
現(xiàn)在開始:用你的Mac訓練和部署一個圖片分類模型
文末福利:開發(fā)者藏經(jīng)閣
可能有些同學學習機器學習的時候比較迷茫,不知道該怎么上手,看了很多經(jīng)典書籍介紹的各種算法,但還是不知道怎么用它來解決問題,就算知道了,又發(fā)現(xiàn)需要準備環(huán)境、準備訓練和部署的機器,啊,好麻煩。
今天,我來給大家介紹一種容易上手的方法,給你現(xiàn)成的樣本和代碼,按照步驟操作,就可以在自己的 Mac 上體驗運用機器學習的全流程啦~~~
下面的 Demo, 最終的效果是給定一張圖片,可以預測圖片的類別。比如我們訓練模型用的樣本是貓啊狗啊,那模型能學到的認識的就是貓啊狗啊, 如果用的訓練樣本是按鈕啊搜索框啊,那模型能學到的認識的就是這個按鈕啊搜索框啊。
如果想了解用機器學習是怎么解決實際問題的,可以看這篇:如何使用深度學習識別UI界面組件?(https://juejin.im/post/5e781a78e51d45271c3016db)從問題定義、算法選型、樣本準備、模型訓練、模型評估、模型服務部署、到模型應用都有介紹。
NO.1
環(huán)境準備
安裝 Anaconda
下載地址:https://www.anaconda.com/products/individual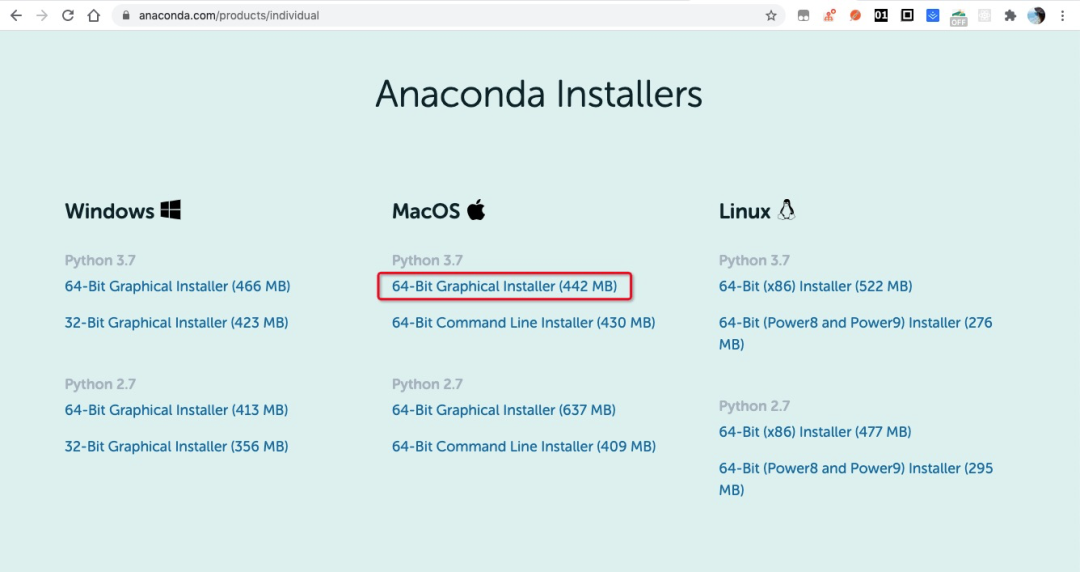
安裝成功后,在終端命令行執(zhí)行以下命令,使環(huán)境變量立即生效:
$ source ~/.bashrc
可以執(zhí)行以下命令,查看環(huán)境變量
$ cat ~/.bashrc
可以看到 anaconda 的環(huán)境變量已經(jīng)自動添加到 .bashrc 文件了
執(zhí)行以下命令:
$ conda list
可以看到 Anaconda 中有很多已經(jīng)安裝好的包,如果有使用到這些包的就不需要再安裝了,python 環(huán)境也裝好了。
注意:如果安裝失敗,重新安裝,在提示安裝在哪里時,選擇「更改安裝位置」,安裝位置選擇其他地方不是用默認的,安裝在哪里自己選擇,可以放在「應用程序」下。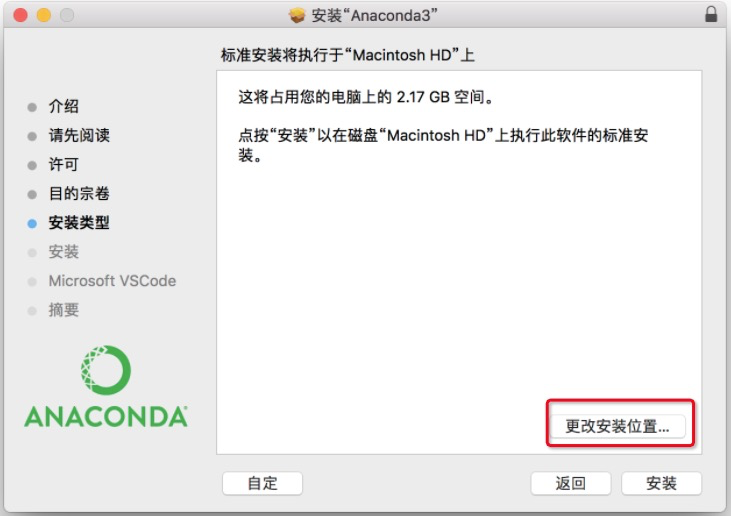
安裝相關依賴
anaconda 中沒有 keras、tensorflow 和 opencv-python, 需要單獨安裝。
$ pip install keras
$ pip install tensorflow
$ pip install opencv-python
NO.2
樣本準備
這里只準備了 4 個分類:button、keyboard、searchbar、switch, 每個分類 200 個左右的樣本。



NO.3
模型訓練
開發(fā)訓練邏輯
新建一個項目 train-project, 文件結構如下:
.
├── CNN_net.py
├── dataset
├── nn_train.py
└── utils_paths.py
入口文件代碼如下,這里的邏輯是將準備好的樣本輸入給圖像分類算法 SimpleVGGNet, 并設置一些訓練參數(shù),例如學習率、Epoch、Batch Size, 然后執(zhí)行這段訓練邏輯,最終得到一個模型文件。
# nn_train.py
from CNN_net import SimpleVGGNet
from sklearn.preprocessing import LabelBinarizer
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from keras.optimizers import SGD
from keras.preprocessing.image import ImageDataGenerator
import utils_paths
import matplotlib.pyplot as plt
from cv2 import cv2
import numpy as np
import argparse
import random
import pickle
import os
# 讀取數(shù)據(jù)和標簽
print("------開始讀取數(shù)據(jù)------")
data = ]
labels = []
# 拿到圖像數(shù)據(jù)路徑,方便后續(xù)讀取
imagePaths = sorted(list(utils_paths.list_images('./dataset')))
random.seed(42)
random.shuffle(imagePaths)
image_size = 256
# 遍歷讀取數(shù)據(jù)
for imagePath in imagePaths:
# 讀取圖像數(shù)據(jù)
image = cv2.imread(imagePath)
image = cv2.resize(image, (image_size, image_size))
data.append(image)
# 讀取標簽
label = imagePath.split(os.path.sep)[-2]
labels.append(label)
data = np.array(data, dtype="float") / 255.0
labels = np.array(labels)
# 數(shù)據(jù)集切分
(trainX, testX, trainY, testY) = train_test_split(data,labels, test_size=0.25, random_state=42)
# 轉換標簽為one-hot encoding格式
lb = LabelBinarizer()
trainY = lb.fit_transform(trainY)
testY = lb.transform(testY)
# 數(shù)據(jù)增強處理
aug = ImageDataGenerator(
rotation_range=30,
width_shift_range=0.1,
height_shift_range=0.1,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode="nearest")
# 建立卷積神經(jīng)網(wǎng)絡
model = SimpleVGGNet.build(width=256, height=256, depth=3,classes=len(lb.classes_))
# 設置初始化超參數(shù)
# 學習率
INIT_LR = 0.01
# Epoch
# 這里設置 5 是為了能盡快訓練完畢,可以設置高一點,比如 30
EPOCHS = 5
# Batch Size
BS = 32
# 損失函數(shù),編譯模型
print("------開始訓練網(wǎng)絡------")
opt = SGD(lr=INIT_LR, decay=INIT_LR / EPOCHS)
model.compile(loss="categorical_crossentropy", optimizer=opt,metrics=["accuracy"])
# 訓練網(wǎng)絡模型
H = model.fit_generator(
aug.flow(trainX, trainY, batch_size=BS),
validation_data=(testX, testY),
steps_per_epoch=len(trainX) // BS,
epochs=EPOCHS
)
# 測試
print("------測試網(wǎng)絡------")
predictions = model.predict(testX, batch_size=32)
print(classification_report(testY.argmax(axis=1), predictions.argmax(axis=1), target_names=lb.classes_))
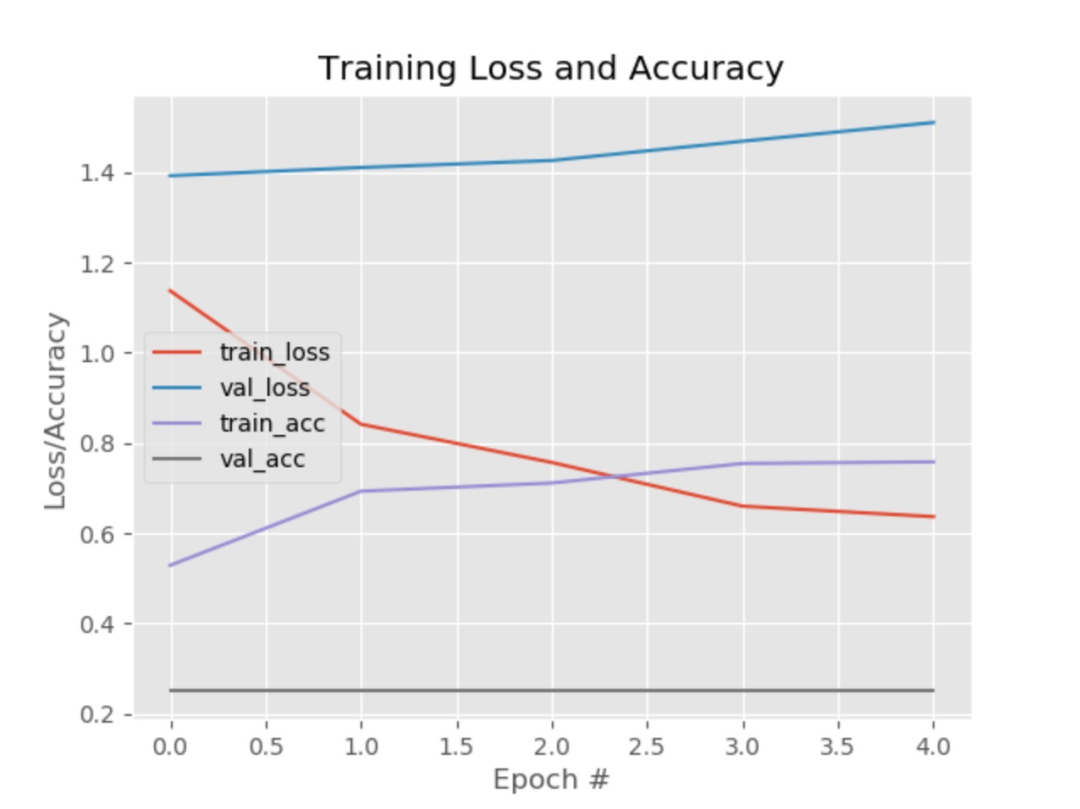
# 繪制結果曲線
N = np.arange(0, EPOCHS)
plt.style.use("ggplot")
plt.figure()
plt.plot(N, H.history["loss"], label="train_loss")
plt.plot(N, H.history["val_loss"], label="val_loss")
plt.plot(N, H.history["accuracy"], label="train_acc")
plt.plot(N, H.history["val_accuracy"], label="val_acc")
plt.title("Training Loss and Accuracy")
plt.xlabel("Epoch #")
plt.ylabel("Loss/Accuracy")
plt.legend()
plt.savefig('./output/cnn_plot.png')
# 保存模型
print("------保存模型------")
model.save('./cnn.model.h5')
f = open('./cnn_lb.pickle', "wb")
f.write(pickle.dumps(lb))
f.close()
對于實際應用場景下,數(shù)據(jù)集很大,epoch 也會設置比較大,并在高性能的機器上訓練。現(xiàn)在要在本機 Mac 上完成訓練任務,我們只給了很少的樣本來訓練模型,epoch 也很小(為 5),當然這樣模型的識別準確率也會很差,但我們此篇文章的目的是為了在本機完成一個機器學習的任務。
開始訓練
執(zhí)行以下命令開始訓練:
$ python nn_train.py
訓練過程日志如下:
訓練結束后,在當前目錄下會生成兩個文件:模型文件 cnn.model.h5 和 損失函數(shù)曲線 output/cnn_plot.png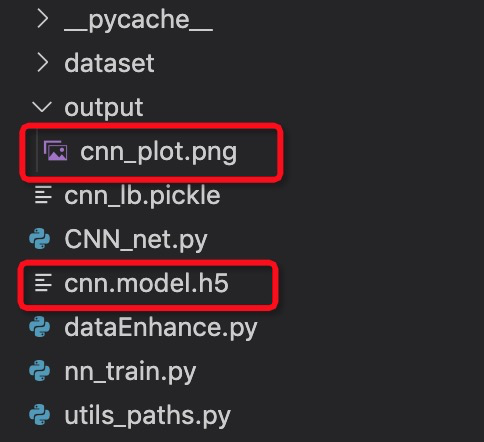
NO.4
模型評估
現(xiàn)在,我們拿到了模型文件 cnn.model.h5, 可以寫一個預測腳本,本地執(zhí)行腳本預測一張圖片的分類。
$ python predict.py
# predict.py
import allspark
import io
import numpy as np
import json
from PIL import Image
import requests
import threading
import cv2
import os
import tensorflow as tf
from tensorflow.keras.models import load_model
import time
model = load_model('./train/cnn.model.h5')
# pred的輸入應該是一個images的數(shù)組,而且圖片都已經(jīng)轉為numpy數(shù)組的形式
# pred = model.predict(['./validation/button/button-demoplus-20200216-16615.png'])
#這個順序一定要與label.json順序相同,模型輸出是一個數(shù)組,取最大值索引為預測值
Label = [
"button",
"keyboard",
"searchbar",
"switch"
]
testPath = "./test/button.png"
images = []
image = cv2.imread(testPath)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
image = cv2.resize(image,(256,256))
images.append(image)
images = np.asarray(images)
pred = model.predict(images)
print(pred)
max_ = np.argmax(pred)
print('預測結果為:',Label[max_])
如果想要知道這個模型的準確率,也可以給模型輸入一批帶有已知分類的數(shù)據(jù),通過模型預測后,將模型預測的分類與真實的分類比較,計算出準確率和召回率。
NO.5
模型服務部署
開發(fā)模型服務
但在實際應用中,我們預測一張圖片的類別, 是通過給定一張圖片,請求一個 API 來拿到返回結果的。我們需要編寫一個模型服務,然后部署到遠端,拿到一個部署之后的模型服務 API。
現(xiàn)在,我們可以編寫一個模型服務,然后在本地部署。
# 模型服務 app.py
import allspark
import io
import numpy as np
import json
from PIL import Image
import requests
import threading
import cv2
import tensorflow as tf
from tensorflow.keras.models import load_model
with open('label.json') as f:
mp = json.load(f)
labels = {value:key for key,value in mp.items()}
def create_opencv_image_from_stringio(img_stream, cv2_img_flag=-1):
img_stream.seek(0)
img_array = np.asarray(bytearray(img_stream.read()), dtype=np.uint8)
image_temp = cv2.imdecode(img_array, cv2_img_flag)
if image_temp.shape[2] == 4:
image_channel3 = cv2.cvtColor(image_temp, cv2.COLOR_BGRA2BGR)
image_mask = image_temp[:,:,3] #.reshape(image_temp.shape[0],image_temp.shape[1], 1)
image_mask = np.stack((image_mask, image_mask, image_mask), axis = 2)
index_mask = np.where(image_mask == 0)
image_channel3[index_mask[0], index_mask[1], index_mask[2]] = 255
return image_channel3
else:
return image_temp
def get_string_io(origin_path):
r = requests.get(origin_path, timeout=2)
stringIo_content = io.BytesIO(r.content)
return stringIo_content
def handleReturn(pred, percent, msg_length):
result = {
"content":[]
}
argm = np.argsort(-pred, axis = 1)
for i in range(msg_length):
label = labels[argm[i, 0]]
index = argm[i, 0]
if(pred[i, index] > percent):
confident = True
else:
confident = False
result['content'].append({'isConfident': confident, 'label': label})
return result
def process(msg, model):
msg_dict = json.loads(msg)
percent = msg_dict['threshold']
msg_dict = msg_dict['images']
msg_length = len(msg_dict)
desire_size = 256
images = []
for i in range(msg_length):
image_temp = create_opencv_image_from_stringio(get_string_io(msg_dict[i]))
image_temp = cv2.cvtColor(image_temp, cv2.COLOR_BGR2RGB)
image = cv2.resize(image_temp, (256, 256))
images.append(image)
images = np.asarray(images)
pred = model.predict(images)
return bytes(json.dumps(handleReturn(pred, percent, msg_length)) ,'utf-8')
def worker(srv, thread_id, model):
while True:
msg = srv.read()
try:
rsp = process(msg, model)
srv.write(rsp)
except Exception as e:
srv.error(500,bytes('invalid data format', 'utf-8'))
if __name__ == '__main__':
desire_size = 256
model = load_model('./cnn.model.h5')
context = allspark.Context(4)
queued = context.queued_service()
workers = []
for i in range(10):
t = threading.Thread(target=worker, args=(queued, i, model))
t.setDaemon(True)
t.start()
workers.append(t)
for t in workers:
t.join()
部署模型服務
模型服務編寫完成后,在本地部署,需要安裝環(huán)境。首先創(chuàng)建一個模型服務項目: deploy-project, 將 cnn.model.h5 拷貝到此項目中, 并在此項目下安裝環(huán)境。
.
├── app.py
├── cnn.model.h5
└── label.json
安裝環(huán)境
可以看下[阿里云的模型服務部署文檔(https://www.alibabacloud.com/help/zh/doc-detail/126314.htm?#h2-3-python-3):3、Python語言-3.2 構建開發(fā)環(huán)境-3.2.3 使用預構建的開發(fā)鏡像(推薦)
安裝 Docker
可以直接查看?Mac Docker 安裝文檔(https://www.runoob.com/docker/macos-docker-install.html)
# 用 Homebrew 安裝 需要先現(xiàn)狀 Homebrew: https://brew.sh
$ brew cask install docker
安裝完之后,桌面上會出現(xiàn) Docker 的圖標。
創(chuàng)建 anaconda 的虛擬環(huán)境
# 使用conda創(chuàng)建python環(huán)境,目錄需指定固定名字:ENV
$ conda create -p ENV python=3.7
# 安裝EAS python sdk
$ ENV/bin/pip install http://eas-data.oss-cn-shanghai.aliyuncs.com/sdk/allspark-0.9-py2.py3-none-any.whl
# 安裝其它依賴包
$ ENV/bin/pip install tensorflow keras opencv-python
# 激活虛擬環(huán)境
$ conda activate ./ENV
# 退出虛擬環(huán)境(不使用時)
$ conda deactivate
運行 Docker 環(huán)境
/Users/chang/Desktop/ml-test/deploy-project 換成自己的項目路徑
sudo docker run -ti -v /Users/chang/Desktop/ml-test/deploy-project:/home -p 8080:8080
registry.cn-shanghai.aliyuncs.com/eas/eas-python-base-image:py3.6-allspark-0.8
本地部署
現(xiàn)在可以本地部署了,執(zhí)行以下命令:
cd /home
./ENV/bin/python app.py
下面的日志可以看到部署成功。
部署成功后,可以通過 localhost:8080/predict 訪問模型服務了。
我們用 curl 命令來發(fā)一個 post 請求, 預測圖片分類:
curl -X POST 'localhost:8080/predict' \
-H 'Content-Type: application/json' \
-d '{
"images": "https://img.alicdn.com/tfs/TB1W8K2MeH2gK0jSZJnXXaT1FXa-638-430.png"],
"threshold": 0.5
}'
得到預測結果:
{"content": [{"isConfident": true, "label": "keyboard"}]}
NO.6
完整代碼
可以直接 clone 代碼倉庫:[https://github.com/imgcook/ml-mac-classify(https://github.com/imgcook/ml-mac-classify)
在安裝好環(huán)境后,直接按以下命令運行。
# 1、訓練模型
$ cd train-project
$ python nn_train.py
# 生成模型文件:cnn.model.h5
# 2、將模型文件拷貝到 deploy-project 中,部署模型服務
# 先安裝模型服務運行環(huán)境
$ conda activate ./ENV
$ sudo docker run -ti -v /Users/chang/Desktop/ml-test/deploy-project:/home -p 8080:8080 registry.cn-shanghai.aliyuncs.com/eas/eas-python-base-image:py3.6-allspark-0.8
$ cd /home
$ ./ENV/bin/python app.py
# 得到模型服務 API:localhost:8080/predict
# 3、訪問模型服務
curl -X POST 'localhost:8080/predict' \
-H 'Content-Type: application/json' \
-d '{
"images": ["https://img.alicdn.com/tfs/TB1W8K2MeH2gK0jSZJnXXaT1FXa-638-430.png"],
"threshold": 0.5
}'
NO.7
最后
好啦,總結一下這里使用深度學習的流程。我們選用了 SimpleVGGNet 作為圖像分類算法(相當于一個函數(shù)),將準備好的數(shù)據(jù)傳給這個函數(shù),運行這個函數(shù)(學習數(shù)據(jù)集的特征和標簽)得到一個輸出,就是模型文件 model.h5。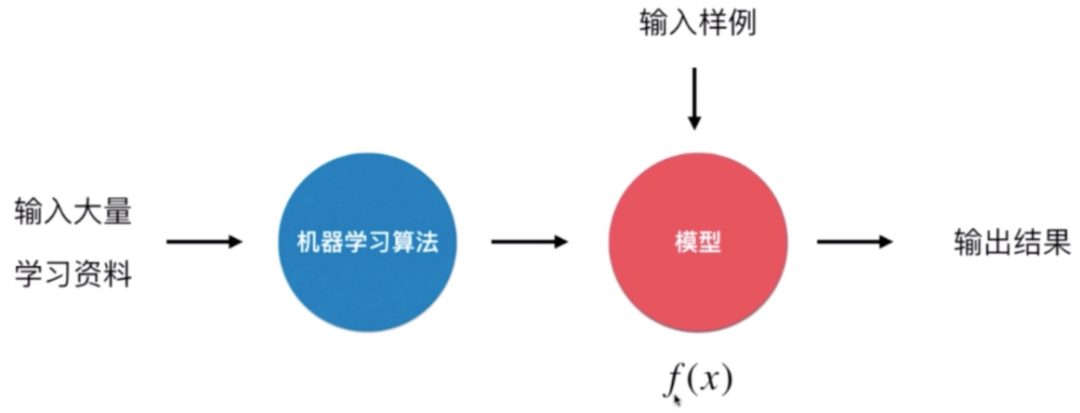
這個模型文件可以接收一張圖片作為輸入,并預測這張圖片是什么,輸出預測結果。但如果想要讓模型可以在線上跑,需要寫一個模型服務(API)并部署到線上以得到一個 HTTP API,我們可以在生產(chǎn)環(huán)境直接調用。
推薦閱讀
2、你不知道的 TypeScript 泛型(萬字長文,建議收藏)
3、你不知道的 Web Workers (萬字長文,建議收藏)
4、immutablejs 是如何優(yōu)化我們的代碼的?
5、或許是一本可以徹底改變你刷 LeetCode 效率的題解書
6、想去力扣當前端,TypeScript 需要掌握到什么程度?
?關注加加,星標加加~
?
如果覺得文章不錯,幫忙點個在看唄