16 個(gè) queue[7], 每個(gè) queue 對應(yīng)一個(gè) FQ,掛在一個(gè) MQ 下面,也就是上面圖中畫的; OVS bond 不支持 MQ,因此只有一個(gè) FQ(v2.3 等老版本行為,新版本不清楚)。 bond 設(shè)備的 TXQ 數(shù)量,可以通過
ls /sys/class/net/{dev}/queues/查看。物理網(wǎng)卡的 TXQ 數(shù)量也可以通過以上命令看,但ethtool -l {dev}看到的信息更多,包括了最大支持的數(shù)量和實(shí)際啟用的數(shù)量。譯注。
數(shù)據(jù)包處理過程
先復(fù)習(xí)下 Cilium datapath,細(xì)節(jié)見 2020 年的分享:

egress 限速工作流程:
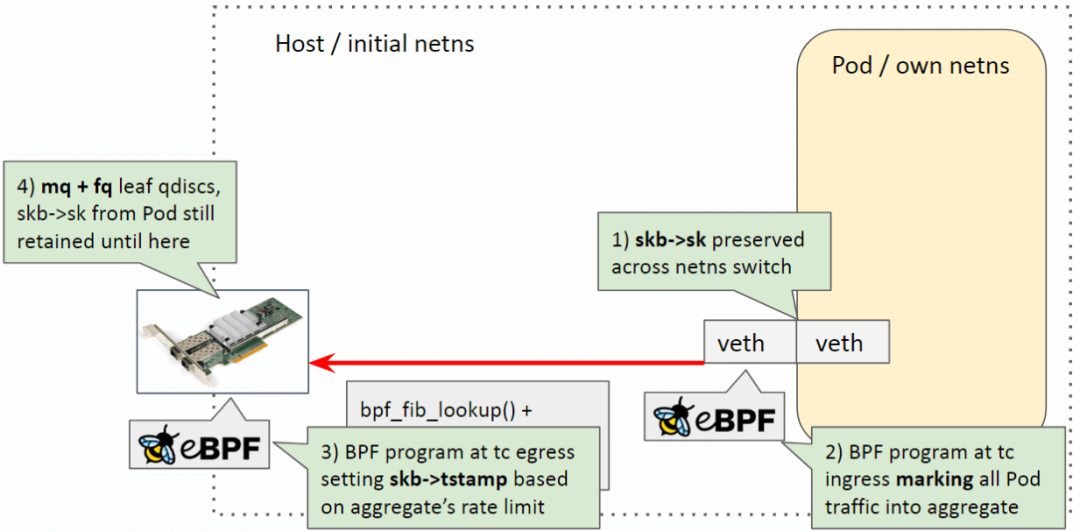
Pod egress 流量從容器進(jìn)入宿主機(jī),此時(shí)會(huì)發(fā)生 netns 切換,但 socket 信息 skb->sk不會(huì)丟失;Host veth 上的 BPF 標(biāo)記(marking)包的 aggregate(queue_mapping),見 Cilium 代碼[8]; 物理網(wǎng)卡上的 BPF 程序根據(jù) aggregate 設(shè)置的限速參數(shù),設(shè)置每個(gè)包的時(shí)間戳 skb->tstamp;FQ+MQ 基本實(shí)現(xiàn)了一個(gè) timing-wheel 調(diào)度器,根據(jù) skb->tstamp調(diào)度發(fā)包。
過程中用到了 bpf map 存儲(chǔ) aggregate 信息。
性能對比:Cilium vs. Bandwidth meta plugin
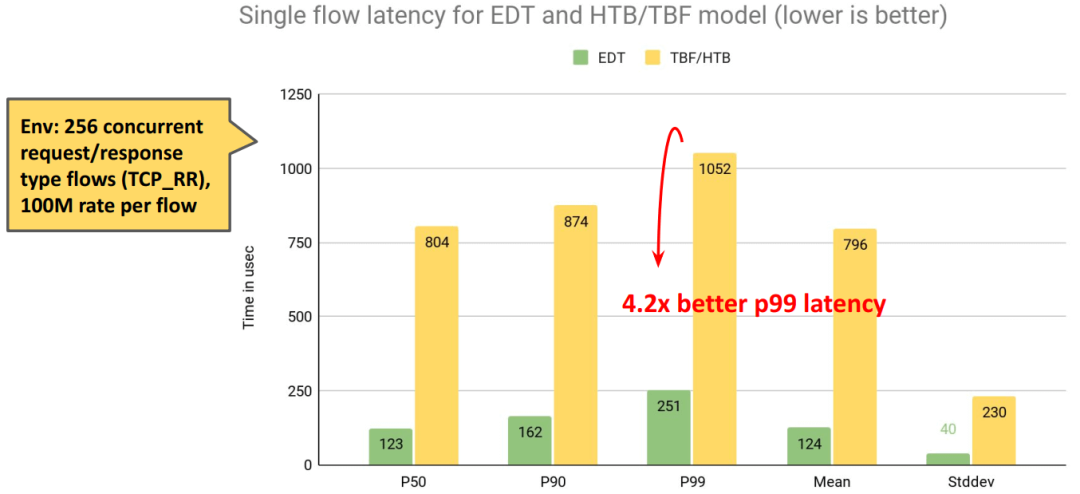
netperf 壓測。
同樣限速 100M,延遲下降:
同樣限速 100M,TPS:

小結(jié)
主機(jī)內(nèi)的問題解決了,那更大范圍 —— 即公網(wǎng)帶寬 —— 管理呢?

別著急,EDT 還能支持 BBR。
公網(wǎng)傳輸:Cilium 基于 BBR 的帶寬管理
BBR 基礎(chǔ)
?想完整了解 BBR 的設(shè)計(jì),可參考 (論文) BBR:基于擁塞(而非丟包)的擁塞控制(ACM, 2017)。譯注。
設(shè)計(jì)初衷
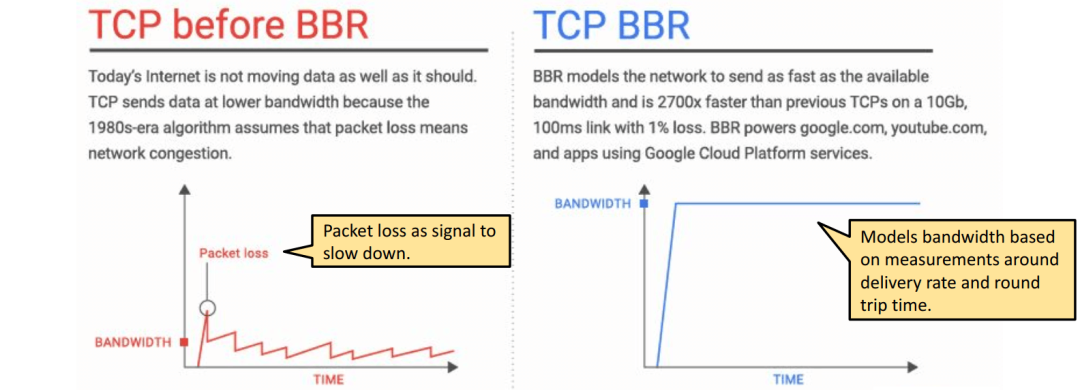
性能對比:bbr vs. cubic
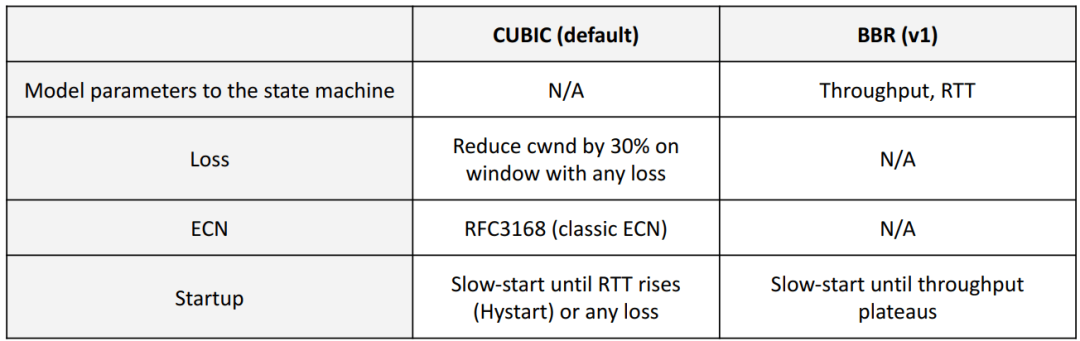
CUBIC + fq_codel:
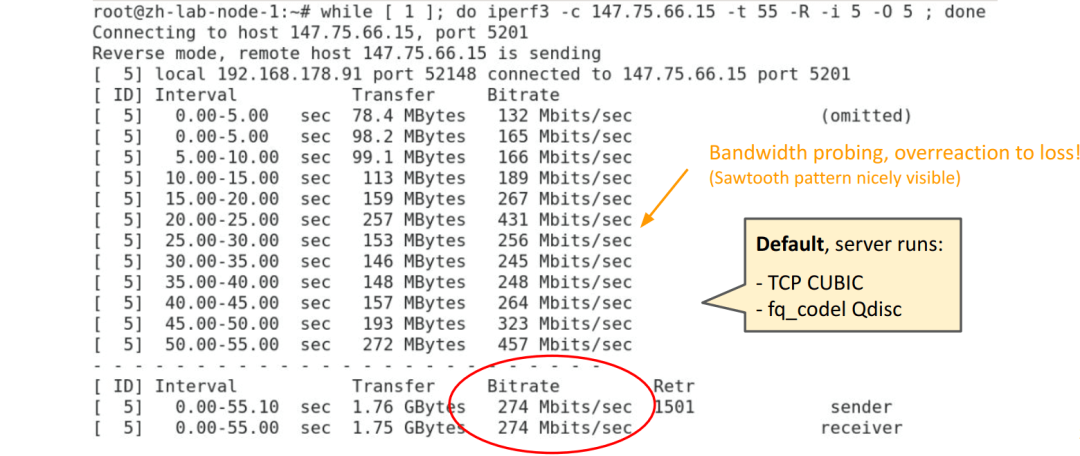
BBR + FQ (for EDT):
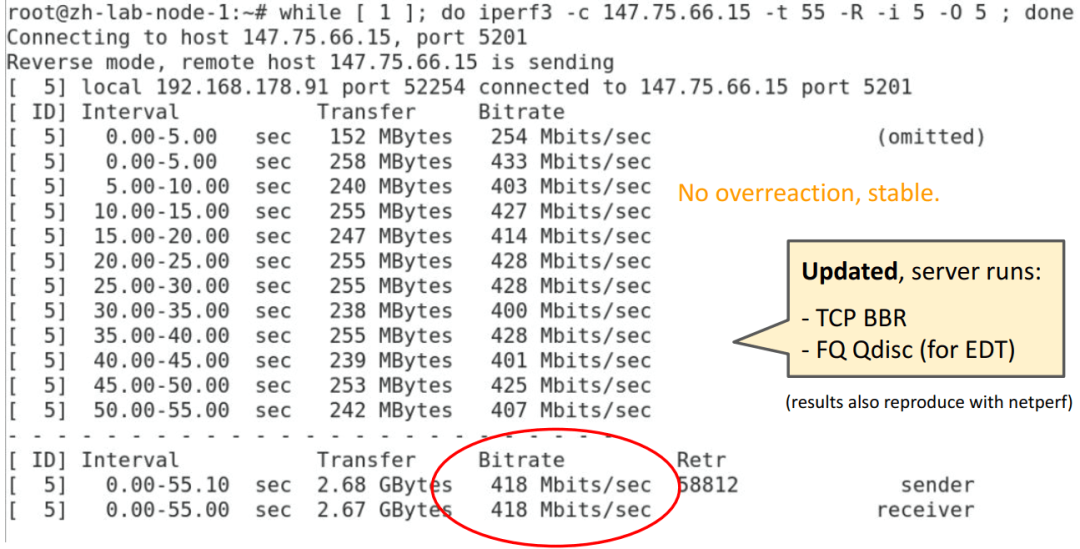
效果非常明顯。
BBR + K8s/Cilium
存在的問題:跨 netns 時(shí),skb->tstamp 要被重置
BBR 能不能用到 k8s 里面呢?
BBR + FQ 機(jī)制上是能協(xié)同工作的;但是, 內(nèi)核在 skb 離開 pod netns 時(shí),將 skb 的時(shí)間戳清掉了,導(dǎo)致包進(jìn)入 host netns 之后沒有時(shí)間戳,F(xiàn)Q 無法工作
問題如下圖所示,
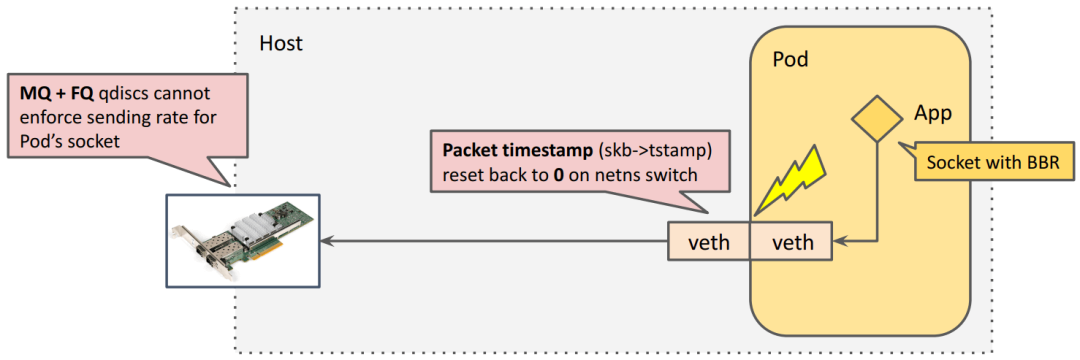
為什么會(huì)被重置
下面介紹一些背景,為什么這個(gè) ts 會(huì)被重置。
?幾種時(shí)間規(guī)范:https://www.cl.cam.ac.uk/~mgk25/posix-clocks.html
對于包的時(shí)間戳 skb->tstamp,內(nèi)核根據(jù)包的方向(RX/TX)不同而使用的兩種時(shí)鐘源:
Ingress 使用 CLOCK_TAI (TAI: international atomic time) Egress 使用 CLOCK_MONOTONIC(也是 FQ 使用的時(shí)鐘類型)
如果不重置,將包從 RX 轉(zhuǎn)發(fā)到 TX 會(huì)導(dǎo)致包在 FQ 中被丟棄,因?yàn)?超過 FQ 的 drop horizon[9]。FQ horizon 默認(rèn)是 10s[10]。
?
horizon是 FQ 的一個(gè)配置項(xiàng),表示一個(gè)時(shí)間長度, 在 net_sched: sch_fq: add horizon attribute[11] 引入,QUIC servers would like to use SO_TXTIME, without having CAP_NET_ADMIN,
to efficiently pace UDP packets.
As far as sch_fq is concerned, we need to add safety checks, so
that a buggy application does not fill the qdisc with packets
having delivery time far in the future.
This patch adds a configurable horizon (default: 10 seconds),
and a configurable policy when a packet is beyond the horizon
at enqueue() time:
- either drop the packet (default policy)
- or cap its delivery time to the horizon.簡單來說,如果一個(gè)包的時(shí)間戳離現(xiàn)在太遠(yuǎn),就直接將這個(gè)包 丟棄,或者將其改為一個(gè)上限值(cap),以便節(jié)省隊(duì)列空間;否則,這種 包太多的話,隊(duì)列可能會(huì)被塞滿,導(dǎo)致時(shí)間戳比較近的包都無法正常處理。內(nèi)核代碼[12]如下:
static bool fq_packet_beyond_horizon(const struct sk_buff *skb, const struct fq_sched_data *q)
{
return unlikely((s64)skb->tstamp > (s64)(q->ktime_cache + q->horizon));
}譯注。
另外,現(xiàn)在給定一個(gè)包,我們無法判斷它用的是哪種 timestamp,因此只能用這種 reset 方式。
能將 skb->tstamp 統(tǒng)一到同一種時(shí)鐘嗎?
其實(shí)最開始,TCP EDT 用的也是 CLOCK_TAI 時(shí)鐘。但有人在郵件列表[13] 里反饋說,某些特殊的嵌入式設(shè)備上重啟會(huì)導(dǎo)致時(shí)鐘漂移 50 多年。所以后來 EDT 又回到了 monotonic 時(shí)鐘,而我們必須跨 netns 時(shí) reset。
我們做了個(gè)原型驗(yàn)證,新加一個(gè) bit skb->tstamp_base 來解決這個(gè)問題,
0 表示使用的 TAI, 1 表示使用的 MONO,
然后,
TX/RX 通過 skb_set_tstamp_{mono,tai}(skb, ktime)helper 來獲取這個(gè)值,fq_enqueue()先檢查 timestamp 類型,如果不是 MONO,就 resetskb->tstamp
此外,
轉(zhuǎn)發(fā)邏輯中所有 skb->tstamp = 0都可以刪掉了skb_mstamp_ns union 也可能刪掉了 在 RX 方向, net_timestamp_check()必須推遲到 tc ingress 之后執(zhí)行
解決
我們和 Facebook 的朋友合作,已經(jīng)解決了這個(gè)問題,在跨 netns 時(shí)保留時(shí)間戳, patch 并合并到了 kernel 5.18+。因此 BBR+EDT 可以工作了,
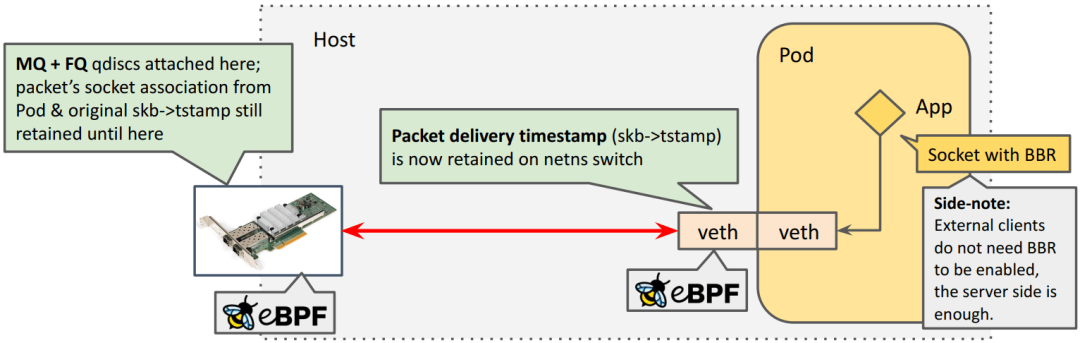
Demo(略)
K8s/Cilium backed video streaming service: CUBIC vs. BBR
BBR 使用注意事項(xiàng)
1?? 如果同一個(gè)環(huán)境(例如數(shù)據(jù)中心)同時(shí)啟用了 BBR 和 CUBIC,那使用 BBR 的機(jī)器會(huì)強(qiáng)占更多的帶寬,造成不公平(unfaireness);

2?? BBR 會(huì)觸發(fā)更高的 TCP 重傳速率,這源自它更加主動(dòng)或激進(jìn)的探測機(jī)制 (higher TCP retransmission rate due to more aggressive probing);
BBRv2 致力于解決以上問題。
總結(jié)及致謝
問題回顧與總結(jié)
K8s 帶寬限速功能可以做地更好; Cilium 的原生帶寬限速功能(v1.12 GA) 基于 BPF+EDT 的高效實(shí)現(xiàn) 第一個(gè)支持 Pod 使用 BBR (及 socket pacing)的 CNI 插件 特別說明:要實(shí)現(xiàn)這樣的架構(gòu),只能用 eBPF(realizing such architecture only possible with eBPF)
致謝
Van Jacobson Eric Dumazet Vytautas Valancius Stanislav Fomichev Martin Lau John Fastabend Cilium, eBPF & netdev kernel community
Cilium 限速方案存在的問題(譯注)
Cilium 的限速功能我們[14] 在 v1.10 就在用了,但是使用下來發(fā)現(xiàn)兩個(gè)問題,到目前(2022.11)社區(qū)還沒有解決,
1?? 啟用 bandwidth manager 之后,Cilium 會(huì) hardcode[15] somaxconn、netdev_max_backlog 等內(nèi)核參數(shù),覆蓋掉用戶自己的內(nèi)核調(diào)優(yōu);
例如,如果 node netdev_max_backlog=8192,那 Cilium 啟動(dòng)之后, 就會(huì)把它強(qiáng)制覆蓋成 1000,導(dǎo)致在大流量場景因?yàn)樗拗鳈C(jī)這個(gè)配置太小而出現(xiàn)丟包。
2?? 啟用 bandwidth manager 再禁用之后,并不會(huì)恢復(fù)到原來的 qdisc 配置,MQ/FQ 是殘留的,導(dǎo)致大流量容器被限流(throttle)。
例如,如果原來物理網(wǎng)卡使用的默認(rèn) pfifo_fast qdisc,或者 bond 設(shè)備默認(rèn)使用 的 noqueue,那啟用再禁用之后,并不到原來的 qdisc 配置。殘留 FQ 的一 個(gè)副作用就是大流量容器的偶發(fā)網(wǎng)絡(luò)延遲,因?yàn)?FQ 要保證 flow 級(jí)別的公平(而實(shí)際場景下并不需要這個(gè)公平,總帶寬不超就行了)。
查看曾經(jīng)啟用 bandwidth manager,但現(xiàn)在已經(jīng)禁用它的 node,可以看到 MQ/FQ 還在,
$ tc qdisc show dev bond0
qdisc mq 8042: root
qdisc fq 0: parent 8042:10 limit 10000p flow_limit 100p buckets 1024 quantum 3028 initial_quantum 15140
qdisc fq 0: parent 8042:f limit 10000p flow_limit 100p buckets 1024 quantum 3028 initial_quantum 15140
...
qdisc fq 0: parent 8042:b limit 10000p flow_limit 100p buckets 1024 quantum 3028 initial_quantum 15140
是否發(fā)生過限流可以在 tc qdisc 統(tǒng)計(jì)中看到:
$ tc -s -d qdisc show dev bond0
qdisc fq 800b: root refcnt 2 limit 10000p flow_limit 100p buckets 1024 orphan_mask 1023 quantum 3028 initial_quantum 15140 refill_delay 40.0ms
Sent 1509456302851808 bytes 526229891 pkt (dropped 176, overlimits 0 requeues 0)
backlog 3028b 2p requeues 0
15485 flows (15483 inactive, 1 throttled), next packet delay 19092780 ns
2920858688 gc, 0 highprio, 28601458986 throttled, 6397 ns latency, 176 flows_plimit
6 too long pkts, 0 alloc errors
要恢復(fù)原來的配置,目前我們只能手動(dòng)刪掉 MQ/FQ。根據(jù)內(nèi)核代碼分析及實(shí)際測試,刪除 qdisc 的操作是無損的:
$ tc qdisc del dev bond0 root
$ tc qdisc show dev bond0
qdisc noqueue 0: root refcnt 2
qdisc clsact ffff: parent ffff:fff1
引用鏈接
Better Bandwidth Management with eBPF: https://kccnceu2022.sched.com/event/ytsQ/better-bandwidth-management-with-ebpf-daniel-borkmann-christopher-m-luciano-isovalent
[2]流量控制(TC)五十年:從基于緩沖隊(duì)列(Queue)到基于時(shí)間戳(EDT)的演進(jìn)(Google, 2018): http://arthurchiao.art/blog/traffic-control-from-queue-to-edt-zh/
[3]《Linux 高級(jí)路由與流量控制手冊(2012)》第九章:用 tc qdisc 管理 Linux 網(wǎng)絡(luò)帶寬: http://arthurchiao.art/blog/lartc-qdisc-zh/
[4]Evolving from AFAP: Teaching NICs about time (Netdev, 2018): https://www.youtube.com/watch?v=MAni0_lN7zE
[5]流量控制(TC)五十年:從基于緩沖隊(duì)列(Queue)到基于時(shí)間戳(EDT)的演進(jìn)(Google, 2018): http://arthurchiao.art/blog/traffic-control-from-queue-to-edt-zh/
[6]為 K8s workload 引入的一些 BPF datapath 擴(kuò)展(LPC, 2021): http://arthurchiao.art/blog/bpf-datapath-extensions-for-k8s-zh/
[7]默認(rèn)支持多隊(duì)列(multi-queue),會(huì)默認(rèn)創(chuàng)建 16 個(gè) queue: https://www.kernel.org/doc/Documentation/networking/bonding.txt
[8]Cilium 代碼: https://github.com/cilium/cilium/blob/v1.10/bpf/lib/edt.h
[9]超過 FQ 的 drop horizon: https://github.com/torvalds/linux/blob/v5.10/net/sched/sch_fq.c#L463
[10]默認(rèn)是 10s: https://github.com/torvalds/linux/blob/v5.10/net/sched/sch_fq.c#L950
[11]net_sched: sch_fq: add horizon attribute: https://github.com/torvalds/linux/commit/39d010504e6b
[12]內(nèi)核代碼: https://github.com/torvalds/linux/blob/v5.10/net/sched/sch_fq.c#L436
[13]郵件列表: https://lore.kernel.org/netdev/[email protected]/
[14]我們: http://arthurchiao.art/blog/trip-large-scale-cloud-native-networking-and-security-with-cilium-ebpf/
[15]hardcode: https://github.com/cilium/cilium/blob/v1.12/pkg/bandwidth/bandwidth.go#L114


你可能還喜歡
點(diǎn)擊下方圖片即可閱讀
2022-10-30

2022-10-27

2022-10-24


云原生是一種信仰 ??
關(guān)注公眾號(hào)
后臺(tái)回復(fù)?k8s?獲取史上最方便快捷的 Kubernetes 高可用部署工具,只需一條命令,連 ssh 都不需要!


點(diǎn)擊 "閱讀原文" 獲取更好的閱讀體驗(yàn)!
發(fā)現(xiàn)朋友圈變“安靜”了嗎?
