
你真的了解深度學(xué)習(xí)生成對抗網(wǎng)絡(luò)(GAN)嗎?
點擊上方“小白學(xué)視覺”,選擇加"星標"或“置頂”
重磅干貨,第一時間送達

生成對抗網(wǎng)絡(luò)(GANshttps://en.wikipedia.org/wiki/Generative_adversarial_network)是一類具有基于網(wǎng)絡(luò)本身即可以生成數(shù)據(jù)能力的神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)。由于GANs的強大能力,在深度學(xué)習(xí)領(lǐng)域里對它們的研究是一個非常熱門的話題。在過去很短的幾年里,它們已經(jīng)從產(chǎn)生模糊數(shù)字成長到創(chuàng)造如真實人像般逼真的圖像。
 ??
??
?
GANs屬于生成模型的一類(https://en.wikipedia.org/wiki/Generative_model)。這意味著它們能夠產(chǎn)生,或者說是生成完全新的“有效”數(shù)據(jù)。有效數(shù)據(jù)是指網(wǎng)絡(luò)的輸出結(jié)果應(yīng)該是我們認為可以接受的目標。
舉例說明,舉一個我們希望為訓(xùn)練一個圖像分類網(wǎng)絡(luò)生成一些新圖像的例子。當(dāng)然對于這樣的應(yīng)用來說,我們希望訓(xùn)練圖像越真實越好,可能在風(fēng)格上與其他圖像分類訓(xùn)練數(shù)據(jù)非常相似。
下面的圖片展示的例子是GANs已經(jīng)生成的一系列圖片。它們看起來非常真實!如果沒人告訴我們它們是計算機生成的,我們真可能認為它們是人工搜集的。

漸進式GAN生成的圖像示例(圖源:https://arxiv.org/pdf/1710.10196.pdf)
為了做到這些,GANs是以兩個獨立的對抗網(wǎng)絡(luò)組成:生成器和判別器。當(dāng)僅將嘈雜的圖像陣列作為輸入時,會對生成器進行訓(xùn)練以創(chuàng)建逼真的圖像。判別器經(jīng)過訓(xùn)練可以對圖像是否真實進行分類。
GANs真正的能力來源于它們遵循的對抗訓(xùn)練模式。生成器的權(quán)重是基于判別器的損失所學(xué)習(xí)到的。因此,生成器被它生成的圖像所推動著進行訓(xùn)練,很難知道生成的圖像是真的還是假的。同時,生成的圖像看起來越來越真實,判別器在分辨圖像真實與否的能力變得越來越強,無論圖像用肉眼看起來多么的相似。
從技術(shù)的角度來看,判別器的損失即是分類圖像是真是假的錯誤值;我們正在測量它區(qū)分真假圖像的能力。生成器的損失將取決于它在用假圖像“愚弄”判別器的能力,即判別器僅對假圖像的分類錯誤,因為生成器希望該值越高越好。
因此,GANs建立了一種反饋回路,其中生成器幫助訓(xùn)練判別器,而判別器又幫助訓(xùn)練生成器。它們同時變得更強。下面的圖表有助于說明這一點。?
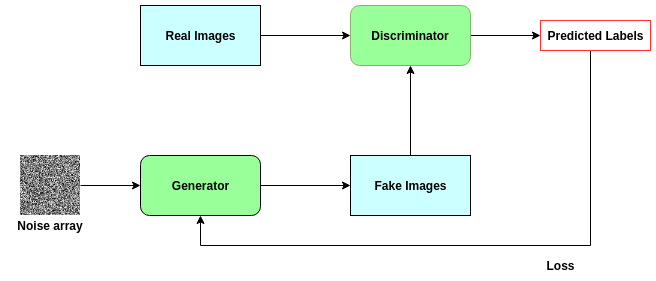
生成對抗網(wǎng)絡(luò)的結(jié)構(gòu)說明
?
現(xiàn)在我們將通過一個例子來展示如何使用PyTorch建立和訓(xùn)練我們自己的GAN!MNIST數(shù)據(jù)集包含60000個訓(xùn)練數(shù)據(jù),數(shù)據(jù)是像素尺寸28x28的1-9的黑白數(shù)字圖片。這個數(shù)據(jù)集非常適合我們的用例,同時也是非常普遍的用于機器學(xué)習(xí)的概念驗證以及一個非常完備的集合。

MNIST 數(shù)據(jù)部分集,圖源:https://www.researchgate.net/figure/A-subset-of-the-MNIST-database-of-handwritten-digits_fig4_232650721
我們將從?import?開始,所需的僅僅是PyTorch中的東西。
import torchfrom torch import nn, optimfrom torch.autograd.variable import Variableimport torchvisionimport torchvision.transforms as transforms
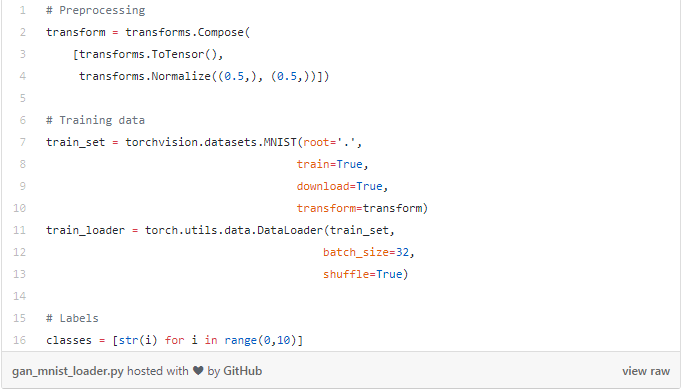
接下來,我們?yōu)橛?xùn)練數(shù)據(jù)準備DataLoader。請記住,我們想要的是為MNIST生成隨機數(shù)字,即從0到9。因此,我也將需要為這10個數(shù)字建立標簽。
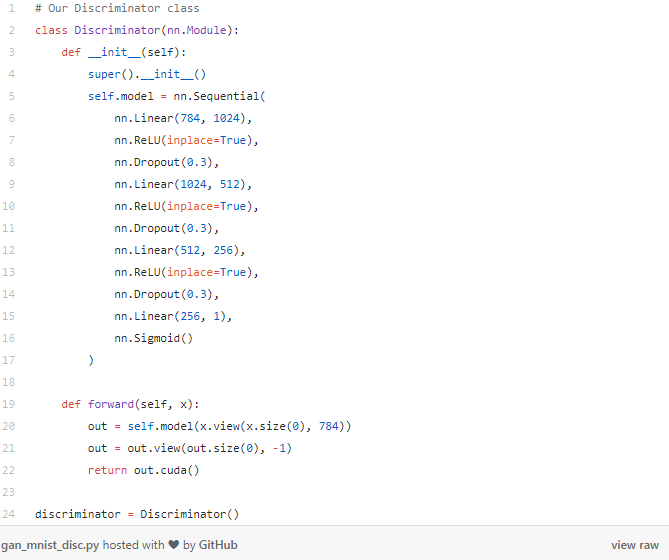
現(xiàn)在我們可以開始建立網(wǎng)絡(luò)了,從下面的Discriminator(判別器)網(wǎng)絡(luò)開始,回想一下,判別器網(wǎng)絡(luò)是對圖像真實與否進行分類——它是一個圖像分類網(wǎng)絡(luò)。因此,我們的輸入是符合標準MNIST大小的圖像:28x28像素。我們把這張圖像展平成一個長度為784的向量。輸出是一個單獨的值,表示圖像是否是實際的MNIST數(shù)字。
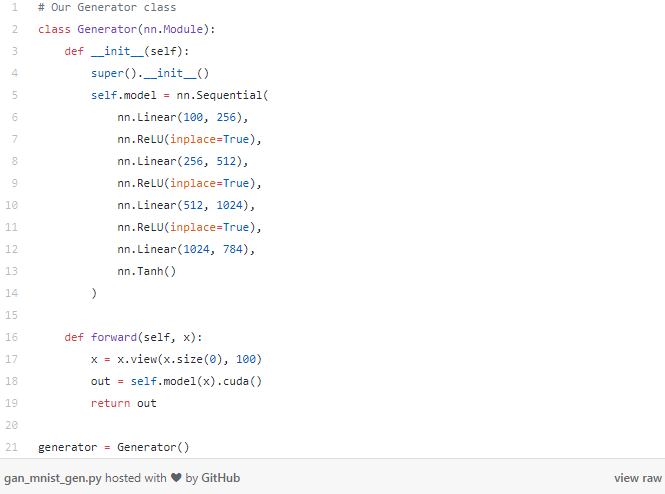
接下來到了生成器部分。生成器網(wǎng)絡(luò)負責(zé)創(chuàng)建實際的圖像——它可以從一個純噪聲的輸入做到這一點!在這個例子中,我們要讓生成器從一個長度為100的向量開始——注意:這只是純隨機噪聲。從這個向量,我們的生成器將輸出一個長度為784的向量,稍后我們可以將其重塑為標準MNIST的28x28像素。
1 . 損失函數(shù) 2 . 每個網(wǎng)絡(luò)的優(yōu)化器 3 . 訓(xùn)練次數(shù) 4 . batch數(shù)量
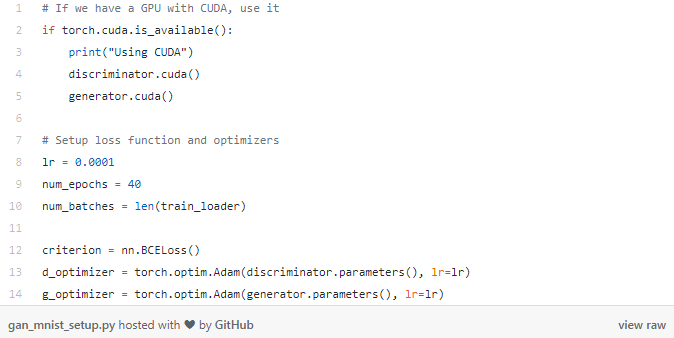
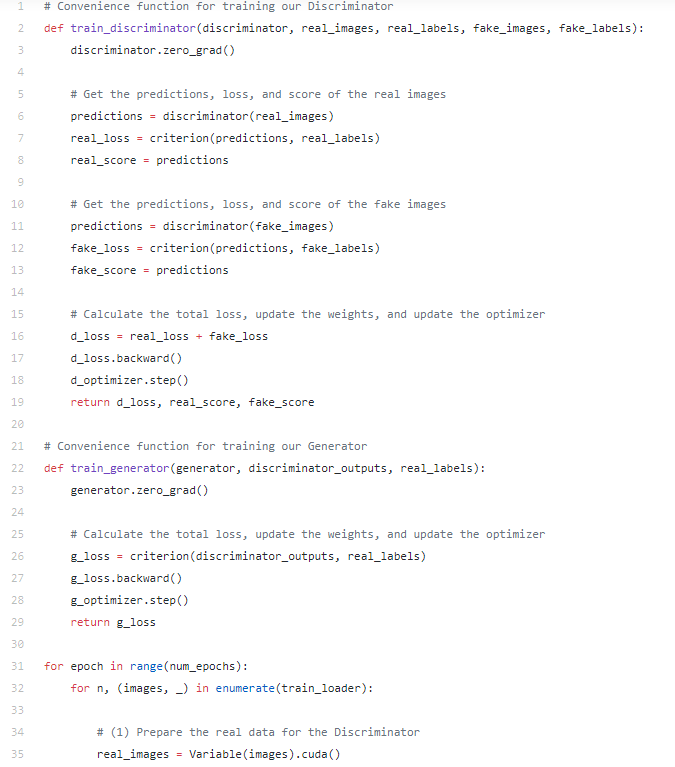

(2)接下來,我們將為生成器準備輸入向量以便生成假圖像。回想一下,我們的生成器網(wǎng)絡(luò)采用長度為100的輸入向量,這就是我們在這里所創(chuàng)建的向量。images.size(0)用于批處理大小。
(3)通過從步驟(2)中創(chuàng)建的隨機噪聲數(shù)據(jù)向量,我們可以繞過這個向量到生成器來生成假的圖像數(shù)據(jù)。這將結(jié)合我們從步驟1的實際數(shù)據(jù)來訓(xùn)練判別器。請注意,這次我們的標簽向量全為0,因為0代表假圖像的類標簽。
(4)通過假的和真的圖像以及它們的標簽,我們可以訓(xùn)練我們的判別器進行分類。總損失將是假圖像的損失+真圖像的損失。
(5)現(xiàn)在我們的判別器已經(jīng)更新,我們可以用它來進行預(yù)測。這些預(yù)測的損失將通過生成器反向傳播,這樣生成器的權(quán)重將根據(jù)它欺騙判別器的程度進行具體更新
(5a)生成一些假圖像進行預(yù)測
(5b)使用判別器對假圖像進行分批次預(yù)測并保存輸出。
(6)使用判別器的預(yù)測訓(xùn)練生成器。注意,我們使用全為1的 _real_labels_ 作為目標,因為我們的生成器的目標是創(chuàng)建看起來真實的圖像并且預(yù)測為1!因此,生成器的損失為0將意味著判別器預(yù)測全為1.
瞧,這就是我們訓(xùn)練GAN生成MNIST圖像的全部代碼!只需要安裝PyTorch即可運行。下面的gif就是經(jīng)過超過40個訓(xùn)練周期生成的圖像。


* via https://towardsdatascience.com/an-easy-introduction-to-generative-adversarial-networks-6f8498dc4bcd
下載1:OpenCV-Contrib擴展模塊中文版教程 在「小白學(xué)視覺」公眾號后臺回復(fù):擴展模塊中文教程,即可下載全網(wǎng)第一份OpenCV擴展模塊教程中文版,涵蓋擴展模塊安裝、SFM算法、立體視覺、目標跟蹤、生物視覺、超分辨率處理等二十多章內(nèi)容。 下載2:Python視覺實戰(zhàn)項目52講 在「小白學(xué)視覺」公眾號后臺回復(fù):Python視覺實戰(zhàn)項目,即可下載包括圖像分割、口罩檢測、車道線檢測、車輛計數(shù)、添加眼線、車牌識別、字符識別、情緒檢測、文本內(nèi)容提取、面部識別等31個視覺實戰(zhàn)項目,助力快速學(xué)校計算機視覺。 下載3:OpenCV實戰(zhàn)項目20講 在「小白學(xué)視覺」公眾號后臺回復(fù):OpenCV實戰(zhàn)項目20講,即可下載含有20個基于OpenCV實現(xiàn)20個實戰(zhàn)項目,實現(xiàn)OpenCV學(xué)習(xí)進階。 交流群
歡迎加入公眾號讀者群一起和同行交流,目前有SLAM、三維視覺、傳感器、自動駕駛、計算攝影、檢測、分割、識別、醫(yī)學(xué)影像、GAN、算法競賽等微信群(以后會逐漸細分),請掃描下面微信號加群,備注:”昵稱+學(xué)校/公司+研究方向“,例如:”張三?+?上海交大?+?視覺SLAM“。請按照格式備注,否則不予通過。添加成功后會根據(jù)研究方向邀請進入相關(guān)微信群。請勿在群內(nèi)發(fā)送廣告,否則會請出群,謝謝理解~