
螞蟻開源新算法,給大模型提提速!

ChatGPT Plus 一個(gè)月就要 20 美元 ,這是筆不小的費(fèi)用。雖然已經(jīng)是尊貴的 Plus 用戶,但 每次 輸 入一個(gè)問題后,還是需要等待一段時(shí)間才能拿到結(jié)果,感覺就像逐字蹦出來的一樣。 這 是什么原因呢?
其實(shí),回答的響應(yīng)速度與服務(wù)成本,關(guān)鍵在于 推理效率 ,這也是大模型目前主要技術(shù)攻堅(jiān)方向之一。
近日,螞蟻開源了一套新算法—— Lookahead 推理加速框架 ,它能做到效果無損、即插即用,實(shí)現(xiàn)無痛推理加速, 支持 包括 Llama、OPT、Bloom、GPTJ、GPT2、Baichuan、ChatGLM、GLM 和 Qwen 在內(nèi)的一系列模型。 該算法 已在螞蟻大量場景進(jìn)行了落地,實(shí)際獲得了 2.66-6.26 倍的加速比,大幅降低了推理耗時(shí)。
下面,讓我們一起來看看這個(gè)算法的加速效果和背后的原理。
加速效果
耳聽為虛眼見為實(shí),下面就以螞蟻百靈大模型 AntGLM 10B 為例,實(shí)測一下面對同樣的一個(gè)問題,生成答案的速度區(qū)別。
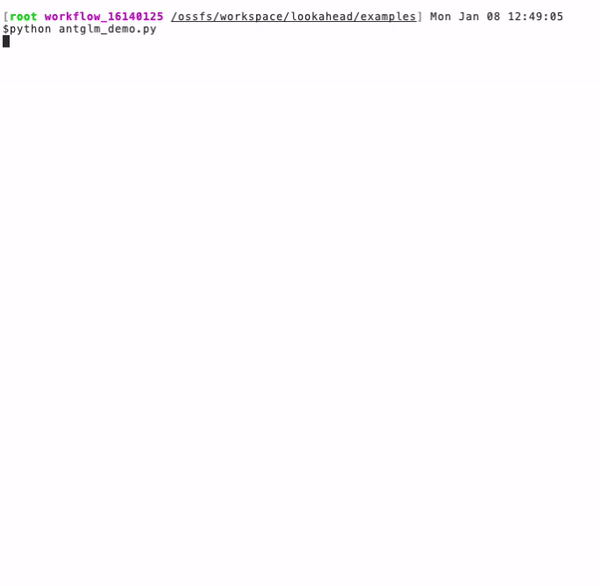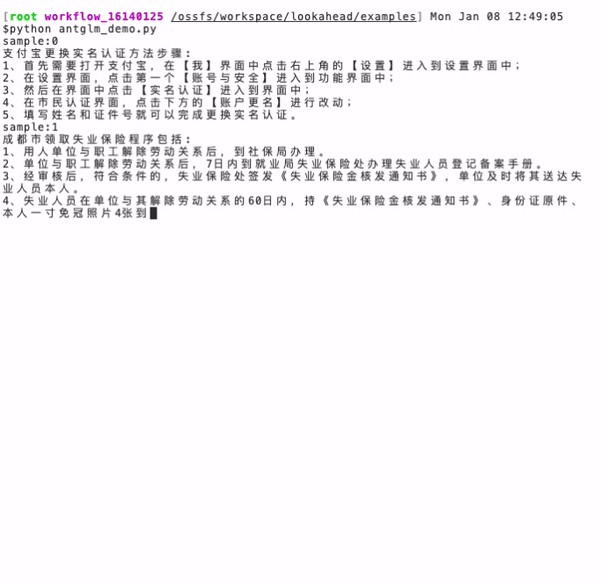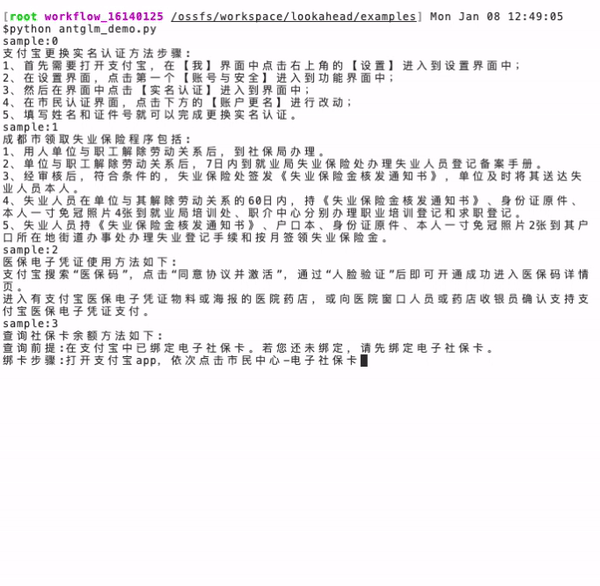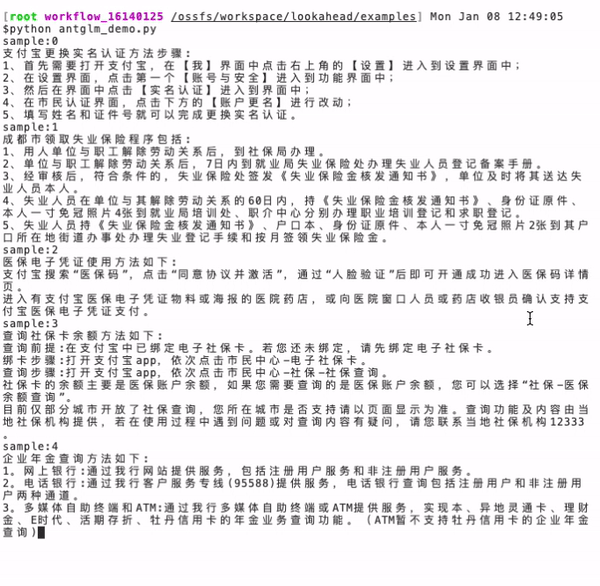

左圖(當(dāng)前主流算法):耗時(shí) 16.9 秒,token 生成速度為 33.8 個(gè)/秒。
右圖(螞蟻 Lookahead 推理算法): 耗時(shí) 3.9 秒,token 生成速度為 147.6 個(gè)/秒,速度提升了 4.37 倍。
| AntGLM 10B 模型 | 耗時(shí) | 生成速度 |
|---|---|---|
| 主流算法 | 16.9s | 33.8 token/s |
| Lookahead 算法 | 3.9s | 147.6 token/s |


左圖(當(dāng)前主流算法):耗時(shí) 15.7 秒,token 生成速度為 48.2 個(gè)/秒;
右圖(螞蟻 Lookahead 推理算法): 耗時(shí) 6.4 秒,token生成速度為 112.9 個(gè)/秒,速度提升了 2.34 倍。
| Llama2-7B-chat 模型 |
耗時(shí) | 生成速度 |
|---|---|---|
| 主流算法 | 15.7s | 48.2 token/s |
| Lookahead 算法 | 6.4s | 112.9 token/s |
技術(shù)原理
當(dāng)下的大模型基本都是基于自回歸解碼,每一步解碼僅生成一個(gè) token,這種操作方式既浪費(fèi)了 GPU 的并行處理能力,也導(dǎo)致用戶體驗(yàn)延遲過高,影響使用流暢度。
業(yè)內(nèi)有少量的優(yōu)化算法,主要集中在如何生成更好的草稿(即猜測生成 token 的序列)上,但是實(shí)踐證明草稿在超過 30 個(gè) token 長度后,端到端的推理效率就無法 進(jìn)一步提高,但是這個(gè)長度遠(yuǎn)沒有 充分利用 GPU 的運(yùn)算能力。
為了進(jìn)一步 壓榨硬件性能,螞蟻 Lookahead 推理加速算法采用了 多分支的策略 ,即草稿序列不再僅僅包含一條分支,而是包含多條并行的分支,多條分支在一次前向過程中進(jìn)行并行驗(yàn)證。 因此可以在耗時(shí)基本不變的前提下,提高一次前向過程生成的 token 個(gè)數(shù)。
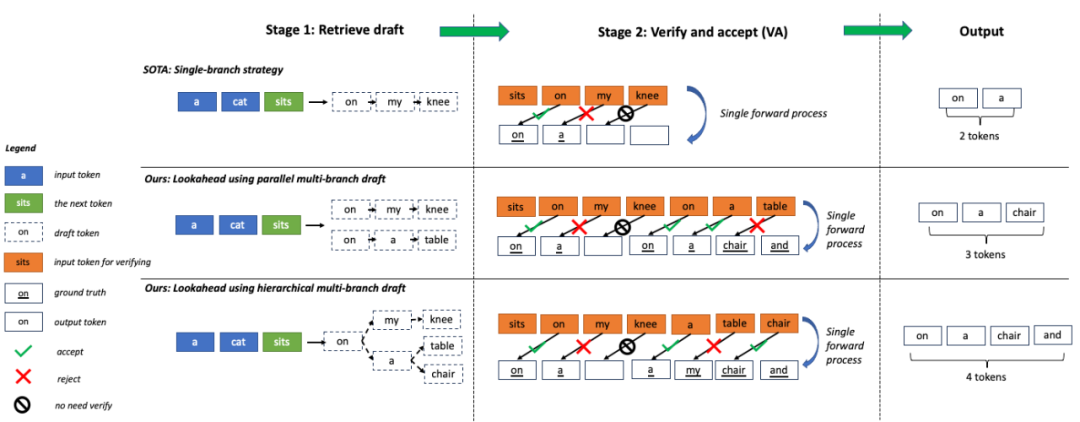
再進(jìn)一步 ,螞蟻 Lookahead 推理加速算法利用 trie 樹存儲和檢索 token 序列,并將多條草稿中相同的父節(jié)點(diǎn)進(jìn)行合并,進(jìn)一步提高了計(jì)算效率。 為了提高易用性,trie 樹的構(gòu)建不依賴額外的草稿模型,只利用推理過程中的 prompt 及生成的回答進(jìn)行動(dòng)態(tài)構(gòu)建,降低了用戶的接入成本。
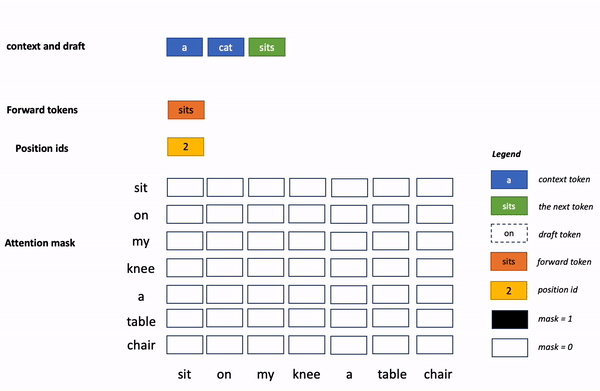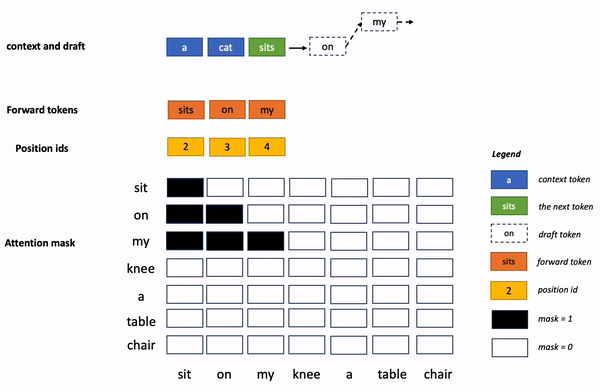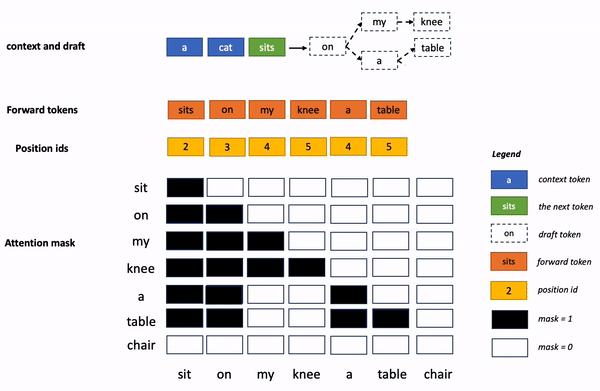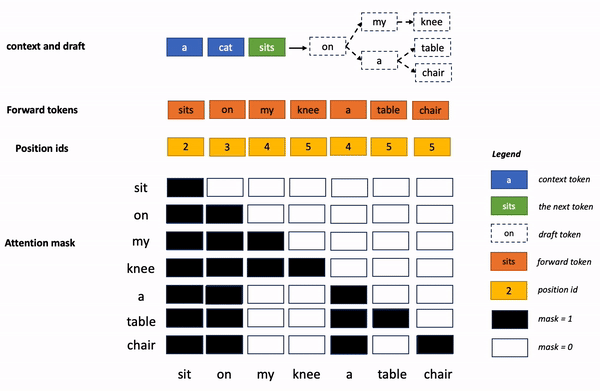
上面的專業(yè)術(shù)語有點(diǎn)多,非專業(yè)的讀者理解起來有點(diǎn)困難。 換個(gè)通俗易懂的說 法,再解釋一下:
原來的 token 生成過程,就像早期中文輸入法,只能一個(gè)字一個(gè)字“敲”出來,采用了螞蟻的加速算法后,token 生成就像聯(lián)想輸入法,有些整句可直接“蹦”出來。
最后
螞蟻 Lookahead 推理加速算法在檢索增強(qiáng)生成(RAG)場景及公開數(shù)據(jù)集進(jìn)行了測試。
-
在螞蟻內(nèi)部的 RAG 數(shù)據(jù)集上,AntGLM10B 模型的加速比達(dá)到 5.36,token 生成速度 280 個(gè)/秒;
-
在 Dolly15k 及 GSM8K 數(shù)據(jù)集上, 多個(gè)開源模型都 有 2 倍以上的加速比,與此同時(shí),顯存增加和內(nèi)存消耗幾乎可以忽略。
該算法現(xiàn)已在 GitHub 上開源,相關(guān)論文也已公布在 ARXIV。感興趣的同學(xué)可以閱讀下相關(guān)論文了解更多技術(shù)細(xì)節(jié),運(yùn)行下源碼查看效果。
論文地址 : https://arxiv.org/abs/2312.12728
代碼倉庫: https://github.com/alipay/PainlessInferenceAcceleration
- END - ?? 關(guān)注「HelloGitHub」收到第一時(shí)間的更新 ??