
Python與Tableau相結(jié)合,萬(wàn)字長(zhǎng)文搞定傳統(tǒng)線(xiàn)下連鎖店數(shù)據(jù)分析
回復(fù)“書(shū)籍”即可獲贈(zèng)Python從入門(mén)到進(jìn)階共10本電子書(shū)
1 分析背景:
這是kaggle上的一份巴西傳統(tǒng)線(xiàn)下汽車(chē)服務(wù)類(lèi)連鎖店的實(shí)際銷(xiāo)售數(shù)據(jù),大小約3.43G,包含了從2017年3月31日到2020年4月1日大約2600萬(wàn)多的銷(xiāo)售數(shù)據(jù)。
分析該數(shù)據(jù)集可以探究該連鎖店的銷(xiāo)售情況,產(chǎn)品的分布,可以對(duì)客戶(hù)進(jìn)行細(xì)分,精細(xì)化銷(xiāo)售,對(duì)員工的生產(chǎn)力進(jìn)行分析。
這里是利用Python結(jié)合Tableau來(lái)進(jìn)行分析,可視化用的Tableau,部分分析用的Python。
數(shù)據(jù)解讀:
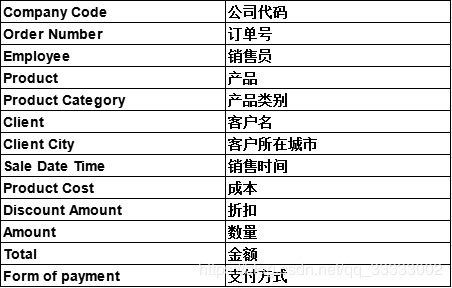
2 分析框架
3 數(shù)據(jù)清洗
3.1 讀取數(shù)據(jù),看看總體情況
這里的數(shù)據(jù)集比較大,Anaconda加載的數(shù)據(jù)都暫時(shí)存在內(nèi)存里,筆者剛開(kāi)始用的8G內(nèi)存,一下子就滿(mǎn)了,這里建議8-12G的內(nèi)存左右,或者關(guān)閉一些暫時(shí)不用先的軟件。
#?導(dǎo)入相關(guān)包
import?numpy?as?np
import?pandas?as?pd?
#?讀取數(shù)據(jù),設(shè)置分割符號(hào)
file_path?=?r'F:\ales?Report.csv\Sales?Report.csv'
df?=?pd.read_csv(file_path,?iterator=True,?sep=';')
data?=?df.get_chunk(30000000)
data.info()
輸出:
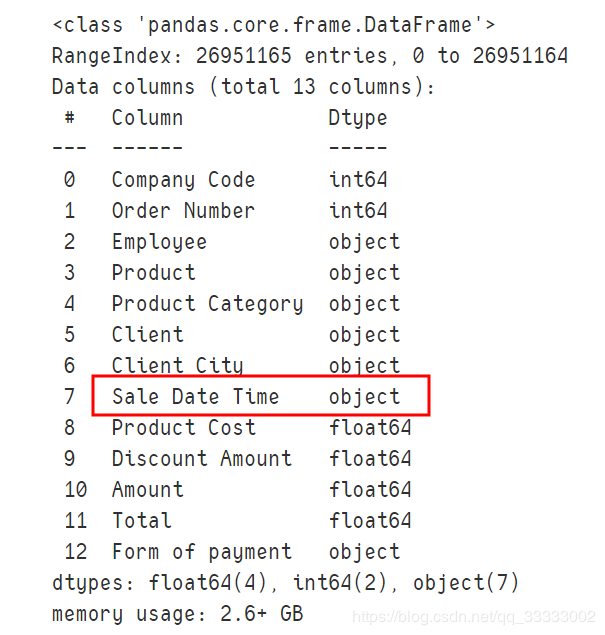
這里的銷(xiāo)售時(shí)間是object類(lèi)型,要轉(zhuǎn)換成datetime類(lèi)型,先記錄下。
#?查看NULL的數(shù)據(jù):
data.isnull().sum()
輸出:
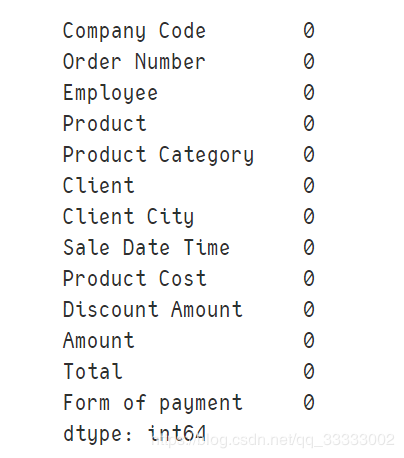
這里的數(shù)據(jù)比較干凈,都沒(méi)有NULL值這些。
查看數(shù)據(jù)的標(biāo)準(zhǔn)差,最大,最下值這些:
data.describe()
輸出:
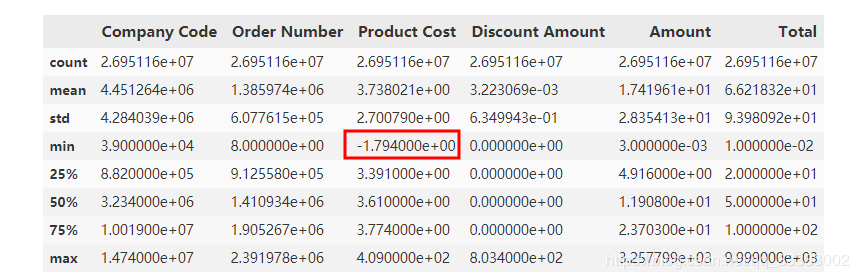
這里的數(shù)據(jù)量比較多,數(shù)據(jù)相對(duì)比較大,這里很明顯可以看出的Product Cost這里有個(gè)負(fù)數(shù),查看這些數(shù)據(jù):
data[data['Product?Cost']?<=?0]
輸出:
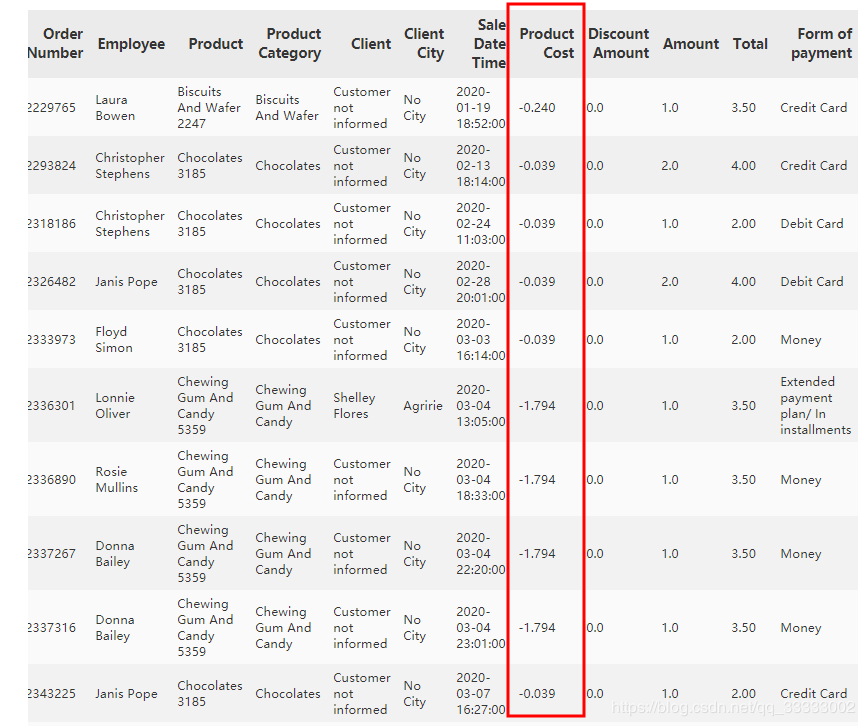
len(data[data['Product?Cost']?0])
輸出:
這里按照字面的意思理解是每銷(xiāo)售出一個(gè)該產(chǎn)品的成本,這里為負(fù)數(shù),暫且這里當(dāng)異常數(shù)據(jù)去處理,這里的數(shù)據(jù)量也不多,只有20條,直接刪除處理。實(shí)際,得和業(yè)務(wù)進(jìn)行溝通,查看該指標(biāo)的具體意思,和該負(fù)數(shù)情況的發(fā)生是出于什么情況來(lái)進(jìn)行分析。
刪除這些數(shù)據(jù):
data.drop(index=data[data['Product?Cost']?0].index,?inplace=True)
3.2 刪除重復(fù)的數(shù)據(jù)
#?數(shù)據(jù)清洗,這里有489567條數(shù)據(jù)是重復(fù)的,刪除這些數(shù)據(jù)
data[data.duplicated()]
輸出:
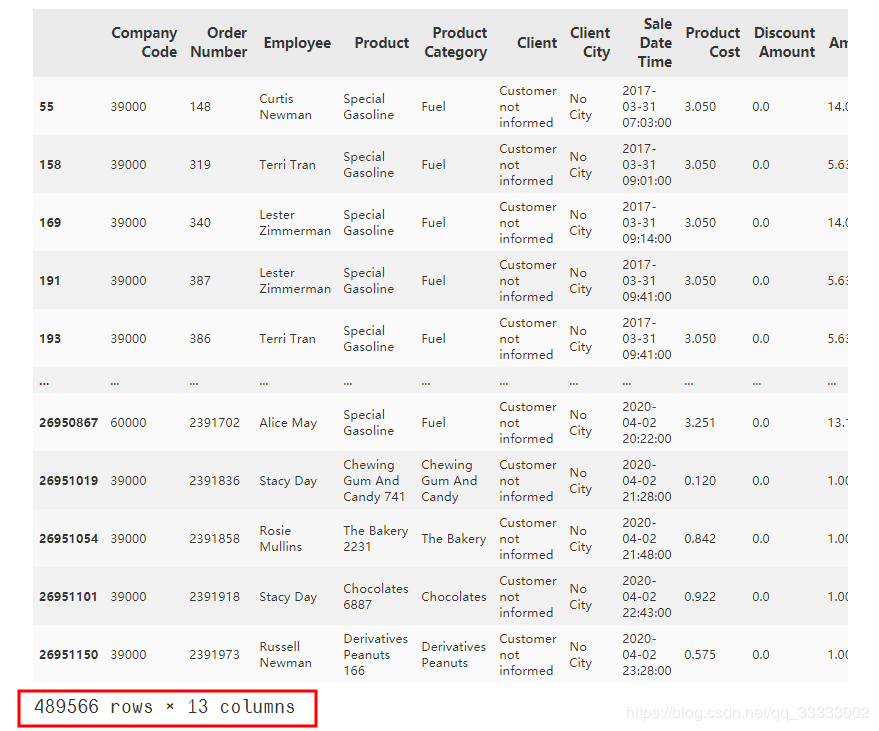
#?刪除重復(fù)的數(shù)據(jù)
#?這里的重復(fù)的數(shù)據(jù)是完全重復(fù)的,所有的值都是相同的,
#?這里只能判斷為異常數(shù)據(jù),直接刪除掉
data.drop(index=data[data.duplicated()].index,?inplace=True)
3.3 日期轉(zhuǎn)換格式
data['Sale?Date?Time']?=?pd.to_datetime(data['Sale?Date?Time'])
data.info()
輸出:
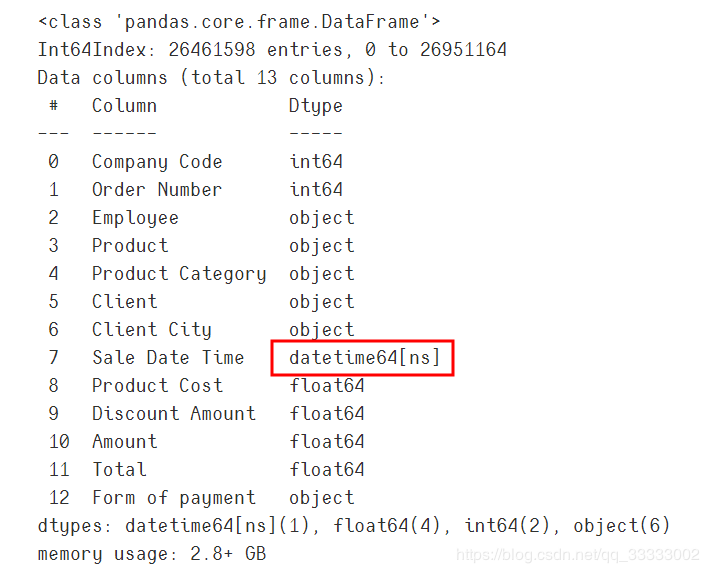
至此,數(shù)據(jù)清洗完畢,可以進(jìn)行分析。
4 分析
4.1 總體情況
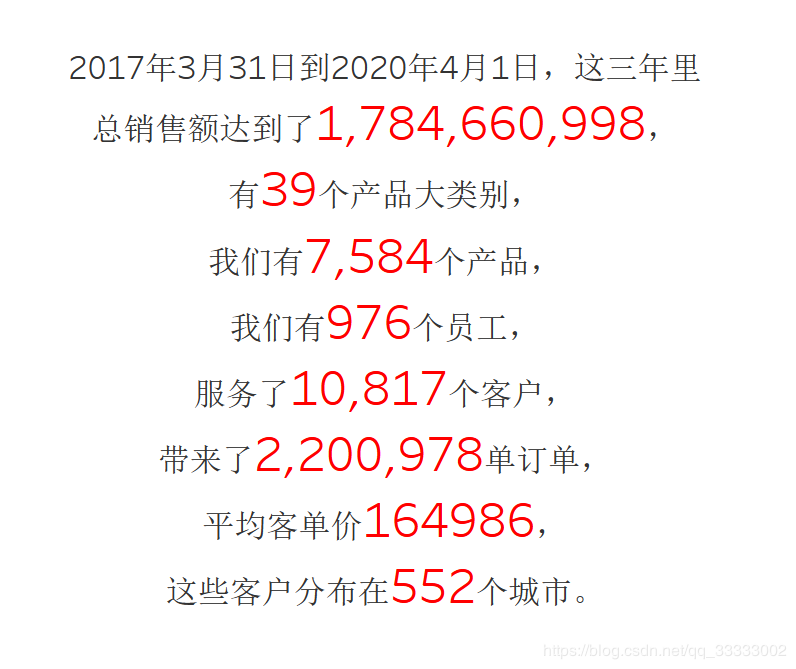
4.2 時(shí)間角度
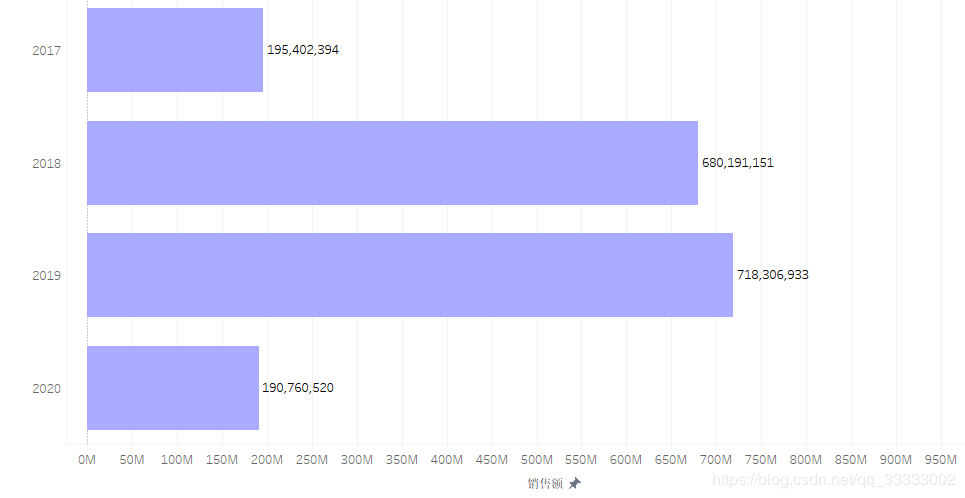
4.2.1 ?年銷(xiāo)售額情況
2017年只有前9個(gè)月的銷(xiāo)售額,2020年只有前4個(gè)月的銷(xiāo)售額。
2019年總銷(xiāo)售額達(dá)到718306933,環(huán)比2018年的680191151,增長(zhǎng)5.6%。
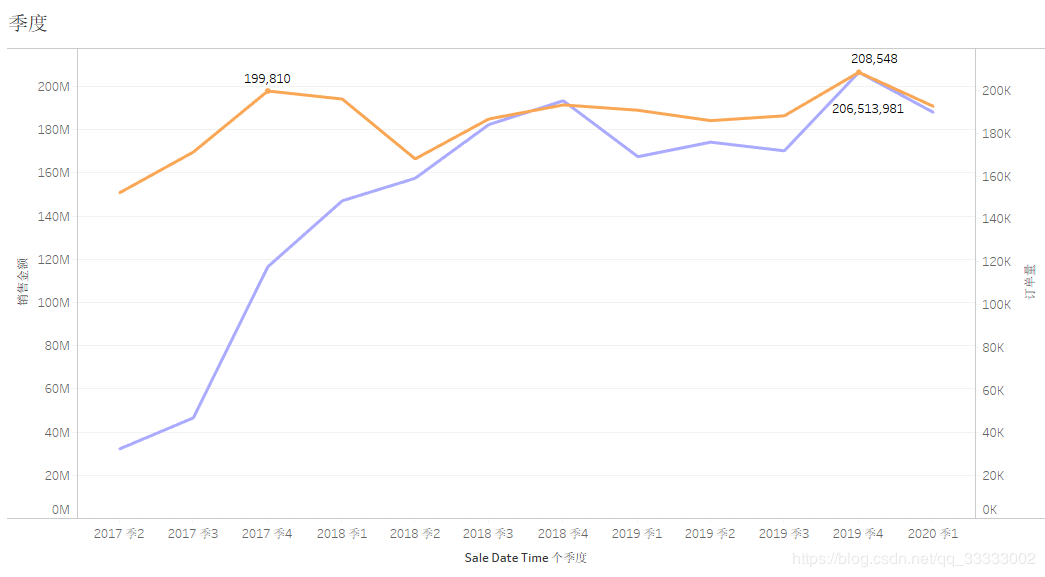
4.2.2 ?季度的銷(xiāo)售額情況
2017第二季度開(kāi)始到2018年底訂單量成直線(xiàn)式上漲,2019年較平穩(wěn)。
2017年該連鎖店出于瘋狂生長(zhǎng)期,訂單量、銷(xiāo)售額均呈現(xiàn)直線(xiàn)上升趨勢(shì)。
2019年第四季度訂單量:208548,銷(xiāo)售額達(dá)到206513981,訂單量、銷(xiāo)售金額均達(dá)到歷史峰值。
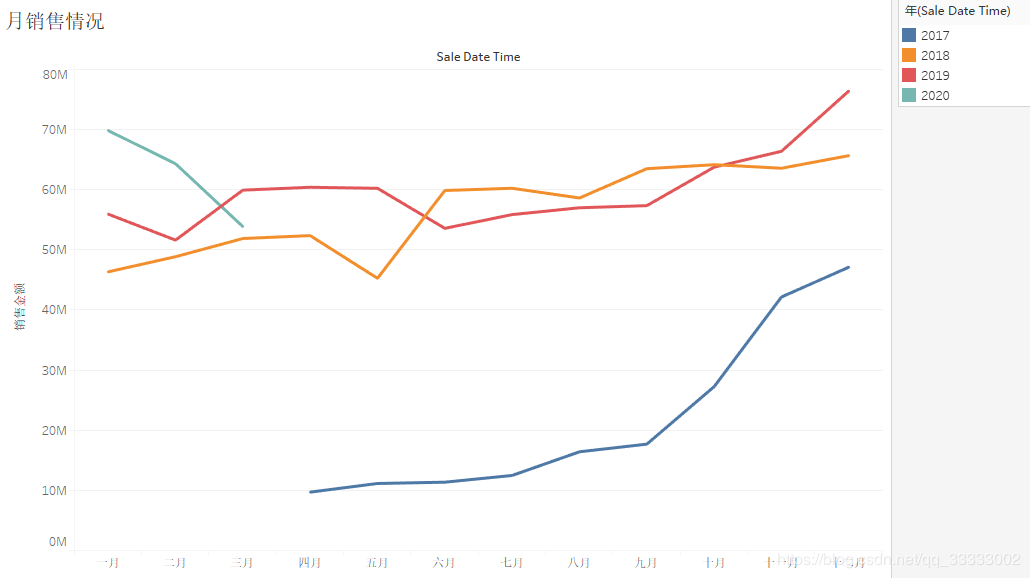
4.2.3 月的銷(xiāo)售情況
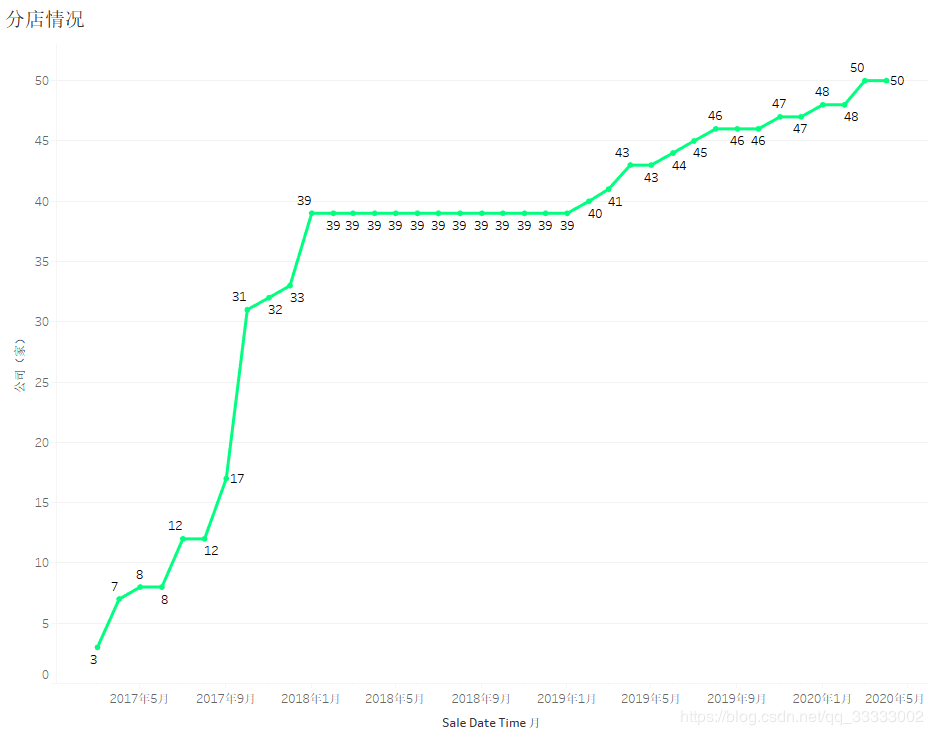
2017年各月份的銷(xiāo)售金額,呈上漲趨勢(shì),其中17年下半年上漲趨勢(shì)較明顯,18、19年呈現(xiàn)較穩(wěn)定的狀態(tài);結(jié)合各月份,連鎖店的數(shù)量。
可以得出結(jié)論:2017年下半年連鎖店數(shù)量的增加帶動(dòng)銷(xiāo)售金額明顯的上漲。
結(jié)合2018、2019年對(duì)比,該連鎖店的銷(xiāo)售額不受季節(jié)的影響,12月為了沖業(yè)績(jī),銷(xiāo)售額會(huì)上漲一些。
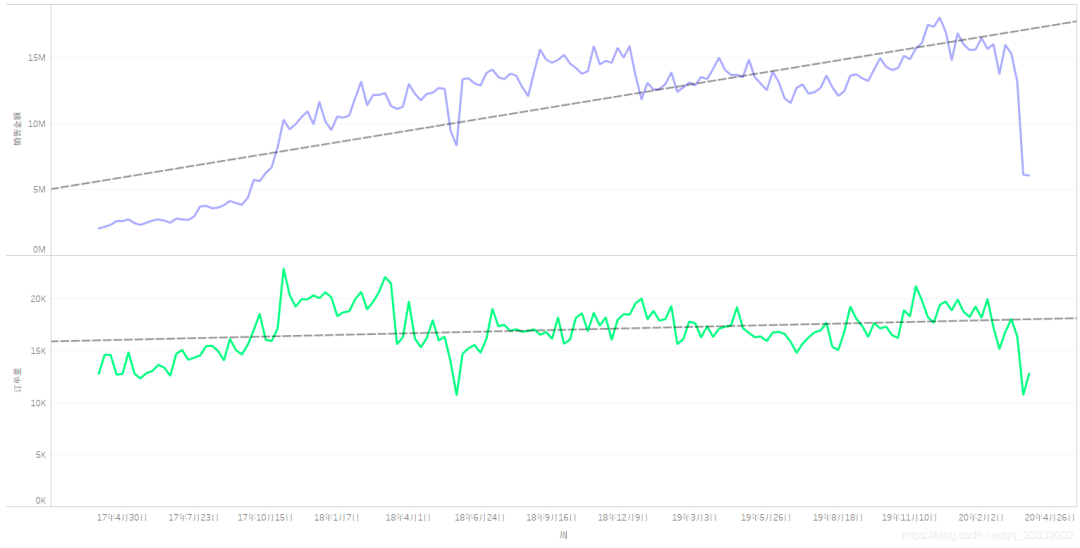
4.2.4 周的銷(xiāo)售情況
周的銷(xiāo)售金額總體上先呈現(xiàn)上升,然后趨向于較穩(wěn)定的狀態(tài)。
周的訂單量處于動(dòng)態(tài)的平衡當(dāng)中,可以看出隨著時(shí)間的增長(zhǎng),每張訂單的購(gòu)買(mǎi)金額逐漸增加。
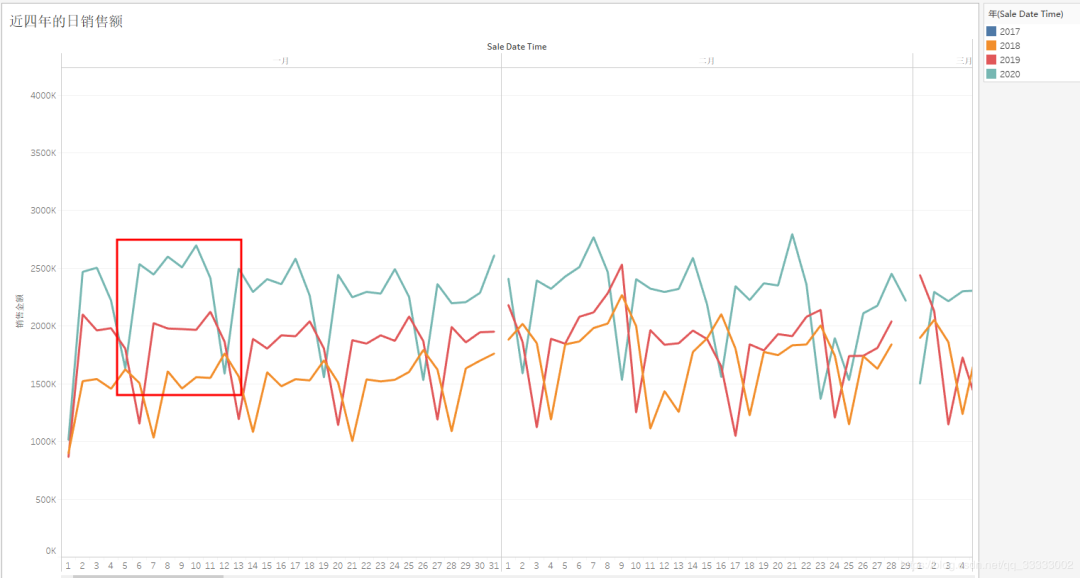
4.2.5 日的銷(xiāo)售情況
總體來(lái)說(shuō),這里只有2018年6月1日左右時(shí)間段的銷(xiāo)售金額有異常,這段時(shí)間既有極大值,也有極小值。具體原因可以深入查明一下。
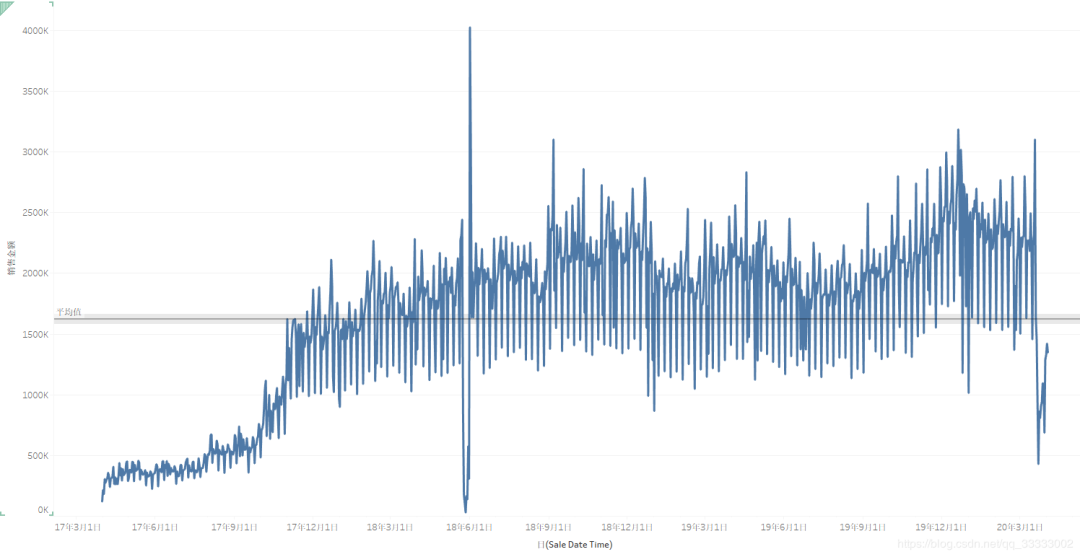
這里的日銷(xiāo)售額呈現(xiàn)周期性規(guī)律,也就是有6天銷(xiāo)售額處于較高的,有一天的銷(xiāo)售額是處于最低的,結(jié)合工作日權(quán)重,可以看出,巴西人民再周日的購(gòu)買(mǎi)欲望較低,或者該商圈處于寫(xiě)字樓附近。
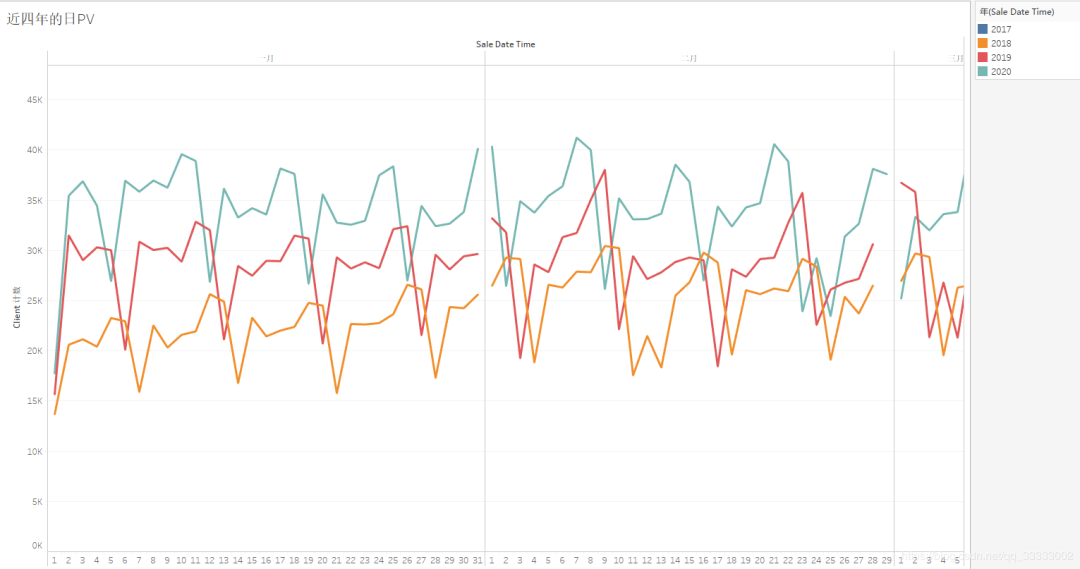
4.2.6 近四年的日UV
縱向?qū)Ρ让磕甑娜誙V,都有上升的趨勢(shì)。
橫向?qū)Ρ犬?dāng)年的日UV,呈現(xiàn)周期性的規(guī)律,這里按7天為一周期,前后一天都是最低的,中間五天相對(duì)來(lái)說(shuō)較高。
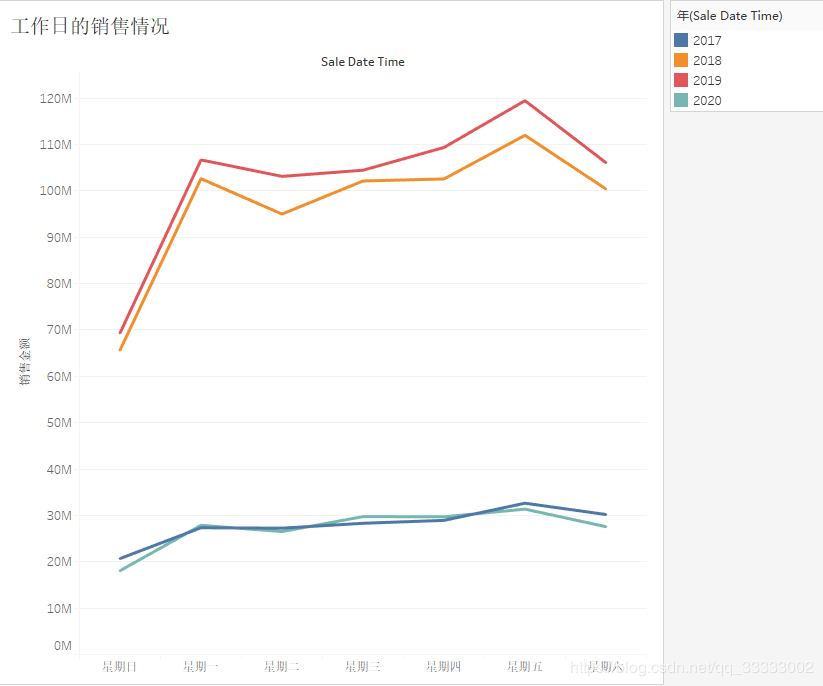
4.2.7 工作日的銷(xiāo)售情況
周日的銷(xiāo)售金額最少。
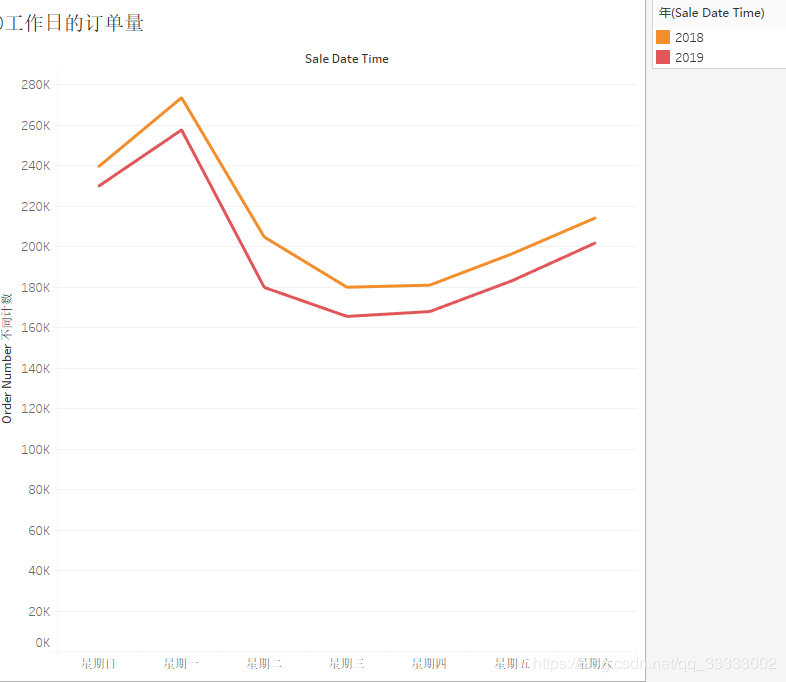
4.2.7 工作日的訂單量
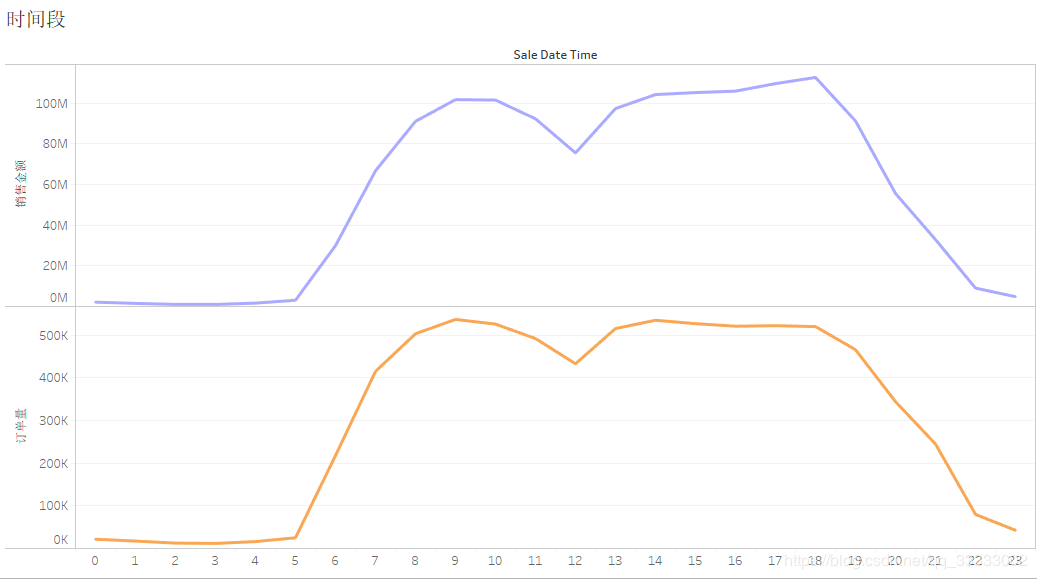
4.2.8 時(shí)間段的銷(xiāo)售金額、訂單量
該商城銷(xiāo)售額、訂單量在7-20點(diǎn)這個(gè)時(shí)間段較高,12點(diǎn)有個(gè)谷底。
4.2.9 工作日的銷(xiāo)售權(quán)重
這里只挑選了2019年全年的數(shù)據(jù)來(lái)進(jìn)行統(tǒng)計(jì)。
在Tableau里實(shí)現(xiàn):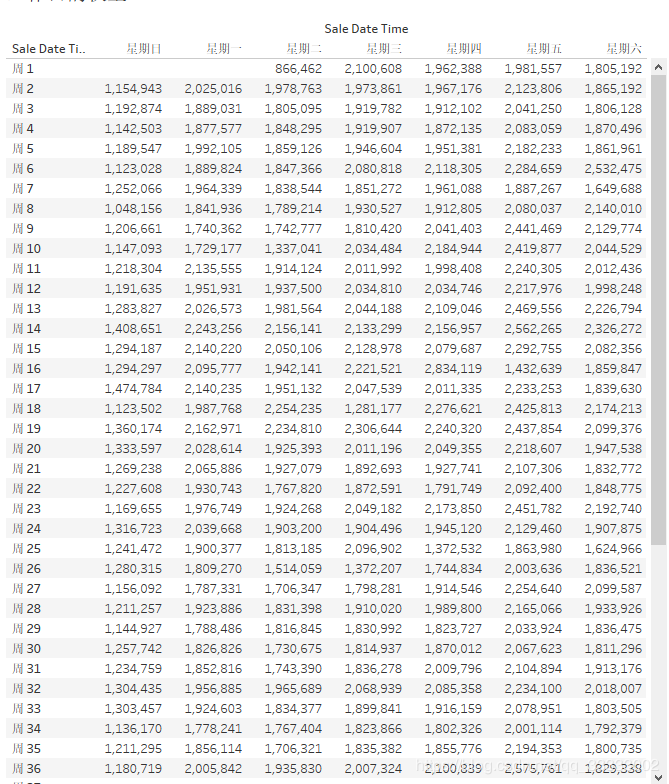
導(dǎo)出數(shù)據(jù)到Excel里計(jì)算。
計(jì)算公式方式:
全年周日的平均值=全年的周日的總銷(xiāo)售額/全年周日的天數(shù),其他工作日類(lèi)推。 挑選1中計(jì)算到的最小值 權(quán)重=某個(gè)工作日的平均值 / 2中選出的最小值
這里的權(quán)重越大,表明當(dāng)日的銷(xiāo)售額越多。

可視化:
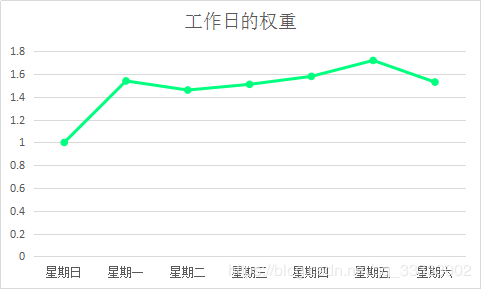
這里可得出的結(jié)論:周五的銷(xiāo)售權(quán)重最大,周日的銷(xiāo)售權(quán)重最小。
4.2.10 銷(xiāo)售預(yù)測(cè)按日
這里只挑選2019年1月1日到2020年2月29的數(shù)據(jù),其中2020年2月份的數(shù)據(jù)用來(lái)做預(yù)測(cè)和對(duì)比。
#?將銷(xiāo)售時(shí)間設(shè)置成索引
data.set_index('Sale?Date?Time',?inplace=True,?drop=True)
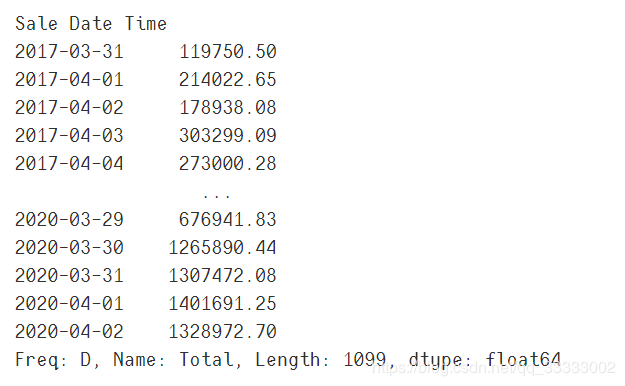
#?將數(shù)據(jù)重新整理成以天來(lái)統(tǒng)計(jì)每天銷(xiāo)售額的匯總
day_data?=?data.resample('d').sum()['Total']
day_data
輸出:
#?挑選2019年1月1日到2020年2月29的數(shù)據(jù)
train_day_data?=?day_data[day_data.index?>=?'2019-01-01']
train_day_data?=?train_day_data[train_day_data.index?<=?'2020-02-29']
#?保存數(shù)據(jù)到Excel
train_day_data.to_excel('./日銷(xiāo)售數(shù)據(jù).xlsx')
#?讀取數(shù)據(jù)
data?=?pd.read_excel('./日銷(xiāo)售數(shù)據(jù).xlsx')
#?重新命名列
data.rename(columns={'Sale?Date?Time':?'date1'},?inplace=True)
data
輸出:
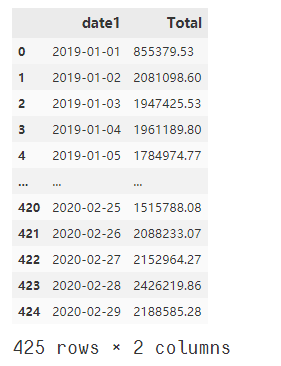
#?將銷(xiāo)售額進(jìn)行縮放,預(yù)測(cè)的只是大概的值,不可能太精確,這里直接根據(jù)數(shù)據(jù)的情況,以10萬(wàn)作為基本的單位。
data['Total']?=?round(data['Total']?/?100000,?4)
進(jìn)行平穩(wěn)性檢驗(yàn)
import?matplotlib.pyplot?as?plt
plt.rcParams['font.sans-serif']?=?'SimHei'
plt.rcParams['axes.unicode_minus']?=?False
%matplotlib?inline
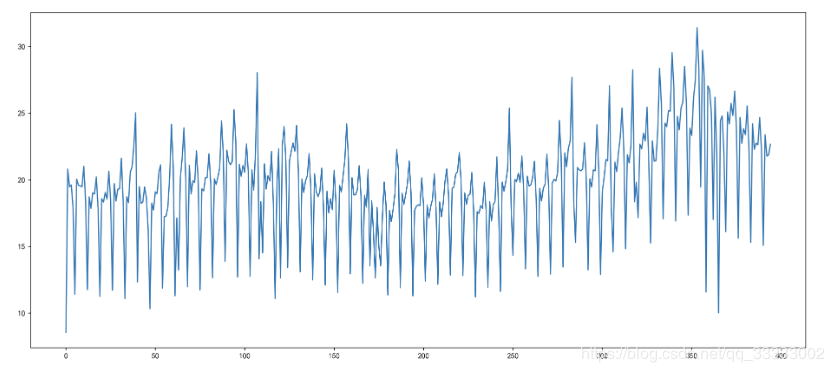
#?時(shí)序圖
plt.figure(figsize=(18,?8),?dpi=256)
data['Total'][:-30].plot()
輸出:
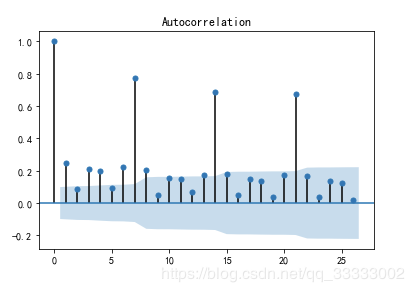
#?自相關(guān)圖
from?statsmodels.graphics.tsaplots?import?plot_acf
plot_acf(data['Total'][:-30])
plt.figure(figsize=(18,?8),?dpi=256)
輸出:
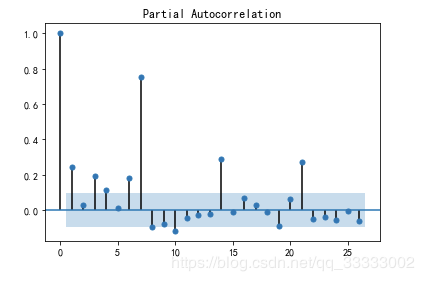
#?偏自相關(guān)圖
from?statsmodels.graphics.tsaplots?import?plot_pacf
plot_pacf(data['Total'][:-30])
plt.figure(figsize=(18,?8),?dpi=256)
輸出:
#?單位跟檢驗(yàn)
from?statsmodels.tsa.stattools?import?adfuller?as?ADF?
print(ADF(data['Total'][:-30]))
輸出:
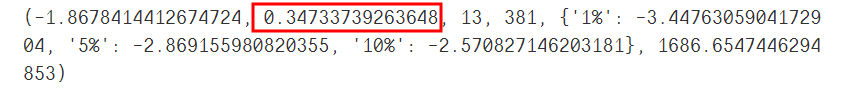
這里的p值等于0.347多,大于0.05,屬于不平穩(wěn)序列,需要進(jìn)行差分后,再檢驗(yàn)是否屬于平穩(wěn)序列。
#?一階差分
D_data?=?data['Total'][:-30].diff().dropna()
print('一階段差分檢驗(yàn)結(jié)果:',?ADF(D_data))
輸出:

一階差分后的序列,屬于平穩(wěn)序列,這里可以使用差分后平穩(wěn)序列的模型ARIMA進(jìn)行預(yù)測(cè),預(yù)測(cè)前還得進(jìn)行白噪聲檢驗(yàn)。
from?statsmodels.stats.diagnostic?import?acorr_ljungbox
print('白噪聲檢驗(yàn)結(jié)果:',?acorr_ljungbox(D_data,?lags=1))
輸出:
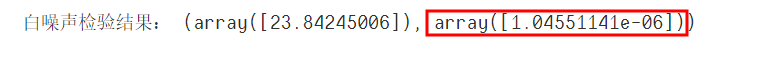
白噪聲檢驗(yàn)的p值遠(yuǎn)小于0.05,一階差分后的時(shí)間序列屬于平穩(wěn)非白噪聲的時(shí)間序列,下面可以利用ARIMA模型進(jìn)行預(yù)測(cè)。
from?statsmodels.tsa.arima_model?import?ARIMA
from?datetime?import?datetime
from?itertools?import?product
#?設(shè)置p階,q階范圍
#?product?p,q的所有組合
#?設(shè)置最好的aic為無(wú)窮大
#?對(duì)范圍內(nèi)的p,q階進(jìn)行模型訓(xùn)練,得到最優(yōu)模型
ps?=?range(0,?5)
qs?=?range(0,?5)
parameters?=?product(ps,?qs)
parameters_list?=?list(parameters)
best_aic?=?float('inf')
results?=?[]
for?param?in?parameters_list:
????try:
????????model?=?ARIMA(data['Total'][:-30],?order=(param[0],?1,?param[1])).fit()
????except?ValueError:
????????print("參數(shù)錯(cuò)誤:",?param)
????????continue
????aic?=?model.aic
????if?aic?????????best_model?=?model
????????best_aic?=?model.aic
????????best_param?=?param
????results.append([param,?model.aic])
results_table?=?pd.DataFrame(results)
results_table.columns?=?['parameters',?'aic']
print("最優(yōu)模型",?best_model.summary())
輸出:
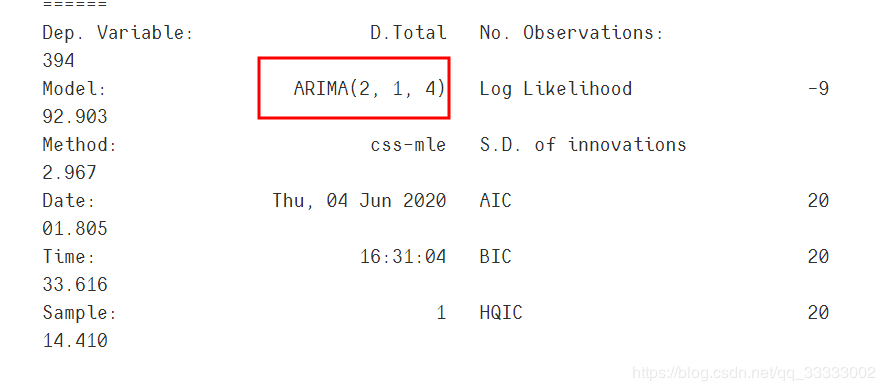
利用最好的模型進(jìn)行預(yù)測(cè)。
best_model.forecast(30)[0]

模型評(píng)價(jià):
from?sklearn.metrics?import?mean_absolute_error
#?pred_y?預(yù)測(cè)值
#?test_y?實(shí)際值
pred_y?=?best_model.forecast(30)[0]
test_y?=?data['Total'][-30:].values
mean_absolute_error(test_y,?pred_y)
輸出:
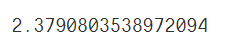
這里的平均絕對(duì)誤差為2.38,這里要根據(jù)實(shí)際的業(yè)務(wù)確定誤差閾值。再來(lái)進(jìn)行模型的評(píng)價(jià)。小于閾值的,模型就是稍微好的,大于閾值的,說(shuō)明模型的準(zhǔn)確率還有待提高,模型還需重新訓(xùn)練等。
畫(huà)折線(xiàn)圖,對(duì)比下實(shí)際和預(yù)測(cè)值之間的差距。
plt.figure(figsize=(14,?7),?dpi=256)
plt.plot(data['date1'][-30:],?test_y,?label='實(shí)際')
plt.plot(data['date1'][-30:],?pred_y,?label='預(yù)測(cè)')
plt.xticks(data['date1'][-30:],?rotation=70)
plt.legend(loc=3)
輸出:
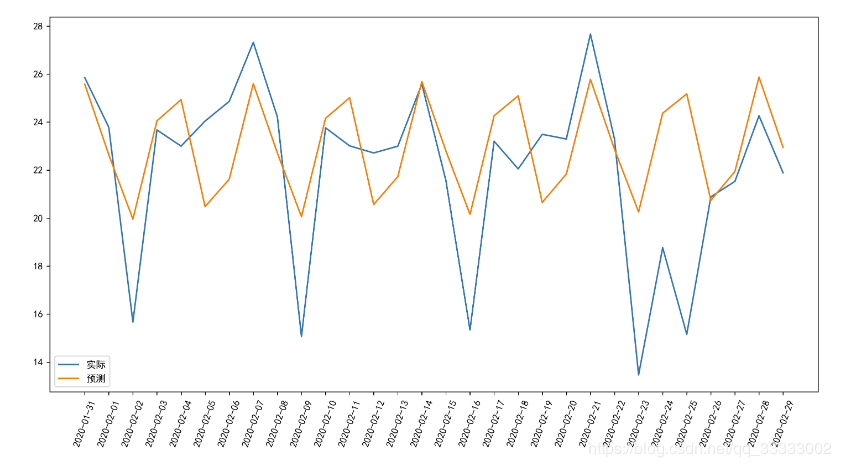
這里可以看出,模型預(yù)測(cè)的結(jié)果還是稍微好點(diǎn)的。
4.3 用戶(hù)角度
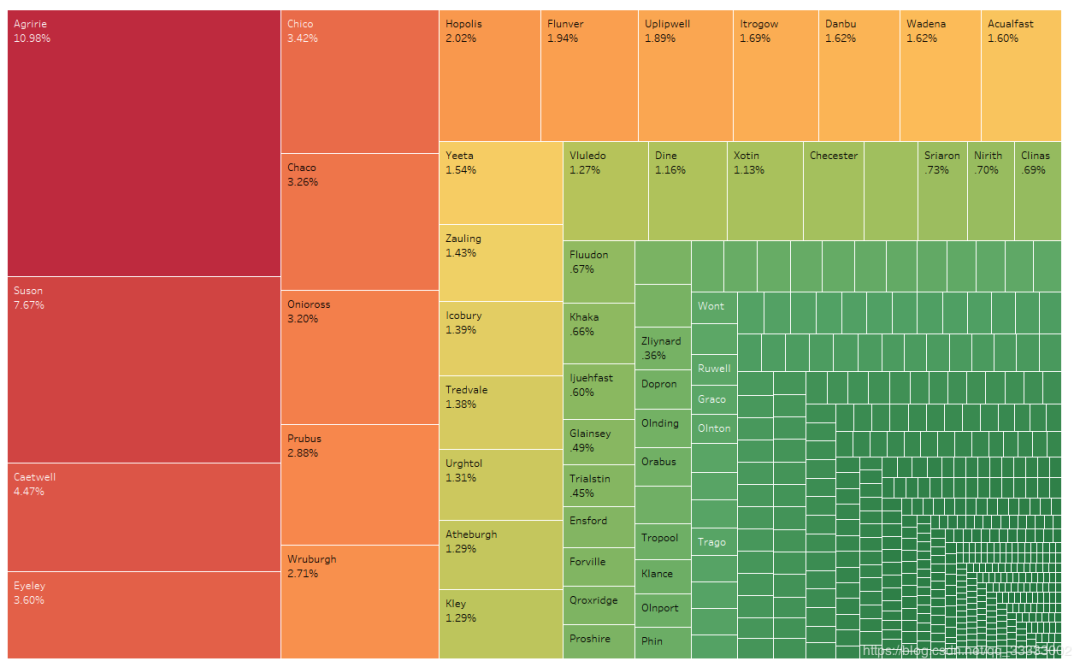
4.3.1 用戶(hù)城市分布
10.98%的用戶(hù)集中在Agirrie這個(gè)城市,用戶(hù)居住城市相對(duì)較分散。
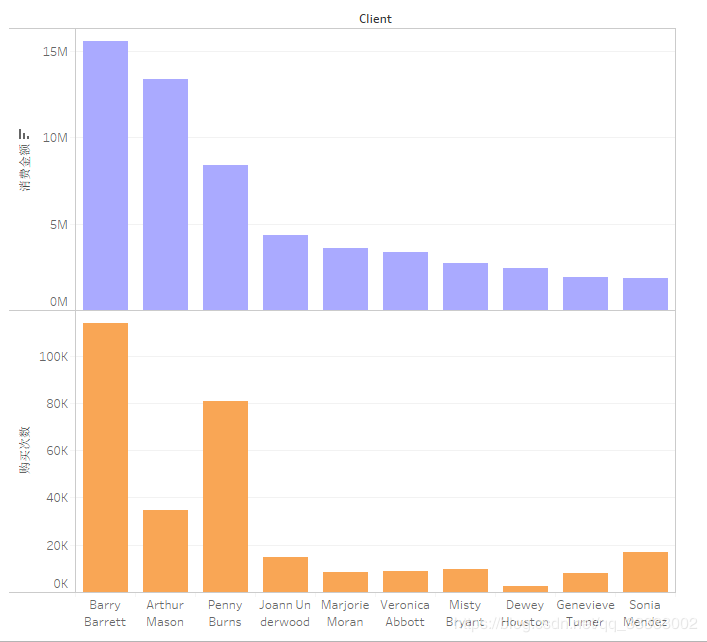
4.3.2 用戶(hù)購(gòu)買(mǎi)金額,購(gòu)買(mǎi)次數(shù)前10的用戶(hù)
用戶(hù)Barry Barrett總購(gòu)買(mǎi)金額達(dá)到15M以上,消費(fèi)次數(shù)也達(dá)到了100K以上,屬于高價(jià)值的客戶(hù)。
4.3.3 復(fù)購(gòu)率
總體復(fù)購(gòu)率:
這里是按這份數(shù)據(jù)所在的時(shí)間段,計(jì)算購(gòu)買(mǎi)次數(shù)大于2次的用戶(hù),再除于總的用戶(hù)數(shù),這里得排除的一個(gè)數(shù)據(jù)是用戶(hù)Client這里,有一個(gè)數(shù)據(jù)是Customer not informed(客戶(hù)沒(méi)有提供名字的情況),這條數(shù)據(jù)得排除了,所以計(jì)算購(gòu)買(mǎi)次數(shù)大于2的用戶(hù)和總用戶(hù)數(shù)對(duì)應(yīng)減去1,這是個(gè)人的想法,實(shí)際是得和業(yè)務(wù)溝通,得到實(shí)際的計(jì)算方法。查看Customer not informed這條數(shù)據(jù):
#?計(jì)算每個(gè)客戶(hù)的購(gòu)買(mǎi)次數(shù),這里使用了nunique(),統(tǒng)計(jì)不同訂單號(hào)的個(gè)數(shù)
client_data?=?data.groupby('Client').nunique()['Order?Number']
#?重命名列
client_data?=?client_data.reset_index().rename(columns={'Order?Number':?
????????????????????????????????????????????????????????'user_num'})
client_data.sort_values('user_num',?ascending=False)????????????????????????????????????????????????????????

#?總復(fù)購(gòu)率
print('總復(fù)購(gòu)率:',
round(
????(len(client_data[client_data['user_num']?>?1])-1)?/
??????(len(client_data)?-?1),?4)?*?100,?"%")
輸出:
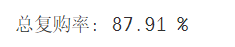
該數(shù)據(jù)所在的時(shí)間段的總體復(fù)購(gòu)率達(dá)到了87.91%,用戶(hù)黏性較高。
這里再細(xì)分下,看下一個(gè)月內(nèi)的復(fù)購(gòu)的情況。
一個(gè)月內(nèi)復(fù)購(gòu)率
這里的一個(gè)月內(nèi)復(fù)購(gòu)率的定義是:從月初的1號(hào)到月底這段時(shí)間內(nèi),用戶(hù)復(fù)購(gòu)的比率。
#?這里的銷(xiāo)售時(shí)間是datetime格式,增加個(gè)輔助列,轉(zhuǎn)換成2017-01這樣的年月顯示
def?parse_year_month(x):
????if?x.month?>=?10:
????????return?str(x.year)?+?"-"?+?str(x.month)
????else:
????????return?str(x.year)?+?"-0"?+?str(x.month)
data['year_month']?=?data['Sale?Date?Time'].apply(parse_year_month)
統(tǒng)計(jì)每個(gè)月用戶(hù)的購(gòu)買(mǎi)次數(shù)
y_m_data?=?data.groupby(['year_month',
?????????????????????????'Client']).nunique()['Order?Number'].reset_index()
y_m_data
輸出:
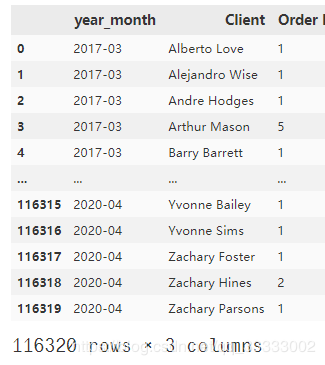
每個(gè)月的復(fù)購(gòu)率
#?保存臨時(shí)數(shù)據(jù),用于構(gòu)建每月的復(fù)購(gòu)率的DataFrame
month_list?=?[]
rate_list?=?[]
#?循環(huán)計(jì)算每個(gè)月的復(fù)購(gòu)率,這里直接遍歷每個(gè)月
for?every_m?in?y_m_data['year_month'].unique():
#?????獲取每個(gè)月用戶(hù)的購(gòu)買(mǎi)次數(shù)的數(shù)據(jù)
????temp?=?y_m_data[y_m_data['year_month']?==?every_m]
#???? print(every_m, "復(fù)購(gòu)率:",
#???????????round((len(temp[temp['Order?Number']?>?1])-1)?/?(len(temp)?-1),4))
????month_list.append(every_m)
#?????選出購(gòu)買(mǎi)次數(shù)>1的數(shù)據(jù),獲取數(shù)據(jù)的長(zhǎng)度(用戶(hù)數(shù))-?1?再除以
#?當(dāng)月的總用戶(hù)數(shù)?-1?
????rate_list.append(round((len(temp[temp['Order?Number']?>?1])-1)?/?(len(temp)?-1),?4))
#將數(shù)據(jù)轉(zhuǎn)換成DataFrame
t_1?=?{'month':?month_list,?'rate':?rate_list}
rate_data?=?pd.DataFrame(t_1)
rate_data
輸出:
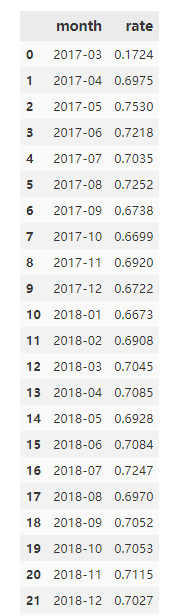
導(dǎo)出數(shù)據(jù),用Excel做可視化:
rate_data.to_excel('./rate_data.xlsx',?index=False)
月復(fù)購(gòu)率都在66%以上,用戶(hù)的黏性較大。
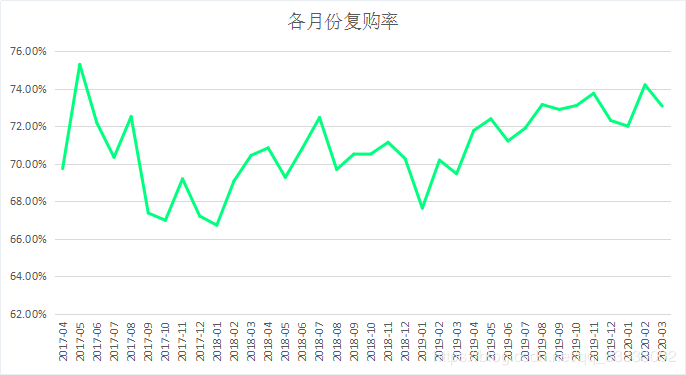
4.3.4 購(gòu)買(mǎi)次數(shù)的情況
這里只挑選了2018年4月這個(gè)月的購(gòu)買(mǎi)次數(shù)來(lái)做分析,其他月份的可以類(lèi)推。
data_201804?=?y_m_data[y_m_data['year_month']?==?'2018-04']
#重命名Order?Number為購(gòu)買(mǎi)次數(shù)buy_frequency
data_201804.rename(columns={'Order?Number':?'buy_frequency'},?inplace=True)
data_201804
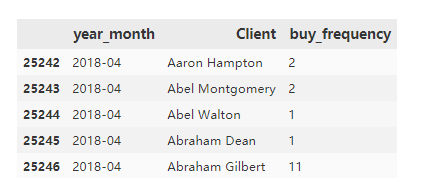
#?設(shè)置數(shù)據(jù)的區(qū)間
bins?=?[0,?1,?2,?5,?10,?50,?100,?100000]
per_frequency?=?pd.cut(data_201804['buy_frequency'],?bins)
per_frequency.value_counts()
per_frequency.value_counts().plot(kind='bar')
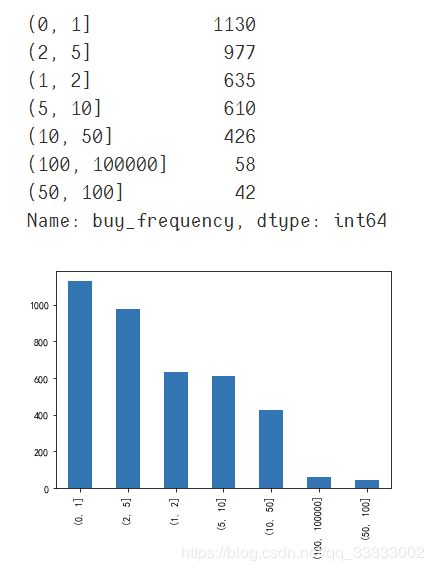
4.3.5 RFM模型分析用戶(hù)的價(jià)值
這里只針對(duì)2018年4月份的用戶(hù)價(jià)值進(jìn)行分類(lèi),其他可以類(lèi)推。
#?按月份提取每個(gè)月用戶(hù)的R、F、M值
RFM_data_all?=?data.groupby(['year_month',
?????????????????????????'Client']).agg({'Order?Number':?'nunique',
????????????????????????????????????????'Sale?Date?Time':?'max',
????????????????????????????????????????'Total':?'sum'})
RFM_data_all.reset_index(inplace=True)
#?保存一份數(shù)據(jù),下次直接讀取該數(shù)據(jù)集就可以,省時(shí)間
RFM_data_all.to_excel('RFM_data_all.xlsx',?index=False)
#?提取2018年4月份的數(shù)據(jù)
RFM_data_201804??=?RFM_data_all[RFM_data_all['year_month']?==?'2018-04']
RFM_data_201804?????????????????????????????????
輸出:
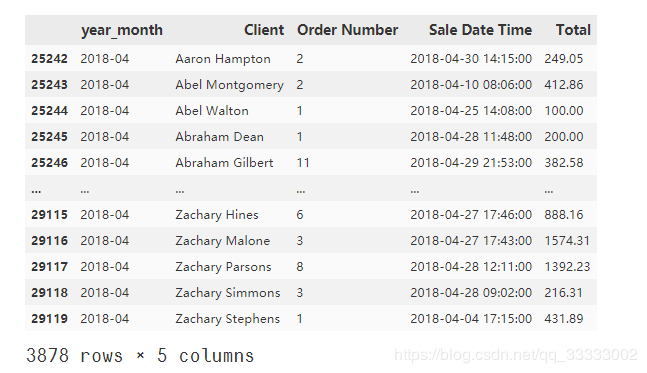
#?參考時(shí)間,這里隨便設(shè)置里2018-05-01?23:59:59,不讓R值為0,這里的R以天作為單位
import?datetime
reference_time?=?datetime.datetime.strptime('2018-05-01?23:59:59',?
????????????????????????????????????????????"%Y-%m-%d?%H:%M:%S")
#?構(gòu)建R指標(biāo)
RFM_data_201804['R']?=?RFM_data_201804['Sale?Date?Time'].apply(lambda?x:?(
????reference_time?-?x).days)
#?重新命名列
RFM_data_201804.rename(columns={'Order?Number':?'F',?'Total':?'M'},?inplace=True)
#?排序查看異常值
RFM_data_201804.sort_values('M',?ascending=False)
輸出:
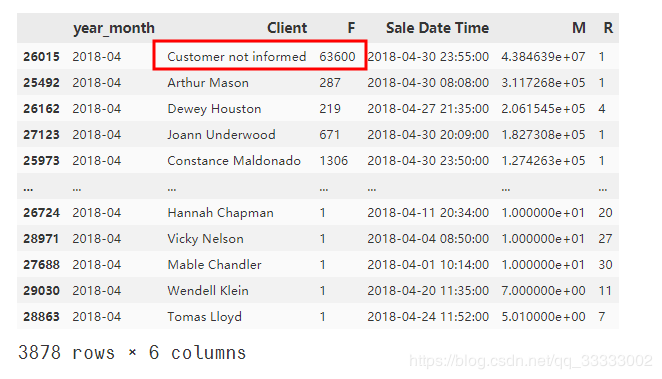
這里有個(gè)異常值,標(biāo)記為客戶(hù)沒(méi)有提及姓名的,直接刪除處理。
RFM_data_201804.drop(index=26015,?inplace=True)
提取RFM指標(biāo)
RFM_data?=?RFM_data_201804[['R',?'F',?'M']]
數(shù)據(jù)規(guī)范化,進(jìn)行聚類(lèi)
from?sklearn.preprocessing?import?StandardScaler
from?sklearn.cluster?import?KMeans
#數(shù)據(jù)規(guī)范化
ss??=?StandardScaler()
train?=?ss.fit_transform(RFM_data)
#?模型進(jìn)行訓(xùn)練,這里直接聚類(lèi)成5類(lèi)。
kmeans_model?=?KMeans(n_clusters=5)
kmeans_model.fit(train)
#查看聚類(lèi)中心
test?=?pd.DataFrame(kmeans_model.cluster_centers_,?columns=['R',?'F',?'M'])
test
輸出:
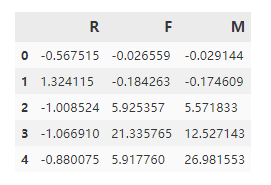
分析:
分群0:R小,F(xiàn)小,M小,這類(lèi)屬于一般價(jià)值客戶(hù)。分群1,R大,F(xiàn)小,M小,這類(lèi)屬于一般發(fā)展客戶(hù)。分群2,R小,R大,M大,這類(lèi)屬于重點(diǎn)保持客戶(hù)。分群3、4 這類(lèi),R小,F(xiàn)、M大,這類(lèi)都屬于高價(jià)值客戶(hù)。
將分群的結(jié)果合并到RFM_data數(shù)據(jù)里看下原數(shù)據(jù)。
RFM_data['sk5_label']?=?kmeans_model.labels_
這里挑出分群3、4的數(shù)據(jù)來(lái)看看。
RFM_data[RFM_data['sk5_label']?==?3]
輸出:
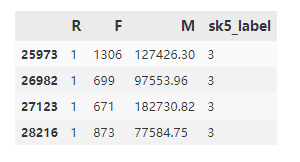
分群3的用戶(hù)的購(gòu)買(mǎi)次數(shù)F在670-1300之間,消費(fèi)金額M在7.7W-18W之間,且R小,屬于高價(jià)值客戶(hù)。
RFM_data[RFM_data['sk5_label']?==?4]
輸出:
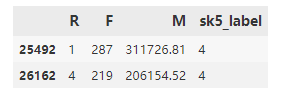
分群4的用戶(hù)購(gòu)買(mǎi)次數(shù)在210-280之間,購(gòu)買(mǎi)金額在20W以上,這類(lèi)是屬于高價(jià)值客戶(hù)。
Tableau實(shí)現(xiàn)的客戶(hù)分群:
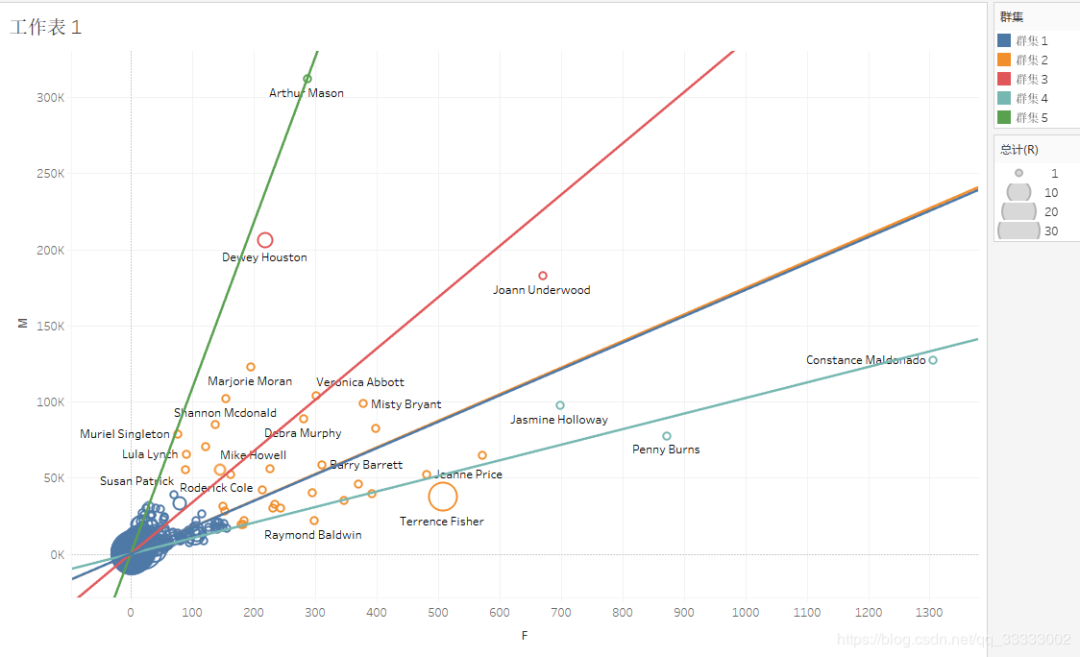
客單價(jià)=M/F。這里可以看出群集5的客單價(jià)最高,其次是群集3,最低的是群集4。
4.3.6 用戶(hù)月留存率
這里統(tǒng)計(jì)用戶(hù)月存留率是上個(gè)月與當(dāng)前月都有購(gòu)買(mǎi)的用戶(hù)的數(shù)量/(除以)上個(gè)月的總用戶(hù)數(shù)(去重)。類(lèi)似流失率,這里不同的是都是上月流向下月的,不是1->2->3這樣的流向,而是1->2, 2->3這樣的流向。
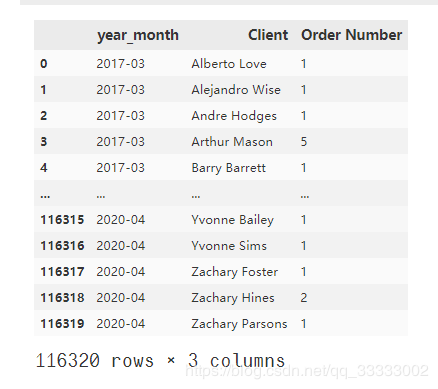
#?提取每個(gè)月的用戶(hù)(去重)
every_month_user?=?data.groupby(['year_month',?
?????????????????????????????????'Client']).nunique()['Order?Number'].reset_index()
every_month_user
輸出:
#?獲取每個(gè)月份的列表,循環(huán)遍歷計(jì)算上個(gè)月與當(dāng)前月的留存率
year_month?=?every_month_user['year_month'].unique()
#?保存月留存率的列表
list_month_rate?=?[]
for?i,?month?in?enumerate(year_month):
#?????計(jì)算上個(gè)月與當(dāng)前月的留存率
????if?i>=?1:
#?????????獲取當(dāng)前月的用戶(hù)(上面groupby已去重)
????????this_month_client?=?every_month_user[every_month_user['year_month']?==?month]['Client']
#????????獲取上個(gè)月的用戶(hù)(上面groupby已去重)
????????previous_month_client?=?every_month_user[every_month_user['year_month']?==?year_month[i-1]]['Client']
#?????????計(jì)算留存率,這里用的是上個(gè)月與當(dāng)前月用戶(hù)的交集個(gè)數(shù)/上個(gè)月的用戶(hù)數(shù)(去重)
????????rate?=?round(len?(set(this_month_client)?&?set(previous_month_client))
??????????????/?len(previous_month_client),2)
#?????????用列表保存數(shù)據(jù),并構(gòu)建DataFrame用戶(hù)繪圖
????????b?=?[month,?rate]
????????list_month_rate.append(b)
#?構(gòu)建DataFrame
rate_data?=?pd.DataFrame(list_month_rate,?columns=['year_month',?'rate'])
rate_data
輸出:
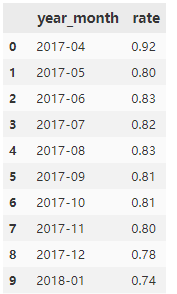
可視化:
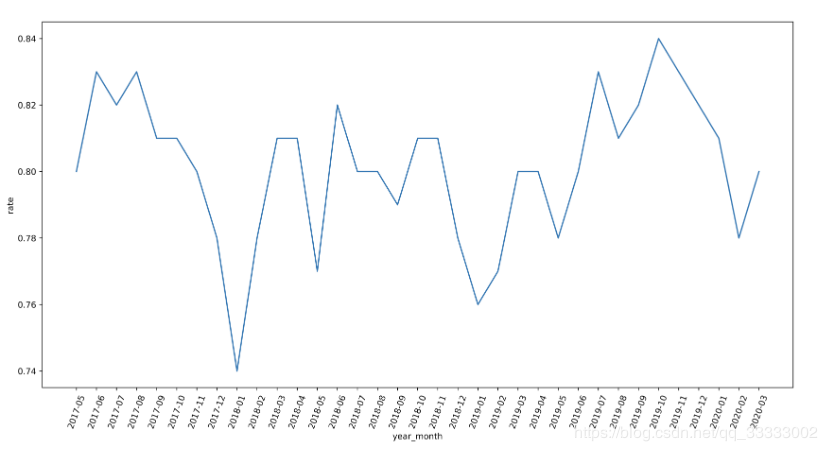
結(jié)論:
月的用戶(hù)留存率達(dá)到74%以上,用戶(hù)黏性高。
4.4 產(chǎn)品角度
4.4.1 銷(xiāo)售額,訂單量前10的銷(xiāo)售產(chǎn)品
產(chǎn)品Special Gasoline、Gasoline汽油類(lèi)的產(chǎn)品的銷(xiāo)售金額、訂單量位居前列;其次是Diesel Auto Clean這個(gè)清潔類(lèi)的產(chǎn)品。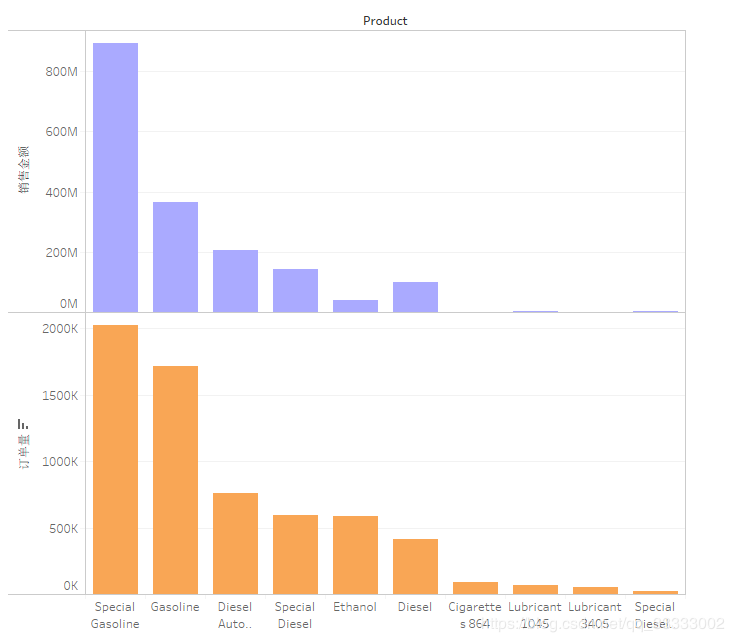
4.4.2 產(chǎn)品分類(lèi)(聚類(lèi)分析)
這里先獲取每個(gè)月的產(chǎn)品的成本C,訂單量F,銷(xiāo)售總金額M,這里只挑選了2018年4月一個(gè)月的產(chǎn)品數(shù)據(jù)來(lái)分析
month_product_data?=?data.groupby(['year_month',?
???????????????????????????????????'Product']).agg({
????'Product?Cost':?'mean',
????'Order?Number':?'nunique',
????'Total':?'sum'
}).reset_index()
#?重命名
month_product_data.rename(columns={'Product?Cost':?'C',?'Order?Number':?'F',?
??????????????????????????????????'Total':?'M'},?inplace=True)
#?導(dǎo)出數(shù)據(jù)到Excel,結(jié)合Tableau一起分析下。
month_product_data.to_excel('./month_product_data.xlsx',?index=False)??????????????????????????????????
#?選擇2018年4月的數(shù)據(jù)
#?這里只取一個(gè)月的產(chǎn)品進(jìn)行聚類(lèi)
month_product_201804?=?month_product_data[month_product_data['year_month']?==?'2018-04']
month_product_201804
輸出:
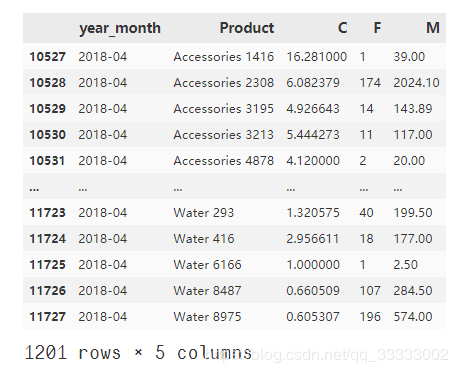
模型訓(xùn)練,進(jìn)行聚類(lèi)
#?導(dǎo)入包
from?sklearn.preprocessing?import?StandardScaler
from?sklearn.cluster?import?DBSCAN
ss?=?StandardScaler()
#?獲取需要的數(shù)據(jù)
X?=?month_product_201804[['C',?'F',?'M']]
#?數(shù)據(jù)規(guī)范化
train_X?=?ss.fit_transform(X)
#?設(shè)置聚類(lèi)數(shù)4個(gè)
dbscan_model?=?DBSCAN(min_samples=4)
#?模型訓(xùn)練
dbscan_model.fit(train_X)
#?將聚類(lèi)的結(jié)果合并到原數(shù)據(jù)集上。
month_product_201804['labels']?=?dbscan_model.labels_
#?查看聚類(lèi)的分布情況
month_product_201804['labels'].value_counts()
輸出:

這里標(biāo)記為-1的數(shù)據(jù)集都是異常的數(shù)據(jù),查看下。
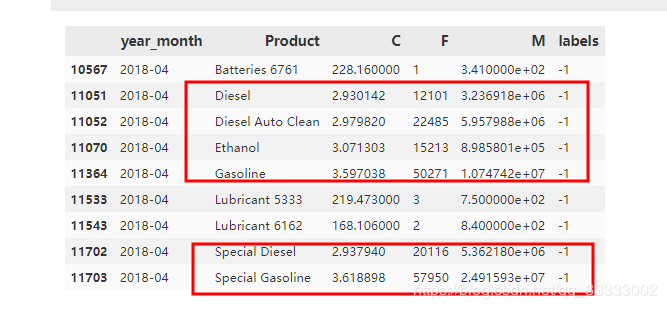
這里結(jié)合Tableau可視化看下。
這里可以看出模型標(biāo)記出來(lái)為-1數(shù)據(jù)的分成兩類(lèi)。
A類(lèi)(上圖和下圖截紅框):成本低,訂單量多,購(gòu)買(mǎi)金額多的,這類(lèi)屬于重點(diǎn)開(kāi)發(fā)的產(chǎn)品。
B類(lèi):成本高,訂單量少,購(gòu)買(mǎi)金額少的,這類(lèi)屬于低價(jià)值的產(chǎn)品,應(yīng)該砍掉。
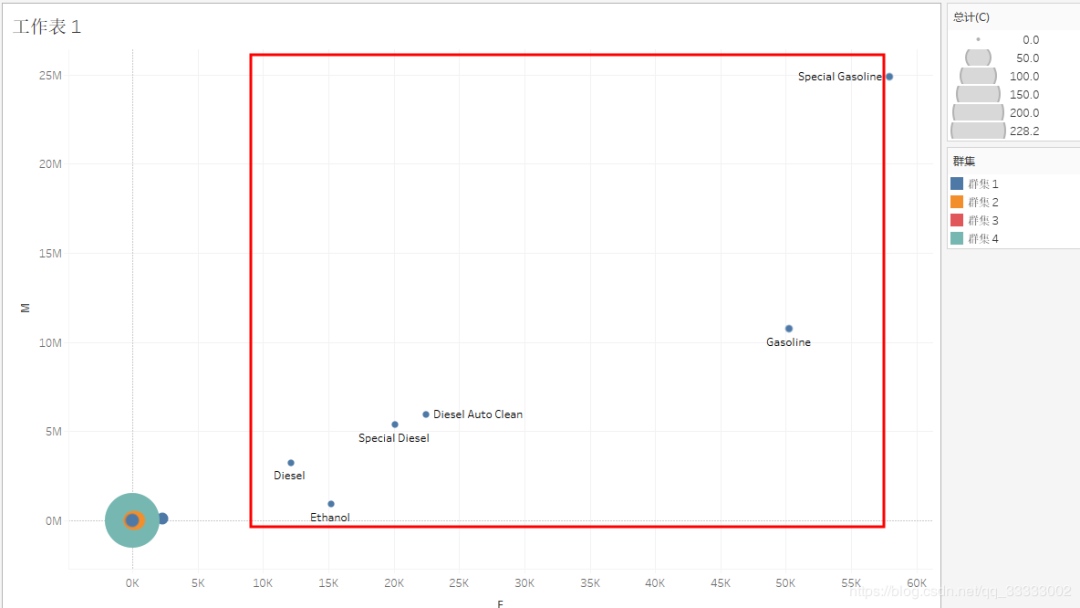
Tableau排除上圖截紅框的一個(gè)教特殊的產(chǎn)品再進(jìn)行產(chǎn)品的聚類(lèi)。
這里的圓圈的大小表示成本C的大小。
針對(duì)群集1:
這里利用二分法為訂單量F分為50以下,50以上。針對(duì)F為50以下的群集1,這類(lèi)購(gòu)買(mǎi)次數(shù)較少,總的銷(xiāo)售金額也在5K以下,這類(lèi)的產(chǎn)品,可以采取部分下架。針對(duì)F為50以上的產(chǎn)品,這類(lèi)產(chǎn)品購(gòu)買(mǎi)次數(shù)稍多,采取維持的狀態(tài)。
針對(duì)群集2:
這里也利用二分法將其分為銷(xiāo)售金額M在3500以上,和3500以下的。3500以下的這類(lèi)的產(chǎn)品成本高,且銷(xiāo)售額也在3500以下,購(gòu)買(mǎi)次數(shù)也低于50,這類(lèi)產(chǎn)品應(yīng)該采取放棄策略。3500以上的則采取先保持策略,再下一階段再繼續(xù)深入觀(guān)察,分析,做進(jìn)一步的決策。
針對(duì)群集3:
這類(lèi)產(chǎn)品的購(gòu)買(mǎi)次數(shù)F在600以上,銷(xiāo)售金額M也在6k以上,成本C也較小,這類(lèi)產(chǎn)品采取繼續(xù)擴(kuò)大。
針對(duì)群集4:
成本C較小,購(gòu)買(mǎi)次數(shù)F在200-600之間,銷(xiāo)售金額在10K以上,這類(lèi)產(chǎn)品屬于重點(diǎn)保持的產(chǎn)品,該類(lèi)產(chǎn)品應(yīng)給與較大的重視,進(jìn)一步發(fā)揮這類(lèi)產(chǎn)品的價(jià)值。
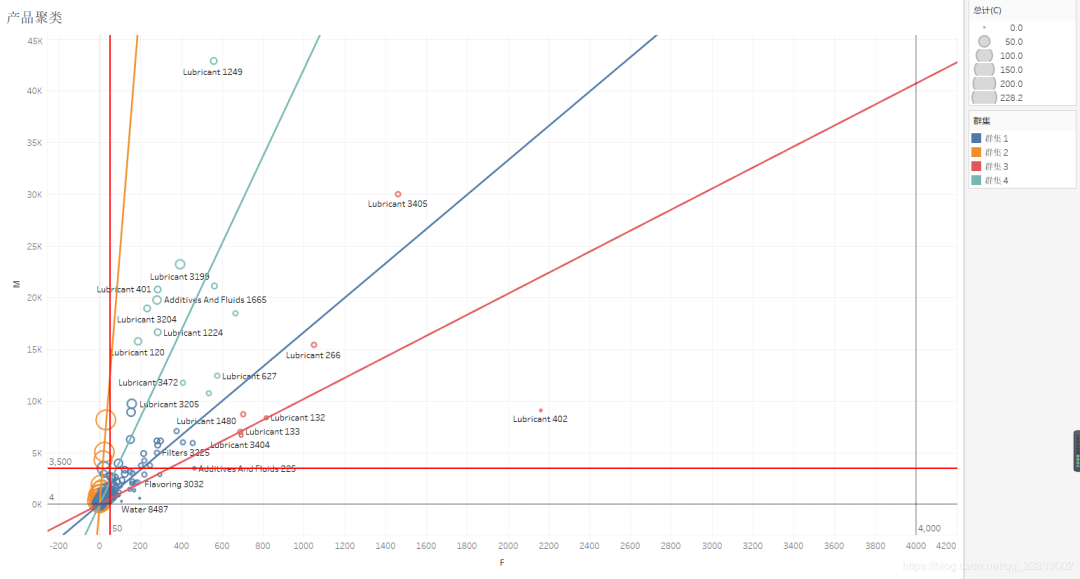
4.4.3 產(chǎn)品銷(xiāo)售額情況及總體的占比(帕累托最優(yōu))
產(chǎn)品的頭部的效應(yīng)明顯,前三產(chǎn)品的總銷(xiāo)售金額達(dá)到總銷(xiāo)售金額的82%以上,符合二八定律。
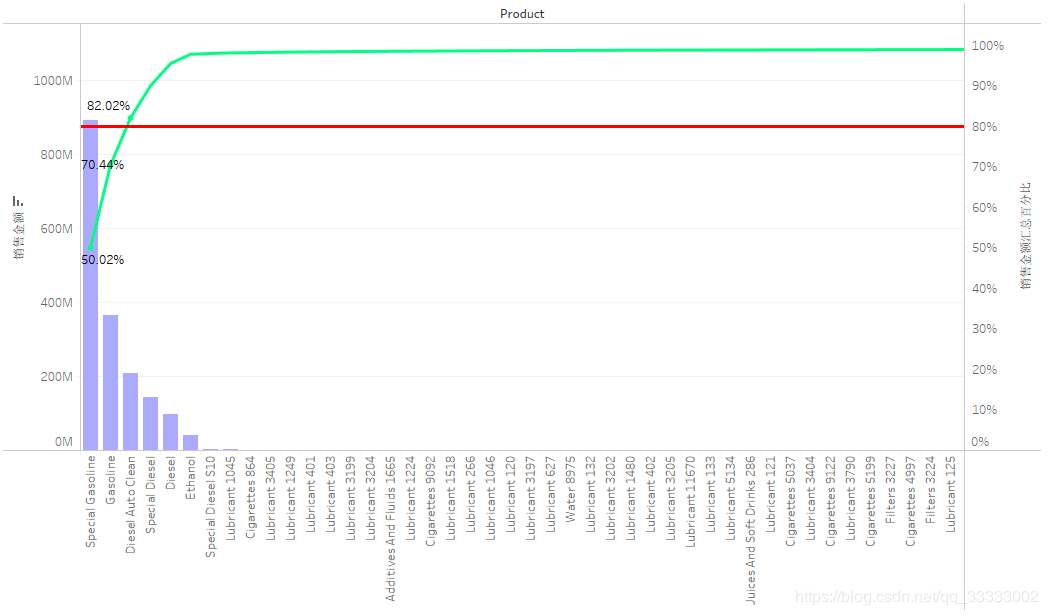
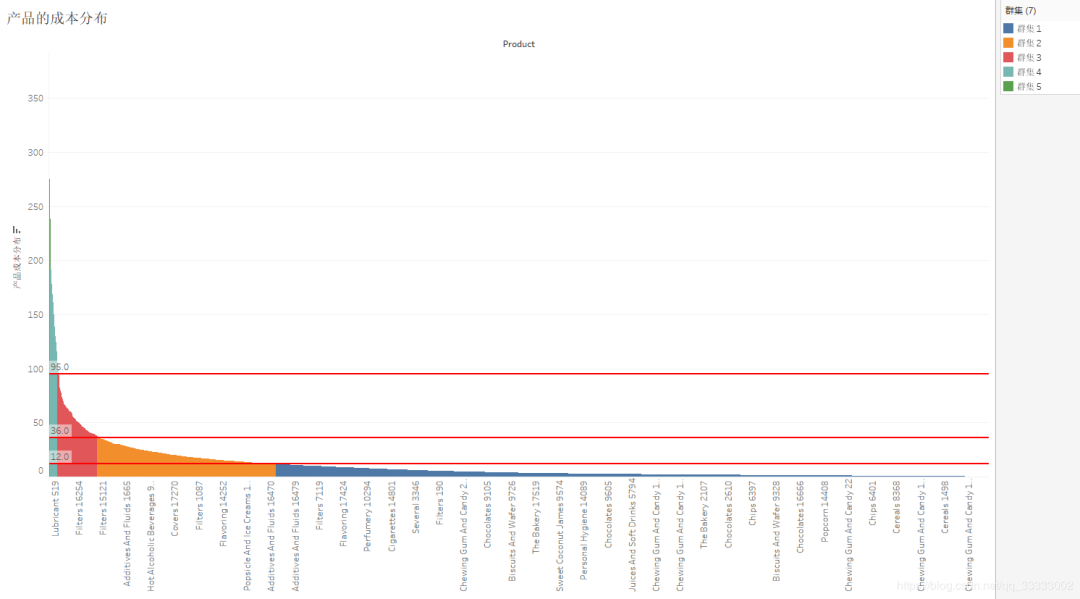
4.4.4 產(chǎn)品的成本分布
較大一部分產(chǎn)品的成本在12以下,其次是在12-36區(qū)間,接著是36-95的區(qū)間,95以上的產(chǎn)品較少。
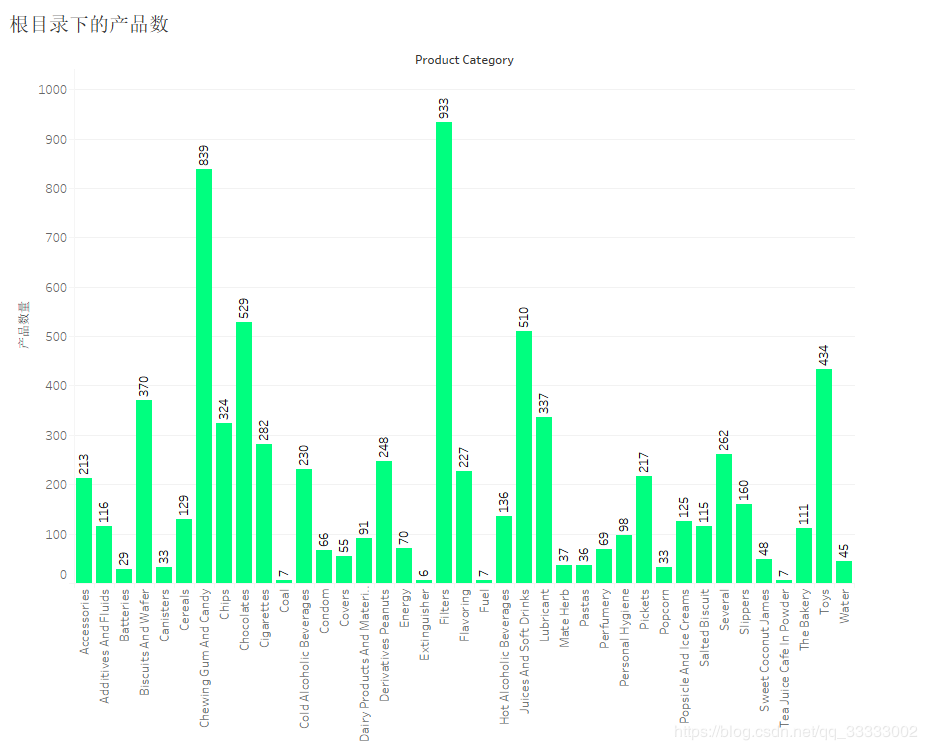
4.4.5 跟目錄下的各個(gè)產(chǎn)品數(shù)
Filters產(chǎn)品類(lèi)別下的產(chǎn)品數(shù)最多,達(dá)到933。其次是839的Chewing Gum And Candy。最少的產(chǎn)品數(shù)的是類(lèi)別Extinguisher,只有6個(gè)。
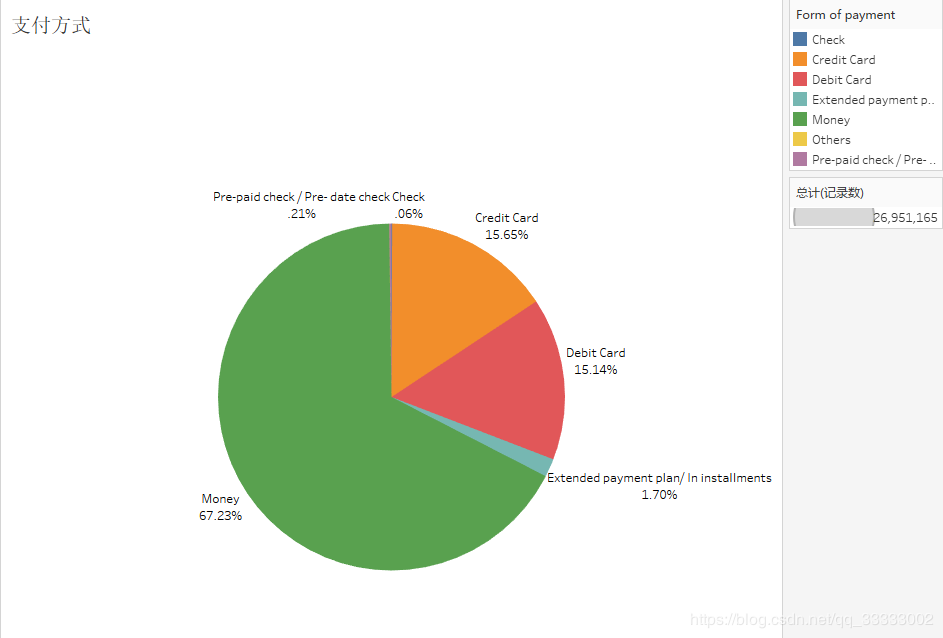
5 支付方式
近7成的用戶(hù)選擇現(xiàn)金支付。
6 總結(jié)
6.1 三年間銷(xiāo)售額達(dá)到了17.8億。
6.2 2017年該連鎖店處于上升期,銷(xiāo)售額、訂單量呈上升狀態(tài),2018、2019年趨于平穩(wěn)。
6.3 該連鎖店的銷(xiāo)售業(yè)績(jī)呈現(xiàn)周期性,周一到星期天較高,星期日最低。
6.4 總體復(fù)購(gòu)率達(dá)到了87.91%,用戶(hù)黏性較大。
6.5 月初到月末的復(fù)購(gòu)率達(dá)到66%以上,用戶(hù)的黏性較大。
6.6 用戶(hù)月留存率達(dá)到74%以上,老客戶(hù)居多。
6.7 產(chǎn)品符合二八分布,前三產(chǎn)品Special Gasoline、Gasoline、Diesel Auto Clean達(dá)到總銷(xiāo)售金額的82%。
6.8 80%的產(chǎn)品的成本在36以下。
6.9 近七成的用戶(hù)選擇現(xiàn)金支付。
如果本文對(duì)大家有幫助,歡迎點(diǎn)贊、在看、收藏~~~
-------------------?End?-------------------
往期精彩文章推薦:
手把手教你使用Flask搭建ES搜索引擎(實(shí)戰(zhàn)篇)
簡(jiǎn)述Python、Anaconda、virtualenv和Miniconda之間的區(qū)別
【進(jìn)階篇】Python+Go——帶大家一起另尋途徑提高計(jì)算性能

歡迎大家點(diǎn)贊,留言,轉(zhuǎn)發(fā),轉(zhuǎn)載,感謝大家的相伴與支持
想加入Python學(xué)習(xí)群請(qǐng)?jiān)诤笈_(tái)回復(fù)【入群】
萬(wàn)水千山總是情,點(diǎn)個(gè)【在看】行不行
/今日留言主題/
隨便說(shuō)一兩句吧~~