
這篇 MySQL 索引和 B+Tree 講的太通俗易懂!
來源:程序員Bug哥
正確的創(chuàng)建合適的索引,是提升數(shù)據(jù)庫查詢性能的基礎(chǔ)。在正式講解之前,對后面舉例中使用的表結(jié)構(gòu)先簡單看一下:
create?table?user
(
????id?????bigint??not?null?comment?'id'?primary?key,
????name???varchar(200)?null?comment?'name',
????age????bigint???????null?comment?'age',
????gender?int??????????null?comment?'gender',
????key?(name)
);
索引是什么及工作機(jī)制?
索引是為了加速對表中數(shù)據(jù)行的檢索而創(chuàng)建的一種分散存儲的數(shù)據(jù)結(jié)構(gòu)。其工作機(jī)制如下圖:
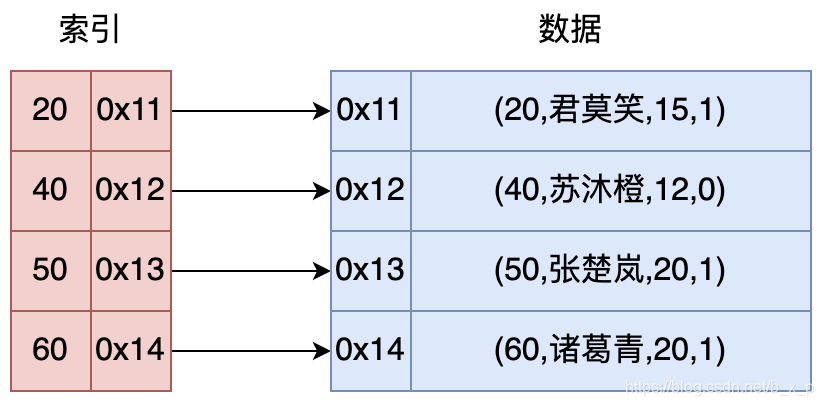
上圖中,如果現(xiàn)在有一條sql語句 select * from user where id = 40,如果沒有索引的條件下,我們要找到這條記錄,我們就需要在數(shù)據(jù)中進(jìn)行全表掃描,匹配id = 13的數(shù)據(jù)。
如果有了索引,我們就可以通過索引進(jìn)行快速查找,如上圖中,可以先在索引中通過id = 40進(jìn)行二分查找,再根據(jù)定位到的地址取出對應(yīng)的行數(shù)據(jù)。
MySQL數(shù)據(jù)庫為什么要使用B+TREE作為索引的數(shù)據(jù)結(jié)構(gòu)?
二叉樹為什么不可行
對數(shù)據(jù)的加速檢索,首先想到的就是二叉樹,二叉樹的查找時(shí)間復(fù)雜度可以達(dá)到O(log2(n))。下面看一下二叉樹的存儲結(jié)構(gòu):
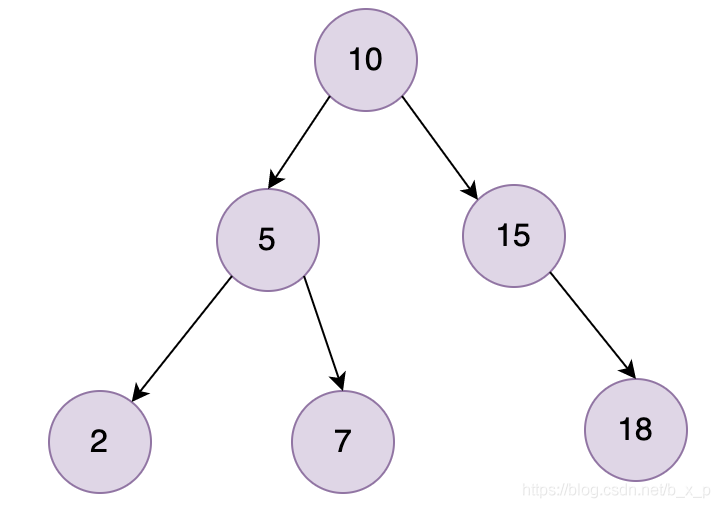
二叉樹搜索相當(dāng)于一個(gè)二分查找。二叉查找能大大提升查詢的效率,但是它有一個(gè)問題:二叉樹以第一個(gè)插入的數(shù)據(jù)作為根節(jié)點(diǎn),如上圖中,如果只看右側(cè),就會發(fā)現(xiàn),就是一個(gè)線性鏈表結(jié)構(gòu)。如果我們現(xiàn)在的數(shù)據(jù)只包含1, 2, 3, 4,就會出現(xiàn)
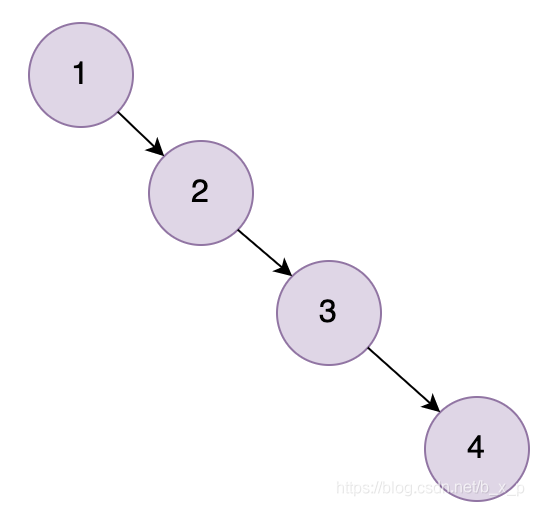
以下情況:
如果我們要查詢的數(shù)據(jù)為4,則需要遍歷所有的節(jié)點(diǎn)才能找到4,即,相當(dāng)于全表掃描,就是由于存在這種問題,所以二叉查找樹不適合用于作為索引的數(shù)據(jù)結(jié)構(gòu)。
平衡二叉樹為什么不可行
為了解決二叉樹存在線性鏈表的問題,會想到用平衡二叉查找樹來解決。下面看看平衡二叉樹是怎樣的:
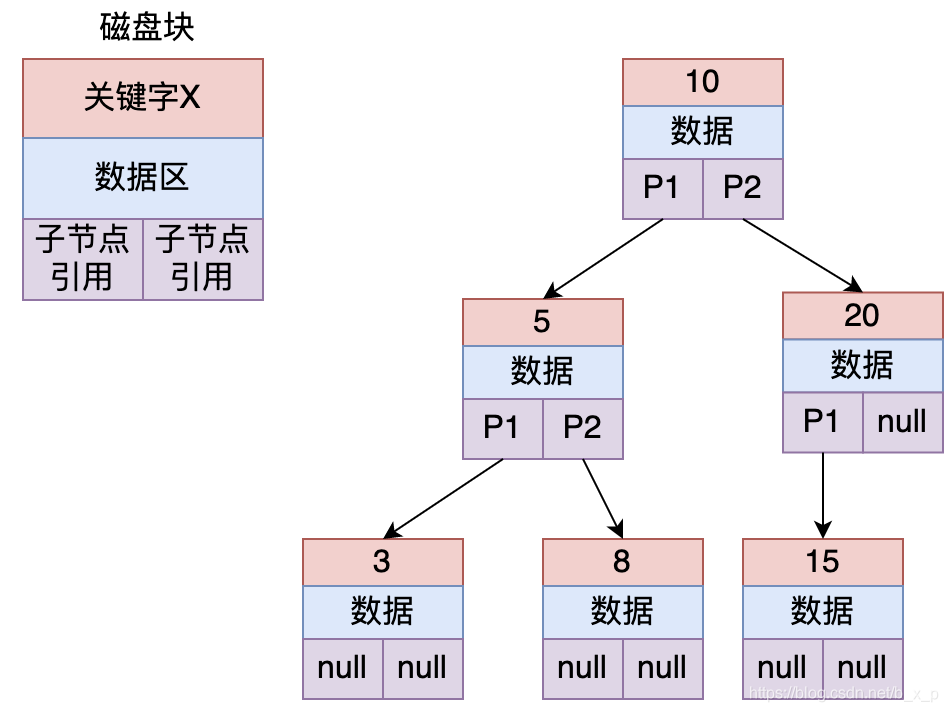
平衡二叉查找樹定義為:節(jié)點(diǎn)的子節(jié)點(diǎn)高度差不能超過1,如上圖中的節(jié)點(diǎn)20,左節(jié)點(diǎn)高度為1,右節(jié)點(diǎn)高度0,差為1,所以上圖沒有違反定義,它就是一個(gè)平衡二叉樹。保證二叉樹平衡的方式為左旋,右旋等操作,至于如何左旋右旋,可以自行去搜索相關(guān)的知識。
如果上圖中平衡二叉樹保存的是id索引,現(xiàn)在要查找id = 8的數(shù)據(jù),過程如下:
把根節(jié)點(diǎn)加載進(jìn)內(nèi)存,用8和10進(jìn)行比較,發(fā)現(xiàn)8比10小,繼續(xù)加載10的左子樹。
把5加載進(jìn)內(nèi)存,用8和5比較,同理,加載5節(jié)點(diǎn)的右子樹。
此時(shí)發(fā)現(xiàn)命中,則讀取id為8的索引對應(yīng)的數(shù)據(jù)。
索引保存數(shù)據(jù)的方式一般有兩種:
數(shù)據(jù)區(qū)保存id 對應(yīng)行數(shù)據(jù)的所有數(shù)據(jù)具體內(nèi)容。
數(shù)據(jù)區(qū)保存的是真正保存數(shù)據(jù)的磁盤地址。
到這里,平衡二叉樹解決了存在線性鏈表的問題,數(shù)據(jù)查詢的效率好像也還可以,基本能達(dá)到O(log2(n)), 那為什么mysql不選擇平衡二叉樹作為索引存儲結(jié)構(gòu),他又存在什么樣的問題呢?
搜索效率不足。一般來說,在樹結(jié)構(gòu)中,數(shù)據(jù)所處的深度,決定了搜索時(shí)的IO次數(shù)(MySql中將每個(gè)節(jié)點(diǎn)大小設(shè)置為一頁大小,一次IO讀取一頁 / 一個(gè)節(jié)點(diǎn))。如上圖中搜索id = 8的數(shù)據(jù),需要進(jìn)行3次IO。當(dāng)數(shù)據(jù)量到達(dá)幾百萬的時(shí)候,樹的高度就會很恐怖。
查詢不不穩(wěn)定。如果查詢的數(shù)據(jù)落在根節(jié)點(diǎn),只需要一次IO,如果是葉子節(jié)點(diǎn)或者是支節(jié)點(diǎn),會需要多次IO才可以。
存儲的數(shù)據(jù)內(nèi)容太少。沒有很好利用操作系統(tǒng)和磁盤數(shù)據(jù)交換特性,也沒有利用好磁盤IO的預(yù)讀能力。因?yàn)椴僮飨到y(tǒng)和磁盤之間一次數(shù)據(jù)交換是以頁為單位的,一頁大小為 4K,即每次IO操作系統(tǒng)會將4K數(shù)據(jù)加載進(jìn)內(nèi)存。但是,在二叉樹每個(gè)節(jié)點(diǎn)的結(jié)構(gòu)只保存一個(gè)關(guān)鍵字,一個(gè)數(shù)據(jù)區(qū),兩個(gè)子節(jié)點(diǎn)的引用,并不能夠填滿4K的內(nèi)容。幸幸苦苦做了一次的IO操作,卻只加載了一個(gè)關(guān)鍵字。在樹的高度很高,恰好又搜索的關(guān)鍵字位于葉子節(jié)點(diǎn)或者支節(jié)點(diǎn)的時(shí)候,取一個(gè)關(guān)鍵字要做很多次的IO。
那有沒有一種結(jié)構(gòu)能夠解決二叉樹的這種問題呢?有,那就是多路平衡查找樹。
多路平衡查找樹(Balance Tree)
B Tree 是一個(gè)絕對平衡樹,所有的葉子節(jié)點(diǎn)在同一高度,如下圖所示:
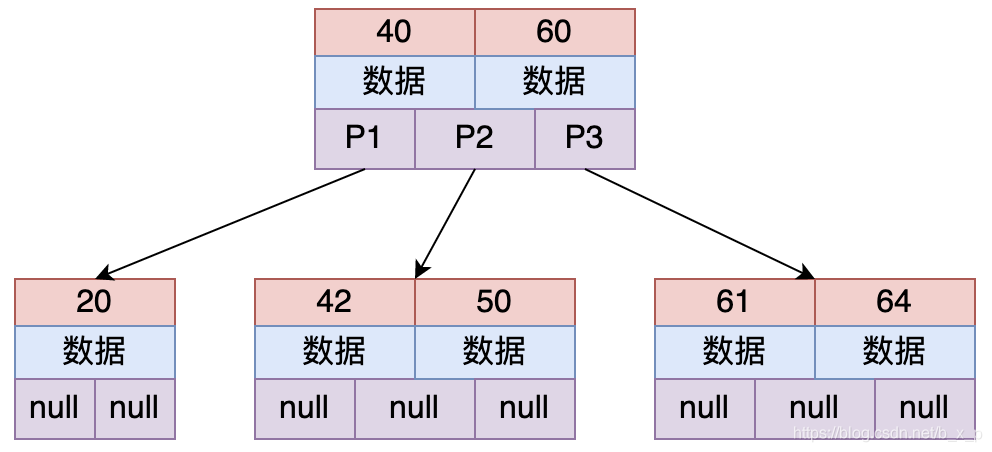
上圖為一個(gè)2-3樹(每個(gè)節(jié)點(diǎn)存儲2個(gè)關(guān)鍵字,有3路),多路平衡查找樹也就是多叉的意思,從上圖中可以看出,每個(gè)節(jié)點(diǎn)保存的關(guān)鍵字的個(gè)數(shù)和路數(shù)關(guān)系為:關(guān)鍵字個(gè)數(shù) = 路數(shù) – 1。
假設(shè)要從上圖中查找id = X的數(shù)據(jù),B TREE 搜索過程如下:
取出根磁盤塊,加載40和60兩個(gè)關(guān)鍵字。
如果X等于40,則命中;如果X小于40走P1;如果40 < X < 60走P2;如果X = 60,則命中;如果X > 60走P3。
根據(jù)以上規(guī)則命中后,接下來加載對應(yīng)的數(shù)據(jù), 數(shù)據(jù)區(qū)中存儲的是具體的數(shù)據(jù)或者是指向數(shù)據(jù)的指針。
為什么說這種結(jié)構(gòu)能夠解決平衡二叉樹存在的問題呢?
B Tree 能夠很好的利用操作系統(tǒng)和磁盤的交互特性, MySQL為了很好的利用磁盤的預(yù)讀能力,將頁大小設(shè)置為16K,即將一個(gè)節(jié)點(diǎn)(磁盤塊)的大小設(shè)置為16K,一次IO將一個(gè)節(jié)點(diǎn)(16K)內(nèi)容加載進(jìn)內(nèi)存。這里,假設(shè)關(guān)鍵字類型為 int,即4字節(jié),若每個(gè)關(guān)鍵字對應(yīng)的數(shù)據(jù)區(qū)也為4字節(jié),不考慮子節(jié)點(diǎn)引用的情況下,則上圖中的每個(gè)節(jié)點(diǎn)大約能夠存儲(16 * 1000)/ 8 = 2000個(gè)關(guān)鍵字,共2001個(gè)路數(shù)。對于二叉樹,三層高度,最多可以保存7個(gè)關(guān)鍵字,而對于這種有2001路的B樹,三層高度能夠搜索的關(guān)鍵字個(gè)數(shù)遠(yuǎn)遠(yuǎn)的大于二叉樹。
這里順便說一下:在B Tree保證樹的平衡的過程中,每次關(guān)鍵字的變化,都會導(dǎo)致結(jié)構(gòu)發(fā)生很大的變化,這個(gè)過程是特別浪費(fèi)時(shí)間的,所以創(chuàng)建索引一定要?jiǎng)?chuàng)建合適的索引,而不是把所有的字段都創(chuàng)建索引,創(chuàng)建冗余索引只會在對數(shù)據(jù)進(jìn)行新增,刪除,修改時(shí)增加性能消耗。
B樹確實(shí)已經(jīng)很好的解決了問題,我先這里先繼續(xù)看一下B+Tree結(jié)構(gòu),再來討論BTree和B+Tree的區(qū)別。
先看看B+Tree是怎樣的,B+Tree是B Tree的一個(gè)變種,在B+Tree中,B樹的路數(shù)和關(guān)鍵字的個(gè)數(shù)的關(guān)系不再成立了,數(shù)據(jù)檢索規(guī)則采用的是左閉合區(qū)間,路數(shù)和關(guān)鍵個(gè)數(shù)關(guān)系為1比1,具體如下圖所示:
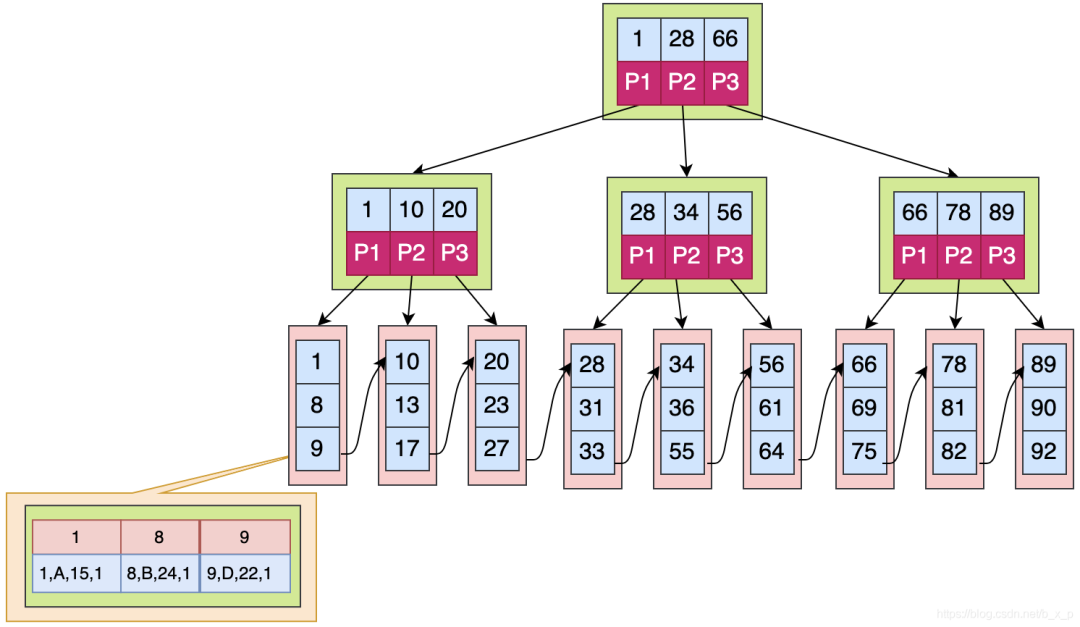
如果上圖中是用ID做的索引,如果是搜索X = 1的數(shù)據(jù),搜索規(guī)則如下:
取出根磁盤塊,加載1,28,66三個(gè)關(guān)鍵字。
X <= 1 走P1,取出磁盤塊,加載1,10,20三個(gè)關(guān)鍵字。
X <= 1 走P1,取出磁盤塊,加載1,8,9三個(gè)關(guān)鍵字。
已經(jīng)到達(dá)葉子節(jié)點(diǎn),命中1,接下來加載對應(yīng)的數(shù)據(jù),圖中數(shù)據(jù)區(qū)中存儲的是具體的數(shù)據(jù)。
B TREE和B+TREE區(qū)別是什么?
B+Tree 關(guān)鍵字的搜索采用的是左閉合區(qū)間,之所以采用左閉合區(qū)間是因?yàn)樗詈玫娜ブС肿栽鰅d,這也是mysql的設(shè)計(jì)初衷。即,如果id = 1命中,會繼續(xù)往下查找,直到找到葉子節(jié)點(diǎn)中的1。
B+Tree 根節(jié)點(diǎn)和支節(jié)點(diǎn)沒有數(shù)據(jù)區(qū),關(guān)鍵字對應(yīng)的數(shù)據(jù)只保存在葉子節(jié)點(diǎn)中。即只有葉子節(jié)點(diǎn)中的關(guān)鍵字?jǐn)?shù)據(jù)區(qū)才會保存真正的數(shù)據(jù)內(nèi)容或者是內(nèi)容的地址。而在B樹種,如果根節(jié)點(diǎn)命中,則會直接返回?cái)?shù)據(jù)。
在B+Tree中,葉子節(jié)點(diǎn)不會去保存子節(jié)點(diǎn)的引用。
B+Tree葉子節(jié)點(diǎn)是順序排列的,并且相鄰的節(jié)點(diǎn)具有順序引用的關(guān)系,如上圖中葉子節(jié)點(diǎn)之間有指針相連接。
MySQL為什么最終要去選擇B+Tree?
B+Tree是B TREE的變種,B TREE能解決的問題,B+TREE也能夠解決(降低樹的高度,增大節(jié)點(diǎn)存儲數(shù)據(jù)量)
B+Tree掃庫和掃表能力更強(qiáng)。如果我們要根據(jù)索引去進(jìn)行數(shù)據(jù)表的掃描,對B TREE進(jìn)行掃描,需要把整棵樹遍歷一遍,而B+TREE只需要遍歷他的所有葉子節(jié)點(diǎn)即可(葉子節(jié)點(diǎn)之間有引用)。
B+TREE磁盤讀寫能力更強(qiáng)。他的根節(jié)點(diǎn)和支節(jié)點(diǎn)不保存數(shù)據(jù)區(qū),所以根節(jié)點(diǎn)和支節(jié)點(diǎn)同樣大小的情況下,保存的關(guān)鍵字要比B TREE要多。而葉子節(jié)點(diǎn)不保存子節(jié)點(diǎn)引用,能用于保存更多的關(guān)鍵字和數(shù)據(jù)。所以,B+TREE讀寫一次磁盤加載的關(guān)鍵字比B TREE更多。
B+Tree排序能力更強(qiáng)。上面的圖中可以看出,B+Tree天然具有排序功能。
B+Tree查詢性能穩(wěn)定。B+Tree數(shù)據(jù)只保存在葉子節(jié)點(diǎn),每次查詢數(shù)據(jù),查詢IO次數(shù)一定是穩(wěn)定的。當(dāng)然這個(gè)每個(gè)人的理解都不同,因?yàn)樵贐 TREE如果根節(jié)點(diǎn)命中直接返回,確實(shí)效率更高。
MySQL B+Tree具體落地形式
這里主要講解的是MySQL根據(jù)B+Tree索引結(jié)構(gòu)不同的兩種存儲引擎(MYISAM 和 INNODB)的實(shí)現(xiàn)。
首先找到MySQL保存數(shù)據(jù)的文件夾,看看MySQL是如何保存數(shù)據(jù)的:
mysql>?show?variables?like?'%datadir%';
+---------------+------------------------+
|?Variable_name?|?Value??????????????????|
+---------------+------------------------+
|?datadir???????|?/usr/local/mysql/data/?|
+---------------+------------------------+
進(jìn)入到這個(gè)目錄下,這個(gè)目錄下保存的是所有數(shù)據(jù)庫,再進(jìn)入到具體的一個(gè)數(shù)據(jù)庫目錄下。就能夠看到MySQL存儲數(shù)據(jù)和索引的文件了。
這里我創(chuàng)建了兩張表,user_innod和user_myisam,分別指定索引為innodb和myisam。對于每張表,MySQL會創(chuàng)建相應(yīng)的文件保存數(shù)據(jù)和索引,具體如下:
-rw-rw----.?1?mysql?mysql??????8652?May??3?21:11?user_innodb.frm
-rw-rw----.?1?mysql?mysql?109051904?May??7?21:26?user_innodb.ibd
-rw-rw----.?1?mysql?mysql??????8682?May?16?18:27?user_myisam.frm
-rw-rw----.?1?mysql?mysql?????????0?May?16?18:27?user_myisam.MYD
-rw-rw----.?1?mysql?mysql??????1024?May?16?18:27?user_myisam.MYI
從圖中可以看出:
MYISAM存儲引擎存儲數(shù)據(jù)庫數(shù)據(jù),一共有三個(gè)文件:
Frm:表的定義文件。
MYD:數(shù)據(jù)文件,所有的數(shù)據(jù)保存在這個(gè)文件中。
MYI:索引文件。
Innodb存儲引擎存儲數(shù)據(jù)庫數(shù)據(jù),一共有兩個(gè)文件(沒有專門保存數(shù)據(jù)的文件):
Frm文件:表的定義文件。
Ibd文件:數(shù)據(jù)和索引存儲文件。數(shù)據(jù)以主鍵進(jìn)行聚集存儲,把真正的數(shù)據(jù)保存在葉子節(jié)點(diǎn)中。
MyISAM存儲引擎
說明:為了畫圖簡便,下面部分圖使用在線數(shù)據(jù)結(jié)構(gòu)工具進(jìn)行組織數(shù)據(jù),組織的B+Tree為右閉合區(qū)間,但不影響理解存儲引擎數(shù)據(jù)存儲結(jié)構(gòu)。
在MYISAM存儲引擎中,數(shù)據(jù)和索引的關(guān)系如下:
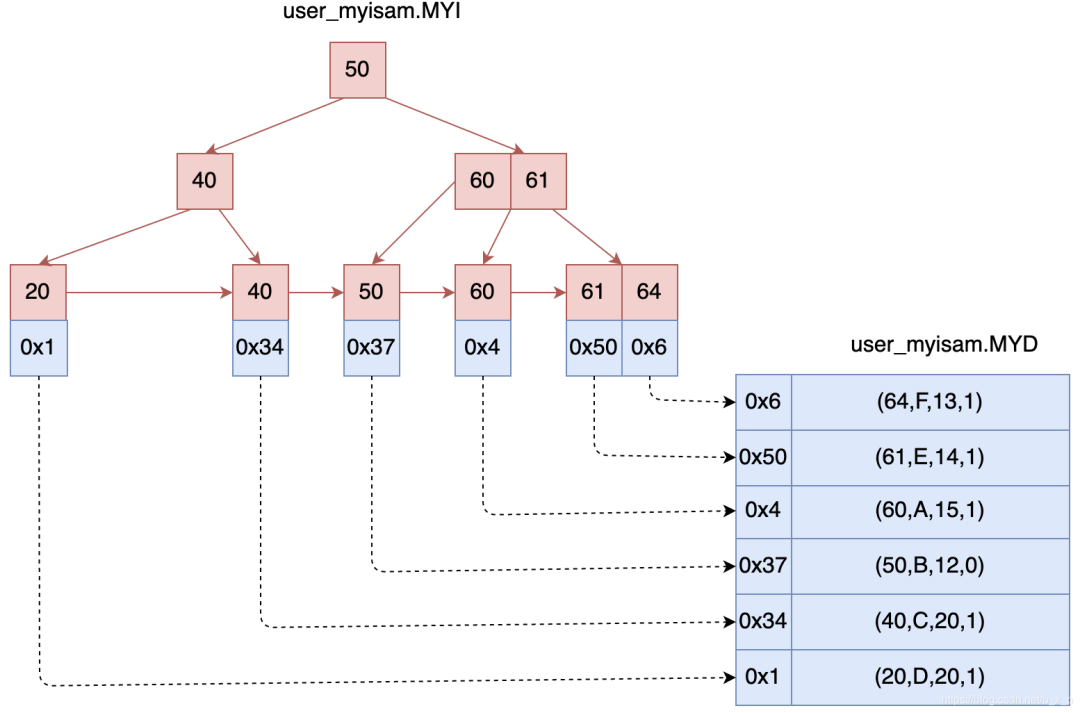
如何查找數(shù)據(jù)的呢?
如果要查詢id = 40的數(shù)據(jù):先根據(jù)MyISAM索引文件(如上圖左)去找id = 40的節(jié)點(diǎn),通過這個(gè)節(jié)點(diǎn)的數(shù)據(jù)區(qū)拿到真正保存數(shù)據(jù)的磁盤地址,再通過這個(gè)地址從MYD數(shù)據(jù)文件(如上圖右)中加載對應(yīng)的記錄。
如果有多個(gè)索引,表現(xiàn)形式如下:
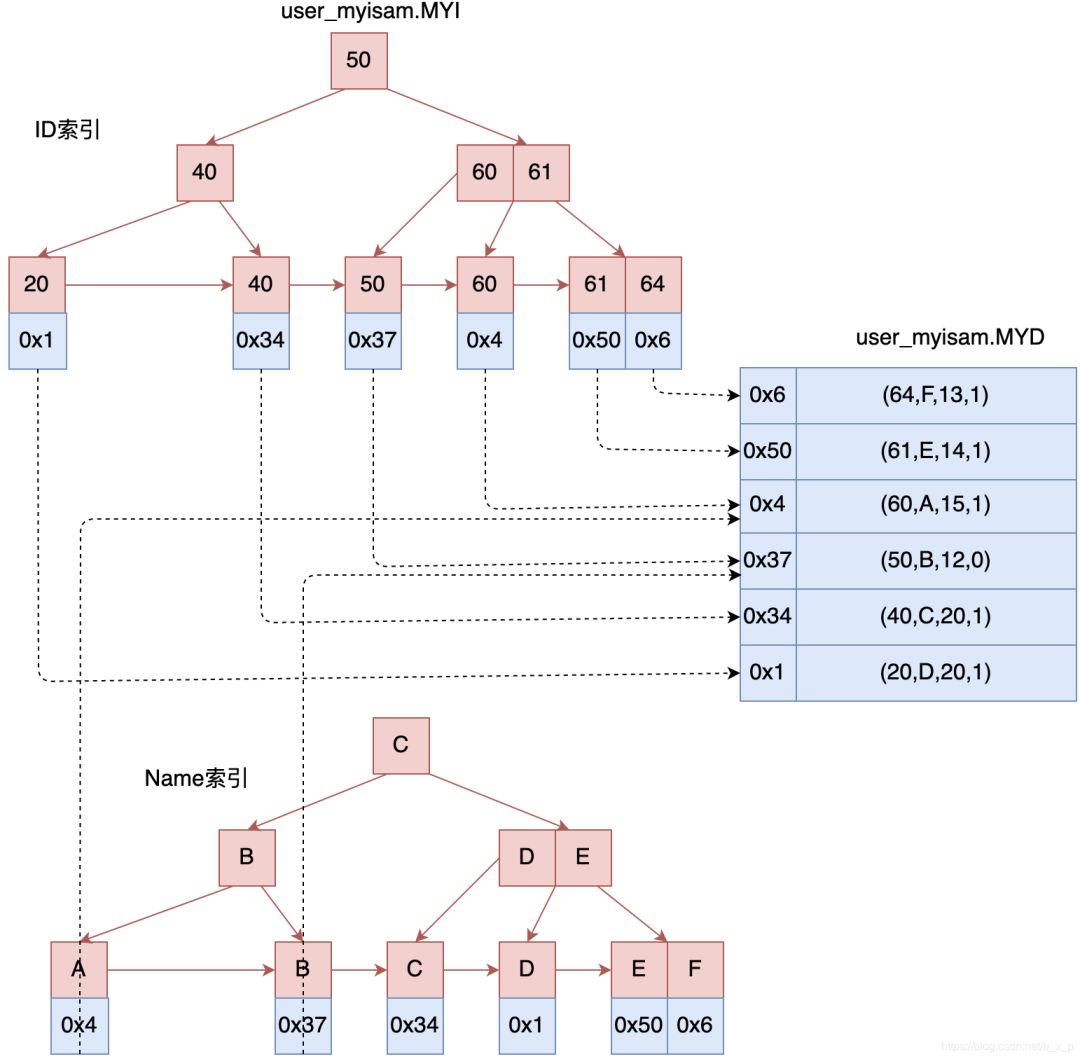
所以在MYISAM存儲引擎中,主鍵索引和輔助索引是同級別的,沒有主次之分。
Innodb存儲引擎
Innodb主鍵索引為聚集索引,首先簡單理解一下聚集索引的概念:數(shù)據(jù)庫表行中數(shù)據(jù)的物理順序和鍵值的邏輯順序相同。
Innodb以主鍵索引來聚集組織數(shù)據(jù)的存儲,下面看看Innodb是如何組織數(shù)據(jù)的。
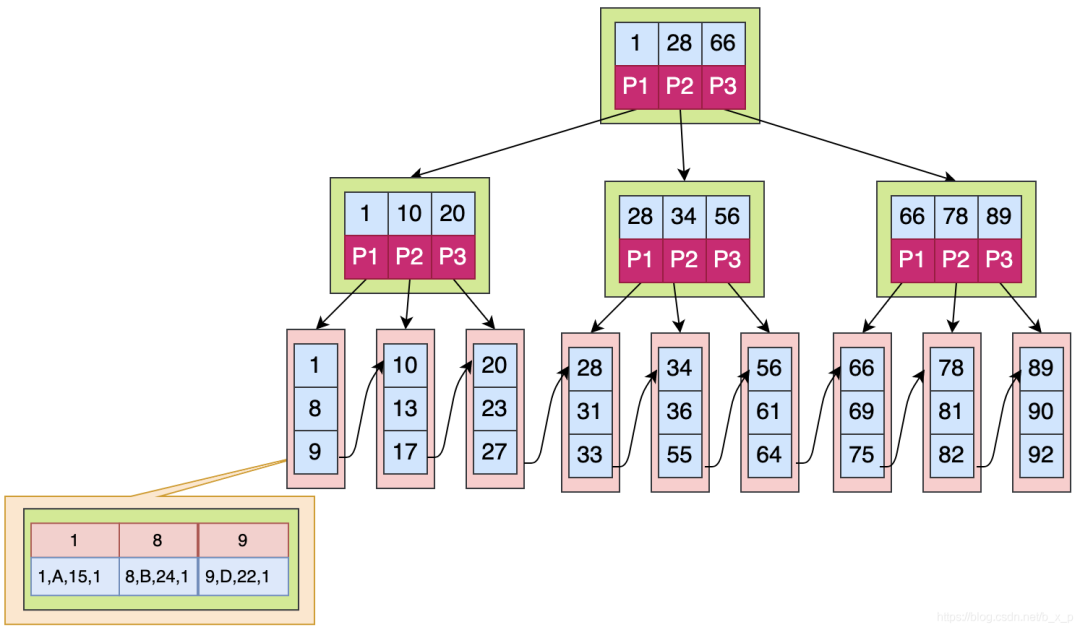
如上圖中,葉子節(jié)點(diǎn)的數(shù)據(jù)區(qū)保存的就是真實(shí)的數(shù)據(jù),在通過索引進(jìn)行檢索的時(shí)候,命中葉子節(jié)點(diǎn),就可以直接從葉子節(jié)點(diǎn)中取出行數(shù)據(jù)。mysql5.5版本之前默認(rèn)采用的是MyISAM引擎,5.5之后默認(rèn)采用的是innodb引擎。
在innodb中,輔助索引的格式如下圖所示?
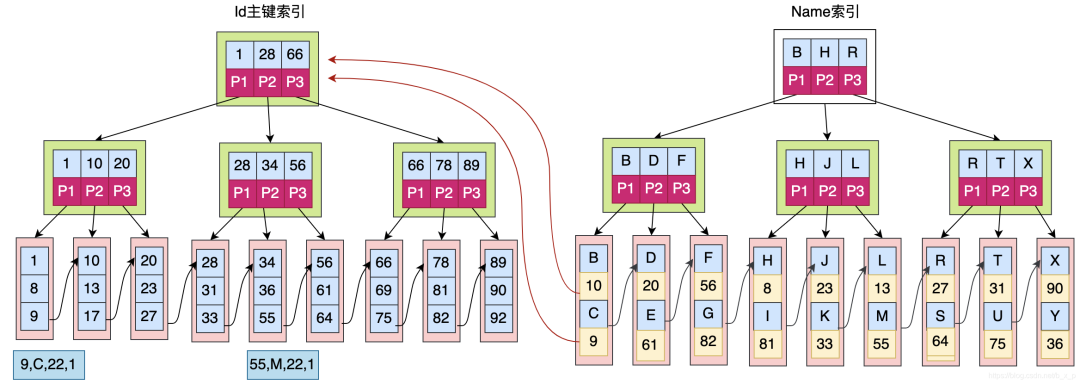
如上圖,主鍵索引的葉子節(jié)點(diǎn)保存的是真正的數(shù)據(jù)。而輔助索引葉子節(jié)點(diǎn)的數(shù)據(jù)區(qū)保存的是主鍵索引關(guān)鍵字的值。
假如要查詢name = C 的數(shù)據(jù),其搜索過程如下:
先在輔助索引中通過C查詢最后找到主鍵id = 9.
在主鍵索引中搜索id為9的數(shù)據(jù),最終在主鍵索引的葉子節(jié)點(diǎn)中獲取到真正的數(shù)據(jù)。
所以通過輔助索引進(jìn)行檢索,需要檢索兩次索引。
之所以這樣設(shè)計(jì),一個(gè)原因就是:如果和MyISAM一樣在主鍵索引和輔助索引的葉子節(jié)點(diǎn)中都存放數(shù)據(jù)行指針,一旦數(shù)據(jù)發(fā)生遷移,則需要去重新組織維護(hù)所有的索引。
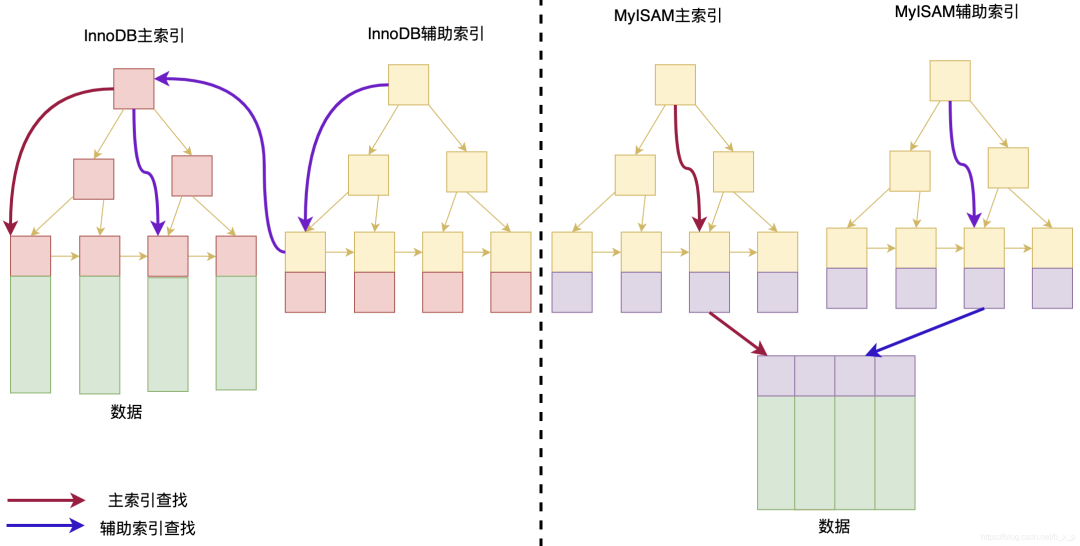
把Innodb 和 MYISAM區(qū)別放在一張圖中看,就如下所示:
創(chuàng)建索引的幾大原則
列的離散型
離散型的計(jì)算公式:count(distinct column_name):count(*),就是用去重后的列值個(gè)數(shù)比個(gè)數(shù)。值在 (0,1] 范圍內(nèi)。離散型越高,選擇型越好。
如下表中各個(gè)字段,明顯能看出Id的選擇性比gender更高。
mysql>?select?*?from?user;
+----+--------------+------+--------+
|?id?|?name?????????|?age??|?gender?|
+----+--------------+------+--------+
|?20?|?君莫笑???????|???15?|??????1?|
|?40?|?蘇沐橙???????|???12?|??????0?|
|?50?|?張楚嵐???????|???25?|??????1?|
|?60?|?諸葛青???????|???27?|??????1?|
|?61?|?若有人兮?????|???38?|??????0?|
|?64?|?馮寶寶???????|???18?|??????0?|
+----+--------------+------+--------+
為什么說離散型越高,選擇型越好?
因?yàn)殡x散度越高,通過索引最終確定的范圍越小,最終掃面的行數(shù)也就越少。
最左匹配原則
對于索引中的關(guān)鍵字進(jìn)行對比的時(shí)候,一定是從左往右以此對比,且不可跳過。之前講解的id都為int型數(shù)據(jù),如果id為字符串的時(shí)候,如下圖:
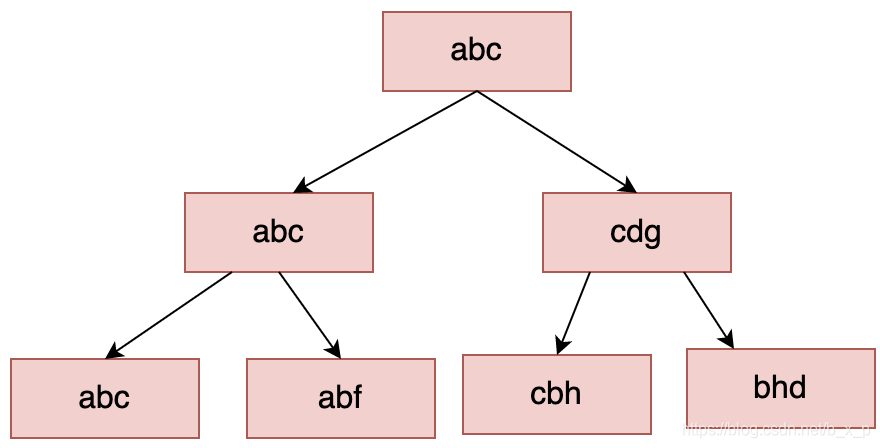
當(dāng)進(jìn)行匹配的時(shí)候,會把字符串轉(zhuǎn)換成ascll碼,如abc變成97 98 99,然后從左往右一個(gè)字符一個(gè)字符進(jìn)行對比。所以在sql查詢中使用like %a 時(shí)候索引會失效,因?yàn)?表示全匹配,如果已經(jīng)全匹配就不需要索引,還不如直接全表掃描。
最少空間原則
前面已經(jīng)說過,當(dāng)關(guān)鍵字占用的空間越小,則每個(gè)節(jié)點(diǎn)保存的關(guān)鍵字個(gè)數(shù)就越多,每次加載進(jìn)內(nèi)存的關(guān)鍵字個(gè)數(shù)就越多,檢索效率就越高。創(chuàng)建索引的關(guān)鍵字要盡可能占用空間小。
聯(lián)合索引
單列索引:節(jié)點(diǎn)中的關(guān)鍵字[name]
聯(lián)合索引:節(jié)點(diǎn)中的關(guān)鍵字[name, age]
可以把單列索引看成特殊的聯(lián)合索引,聯(lián)合索引的比較也是根據(jù)最左匹配原則。
聯(lián)合索引列的選擇原則
經(jīng)常用的列優(yōu)先(最左匹配原則)
離散度高的列優(yōu)先(離散度高原則)
寬度小的列優(yōu)先(最少空間原則)
實(shí)例分析
下面簡單舉例平時(shí)經(jīng)常會遇到的問題:
如,平時(shí)經(jīng)常使用的查詢sql如下:
select?*?from?users?where?name?=??
select?*?from?users?where?name?=???and?age?=??
為了加快檢索速度,為上面的查詢sql創(chuàng)建索引如下:
create?index?idx_name?on?users(name)
create?index?idx_name_age?on?users(name,?age)
在上面解決方案中,根據(jù)最左匹配原則,idx_name為冗余索引, where name = ?同樣可以利用索引idx_name_age進(jìn)行檢索。冗余索引會增加維護(hù)B+TREE平衡時(shí)的性能消耗,并且占用磁盤空間。
覆蓋索引
如果查詢的列,通過索引項(xiàng)的信息可直接返回,則該索引稱之為查詢SQL的覆蓋索引。覆蓋索引可以提高查詢的效率。
如上圖,如果通過name進(jìn)行數(shù)據(jù)檢索:
select?*?from?users?where?name?=??
需要需要在name索引中找到name對應(yīng)的Id,然后通過獲取的Id在主鍵索引中查到對應(yīng)的行。整個(gè)過程需要掃描兩次索引,一次name,一次id。
如果我們查詢只想查詢id的值,就可以改寫SQL為:
select?id?from?users?where?name?=??
因?yàn)橹恍枰猧d的值,通過name查詢的時(shí)候,掃描完name索引,我們就能夠獲得id的值了,所以就不需要再去掃面id索引,就會直接返回。
當(dāng)然,如果你同時(shí)需要獲取age的值:
select?id,age?from?users?where?name?=??
這樣就無法使用到覆蓋索引了。
知道了覆蓋索引,就知道了為什么sql中要求盡量不要使用select *,要寫明具體要查詢的字段。其中一個(gè)原因就是在使用到覆蓋索引的情況下,不需要進(jìn)入到數(shù)據(jù)區(qū),數(shù)據(jù)就能直接返回,提升了查詢效率。在用不到覆蓋索引的情況下,也盡可能的不要使用select *,如果行數(shù)據(jù)量特別多的情況下,可以減少數(shù)據(jù)的網(wǎng)絡(luò)傳輸量。當(dāng)然,這都視具體情況而定,通過select返回所有的字段,通用性會更強(qiáng),一切有利必有弊。
總結(jié)
索引列的數(shù)據(jù)長度滿足業(yè)務(wù)的情況下能少則少。
表中的索引并不是越多越好,冗余或者無用索引會占用磁盤空間并且會影響增刪改的效率。
Where 條件中,like 9%, like %9%, like%9,三種方式都用不到索引。后兩種方式對于索引是無效的。第一種9%是不確定的,決定于列的離散型,結(jié)論上講可以用到,如果發(fā)現(xiàn)離散情況特別差的情況下,查詢優(yōu)化器覺得走索引查詢性能更差,還不如全表掃描。
Where條件中IN可以使用索引, NOT IN 無法使用索引。
多用指定查詢,只返回自己想要的列,少用select *。
查詢條件中使用函數(shù),索引將會失效,這和列的離散性有關(guān),一旦使用到函數(shù),函數(shù)具有不確定性。
聯(lián)合索引中,如果不是按照索引最左列開始查找,無法使用索引。
對聯(lián)合索引精確匹配最左前列并范圍匹配另一列,可以使用到索引。
聯(lián)合索引中,如果查詢有某個(gè)列的范圍查詢,其右邊所有的列都無法使用索引。
轉(zhuǎn)自:he_321
鏈接:https://blog.csdn.net/b_x_p/article/details/86434387