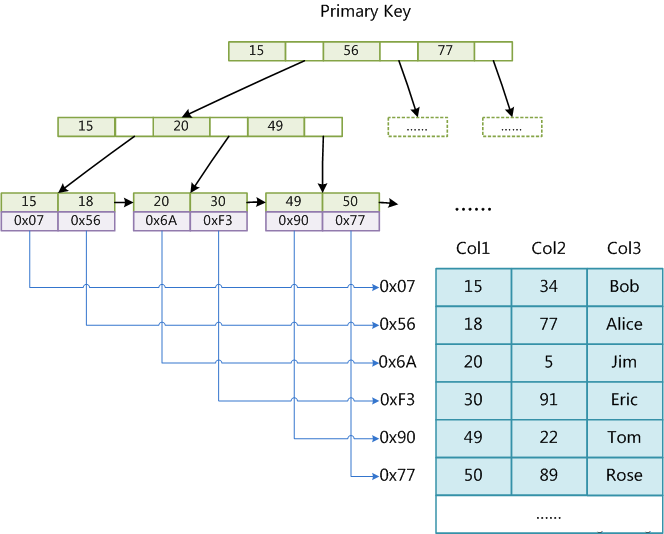
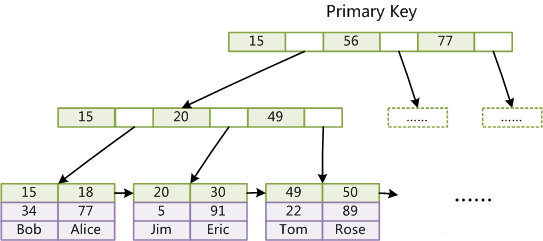
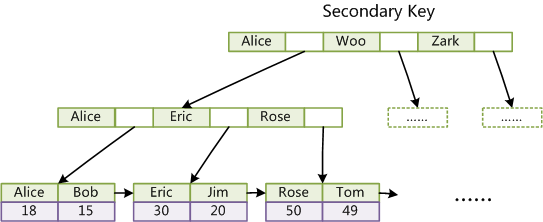
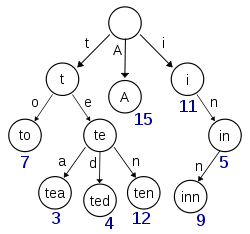
MySQL和Lucene(Elasticsearch)索引對比分析
點擊上方藍(lán)色字體,選擇“設(shè)為星標(biāo)”







版權(quán)聲明:
文章不錯?點個【在看】吧!??
評論
圖片
表情
<b id="afajh"><abbr id="afajh"></abbr></b>
 下載APP
下載APP點擊上方藍(lán)色字體,選擇“設(shè)為星標(biāo)”
版權(quán)聲明:
文章不錯?點個【在看】吧!??
<b id="afajh"><abbr id="afajh"></abbr></b>