
基于Pytorch的動態(tài)卷積復現(xiàn)
【GaintPandaCV導語】 最近動態(tài)卷積開始有人進行了研究,也有不少的論文發(fā)表(動態(tài)卷積論文合集https://github.com/kaijieshi7/awesome-dynamic-convolution),但是動態(tài)卷積具體的實現(xiàn)代碼卻很少有文章給出。本文以微軟發(fā)表在CVPR2020上面的文章為例,詳細的講解了動態(tài)卷積實現(xiàn)的難點以及如何動分組卷積巧妙的解決。希望能給大家以啟發(fā)。
這篇文章也同步到知乎平臺,鏈接為:https://zhuanlan.zhihu.com/p/208519425
論文的題目為《Dynamic Convolution: Attention over Convolution Kernels》
paper的地址arxiv.org/pdf/1912.0345
代碼實現(xiàn)地址,其中包含一維,二維,三維的動態(tài)卷積;分別可以用于實現(xiàn)eeg的處理,正常圖像的處理,醫(yī)療圖像中三維腦部的處理等等(水漫金山)。github.com/kaijieshi7/D,大家覺得有幫助的話,可以點個星星。
一句話描述下文的內(nèi)容:將? ?的大小視為分組卷積里面的組的大小進行動態(tài)卷積。如?
?的大小視為分組卷積里面的組的大小進行動態(tài)卷積。如? ?,那么就轉化成?
?,那么就轉化成? ?,?
?,? ?的分組卷積。
?的分組卷積。
簡單回顧
這篇文章主要是改進傳統(tǒng)卷積,讓每層的卷積參數(shù)在推理的時候也是隨著輸入可變的,而不是傳統(tǒng)卷積中對任何輸入都是固定不變的參數(shù)。(由于本文主要說明的是代碼如何實現(xiàn),所以推薦給大家一個講解論文的連接:Happy:動態(tài)濾波器卷積|DynamicConv)
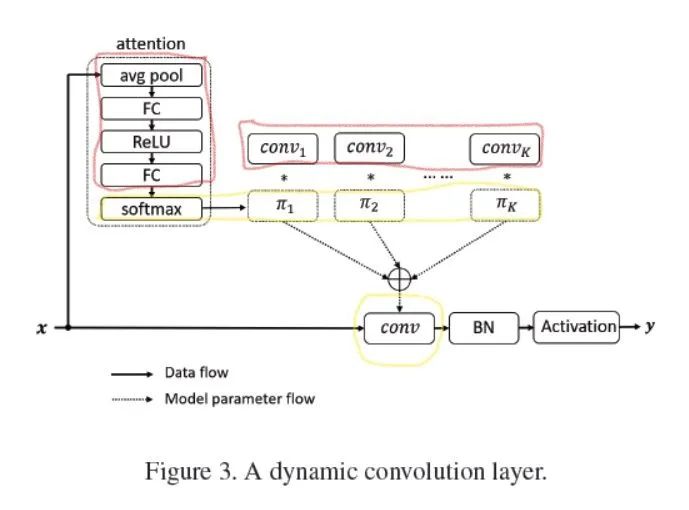
對于卷積過程中生成的一個特征圖? ?,先對特征圖做幾次運算,生成?
?,先對特征圖做幾次運算,生成? ?個和為?
?個和為? ?的參數(shù)?
?的參數(shù)? ?,然后對??個卷積核參數(shù)進行線性求和,這樣推理的時候卷積核是隨著輸入的變化而變化的。(可以看看其他的講解文章,本文主要理解怎么寫代碼)
?,然后對??個卷積核參數(shù)進行線性求和,這樣推理的時候卷積核是隨著輸入的變化而變化的。(可以看看其他的講解文章,本文主要理解怎么寫代碼)
下面是attention代碼的簡易版本,輸出的是[??,??]大小的加權參數(shù)。??對應著要被求和的卷積核數(shù)量。
class attention2d(nn.Module):
def __init__(self, in_planes, K,):
super(attention2d, self).__init__()
self.avgpool = nn.AdaptiveAvgPool2d(1)
self.fc1 = nn.Conv2d(in_planes, K, 1,)
self.fc2 = nn.Conv2d(K, K, 1,)
def forward(self, x):
x = self.avgpool(x)
x = self.fc1(x)
x = F.relu(x)
x = self.fc2(x).view(x.size(0), -1)
return F.softmax(x, 1)下面是文章中??個卷積核求和的公式。

其中??是輸入,? ?是輸出;可以看到??進行了兩次運算,一次用于求注意力的參數(shù)(用于生成動態(tài)的卷積核),一次用于被卷積。
?是輸出;可以看到??進行了兩次運算,一次用于求注意力的參數(shù)(用于生成動態(tài)的卷積核),一次用于被卷積。
但是,寫代碼的時候如果直接將??個卷積核求和,會出現(xiàn)問題。接下來我們先回顧一下Pytorch里面的卷積參數(shù),然后描述一下可能會出現(xiàn)的問題,再講解如何通過分組卷積去解決問題。
Pytorch卷積的實現(xiàn)
我會從維度的視角回顧一下Pytorch里面的卷積的實現(xiàn)(大家也可以手寫一下,幾個重點:輸入維度、輸出維度、正常卷積核參數(shù)維度、分組卷積維度、動態(tài)卷積維度、attention模塊輸出維度)。
輸入:輸入數(shù)據(jù)維度大小為[?,? ?,?
?,? ?,?
?,? ?]。
?]。
輸出:輸出維度為[??,? ?,??,??]。
?,??,??]。
卷積核:正常卷積核參數(shù)維度為[??,??,? ?,??]。(在Pytorch中,2d卷積核參數(shù)應該是固定這種維度的)
?,??]。(在Pytorch中,2d卷積核參數(shù)應該是固定這種維度的)
這里我們可以注意到,正常卷積核參數(shù)的維度是不存在??的。因為對于正常的卷積來說,不同的輸入數(shù)據(jù),使用的是相同的卷積核,卷積核的數(shù)量與一次前向運算所輸入的??大小無關(相同層的卷積核參數(shù)只需要一份)。
可能會出現(xiàn)的問題
這里描述一下實現(xiàn)動態(tài)卷積代碼的過程中可能因為??大于1而出現(xiàn)的問題。
對于圖中attention模塊最后softmax輸出的??個數(shù),他們的維度為[??,??,??,??],可以直接.view成[??,??],緊接著??作用于??卷積核參數(shù)上(形成動態(tài)卷積)。
問題所在:正常卷積,一次輸入多個數(shù)據(jù),他們的卷積核參數(shù)是一樣的,所以只需要一份網(wǎng)絡參數(shù)即可;但是對于動態(tài)卷積而言,每個輸入數(shù)據(jù)用的都是不同的卷積核,所以需要??份網(wǎng)絡參數(shù),不符合Pytorch里面的卷積參數(shù)格式,會出錯。
看下維度運算[??,??]*[??,??,??,??,??],生成的動態(tài)卷積核是[??,??,??,??,??],不符合Pytorch里面的規(guī)定,不能直接參與運算(大家可以按照這個思路寫個代碼看看,體會一下,光看可能感覺不出來問題),最簡單的解決辦法就是??等于1,不會出現(xiàn)錯誤,但是慢啊!!!
總之,??大于1會導致中間卷積核參數(shù)不符合規(guī)定。
分組卷積以及如何通過分組卷積實現(xiàn)??大于1的動態(tài)卷積
一句話描述分組卷積:對于多通道的輸入,將他們分成幾部分各自進行卷積,結果concate。
組卷積過程用廢話描述:對于輸入的數(shù)據(jù)[??,??,??,??],假設??為? ?,那么分組卷積就是將他分為兩個??為?
?,那么分組卷積就是將他分為兩個??為? ?的數(shù)據(jù)(也可以用其他方法分),那么維度就是[??, 5x2?,??,??],換個維度換下視角,[?
?的數(shù)據(jù)(也可以用其他方法分),那么維度就是[??, 5x2?,??,??],換個維度換下視角,[? ?,??,??,??],那么?
?,??,??,??],那么? ?為2的組卷積可以看成??的正常卷積。(如果還是有點不了解分組卷積,可以閱讀其他文章仔細了解一下。)
?為2的組卷積可以看成??的正常卷積。(如果還是有點不了解分組卷積,可以閱讀其他文章仔細了解一下。)
巧妙的轉換:上面將??翻倍即可將分組卷積轉化成正常卷積,那么反向思考一下,將??變?yōu)?,是不是可以將正常卷積變成分組卷積?
我們將??大小看成分組卷積中??的數(shù)量,令??所在維度直接變?yōu)?/span>??!!!直接將輸入數(shù)據(jù)從[??,? ?,??,??]變成[1,?
?,??,??]變成[1,? ?,??,??],就可以用分組卷積解決問題了!!!
?,??,??],就可以用分組卷積解決問題了!!!
詳細描述實現(xiàn)過程:將輸入數(shù)據(jù)的維度看成[1,??,??,??](分組卷積的節(jié)奏);卷積權重參數(shù)初始化為[??,? ?,??,??,??],attention模塊生成的維度為[??,??],直接進行正常的矩陣乘法[??,??]*[??,??*?*??*??]生成動態(tài)卷積的參數(shù),生成的動態(tài)卷積權重維度為[??,??,??,??,??],將其看成分組卷積的權重[?
?,??,??,??],attention模塊生成的維度為[??,??],直接進行正常的矩陣乘法[??,??]*[??,??*?*??*??]生成動態(tài)卷積的參數(shù),生成的動態(tài)卷積權重維度為[??,??,??,??,??],將其看成分組卷積的權重[? ?,??,??,??](過程中包含reshape)。這樣的處理就完成了,輸入數(shù)據(jù)[??,?
?,??,??,??](過程中包含reshape)。這樣的處理就完成了,輸入數(shù)據(jù)[??,? ?,??,??],動態(tài)卷積核[??,??,??,??],直接是?
?,??,??],動態(tài)卷積核[??,??,??,??],直接是? ?的分組卷積,問題解決。
?的分組卷積,問題解決。
具體代碼如下:
class Dynamic_conv2d(nn.Module):
def __init__(self, in_planes, out_planes, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True, K=4,):
super(Dynamic_conv2d, self).__init__()
assert in_planes%groups==0
self.in_planes = in_planes
self.out_planes = out_planes
self.kernel_size = kernel_size
self.stride = stride
self.padding = padding
self.dilation = dilation
self.groups = groups
self.bias = bias
self.K = K
self.attention = attention2d(in_planes, K, )
self.weight = nn.Parameter(torch.Tensor(K, out_planes, in_planes//groups, kernel_size, kernel_size), requires_grad=True)
if bias:
self.bias = nn.Parameter(torch.Tensor(K, out_planes))
else:
self.bias = None
def forward(self, x):#將batch視作維度變量,進行組卷積,因為組卷積的權重是不同的,動態(tài)卷積的權重也是不同的
softmax_attention = self.attention(x)
batch_size, in_planes, height, width = x.size()
x = x.view(1, -1, height, width)# 變化成一個維度進行組卷積
weight = self.weight.view(self.K, -1)
# 動態(tài)卷積的權重的生成, 生成的是batch_size個卷積參數(shù)(每個參數(shù)不同)
aggregate_weight = torch.mm(softmax_attention, weight).view(-1, self.in_planes, self.kernel_size, self.kernel_size)
if self.bias is not None:
aggregate_bias = torch.mm(softmax_attention, self.bias).view(-1)
output = F.conv2d(x, weight=aggregate_weight, bias=aggregate_bias, stride=self.stride, padding=self.padding,
dilation=self.dilation, groups=self.groups*batch_size)
else:
output = F.conv2d(x, weight=aggregate_weight, bias=None, stride=self.stride, padding=self.padding,
dilation=self.dilation, groups=self.groups * batch_size)
output = output.view(batch_size, self.out_planes, output.size(-2), output.size(-1))
return output完整的代碼在github.com/kaijieshi7/D,大家覺得有幫助的話,求點個星星。
紙上得來終覺淺,絕知此事要躬行。試下代碼,方能體會其中妙處。
對文章有疑問或者想加入交流群,歡迎添加BBuf微信
為了方便各位獲取公眾號獲取資料,可以加入QQ群獲取資源,更歡迎分享資源