
大模型&ChatGPT對(duì)計(jì)算機(jī)視覺的影響
點(diǎn)擊下方卡片,關(guān)注“新機(jī)器視覺”公眾號(hào)
視覺/圖像重磅干貨,第一時(shí)間送達(dá)
夕小瑤科技說(shuō) 分享
來(lái)源 | CCF計(jì)算機(jī)視覺專委會(huì)
引言 隨著ChatGPT熱潮襲來(lái),大模型如何在計(jì)算機(jī)視覺里發(fā)揮重要作用、如何應(yīng)用大模型服務(wù)各種視覺任務(wù)、如何借助海量數(shù)據(jù)突破算法性能上界等一系列問題,成為學(xué)術(shù)界與產(chǎn)業(yè)界共同關(guān)注的熱點(diǎn)。為此,RACV2023組織了“大模型與ChatGPT對(duì)計(jì)算機(jī)視覺影響”的專題研討會(huì),邀請(qǐng)相關(guān)領(lǐng)域的專家學(xué)者,共同對(duì)大模型及視覺未來(lái)的發(fā)展趨勢(shì)、亟待解決的科學(xué)技術(shù)問題等做了充分的交流與討論。
專題組織者:王井東、王興剛、李弘揚(yáng)
討論時(shí)間:2023年7月24日
引導(dǎo)發(fā)言:陳熙霖、沈春華、代季峰、謝凌曦
參與討論嘉賓(按發(fā)言順序):盧湖川、王興剛、山世光、王菡子、魏云超、林倞、黃高、王濤、胡事民、徐凱、謝凌曦、操曉春、吳小俊、陳寶權(quán)、金連文、查紅彬、肖斌、毋立芳、劉靜、代季峰、湯進(jìn)、吳保元
文字整理:李弘揚(yáng)、汪邦駿
校審發(fā)布:楊巨峰
本文得到CCF-CV專委會(huì)(公眾號(hào): CCF計(jì)算機(jī)視覺專委會(huì))授權(quán)發(fā)布
主講嘉賓發(fā)言實(shí)錄
1.陳熙霖(中國(guó)科學(xué)院計(jì)算技術(shù)研究所)

我是第二次來(lái)RACV,想起一首歌叫‘笨小孩’,說(shuō)的是 60 后,大概就是我們這一代人,所以有些事因?yàn)椤氨俊倍氩磺宄=裉旖柽@個(gè)機(jī)會(huì),向大家請(qǐng)教,集大家的智慧一起討論。
查老師說(shuō)我這個(gè)題目偷懶。為什么懶?前面加了個(gè)‘關(guān)于’,后面加了個(gè)‘思考’。先講講計(jì)算機(jī)視覺,這些年我們看到了一些喜憂參半的事情。為什么叫喜憂參半呢?
一方面大家看到文章很多,但另外一方面,回過頭來(lái)看計(jì)算機(jī)視覺領(lǐng)域這些年到底在做什么?研究的問題被不斷碎片化。我們這個(gè)領(lǐng)域的好處是開放開源,進(jìn)入的門檻似乎很低。另一個(gè)是常常圍繞榜單任務(wù)進(jìn)行,到底為什么要做?有時(shí)候你問學(xué)生,學(xué)生講因?yàn)橛腥俗觯驗(yàn)橛羞@么一個(gè)數(shù)據(jù)集,因?yàn)橛羞@種測(cè)試,這實(shí)際上是一個(gè)不好的趨勢(shì)。

但是現(xiàn)在我們看到一些新的變化,例如SAM。我不知道有多少人真正用它去跑了一些實(shí)驗(yàn)結(jié)果。如果你真正用它測(cè)試,結(jié)果可能不太一樣。假期學(xué)生幫我跑了不少結(jié)果,每次我都能看到一些不一樣的結(jié)果,其實(shí)遠(yuǎn)沒有我們想象的這么好,甚至于一些做合成的大模型也沒有那么好,但是它提供了一件可能。
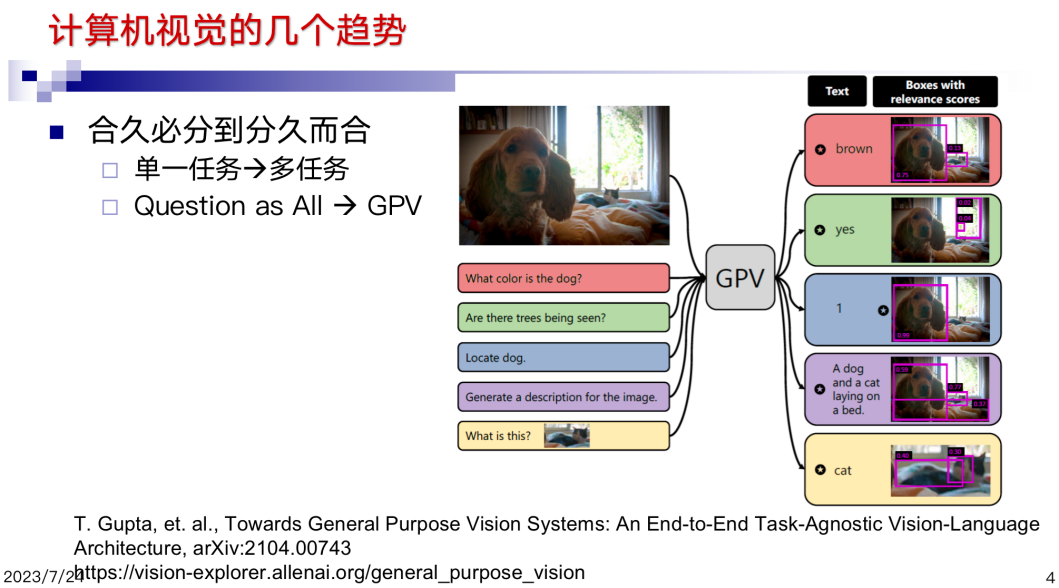
本質(zhì)上 SAM 提供的任意分割,是一個(gè)多尺度的分割,因?yàn)榉指钣肋h(yuǎn)是具有邏輯含義的任務(wù)。而不是一個(gè)物理含義的任務(wù),它提供了將碎片化任務(wù)收斂的機(jī)會(huì)。當(dāng)然現(xiàn)在也有一些學(xué)者試圖用類似于 ChatGPT 的方式把視覺任務(wù)都統(tǒng)一起來(lái),但視覺任務(wù)到底能不能統(tǒng)一,這件事情值得思考。也有人說(shuō)大模型來(lái)了以后是不是我們的研究就終結(jié)了?包括 SAM、CLIP等對(duì)我們領(lǐng)域的影響是終結(jié)性的?《三體》里有一句話“物理學(xué)好像不存在了”。是不是我們的領(lǐng)域也不存在了?

這里提出十個(gè)與大家共同思考的問題。第一個(gè)就是現(xiàn)在的大模型,多大算大?我回想起當(dāng)年講大數(shù)據(jù)的一句話,什么叫大數(shù)據(jù)?超越當(dāng)前設(shè)備處理能力上限的數(shù)據(jù)才叫大數(shù)據(jù),我非常認(rèn)可這個(gè)觀點(diǎn),今天我們的大模型是否也是這樣。一個(gè)million參數(shù),一個(gè)billion參數(shù),還是10個(gè)billion參數(shù),所以到底多大算大模型?我們今天在視覺領(lǐng)域所談的大模型,到底是大模型還是‘大的模型’?我個(gè)人認(rèn)為是‘大的模型’,因?yàn)轭A(yù)訓(xùn)練往往是針對(duì)少數(shù)任務(wù)的,我們現(xiàn)在講的大模型,因?yàn)樗讯鄠€(gè)任務(wù)能夠同時(shí)完成,或者找到了一個(gè)核心的任務(wù),比如我們的姊妹領(lǐng)域語(yǔ)音識(shí)別,任務(wù)就相對(duì)統(tǒng)一。
我們今天講的問題本質(zhì)上遇到的困惑,大模型改變了沒?如果大模型沒改變,那大模型還能走多遠(yuǎn)?或者說(shuō)大模型是不是在維數(shù)災(zāi)難發(fā)生以前就解決了問題?我們知道造房子無(wú)限制地加高,早晚是會(huì)倒的,如果只需要造一個(gè) 100 層的房子,會(huì)不會(huì)倒?大模型同樣,是不是我們可以在維度災(zāi)難超越承受之重之前,已經(jīng)能夠完成我們的任務(wù)?
第三個(gè)問題,就是大模型復(fù)雜度的問題,復(fù)雜性和蠻力究竟誰(shuí)先到邊界?如果依靠蠻力已經(jīng)到達(dá)問題的邊界了,復(fù)雜性就不是問題。我們做100個(gè)數(shù)的排序,沒有人會(huì)考慮排序算法的復(fù)雜度,但是如果對(duì)網(wǎng)絡(luò)上的海量數(shù)據(jù)進(jìn)行排序就要考慮了。
所以復(fù)雜性和蠻力究竟誰(shuí)先到邊界,我個(gè)人對(duì)模型復(fù)雜度的考慮:第一個(gè)是用算法的復(fù)雜程度來(lái)度量,第二個(gè)是需要的養(yǎng)成數(shù)據(jù)的規(guī)模。什么叫養(yǎng)成數(shù)據(jù)?養(yǎng)成數(shù)據(jù)主導(dǎo)了大多數(shù)大模型的性能,所以今天復(fù)現(xiàn)大模型,就算法本身已經(jīng)幾乎是公開的,但養(yǎng)成數(shù)據(jù)的規(guī)模和性能到底是什么關(guān)系,我覺得是要考慮的。
模型的成熟程度,什么時(shí)候模型能用?我定義了一個(gè)衡量模型成熟度的量--算力除以模型的復(fù)雜程度。如果成熟程度達(dá)到一定級(jí)別就可以走向規(guī)模應(yīng)用,我分了四級(jí),分別稱為思考級(jí)、研究級(jí)、產(chǎn)業(yè)級(jí)、個(gè)人用戶級(jí)。當(dāng)模型成熟很低的時(shí)候只有研究者認(rèn)識(shí)到它的價(jià)值,當(dāng)它到了一定程度以后,學(xué)術(shù)界可以用,再到一定程度如今天的大模型,工業(yè)界就可以用,如果算力再往前漲一個(gè)數(shù)量級(jí)或兩個(gè)數(shù)量級(jí),也許可以很方便地普及到個(gè)人設(shè)備上。
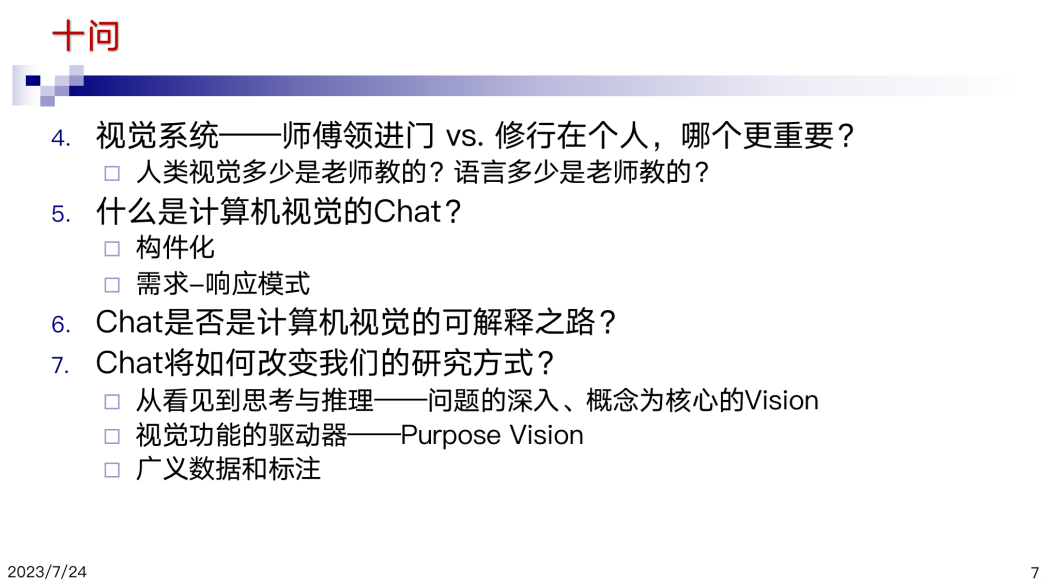
視覺和語(yǔ)言模型,我個(gè)人認(rèn)為是不一樣的,不能完全拿語(yǔ)言模型過來(lái)對(duì)比。語(yǔ)言是我們生下來(lái)以后被人教了很久才會(huì)的,可是我們的視覺是生下來(lái)睜眼即會(huì)。在這個(gè)意義上來(lái)講,人類視覺有多少是靠師傅領(lǐng)進(jìn)門的,應(yīng)該基本還是靠自己學(xué)習(xí)的。而語(yǔ)言系統(tǒng)是反過來(lái)的。視覺任務(wù)到底是什么?如果我們僅僅考慮視覺,我一直認(rèn)為視覺就是動(dòng)物生存的支撐。
視覺是為生存而生的,只有動(dòng)物才有視覺,植物不需要。為什么是為了生存?幾個(gè)基本需求,第一是別讓天敵吃了,第二是找到食物,第三不要碰到意外,這都需要視覺能力的支撐。
ChatGPT 核心是chat,那么什么是視覺的chat?在我看來(lái),視覺的chat是一些基本的功能。這些功能是依任務(wù)而激活的,依響應(yīng)而反應(yīng),是在一個(gè) loop中的,大多數(shù)時(shí)候是處于不工作的狀態(tài),我們每天看了很多對(duì)象都視而不見,但是一旦威脅到生存或者有需求的驅(qū)動(dòng),我們就會(huì)去響應(yīng)和處理。反過來(lái)講,如果我們盲目地把在語(yǔ)言處理中的一套方法直接拿過來(lái)試圖解決計(jì)算機(jī)視覺的問題是不是可以?所以我覺得視覺的“chat”可能是一個(gè)構(gòu)件化的需求-響應(yīng)模式,它是在一個(gè)智能體里,因?yàn)槟撤N需要才采取的動(dòng)作,所以它的基本功能相對(duì)很簡(jiǎn)單。 另外今天我們要的解釋其實(shí)是基本的chat。一個(gè)就是講 ChatGPT 對(duì)我們的改變,這里chat是不是ChatGPT?大概幾類問題,一個(gè)是能夠讓我們從看見到思考,就是有了 ChatGPT以后,現(xiàn)在很多研究可以和ChatGPT連接起來(lái)。 今天早上林倞講了一個(gè)重要的事情,是怎樣形成loop。有了 chat 以后的loop和響應(yīng)-需求模式本身是一個(gè)途徑,ChatGPT也是一個(gè)loop。再一個(gè)就是視覺功能的驅(qū)動(dòng)是什么?80年代末、90年代初就有研究者提出類似的概念—Purpose Vision。Chat的另外一個(gè)用途是能夠幫助我們做廣義的數(shù)據(jù)和標(biāo)注,有了chat,就能把這件事情幫我們做得很好。

討論的第8個(gè)問題是關(guān)于多模態(tài)的。模態(tài)之間的協(xié)同很重要,但是模態(tài)之間要不要有邊界?模態(tài)的邊界在哪里?比如單純從視覺來(lái)講,現(xiàn)在有時(shí)候把視覺任務(wù)無(wú)限制地?cái)U(kuò)張。如果從腦或者智能體來(lái)講,擴(kuò)大是正確的,但如果從視覺而言,邊界在哪里?與其他模態(tài)之間什么地方是界,什么地方是協(xié)同? 因此,我覺得 AI 會(huì)有一個(gè)體系結(jié)構(gòu),是 AI 基本能力的界面或AGI的結(jié)構(gòu)支撐。過去做 AI 的研究者大都只是局限在某一特定智能能力方面,今天需要做的智能體,是一個(gè)綜合體,所以會(huì)有一些新的問題和挑戰(zhàn)。
關(guān)于大模型和ChatGPT,我覺得它是AGI 之光,但是要注意一件事情,現(xiàn)在大模型帶來(lái)一個(gè)最大的改變是什么?我們過去都在比誰(shuí)把算法做得更精巧。今天的一個(gè)趨勢(shì),就是從構(gòu)造越來(lái)越復(fù)雜的算法,到構(gòu)造能夠容納復(fù)雜能力的算法,通用模型本身會(huì)趨向于簡(jiǎn)單化,只有這樣才可能將能力不斷放大。
ChatGPT 問世以后,對(duì)研究者無(wú)疑是一場(chǎng)巨大的沖擊,以前的一些問題可能不需要再進(jìn)行研究了,如同海平面的上升,這些問題已經(jīng)成了水下的部分了,也可能僅僅是看起來(lái)解決了,如同海嘯襲來(lái),退潮之后問題還在。對(duì)我們來(lái)說(shuō),ChatGPT帶來(lái)的到底是海嘯還是海平面的上升?這是我們需要思考的問題。謝謝大家。
2.沈春華(浙江大學(xué))
謝謝井東老師的邀請(qǐng),非常高興能在這里跟大家分享一下大模型和 ChatGPT 對(duì)視覺的影響。實(shí)際上有點(diǎn)趕鴨子上架,我不做ChatGPT,也不做大模型,基本上沒做過什么大模型,雖然我很想做大模型。我就簡(jiǎn)單講一下我的一些理解,我覺得ChatGPT從今年年初開始到現(xiàn)在對(duì)于做不管是視覺還是 NLP 還是 speech recognition,有巨大的影響。

一個(gè)影響是,通過大數(shù)據(jù)訓(xùn)練大模型,人們開始認(rèn)識(shí)到這是實(shí)現(xiàn)人工通用智能(AGI)可能的一個(gè)較為可行的途徑。目前我們已經(jīng)看到在視覺任務(wù)方面的一些例子,陳老師也提到,這些都是在這個(gè)方向上的發(fā)展。如果我們能夠通過大數(shù)據(jù)訓(xùn)練大模型,在圖像理解等任務(wù)上取得最優(yōu)結(jié)果,那么我們就不再僅僅局限于設(shè)計(jì)各種新的算法,因?yàn)檫@可能是一個(gè)進(jìn)退維谷的做法。相反地,利用大數(shù)據(jù)和簡(jiǎn)單算法來(lái)實(shí)現(xiàn)最佳性能,可能是一條更為優(yōu)秀的道路。
在我們視覺圈子里就在說(shuō)這個(gè):過去二三十年視覺的發(fā)展基本上就是數(shù)據(jù)集帶來(lái)的發(fā)展。從最早的 MNIST 到后面 Pascal VOC 到ImageNet,統(tǒng)治了視覺很多年。2015 年 AlexNet的論文,當(dāng)時(shí)就是 Jupiter 和他的幾個(gè)學(xué)生, Alex 和Suscuva,他們最早是在 Pascal VOC 的數(shù)據(jù)集上去訓(xùn)神經(jīng)網(wǎng)絡(luò)。AlexNet 沒有得到好的結(jié)果,因?yàn)檫@個(gè)數(shù)據(jù)集太小了。他去用了ImageNet,然后才有了 AlexNet 這篇論文。所以基本上就是數(shù)據(jù)集帶來(lái)提升。

在訓(xùn)練大規(guī)模的模型時(shí),確實(shí)需要足夠的算力來(lái)處理大規(guī)模的數(shù)據(jù)集。根據(jù)一個(gè)PPT上的統(tǒng)計(jì)數(shù)據(jù),從2012年到2018年的6年間,算力提升了30萬(wàn)倍。如果算力繼續(xù)提升,我們可以預(yù)見未來(lái)會(huì)使用更大的數(shù)據(jù)集和更大的模型來(lái)進(jìn)行訓(xùn)練。從另一份PPT中的數(shù)據(jù)也可以看到,在2012年到2018年的時(shí)間跨度中,訓(xùn)練模型所需的算力復(fù)雜度顯著下降,即便與AlphaGo相比,現(xiàn)在的許多模型已經(jīng)無(wú)法達(dá)到以前所需的復(fù)雜度。
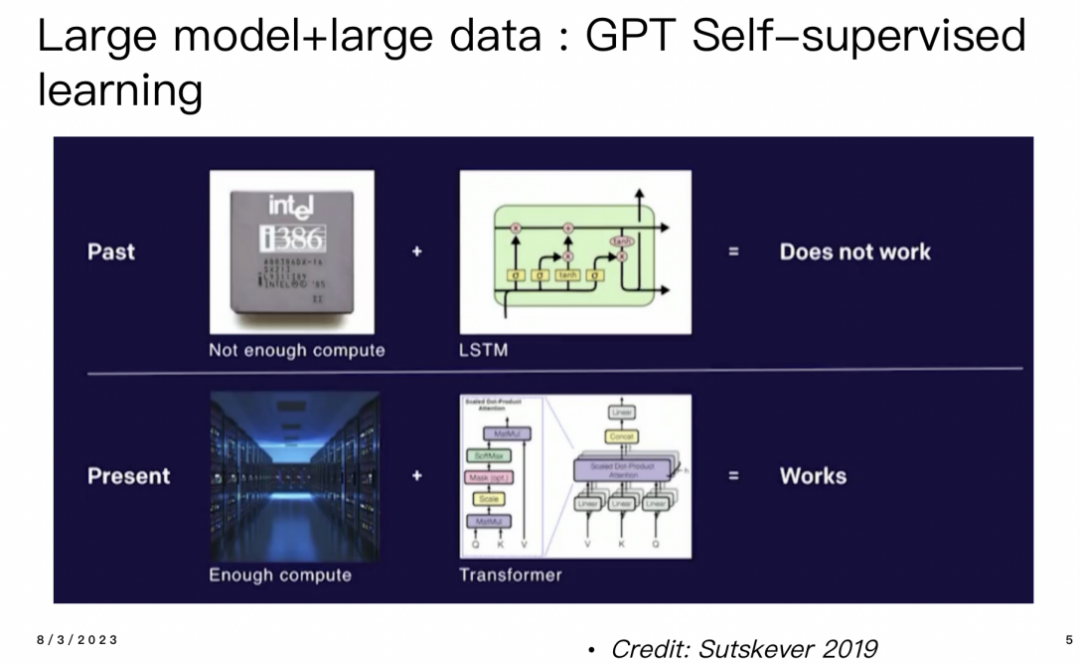
現(xiàn)在,回顧C(jī)hatGPT,最早的GPT模型采用了Transformer架構(gòu)進(jìn)行自監(jiān)督學(xué)習(xí),其訓(xùn)練方式是預(yù)測(cè)下一個(gè)單詞。在早期,GPT的訓(xùn)練受限于算力和Transformer架構(gòu)相對(duì)于LSTM較難并行化的問題,因此很難繼續(xù)擴(kuò)展。但是,ChatGPT的成功部分歸功于預(yù)測(cè)下一個(gè)單詞作為預(yù)訓(xùn)練的關(guān)鍵因素。
陳老師之前提到,在NLP中,文本與圖像和其他傳感器獲取的數(shù)據(jù)最大的區(qū)別在于文本本身就是帶有標(biāo)注的,因?yàn)槲谋臼强梢杂涗浵聛?lái)的。而圖像和其他數(shù)據(jù)則沒有這種自帶的標(biāo)注,因此直接將ChatGPT的方法應(yīng)用于圖像領(lǐng)域是行不通的。圖像數(shù)據(jù)是一種“智能傳感器”,它本身不具備內(nèi)在的語(yǔ)義標(biāo)注,因此我們無(wú)法直接借鑒ChatGPT的方式。

最近實(shí)現(xiàn)的一種知識(shí)蒸餾的方法,在知識(shí)蒸餾的過程中,T球網(wǎng)絡(luò)用于代表人類的知識(shí),它原本應(yīng)該去擬合概率分布,但現(xiàn)在由于缺少確切的概率信息,我們可以用一個(gè)delta函數(shù)來(lái)近似概率,從而實(shí)現(xiàn)預(yù)測(cè)下一個(gè)單詞的目標(biāo)。

對(duì)于視覺領(lǐng)域,與NLP不同的是,視覺問題需要解決多種不同的任務(wù)。而與GPT對(duì)NLP的廣泛適用性不同,對(duì)視覺領(lǐng)域的模型來(lái)說(shuō),并沒有一個(gè)統(tǒng)一的模型可以勝任所有任務(wù)。其中,DINO v2是一個(gè)無(wú)監(jiān)督的self-supervised learning模型,它在視覺領(lǐng)域的許多下游任務(wù)上表現(xiàn)良好。即使只是將DINO v2的模型固定住,直接將其用于特征提取,再進(jìn)行encoder和decoder的構(gòu)建,也能在很多下游任務(wù)上表現(xiàn)出色。
第二類模型,像SAM這樣的模型被稱為任務(wù)特定的基礎(chǔ)模型,它與特定任務(wù)相關(guān)。在視覺領(lǐng)域中,像圖像校準(zhǔn)這樣的任務(wù)目前可能研究較少,而更重要的是進(jìn)行像素級(jí)的預(yù)測(cè),例如分割,以及其他一些任務(wù)如3D重建。

第三類模型可能介于兩者之間,或者是一種弱監(jiān)督學(xué)習(xí)模型。弱監(jiān)督學(xué)習(xí)指的是很多像CLIP和captioning這樣的模型,這些模型使用圖像級(jí)別的監(jiān)督信號(hào)來(lái)訓(xùn)練,通過圖像的描述來(lái)完成任務(wù)。盡管使用了圖像級(jí)別的監(jiān)督信息,但它們實(shí)際上學(xué)習(xí)了像素級(jí)別的信息。特別是對(duì)于生成模型,其實(shí)它是學(xué)習(xí)像素級(jí)別的分布信息。DINO v2的內(nèi)容我就不再詳述,但可以明確的是,它在實(shí)驗(yàn)結(jié)果中表現(xiàn)非常出色。

SAM是Facebook今年的研究成果,他們使用了1000萬(wàn)張圖片進(jìn)行訓(xùn)練。21年時(shí),我在亞馬遜工作了一年,并嘗試了一個(gè)類似的工作,收集了大約200萬(wàn)張圖片并訓(xùn)練了一個(gè)SegFormer模型。不過遺憾的是,這個(gè)工作投了兩年CVPR都被拒絕了,記得分?jǐn)?shù)都是455。 盡管如此,這個(gè)工作的結(jié)果還是非常好的,盡管沒有像SAM那樣規(guī)模龐大(1000萬(wàn)張圖片),并且當(dāng)時(shí)的工作只涉及semantic segmentation,并未像SAM一樣做 instance level的Instant segmentation。

在學(xué)術(shù)領(lǐng)域,我想強(qiáng)調(diào)一點(diǎn),單純地訓(xùn)練大型模型并不一定能確保論文容易發(fā)表。雖然我們的研究結(jié)果還不錯(cuò),我們花了大半年的時(shí)間來(lái)完成這篇論文,并消耗了很多GPU資源,將它上傳到了arXiv。但是,即便結(jié)果不錯(cuò),論文發(fā)表也可能面臨困難。除了這個(gè),我還想提到另一個(gè)項(xiàng)目。我們?cè)?D重建方面的研究,收集了大約1000萬(wàn)張圖片。這個(gè)項(xiàng)目是由我之前的一個(gè)學(xué)生進(jìn)行的。現(xiàn)在,大疆公司擁有GPU資源,他們也在進(jìn)行類似的研究。盡管這個(gè)項(xiàng)目對(duì)技術(shù)要求很高,但在CVPR 23年投稿時(shí)遭到了拒絕,之后我們改進(jìn)后在ICCV上獲得了接收。
無(wú)論如何,我想說(shuō)的是,確實(shí)我的方法本身并沒有特別大的創(chuàng)新。主要是利用大數(shù)據(jù)來(lái)訓(xùn)練一個(gè)較大的模型。但從最后的結(jié)果來(lái)看,效果確實(shí)非常好。此外,我們訓(xùn)練的模型本身并不大,只是訓(xùn)練了一個(gè)ConvNeXt模型,并沒有用到Transformer。所以,這也強(qiáng)調(diào)了大數(shù)據(jù)的重要性。即使訓(xùn)練一個(gè)相對(duì)較小的模型,借助大數(shù)據(jù),性能也可以做得非常好。另外,第三類方法可以看作是介于unsupervised-learning 和像SAM這樣的pixel level的模型之間。這種方法可以將image level的supervision信號(hào)用于學(xué)習(xí)pixel level的信息。

CLIP是一個(gè)非常好的例子,它也是OpenAI的研究成果。和ChatGPT之前的做法一樣,CLIP的方法也是基于大數(shù)據(jù),并將整個(gè)架構(gòu)放在Transformer這樣的框架中,類似于NLP里的GPT,采用了類似的sequence to sequence學(xué)習(xí)方法。因此,這個(gè)formulation非常簡(jiǎn)單,包括像stable AI的生成模型也是如此,整個(gè)做法都是非常直接的。

個(gè)人而言,我更傾向于第三種方法,即使用image level的注釋來(lái)訓(xùn)練模型,并希望獲得pixel level的信息。因?yàn)閺睦碚撋蟻?lái)說(shuō),這樣的方法確實(shí)可以學(xué)習(xí)到pixel level的信息。

在21年,我們進(jìn)行了dance share的工作,它實(shí)際上是一個(gè)unsupervised learning,旨在獲得良好的pixel wise correspondence。因?yàn)樵S多數(shù)據(jù)任務(wù)最終都需要找到correspondence。今年我們做了一個(gè)使用diffusion model的工作,來(lái)處理大量生成的圖像,并使用算法獲得它們的pixel level的annotation。理論上來(lái)說(shuō),一旦獲得大量這樣的訓(xùn)練數(shù)據(jù),就可以用于訓(xùn)練下游的視覺任務(wù)。這里面一個(gè)關(guān)鍵的觀察是,diffusion mode或其他生成模型需要將像素分配標(biāo)注出來(lái)。

沒錯(cuò),一旦將像素分布出來(lái),理論上就可以獲得更好的標(biāo)注。我個(gè)人預(yù)測(cè),像DINO v2這樣的大規(guī)模自監(jiān)督學(xué)習(xí)方法,可以在不需要標(biāo)注數(shù)據(jù)的情況下訓(xùn)練大型模型,這可能會(huì)促使更多的研究工作涌現(xiàn)出來(lái),因?yàn)镈INO v2本身是非常有用的。但是是否會(huì)實(shí)現(xiàn)類似于視覺GPT這樣的方法,現(xiàn)在還不清楚,也許會(huì)有,也許并不一定有必要。像SAM這樣的specific 的foundation model,可能會(huì)在未來(lái)看到更多類似的工作,包括像3D重建、單目深度估計(jì)等模型,也可能會(huì)公開發(fā)布。
當(dāng)然,我對(duì)如何利用weakly supervised learning也很感興趣。使用 image level的標(biāo)簽來(lái)訓(xùn)練一個(gè)非常大的模型是一個(gè)有挑戰(zhàn)的問題,因?yàn)橛?xùn)練數(shù)據(jù)本身缺乏pixel level的信息。但是通過訓(xùn)練,希望可以得到更豐富的像素級(jí)信息。
3.代季峰(清華大學(xué))

今天非常高興來(lái)分享我的報(bào)告,題目叫做"從感知基石模型到智能體基石模型"。最近大家一直在談?wù)摯竽P停矣X得實(shí)際上這個(gè)概念應(yīng)該叫做基石模型。最近,王乃巖也在一個(gè)帖子中提到了這個(gè)問題。我之前和他參加過一個(gè)panel,我們一直在談?wù)撨@個(gè)話題。實(shí)際上,大模型很多時(shí)候體現(xiàn)了智能的一種表現(xiàn)形式,它成為了基石模型這一更本質(zhì)的概念。所謂基石模型,它指的是一個(gè)模型能夠從海量的互聯(lián)網(wǎng)數(shù)據(jù)中學(xué)到非常多有用的知識(shí)。同時(shí),這個(gè)模型具有很強(qiáng)的通用性和泛化性,能夠在許多下游任務(wù)中應(yīng)用,并且能夠在未見過的數(shù)據(jù)或任務(wù)上得到reasonable的結(jié)果。
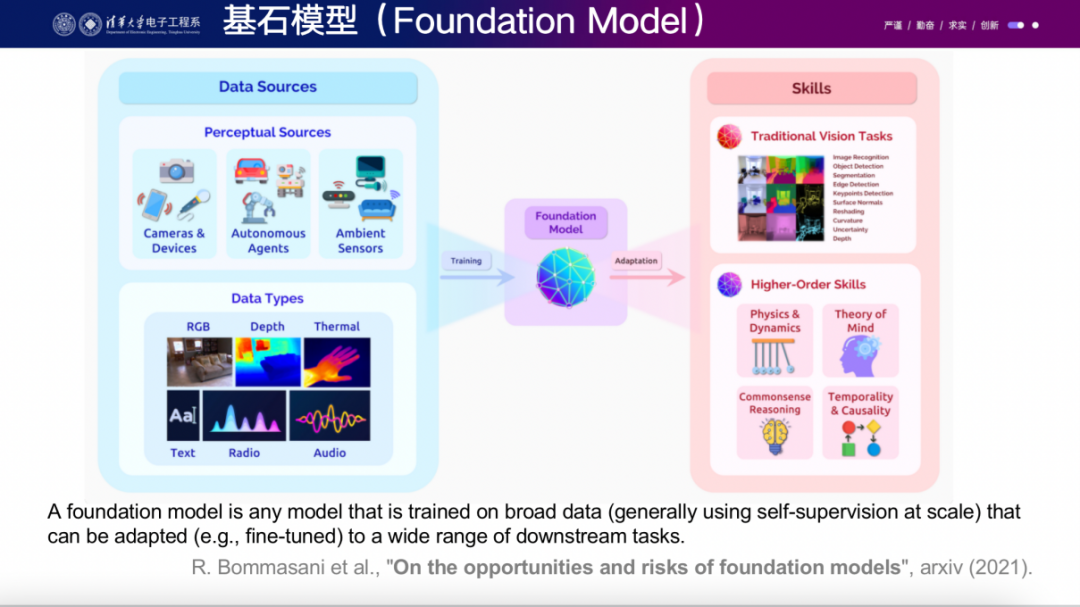
這是foundation model的一個(gè)非常重要的特征。不過,我暫時(shí)不深入討論這里面的細(xì)節(jié)。我覺得21年opportunity and risk foundation models的定義還是相對(duì)超前的。舉個(gè)例子,之前的BERT在預(yù)定義的NLP任務(wù)上表現(xiàn)非常出色,而后來(lái)的GPT系列在相同的對(duì)比實(shí)驗(yàn)中,在這些預(yù)定義任務(wù)上的性能可能不如BERT。但是GPT系列的強(qiáng)大之處在于其能夠具備通用性,你可以向它問任何問題,這也是它為什么能夠受到如此廣泛關(guān)注的重要原因。
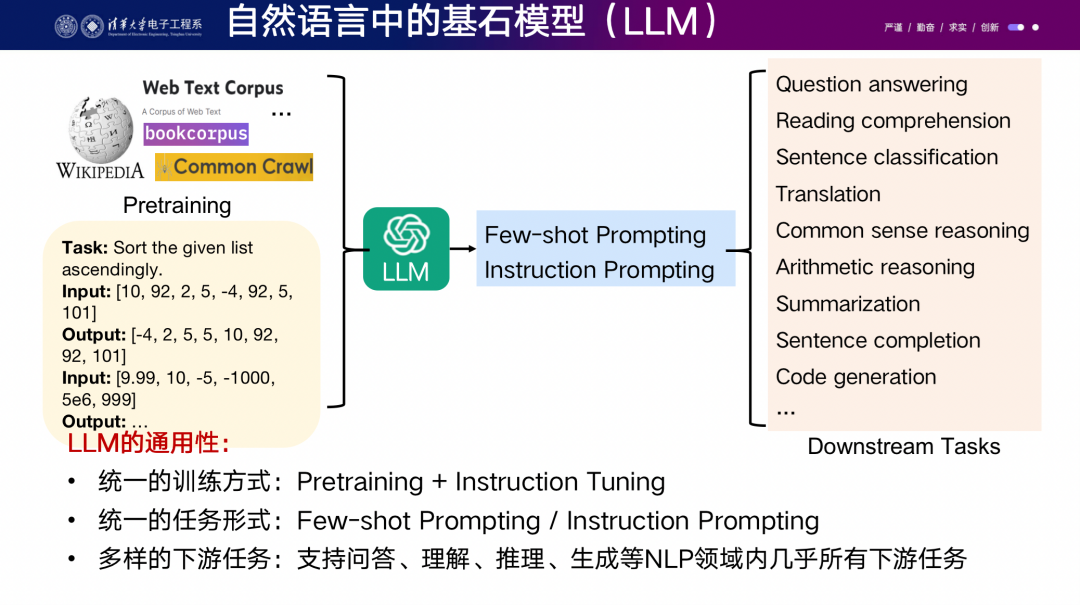
在自然語(yǔ)言領(lǐng)域,我們首先實(shí)現(xiàn)了一個(gè)目標(biāo),帶來(lái)了巨大的生產(chǎn)力變化。訓(xùn)練一個(gè)大型模型的成本非常高,需要成千上萬(wàn)塊GPU,比如OpenAI花費(fèi)了大量資源。去年幾十位精英研究員花費(fèi)了數(shù)月時(shí)間管理數(shù)據(jù)標(biāo)注,需要付高額工資給名校的研究員,這是一筆相當(dāng)高昂的開支。然而,這樣的投入帶來(lái)的好處在于應(yīng)用編輯成本非常低。因?yàn)楫?dāng)你問ChatGPT任何問題時(shí),后臺(tái)不需要再花費(fèi)大量成本去標(biāo)注新的數(shù)據(jù)或者訓(xùn)練新的模型,它直接在服務(wù)器上推理。
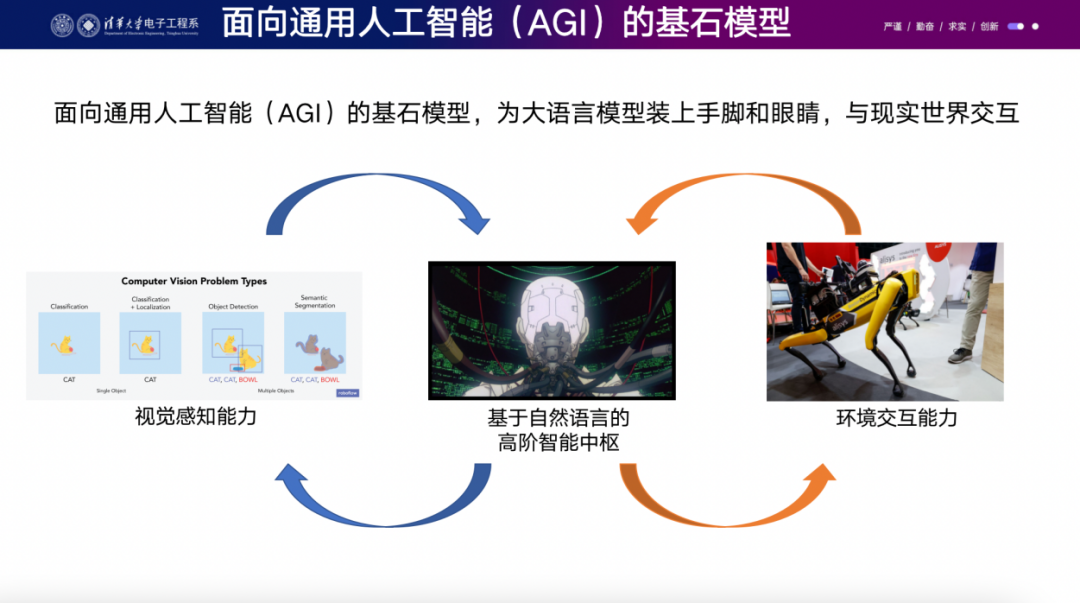
接下來(lái),我們需要思考一下,如果像ChatGPT這樣的模型具有通向AGI的潛力,我們?nèi)绾文軌驍U(kuò)大這種能力,將其應(yīng)用到更多行業(yè)中?我們可以把ChatGPT類比為一個(gè)關(guān)在黑屋子里的聰明人,每次你遞給他一張紙條,他會(huì)回復(fù)幾張紙條。我們希望給他加上眼睛,讓他看見這個(gè)世界,同時(shí)給他裝上手和腳,讓他與環(huán)境進(jìn)行交互。
我可以部分回答之前熙霖老師提出的問題,不過現(xiàn)在時(shí)間有限,暫時(shí)不做展開。我們希望打造一個(gè)具身智能的機(jī)器人,讓它在現(xiàn)實(shí)世界中運(yùn)行。視覺就像語(yǔ)言一樣,而我們的ChatGPT已經(jīng)在人類所有的文字上實(shí)現(xiàn)了一個(gè)閉環(huán),你可以訓(xùn)練它去回答任何問題并得到正確的答案,比如你可以問它“TOKEN是什么東西?”然而,在視覺領(lǐng)域,這些任務(wù)都是人為定義的特定case,而視覺的最終目標(biāo)是讓機(jī)器能夠在現(xiàn)實(shí)世界中生存。
陳老師剛才總結(jié)得非常好,我就不再多說(shuō)了。我認(rèn)為大量的supervision信號(hào)應(yīng)該來(lái)自與現(xiàn)實(shí)世界的交互,但是為了高效地進(jìn)行實(shí)驗(yàn),我們可以在虛擬環(huán)境中進(jìn)行這些交互。目前計(jì)算機(jī)視覺還是特定于任務(wù)的反向傳播,這也是為什么之前的一代AI公司一直在虧損的原因,因?yàn)樗鼈兊倪呺H成本非常高。

之前的視覺模型,無(wú)論設(shè)計(jì)多少個(gè)Backbone網(wǎng)絡(luò),我覺得都不能構(gòu)成所謂的foundation model,因?yàn)楫?dāng)應(yīng)用于下游的任何新任務(wù)時(shí),都需要特定于任務(wù)的微調(diào)和解碼器。這導(dǎo)致隨著任務(wù)數(shù)量的增加,模型參數(shù)不斷增加,無(wú)法直接共享處理不同任務(wù)的參數(shù)。
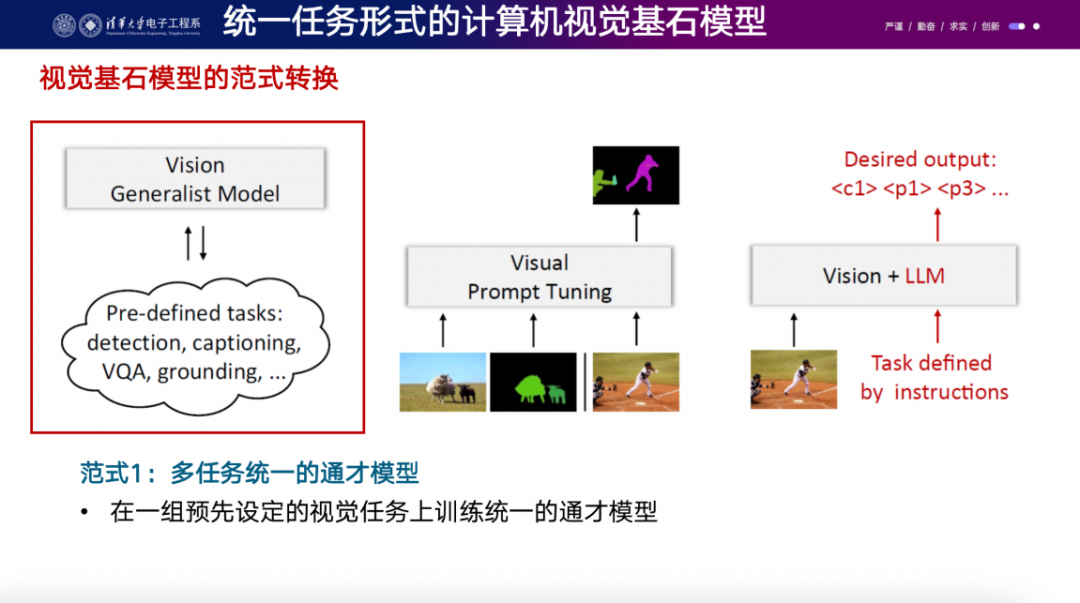
理解視覺的foundation model有很多特點(diǎn),其中一個(gè)是它需要通用的解碼器,這樣就可以包含各種視覺任務(wù)。你可以在一組預(yù)先定義的視覺任務(wù)上進(jìn)行訓(xùn)練,但同時(shí)也可以在編譯的視覺任務(wù)上進(jìn)行訓(xùn)練。然而,如果要處理新的任務(wù),可能仍需要一些人工工作。這些方法可能比ChatGPT之前的方法更早一些,我們也進(jìn)行了一些嘗試。還有一些其他的工作,如軟件工作中臺(tái)、perceiver、reperceiver等,都是比較不錯(cuò)的嘗試
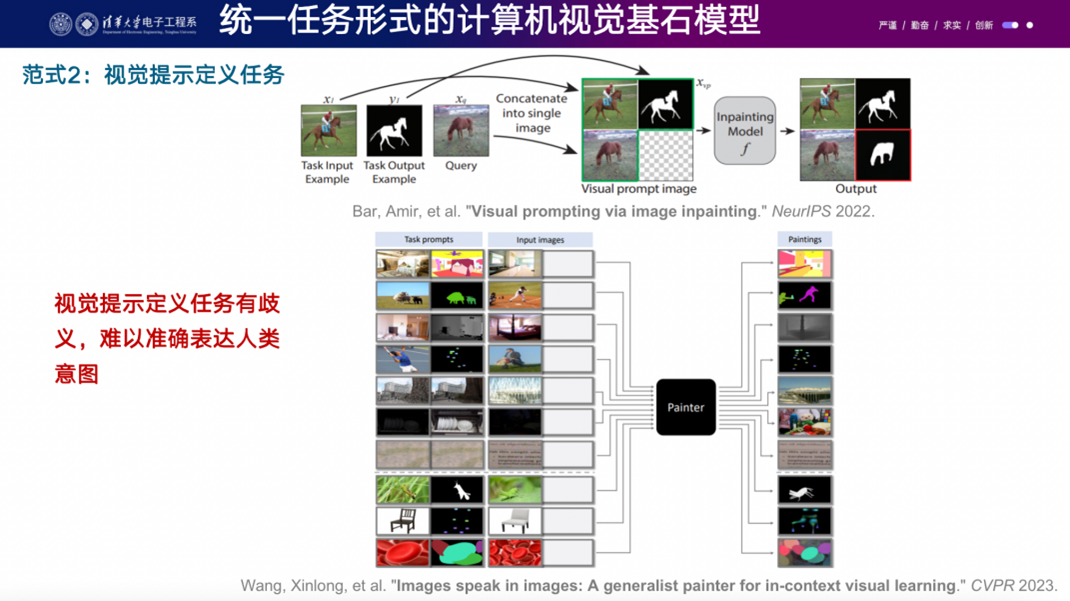
另外一個(gè)技術(shù)路線是直接將自然語(yǔ)言處理中的prompt engineering方法應(yīng)用到視覺領(lǐng)域。在自然語(yǔ)言處理中,prompt engineering是一個(gè)很好的方法,它解決了不再需要finetune的問題。他們的想法是將這個(gè)概念直接復(fù)制到視覺領(lǐng)域。比如,訓(xùn)練了一個(gè)模型后,給它一個(gè)提示,比如一個(gè)原始自然圖像和羊的分割結(jié)果,然后再給它一個(gè)新的人的圖片,它應(yīng)該得到足夠的提示來(lái)分割出人物。這樣的方法已經(jīng)在一些工作中得到了應(yīng)用,比如谷歌在2022年的visual-prompt image impainting和王鑫龍博士的image speak in image等。但是在當(dāng)前技術(shù)條件下,這條路線仍處于比較早期的階段,因?yàn)槲覀儗?duì)視覺建模的能力還不是很清楚。
但是另外一個(gè)相對(duì)實(shí)用一些的技術(shù)路線是將大型語(yǔ)言模型和視覺模型進(jìn)行強(qiáng)耦合。現(xiàn)在我們可以直接用自然語(yǔ)言來(lái)定義視覺任務(wù),并用自然語(yǔ)言來(lái)輸出我們想要的結(jié)果。具體而言,我們可以教給一個(gè)強(qiáng)大的視覺backbone model這樣的主干網(wǎng)絡(luò),讓它理解我們的任務(wù)定義,并用自然語(yǔ)言來(lái)描述任務(wù)的輸入和輸出。我們?cè)谶@個(gè)方向上的工作比較多,這個(gè)方法被稱為"Vision LLM",我們覺得效果還是挺不錯(cuò)的。

現(xiàn)在我們可以通過定義一個(gè)強(qiáng)大的視覺backbone模型來(lái)處理各種視覺任務(wù),就像以前我們靠object detector或segmentation網(wǎng)絡(luò)來(lái)處理任務(wù)一樣。現(xiàn)在我們通過自然語(yǔ)言來(lái)定義任務(wù),并用自然語(yǔ)言來(lái)輸出我們想要的結(jié)果。這個(gè)方法在一些工作中得到了應(yīng)用。
你可以用自然語(yǔ)言來(lái)告訴這個(gè)智能體你想讓它做什么。比如,你可以告訴它要檢測(cè)一個(gè)小孩在吃什么,用什么坐標(biāo)系來(lái)表達(dá)圖片,然后它會(huì)給你輸出一個(gè)結(jié)果,還可以做一些復(fù)雜的推理問題。這種方法在一些實(shí)驗(yàn)中得到了應(yīng)用,非常有趣。
在這個(gè)技術(shù)路線中,還有一些人嘗試同時(shí)使用語(yǔ)言和視覺提示來(lái)定義任務(wù),以提高任務(wù)定義的準(zhǔn)確性。在虛擬環(huán)境中進(jìn)行實(shí)驗(yàn)可以極大地增強(qiáng)實(shí)驗(yàn)效率。
以前的智能體是基于強(qiáng)化學(xué)習(xí)的,比如Alpha Go、打星際爭(zhēng)霸、打dota等。但是當(dāng)它們面對(duì)開放世界的推進(jìn)時(shí),遇到了巨大的泛化性挑戰(zhàn)。比如,玩一個(gè)簡(jiǎn)單的游戲俄羅斯方塊,訓(xùn)練好后,如果將整個(gè)像素向上移動(dòng)幾個(gè)像素,訓(xùn)練出的模型就完全不知道該怎么玩了。這表明在這樣的任務(wù)中,強(qiáng)化學(xué)習(xí)面臨著一些困難。

我們嘗試使用大語(yǔ)言模型來(lái)解決這個(gè)問題。首先,我們選擇了世界上銷量最大、最開放的游戲"Minecraft",因?yàn)樵谶@個(gè)游戲中,玩家可以創(chuàng)造世界、建造城市,甚至創(chuàng)建CPU和存儲(chǔ)等。我們的基本想法是將一個(gè)大型語(yǔ)言模型放置在虛擬環(huán)境中,因?yàn)樗呀?jīng)見過全世界的語(yǔ)料,所以具有一定的類似AGI的能力。然后,我們?cè)谶@個(gè)環(huán)境中給它一些提示和指令,看它能否在虛擬環(huán)境中表現(xiàn)出色。
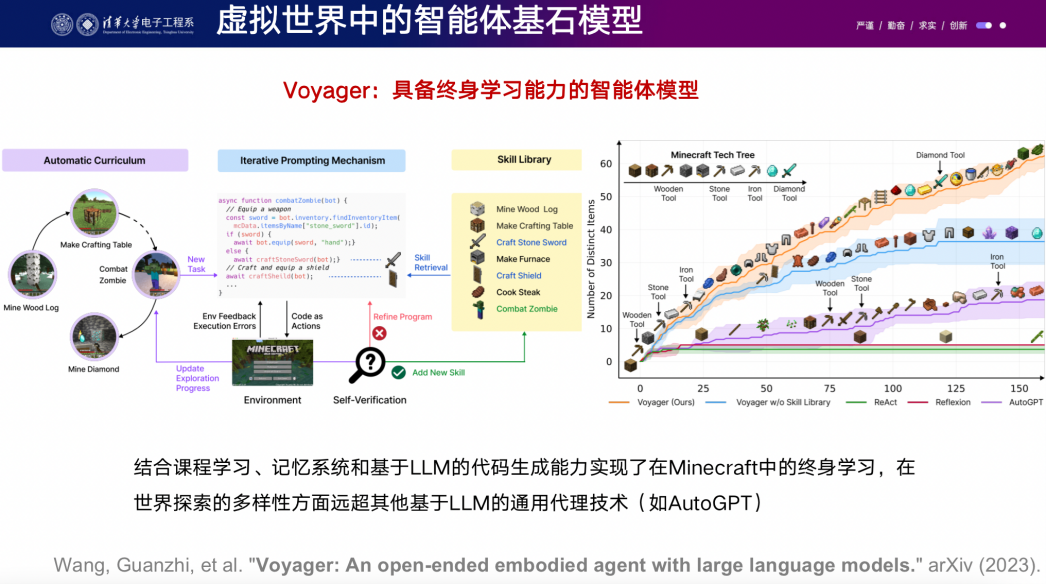
在這個(gè)方向上,有兩篇相關(guān)工作。其中一篇是由英偉達(dá)提出的"Voyager",它將指令輸出為控制智能體的代碼,相比以前純使用強(qiáng)化學(xué)習(xí)算法的智能體,它有了巨大的進(jìn)步。另一篇是我們的工作"Ghost in the Minecraft",我們輸出稍微高級(jí)一些的文字指令,需要一些更多的engineering,但換來(lái)的是更好的性能。我們的方法在測(cè)試中取得了3.7倍的性能提升,而之前使用強(qiáng)化學(xué)習(xí)的方法則需要大量的計(jì)算資源,并且能力有限。

最后要提及的是通用具身機(jī)器人,谷歌的"Palm-E"工作可能是代表性的。它將圖像、動(dòng)作、姿勢(shì)等內(nèi)容轉(zhuǎn)換成TOKEN,并在預(yù)訓(xùn)練的大型語(yǔ)言模型上進(jìn)行微調(diào),用于控制機(jī)器人。這樣的方法取得了很有趣的demo。 通過使用自然語(yǔ)言與機(jī)器人進(jìn)行對(duì)話,比如讓它將不同顏色的塊放到不同的位置,經(jīng)過訓(xùn)練后,機(jī)器人可以執(zhí)行這樣的任務(wù),并且具有泛化能力。一旦學(xué)會(huì)了一些任務(wù),你可以讓它去做一些新的任務(wù),它有可能表現(xiàn)得非常好。這是它的一個(gè)demo。以上就是我今天的報(bào)告內(nèi)容,謝謝大家。
4. 謝凌曦(華為)

大家好,我是謝凌曦。很高興能在這里與大家分享我們最近的心得體會(huì)。我之前在VALSE上做過一次報(bào)告,題目是“走向計(jì)算機(jī)視覺的通用人工智能”。雖然標(biāo)題沒有改變,但它非常貼合今天的主題,所以我將再次分享一下。
我今天的報(bào)告將分為幾個(gè)部分。首先,我會(huì)簡(jiǎn)要介紹AGI和NLP在這個(gè)領(lǐng)域的進(jìn)展和成就。接著,我將深入探討CV領(lǐng)域?yàn)槭裁丛趯?shí)現(xiàn)AGI方面看起來(lái)還很遙遠(yuǎn),面臨的主要困難是什么,以及目前的解決方法以及其中隱藏的真正本質(zhì)困難是什么。最后,我將簡(jiǎn)要分享一下我個(gè)人對(duì)于如何解決這些困難的看法。

在探討AGI之前,我們需要明確其含義。AGI是人工智能的最高理想,可以被定義為一種能夠達(dá)到或超越人類和動(dòng)物能力的系統(tǒng)。從較為正式的角度來(lái)看,我們可以采用2007年AGI一書中的定義,將AGI定義為在一個(gè)環(huán)境中與其互動(dòng),通過采取行動(dòng)來(lái)最大化獎(jiǎng)勵(lì)的系統(tǒng)或算法。在這樣的定義下,AGI是非常通用的,因?yàn)樗恢谰唧w環(huán)境是什么,環(huán)境中包含什么內(nèi)容,以及需要完成什么任務(wù)。
近年來(lái),隨著深度學(xué)習(xí)的發(fā)展,AGI取得了很大的進(jìn)展。深度學(xué)習(xí)是一種通用的方法論,只要給定輸入和輸出,就可以用統(tǒng)一的方法來(lái)建模輸入與輸出之間的關(guān)系。因此,在深度學(xué)習(xí)的推動(dòng)下,我們能夠用統(tǒng)一的方法來(lái)解決CV、NLP和強(qiáng)化學(xué)習(xí)等一系列問題。但是,距離真正的AGI還有相當(dāng)大的距離要走。
在NLP領(lǐng)域,ChatGPT和GPT-4的出現(xiàn)讓我們看到了AGI的曙光。國(guó)外的一些研究者稱其為AGI的“火花”,因?yàn)镚PT系列可以完成各種通用任務(wù),甚至可以作為邏輯連接器將不同模塊連接在一起。
舉個(gè)我自己使用的例子,我用ChatGPT來(lái)寫一段強(qiáng)化學(xué)習(xí)程序,雖然我沒有學(xué)過強(qiáng)化學(xué)習(xí),但它幫助我寫出了程序,并回答了我的問題,比如為什么模塊沒有正確運(yùn)行等等。通過幾次交互,我成功地運(yùn)行了程序并得到了期望的結(jié)果。這表明ChatGPT或GPT-4已經(jīng)成為一個(gè)通用的問題解決程序,而不僅僅是我們?cè)谟?jì)算機(jī)視覺領(lǐng)域經(jīng)常見到的toy example。
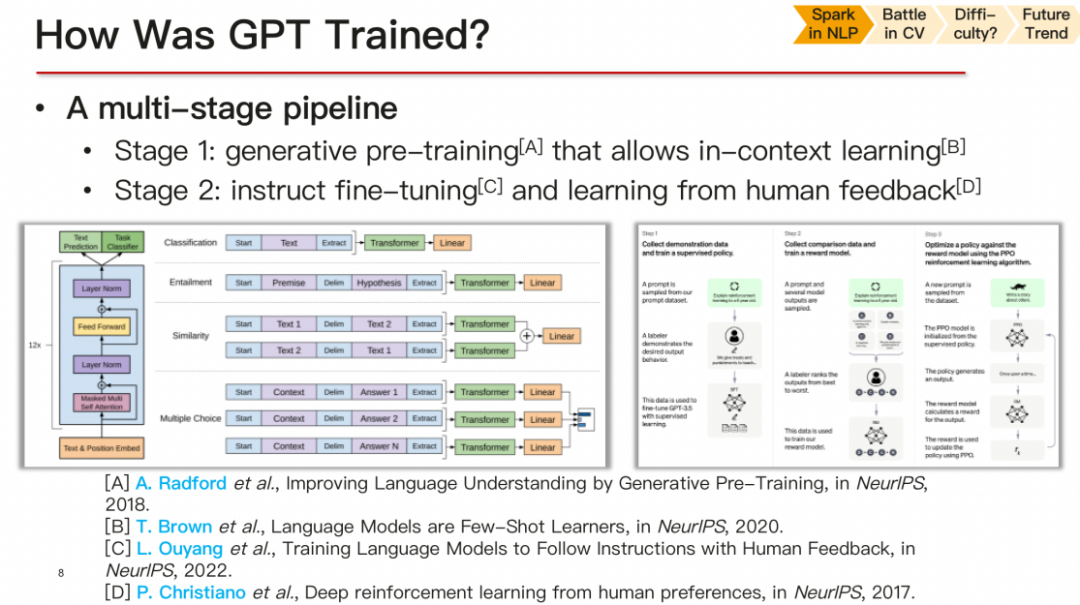
關(guān)于GPT的訓(xùn)練過程,它分為兩個(gè)階段。首先,在大規(guī)模的無(wú)標(biāo)簽語(yǔ)料庫(kù)上進(jìn)行無(wú)監(jiān)督學(xué)習(xí),掌握數(shù)據(jù)分布。然后,在帶有標(biāo)簽的語(yǔ)料庫(kù)上進(jìn)行指令微調(diào),以完成特定任務(wù)。這是一個(gè)兩步走的過程,大家可能都比較熟悉,所以我就不再詳細(xì)解釋了。
在CV領(lǐng)域,與NLP相比,雖然NLP已經(jīng)看到了AGI的曙光,但CV仍然面臨著一些挑戰(zhàn)。CV問題更加復(fù)雜,涉及的解決方案更加多樣化。每個(gè)CV下游任務(wù),如檢測(cè)、追蹤和分割,可能需要不同的方法和微調(diào),與AGI目標(biāo)相去甚遠(yuǎn)。因此,CV領(lǐng)域需要邁向統(tǒng)一性,即大一統(tǒng)或統(tǒng)一化。目前業(yè)界已經(jīng)提出了五類走向,旨在實(shí)現(xiàn)CV的統(tǒng)一。第一個(gè)是,通過開放域的視覺識(shí)別實(shí)現(xiàn)形式上的統(tǒng)一,引入其他模態(tài)來(lái)實(shí)現(xiàn)視覺識(shí)別的統(tǒng)一化。第二類是,SAM的出現(xiàn)成為一種基座,從而實(shí)現(xiàn)各種下游任務(wù)的相對(duì)統(tǒng)一。第三類:統(tǒng)一視覺編碼,通過編碼的方式將不同的視覺任務(wù)定義成相似或相同的形式,使得一個(gè)模型可以處理多樣的視覺任務(wù)。第四點(diǎn)是統(tǒng)一邏輯,通過大語(yǔ)言模型提供邏輯支持,從中發(fā)現(xiàn)視覺復(fù)雜任務(wù)的邏輯,并調(diào)用基本模塊來(lái)解決它。第五類是統(tǒng)一交互方式,通過統(tǒng)一的交互方式使得CV系統(tǒng)更加靈活和智能。盡管CV領(lǐng)域的統(tǒng)一性面臨著挑戰(zhàn),但這些工作的出現(xiàn)以及不斷的努力,將有望推動(dòng)CV領(lǐng)域向著更加統(tǒng)一和通用的方向發(fā)展。
從識(shí)別和對(duì)話等任務(wù)的角度來(lái)看,計(jì)算機(jī)視覺在識(shí)別細(xì)粒度信息和抽取圖片中的內(nèi)容方面表現(xiàn)不錯(cuò)。然而,回到AGI的定義,即在與環(huán)境互動(dòng)并最大化reward的環(huán)境中實(shí)現(xiàn)通用智能,我們目前還無(wú)法做到這一點(diǎn)。為什么目前無(wú)法實(shí)現(xiàn)AGI呢?這涉及到計(jì)算機(jī)視覺目前面臨的本質(zhì)困難。盡管CV的發(fā)展迅速,但仍然面臨著很大的瓶頸。我們需要分析一下,為什么這些方法不能完全通用,本質(zhì)困難是什么?
在這個(gè)分析過程中,結(jié)論是GPT給我們帶來(lái)的最大啟發(fā)不在于它的預(yù)訓(xùn)練和微調(diào)的方法,而在于對(duì)對(duì)話這一任務(wù)的思考。進(jìn)一步解釋,GPT的最大啟發(fā)在于對(duì)對(duì)話任務(wù)本身的探索。雖然GPT采用了預(yù)訓(xùn)練和微調(diào)的方法,但這并不是其最大的啟發(fā)。對(duì)話任務(wù)的本質(zhì)讓我們開始思考如何在計(jì)算機(jī)視覺中實(shí)現(xiàn)更加通用的方法。因此,我們需要從對(duì)話任務(wù)中汲取啟示,以解決計(jì)算機(jī)視覺面臨的本質(zhì)困難。
對(duì)話任務(wù)在NLP中是一個(gè)非常完美的任務(wù),因?yàn)樗沟梦覀兛梢酝ㄟ^對(duì)話來(lái)實(shí)現(xiàn)非常復(fù)雜的行為。假設(shè)我們生活在一個(gè)純文本的世界中,對(duì)話就成為了一個(gè)可以學(xué)習(xí)任何東西并達(dá)成任何想要做的事情的完備任務(wù)。但是對(duì)于CV,我們需要思考什么樣的任務(wù)能夠?qū)崿F(xiàn)類似對(duì)話任務(wù)的完備性。
回顧AGI的定義,它要求能夠與環(huán)境進(jìn)行互動(dòng)并最大化獎(jiǎng)勵(lì),這樣才能實(shí)現(xiàn)通用人工智能。然而,CV目前還沒有實(shí)現(xiàn)這一點(diǎn)。幾十年前,David Marr等人已經(jīng)提出過,CV必須構(gòu)建一個(gè)世界的模型,并與之進(jìn)行交互,才能實(shí)現(xiàn)廣泛的識(shí)別和通用性。然而到目前為止,這個(gè)構(gòu)建通用環(huán)境的想法還沒有得到充分的實(shí)現(xiàn)。主要原因在于在CV中構(gòu)建通用環(huán)境非常困難。
在CV中,構(gòu)建環(huán)境有兩種可能性:真實(shí)環(huán)境和虛擬環(huán)境。真實(shí)環(huán)境意味著將一個(gè)智能體放在真實(shí)世界中與周圍環(huán)境互動(dòng),但這樣做對(duì)規(guī)模、成本和安全性的要求都非常高。另一種方法是構(gòu)建虛擬環(huán)境,但這個(gè)虛擬環(huán)境的真實(shí)度可能無(wú)法滿足要求,尤其是其他智能體和物體的行為是否符合真實(shí)模式。目前還沒有一個(gè)很好的虛擬環(huán)境能夠解決這個(gè)問題。因此,CV在實(shí)現(xiàn)通用性和構(gòu)建通用環(huán)境方面面臨著困難。
目前,我們無(wú)法完全模擬或仿真一個(gè)真實(shí)的通用環(huán)境,因此在計(jì)算機(jī)視覺中,我們只能通過采樣這個(gè)世界來(lái)獲取數(shù)據(jù)。采樣世界意味著我們利用已有的照片和視頻作為離散的采樣點(diǎn),并在這些離散的點(diǎn)上進(jìn)行模型訓(xùn)練。然而,由于這些采樣點(diǎn)是離散的,我們無(wú)法進(jìn)行與環(huán)境的真正交互,這給構(gòu)建通用環(huán)境帶來(lái)了困難。

為了解決這個(gè)問題,我們可以設(shè)想智能體在與環(huán)境進(jìn)行真實(shí)交互時(shí)所需要的能力,并通過這些想象來(lái)定義代理任務(wù),例如檢測(cè)和追蹤。我們過去二三十年,甚至更長(zhǎng)時(shí)間,CV領(lǐng)域的研究人員都在努力構(gòu)建代理任務(wù),并認(rèn)為通過在這些代理任務(wù)上取得更好的表現(xiàn),我們就能更接近實(shí)現(xiàn)AGI的目標(biāo)。然而,現(xiàn)在的問題是,所有的代理任務(wù)幾乎都已經(jīng)飽和,我們無(wú)法在這些任務(wù)上獲得更多的好處。
在深度學(xué)習(xí)之前,我們走向代理任務(wù)的過程是朝著實(shí)現(xiàn)AGI的方向發(fā)展的,但現(xiàn)在我們似乎已經(jīng)達(dá)到了一個(gè)瓶頸。我們走向代理任務(wù)的同時(shí),可能遠(yuǎn)離了實(shí)現(xiàn)AGI的目標(biāo)。現(xiàn)在我們面臨的一個(gè)最大問題是,過去幾十年所熟悉的研究范式在今天可能已經(jīng)不再適用或者難以繼續(xù)發(fā)展,這是一個(gè)非常重要的問題。
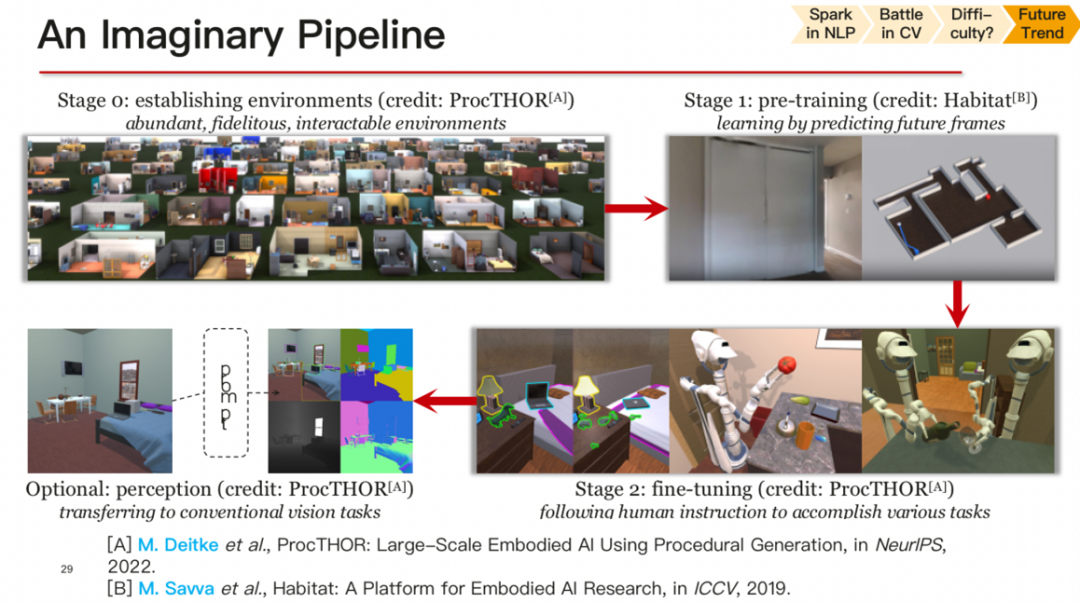
構(gòu)建一個(gè)真實(shí)而足夠復(fù)雜的環(huán)境,讓智能體在其中進(jìn)行學(xué)習(xí)。在這個(gè)pipeline中,首先需要構(gòu)建一個(gè)具有足夠真實(shí)感的環(huán)境,其中不僅包括視覺上的真實(shí)感,還包括其他智能體和物體的真實(shí)行為。在這個(gè)環(huán)境中,可以進(jìn)行預(yù)訓(xùn)練任務(wù),就像GPT預(yù)測(cè)下一個(gè)單詞一樣,智能體可以預(yù)測(cè)下一幀會(huì)看到什么內(nèi)容,從而進(jìn)行真正的預(yù)訓(xùn)練。完成預(yù)訓(xùn)練后,可以進(jìn)行特定的微調(diào)任務(wù),使智能體能夠完成我們希望它完成的任務(wù),如識(shí)別或感知。
然而,目前整個(gè)CV屆可能有些本末倒置,忽略了構(gòu)建真實(shí)環(huán)境的重要性,而過于關(guān)注特定的代理任務(wù)。這導(dǎo)致了一種局限性,阻礙了實(shí)現(xiàn)通用人工智能的發(fā)展。為了實(shí)現(xiàn)提出的pipeline,我們需要關(guān)注相關(guān)的研究工作,包括環(huán)境構(gòu)建和預(yù)訓(xùn)練等方面的工作。尤其要強(qiáng)調(diào)的是,預(yù)訓(xùn)練的方法本身并沒有問題,但是現(xiàn)在的預(yù)訓(xùn)練方法可能在構(gòu)建通用環(huán)境方面有一定的局限性。
因此,為了實(shí)現(xiàn)通用人工智能,我們需要重點(diǎn)關(guān)注如何構(gòu)建更真實(shí)和復(fù)雜的環(huán)境,并探索更加通用的預(yù)訓(xùn)練方法,使得智能體能夠在這樣的環(huán)境中進(jìn)行學(xué)習(xí),獲得更強(qiáng)大的感知和理解能力。這樣的研究將為實(shí)現(xiàn)AGI帶來(lái)重要的突破。
未來(lái),若能有一個(gè)良好的環(huán)境,所有的預(yù)訓(xùn)練方法都會(huì)得到更新。包括過去十年深度強(qiáng)化學(xué)習(xí)在游戲等方面帶來(lái)的一些算法,也可以借鑒視覺中的具身視覺,其中定義了很多任務(wù),如交互和問答。但最本質(zhì)的問題在于目前具身視覺所定義的內(nèi)容還過于簡(jiǎn)單,無(wú)法讓我們?cè)谡鎸?shí)環(huán)境中取得更好的表現(xiàn)。最近出現(xiàn)了一些像PaLM這樣的工作,它們帶給我們更多啟發(fā)。然而,我們只能盡力去模擬這個(gè)環(huán)境,我認(rèn)為這是一個(gè)非常大的問題,其難度甚至不亞于計(jì)算機(jī)視覺本身。
總結(jié)起來(lái),過去二三十年間我們所熟悉的那套范式,在今天看來(lái)也許是難以為繼的。如果是這樣的話,計(jì)算機(jī)視覺領(lǐng)域面臨的困難可能比我們想象的更大。這個(gè)領(lǐng)域現(xiàn)在走到了一個(gè)關(guān)鍵的點(diǎn),對(duì)于我來(lái)說(shuō)可能不太合適,因?yàn)槲耶吘贡容^年輕。然而,我們都需要認(rèn)真思考這個(gè)問題。
現(xiàn)在我想分享一下我的個(gè)人思想,我認(rèn)為現(xiàn)在大語(yǔ)言模型,包括GPT的出現(xiàn),給計(jì)算機(jī)視覺提出了很嚴(yán)峻的問題,我們需要想辦法趕上這個(gè)趨勢(shì)。一方面,我們需要探索一些新的方法論,不再僅僅依賴于數(shù)據(jù)集,但這可能需要一段時(shí)間來(lái)改變。但我認(rèn)為這是趨勢(shì)。另一方面,作為研究者,我們需要勇于擁抱一些新的方法論,不要再固守舊有的方法,否則我們可能會(huì)被這個(gè)時(shí)代所淘汰。總之,謝謝大家的聆聽。
這個(gè)演講的完整版本可以在鏈接: https://github.com/198808xc/Vision-AGI-Survey/中找到,如果有興趣,可以去下載查閱。謝謝大家。
研討階段
Q1:什么是大模型?
盧湖川(大連理工大學(xué))
聽了陳老師的問題后,我想談?wù)勎业南敕āN艺J(rèn)為要從AGI的角度來(lái)看待這個(gè)問題。AGI要求一個(gè)模型具備通吃能力,就像人一樣能夠處理多模態(tài)輸入和輸出,并能解決多種任務(wù)。這就意味著我們需要改變過去的研究范式,從一個(gè)模型解決一個(gè)任務(wù),轉(zhuǎn)變?yōu)橐粋€(gè)模型處理多樣化的數(shù)據(jù),并面向多個(gè)任務(wù)來(lái)解決。為了實(shí)現(xiàn)這種通用任務(wù)能力,我們需要大模型和大數(shù)據(jù)。只有這樣,模型才能涌現(xiàn)出解決各種下游任務(wù)的能力和創(chuàng)新能力,解決未知領(lǐng)域的問題。因此,大模型和大的模型是完全不同的。當(dāng)然,數(shù)據(jù)量也會(huì)對(duì)模型的表現(xiàn)產(chǎn)生影響。
大模型的好處之一是具備強(qiáng)大的通用特征表達(dá)能力,因?yàn)樗{了大量數(shù)據(jù)。另外,大模型還能完成多個(gè)任務(wù),這也是季峰和凌曦所介紹的。過去的解決方案是使用多個(gè)Adapter或Transformer來(lái)處理每個(gè)任務(wù),但這可能會(huì)變得繁瑣。我們需要通用的解決方法,目前也有一些相關(guān)的工作進(jìn)行研究。所以,在大模型的基礎(chǔ)上,我們應(yīng)該思考新的foundation model的研究范式改變。過去我們認(rèn)為對(duì)算力要求很高,但隨著算力的增強(qiáng),目前foundation model的算力要求并不高,這意味著研究方向發(fā)生了改變。至于通才能力和專才能力,我認(rèn)為它們是交互發(fā)展的。通用能力對(duì)于大模型非常重要,但專業(yè)知識(shí)和能力仍然是必需的,就像我們?nèi)祟愐粯樱總€(gè)人都有通用的能力,但同時(shí)也具備自己的專業(yè)知識(shí)和能力,因此它們是交互發(fā)展的。總結(jié)來(lái)說(shuō),大模型和大數(shù)據(jù)是實(shí)現(xiàn)通用人工智能的關(guān)鍵,而大模型帶來(lái)的通用特征表達(dá)能力和多任務(wù)處理能力是其優(yōu)勢(shì)。研究范式的改變和通才能力與專才能力的交互發(fā)展都是當(dāng)前需要考慮的問題。
王興剛(華中科技大學(xué))
大模型在計(jì)算機(jī)視覺領(lǐng)域的通用性和表征能力是一個(gè)重要的問題。目前,雖然通用視覺表征是追求的目標(biāo),但在短期內(nèi)實(shí)現(xiàn)整個(gè)視覺領(lǐng)域的統(tǒng)一可能需要較長(zhǎng)時(shí)間。現(xiàn)在的大模型,比如像CLIP這樣的模型,在某些任務(wù)上具有較強(qiáng)的通用性和表征能力,但對(duì)于其他任務(wù)可能不太適用。從表征的角度來(lái)看,通用的視覺表征在解決各種任務(wù)時(shí)是非常重要的。雖然有許多不同的任務(wù),但我們希望能夠通過一個(gè)統(tǒng)一的特征提取方法來(lái)適用于所有任務(wù),而不需要為每個(gè)任務(wù)設(shè)計(jì)特定的特征提取器。這樣可以節(jié)省時(shí)間和資源,并提高模型的效率和泛化能力。在這方面,一些大模型如CLIP不斷演進(jìn),不斷出現(xiàn)新的版本,通過不同的訓(xùn)練機(jī)制和更多的訓(xùn)練數(shù)據(jù),它們?cè)诟鞣N任務(wù)上的表現(xiàn)能力不斷增強(qiáng)。
因此,模型的參數(shù)量并不是唯一的衡量標(biāo)準(zhǔn),而是要綜合考慮訓(xùn)練機(jī)制、數(shù)據(jù)量和在各種任務(wù)上的性能。另一方面,一些公司和項(xiàng)目存在濫用大模型的情況,把大模型作為實(shí)現(xiàn)目標(biāo)的借口。從科學(xué)的角度來(lái)看,這種濫用并不正確。大模型應(yīng)該在適當(dāng)?shù)膱?chǎng)景下得到應(yīng)用,而不是一味地追求參數(shù)量的增加。科學(xué)家們應(yīng)該以負(fù)責(zé)任的態(tài)度來(lái)推進(jìn)研究,并結(jié)合實(shí)際情況使用合適的模型。總體而言,大模型在計(jì)算機(jī)視覺領(lǐng)域有著重要的作用,但要在科學(xué)的指導(dǎo)下加以使用,以實(shí)現(xiàn)更好的研究和應(yīng)用效果。
山世光(中國(guó)科學(xué)院計(jì)算技術(shù)研究所)
我傾向于稱之為"foundation model",而不是簡(jiǎn)單地區(qū)分大小。我認(rèn)為基礎(chǔ)模型的規(guī)模可能會(huì)非常大,甚至可能比語(yǔ)言模型還大。然而,目前我們可能還沒有找到合適的方法來(lái)實(shí)現(xiàn)這種超大規(guī)模的基礎(chǔ)模型,但最終基礎(chǔ)模型會(huì)變得更大。關(guān)于基礎(chǔ)模型的作用,它的主要目標(biāo)是對(duì)無(wú)法用語(yǔ)言或符號(hào)表達(dá)的知識(shí)進(jìn)行建模。類比人類的視覺發(fā)育,嬰兒在學(xué)會(huì)語(yǔ)言之前,已經(jīng)通過視覺和其他感覺系統(tǒng)接收了大量的信息,并形成了關(guān)于物理世界的一些常識(shí)性知識(shí)。這些常識(shí)性知識(shí)可能無(wú)法通過語(yǔ)言來(lái)完全表達(dá),而是存在于我們的視覺皮層及相關(guān)腦區(qū)中。因此,基礎(chǔ)模型應(yīng)該能夠表示這些只可意會(huì)不可言傳的常識(shí)性知識(shí),它是一種分布式的、與人類符號(hào)型知識(shí)體系完全不同的知識(shí)表示方式。
ChatGPT的最大成功之處在于提供了解決人工智能領(lǐng)域最難的知識(shí)表示特別是常識(shí)性知識(shí)表示問題的一個(gè)重要進(jìn)展。傳統(tǒng)的符號(hào)主義知識(shí)表示方法,如知識(shí)庫(kù)和知識(shí)圖譜,在常識(shí)性知識(shí)表示方面存在很大的局限性。而基于大模型的分布式表示方法,如ChatGPT,成功地突破了這些限制,并提供了一種新型的知識(shí)表示和利用方式。
我認(rèn)為,在表達(dá)常識(shí)性的隱性知識(shí)方面,基礎(chǔ)模型是必不可少的。此外,類似CLIP之類的視覺-語(yǔ)言雙模態(tài)模型,通過在表示層次上對(duì)齊視覺和語(yǔ)言的語(yǔ)義,更為大量視覺理解類任務(wù)提供了解決“理解”類任務(wù)必需的語(yǔ)義知識(shí)。
王菡子(廈門大學(xué))
隨著模型規(guī)模的不斷增大,從最初簡(jiǎn)單的幾個(gè)參數(shù)到現(xiàn)在的千億級(jí)參數(shù),我們確實(shí)面臨著一系列新的挑戰(zhàn)。其中一個(gè)挑戰(zhàn)是對(duì)大模型結(jié)果的驗(yàn)證和解釋。在過去,我們可以輕松地驗(yàn)證和解釋簡(jiǎn)單的模型,比如直線模型。但是現(xiàn)在,像ChatGPT這樣龐大的模型,以及上午提到的可信人工智能,其參數(shù)量已經(jīng)超出了我們?nèi)祟惱斫獾姆懂牐茈y通過傳統(tǒng)方式解釋其內(nèi)部運(yùn)作和結(jié)果。
這就引發(fā)了一個(gè)問題,如何驗(yàn)證大模型的結(jié)果是否正確、可信。由于大模型是類似黑盒子,我們難以直接解釋其內(nèi)部工作,從而也難以確定其結(jié)果的準(zhǔn)確性。在這種情況下,我們需要探索新的方法來(lái)驗(yàn)證大模型的輸出,以及評(píng)估其結(jié)果的準(zhǔn)確性。此外,作為高校老師,面臨的挑戰(zhàn)之一是算力不足。與一些公司擁有強(qiáng)大算力不同,在算力不足的情況下進(jìn)行大模型的研究可能會(huì)面臨一定的困難。在有限的算力下,如何深入地研究大模型,甚至創(chuàng)造性地發(fā)展新的方法,而不僅僅是簡(jiǎn)單地調(diào)整模型參數(shù),是一個(gè)值得探索的問題。
總的來(lái)說(shuō),大模型的發(fā)展帶來(lái)了許多新的挑戰(zhàn),包括驗(yàn)證結(jié)果的可信性和解釋性,以及在算力有限的情況下進(jìn)行研究的難題。這些問題需要我們?cè)谌斯ぶ悄茴I(lǐng)域不斷尋求新的解決方案和創(chuàng)新。
魏云超(北京交通大學(xué))
很高興能參與這次研討,我個(gè)人認(rèn)為,對(duì)于“大模型”這個(gè)概念,實(shí)際上是相對(duì)而言的,取決于我們當(dāng)前的硬件資源和計(jì)算技術(shù)的限制。比如,現(xiàn)在的一個(gè)小模型在10年前或20年前可能都算是大模型,而未來(lái)隨著硬件設(shè)備或量子計(jì)算等技術(shù)的進(jìn)步,現(xiàn)在的所有模型可能都會(huì)變成小模型。
因此,“大”與“小”都有時(shí)間上的局限性。另外,我們目前都在追求通用的視覺模型,但是視覺任務(wù)本身非常復(fù)雜,應(yīng)用場(chǎng)景也非常多樣,包括工業(yè)視覺、醫(yī)學(xué)視覺等等。如果有一個(gè)模型能在特定領(lǐng)域內(nèi)表現(xiàn)得極其優(yōu)秀,解決問題的能力非常出色,那對(duì)于這個(gè)特定的視覺領(lǐng)域來(lái)說(shuō),這個(gè)模型就可以被認(rèn)為是我們當(dāng)前認(rèn)知下的大模型或者基礎(chǔ)模型。
Q2:大模型帶來(lái)了什么幫助?
林倞(中山大學(xué))
大型語(yǔ)言模型,尤其是像GPT這樣的模型,對(duì)視覺領(lǐng)域帶來(lái)了很多幫助。它們解決了視覺領(lǐng)域常常面臨的常識(shí)理解和推理難題。過去,視覺領(lǐng)域常常面臨將領(lǐng)域知識(shí)融入視覺模型的難題,而現(xiàn)在,像CLIP這樣的模型真正實(shí)現(xiàn)了將對(duì)世界的理解和常識(shí)融入到一個(gè)大模型中,使其具備了更強(qiáng)的通用性。因此,我們應(yīng)該充分利用這些大型語(yǔ)言模型為視覺領(lǐng)域帶來(lái)的能力,用于推理和跨領(lǐng)域的任務(wù)。
此外,大型多模態(tài)模型的發(fā)展也推動(dòng)了人工智能生成領(lǐng)域的發(fā)展。它們給了我們很多啟發(fā),使我們考慮是否可以將視覺領(lǐng)域的模型設(shè)計(jì)成通用架構(gòu),從底層的通用性到上層的任務(wù)導(dǎo)向逐步演進(jìn)。這種思路可以促進(jìn)視覺領(lǐng)域的研究發(fā)展,從而更好地應(yīng)用于實(shí)際問題。大型語(yǔ)言模型為計(jì)算機(jī)視覺帶來(lái)了很多可能性,并且啟發(fā)了視覺領(lǐng)域的發(fā)展方向。我們應(yīng)該充分利用這些機(jī)會(huì),進(jìn)一步推動(dòng)計(jì)算機(jī)視覺和人工智能生成領(lǐng)域的研究。
黃高(清華大學(xué))
我分享兩個(gè)觀點(diǎn)。第一個(gè)觀點(diǎn)強(qiáng)調(diào)了大模型的質(zhì)變。在NLP領(lǐng)域,大模型的出現(xiàn)帶來(lái)了質(zhì)變的能力提升,讓我們看到了更大的潛力和想象空間。以前在視覺領(lǐng)域,數(shù)據(jù)集刷到一定程度后可能就會(huì)飽和,沒有顯著的性能提升。而現(xiàn)在,大模型在視覺領(lǐng)域也帶來(lái)了新的啟發(fā),當(dāng)參數(shù)量增加到一定程度時(shí),可能會(huì)出現(xiàn)質(zhì)變的能力提升。這讓我們有可能評(píng)估和debug大模型,尋找性能的關(guān)鍵點(diǎn)。
第二個(gè)觀點(diǎn)強(qiáng)調(diào)了通用模型的設(shè)計(jì)。像CLIP這樣的模型向我們展示了開放設(shè)置下的小樣本學(xué)習(xí)能力。然而,現(xiàn)實(shí)世界中的視覺挑戰(zhàn)遠(yuǎn)不止于此,它還涉及到對(duì)三維和動(dòng)態(tài)世界的感知。雖然我們已經(jīng)取得了一些進(jìn)展,但在這方面,我們?nèi)匀惶幱谄鸩诫A段。真正將對(duì)三維和動(dòng)態(tài)世界的感知能力融入到視覺模型中,這是未來(lái)的一個(gè)重要目標(biāo)。類似于生物進(jìn)化中,視覺帶來(lái)了巨大的進(jìn)步,我們相信在未來(lái)的研究中,對(duì)于三維和動(dòng)態(tài)世界的理解也將為計(jì)算機(jī)視覺帶來(lái)重要的突破。這些觀點(diǎn)都對(duì)計(jì)算機(jī)視覺領(lǐng)域的發(fā)展和研究方向提供了有益的啟示。
王濤(航天宏圖)
今天我們進(jìn)行了很多討論,我認(rèn)為非常有價(jià)值。我想提出一個(gè)問題,就是關(guān)于ChatGPT的參數(shù)存儲(chǔ)。大家都認(rèn)為其擁有1750億參數(shù),但這些參數(shù)實(shí)際上存儲(chǔ)了什么內(nèi)容呢?我覺得一方面它包含了人類的語(yǔ)言推理能力,比如符號(hào)推理等理解能力。另一方面,它還蘊(yùn)含了大量人類知識(shí),因?yàn)槿祟惖闹R(shí)庫(kù)非常龐大,所以ChatGPT可以回答各種問題,ChatGPT給我們帶來(lái)了很多啟示。首先,我們之前討論過掩碼學(xué)習(xí)這種方式,但是ChatGPT可以回答問題,做摘要,進(jìn)行語(yǔ)言翻譯,這些功能讓人驚嘆。它同時(shí)還學(xué)習(xí)了中英文,具備跨語(yǔ)言能力。我們需要進(jìn)一步思考,它是如何打通這些環(huán)節(jié)的,陳老師提到的基本模塊似乎是一個(gè)關(guān)鍵。
另一個(gè)問題是關(guān)于video chat,我們應(yīng)該如何設(shè)計(jì)?大家提到了算力和數(shù)據(jù)的問題,我們應(yīng)該如何訓(xùn)練和標(biāo)記數(shù)據(jù)?如何將語(yǔ)義和圖像之間的關(guān)系打通?給他一個(gè)片段,中間掩碼掉一些內(nèi)容,這種方式是否可行?還有人類的視覺先天基本模塊,像識(shí)別顏色、點(diǎn)線面、人臉等結(jié)構(gòu),但后天學(xué)習(xí)也很重要。我們是否可以將這些基本模塊和ChatGPT的模塊相結(jié)合,形成一個(gè)語(yǔ)言推理再加上視覺基本能力的系統(tǒng),以獲得更好的結(jié)果?這個(gè)問題值得我們深入探討。
胡事民(清華大學(xué))
有一點(diǎn)我想談的是,ChatGPT推出后我們的思考是什么?首先,大模型已經(jīng)呈現(xiàn)出多方競(jìng)爭(zhēng)的狀態(tài),主要分為三派。一派是OpenAI和由OpenAI派生出來(lái)的Claude,他們技術(shù)上處于領(lǐng)先地位,自我迭代發(fā)展非常快。另一派是以Meta的LLaMA為代表的開源派,許多單位在使用開源的大模型進(jìn)行微調(diào)和改進(jìn)。第三個(gè)是本土派,國(guó)內(nèi)的一些大學(xué)和公司在進(jìn)行自己的研究,如清華唐杰、復(fù)旦邱錫鵬等,以及百度、訊飛等企業(yè)。對(duì)于自然語(yǔ)言大模型,現(xiàn)在主要采用Transformer架構(gòu),但它仍然存在問題,因?yàn)槿祟惖闹R(shí)表示和推理還沒有很好整合,存在差距。
談到視覺大模型,我們討論了很多,如SegmentAnything、CLIP等,但與ChatGPT這種現(xiàn)象級(jí)的應(yīng)用相比,仍然有很大差距。ChatGPT之所以有影響,是因?yàn)樗鼘?shí)現(xiàn)了很好的對(duì)話應(yīng)用,引起了全社會(huì)的極大關(guān)注。
但是對(duì)于視覺大模型,我們需要探討更多的問題,如采用何種架構(gòu),是否需要一個(gè)像ChatGPT一樣的應(yīng)用場(chǎng)景來(lái)讓視覺大模型落地。我個(gè)人覺得可以嘗試創(chuàng)建一個(gè)人與機(jī)器人交互的場(chǎng)景,讓機(jī)器人理解人類,并將檢測(cè)、識(shí)別等計(jì)算機(jī)視覺的常用功能整合起來(lái);這樣的場(chǎng)景才能催生視覺大模型的發(fā)展。為了解決這個(gè)問題,我們面臨兩個(gè)挑戰(zhàn)。第一個(gè)是需要一個(gè)統(tǒng)一的視覺內(nèi)容的骨干網(wǎng)絡(luò),類似于自然語(yǔ)言處理中的Transformer。第二個(gè)是算力問題,因?yàn)橐曈X大模型的算力遠(yuǎn)超過自然語(yǔ)言大模型,需要發(fā)展算力網(wǎng),通過軟硬件協(xié)同優(yōu)化,積極發(fā)揮國(guó)產(chǎn)芯片的落地應(yīng)用。
徐凱(國(guó)防科技大學(xué))
胡老師剛才談的非常有啟發(fā)性。最近OpenAI的一篇博客討論了通用AI的一個(gè)實(shí)現(xiàn)思路,我非常認(rèn)同。他們提出將智能系統(tǒng)分為三層:最上層是一個(gè)大語(yǔ)言模型,用于和用戶交互,接受用戶指令,理解用戶意圖,同時(shí)將用戶指定的某項(xiàng)復(fù)雜任務(wù)拆解成一系列相對(duì)簡(jiǎn)單的子任務(wù),類似于基于思維鏈(Chain-of-Thought)的任務(wù)拆解。每一個(gè)子任務(wù),可能對(duì)應(yīng)一段代碼,一個(gè)工具,或者是一個(gè)軟件、一個(gè)服務(wù),比如計(jì)算器、瀏覽器、各種app等,用于執(zhí)行具體任務(wù),這一層叫工具利用。在大語(yǔ)言模型層和工具利用層之間,還要有一個(gè)記憶層。
為什么要有這么一個(gè)記憶層呢?我們知道大模型具有一定的記憶能力(注:這里的記憶指的是與特定用戶或情境相關(guān)的記憶,而不是大模型在預(yù)訓(xùn)練階段記憶的通用知識(shí)),多輪對(duì)話本身就體現(xiàn)了一定的記憶能力,但這是短期記憶能力。一個(gè)智能體要想完成更復(fù)雜的任務(wù),比如像家庭機(jī)器人一樣長(zhǎng)期陪伴在用戶身邊,需要長(zhǎng)期記憶用戶的習(xí)慣愛好、脾氣秉性等,只有基于長(zhǎng)期記憶機(jī)制,才能逐漸“馴化”出一個(gè)定制化的智能體,以提升用戶的使用體驗(yàn)。文章提出可以基于向量數(shù)據(jù)庫(kù)來(lái)實(shí)現(xiàn)長(zhǎng)期記憶,因?yàn)樗梢灾С指咝Р樵儭?/p>
不過我認(rèn)為,這個(gè)長(zhǎng)期記憶應(yīng)該不止是符號(hào)化的、知識(shí)型的記憶,還需要有對(duì)3D空間的記憶,也就是要對(duì)智能體所在的3D環(huán)境、周遭的3D對(duì)象進(jìn)行高效的建模和編碼,以支持智能體在3D環(huán)境中完成復(fù)雜交互任務(wù),從而實(shí)現(xiàn)具身智能。這對(duì)于機(jī)器人來(lái)說(shuō)是很有必要的:比如機(jī)器人倒水的時(shí)候把杯子碰倒了,GPT可以告訴機(jī)器人去拿抹布。要具體執(zhí)行“拿抹布”這個(gè)動(dòng)作,需要進(jìn)一步輸出細(xì)化的動(dòng)作指令,如果沒有關(guān)于3D空間的記憶,GPT發(fā)出的動(dòng)作指令可能根本無(wú)法完成。
那么,該如何實(shí)現(xiàn)對(duì)3D場(chǎng)景的高效建模和表征,以支持上述的空間智能呢?還沒有一個(gè)很好的答案。剛才有老師提到了NeRF表示的前景,NeRF的確非常強(qiáng)大,但它在這里是否合適?我不知道。NeRF的提出面向的是新視角合成(渲染),它把幾何編碼在神經(jīng)網(wǎng)絡(luò)里,這的確是一種非常緊湊的表示,但是它對(duì)高效查詢并不友好,給定一個(gè)3D空間中的位置,神經(jīng)網(wǎng)絡(luò)只能告訴你這一點(diǎn)在物體內(nèi)(occupied)還是物體外(free space),以及顏色信息,卻無(wú)法告知你附近的幾何信息(為此你需要逐點(diǎn)去查詢),更無(wú)法告訴你全局的拓?fù)浜蛶缀涡畔ⅲ@對(duì)于實(shí)現(xiàn)空間智能是有問題的。我想,可能需要一種更加結(jié)構(gòu)化的、同時(shí)也是可微分學(xué)習(xí)的3D場(chǎng)景表達(dá),同時(shí)支持幾何和語(yǔ)義信息的高效關(guān)聯(lián)、查詢、更新等。這個(gè)方向會(huì)非常有意思。
謝凌曦(華為)
我想解釋一下我的定義,什么是foundation model。我認(rèn)為作為一個(gè)foundation model,它的大小或者完成的任務(wù)并不是它的本質(zhì)。它的本質(zhì)在于建立這個(gè)世界的數(shù)據(jù)分布,只要一個(gè)模型建立了一個(gè)好的數(shù)據(jù)分布,它就可以被稱為是一個(gè)foundation model。在這種情況下,我們需要回應(yīng)一下山老師之前提出的問題,即視覺模型的參數(shù)量。我認(rèn)為視覺模型的參數(shù)量會(huì)比NLP模型要大很多,因?yàn)橐曈X世界比自然語(yǔ)言的世界要復(fù)雜。所以,如果我們要用一個(gè)模型來(lái)建模視覺世界的數(shù)據(jù)分布,它所需要的參數(shù)量會(huì)至少要大一些。在這種情況下,我們目前的關(guān)鍵問題不是我們不知道什么樣的架構(gòu)是合適的,因?yàn)槲艺J(rèn)為現(xiàn)在的Transformer已經(jīng)足夠強(qiáng)大了。我們現(xiàn)在真正不知道的是這個(gè)世界到底是什么樣的。我們沒有一個(gè)很好的理解,難道互聯(lián)網(wǎng)就是我們整個(gè)世界的一個(gè)映射?
所以我想再?gòu)?qiáng)調(diào)一下,我們需要自己去定義這個(gè)世界的模型。無(wú)論是用Yann LeCun的方法去定義一個(gè)world model,還是通過具身的方法去實(shí)現(xiàn)高度真實(shí)的仿真來(lái)定義這個(gè)世界,這是我們現(xiàn)在最迫切需要做的事情。一旦有了這個(gè)定義,我們就能夠建立起自然和人工的對(duì)齊,然后在這個(gè)基礎(chǔ)上運(yùn)行各種模型,將分布對(duì)齊到各種任務(wù)中,從而實(shí)現(xiàn)各種復(fù)雜的任務(wù)。至于徐老師剛才提到的記憶力,我認(rèn)為NLP是一個(gè)記憶力很好的典范,它可以記住很多知識(shí)。為什么呢?因?yàn)槲覀兘o予它足夠多的數(shù)據(jù),讓它真正地記住了這個(gè)數(shù)據(jù)分布,并且它發(fā)現(xiàn)了數(shù)據(jù)與任務(wù)之間的關(guān)聯(lián)。如果我們能夠真正訂閱一個(gè)足夠真實(shí)的世界,那么在這樣的環(huán)境中訓(xùn)練出來(lái)的模型也一定會(huì)具有足夠強(qiáng)的記憶力,否則它不可能去記住這個(gè)分布。所以我認(rèn)為理解這個(gè)世界,或者說(shuō)建立仿真環(huán)境是非常重要的。
操曉春(中山大學(xué))
剛才提到的NLP研究里無(wú)監(jiān)督填空的角度,我們漢字常用的有6000個(gè)字,所以復(fù)雜度是1/6000。如果是兩個(gè)字,最多則是6000的2次方。因?yàn)檎Z(yǔ)言是人類創(chuàng)造的,所以存在強(qiáng)烈的規(guī)則性,這個(gè)填空尋優(yōu)的復(fù)雜度遠(yuǎn)低于暴力的指數(shù)次方,所以在這種填空問題上應(yīng)該是相對(duì)容易的。比如說(shuō)我們學(xué)過漢字的人都可以去填詞,填得好不好不說(shuō),至少可以填上去。
第二點(diǎn)是視覺大模型為什么相對(duì)困難?凌曦老師剛才說(shuō)復(fù)雜2到3個(gè)數(shù)量級(jí),我感覺可能還不止,因?yàn)槲覀兛梢院?jiǎn)單算一下。以NLP填空和視覺的completion為例,一個(gè)物體旁邊可能是任何幾何形狀(遮擋)和顏色的物體,這個(gè)可能性幾乎是無(wú)限的,譬如一個(gè)人的旁邊可以是杯子、墻、掃帚,甚至是恐龍或者泰國(guó)大象,所以在這種情況下,咱們不應(yīng)該做太多假設(shè),否則容易被pre-train影響而產(chǎn)生bias,因此復(fù)雜度是遠(yuǎn)遠(yuǎn)高于NLP的。目前早期的視覺基礎(chǔ)大模型還不夠強(qiáng)大,僅通過類似于NLP填空的的方法效果不佳,至少現(xiàn)在沒有成功。所以,我直覺可能還需要一步一步來(lái),在某些特定領(lǐng)域,比如面向卡通或者日本漫畫的視覺任務(wù),由于存在大量的先驗(yàn)和簡(jiǎn)化,問題空間大大降低,其卡通任務(wù)的視覺大模型可能先于泛在視覺大模型,超越人類的視覺系統(tǒng)。
最后是胡老師說(shuō)到的統(tǒng)一視覺基礎(chǔ)大模型的骨干網(wǎng)絡(luò),剛才有人說(shuō)了Transformer這個(gè)framework,我也一直在跟學(xué)生討論,它在NLP為什么成功?因?yàn)樗腥祟愒O(shè)計(jì)的或者約定俗成的語(yǔ)法結(jié)構(gòu),有元音、輔音、主謂賓等很好切割的components,但是視覺是不好斷開的,其語(yǔ)義components及components之間的關(guān)系要更加復(fù)雜。雖然Transformer在視覺上也取得了很多進(jìn)展,但是是否成為胡老師要求的視覺大模型骨干網(wǎng)絡(luò),現(xiàn)在還不清楚。
吳小俊(江南大學(xué))
我認(rèn)為大模型可以用數(shù)學(xué)中的子空間概念來(lái)理解。每個(gè)大模型實(shí)際上就是物理世界子空間的建模。現(xiàn)有的模型如SAM和CLIP可以看作現(xiàn)實(shí)世界的子空間,可能還有細(xì)分行業(yè)的子空間。因此,基礎(chǔ)模型可以看作是子空間的一個(gè)實(shí)例,而子空間的本質(zhì)是由其特征量決定的。找到我們數(shù)據(jù)的大模型,就是要找到數(shù)據(jù)的這些特征量。因?yàn)橐曈X大模型與一些基礎(chǔ)功能模塊相關(guān),而這些基礎(chǔ)功能模塊實(shí)際上就是子空間的特征量。
這些子空間可能呈現(xiàn)的方式不同,例如在歐式空間中可能是特征,或者像張老師早期提出的remaining management中可能會(huì)呈現(xiàn)出全面空間,這也與現(xiàn)實(shí)世界對(duì)應(yīng)。用子空間這個(gè)概念來(lái)理解ChatGPT可能會(huì)有點(diǎn)異想天開,但可以認(rèn)為整體上我們從線性代數(shù)到泛函分析,再到泛函的維度,從有限到無(wú)限,可能現(xiàn)在的ChatGPT是一個(gè)比較大的子空間,甚至有點(diǎn)像泛函的子空間。
而我們現(xiàn)在的視覺模型里的子空間是一些具體領(lǐng)域的小子空間。但是這些子空間經(jīng)過研究后,最后匯聚成了我們視覺的大模型。這個(gè)觀點(diǎn)可以解釋陳老師提出的觀點(diǎn),以及其他專家提出的相似觀點(diǎn)。至于徐老師提出的內(nèi)部記憶和外部記憶,我不太認(rèn)同。因?yàn)槲矣X得模型中的記憶機(jī)制更像是受到宏觀計(jì)算架構(gòu)的影響,而我們?nèi)四X中的信息存儲(chǔ)機(jī)制實(shí)際上是內(nèi)容相關(guān)的。
陳寶權(quán)(北京大學(xué))
視覺領(lǐng)域的問題非常復(fù)雜,因?yàn)榭臻g太大。目前的基礎(chǔ)模型只是滿足了需求的兩三個(gè)部分,只有到那個(gè)時(shí)候,我們才可能看到類似video ChatGPT 這樣的東西。AIMP對(duì)視覺提供了很大的啟示,現(xiàn)在大家正在研究視覺語(yǔ)言大模型,像SAM這樣的模型出現(xiàn)后,下一步可能是通過數(shù)據(jù)量和標(biāo)注的提升,提高精度,讓人們感到驚艷。類似ImageNet標(biāo)注大數(shù)據(jù)集推動(dòng)了視覺發(fā)展一樣,接下來(lái)可能會(huì)有視覺語(yǔ)言的大模型,類似ChatGPT,通過眾多人對(duì)視覺任務(wù)進(jìn)行語(yǔ)言標(biāo)注,從而完成更大的數(shù)據(jù)集建設(shè),推動(dòng)視覺語(yǔ)言大模型的誕生,產(chǎn)生讓人驚艷的video ChatGPT等等。
另外,目前的視覺大模型讓我們從閉集走向了開集,以前在所有任務(wù)上,包括RTC任務(wù),都是在封閉的數(shù)據(jù)集里進(jìn)行。但是現(xiàn)在SAM出現(xiàn)后,雖然在閉集上表現(xiàn)不太好,但是因?yàn)槠浞夯芰軓?qiáng),它在通用表達(dá)上接近人類認(rèn)知,因此受到認(rèn)可。隨著技術(shù)不斷進(jìn)步,可能會(huì)真正實(shí)現(xiàn)在現(xiàn)實(shí)中開集驗(yàn)證。最后,這些大模型對(duì)未來(lái)的機(jī)器人和嵌入式設(shè)備,包括手機(jī)等,都會(huì)有很大幫助。因?yàn)樗鼈兛梢酝瓿赏ㄓ萌蝿?wù),與環(huán)境交互,使ChatGPT不斷地進(jìn)行交互和學(xué)習(xí),從而不斷提升能力,這將帶來(lái)更大的潛力。
Q3:計(jì)算機(jī)視覺的哪些問題在大模型的背景下不值得再繼續(xù)做下去了?
金連文(華南理工大學(xué))
結(jié)合我在OCR領(lǐng)域的經(jīng)驗(yàn),我想談?wù)勔恍w會(huì)。在OCR領(lǐng)域,我們需要處理視覺和語(yǔ)言方面的任務(wù)。比如,給定一個(gè)發(fā)票,我們需要識(shí)別其中的內(nèi)容,并提取關(guān)鍵信息,生成結(jié)構(gòu)化的輸出,這也適用于其他包含結(jié)構(gòu)化文檔的任務(wù)。關(guān)于GPT模型,它在理解和語(yǔ)言相關(guān)任務(wù)上表現(xiàn)優(yōu)秀,讓我們感覺像大腦皮質(zhì)一樣有效。我們進(jìn)行了一些實(shí)驗(yàn),比如在小組或?qū)W習(xí)中,使用開源的大模型(如V3引擎、GPT-3.5的API),來(lái)完成理解任務(wù),如從視頻中抽取關(guān)鍵文本。這些模型的效果都非常好,尤其在與語(yǔ)言相關(guān)的任務(wù)上。
接下來(lái),我想補(bǔ)充一點(diǎn)。作為CV領(lǐng)域的研究人員,我們希望能在CV領(lǐng)域發(fā)展出自己的基礎(chǔ)模型,而不僅僅受到NLP領(lǐng)域的影響。GPT模型給我們帶來(lái)的最大啟示并不是在語(yǔ)言理解或文本生成方面的突破,而是在將全人類的知識(shí)融入一個(gè)模型的簡(jiǎn)單方法。盡管目前還不完美,但我們已經(jīng)看到了它的潛力。通過內(nèi)訓(xùn)練和強(qiáng)化學(xué)習(xí)技術(shù),我們可以使模型學(xué)習(xí)全人類的知識(shí)。在視頻領(lǐng)域是否能實(shí)現(xiàn)類似的模型,還需要進(jìn)一步探索和研究。
操曉春(中山大學(xué))
接著金老師的答案,我補(bǔ)充一點(diǎn)。由于在座的金老師、白翔老師等在OCR技術(shù)方面的技術(shù)創(chuàng)新,許多其它領(lǐng)域的任務(wù)已經(jīng)不再需要。比如以前我們想要從PDF、PPT中提取文字,需要研究PDF、PPT的格式,這需要不停地更新技術(shù)版本。然而,有了OCR后,我們可以簡(jiǎn)化這個(gè)過程,Screen Capture文檔,直接用OCR高效地提取所需的關(guān)鍵文字信息。
謝凌曦(華為)
我來(lái)談?wù)剝蓚€(gè)較好的研究方向。第一個(gè)是視覺網(wǎng)絡(luò)架構(gòu)的設(shè)計(jì),第二個(gè)是視頻預(yù)訓(xùn)練。當(dāng)然,我并不是說(shuō)這兩個(gè)方向一定不要去做,因?yàn)檫@兩個(gè)領(lǐng)域都非常龐大,但我們覺得這兩個(gè)領(lǐng)域目前都面臨著很大的挑戰(zhàn)。比如以前在網(wǎng)絡(luò)架構(gòu)設(shè)計(jì)方面,我們可以設(shè)計(jì)一個(gè)新的網(wǎng)絡(luò)架構(gòu),并在baseline上進(jìn)行評(píng)測(cè),如果分類效果更好,那就說(shuō)明這個(gè)網(wǎng)絡(luò)效果更好。預(yù)訓(xùn)練也是一樣,我們可以設(shè)計(jì)預(yù)訓(xùn)練結(jié)構(gòu)和算法,并在相應(yīng)數(shù)據(jù)集上進(jìn)行測(cè)試,如果精度更高,那就說(shuō)明我們的算法更好。
但為什么現(xiàn)在這兩個(gè)領(lǐng)域似乎進(jìn)展緩慢呢?這是因?yàn)楝F(xiàn)有的數(shù)據(jù)集已經(jīng)相當(dāng)飽和了,即使我們換用更大的數(shù)據(jù)集,也很難獲得明顯的提升。所以我認(rèn)為,現(xiàn)在這兩個(gè)方向并非沒有必要繼續(xù)研究,而是因?yàn)樗鼈兠媾R一些困境,我們迫切需要一個(gè)更好的評(píng)測(cè)指標(biāo)來(lái)指導(dǎo)研究。這個(gè)評(píng)測(cè)指標(biāo)可能是多方面的,要么是更大、更難的數(shù)據(jù)集,但我對(duì)這一點(diǎn)不太看好;要么是一個(gè)更好的交互環(huán)境。在報(bào)告中重點(diǎn)討論了環(huán)境的問題,如果我們解決了評(píng)測(cè)或環(huán)境的問題,我相信無(wú)論是更好的網(wǎng)絡(luò)架構(gòu)還是更優(yōu)的預(yù)訓(xùn)練算法,都會(huì)涌現(xiàn)出來(lái)。
剛才有老師說(shuō)了,現(xiàn)在的一些模型都是盲目的嘗試,我非常同意這一觀點(diǎn)。但現(xiàn)在為什么沒有人去專注于這個(gè)方面呢?因?yàn)榧词鼓阍O(shè)計(jì)了一個(gè)非常巧妙的方法,可能在實(shí)際應(yīng)用中也只能使點(diǎn)擊率提高0.2個(gè)百分點(diǎn),可能這篇論文的影響力也不會(huì)很大。所以我們面臨的評(píng)測(cè)壓力更大,我認(rèn)為一旦評(píng)測(cè)或環(huán)境的問題解決了,很多視覺領(lǐng)域都會(huì)迎來(lái)新的突破。我就是這么認(rèn)為的。
山世光(中國(guó)科學(xué)院計(jì)算技術(shù)研究所)
陳老師說(shuō)的很有道理。我想表達(dá)的意思是,有一段時(shí)間sparse coding、sparse representation特別火的時(shí)候,我當(dāng)時(shí)做編委的期刊主編確實(shí)曾給全體編委發(fā)郵件,建議謹(jǐn)慎錄用這類主題的投稿,當(dāng)然是謹(jǐn)慎錄用,不是直接拒稿,但暗示不鼓勵(lì),因?yàn)橐呀?jīng)難以判斷很多投稿的實(shí)際價(jià)值。回到井東的問題,我覺得很難一一列舉哪些問題可能不該做。但的確,當(dāng)我們有了更大的context model或更強(qiáng)的基礎(chǔ)模型后,過去很多問題的定義確實(shí)就看起來(lái)不那么有意義了。例如小樣本學(xué)習(xí)任務(wù),特別是基于Meta learning的方法,benchmark的設(shè)置是假設(shè)有幾十類甚至只有幾類組成的base set,然后要做新類的N-way K-shot,我認(rèn)為這個(gè)問題的定義就是錯(cuò)的。類比人,人不是這樣的setting,人的小樣本學(xué)習(xí)能力是構(gòu)建在大量學(xué)習(xí)基礎(chǔ)上的,沒有進(jìn)化和發(fā)育過程中對(duì)大量“基類”的學(xué)習(xí),人恐怕也不會(huì)具有“小樣本學(xué)習(xí)能力”。
我們要解決的AI問題,是沒法突破信息論瓶頸的,要解決大規(guī)模未知參數(shù)的欠定求解問題,要么引入更多數(shù)據(jù)形成更多方程,要么引入更多知識(shí)或信息作為約束條件,否則沒有理由獲得更確定的解。現(xiàn)在有了foundation model,我認(rèn)為就是帶來(lái)了更多隱性知識(shí)或上下文信息,從而使得我們獲得滿意解的可能性大大增強(qiáng)。如果不用這些知識(shí)或信息,之前的方法很難獲得滿意的解。我認(rèn)為這是foundation model起作用的本質(zhì),它為下游的數(shù)據(jù)不足任務(wù)的求解提供了一個(gè)強(qiáng)大的基石——基石之外的解就不用考慮了,或者只需要在基石上再增點(diǎn)磚添點(diǎn)瓦就OK了。所以,從這個(gè)意義上講,可能大量問題的解決都要從這個(gè)角度來(lái)重新考慮benchmark,重新設(shè)定測(cè)試協(xié)議。
王濤(航天宏圖)
工業(yè)界還有很多大模型沒有解決的問題。通用大模型、行業(yè)模大模型和場(chǎng)景大模型是分階段發(fā)展的。在工業(yè)場(chǎng)景中,場(chǎng)景級(jí)的大模型非常困難,尤其是由于數(shù)據(jù)量很小的問題,如在無(wú)人機(jī)巡檢中,道路、電力線缺陷識(shí)別,或者在亞米級(jí)遙感影像飛機(jī)、艦船類型等弱小目標(biāo)識(shí)別等。這些場(chǎng)景級(jí)的大模型的實(shí)際應(yīng)用都面臨很大的挑戰(zhàn)。解決場(chǎng)景級(jí)的大模型問題必須考慮樣本收集、小樣本學(xué)習(xí)和遷移學(xué)習(xí)。
在工業(yè)場(chǎng)景中,收集樣本是一個(gè)挑戰(zhàn),例如對(duì)于事故車的檢測(cè),需要大量各種類型的事故車照片。遷移學(xué)習(xí)也是一個(gè)問題,如何將大模型的知識(shí)遷移到具體的工業(yè)應(yīng)用場(chǎng)景。在文字識(shí)別中,當(dāng)遇到藝術(shù)字體等復(fù)雜情況時(shí),視頻難度會(huì)急劇增加。大模型具備普通人的基本能力,但要成為場(chǎng)景級(jí)的專家也同樣困難。這種場(chǎng)景級(jí)的專家模型可以應(yīng)用在具體的工業(yè)場(chǎng)景中,而通用大模型可以用于普通人的生活場(chǎng)景。
查紅彬(北京大學(xué))
大家在討論當(dāng)前大模型時(shí)代該做什么,不該做什么,以及可能要做什么。大模型如ChatGPT在文本與語(yǔ)音處理方面確實(shí)發(fā)揮了重要作用,能夠有效利用從大數(shù)據(jù)中獲取的結(jié)構(gòu)性和抽象知識(shí)。然而,大模型只是我們解決現(xiàn)實(shí)問題的一部分。人類智能在發(fā)展過程中,具有先天和后天兩個(gè)部分,其中基因是一種重要的先天信息來(lái)源。可以說(shuō),基因是在數(shù)百萬(wàn)年人類進(jìn)化過程中積累下來(lái)的一種大模型知識(shí),但是只有基因是不能讓人具備智能的。要成為具有智能的個(gè)體,還需要人的腦與身體系統(tǒng)具有柔性,具有可塑性,即能夠通過與環(huán)境交互和反饋進(jìn)行學(xué)習(xí),使人的系統(tǒng)本身在現(xiàn)實(shí)環(huán)境中產(chǎn)生變化。所以,大模型提供了類似于基因的基礎(chǔ)信息,但要使系統(tǒng)具備柔性和適應(yīng)性,需要在線的學(xué)習(xí)和處理能力,通過與環(huán)境的交互來(lái)改變模型自身,使其更好地適應(yīng)現(xiàn)實(shí)環(huán)境及其變化。因此,除了研究大模型,我們還需要考慮怎樣使系統(tǒng)具備這種柔性和適應(yīng)性。
金連文(華南理工大學(xué))
剛才聽了很多老師的講解,非常受啟發(fā),我也再談?wù)劊M蠹乙黄鹚伎肌J紫龋珻hatGPT在自然語(yǔ)言處理方面讓我們看到了一些令人驚喜的地方,比如有限能力和規(guī)模定義、語(yǔ)言模型的思維鏈等問題。我一直在思考,雖然已經(jīng)有一些相關(guān)的研究,但涉及視覺領(lǐng)域的研究似乎還比較少,不知道是否存在與NLP類似的有限能力和規(guī)模定義的問題。在通用的視覺領(lǐng)域研究這個(gè)問題可能很困難,因?yàn)樾枰罅康挠?jì)算資源,這也是之前大部分老師講的。但在一些垂直領(lǐng)域中,也許大家可以探討這個(gè)問題。
其次,ChatGPT給我們帶來(lái)的啟示并不在于它在特定任務(wù)中的性能有多好,我們的體會(huì)在于它解決實(shí)際問題的通用能力非常強(qiáng)。比如,一個(gè)模型可以放置在任何地方使用。而在我們以前做研究或解決實(shí)際應(yīng)用問題時(shí),對(duì)不同的廠家可能需要重新獲取數(shù)據(jù)并進(jìn)行處理。但有了這樣通用的基礎(chǔ)模型后,這種情況會(huì)大大減少。所以我想問,在垂直領(lǐng)域中是否有可能發(fā)現(xiàn)視覺存在類似的尺度定理、思維鏈,或者視覺有限能力的問題?在NLP領(lǐng)域中研究較多,而視覺領(lǐng)域的相關(guān)文章還較少。
Q4:大模型背景下科研該如何展開?
肖斌(重慶郵電大學(xué))
我認(rèn)為在目前大模型發(fā)展的趨勢(shì)下,CV方向受到的沖擊很大,我們應(yīng)該避免受到過大的影響,而是要轉(zhuǎn)變思路。最近參加了幾次NLP和大模型領(lǐng)域內(nèi)的調(diào)研,邀請(qǐng)了很多該領(lǐng)域的專家參加。一個(gè)共性問題是,高校研究人員做大模型研究所面臨的挑戰(zhàn)主要是計(jì)算能力的問題。NLP領(lǐng)域的大模型參數(shù)量相對(duì)CV領(lǐng)域的參數(shù)較少,即使NLP做得較好的團(tuán)隊(duì),也只有數(shù)百?gòu)埳踔辽锨圙PU卡,對(duì)于我們高校來(lái)說(shuō),這已經(jīng)是極限了,這帶來(lái)了算力上的巨大挑戰(zhàn)。我認(rèn)為,我們可以嘗試從以下幾個(gè)方面來(lái)切入。首先,數(shù)據(jù)共享,避免每個(gè)團(tuán)隊(duì)做大模型時(shí)重復(fù)清洗大量數(shù)據(jù)。其次,模型結(jié)構(gòu)共享和開源,研究適用于計(jì)算機(jī)視覺的基礎(chǔ)結(jié)構(gòu),并開源這些結(jié)構(gòu)。第三,算法優(yōu)化,針對(duì)特定任務(wù)優(yōu)化算法,使其在有限算力下運(yùn)行效果良好。最后,模型的度量,制定統(tǒng)一客觀的度量標(biāo)準(zhǔn),以確定大模型的性能,避免局部指標(biāo)誤導(dǎo)。總的來(lái)說(shuō),當(dāng)前我們需要關(guān)注如何轉(zhuǎn)變思維,解決算力問題,推動(dòng)數(shù)據(jù)、模型結(jié)構(gòu)和算法的共享和優(yōu)化,并確立統(tǒng)一的模型性能評(píng)估標(biāo)準(zhǔn)。這將有助于我們?cè)谟?jì)算機(jī)視覺領(lǐng)域的大模型研究取得更好的進(jìn)展。
毋立芳(北京工業(yè)大學(xué))
首先,關(guān)于大模型的作用,大模型在很大程度上是對(duì)現(xiàn)有知識(shí)的總結(jié)和應(yīng)用。它們可以視為一種基于大量數(shù)據(jù)和經(jīng)驗(yàn)的知識(shí)遷移工具。然而,大模型的適應(yīng)能力有限,它們可能無(wú)法處理一些特定場(chǎng)景下的問題。如何在大模型的基礎(chǔ)上進(jìn)一步提高它們?cè)诓煌瑘?chǎng)景下的適應(yīng)性和靈活性,這可以是一個(gè)有意義的研究方向,探索如何讓大模型更好地理解和應(yīng)對(duì)不同的環(huán)境和情境。其次,關(guān)于資源有限的問題。雖然許多人可能沒有足夠的計(jì)算資源來(lái)構(gòu)建大規(guī)模模型,但我們可以通過引入外部知識(shí)、背景信息或領(lǐng)域?qū)I(yè)知識(shí),來(lái)提高問題的解決效率。這種知識(shí)引入的方法可以在特定場(chǎng)景下,甚至是傳統(tǒng)任務(wù)中,幫助我們更好地解決問題,從而彌補(bǔ)資源有限的情況。這種方法可能會(huì)涉及到知識(shí)圖譜、遷移學(xué)習(xí)、領(lǐng)域知識(shí)的融合等技術(shù),是一個(gè)值得進(jìn)一步研究的方向。
劉靜(中國(guó)科學(xué)院自動(dòng)化研究所)
在簡(jiǎn)潔的描述中,我認(rèn)為大模型的能力評(píng)價(jià)是一個(gè)復(fù)雜的問題,對(duì)科研方向有著重要的引導(dǎo)作用。為了確保自己的工作性能達(dá)到最佳水平,我們需要建立有效的評(píng)測(cè)方法。以GPT-4為例,他在綜合評(píng)測(cè)中表現(xiàn)出色,包括檢索、視覺問答和開放領(lǐng)域的任務(wù)。這表明大模型在開放環(huán)境下的任務(wù)需求日益凸顯,傳統(tǒng)的研究更偏向于閉集任務(wù),而這需要變化。大模型的能力可能不適合簡(jiǎn)單的單一樣本評(píng)價(jià),而應(yīng)更關(guān)注開放環(huán)境下的綜合表現(xiàn)。這引出了一個(gè)值得深入研究的問題,即如何評(píng)價(jià)大模型的綜合能力,以及如何比較大模型、小模型和更強(qiáng)能力模型的表現(xiàn),而不僅僅依賴于現(xiàn)有的基準(zhǔn)測(cè)試。同時(shí),對(duì)于開放任務(wù)的價(jià)值也需要更深入地探索和思考。
代季峰(清華大學(xué))
我認(rèn)為這個(gè)問題可以從另一個(gè)角度來(lái)思考,可能會(huì)更有益。我覺得實(shí)際上與其說(shuō)重點(diǎn)在于模型參數(shù)或者Bug,不如強(qiáng)調(diào)在構(gòu)建性模型以及實(shí)現(xiàn)任務(wù)通用性或強(qiáng)泛化能力方面的重要性。模型參數(shù)和Bug可以被視為實(shí)現(xiàn)這一目標(biāo)的手段,或者說(shuō)是當(dāng)前階段的手段。如果我們圍繞"Action Model"這一概念展開,會(huì)發(fā)現(xiàn)有許多值得探索的事情。
舉例來(lái)說(shuō),在ChatGPT或者NLP領(lǐng)域,他們的重要之處在于找到了一種對(duì)NLP世界進(jìn)行本質(zhì)建模的方法。他們直接對(duì)NLP中的每個(gè)TOKEN、每個(gè)word的分布進(jìn)行建模,而不是通過預(yù)測(cè)下一個(gè)TOKEN來(lái)建模。對(duì)于視覺領(lǐng)域,我們以前在處理靜態(tài)圖像時(shí)往往放棄了物理世界的復(fù)雜性,只關(guān)注于靜態(tài)的像素分布。我們需要思考更本質(zhì)的方式,如何更有效地對(duì)圖像中的分布、表征和監(jiān)督進(jìn)行建模。盡管現(xiàn)有的圖像方法在某些方面有效,但并不足夠本質(zhì),因?yàn)楝F(xiàn)實(shí)世界不僅僅是圖像瞬間的表現(xiàn),還包含著時(shí)間的流逝、因果關(guān)系等。這些方面在圖像領(lǐng)域的Master運(yùn)行模型中并沒有得到本質(zhì)建模,因此我認(rèn)為在這個(gè)領(lǐng)域還有許多值得探索的問題。對(duì),這就是我的看法。
湯進(jìn)(安徽大學(xué))
我們還需要補(bǔ)充一點(diǎn),就是很多人在擔(dān)憂這個(gè)問題,特別是在網(wǎng)絡(luò)使用GPU的情況下。我想通過一個(gè)例子來(lái)說(shuō)明,就像航空學(xué)院是否還自己制造飛機(jī)一樣。航空學(xué)院專注于培養(yǎng)學(xué)生,而不是自己制造飛機(jī)。同樣,我們?cè)谶^去的科學(xué)與技術(shù)領(lǐng)域,也存在著工程與系統(tǒng)之間的差距。因此,我們過去認(rèn)為應(yīng)該做任何事情,但當(dāng)事情發(fā)展到一定程度時(shí),當(dāng)它變成了確定性事件時(shí),只需要采取行動(dòng),就能實(shí)現(xiàn)目標(biāo)。我們可以考慮是否值得在工業(yè)界修復(fù)BUG,因?yàn)橛袝r(shí)候在辦事之前會(huì)遇到虧損的情況。所以,我建議大家仔細(xì)思考一下,我們今天所做的事情背后的動(dòng)機(jī)。此外,我們也需要考慮歷史的發(fā)展,以及未來(lái)可能出現(xiàn)的情況。就像海嘯或海浪過后,我們是否還會(huì)停留在原地不前進(jìn)?如果海平面上升,我們是否還能繼續(xù)從事當(dāng)前的工作?也許我們需要做出一些調(diào)整,適應(yīng)新的情況。
吳保元(香港中文大學(xué)(深圳))
我對(duì)這個(gè)問題有兩個(gè)角度的思考。第一個(gè)角度研究大模型的安全性問題,因?yàn)榇竽P偷陌踩珕栴}可能會(huì)造成更嚴(yán)重的安全后果。首先一個(gè)考慮是我們之前針對(duì)小模型的研究方法是否適用于大模型,目前已經(jīng)有一些這方面的探索,初步發(fā)現(xiàn)了一些新的挑戰(zhàn),比如效率問題。另一個(gè)考慮是大模型是否存在全新的安全隱患,比如數(shù)據(jù)記憶能力過強(qiáng)和幻想問題。另一個(gè)角度是將大模型視為一種工具來(lái)使用。例如,我們可以將其用作輔助工具,而不是全程自主完成任務(wù)。比如,當(dāng)我們想要完成一項(xiàng)特定的復(fù)雜任務(wù)時(shí),盡管大模型的通用能力可能不足以很好地解決該復(fù)雜問題,但可以將該問題分解成多個(gè)較為簡(jiǎn)單的子問題,然后利用大模型完成其中的一部分,以加速整個(gè)流程。在這方面我們已經(jīng)進(jìn)行了一些探索,初步驗(yàn)證了這種思路的可行性,其潛力值得進(jìn)一步挖掘。
聲明:部分內(nèi)容來(lái)源于網(wǎng)絡(luò),僅供讀者學(xué)習(xí)、交流之目的。文章版權(quán)歸原作者所有。如有不妥,請(qǐng)聯(lián)系刪除。