
那些看過比較過癮的數據分析方法論[萬字長文]
01
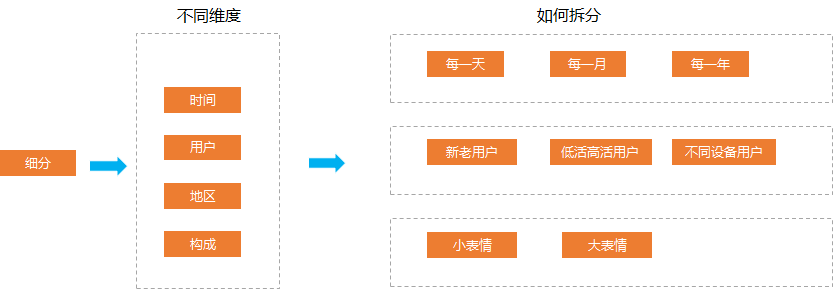
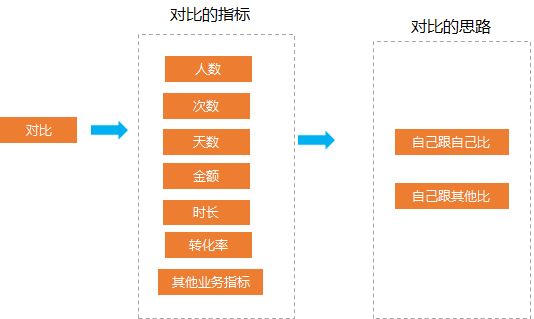
02
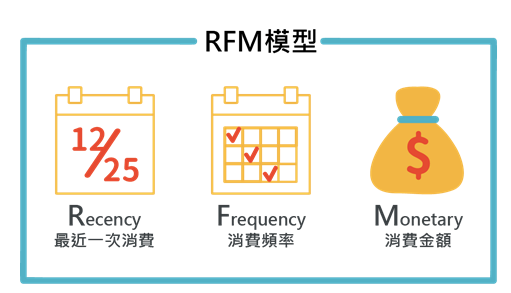
RFM 模型是利用 R, F, M 三個特征去對用戶進行劃分的。
其中R是表示最后一次付費的日期距離現在的時間, 比如你在 12月20號給一個主播打賞過, 那么到現在的距離的天數是5 那么R就是5, R是用來刻畫用戶的忠誠度, 一般來說R越小, 代表用戶上一次剛剛才付費的, 這種用戶的忠誠度比較高。
F是表示一段時間的付費頻次, 也就是比如一個月付費了多少次, 這個是用來刻畫用戶付費行為的活躍度, 我們認為用戶的付費行為頻次越高, 一定程度上代表他的價值度
M是表示一段時間的付費金額, 比如一個月付費了10000元, M=10000, M主要是用來刻畫用戶的土豪程度。
以上我們就從用戶的忠誠度, 活躍度, 土豪度三個方面去刻畫一個用戶的價值度。
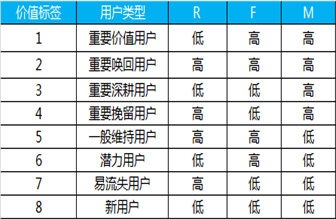
根據RFM的值, 我們就可以把用戶劃分為以下不同的類別:
重要價值用戶: R 低, F 高, M 高, 這種用戶價值度非常高, 因為忠誠度高, 付費頻次高, 又很土豪
重要召回用戶: R 低, F 低 M 高, 因為付費頻次低, 但金額高, 所以是重點召回用戶
重要發(fā)展用戶: R 高, F 低, M 高 因為忠誠度不夠, 所以需要大力發(fā)展
重要挽留用戶: R 高 F 低 M高 因為 忠誠度和活躍度都不夠 很容易流失 所以需要重點挽留
還有四種其他用戶就不一一列舉
RFM如何分群:
1.首先是利用sql 計算 每一個用戶的 R, F, M, 最終得到的數據格式如下
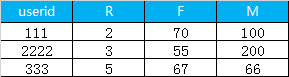
2. 讀取數據和查看數據
pay_data= pd.read_csv('d:/My Documents/Desktop/train_pay.csv')# 路徑名 'd:/My Documents/Desktop/train_pay.csv' 填寫你自己的即可pay_data.head() # 查看數據前面幾行
3. 選取我們要聚類的特征
pay_RFM = pay_data[['r_c','f_c','m_c']]4. 開始聚類, 因為我們用戶分群分的是八個類別, 所以k =8
# 創(chuàng)建模型model_k = KMeans(n_clusters=8,random_state=1)# 模型訓練model_k.fit(pay_RFM)# 聚類出來的類別賦值給新的變量 cluster_labelscluster_labels = model_k.labels_
5. 對聚類的結果中每一個類別計算 每個類別的數量 最小值 最大值 平均值等指標
rfm_kmeans = pay_RFM.assign(class1=cluster_labels)num_agg = {'r_c':['mean', 'count','min','max'], 'f_c':['mean', 'count','min','max'],'m_c':['mean','sum','count','min','max']}rfm_kmeans.groupby('class1').agg(num_agg).round(2)
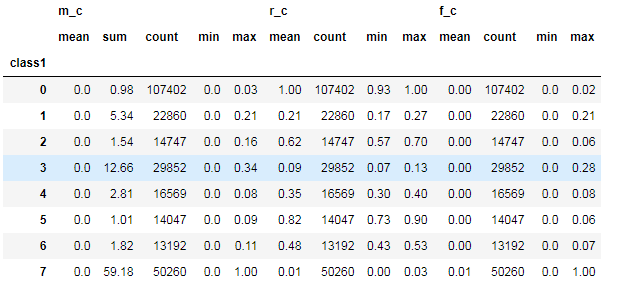
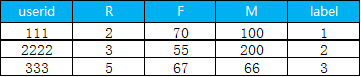
6. 把聚類出來的類別和用戶id 拼接在一起
pay_data.assign(class1=cluster_labels).to_csv('d:/My Documents/Desktop/result.csv',header=True, sep=',')下面就是最終結果, label 表示用戶是屬于哪一個細分的類別
03
生命周期模型
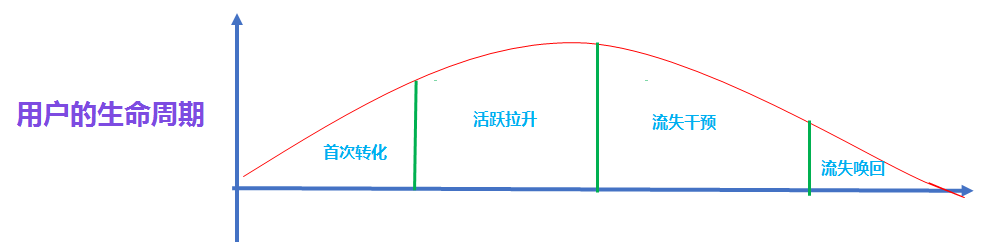
分位數法:
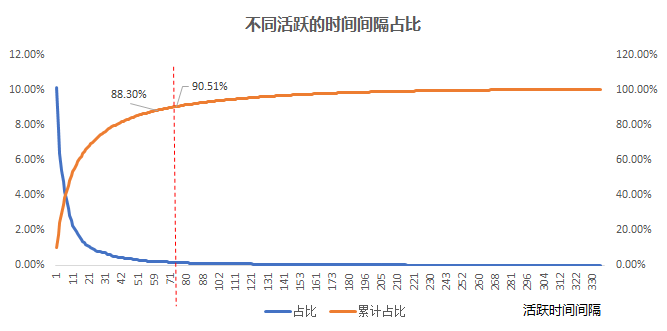
首先先計算用戶活躍的時間間隔, 比如用戶a 活躍的時間日期分別是 2020-12-01 和 2020-12-14 那么間隔就是13天, 我們把所有用戶的活躍的時間間隔都計算好, 然后找出間隔的 90% 分位數.
為什么是90% 分位數呢?這是因為如果有90% 的活躍時間間隔都在某個周期以內的話, 那么這個周期內不活躍的話, 之后活躍的可能性也不高。
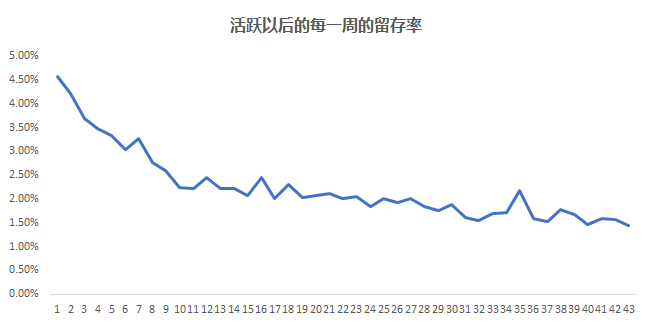
在數據分析的問題中, 經常會遇見的一種問題就是相關的問題, 比如抖音短視頻的產品經理經常要來問留存(是否留下來)和觀看時長, 收藏的次數, 轉發(fā)的次數, 關注的抖音博主數等等是否有相關性, 相關性有多大。
因為只有知道了哪些因素和留存比較相關, 才知道怎么去優(yōu)化從產品的方向去提升留存率, 比如 如果留存和收藏的相關性比較大 那么我們就要引導用戶去收藏視頻, 從而提升相關的指標,
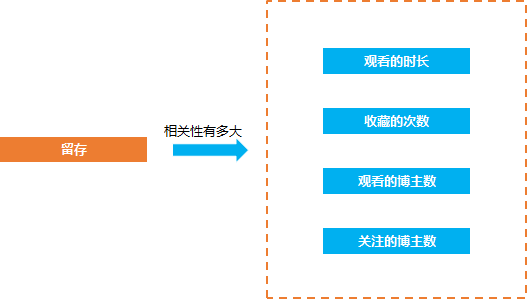
除了留存的相關性計算的問題, 還有類似的需要去計算相關性的問題, 比如淘寶的用戶 他們的付費行為和哪些行為相關, 相關性有多大, 這樣我們就可以挖掘出用戶付費的關鍵行為
這種問題就是相關性量化, 我們要找到一種科學的方法去計算這些因素和留存的相關性的大小,
這種方法就是相關性分析
04
相關性分析是指對兩個或多個具備相關性的變量元素進行分析,從而衡量兩個變量因素的相關密切程度。相關性的元素之間需要存在一定的聯系或者概率才可以進行相關性分析(官方定義)
簡單來說, 相關性的方法主要用來分析兩個東西他們之間的相關性大小
相關性大小用相關系數r來描述,關于r的解讀:(從知乎摘錄的)
(1)正相關:如果x,y變化的方向一致,如身高與體重的關系,r>0;一般地,
·|r|>0.95 存在顯著性相關;
·|r|≥0.8 高度相關;
·0.5≤|r|<0.8 中度相關;
·0.3≤|r|<0.5 低度相關;
·|r|<0.3 關系極弱,認為不相關
(2)負相關:如果x,y變化的方向相反,如吸煙與肺功能的關系,r<0;
(3)無線性相關:r=0, 這里注意, r=0 不代表他們之間沒有關系, 可能只是不存在線性關系。
下面用幾個圖來描述一下 不同的相關性的情況
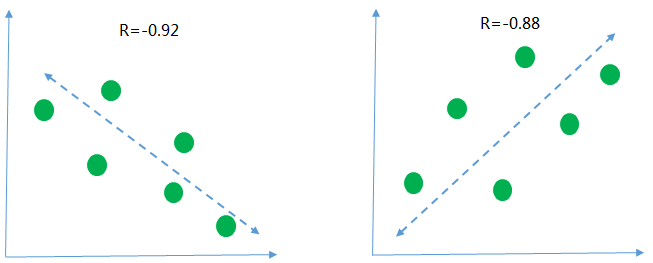
第一張圖r=-0.92 <0 是說明橫軸和縱軸的數據呈現負相關, 意思就是隨著橫軸的數據值越來越大縱軸的數據的值呈現下降的趨勢, 從r的絕對值為0.92>0.8 來看, 說明兩組數據的相關性高度相關
同樣的, 第二張圖 r=0.88 >0 說明縱軸和橫軸的數據呈現正向的關系, 隨著橫軸數據的值越來越大, 縱軸的值也隨之變大, 并且兩組數據也是呈現高度相關
如何實現相關性分析:
前面已經講了什么是相關性分析方法, 那么我們怎么去實現這種分析方法呢, 以下先用python 實現
1. 首先是導入數據集, 這里以tips 為例
import numpy as npimport pandas as pdimport matplotlib.pyplot as pltimport seaborn as sns%matplotlib inline## 定義主題風格sns.set(style="darkgrid")## 加載tipstips = sns.load_dataset("tips")
2. 查看導入的數據集情況,
字段分別代表
total_bill: 總賬單數
tip: 消費數目
sex: 性別
smoker: 是否是吸煙的群眾
day: 天氣
time: 晚餐 dinner, 午餐lunch
size: 顧客數
tips.head() # 查看數據的前幾行
3. 最簡單的相關性計算
tips.corr()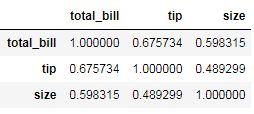
4. 任意看兩個數據之間相關性可視化,比如看 total_bill 和 tip 之間的相關性,就可以如下操作進行可視化
## 繪制圖形,根據不同種類的三點設定圖注sns.relplot(x="total_bill", y="tip", data=tips);plt.show()
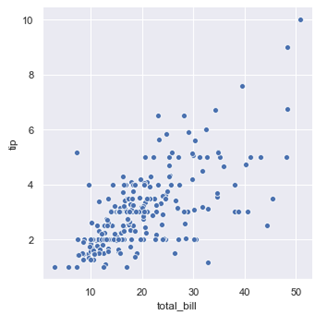
從散點圖可以看出賬單的數目和消費的數目基本是呈正相關, 賬單的總的數目越高, 給得消費也會越多
5. 如果要看全部任意兩兩數據的相關性的可視化
sns.pairplot(tips)
6. 如果要分不同的人群, 吸煙和非吸煙看總的賬單數目total_bill和小費tip 的關系。
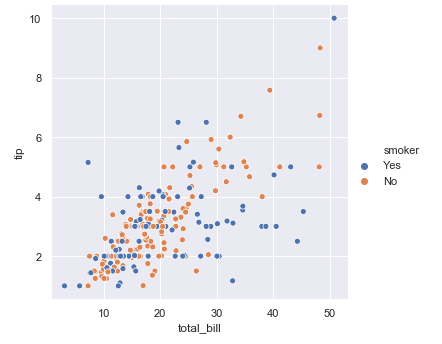
sns.relplot(x="total_bill", y="tip", hue="smoker", data=tips)# 利用hue 進行區(qū)分plt.show()
7. 同樣的 區(qū)分抽煙和非抽煙群體看所有數據之間的相關性,我們可以看到
對于男性和女性群體, 在小費和總賬單金額的關系上, 可以同樣都是賬單金額越高的時候, 小費越高的例子上, 男性要比女性給得小費更大方
在顧客數量和小費的數目關系上, 我們可以發(fā)現, 同樣的顧客數量, 男性要比女性給得小費更多
在顧客數量和總賬單數目關系上, 也是同樣的顧客數量, 男性要比女性消費更多
sns.pairplot(tips ,hue ='sex')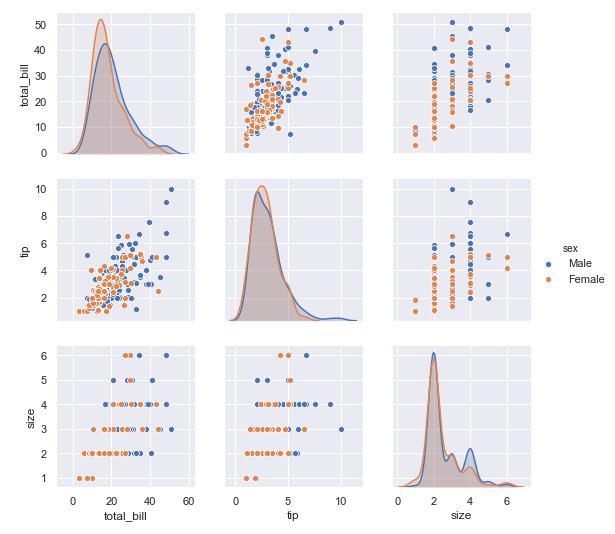
實戰(zhàn)案例:
問題:
影響B(tài) 站留存的相關的關鍵行為有哪些?
這些行為和留存哪一個相關性是最大的?
分析思路:
找全與留存相關的行為
計算這些行為和留存的相關性大小
首先規(guī)劃好完整的思路, 哪些行為和留存相關, 然后利用這些行為+時間維度 組成指標, 因為不同的時間跨度組合出來的指標, 意義是不一樣的, 比如登錄行為就有 7天登錄天數, 30天登錄天數
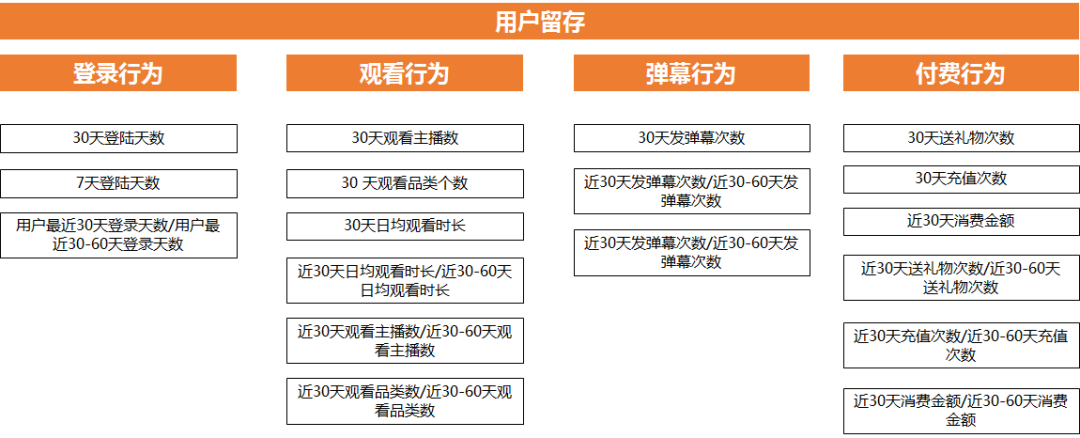
第二步計算這些行為和留存的相關性, 我們用1 表示會留存 0 表示不會留存
那么就得到 用戶id + 行為數據+ 是否留存 這幾個指標組成的數據
然后就是相關性大小的計算
import matplotlib.pyplot as pltimport seaborn as snsretain2 = pd.read_csv("d:/My Documents/Desktop/train2.csv") # 讀取數據retain2 = retain2.drop(columns=['click_share_ayyuid_ucnt_days7']) # 去掉不參與計算相關性的列plt.figure(figsize=(16,10), dpi= 80)# 相關性大小計算sns.heatmap(retain2.corr(), xticklabels=retain2.corr().columns, yticklabels=retain2.corr().columns, cmap='RdYlGn', center=0, annot=True)# 可視化plt.title('Correlogram of retain', fontsize=22)plt.xticks(fontsize=12)plt.yticks(fontsize=12)plt.show()
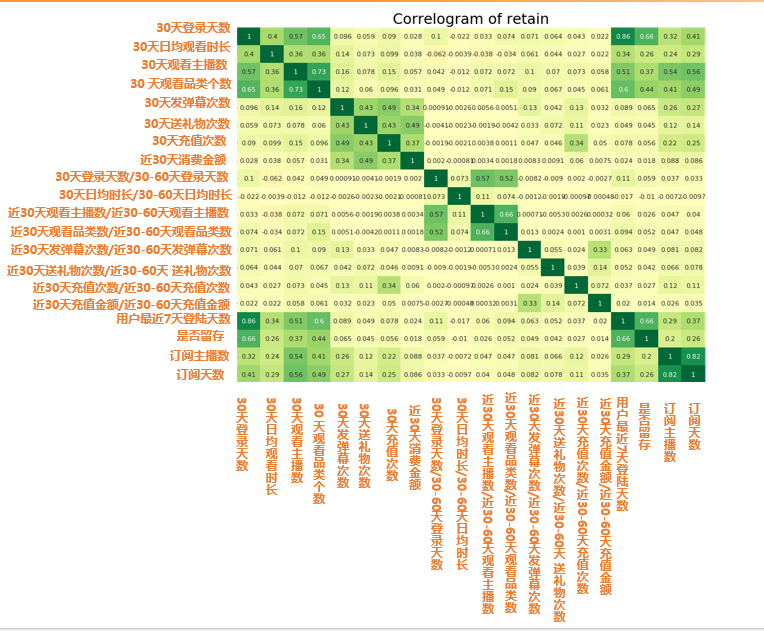
圖中的數字值就是代表相關性大小 r 值 所以從圖中我們可以發(fā)現
留存相關最大的四大因素:
?30天或者7天登錄天數(cor: 0.66)
?30天觀看品類個數(cor: 0.44)
?30天觀看主播數 (cor: 0.37)
?30天日均觀看時長(cor: 0.26)
05

我們經常在淘寶上購物, 作為淘寶方, 他們肯定想知道他的使用用戶是什么樣的, 是什么樣的年齡性別, 城市, 收入, 他的購物品牌偏好, 購物類型, 平時的活躍程度是什么樣的, 這樣的一個用戶描述就是用戶畫像分析
無論是產品策劃還是產品運營, 前者是如何去策劃一個好的功能, 去獲得用戶最大的可見的價值以及隱形的價值, 必須的價值以及增值的價值, 那么了解用戶, 去做用戶畫像分析, 會成為數據分析去幫助產品做做更好的產品設計重要的一個環(huán)節(jié)。
那么作為產品運營, 比如要針用戶的拉新, 挽留, 付費, 裂變等等的運營, 用戶畫像分析可以幫助產品運營去找到他們的潛在的用戶, 從而用各種運營的手段去觸達。
因為當我們知道我們的群體的是什么樣的一群人的時候, 潛在的用戶也是這樣的類似的一群人, 這樣才可以做最精準的拉新, 提高我們的ROI
在真正的工作中, 用戶畫像分析是一個重要的數據分析手段去幫助產品功能迭代, 幫助產品運營做用戶增長。
總的來說, 用戶畫像分析就是基于大量的數據, 建立用戶的屬性標簽體系, 同時利用這種屬性標簽體系去描述用戶
用戶畫像的作用:
像上面描述的那樣, 用戶畫像的作用主要有以下幾個方面
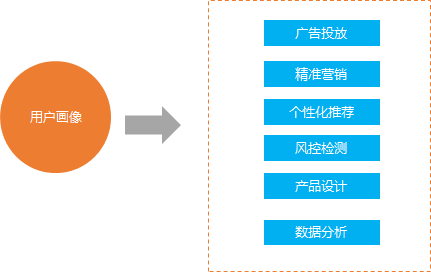
1.廣告投放
在做用戶增長的例子中, 我們需要在外部的一些渠道上進行廣告投放, 對可能的潛在用戶進行拉新, 比如B站在抖音上投廣告
我們在選擇平臺進行投放的時候, 有了用戶畫像分析, 我們就可以精準的進行廣告投放, 比如抖音的用戶群體是18-24歲的群體, 那么廣告投放的時候就可以針對這部分用戶群體進行投放, 提高投放的ROI
假如我們沒有畫像分析, 那么可能會出現投了很多次廣告, 結果沒有人點擊

2.精準營銷
假如某個電商平臺需要做個活動給不同的層次的用戶發(fā)放不同的券, 那么我們就要利用用戶畫像對用戶進行劃分, 比如劃分成不同的付費的活躍度的用戶, 然后根據不同的活躍度的用戶發(fā)放不用的優(yōu)惠券。
比如針對付費次數在 [1-10] 的情況下發(fā) 10 元優(yōu)惠券刺激, 依次類推
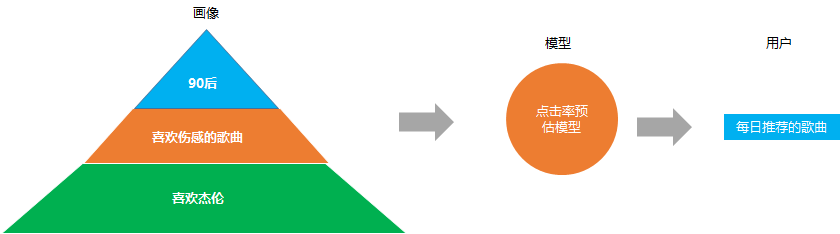
3. 個性化推薦
精確的內容分發(fā), 比如我們在音樂app 上看到的每日推薦, 網易云之所以推薦這么準, 就是他們在做點擊率預估模型(預測給你推薦的歌曲你會不會點擊)的時候, 考慮了你的用戶畫像屬性。
比如根據你是90后, 喜歡傷感的, 又喜歡杰倫, 就會推薦類似的歌曲給你, 這些就是基于用戶畫像推薦
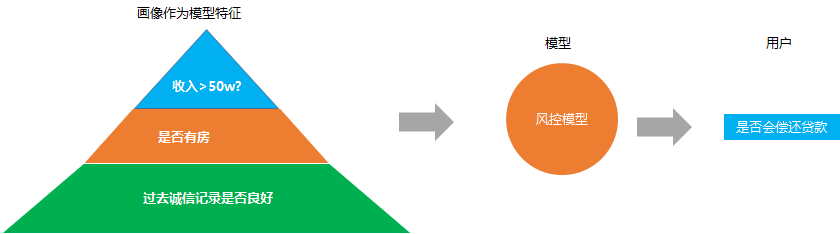
4. 風控檢測
這個主要是金融或者銀行業(yè)設計的比較多, 因為經常遇到的一個問題就是銀行怎么決定要不要給一個申請貸款的人給他去放貸
經常的解決方法就是搭建一個風控預測模型, 去預約這個人是否會不還貸款,同樣的, 模型的背后很依賴用戶畫像。
用戶的收入水平, 教育水平, 職業(yè), 是否有家庭, 是否有房子, 以及過去的誠信記錄, 這些的畫像數據都是模型預測是否準確的重要數據
5. 產品設計
互聯網的產品價值 離不開 用戶 需求 場景 這三大元素, 所以我們在做產品設計的時候, 我們得知道我們的用戶到底是怎么樣的一群人, 他們的具體情況是什么, 他們有什么特別的需求, 這樣我們才可以設計出對應解決他們需求痛點的產品功能
在產品功能迭代的時候, 我們需要分析用戶畫像行為數據, 去發(fā)現用戶的操作流失情況, 最典型的一種場景就是漏斗轉化情況, 就是基于用戶的行為數據去發(fā)現流失嚴重的頁面, 從而相對應的去優(yōu)化對應的頁面,
比如我們發(fā)現從下載到點擊付款轉化率特別低,那么有可能就是我們付款的按鈕的做的有問題, 就可以針對性的優(yōu)化按鈕的位置等等
同時也可以分析這部分轉化率主要是在那部分用戶群體中低, 假如發(fā)現高齡的用戶的轉化率要比中青年的轉化率低很多, 那有可能是因為我們字體的設置以及按鈕本身位置不顯眼等等, 還有操作起來不方便等等因素
6. 數據分析
在做描述性的數據分析的時候, 經常需要畫像的數據, 比如描述抖音的美食博主是怎么樣的一群人, 他們的觀看的情況, 他們的關注其他博主的情況等等
簡單來說就是去做用戶刻畫的時候, 用戶畫像可以幫助數據分析刻畫用戶更加清晰。
如何構建用戶畫像:
用戶畫像搭建的架構如下:
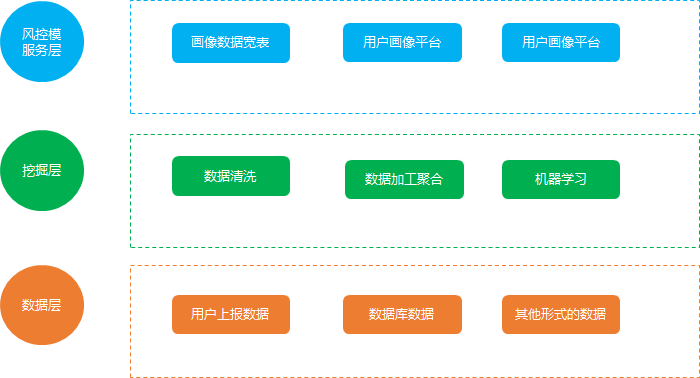
數據層:
首先 是數據層, 用戶畫像的基礎是首先要去獲取完整的數據, 互聯網的數據主要是 利用打點, 也就是大家說的數據埋點上報上來的, 整個過程就是 數據分析師會根據業(yè)務需要提數據上報的需求,然后由開發(fā)完成, 這樣就有了上報的數據。

除了上報的數據, 還有其他數據庫同步的數據, 一般會把數據庫的數據同步到hive表中, 按照數據倉庫的規(guī)范, 按照一個個主題來放置
還有一些其他的數據比如外部的一些調研的數據, 以excel 格式存在, 就需要把excel 數據導入到hive 表中
挖掘層:
有了基礎的數據以后, 就進入到挖掘層, 這個層次主要是兩件事情, 一個是數據倉庫的構建, 一個是標簽的預測, 前者是后者的基礎。
一般來說我們會根據數據層的數據表, 對這些數據表的數據進行數據清洗,數據計算匯總, 然后按照數據倉庫的分層思想, 比如按照 數據原始層, 數據清洗層, 數據匯總層, 數據應用層等等進行表的設計

數據原始層的表的數據就是上報上來的數據入庫的數據, 這一層的數據沒有經過數據清洗處理, 是最外層的用戶明細數據
數據清洗層主要是數據原始層的數據經過簡單數據清洗之后的數據層, 主要是去除明顯是臟數據, 比如年齡大于200歲, 地域來自 FFFF的 等明顯異常數據
數據匯總層的數據主要是根據數據分析的需求, 針對想要的業(yè)務指標, 比如用戶一天的聽歌時長, 聽歌歌曲數, 聽的歌手數目等等, 就可以按照用戶的維度, 把他的行為進行聚合, 得到用戶的輕量指標的聚合的表。
這個層的用處主要是可以快速求出比如一天的聽歌總數, 聽歌總時長, 聽歌時長高于1小時的用戶數, 收藏歌曲數高于100 的用戶數是多少等等的計算就可以從這個層的表出來
數據應用層主要是面向業(yè)務方的需求進行加工, 可能是在數據匯總的基礎上加工成對應的報表的指標需求, 比如每天聽歌的人數, 次數, 時長, 搜索的人數, 次數, 歌曲數等等
按照規(guī)范的數據倉庫把表都設計完成后, 我們就得到一部分的用戶的年齡性別地域的基礎屬性的數據以及用戶觀看 付費 活躍等等行為的數據
但是有一些用戶的數據是拿不到的比如音樂app 為例, 我們一般是拿不到用戶的聽歌偏好這個屬性的數據, 我們就要通過機器學習的模型對用戶的偏好進行預測

機器學習的模型預測都是基于前面我們構建的數據倉庫的數據的, 因為只有完整的數據倉庫的數據, 是模型特征構建的基礎
服務層:
有了數據層和挖掘層以后, 我們基本對用戶畫像體系構建的差不多, 那么就到了用戶畫像賦能的階段。
最基礎的應用就是利用用戶畫像寬表的數據, 對用戶的行為進行洞察歸因 挖掘行為和屬性特征上的規(guī)律
另外比較大型的應用就是搭建用戶畫像的平臺, 背后就是用戶畫像表的集成。
用戶提取: 我們可以利用用戶畫像平臺, 進行快速的用戶選取, 比如抽取18-24歲的女性群體 聽過杰倫歌曲的用戶, 我們就可以快速的抽取。
分群對比: 我們可以利用畫像平臺進行分群對比。比如我們想要比較音樂vip 的用戶和非vip 的用戶他們在行為活躍和年齡性別地域 注冊時間, 聽歌偏好上的差異, 我們就可以利用這個平臺來完成
功能畫像分析: 我們還可以利用用戶畫像平臺進行快速進行某個功能的用戶畫像描述分析, 比如音樂app 的每日推薦功能, 我們想要知道使用每日推薦的用戶是怎么樣的用戶群體, 以及使用每日推薦不同時長的用戶他們的用戶特征分別都是怎么樣的,就可以快速的進行分析
06
在數據分析的面試中, 你是否不止一次遇到以下的問題:
DAU降低了, 怎么分析,
用戶留存率下降了怎么分析
訂單數量下降了怎么分析
像這樣的問題, 如果沒有科學的思維框架去梳理你的思路的話, 去回答這個問題我們就會有一種想要說很多個點, 但不知道先說哪一個點, 只會造成回答很亂, 沒有條理性, 同時有可能會漏斗很多點
回答這種分析的類似的問題的時候, 大多數情況下都可以利用5w2h 的方法幫助我們去組織思路, 這樣可以在回答這種類似的問題的時候, 可以做到邏輯清晰, 答得點縝密完善
比如DAU下降了, 5w2h 分析法會教你如何拆解DAU下降以及歸因以及給出建議
比如用戶留存率下降了, 5w2h方法會教你去拆解用戶, 歸納不同群體的留存率下跌原因
比如訂單數量下跌了, 5w2h 方法助力漏斗分析, 快速挖掘流失的關鍵步驟, 關鍵節(jié)點
什么是5w2h:
5w2h 分析法主要是 以五個W開頭的英語單詞和兩個以H開頭的英語單詞組成的, 這五個單詞為我們提供了問題的分析框架
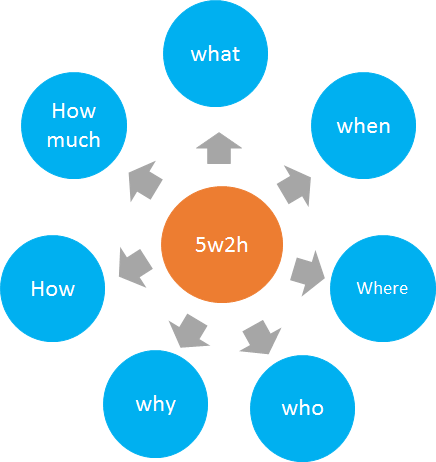
5W的內容
1.What-發(fā)生了什么?一般用來值得是問題是什么, what 的精髓在于告訴我們第一步要認清問題的本質是什么
2.When-何時?在什么時候發(fā)生的? 問題發(fā)生的時間, 比如dau 下降了就是下降的具體時間分析, 這個時間是不是節(jié)假日等等
3.Where-何地?在哪里發(fā)生的? 問題發(fā)生的拆解其中一個環(huán)節(jié), 還是dau 下降了, 是哪一個的地區(qū)的下降了, 是哪一個功能的使用的人下降了等等
4.Who-是誰? 比如dau 下降了, 就是是哪一部分的用戶群體在降, 是哪一個的年齡, 性別, 使用app 時長等等
5.Why-為什么會這樣?dau 可能降低的原因猜想, 比如某個地區(qū)的dau 降低了, 其他地方的沒有降低, 那可能是這個地區(qū)的app 在使用的過程中有什么問題
2H的內容
1.How-怎樣做?知道了問題是什么以后, 就到了策略層了, 就是我們要采取什么樣的方法和策略去解決這個dau 下降的問題
2.How Much-多少?做到什么程度?這個主要是比如dau下降了以后, 我們采取對應的策略是可能花費的成本是多少, 以及我們要解決這個降低的問題解決到什么程度才可以
案例實戰(zhàn):
1.背景:
某APP的付費人數一直在流失, 如何通過數據分析去幫助產品和業(yè)務去挖掘對應的付費的流失原因并給出對應的解決策略
2.分析思路:
嘗試用5w2h 分析法去拆解這個問題

what: 我們的問題是付費人數開始流失了, 這種流失應該就是表現出來同比和環(huán)比可能都是下降的
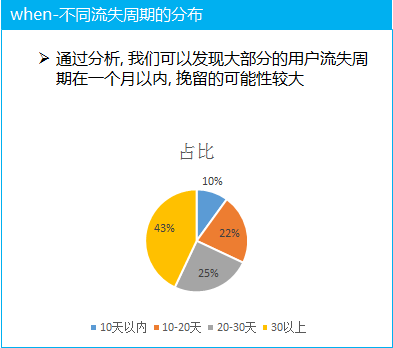
when: 整體的流失很難看出問題, 所以我們需要去分析不同的流失周期的用戶的占比大概都是多大, 從而分析出現在付費用戶的流失周期主要集中在哪里。
where: 付費的入口和不同付費點的分析, 主要是分析哪一個入口的付費人數流失嚴重或者哪個功能的付費人數流失嚴重, 挖掘關鍵位置
who: 對用戶的屬性和行為進行分析, 分析流失的這部分用戶群體是否具有典型的特征, 比如集中在老年群體, 集中在某個地區(qū)等等, 行為的特征分析表現在流失的用戶的行為活躍表現是怎么樣的, 比如是否還在app 上活躍, 活躍的時長和天數等等的分析
why: 通過上面的分析, 就可能大致得出用戶的流失的原因, 需要把數據結論和猜想對應起來去看, 并做好歸納總結
how: 當我們挖掘和分析出付費用戶流失的原因了以后, 需要采取對應的策略去減少流失的速度, 同時針對流失的用戶進行挽留和召回
how much: 在通過數據分析給出對應的策略的時候, 也需要幫助業(yè)務方去評估我們的策略大概需要的成本, 讓業(yè)務方知道這個策略的可行性以及價值
3.分析過程:
(1) 不同用戶的流失周期比例分析, 大部分的群體的流失周期還不是很長, 說明整體來說用戶的流失是最近剛發(fā)生的, 同時流失的周期不長, 說明我們有能力可以針對這部分的流失用戶利用策略進行挽留
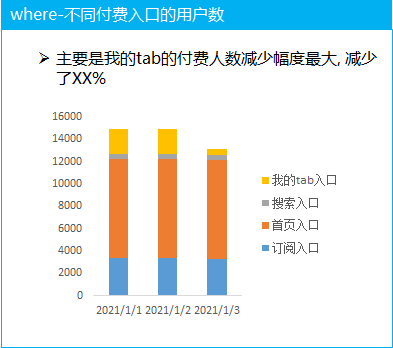
(2)不同付費入口的拆解分析
對比付費的四個主要的入口, 分析每天的付費人數的走勢, 發(fā)現付費人數的減少主要集中在我的tab 入口, 我的tab 入口的付費降低的可能原因是什么呢
這就需要拉上業(yè)務方一起去分析對應的原因, 比如是可能是這個位置的付費功能的具體流失的每一個環(huán)節(jié)的流失情況(結合漏斗分析一起去看)
分析出我的tab 頁面中 付費功能具體的流失環(huán)節(jié), 然后再針對性的進行調整迭代
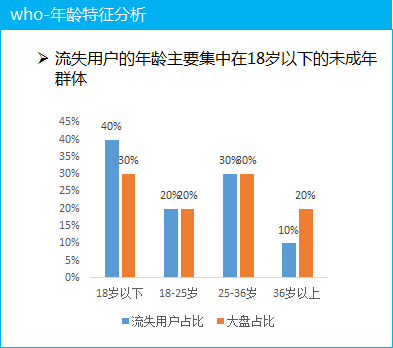
(3) 用戶特征分析
這里以年齡為例, 分析流失的付費用戶的年齡特征, 發(fā)現主要集中在18歲以下的未成年群體, 這部分的用戶群體為什么流失呢? 就需要結合用戶反饋等一起去看
除了年齡的角度, 我們還可以分析流失的用戶的性別特征, 城市級別特征, 活躍時長和活躍天數, 經常使用的功能等特征
(4) 原因總結歸納
通過分析, 付費的用戶群體主要原因是我的tab 的付費功能引起的, 可能是具體的某個付費轉化環(huán)節(jié)出現問題
流失的用戶群體主要是18歲以下, 男性, 三線城市為主(假設)
流失的用戶群體活躍時長, 活躍次數, 活躍天數等沒有明顯下降
(5) 策略落地
這個環(huán)節(jié)需要和業(yè)務方反饋我們的數據分析結論, 然后結合產品的經驗以及用戶反饋以及調查問卷等方法進一步確定原因
如果確定好是我的tab 中付費功能的某個環(huán)節(jié)出現問題, 就需要針對的進行改進, 同時上線小流量的ab test 去驗證我們的策略是否有效
07
麥肯錫邏輯樹
邏輯樹又稱為問題數,演繹樹或者分解樹,是麥肯錫公司提出的分析問題,解決問題的重要方法
首先它的形態(tài)像一顆樹,把已知的問題比作樹干,然后考慮哪些問題或者任務與已知問題有關,將這些問題或子任務比作邏輯樹的樹枝,一個大的樹枝還可以繼續(xù)延續(xù)伸出更小的樹枝,逐步列出所有與已知問題相關聯的問題
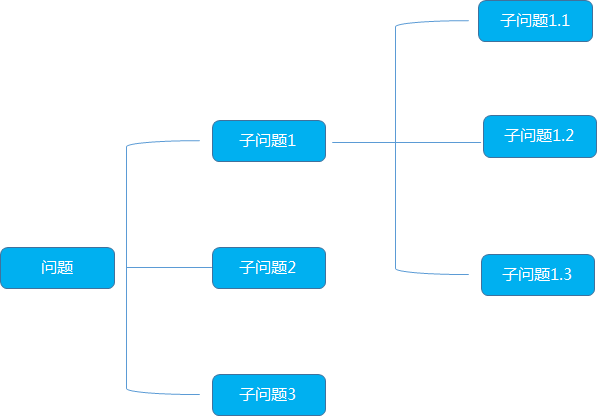
總的來說, 邏輯樹滿足三個要素
要素化:把相同問題總結歸納成要素
框架化:將各個要素組織成框架,遵守不重不漏的原則
關聯化:框架內的各要素保持必要的相互關系,簡單而不孤立
邏輯樹的作用:
數據體系的搭建
數據體系的搭建中, 需要借助邏輯樹的思路將業(yè)務的整體的目標結構化的進行拆解, 然后轉化成可以量化的數據指標, 再轉變?yōu)橹笜梭w系。
舉個例子, 比如下面的OSM模型搭建數據體系的思路就是借助了邏輯樹的思路
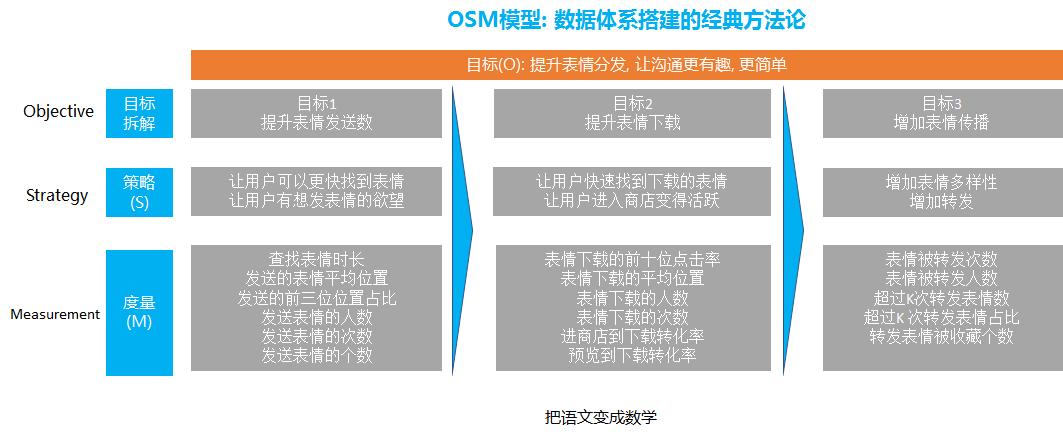
首先業(yè)務的整體目標是 提升表情的分發(fā), 讓表情的溝通更有趣更簡單
通過邏輯樹分析法, 我們可以進行第一步的拆解, 就是把整體表情進行拆解為提升表情發(fā)送數, 提升表情下載, 增加表情傳播
提高表情發(fā)送數主要是提升用戶的發(fā)送, 那么就變成去提升用戶的發(fā)送, 那么怎么提升用戶的發(fā)送呢, 我們可以通過內容和功能維度去解答
在內容方面, 我們要做到我們的表情豐富度和有趣度和新穎度和表達度等等, 要讓用戶有發(fā)這個表情的欲望
除了表情本身, 在發(fā)表情功能上我們也要針對性的進行優(yōu)化, 比如提高用戶查找表情的效率, 我們要去縮短查找表情的時間。
提升表情的下載, 也是同樣的內容和功能本身, 在功能方面, 我們涉及到怎么把每個用戶喜歡的表情排在最前面, 因為這樣用戶可以快速找到他們想要下載的表情.
另外, 也要通過功能的優(yōu)化, 提升用戶進入到表情商店的比例, 從源頭上保證有足夠的用戶數都能夠進入到表情商店
在內容方面, 我們要保證表情商店的表情在豐富度和吸引用戶方面進行優(yōu)化等等
提升表情的傳播, 也是需要在內容和功能上優(yōu)化, 這就涉及到社交關系的傳播和表情的關系, 涉及除了要去引導用戶下載自己喜歡的, 還要去下載他和朋友共同喜歡的表情
這樣當a 用戶發(fā)送了a 和a 的朋友b 共同喜歡的表情 就可以得到更多的轉發(fā)
2. 數據問題的分析
針對用戶訂單減少的問題的分析, 可以利用邏輯樹分析法, 定位到可能的流失原因, 再用數據驗證
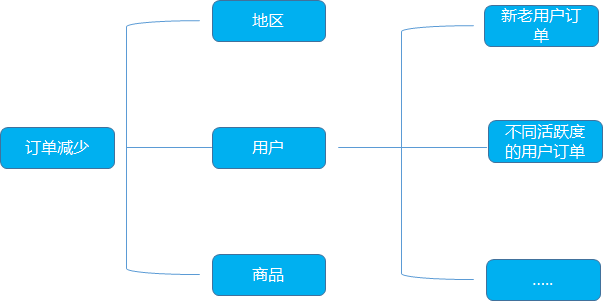
比如某個電商平臺的訂單降低, 我們利用邏輯樹的拆解從地區(qū), 用戶, 商品類型等多個維度去思考。
從地區(qū)的角度, 整體的訂單減少, 可以看一下是否是某個地區(qū)降低了, 可以細分到省, 市
從用戶的角度, 是否是哪一類的用戶的訂單在減少, 同時還可以區(qū)分不同活躍度的用戶在訂單上的表現, 看具體的原因猜想
從商品的角度, 可以區(qū)分一下不同品類的商品看是否是特定品類的商品訂單量跌了
邏輯樹分析法在dau 中的應用:
背景:
某電商app DAU 跌了, 需要分析為什么dau 會跌, 這也是數據分析面試經典的問題, 在回答這個問題的時候, 為了使得我們的答案具有結構化和條理化, 需要應用邏輯樹分析法
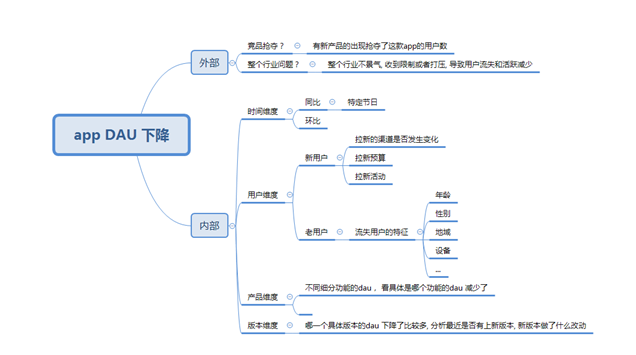
分析思路:
整體的分析思路如上,首先是拆分成外部和內部因素, 從最大的兩個思路去切入, 一般去分析這個問題的時候, 很容易就會忽略外部因素, 外部因素也是很重要的一部分
外部的思考主要是競品分析, 分析是否是競品的崛起導致一部分用戶轉移到他們那邊去了
外部的另外一個就是行業(yè)分析, 可以借助pest 等分析方法,分析這個行業(yè)的外部環(huán)境是否變得惡劣, 比如國家限制, 生活, 經濟, 政策, 政治等外部原因
假如外部沒有明顯的問題, 這才進入到內部因素的排查
內部的分析首先應該是時間因素, 因為真正在工作實際中, 我們發(fā)現大多數的dau 等數據指標有大幅度波動都是因為節(jié)日引起的
所以有兩個判斷的方法, 假如這個dau 只是環(huán)比跌的很厲害, 然而同比沒有明顯變化, 甚至可能比去年這個指標還是漲的, 那么很大的概率可能就是節(jié)假日的影響
然后是用戶維度, 整體的DAU= 新用戶+老用戶, 所以應該看這兩個部分的是哪一部分的用戶數減少
如果是新用戶減少, 因為新用戶是從渠道通過廣告買量買過來的, 與這個數量相關的涉及到 渠道的質量, 買量的錢, 買完的一些承接運營活動
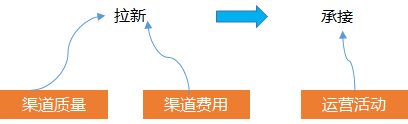
所以, 可以分開拆解看, 是否是渠道本身的質量問題, 比如騰訊廣點通, 頭條巨量, 看渠道本身在投放上起量是否是有問題的
同時也要看我們投放廣告的錢是否有減少這會直接影響到我們能拉多少的人,預算直接決定了你的拉新絕對量的上限
拉取過來的用戶要保證活躍, 我們通常會有運營活動或其他策略的承接, 也就是業(yè)界說的拉承一體化, 所以我們要去分析是否是運營活動的效果或者其他策略的效果影響我們的承接, 導致這部分用戶的活躍度下降
除了新用戶的分析, 老用戶的分析也是非常重要的, 主要有常用的用戶畫像分析, 這部分可以參照 數據分析思維和方法—用戶畫像分析
主要是分析老用戶是否下降, 如果下降了分析這部分下降的用戶群體具有什么樣的畫像特征, 這樣可以輸出一個下跌用戶的完整行為和基礎屬性的洞察, 比如下降的用戶群主要是18歲以下的未成年人等等
第三個是產品本身維度, 如果分析出是所有類型的用戶, 所有渠道的用戶都在跌, 那就可能是產品本身的功能引起的
我們需要去排查一下dau 主要的功能模塊的組成的用戶, 去看一下這些功能的dau 是否跌的, 一般如果沒有版本上線, 舊的功能的用戶波動是由于功能bug 引起的
產品本身的排查比較麻煩, 因為有可能定位某個功能的人數變少了但是不知道原因, 這時候可以借助用戶反饋, 一般可以從用戶反饋上發(fā)現一些問題
08
漏斗分析法
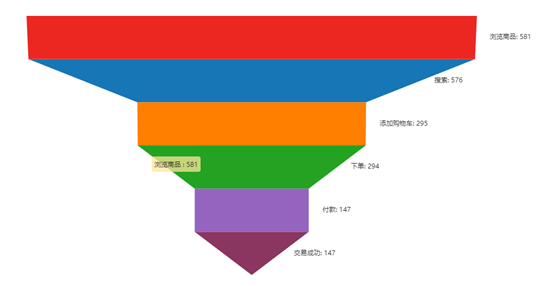
漏斗分析是一種可以直觀地呈現用戶行為步驟以及各步驟之間的轉化率,分析各個步驟之間的轉化率的分析方法
比如對應我們每一次在淘寶上的購物, 從打開淘寶app, 到搜索產品, 到查看產品詳情, 到添加購物車, 到下單, 到成功交易, 漏斗分析就是幫助我們去計算每一個環(huán)節(jié)的轉化率
從打開淘寶app 到搜索的轉化率, 從搜索產品到查看產品的詳情的轉化率,從查看產品到添加購物車的轉化率, 從添加購物車到下單的轉化率等等
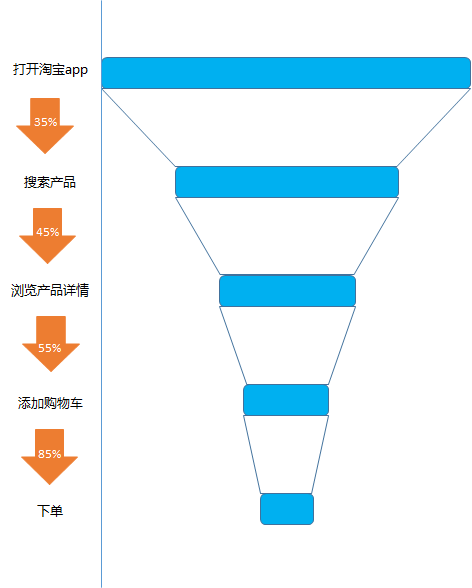
漏斗分析的價值:
漏斗分析的價值主要有: 功能優(yōu)化, 運營投放, 用戶流失等

功能優(yōu)化:
以視頻制作工具為例, 從下面我們可以明顯看出, 進入到上傳視頻的轉化率只有80%, 可能是上傳入口不明顯, 上傳的引導不夠, 上傳功能的吸引程度不夠等原因引起的, 我們就可以去優(yōu)化上傳功能

運營投放:
以運營投放類為例, 在實際業(yè)務中經常會對一些定向的用戶投放一些活動, 讓他們參加活動, 比如針對游戲的業(yè)務, 會定期針對潛在的付費用戶投放一批充值優(yōu)惠大禮包活動
從下圖的觸達到參與的轉化率只有 62.5%, 說明我們選的定向的用戶可能對于我們的活動不是非常感興趣, 可能是這批用戶本身不是特別喜歡參與活動, 所以我們就可以重新選取其他可能更加可能響應的用戶來做定向推送
那么怎么選取最有可能參與活動的用戶呢, 這里最簡單的就可以用用戶特征分析的方法來, 我們可以分析出參與活動和不參與活動的特征差異, 進行對比,
也就是采取對比的分析方法, 具體可以見數據分析方法和思維—對比細分
分析的結果就可以得到比如參與活動的用戶可能本身在過去的付費頻次上更好, 付費的金額更大, 并且在游戲的平均時長, 平均的游戲局數上更多, 年齡集中在18歲以下的群體中
那么我們就可以用這些特征去圈定更多的用戶去做投放
另外一種去優(yōu)化定向用戶提高參與率的方法就是去利用模型去提前預測好哪些用戶可能會參與活動, 可能使用的模型比如決策樹, 邏輯回歸等分類模型

用戶流失:
以電商app 淘寶為例, 假如我們的訂單人數下降了, 這時候就需要梳理用戶購買鏈路, 把用戶從打開app 到下單的所有的鏈路都梳理一遍, 然后利用漏斗分析, 計算每個環(huán)節(jié)的轉化率
假如我們梳理鏈路中發(fā)現, 從搜索商品到查看商品的轉化率很低, 那么我們就需要看是否是很多搜索無結果, 或者是搜索中的結果很多用戶不太滿意, 導致用戶不買單
那就可以把電商的付費問題轉化為搜索的問題, 從而又可以對搜索的整個轉化鏈路再做一次漏斗分析, 一步步的去定位問題

漏斗分析的作用:
在用戶增長的最出名的漏斗模型叫做AARRR, 即從用戶獲取, 用戶激活, 用戶留存, 用戶付費到用戶傳播
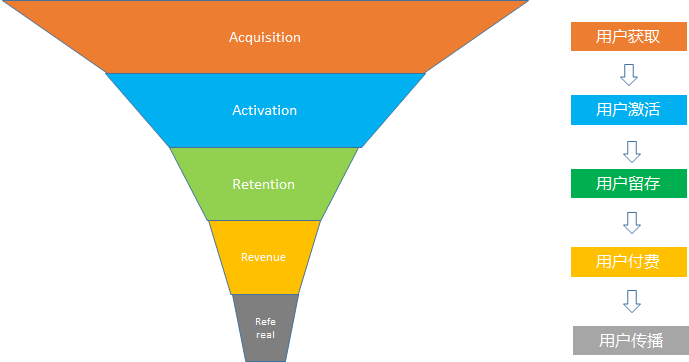
以拼多多為例, 以AARRR漏斗模型解析拼多多的用戶增長之路
1.用戶獲取
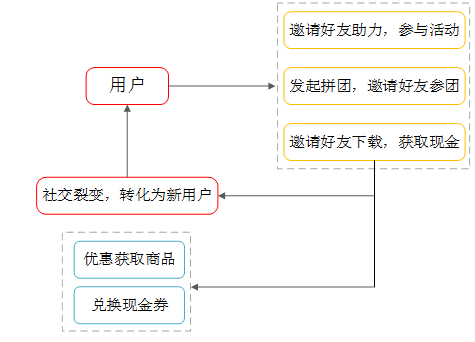
拼多多主要的目標群體是三四線城市,這也屬于現有電商品臺比較空白的區(qū)域,對于三四線用戶來說,最好的吸引方案就是優(yōu)惠。
而且三四線用戶時間充足,時間成本于他們而言是非常低的,而砍價也是一種慣常的方法,在他們的群體中很少存在對貪小便宜歧視的問題,也沒有太多的社交壓力,甚至砍價可以變成一種聯系的手段,砍價群又何嘗不是一種交流。
他們也很樂意用時間和社交成本來換取更大的優(yōu)惠。所以砍價這種優(yōu)惠活動紅極一時,也幫助拼多多拉取了很多流量
砍價活動借助微信朋友圈和微信群的關系鏈, 成為爆發(fā)式的轉發(fā)和增長, 一般親朋友不會拒絕你的要請砍一刀
2.用戶激活
當拉到新用戶的時候, 就要保證最大程度的去激活他, 拼多多采取的做法也是跟拉新類似, 就是不斷用用戶的傳播去觸達好友
當一個用戶被其他朋友反復觸達的時候, 自然而然就會去打開曾經下載過的app,在其他朋友感受到拼多多百億補貼各種補貼各種優(yōu)惠的真香的時候, 自己也會去嘗試
3.留存
為了提高用戶的留存, 拼多多提供了一個簽到領取獎品的活動鼓勵用戶每天都打開app 來簽到打卡, 簽到滿XX天就可以送你對應的商品禮物, 大大促進拼多多用戶群體的薅羊毛的心理, 同時也提升了留存
除了這個活動拼多多里面還設置了不同的各種小活動, 滿足不同的用戶群體的需要, 在玩小任務的過程中領取對應的獎勵
4. 用戶付費
拼多多以優(yōu)惠券等的形式刺激用戶下單, 比如下面的下首單并賺XX元, 而且還不給你叉掉這個頁面的按鈕
還有就是非常出名的百億補貼, 直接用大額現金給用戶補貼, 這一個打法把一二線的用戶也被轉化了
還有就是0元下單的活動, 0元免費下三單全額返還金額的活動
以及限時優(yōu)惠限時秒殺, 9快手特賣等都是促使用戶去下單等活動
頁面上也是各種“”XX已經拼單“”等文字的提醒引導也是促進用戶下單
5. 用戶傳播
傳播主要依賴微信這個流量大平臺以及微信關系鏈, 朋友之間的傳播分為, 有些東西是要轉發(fā)朋友才可以領取現金以及拼單以及優(yōu)惠, 在這些優(yōu)惠面前, 轉發(fā)的成本變得很小
另外拼多多上是有一些真的實惠又好用的高性價比的商品, 這種的商品會引發(fā)朋友之間互相推薦
以上的一些原因, 拼多多的商品和玩法在朋友之前瘋狂流轉, 在傳播的過程中, 每個用戶都熟知了拼多多可以做到這么實惠的玩法, 被觸達的用戶又會開始新的轉發(fā), 從而引爆增長
社交網絡的增長是沒有盡頭的, 也是阻止不了的, 一代帝國的誕生
數據是風, 你們是風上閃爍的星群
風中細數星群, 一如那余味纏繞的甘醇
-----------------------------------------------------------------