
【解密】硅谷互聯(lián)網(wǎng)公司的大數(shù)據(jù)平臺架構(gòu)
↑↑↑點(diǎn)擊上方藍(lán)字,回復(fù)資料,10個G的驚喜
導(dǎo)讀:本文分析一下典型硅谷互聯(lián)網(wǎng)企業(yè)的大數(shù)據(jù)平臺架構(gòu)。

Production Hosts:直接服務(wù)用戶的生產(chǎn)服務(wù)器,也就是業(yè)務(wù)系統(tǒng)。 MySQL/Gizzard:用戶關(guān)系圖存在于Twitter的大規(guī)模MySQL分布式集群中,使用單個MySQL作為存儲單位,在上面增加一層分布式協(xié)調(diào)數(shù)據(jù)分片(sharding)和調(diào)度的系統(tǒng)。 Distributed Crawler, Crane:類似于Sqoop和DataX的系統(tǒng),可以從MySQL中將業(yè)務(wù)數(shù)據(jù)導(dǎo)出到Hadoop、HBase、Vertica里,主要用Java編寫。 Vertica:大規(guī)模分布式數(shù)據(jù)處理系統(tǒng)(MPP),可以理解為一個以O(shè)LAP為主要任務(wù)的分布式數(shù)據(jù)庫,主要用于建設(shè)數(shù)據(jù)倉庫。類似的商業(yè)產(chǎn)品有Teradata、Greenplum等,類似的開源工具有Presto、Impala等。 Rasvelg:基于SQL的ETL工具,主要用于數(shù)據(jù)清洗、治理和數(shù)據(jù)倉庫建設(shè)。 ScribeAggregators:日志實(shí)時采集工具,類似于Flume和Logstash,主要目的是將日志實(shí)時采集到Hadoop集群中(圖7-2中的RT Hadoop Cluster)。 Log Events:主要是將客戶端埋點(diǎn)的數(shù)據(jù)或其他需要實(shí)時處理的數(shù)據(jù)寫入各種消息中間件中。 EventBus、Kafka、Kestrel queue:Kafka是開源的消息中間件,EventBus和Kestrel都是Kafka出現(xiàn)之前Twitter內(nèi)部開發(fā)的消息中間件。需要內(nèi)部系統(tǒng)的原因是有些業(yè)務(wù)需要類似于exactly-once(確定一次)的語義或者其他特殊需求,而Kafka成熟較晚,直到2017年的0.11版才推出exactly-once這種語義。 Storm、Heron:消息中間件的數(shù)據(jù)會被一個實(shí)時處理系統(tǒng)處理。Twitter早期用的是Storm,但后來發(fā)現(xiàn)Storm性能和開發(fā)問題比較大,就自己用C++開發(fā)了一個與Storm API兼容的系統(tǒng)Heron來取代Storm,并在2016年開源。 Nighthawk、Manhattan:Nighthawk是sharded Redis,Manhattan是sharded key-value store(用來取代Cassandra),推文、私信等用戶信息存放在Manhattan里,Nighthawk作為緩存,這些組件是直接服務(wù)業(yè)務(wù)的;實(shí)時處理的數(shù)據(jù)和一些批處理分析的數(shù)據(jù)也會放在這里,被業(yè)務(wù)系統(tǒng)調(diào)用。 LogMover:日志復(fù)制工具,主要使用Hadoop的distcp功能將日志從實(shí)時服務(wù)器復(fù)制到另一個大的生產(chǎn)集群。 第三方數(shù)據(jù):例如蘋果應(yīng)用商店的數(shù)據(jù),這些數(shù)據(jù)使用定制的爬蟲程序在Crane框架里執(zhí)行。 Pig、Hive、Scalding、Spark:各種內(nèi)部批處理分析框架,也用來開發(fā)ETL工具。 DirReplicator:用來在各個數(shù)據(jù)中心、冷熱Hadoop集群、測試/生產(chǎn)集群中同步數(shù)據(jù)目錄。 DAL:Twitter的數(shù)據(jù)門戶,基本上所有的數(shù)據(jù)操作都要經(jīng)過DAL的處理。 Tableau、Birdbrain:Twitter的數(shù)據(jù)可視化/BI工具,Tableau是通用的商業(yè)化工具,主要供具有統(tǒng)計背景的數(shù)據(jù)分析師使用;Birdbrain是內(nèi)部的BI系統(tǒng),它將最常用的報表和指標(biāo)做成自助式的工具,確保從CEO到銷售人員都可以使用。
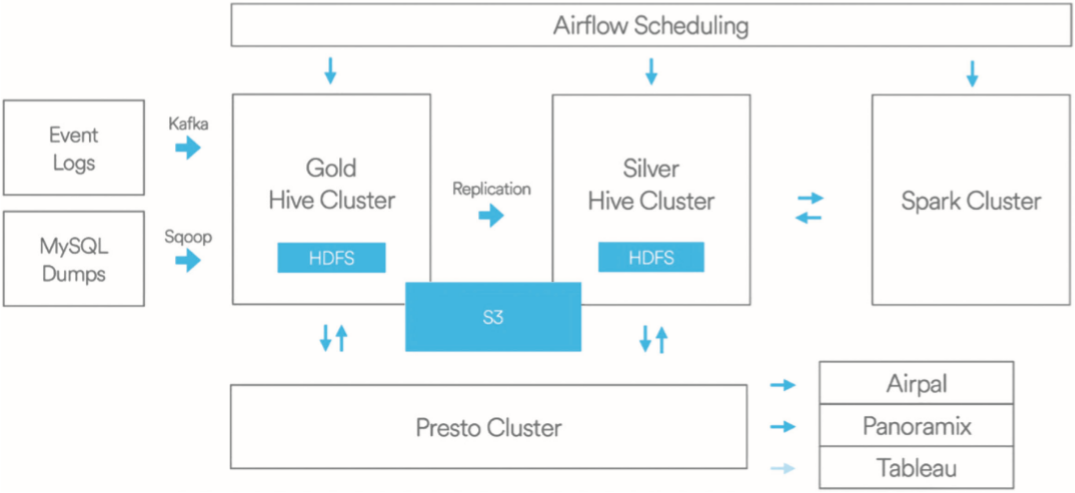
數(shù)據(jù)源:包含各種業(yè)務(wù)數(shù)據(jù)的采集,例如將數(shù)據(jù)埋點(diǎn)事件日志發(fā)送到Kafka,MySQL數(shù)據(jù)通過數(shù)據(jù)傳輸組件Sqoop傳輸?shù)紿ive集群。 存儲:使用的是Hadoop的HDFS和AWS的S3。 復(fù)制:有專門的復(fù)制程序在金、銀集群中復(fù)制數(shù)據(jù)。 資源管理:用到了YARN,同時通過Druid和亞馬遜的RDS實(shí)現(xiàn)對數(shù)據(jù)庫連接的監(jiān)控、操作與擴(kuò)展。 計算:主要采用MapReduce、Hive、Spark、Presto。其中,Presto是Facebook研發(fā)的一套開源的分布式SQL查詢引擎,適用于交互式分析查詢。 調(diào)度:開發(fā)并開源了任務(wù)調(diào)度系統(tǒng)Airflow,可以跨平臺運(yùn)行Hive、Presto、Spark、MySQL等Job,并提供調(diào)度和監(jiān)控功能。 查詢:主要使用Presto。 可視化:開發(fā)了負(fù)責(zé)界面顯示的Airpal、簡易的數(shù)據(jù)搜索分析工具Caravel及Tableau公司的可視化數(shù)據(jù)分析產(chǎn)品。
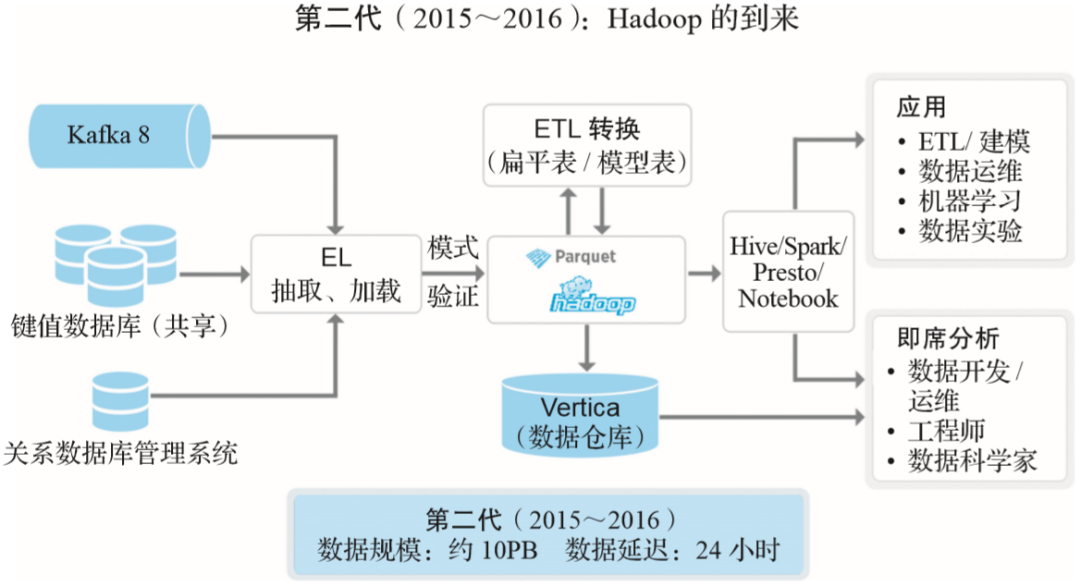
實(shí)時數(shù)據(jù)采集:Kafka。 鍵值數(shù)據(jù)庫:類似于Twitter的Manhattan。 RDBMS DB:關(guān)系型數(shù)據(jù)庫。 Ingestion:數(shù)據(jù)采集(這里它強(qiáng)調(diào)了強(qiáng)制類型檢查,即schema enforced,強(qiáng)制類型檢查是數(shù)據(jù)治理中的一環(huán))。 數(shù)據(jù)采集、存儲:主要使用Hadoop,采取Twitter開源的列式存儲格式Parquet,構(gòu)建了一個集中模式服務(wù)來收集、存儲相關(guān)客戶端庫,將不同服務(wù)數(shù)據(jù)模式集成到這個中央模式服務(wù)中。 ETL:在Hadoop數(shù)據(jù)湖上進(jìn)行數(shù)據(jù)的整合、治理、分析。 數(shù)據(jù)倉庫:使用Vertica,主要存儲從數(shù)據(jù)湖中計算出來的寬表,因?yàn)樘幚砟芰τ邢蓿话阒淮鎯ψ罱臄?shù)據(jù)。 計算框架:采用MapReduce、Hive、Spark和Presto。 查詢工具:使用Presto來實(shí)現(xiàn)交互式查詢,使用Spark對原始數(shù)據(jù)進(jìn)行編程訪問,使用Hive進(jìn)行非常大的離線查詢,并允許用戶根據(jù)需求進(jìn)行選擇。 支持的數(shù)據(jù)應(yīng)用:建模、機(jī)器學(xué)習(xí)、運(yùn)營人員、A/B測試。 支持隨機(jī)查詢:運(yùn)營人員、數(shù)據(jù)科學(xué)家。


統(tǒng)一的平臺支持端到端的數(shù)據(jù)工具體系,尤其強(qiáng)調(diào)體現(xiàn)數(shù)據(jù)價值的應(yīng)用。 強(qiáng)調(diào)數(shù)據(jù)能力的閉環(huán),從數(shù)據(jù)的產(chǎn)生、使用到最后反饋到產(chǎn)品。 數(shù)據(jù)的采集、治理、分析、使用由所有部門在統(tǒng)一體系中完成。 主要的基礎(chǔ)組件大部分采用成熟系統(tǒng),如Hadoop、Hive、Kafka、Spark、Vertica。 自己開發(fā)一些側(cè)重用戶交互的組件,如ETL開發(fā)調(diào)度平臺、數(shù)據(jù)門戶、建模/數(shù)據(jù)治理。
全局的數(shù)據(jù)和應(yīng)用資產(chǎn)的管理和運(yùn)營; 明確平臺團(tuán)隊和業(yè)務(wù)團(tuán)隊的分工和合作; 重視可衡量的數(shù)據(jù)能力。
重復(fù)造輪子風(fēng)險大、投入高、見效慢; 自己造的輪子沒有社區(qū),原始開發(fā)人員離職后難以招人替代; 開發(fā)人員更愿意使用現(xiàn)有開源工具,閉源系統(tǒng)很難招到頂尖人才; 閉源開發(fā)的系統(tǒng)迭代一般比開源要慢很多,如果趕不上,差距會越來越大; 涉及系統(tǒng)越來越復(fù)雜,一個公司很難自己覆蓋所有系統(tǒng)。
基礎(chǔ)架構(gòu)組件:這方面的產(chǎn)品或組件最好選擇成熟的開源體系,因?yàn)槌墒斓拈_源體系經(jīng)過了眾多企業(yè)的千錘百煉,具有較高的穩(wěn)定性和可靠性,而如果自己重新來做,未知因素太多,坑也太多。 用戶交互組件:在基礎(chǔ)架構(gòu)之上與用戶打交道的交互產(chǎn)品,因?yàn)楦鱾€企業(yè)使用習(xí)慣不一樣,底層技術(shù)棧不一樣,所以最好選擇定制服務(wù)或者自主開發(fā)。

也可以加一下老胡的微信 圍觀朋友圈~~~
推薦閱讀
(點(diǎn)擊標(biāo)題可跳轉(zhuǎn)閱讀)
老鐵,三連支持一下,好嗎?↓↓↓
評論
圖片
表情