
Python 教你訓練一個98%準確率的微博抑郁文本分類模型(含數(shù)據(jù))
Paddle是一個比較高級的深度學習開發(fā)框架,其內置了許多方便的計算單元可供使用,我們之前寫過PaddleHub相關的文章:
在這些文章里面,我們基于PaddleHub訓練好的模型直接進行預測,用起來特別方便。不過,我并沒提到如何用自己的數(shù)據(jù)進行訓練,因此本文將彌補前幾篇文章缺少的內容,講解如何使用paddle訓練、測試、推斷自己的數(shù)據(jù)。
1.準備
開始之前,你要確保Python和pip已經成功安裝在電腦上噢,如果沒有,請訪問這篇文章:超詳細Python安裝指南 進行安裝。
Windows環(huán)境下打開Cmd(開始—運行—CMD),蘋果系統(tǒng)環(huán)境下請打開Terminal(command+空格輸入Terminal),準備開始輸入命令安裝依賴。
當然,我更推薦大家用VSCode編輯器,把本文代碼Copy下來,在編輯器下方的終端裝依賴模塊,多舒服的一件事啊:Python 編程的最好搭檔—VSCode 詳細指南。
然后,我們需要安裝百度的paddlepaddle, 進入他們的官方網站就有詳細的指引:
https://www.paddlepaddle.org.cn/install/quick
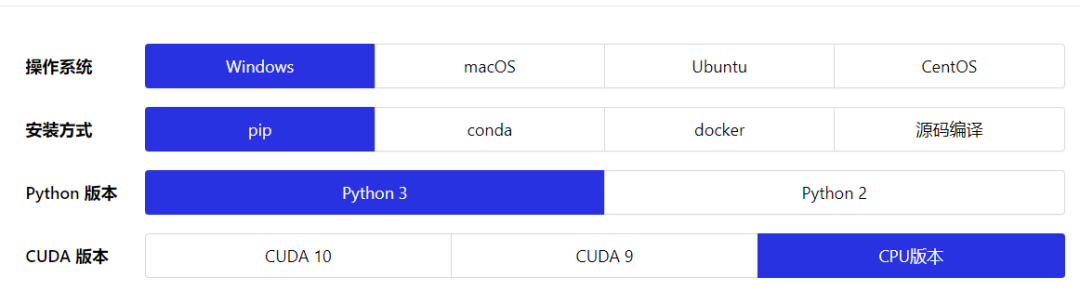
根據(jù)你自己的情況選擇這些選項,最后一個CUDA版本,由于本實驗不需要訓練數(shù)據(jù),也不需要太大的計算量,所以直接選擇CPU版本即可。選擇完畢,下方會出現(xiàn)安裝指引,不得不說,Paddlepaddle這些方面做的還是比較貼心的(就是名字起的不好)。
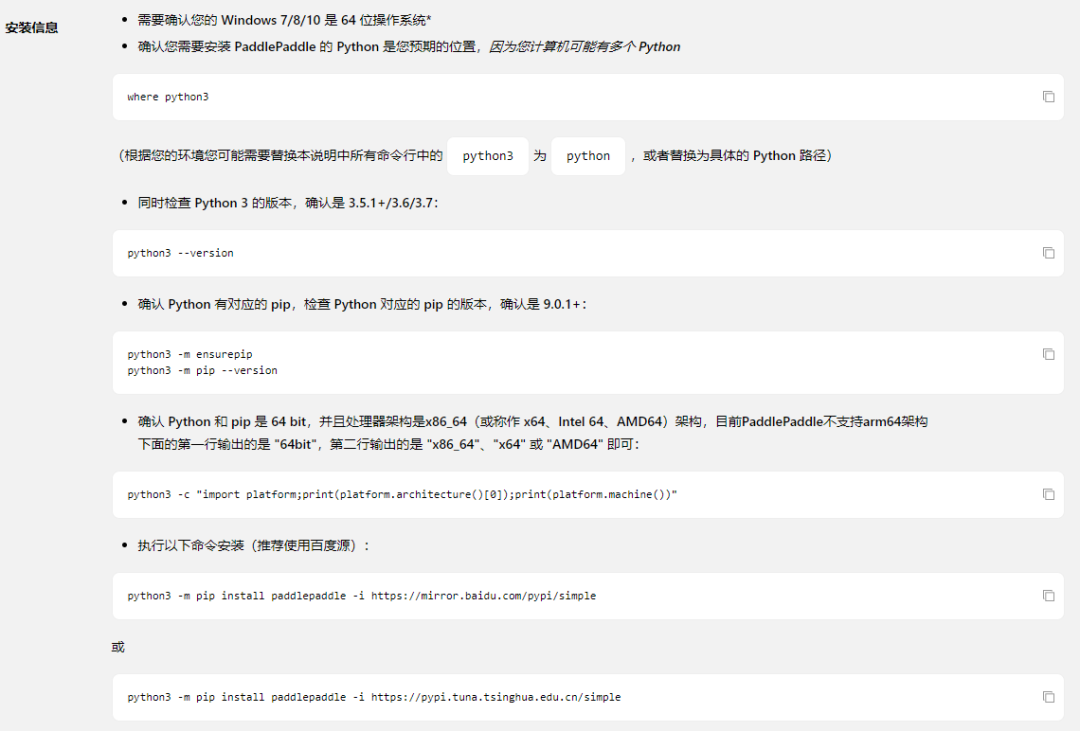
要注意,如果你的Python3環(huán)境變量里的程序名稱是Python,記得將python3 xxx 語句改為Python xxx 如下進行安裝:
python -m pip install paddlepaddle -i https://mirror.baidu.com/pypi/simple然后你還需要安裝paddlehub:
pip install -i https://mirror.baidu.com/pypi/simple paddlehub
如果你需要本文的抑郁文本數(shù)據(jù),請在Python實用寶典后臺回復【微博抑郁文本】下載,總計9000條,如果不夠你使用,可以參考下面這篇文章爬取數(shù)據(jù):
2. 數(shù)據(jù)預處理
這次實驗,我使用了8000條走飯下面的評論和8000條其他微博的正常評論作為訓練集,兩個分類分別使用1000條數(shù)據(jù)作為測試集。
2.1 去重去臟
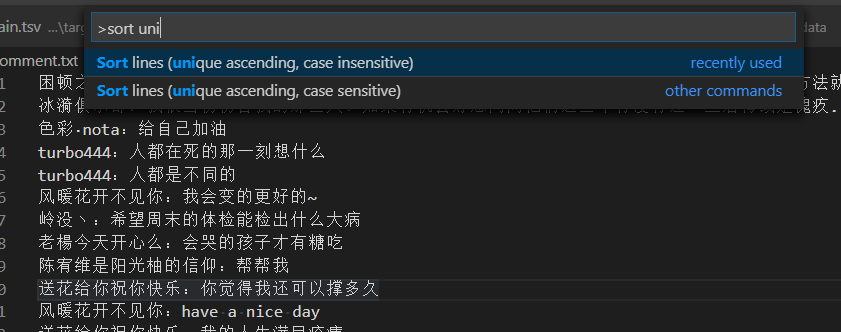
在這一步,我們需要先去除重復數(shù)據(jù),并使用正則表達式@.* 和 ^@.*\n 去除微博@的臟數(shù)據(jù)。如果你是使用Vscode的,可以使用sort lines插件去除重復數(shù)據(jù):
如果不是Vscode,請用Python寫一個腳本,遍歷文件,將每一行放入集合中進行去重。比較簡單,這里不贅述啦。
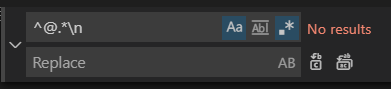
正則表達式去除臟數(shù)據(jù),我這里數(shù)據(jù)量比較少,直接編輯器解決了:
2.2 分詞
首先,需要對我們的文本數(shù)據(jù)進行分詞,這里我們采用結巴分詞的形式進行:

然后需要在分詞的結果后面使用\t隔開加入標簽,我這里是將有抑郁傾向的句子標為0,將正常的句子標為1. 此外,還需要將所有詞語保存起來形成詞典文件,每個詞為一行。
并分別將訓練集和測試集保存為 train.tsv 和 dev.tsv, 詞典文件命名為word_dict.txt, 方便用于后續(xù)的訓練。
3.訓練
下載完Paddle模型源代碼后,進入 models/PaddleNLP/sentiment_classification文件夾下,這里是情感文本分類的源代碼部分。
在開始訓練前,你需要做以下工作:
1. 將train.tsv、dev.tsv及word_dict.txt放入senta_data文件夾.
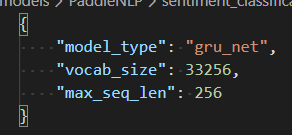
2. 設置senta_config.json的模型類型,我這里使用的是gru_net:
3. 修改run.sh相關的設置:
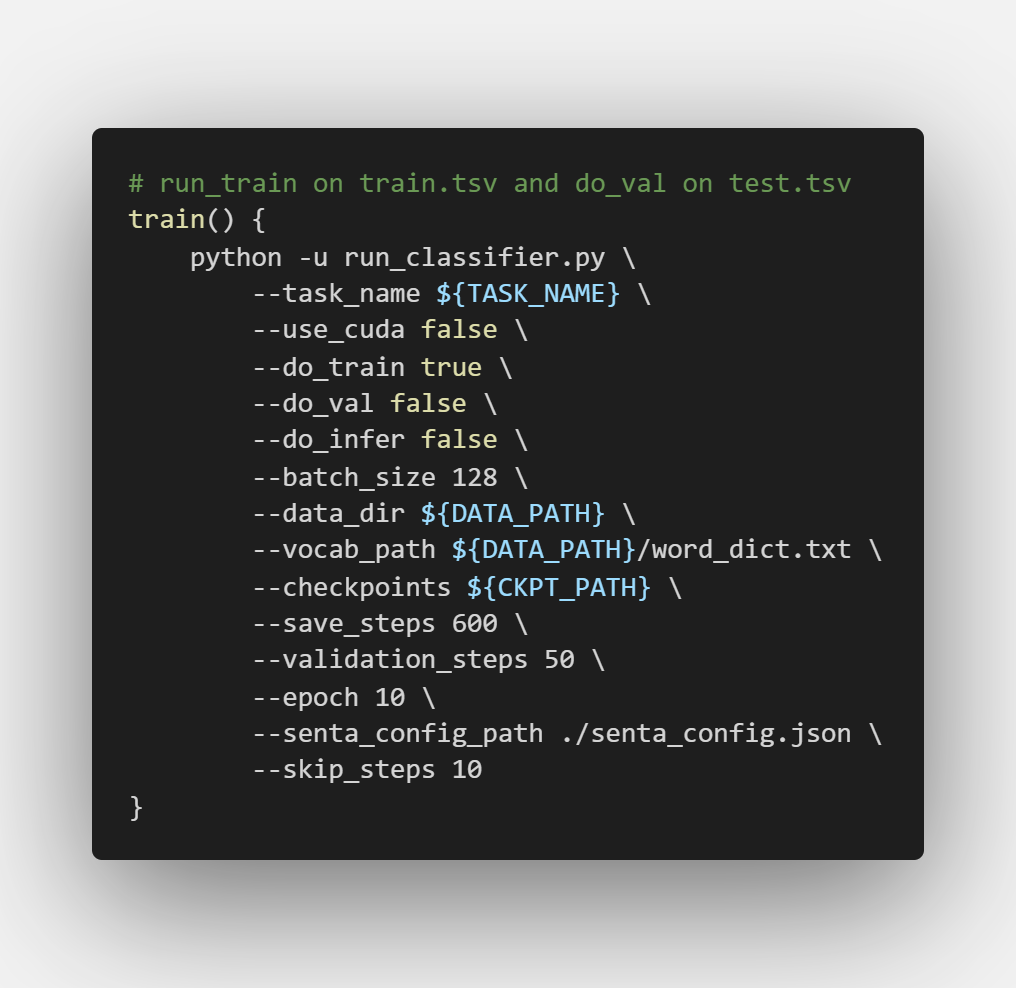
如果你的paddle是CPU版本的,請把use_cuda改為false。此外還有一個save_steps要修改,代表每訓練多少次保存一次模型,還可以修改一下訓練代數(shù)epoch,和 一次訓練的樣本數(shù)目 batch_size.
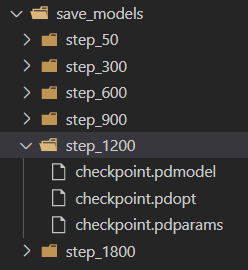
4. 如果你是windows系統(tǒng),還要新建一個save_models文件夾,然后在里面分別以你的每訓練多少次保存一次的數(shù)字再新建文件夾。。沒錯,這可能是因為他們開發(fā)這個框架的時候是基于linux的,他們寫的保存語句在linux下會自動生成文件夾,但是windows里不會。
現(xiàn)在可以開始訓練了,由于訓練啟動腳本是shell腳本,因此我們要用powershell或git bash運行指令,Vscode中可以選擇默認的終端,點擊Select Default Shell后選擇一個除cmd外的終端即可。
輸入以下語句開始訓練
sh run.sh train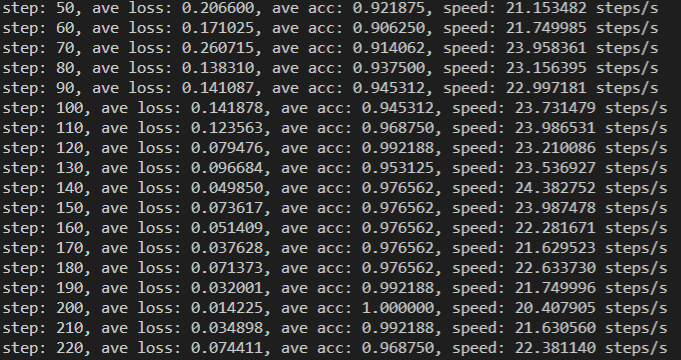
4.測試
恭喜你走到了這一步,作為獎勵,這一步你只需要做兩個操作。首先是將run.sh里的MODEL_PATH修改為你剛保存的模型文件夾:
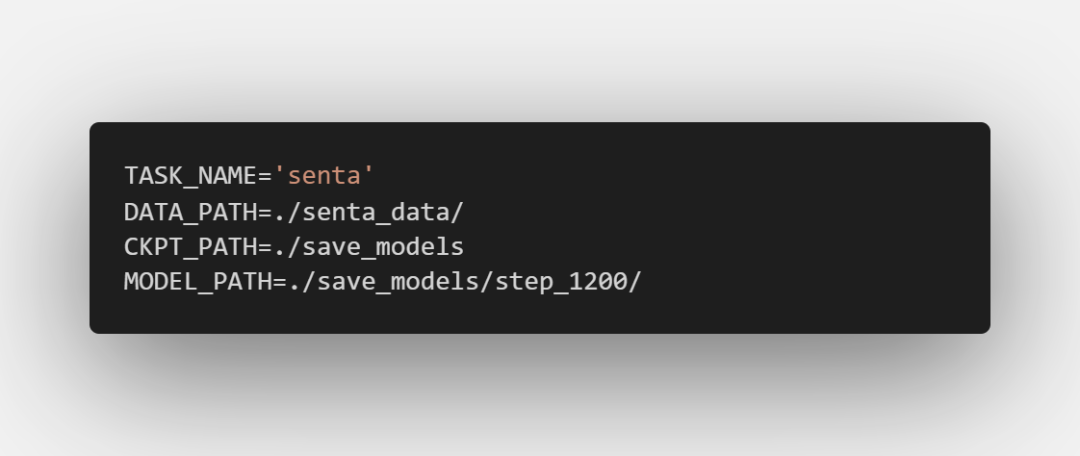
我這里最后一次訓練保存的文件夾是step_1200,因此填入step_1200,要依據(jù)自己的情況填入。然后一句命令就夠了:
sh run.sh eval
可以看到我的模型準確率大概有98%,還是挺不錯的。
5.預測
我們隨意各取10條抑郁言論和普通言論,命名為test.txt存入senta_data文件夾中,輸入以下命令進行預測:
sh run.sh test這二十條句子如下,前十條是抑郁言論,后十條是普通言論:
好崩潰每天都是折磨真的生不如死
姐姐 我可以去找你嗎
內心陰暗至極……
大家今晚都是因為什么沒睡
既然兒子那么好 那就別生下我啊 生下我又把我扔下 讓我自生自滅 這算什么
走飯小姐姐怎么辦我該怎么辦每天都心酸心如刀絞每天都有想要死掉的念頭我不想那么痛苦了
你憑什么那么輕松就說出這種話
一閉上眼睛腦子里浮現(xiàn)的就是他的臉和他的各種點點滴滴好難受睡不著啊好難受為什么吃了這么多東西還是不快樂呢
以前我看到那些有手有腳的人在乞討我都看不起他們 我覺得他們有手有腳的不應該乞討他們完全可以憑自己的雙手掙錢 但是現(xiàn)在我有手有腳我也想去人多的地方乞討…我不想努力了…
熬過來吧求求你了好嗎
是在說我們合肥嗎?
這歌可以啊
用一個更壞的消息掩蓋這一個壞消息
請尊重他人隱私這種行為必須嚴懲不貸
這個要轉發(fā)
????保佑咱們國家各個省千萬別再有出事的也別瞞報大家一定要好好的堅持到最后加油
我在家比在學校有錢 在家吃飯零食水果奶都是我媽天天給我買 每天各種水果 還可以壓榨我弟跑腿 買衣服也是 水乳也是 除了化妝品反正現(xiàn)在也用不上 比學校的日子過得好多了
廣西好看的是柳州的滿城紫荊花
加油一起共同度過這次難關我們可以
平安平安老天保佑
得到結果如下:
Final test result:
0 0.999999 0.000001
0 0.994013 0.005987
0 0.997636 0.002364
0 0.999975 0.000025
0 1.000000 0.000000
0 1.000000 0.000000
0 0.999757 0.000243
0 0.999706 0.000294
0 0.999995 0.000005
0 0.998472 0.001528
1 0.000051 0.999949
1 0.000230 0.999770
1 0.230227 0.769773
1 0.000000 1.000000
1 0.000809 0.999191
1 0.000001 0.999999
1 0.009213 0.990787
1 0.000003 0.999997
1 0.000363 0.999637
1 0.000000 1.000000第一列是預測結果(0代表抑郁文本),第二列是預測為抑郁的可能性,第三列是預測為正常微博的可能性。可以看到,基本預測正確,而且根據(jù)這個分數(shù)值,我們還可以將文本的抑郁程度分為:輕度、中度、重度,如果是重度抑郁,應當加以干預,因為其很可能會發(fā)展成自殺傾向。
我們可以根據(jù)這個模型,構建一個自殺預測監(jiān)控系統(tǒng),一旦發(fā)現(xiàn)重度抑郁的文本跡象,即可實行干預,不過這不是我們能一下子做到的事情,需要隨著時間推移慢慢改進這個識別算法,并和相關機構聯(lián)動實行干預。
如果你需要本文的抑郁文本數(shù)據(jù),請在Python實用寶典后臺回復【微博抑郁文本】下載,總計9000條,如果不夠你使用,可以參考下面這篇文章爬取數(shù)據(jù):
如果你喜歡今天的Python 教程,請持續(xù)關注Python實用寶典,如果對你有幫助,麻煩在下面點一個贊/在看 ,有任何問題都可以在下方留言,我們會耐心解答的!
,有任何問題都可以在下方留言,我們會耐心解答的!
點擊下方閱讀原文可以獲取所有代碼和鏈接哦!
Python實用寶典 (pythondict.com)
不只是一個寶典