
詳解:生成對(duì)抗網(wǎng)絡(luò)GAN
點(diǎn)擊下方卡片,關(guān)注“新機(jī)器視覺(jué)”公眾號(hào)
重磅干貨,第一時(shí)間送達(dá)
解析一
GAN之所以是對(duì)抗的,是因?yàn)镚AN的內(nèi)部是競(jìng)爭(zhēng)關(guān)系,一方叫g(shù)enerator,它的主要工作是生成圖片,并且盡量使得其看上去是來(lái)自于訓(xùn)練樣本的。另一方是discriminator,其目標(biāo)是判斷輸入圖片是否屬于真實(shí)訓(xùn)練樣本。
生成對(duì)抗網(wǎng)絡(luò)的一個(gè)簡(jiǎn)單解釋如下:假設(shè)有兩個(gè)模型,一個(gè)是生成模型(Generative Model,下文簡(jiǎn)寫為G),一個(gè)是判別模型(Discriminative Model,下文簡(jiǎn)寫為D),判別模型(D)的任務(wù)就是判斷一個(gè)實(shí)例是真實(shí)的還是由模型生成的,生成模型(G)的任務(wù)是生成一個(gè)實(shí)例來(lái)騙過(guò)判別模型(D) ,兩個(gè)模型互相對(duì)抗,發(fā)展下去就會(huì)達(dá)到一個(gè)平衡,生成模型生成的實(shí)例與真實(shí)的沒(méi)有區(qū)別,判別模型無(wú)法區(qū)分自然的還是模型生成的。
比如,將generator想象成假幣制造商,而discriminator是警察。generator目的是盡可能把假幣造的跟真的一樣,從而能夠騙過(guò)discriminator,即生成樣本并使它看上去好像來(lái)自于真實(shí)訓(xùn)練樣本一樣。
再比如,以贗品商人為例,贗品商人(生成模型)制作出假的畢加索畫作來(lái)欺騙行家(判別模型D),贗品商人一直提升他的高仿水平來(lái)區(qū)分行家,行家也一直學(xué)習(xí)真的假的畢加索畫作來(lái)提升自己的辨識(shí)能力,兩個(gè)人一直博弈,最后贗品商人高仿的畢加索畫作達(dá)到了以假亂真的水平,行家最后也很難區(qū)分正品和贗品了。
如下圖中的左右兩個(gè)場(chǎng)景:
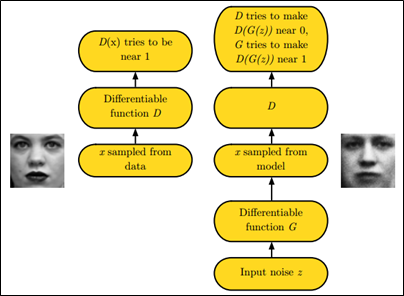
解析二
引言

自2014年Ian Goodfellow提出了GAN(Generative Adversarial Network)以來(lái),對(duì)GAN的研究可謂如火如荼。各種GAN的變體不斷涌現(xiàn),下圖是GAN相關(guān)論文的發(fā)表情況:

大牛Yann LeCun甚至評(píng)價(jià)GAN為 “adversarial training is the coolest thing since sliced bread”。那么到底什么是GAN呢?它又好在哪里?下面我們開(kāi)始進(jìn)行介紹。
1. GAN的基本思想
GAN全稱對(duì)抗生成網(wǎng)絡(luò),顧名思義是生成模型的一種,而他的訓(xùn)練則是處于一種對(duì)抗博弈狀態(tài)中的。下面舉例來(lái)解釋一下GAN的基本思想。
圖二 球員與教練員

假如你是一名籃球運(yùn)動(dòng)員,你想在下次比賽中得到上場(chǎng)機(jī)會(huì)。
于是在每一次訓(xùn)練賽之后你跟教練進(jìn)行溝通:
你:教練,我想打球
教練:(評(píng)估你的訓(xùn)練賽表現(xiàn)之后)... 算了吧
(你通過(guò)跟其他人比較,發(fā)現(xiàn)自己的運(yùn)球很差,于是你苦練了一段時(shí)間)
你:教練,我想打球
教練:... 嗯 還不行
(你發(fā)現(xiàn)大家投籃都很準(zhǔn),于是你苦練了一段時(shí)間的投籃)
你:教練,我想打球
教練:... 嗯 還有所欠缺
(你發(fā)現(xiàn)你的身體不夠壯,被人一碰就倒,于是你去泡健身房)
......
通過(guò)這樣不斷的努力和被拒絕,你最終在某一次訓(xùn)練賽之后得到教練的贊賞,獲得了上場(chǎng)的機(jī)會(huì)。
值得一提的是在這個(gè)過(guò)程中,所有的候選球員都在不斷地進(jìn)步和提升。因而教練也要不斷地通過(guò)對(duì)比場(chǎng)上球員和候補(bǔ)球員來(lái)學(xué)習(xí)分辨哪些球員是真正可以上場(chǎng)的,并且要“觀察”得比球員更頻繁。隨著大家的成長(zhǎng)教練也會(huì)變得越來(lái)越嚴(yán)格。
現(xiàn)在大家對(duì)于GAN的思想應(yīng)該有了感性的認(rèn)識(shí)了,下面開(kāi)始進(jìn)一步窺探GAN的結(jié)構(gòu)和思想。
2. GAN淺析
2.1 GAN的基本結(jié)構(gòu)
GAN的主要結(jié)構(gòu)包括一個(gè)生成器G(Generator)和一個(gè)判別器D(Discriminator)。在上面的例子中的球員就相當(dāng)于生成器,我們需要他在球場(chǎng)上能有好的表現(xiàn)。而球員一開(kāi)始都是初學(xué)者,這個(gè)時(shí)候就需要一個(gè)教練員來(lái)指導(dǎo)他們訓(xùn)練,告訴他們訓(xùn)練得怎么樣,直到真的能夠達(dá)到上場(chǎng)的標(biāo)準(zhǔn)。而這個(gè)教練就相當(dāng)于判別器。
下面我們舉另外一個(gè)手寫字的例子來(lái)進(jìn)行進(jìn)一步窺探GAN的結(jié)構(gòu)。
圖三 GAN基本結(jié)構(gòu)
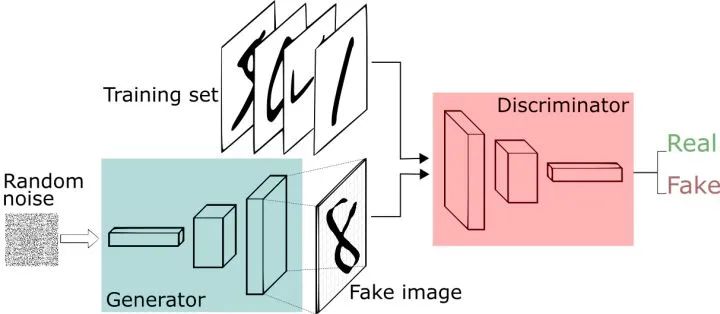
我們現(xiàn)在擁有大量的手寫數(shù)字的數(shù)據(jù)集,我們希望通過(guò)GAN生成一些能夠以假亂真的手寫字圖片。主要由如下兩個(gè)部分組成:定義一個(gè)模型來(lái)作為生成器(圖三中藍(lán)色部分Generator),能夠輸入一個(gè)向量,輸出手寫數(shù)字大小的像素圖像。
定義一個(gè)分類器來(lái)作為判別器(圖三中紅色部分Discriminator)用來(lái)判別圖片是真的還是假的(或者說(shuō)是來(lái)自數(shù)據(jù)集中的還是生成器中生成的),輸入為手寫圖片,輸出為判別圖片的標(biāo)簽。
2.2 GAN的訓(xùn)練方式
前面已經(jīng)定義了一個(gè)生成器(Generator)來(lái)生成手寫數(shù)字,一個(gè)判別器(Discrimnator)來(lái)判別手寫數(shù)字是否是真實(shí)的,和一些真實(shí)的手寫數(shù)字?jǐn)?shù)據(jù)集。那么我們?cè)鯓觼?lái)進(jìn)行訓(xùn)練呢?
2.2.1 關(guān)于生成器
對(duì)于生成器,輸入需要一個(gè)n維度向量,輸出為圖片像素大小的圖片。因而首先我們需要得到輸入的向量。
Tips: 這里的生成器可以是任意可以輸出圖片的模型,比如最簡(jiǎn)單的全連接神經(jīng)網(wǎng)絡(luò),又或者是反卷積網(wǎng)絡(luò)等。這里大家明白就好。這里輸入的向量我們將其視為攜帶輸出的某些信息,比如說(shuō)手寫數(shù)字為數(shù)字幾,手寫的潦草程度等等。
由于這里我們對(duì)于輸出數(shù)字的具體信息不做要求,只要求其能夠最大程度與真實(shí)手寫數(shù)字相似(能騙過(guò)判別器)即可。所以我們使用隨機(jī)生成的向量來(lái)作為輸入即可,這里面的隨機(jī)輸入最好是滿足常見(jiàn)分布比如均值分布,高斯分布等。
Tips: 假如我們后面需要獲得具體的輸出數(shù)字等信息的時(shí)候,我們可以對(duì)輸入向量產(chǎn)生的輸出進(jìn)行分析,獲取到哪些維度是用于控制數(shù)字編號(hào)等信息的即可以得到具體的輸出。而在訓(xùn)練之前往往不會(huì)去規(guī)定它。
2.2.2 關(guān)于判別器
對(duì)于判別器不用多說(shuō),往往是常見(jiàn)的判別器,輸入為圖片,輸出為圖片的真?zhèn)螛?biāo)簽。
Tips: 同理,判別器與生成器一樣,可以是任意的判別器模型,比如全連接網(wǎng)絡(luò),或者是包含卷積的網(wǎng)絡(luò)等等。
2.2.3 如何訓(xùn)練
上面進(jìn)一步說(shuō)明了生成器和判別器,接下來(lái)說(shuō)明如何進(jìn)行訓(xùn)練。
基本流程如下:
1) 初始化判別器D的參數(shù)和生成器G的參數(shù)
;
2) 從真實(shí)樣本中采樣個(gè)樣本
} ,從先驗(yàn)分布噪聲中采樣
} 并通過(guò)生成器獲取
} 。固定生成器G,訓(xùn)練判別器D盡可能好地準(zhǔn)確判別真實(shí)樣本和生成樣本,盡可能大地區(qū)分正確樣本和生成的樣本;
3) 循環(huán)k次更新判別器之后,使用較小的學(xué)習(xí)率來(lái)更新一次生成器的參數(shù),訓(xùn)練生成器使其盡可能能夠減小生成樣本與真實(shí)樣本之間的差距,也相當(dāng)于盡量使得判別器判別錯(cuò)誤;
4) 多次更新迭代之后,最終理想情況是使得判別器判別不出樣本來(lái)自于生成器的輸出還是真實(shí)的輸出。亦即最終樣本判別概率均為0.5。
Tips: 之所以要訓(xùn)練k次判別器,再訓(xùn)練生成器,是因?yàn)橐葥碛幸粋€(gè)好的判別器,使得能夠教好地區(qū)分出真實(shí)樣本和生成樣本之后,才好更為準(zhǔn)確地對(duì)生成器進(jìn)行更新。更直觀的理解可以參考下圖:
圖四 生成器判別器與樣本示意
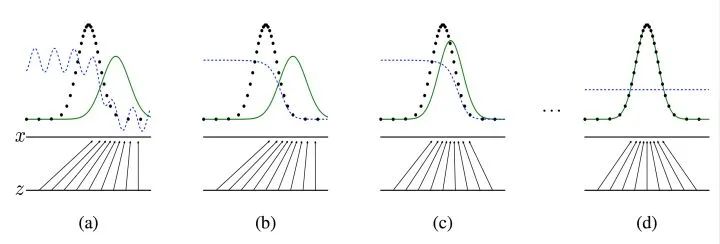
圖注:圖中的黑色虛線表示真實(shí)的樣本的分布情況,藍(lán)色虛線表示判別器判別概率的分布情況,綠色實(shí)線表示生成樣本的分布。表示噪聲,
表示通過(guò)生成器之后的分布的映射情況。
我們的目標(biāo)是使用生成樣本分布(綠色實(shí)線)去擬合真實(shí)的樣本分布(黑色虛線),來(lái)達(dá)到生成以假亂真樣本的目的。
第①步:可以看到在(a)狀態(tài)處于最初始的狀態(tài)的時(shí)候,生成器生成的分布和真實(shí)分布區(qū)別較大,并且判別器判別出樣本的概率不是很穩(wěn)定,因此會(huì)先訓(xùn)練判別器來(lái)更好地分辨樣本。
第②步:通過(guò)多次訓(xùn)練判別器來(lái)達(dá)到(b)樣本狀態(tài),此時(shí)判別樣本區(qū)分得非常顯著和良好。然后再對(duì)生成器進(jìn)行訓(xùn)練。
第③步:訓(xùn)練生成器之后達(dá)到(c)樣本狀態(tài),此時(shí)生成器分布相比之前,逼近了真實(shí)樣本分布。
第④步:經(jīng)過(guò)多次反復(fù)訓(xùn)練迭代之后,最終希望能夠達(dá)到(d)狀態(tài),生成樣本分布擬合于真實(shí)樣本分布,并且判別器分辨不出樣本是生成的還是真實(shí)的(判別概率均為0.5)。也就是說(shuō)我們這個(gè)時(shí)候就可以生成出非常真實(shí)的樣本啦,目的達(dá)到。
3. 訓(xùn)練相關(guān)理論基礎(chǔ)
前面用了大白話來(lái)說(shuō)明了訓(xùn)練的大致流程,下面會(huì)從交叉熵開(kāi)始說(shuō)起,一步步說(shuō)明損失函數(shù)的相關(guān)理論,尤其是論文中包含min,max的公式如下圖5形式:
圖5 minmax公式
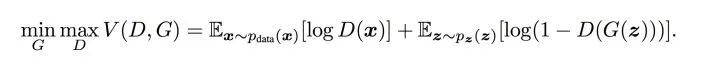
判別器在這里是一種分類器,用于區(qū)分樣本的真?zhèn)危虼宋覀兂3J褂媒徊骒兀╟ross entropy)來(lái)進(jìn)行判別分布的相似性,交叉熵公式如下圖6所示:
圖6 交叉熵公式

Tips: 公式中和
為真實(shí)的樣本分布和生成器的生成分布。由于交叉熵是非常常見(jiàn)的損失函數(shù),這里默認(rèn)大家都較為熟悉,就不進(jìn)行贅述了。在當(dāng)前模型的情況下,判別器為一個(gè)二分類問(wèn)題,因此可以對(duì)基本交叉熵進(jìn)行更具體地展開(kāi)如下圖7所示:
圖7 二分類交叉熵
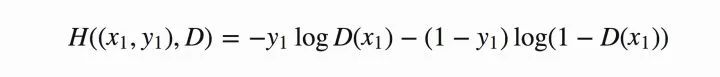
Tips: 其中,假定為正確樣本分布,那么對(duì)應(yīng)的(
)就是生成樣本的分布。
表示判別器,則
表示判別樣本為正確的概率,
則對(duì)應(yīng)著判別為錯(cuò)誤樣本的概率。這里僅僅是對(duì)當(dāng)前情況下的交叉熵?fù)p失的具體化。相信大家也還是比較熟悉。
將上式推廣到N個(gè)樣本后,將N個(gè)樣本相加得到對(duì)應(yīng)的公式如下:
圖8 N個(gè)樣本的情況
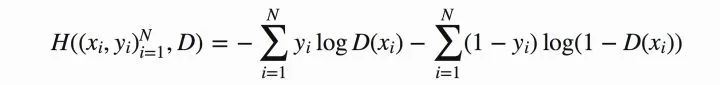
OK,到目前為止還是基本的二分類,下面加入GAN中特殊的地方。對(duì)于GAN中的樣本點(diǎn),對(duì)應(yīng)于兩個(gè)出處,要么來(lái)自于真實(shí)樣本,要么來(lái)自于生成器生成的樣本
~
( 這里的
是服從于投到生成器中噪聲的分布)。
其中,對(duì)于來(lái)自于真實(shí)的樣本,我們要判別為正確的分布。來(lái)自于生成的樣本我們要判別其為錯(cuò)誤分布(
)。將上面式子進(jìn)一步使用概率分布的期望形式寫出(為了表達(dá)無(wú)限的樣本情況,相當(dāng)于無(wú)限樣本求和情況),并且讓
圖8 GAN損失函數(shù)期望形式表達(dá)
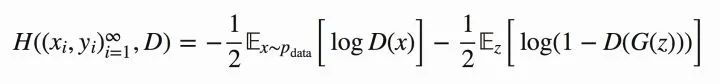
OK,現(xiàn)在我們?cè)倩剡^(guò)頭來(lái)對(duì)比原本的的公式,發(fā)現(xiàn)他們是不是其實(shí)就是同一個(gè)東西呢!:-D
圖9 損失函數(shù)的min max表

我們回憶一下上面2.2.3中介紹的流程理解一下這里的
i) 這里的相當(dāng)于表示真實(shí)樣本和生成樣本的差異程度。
ii) 先看。這里的意思是固定生成器G,盡可能地讓判別器能夠最大化地判別出樣本來(lái)自于真實(shí)數(shù)據(jù)還是生成的數(shù)據(jù)。
iii) 再將后面部分看成一個(gè)整體令=
,這里是在固定判別器D的條件下得到生成器G,這個(gè)G要求能夠最小化真實(shí)樣本與生成樣本的差異。
iv) 通過(guò)上述min max的博弈過(guò)程,理想情況下會(huì)收斂于生成分布擬合于真實(shí)分布。
4. 總結(jié)
本文大致介紹了GAN的整體情況。但是對(duì)于GAN實(shí)際上還有更多更完善的理論相關(guān)描述,進(jìn)一步了解可以看相關(guān)的論文。并且在GAN一開(kāi)始提出來(lái)的時(shí)候,實(shí)際上針對(duì)于不同的情況也有存在著一些不足,后面也陸續(xù)提出了不同的GAN的變體來(lái)完善GAN。通過(guò)一個(gè)判別器而不是直接使用損失函數(shù)來(lái)進(jìn)行逼近,更能夠自頂向下地把握全局的信息。
比如在圖片中,雖然都是相差幾像素點(diǎn),但是這個(gè)像素點(diǎn)的位置如果在不同地方,那么他們之間的差別可能就非常之大。
圖10 不同像素位置的差別

比如上圖10中的兩組生成樣本,對(duì)應(yīng)的目標(biāo)為字體2,但是圖中上面的兩個(gè)樣本雖然只相差一個(gè)像素點(diǎn),但是這個(gè)像素點(diǎn)對(duì)于全局的影響是比較大的,但是單純地去使用使用損失函數(shù)來(lái)判斷,那么他們的誤差都是相差一個(gè)像素點(diǎn),而下面的兩個(gè)雖然相差了六個(gè)像素點(diǎn)的差距(粉色部分的像素點(diǎn)為誤差),但是實(shí)際上對(duì)于整體的判斷來(lái)說(shuō),是沒(méi)有太大影響的。但是直接使用損失函數(shù)的話,卻會(huì)得到6個(gè)像素點(diǎn)的差距,比上面的兩幅圖差別更大。而如果使用判別器,則可以更好地判別出這種情況(不會(huì)拘束于具體像素的差距)。
總之GAN是一個(gè)非常有意思的東西,現(xiàn)在也有很多相關(guān)的利用GAN的應(yīng)用,比如利用GAN來(lái)生成人物頭像,用GAN來(lái)進(jìn)行文字的圖片說(shuō)明等等。后面我也會(huì)使用GAN來(lái)做一些簡(jiǎn)單的實(shí)驗(yàn)來(lái)幫助進(jìn)一步理解GAN。
最后附上論文中的GAN算法流程,通過(guò)上面的介紹,這里應(yīng)該非常好理解了。
圖11 論文中的GAN算法流程

本文僅做學(xué)術(shù)分享,如有侵權(quán),請(qǐng)聯(lián)系刪文。
評(píng)論
圖片
表情