
現(xiàn)場直播懟臉!騰訊云行業(yè)大模型炸場,超炫AI能力全能輸出

新智元報道
新智元報道
【新智元導(dǎo)讀】現(xiàn)在,國內(nèi)各家大廠竟不約而同地走上了在各行各業(yè)應(yīng)用的路線,看來,行業(yè)大模型大概率已經(jīng)成為了產(chǎn)業(yè)共識。
6月19日,騰訊云在行業(yè)大模型這個領(lǐng)域成功秀了一把,還是現(xiàn)場直懟臉的那種。
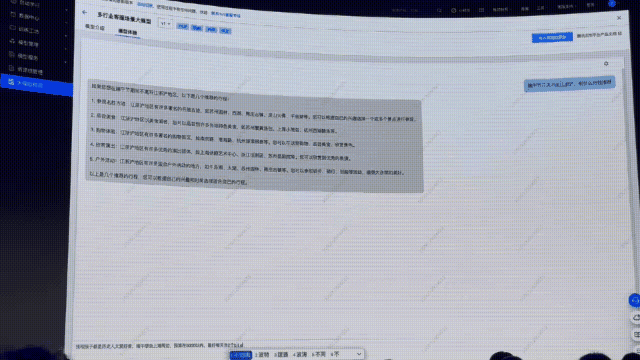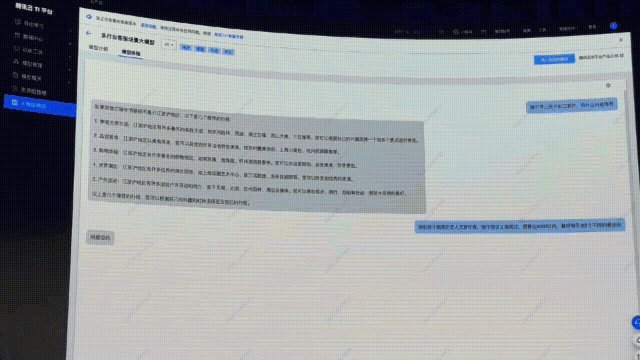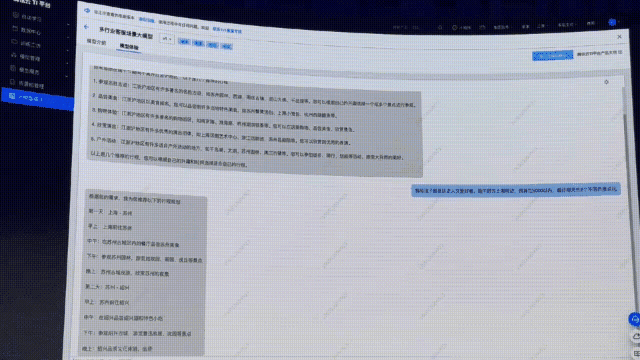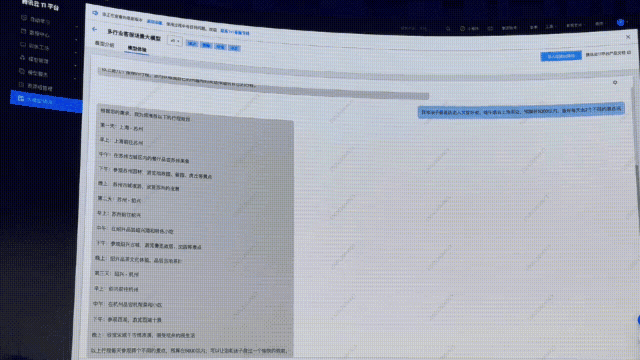
這不,端午節(jié)就要來了,不如問個實際點的:端午節(jié)三天不出江浙滬,有什么行程推薦?

先來看標準的語言大模型模型的回答。
它給出了和許多LLM同樣的「配方」,比如參觀名勝古跡、品嘗美食等簡單安排。
總之,讓人感覺好像安排了,又好像沒有安排,參考性比較弱。
如果求助用行業(yè)場景數(shù)據(jù)訓練后的大模型,效果如何?
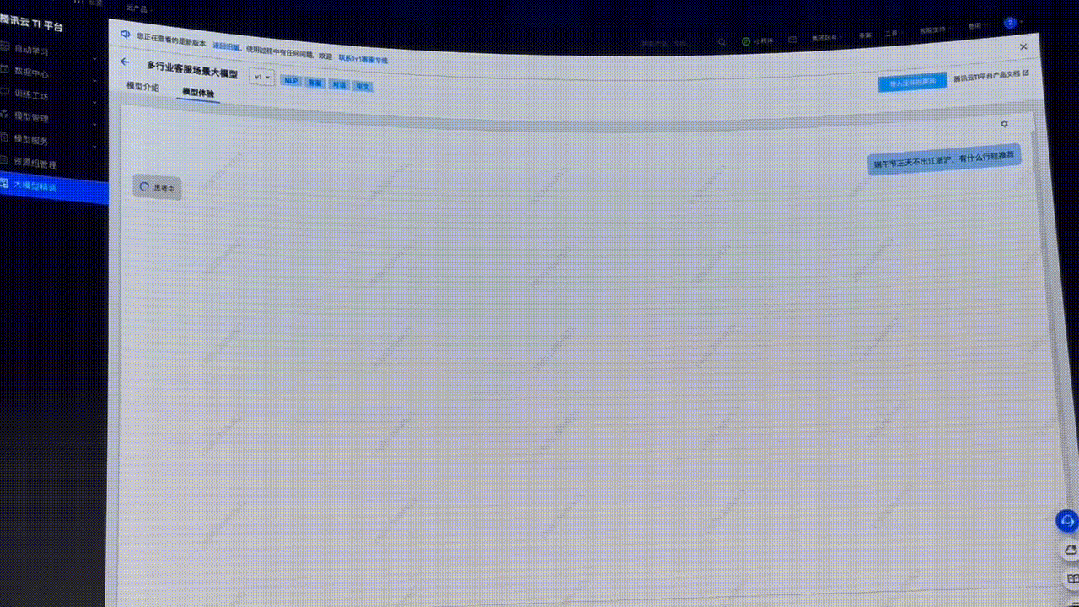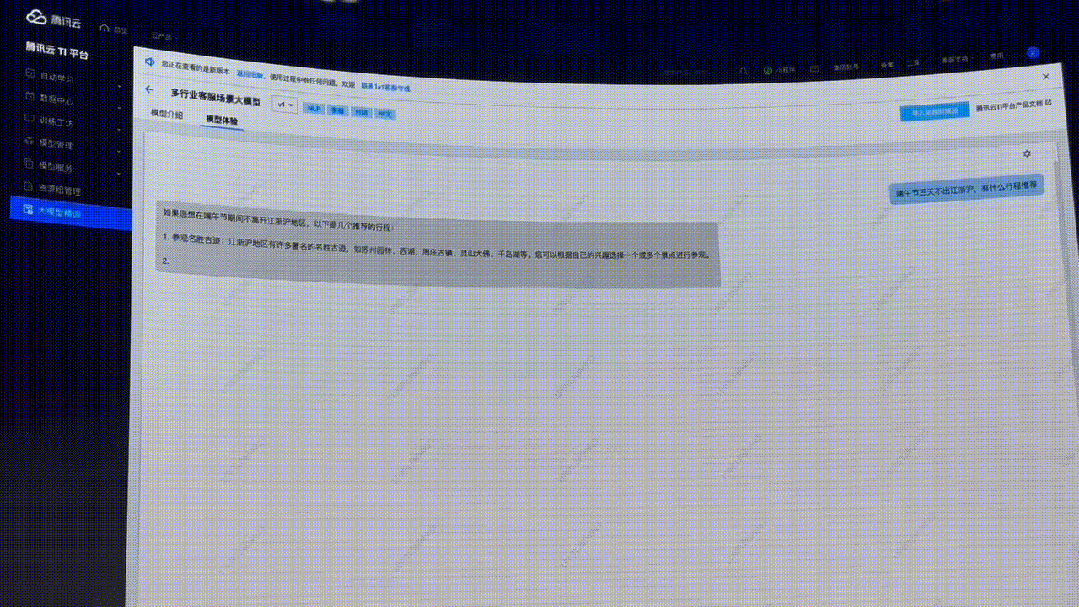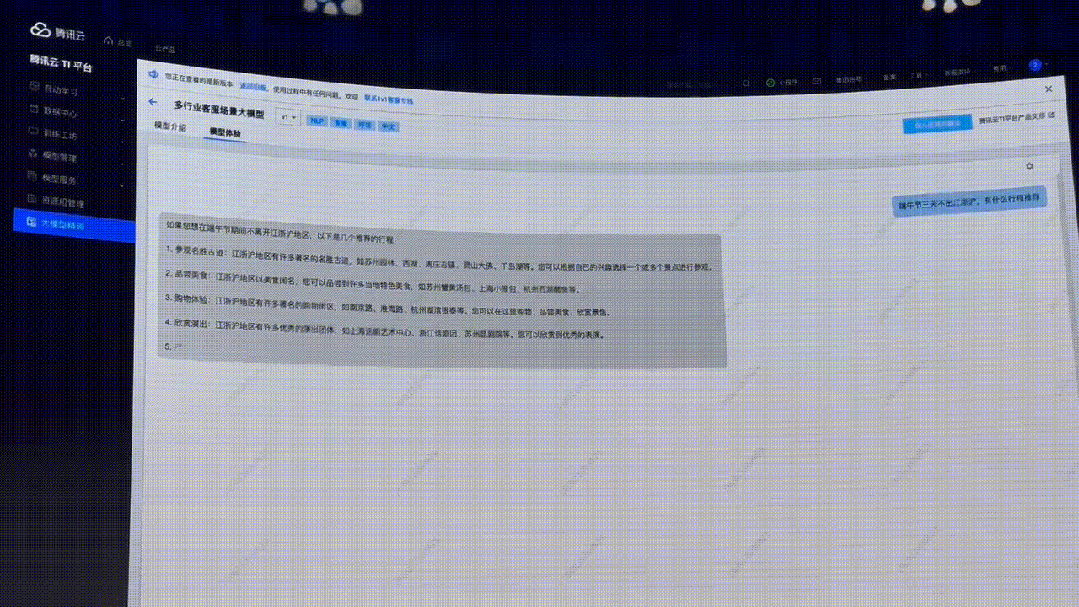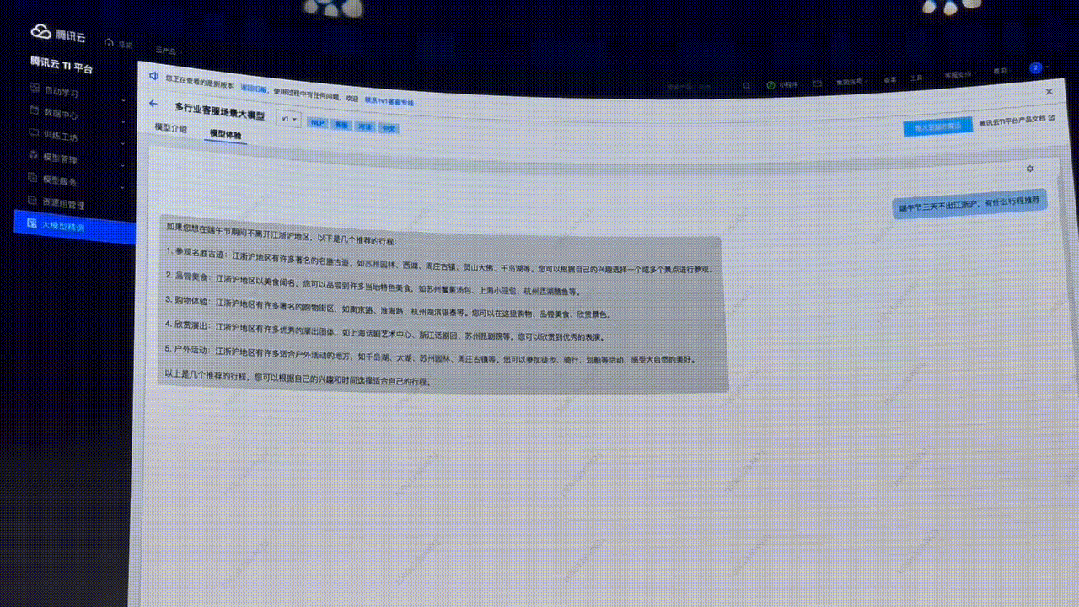
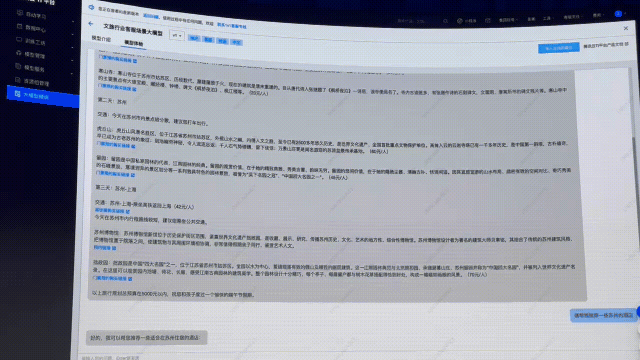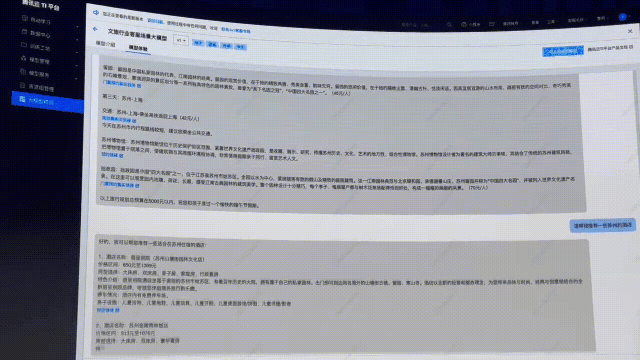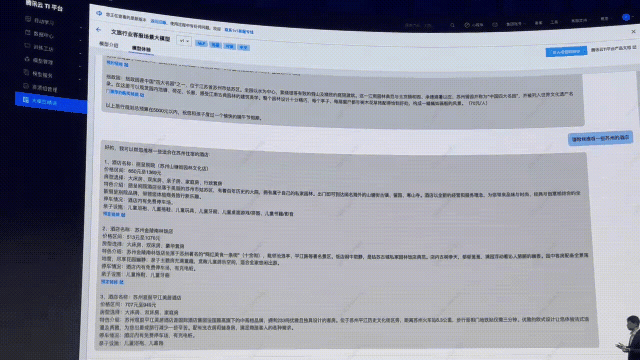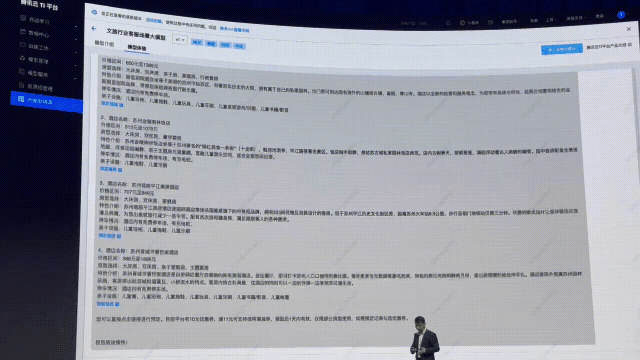
這次,順便升級一下問題復(fù)雜度:「我和孩子都是歷史人文愛好者,端午節(jié)想去上海周邊,預(yù)算5000以內(nèi),最好每天去2個景點玩。」
可以看到,模型給出了三天的行程規(guī)劃。相較之前的回復(fù),細致了很多,但實操性還是不夠強。
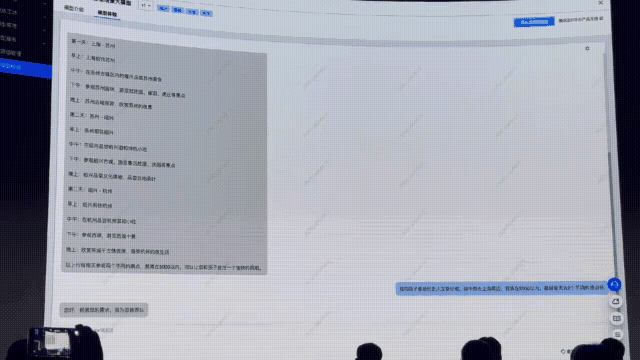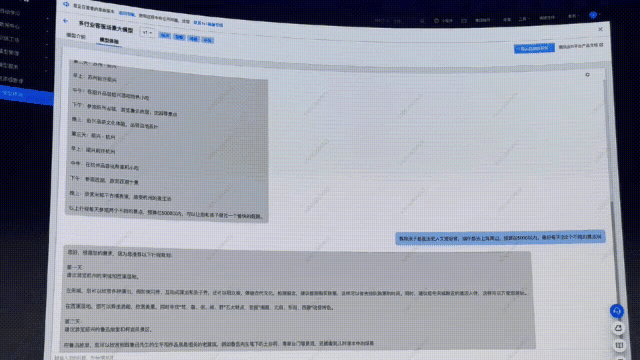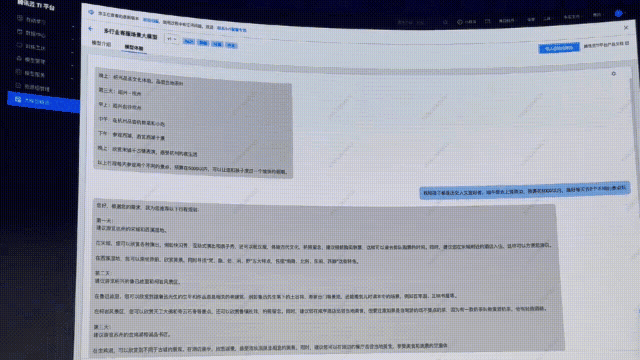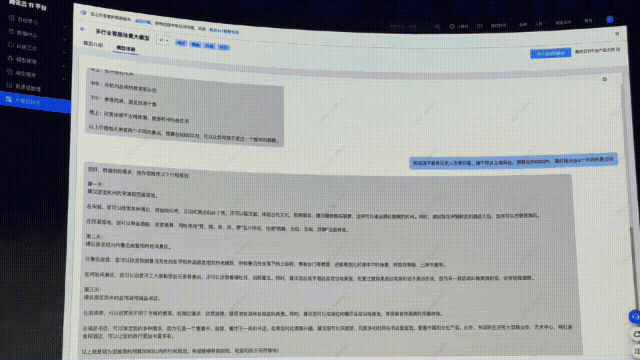
接下來,同樣的問題,再扔給接入文旅客戶API接口后的行業(yè)大模型問一遍。
顯然,這次直接提供了「保姆級三天攻略」,詳細介紹了景點的特色。
另外,還給出了每天景點的交通安排,甚至,可以實時查詢到今年的介紹信息、購票鏈接、還有價格等相關(guān)信息。
讓人看完,瞬間覺得這樣的行程不僅有意義,還省去了做出行功課的時間。
如果再讓它推薦一下蘇州的酒店,你直接得到了不同檔次的推薦和介紹,還有酒店的預(yù)定鏈接。
足見,精調(diào)后的文旅客服大模型的回答讓人拍手叫絕。
值得一提的是,這樣的模型不僅可以制訂詳細的旅行攻略,也讓智能客服系統(tǒng),實現(xiàn)服務(wù)商業(yè)化的閉環(huán)。
未來,隨著更高質(zhì)量數(shù)據(jù)增加,模型的精調(diào)效果還會更好。
行業(yè)大模型已成共識
在這場ChatGPT引爆AI大模型的熱潮中,企業(yè)雖然期待能夠得到大模型能力的加持,但通用大模型在解決他們問題時多多少少遇到一些局限性。
首先,安全方面。
由于很多企業(yè)的業(yè)務(wù)數(shù)據(jù)等都是非常隱私的核心數(shù)據(jù),他們根本不會將其放在數(shù)據(jù)集上進行公開訓練。
然而,訓練模型的專業(yè)、且高質(zhì)量的數(shù)據(jù)收集是非常難的。
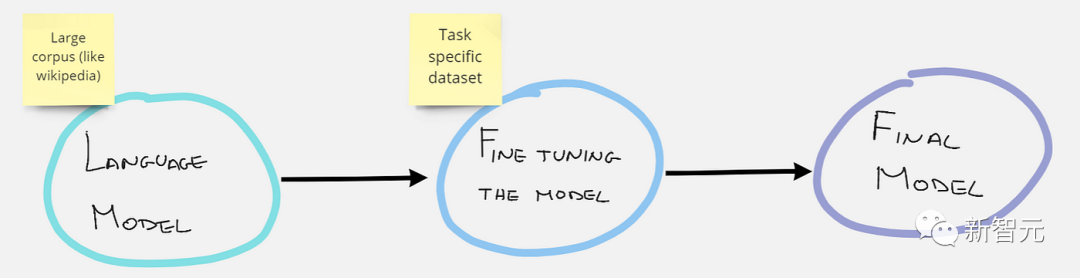
其次,經(jīng)濟方面。
很多企業(yè)和機構(gòu)在構(gòu)建大模型上,算力需求還是極大的。但是并非每家企業(yè)都有足夠的資源,讓大模型完成訓練和推理。
英偉達曾公布數(shù)據(jù)顯示,訓練一次大模型,大約100多萬美金。

再加上,如果遇到服務(wù)器過熱宕機,整個GPU集群都要停止工作,訓練任務(wù)也要重新開始。
這對云服務(wù)運維能力與排查問題能力的要求非常高,所以很多算法團隊都選擇最專業(yè)的云服務(wù)廠商來支持。
這些都需要高成本的投入,但許多企業(yè)級用戶是無法做到的。
最后,效率方面。
對于通用大模型來說,數(shù)據(jù)質(zhì)量非常重要。
大模型需要大量的高質(zhì)量數(shù)據(jù)進行訓練和優(yōu)化。必須經(jīng)過清洗和預(yù)處理,來消除噪聲、填補缺失值并確保數(shù)據(jù)質(zhì)量。
否則,訓練出的模型效果、效率都無法得到保障。
除此之外,在很多產(chǎn)業(yè)場景中,用戶對企業(yè)提供的專業(yè)服務(wù)要求高,容錯性低。企業(yè)一旦提供了錯誤信息,可能引起巨大的法律責任或公關(guān)危機。
因此,企業(yè)使用的大模型必須可控、可追溯、可溯源,而且必須反復(fù)、充分測試才能上線。
以上種種難題,怎么破?答案就是行業(yè)大模型。
稍加觀察就會發(fā)現(xiàn),現(xiàn)在國內(nèi)很多家大模型,都在往產(chǎn)業(yè)領(lǐng)域和具體的業(yè)務(wù)場景上走。
不止騰訊云,回看國內(nèi)各大廠,包括阿里云、百度云、京東云在內(nèi)都在加速大模型在各行各業(yè)的應(yīng)用。
可以看到,行業(yè)大模型大概率已經(jīng)成為了產(chǎn)業(yè)共識。因為聚焦到具體應(yīng)用場景中,行業(yè)大模型更符合垂類場景的需求。

當然,在此之前,騰訊云早已在自家平臺上做了深度的探索。
作為國內(nèi)開發(fā)者最常用的輔助工具,GitHub Copilot讓大家充分感受到了智能的力量。代碼自動補全的功能,代表著巨大飛躍的來臨。
而騰訊云的新一代AI代碼助手,也實現(xiàn)了GitHub Copilot的類似功能。多種編程語言、主流開發(fā)框架、常用IDE等,AI代碼助手都支持。
舉個例子,比如有段代碼不會寫,AI代碼助手就可以根據(jù)代碼類型、代碼上下文等信息,自動進行代碼補全。不僅如此,它還能根據(jù)代碼反向生成注釋和單元測試代碼,甚至更進一步地幫你debug。
MaaS一站式解決方案
現(xiàn)在,騰訊云基于自己的應(yīng)用積累,以及行業(yè)上的實際需求,重磅推出了全新的MaaS(Model-as-a-Service)一站式服務(wù),大幅降低了大模型的應(yīng)用門檻。
目前,騰訊云已經(jīng)聯(lián)合頭部企業(yè),為諸如金融、傳媒、文旅、政務(wù)、教育等10大行業(yè),輸出了超過50個解決方案。

具體來說,騰訊云MaaS可以覆蓋行業(yè)大模型生命周期的整個流程——「模型選型-訓練共建-部署應(yīng)用」,同時支持MLOps體系及相關(guān)工具。
在配套服務(wù)方面,騰訊云提供本地化的訓練、落地及陪跑優(yōu)化服務(wù),并可以針對用戶的需求,提供私有化部署、公有云托管、混合云部署等靈活部署方案。
其中,企業(yè)可以利用自己的場景數(shù)據(jù),定制專屬的精調(diào)大模型。或者,也可以根據(jù)自身的需求,開展多模型訓練任務(wù)。
舉個例子,在某商業(yè)銀行的日常業(yè)務(wù)中,就時常遇到這樣的難題。
客戶業(yè)務(wù)中涉及到大量銀行回單、交易發(fā)票、跨境匯款申請書、業(yè)務(wù)往來郵件、傳真等數(shù)據(jù),需要整理、錄入系統(tǒng)。
如果純依賴人工,就會面臨耗時長、效率低、成本高、易出錯的難題。

即使是采用傳統(tǒng)的OCR深度學習模型,也需要經(jīng)過「檢測→識別→結(jié)構(gòu)化」等多個階段,這個流程一走完,經(jīng)過各個階段的錯誤累積,檢測識別的難點往往難以突破。
并且,模型也不具備閱讀理解和推理能力、指標上限低,在不同場景下,模型的能力更是無法復(fù)制、定制成本極高。
而騰訊云TI-OCR大模型卻充分解決了以上痛點。
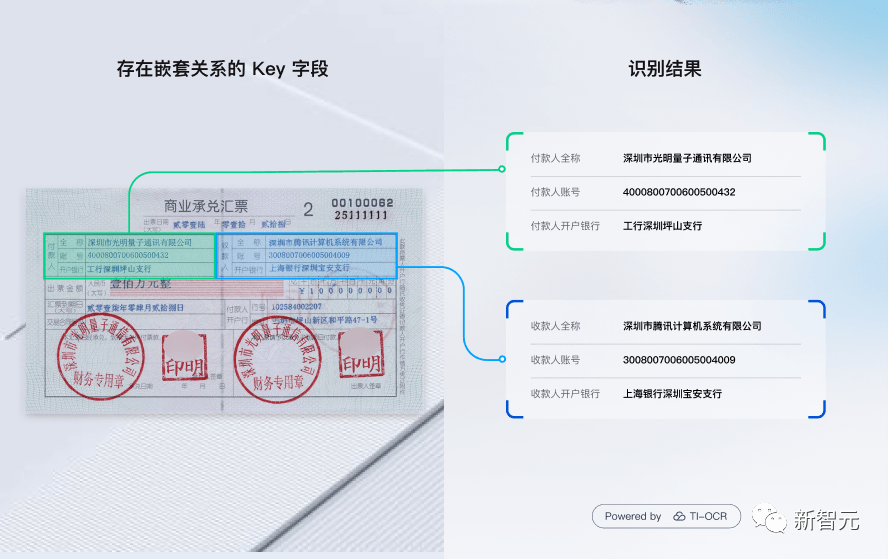
首先,它是基于原生大模型,不經(jīng)過訓練,就可以直接支持常規(guī)下游任務(wù),零樣本學習泛化召回率可達93%。
其次,通過prompt設(shè)計,模型不經(jīng)過訓練,就可支持復(fù)雜的下游任務(wù),小樣本學習泛化召回率可達95%。
另外,通過多模態(tài)技術(shù),模型可以通過小樣本精調(diào)解決傳統(tǒng)OCR難題,比傳統(tǒng)模型召回率提高了3%-20%。
最終,在在智能OCR應(yīng)用方面,騰訊云針對交易回單、交易發(fā)票、業(yè)務(wù)往來郵件等多種格式的數(shù)據(jù),實現(xiàn)了95%以上準確率的文件智能識別和關(guān)鍵詞提取。極大地減少低價值高耗時手工作業(yè),節(jié)省運營人力成本。
那么,這樣「預(yù)制菜」式的大模型精調(diào),是怎么實現(xiàn)的呢?
堅實的技術(shù)積累
為了幫助用戶實現(xiàn)一站式的大模型精調(diào),騰訊云也給TI平臺來了個全面升級,提供包括數(shù)據(jù)標注、訓練、評估、測試和部署等全套工具鏈。
升級之后的TI平臺,能夠更好地完成「業(yè)務(wù)分析-數(shù)據(jù)分析-數(shù)據(jù)清洗-數(shù)據(jù)標注-大模型選擇-訓練加速-模型評測-應(yīng)用落地」這一全套的行業(yè)大模型落地流程。

人人皆知,算力、數(shù)據(jù)、算法是AI的三要素,大模型時代也是如此。

大模型訓練,算力是基礎(chǔ)。
就算力來講,可以說,騰訊云把配置全給拉滿了。
早在今年4月,騰訊云便發(fā)布了面向大模型訓練的最新一代HCC(High-Performance Computing Cluster)高性能計算集群。
采用最新一代騰訊云星星海自研服務(wù)器,結(jié)合多層加速的高性能存儲系統(tǒng),能夠提供3.2Tbps業(yè)界最高互聯(lián)帶寬,算力性能提升3倍。
具體來說,集群的單GPU卡能夠在不同精度下,輸出最高1979 TFlops的算力。
而在大模型場景下,集群利用并行計算理念,通過CPU和GPU節(jié)點的一體化設(shè)計,能夠?qū)吸c算力性能提升至更高。
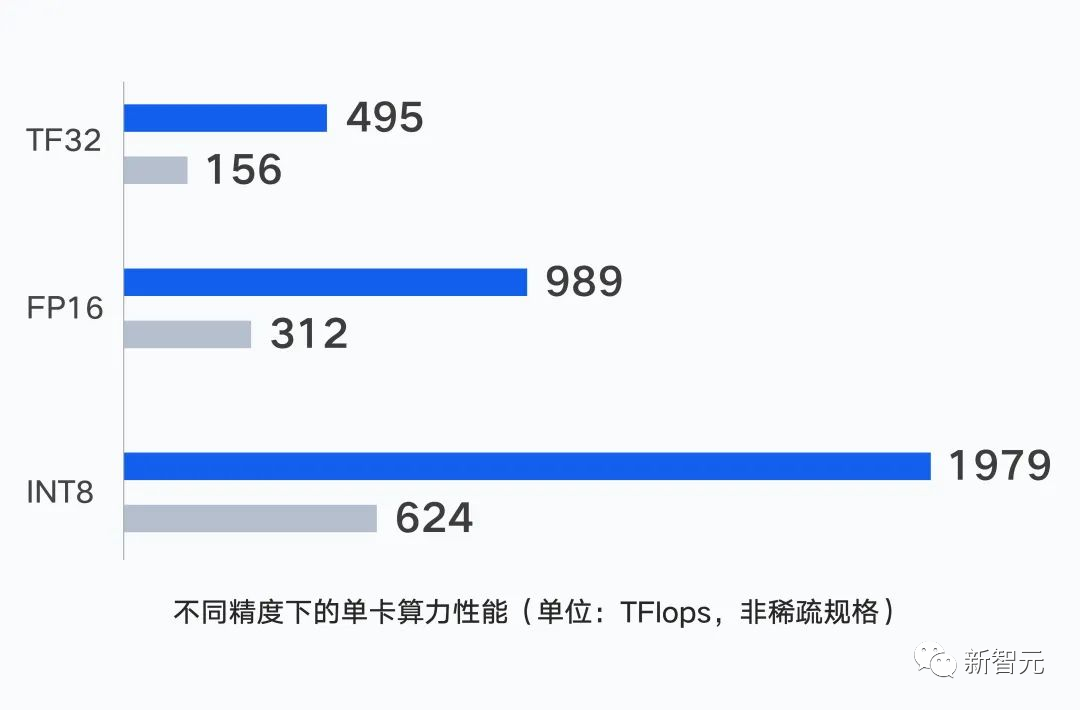
除了單點的運算能力外,集群中不同計算節(jié)點之間的通信性能也會直接影響訓練效率。
為此,騰訊云自研了具備業(yè)界最高3.2T RDMA通信帶寬的星脈高性能計算網(wǎng)絡(luò),能夠更好地滿足節(jié)點間海量的數(shù)據(jù)交互需求。
實測結(jié)果顯示,相較于此前的1.6T網(wǎng)絡(luò),在GPU數(shù)量不變的情況下,3.2T星脈網(wǎng)絡(luò)能夠給集群帶來20%的算力提升。

其次,大模型的訓練數(shù)據(jù)至關(guān)重要,經(jīng)常會遇到數(shù)據(jù)清洗、標注、分析等問題。
而在前期的數(shù)據(jù)處理階段,TI-DataTruth數(shù)據(jù)標注平臺能提供智能數(shù)據(jù)生產(chǎn)服務(wù)支持,包括數(shù)據(jù)標注作業(yè)、數(shù)據(jù)眾包管理、場景數(shù)據(jù)挖掘等。
在接下來的模型訓練上,TI-ONE一站式機器學習平臺內(nèi)置了多種訓練方式和算法框架,可以滿足不同AI應(yīng)用場景的需求,并支持從數(shù)據(jù)接入、模型訓練、模型管理到模型服務(wù)的全流程開發(fā)。

ChatGPT還沒聯(lián)網(wǎng)之前,訓練數(shù)據(jù)只截止到2021年9月,而對訓練截止之日之后發(fā)生的事情一無所知。而向量數(shù)據(jù)庫通過存儲最新信息,讓大模型能夠訪問,來彌補這個不足點。
向量是AI理解世界的數(shù)據(jù)形式,由此向量數(shù)據(jù)庫之于大模型的價值就是「記憶體」,能夠給LLM提供與加強記憶。可以說,向量數(shù)據(jù)庫是大模型時代「儲存新基座」。
就在今年3月,老黃在GTC大會上還首次提及了將要推出的RAFT向量數(shù)據(jù)庫。
基于這一需求,騰訊自研的大模型向量數(shù)據(jù)庫(Tecent Cloud Vector DB),不僅具備高吞吐、低延遲、低成本、高可用、彈性擴展等特點,而且還能進行實時更新,并大幅提升大模型閱讀理解的長度,從2千字到8千字。

為了提升模型的訓練推理效率,降低用戶成本,騰訊云在去年推出了TI-ACC加速工具。
TI-ACC底層使用TNN作為框架,訓練加速實現(xiàn)了數(shù)據(jù)IO優(yōu)化、計算加速、通信加速、并行訓練、顯存優(yōu)化等能力,兼容原生PyTorch、TensorFlow框架和DDP、PS工具。
而TI-ACC推理加速則可以實現(xiàn)計算優(yōu)化、低精度加速、內(nèi)存優(yōu)化等能力,能力通過統(tǒng)一的加速庫和優(yōu)化函數(shù)的形式提供,同樣兼容原生PyTorch等框架,無需進行模型轉(zhuǎn)換。
這次,騰訊云更進一步地將TI-ACC升級為「太極Angel」,從而提供更優(yōu)和更完整的大模型訓練和推理加速能力。
在傳統(tǒng)CV、NLP算法模型的基礎(chǔ)上,太極Angel新增了對大模型的訓練和推理加速能力,通過異步調(diào)度優(yōu)化、顯存優(yōu)化、計算優(yōu)化等方式,相比行業(yè)常用方案性能提升30%+。
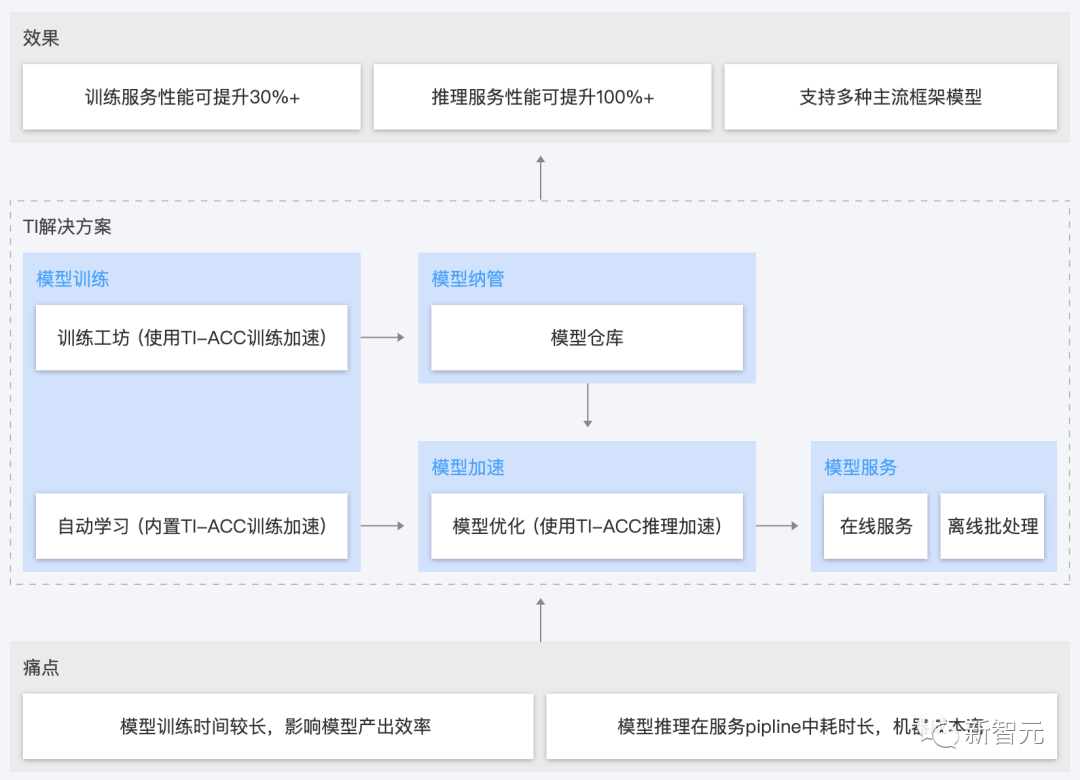
在模型的應(yīng)用和部署上,TI-Matrix應(yīng)用平臺支持快速接入各種數(shù)據(jù)、算法和智能設(shè)備。用戶則可以借助可視化編排工具,進行模型服務(wù)和資源的管理及調(diào)度。
最后,對于行業(yè)大模型尤為重要的安全、合規(guī)方面,騰訊云也有成熟的技術(shù)積累和經(jīng)驗。
通過在問題側(cè)、模型側(cè)和答案側(cè)同時進行敏感信息的過濾和規(guī)避,可以讓輸出的答案符合安全、規(guī)范的要求,并確保大模型可信、可靠、可用。
模型應(yīng)用,產(chǎn)業(yè)先行
大模型方興未艾,為什么大家都在走向大模型通往產(chǎn)業(yè)領(lǐng)域的路徑?這是否意味著通用大模型失去了價值?
其實不然。我們見證了,GPT-4、PaLM等巨量參數(shù)的通用大模型,涌現(xiàn)出「舉一反三」的強大泛化能力。
它們都是利用大算力,在大規(guī)模無標注數(shù)據(jù)集中進行訓練,相當于完成了「通識教育」。
最直接的證明是,OpenAI把通用大模型的訓練結(jié)果——ChatGPT帶到所有人面前,讓發(fā)展大半個世紀的AI真正步入提升人類生產(chǎn)力的新紀元。
可見,通用大模型是邁向通用人工智能里程碑的重要一步,其價值不可估量。
對于通用大模型來講,生態(tài)最為重要,可以讓眾多企業(yè)接入大模型底座去賦能千行百業(yè)。
同時,我們也要看到,通用大模型并非萬能,在更加深入的一個專業(yè)領(lǐng)域中,其know-how是遠遠無法滿足的。
再加上大模型經(jīng)常會出現(xiàn)「胡說八道」,對于至關(guān)重要的場景,比如律師行業(yè),將帶來更大的風險。
然而,現(xiàn)有大模型的算力和能耗的挑戰(zhàn),再加上行業(yè)不同,需求不同,垂直領(lǐng)域大模型的到來注定是必然的。
因為,專業(yè)領(lǐng)域大模型在金融、文旅、傳媒、政務(wù)、教育等多個產(chǎn)業(yè)場景中具有廣泛應(yīng)用和商業(yè)創(chuàng)新價值。
比如,今年3月,彭博社發(fā)布了為金融界打造的500億大模型BloombergGPT。
這一模型依托彭博社大量金融數(shù)據(jù)源,在金融任務(wù)上的表現(xiàn)超過任一模型。甚至,在通用場景中,也能與現(xiàn)有模型一較高下。
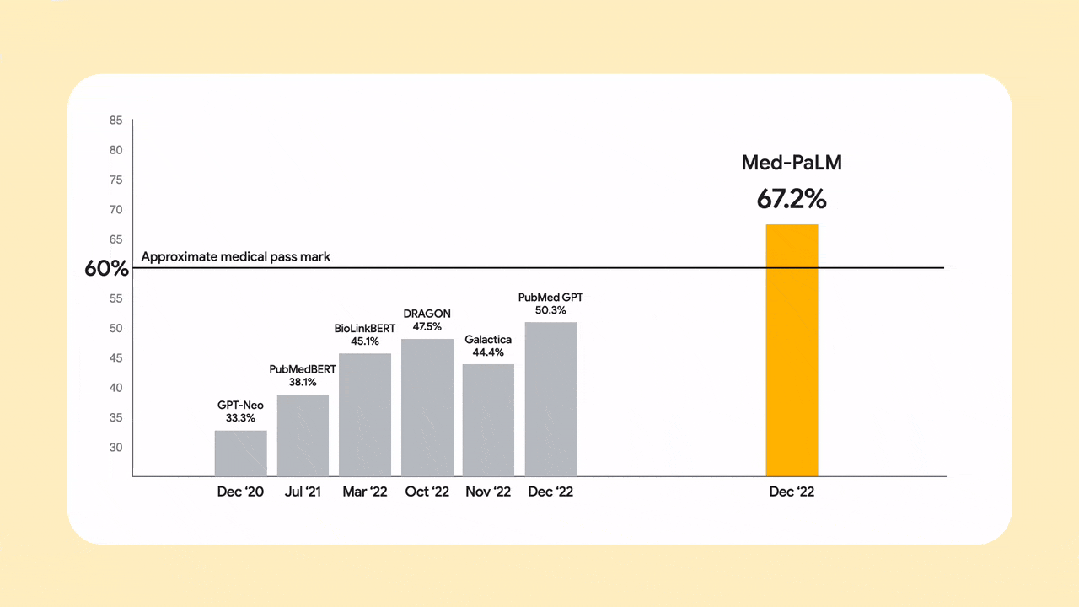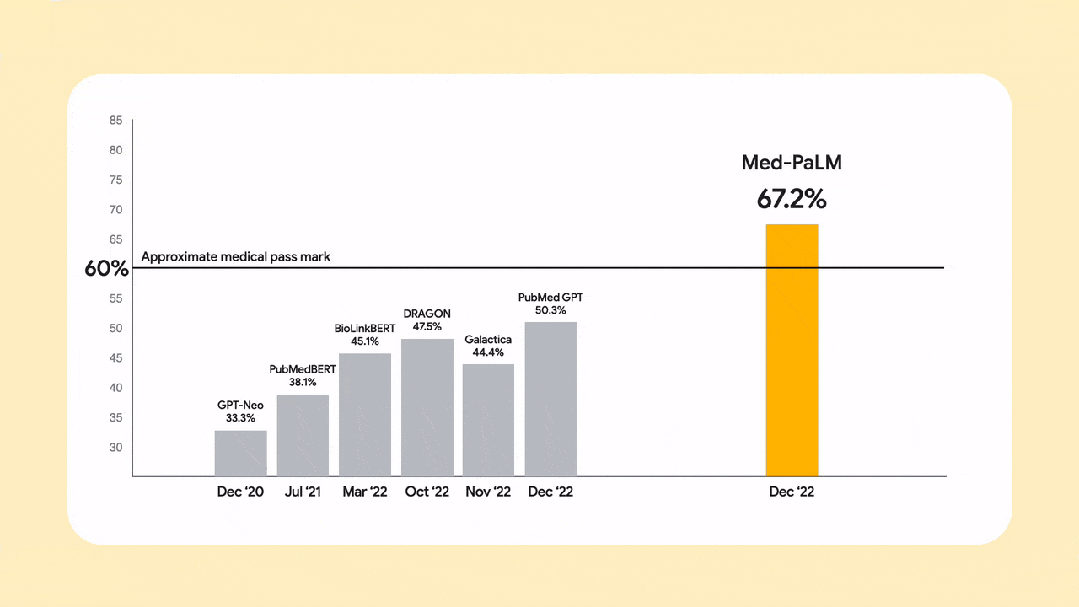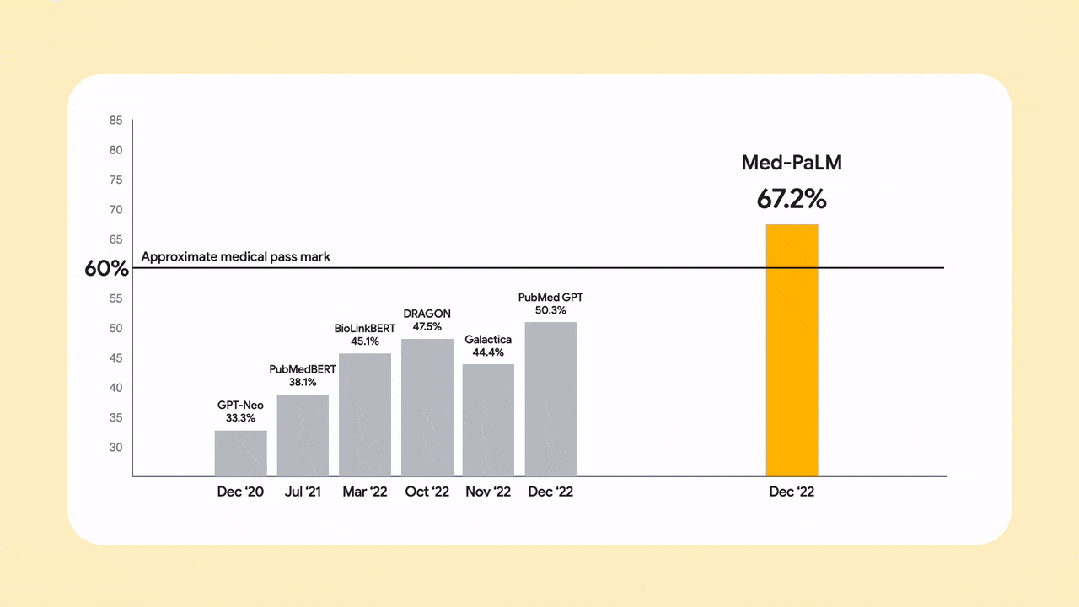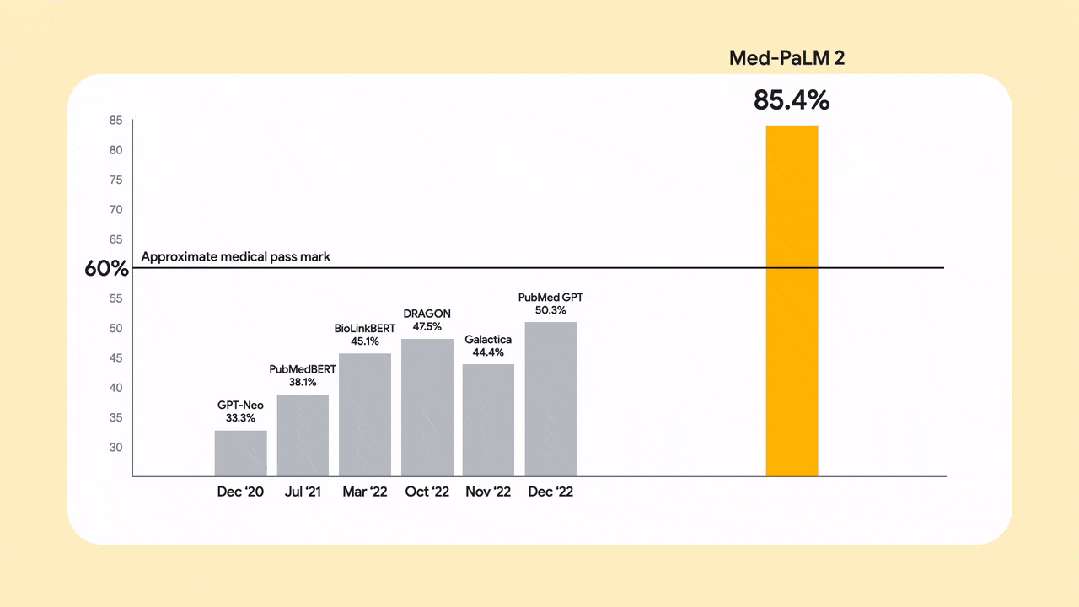
還有谷歌推出的醫(yī)療領(lǐng)域大模型Med-PALM2,在醫(yī)學考試問答上超過了許多專家的水平。
要知道,只有真正創(chuàng)造價值的技術(shù)才能可持續(xù)、高質(zhì)量地發(fā)展。
目前,國內(nèi)布局大模型領(lǐng)域的大廠,正在不斷夯實通用大模型,打造產(chǎn)業(yè)大模型,進而助力AI產(chǎn)業(yè)大模型的發(fā)展。
「通用大模型+產(chǎn)業(yè)大模」兩條腿走路,并駕齊驅(qū),可能更適合目前我國發(fā)展的情況。
甚至,國家也在營造人工智能大模型產(chǎn)業(yè)生態(tài)中給予大力支持。
比如「北京市通用人工智能產(chǎn)業(yè)創(chuàng)新伙伴計劃」的啟動,就是要推動大模型賦能千行百業(yè)數(shù)智化轉(zhuǎn)型。
要看到的是,垂直大模型是一種全新的生產(chǎn)力。
以GPT-4為代表的認知大模型在多個任務(wù)上實現(xiàn)了驚艷的表現(xiàn),同時也帶動了相關(guān)產(chǎn)業(yè)創(chuàng)新應(yīng)用也在不斷涌現(xiàn)。
這次技術(shù)峰會,騰訊云進一步釋放行業(yè)大模型的服務(wù)能力。從側(cè)面也看出,目前企業(yè)對大模型實際落地需求也是非常迫切的。
從真實客戶需求場景出發(fā),騰訊云獨到的「量體裁衣、普惠適用」的行業(yè)模型解決方案,讓大家做屬于自己的行業(yè)模型,實現(xiàn)提質(zhì)增效。

騰訊集團高級執(zhí)行副總裁、云與智慧產(chǎn)業(yè)事業(yè)群CEO湯道生表示,
大模型只是開端,AI與產(chǎn)業(yè)的融合,將綻放出更有創(chuàng)造力的未來。生態(tài)共建是AI發(fā)展的有效路徑,騰訊將堅持生態(tài)開放,為企業(yè)提供高質(zhì)量模型服務(wù),同時支持客戶多模型訓練任務(wù),加速大模型在產(chǎn)業(yè)場景的創(chuàng)新探索。
在這個AI2.0時代,若想成為掌握下一個十年的核心競爭力的先行者,還需模型應(yīng)用,產(chǎn)業(yè)先行。
騰訊云在做的,讓行業(yè)大模型落地更實在。

