
Facebook AI PyTorch數(shù)據(jù)并行訓(xùn)練秘籍大揭秘

極市導(dǎo)讀
?本文介紹了PyTorch最新版本下分布式數(shù)據(jù)并行包的系統(tǒng)設(shè)計(jì)、具體實(shí)現(xiàn)和結(jié)果評(píng)估等方面的內(nèi)容。>>加入極市CV技術(shù)交流群,走在計(jì)算機(jī)視覺的最前沿
在芯片性能提升有限的今天,分布式訓(xùn)練成為了應(yīng)對(duì)超大規(guī)模數(shù)據(jù)集和模型的主要方法。本文將向你介紹流行深度學(xué)習(xí)框架 PyTorch 最新版本( v1.5)的分布式數(shù)據(jù)并行包的設(shè)計(jì)、實(shí)現(xiàn)和評(píng)估。

系統(tǒng)設(shè)計(jì)
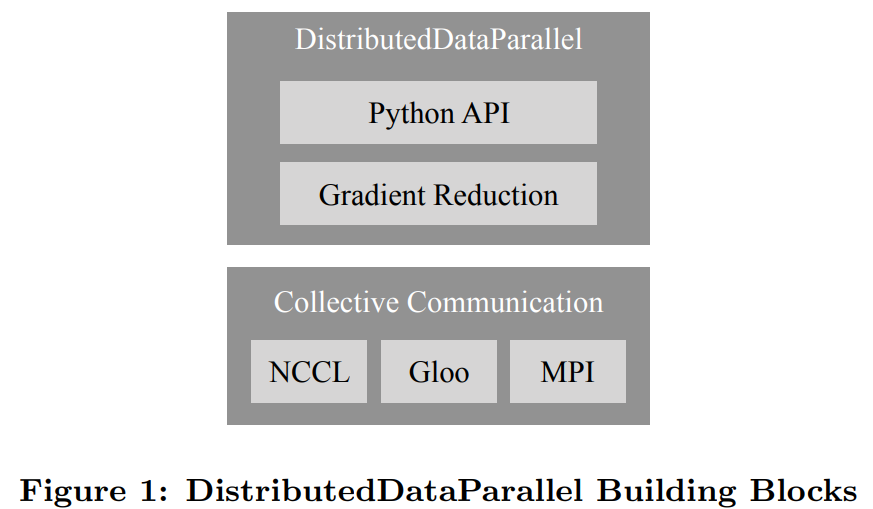
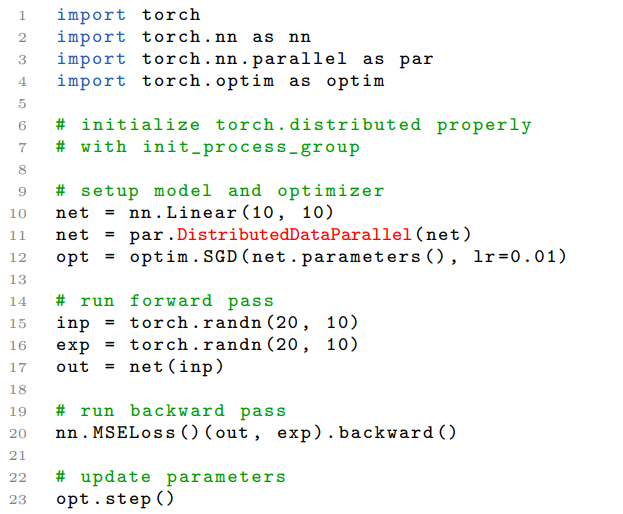
從相同的模型狀態(tài)開始;
每次迭代花費(fèi)同樣多的梯度。
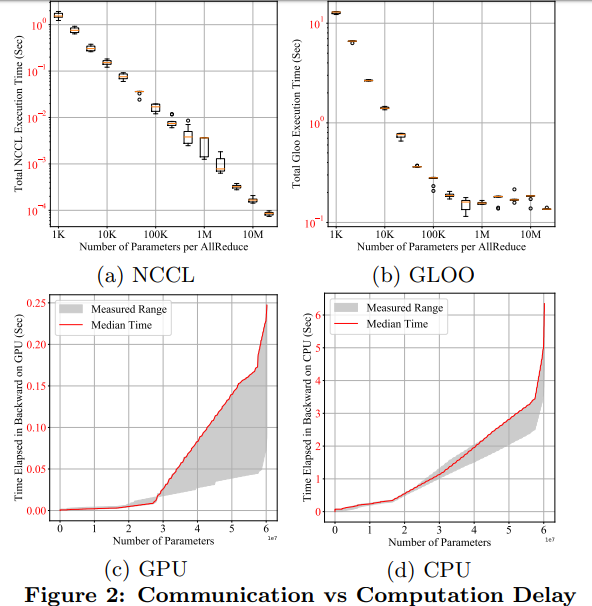
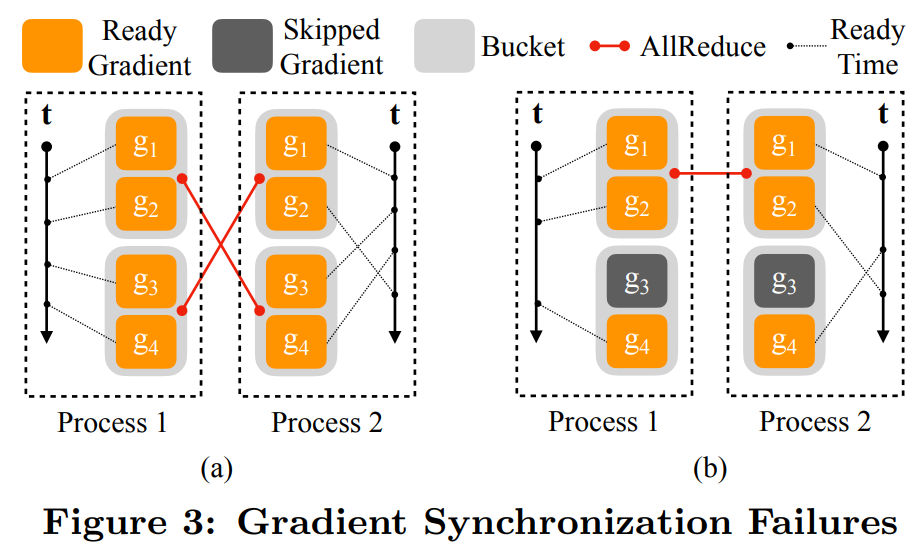

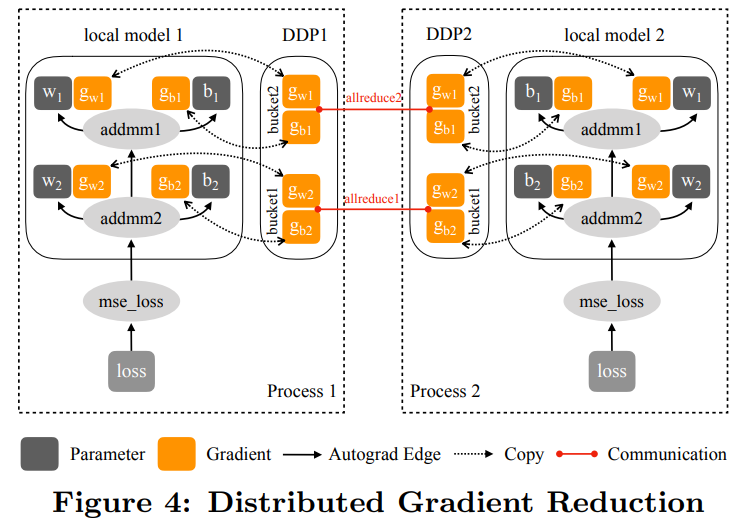

具體實(shí)現(xiàn)
分組處理以找出 DDP 中運(yùn)行 AllReduce 的進(jìn)程組實(shí)例,它能夠幫助避免與默認(rèn)進(jìn)程組混淆; bucket_cap_mb 控制 AllReduce 的 bucket 大小,其中的應(yīng)用應(yīng)調(diào)整 knob 來(lái)優(yōu)化訓(xùn)練速度; 找出沒有用到的參數(shù)以驗(yàn)證 DDP 是否應(yīng)該通過遍歷 autograd 圖來(lái)檢測(cè)未用到的參數(shù)。
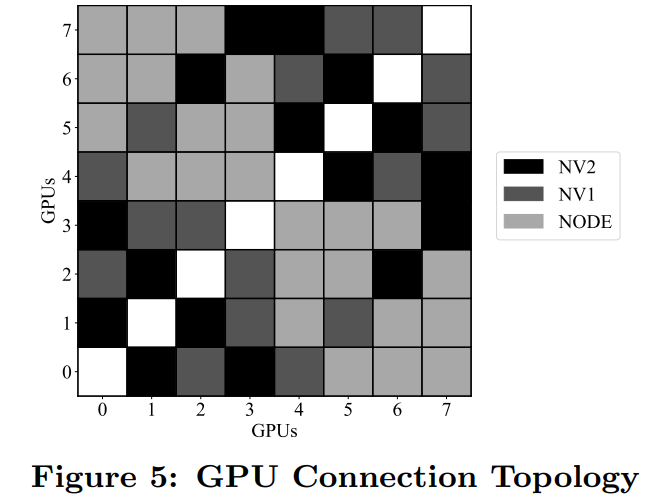
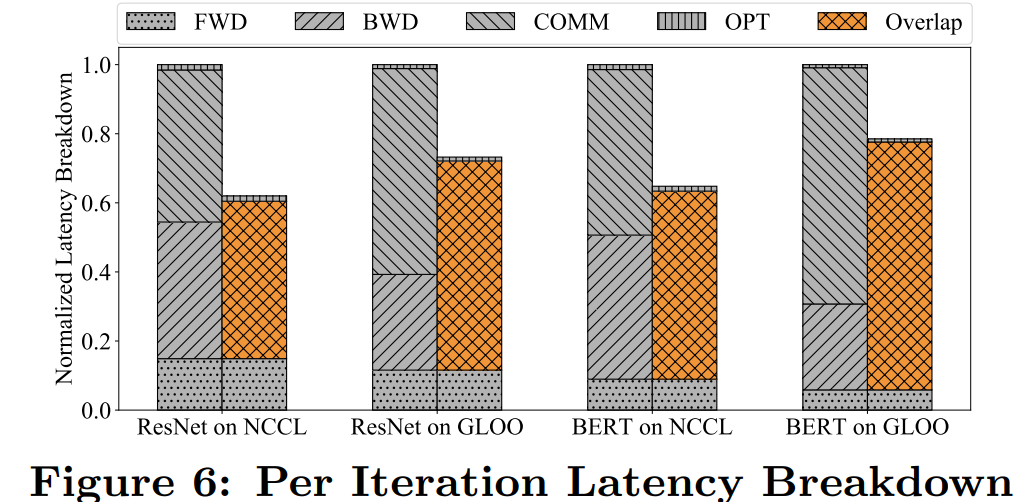
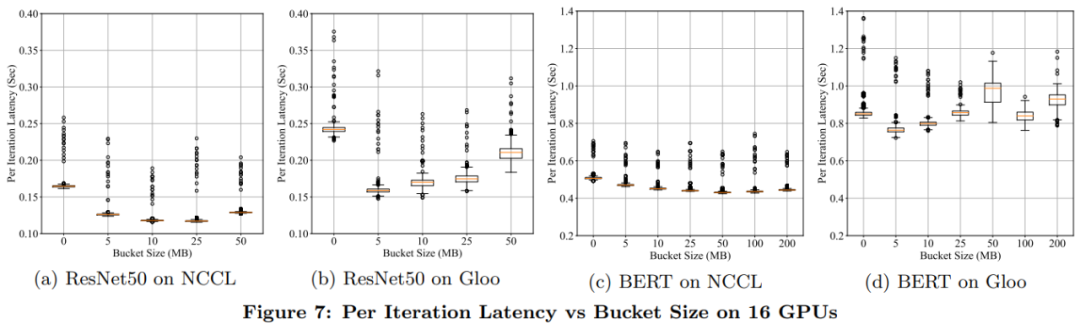
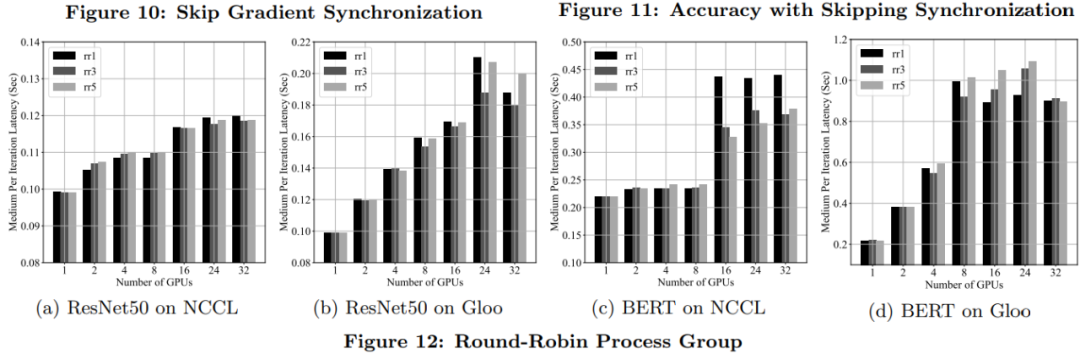
實(shí)驗(yàn)評(píng)估
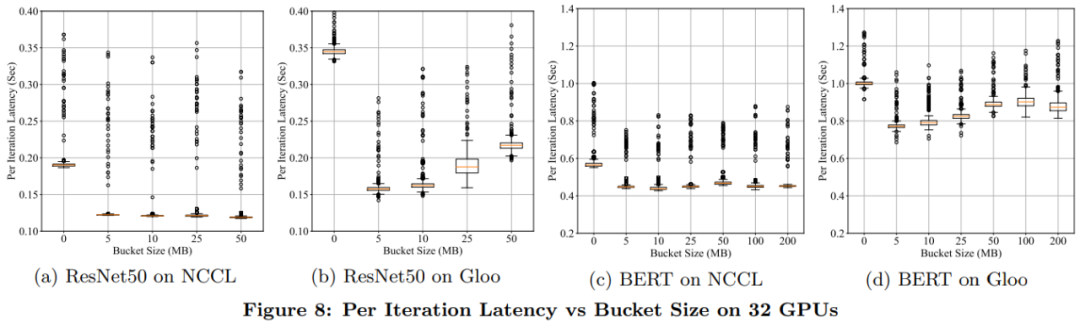
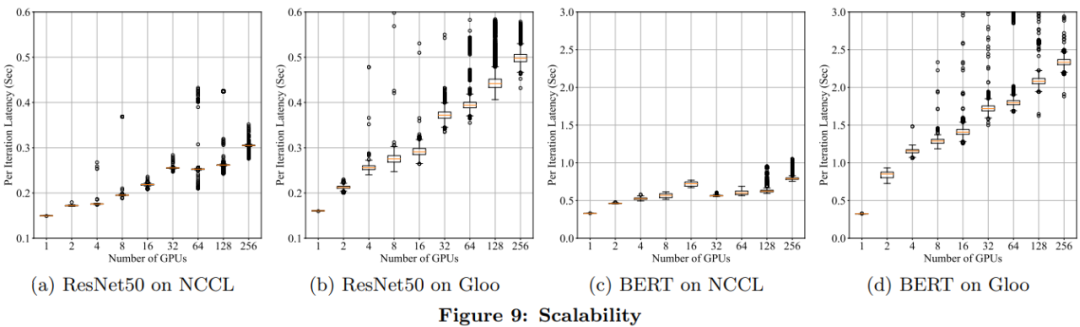
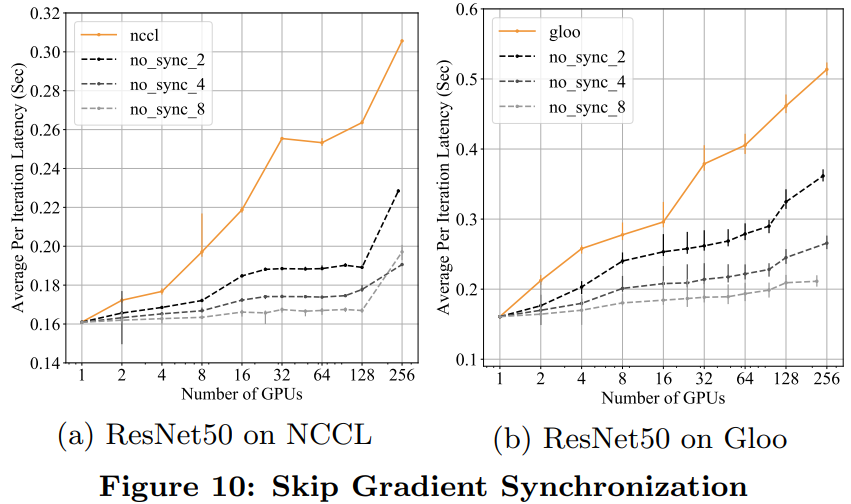
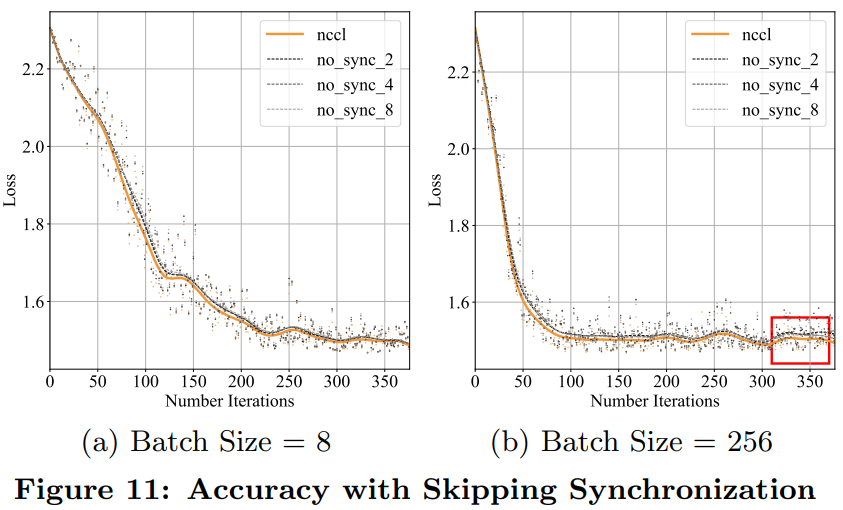
推薦閱讀

評(píng)論
圖片
表情