
『每周譯Go』Go性能工具小抄
原文地址:https://steveazz.xyz/blog/go-performance-tools-cheat-sheet
原文作者:
Steve Azzopardi本文永久鏈接:https://github.com/gocn/translator/blob/master/2021/w23_go_performance_tools_cheat_sheet.md
譯者:Cluas
校對:Martinho0330
Go有很多工具可以讓你了解你的應(yīng)用程序可能在哪里花費CPU時間或分配內(nèi)存。我不是每天都使用這些工具,所以我每次都是在尋找同樣的東西。這篇文章的目的是為這些Go所提供的工具提供一個參考文獻。
我們將使用 https://gitlab.com/steveazz-blog/go-performance-tools-cheat-sheet 作為一個演示項目,同樣的事情有3種實現(xiàn)方式,每一種都比前一種性能更好。
默認實現(xiàn) 性能更好的實現(xiàn) 性能最好的實現(xiàn)
基準測試(Benchmarks)
最流行的方法之一是使用Go中內(nèi)置的 基準測試 來看看你是否改進了什么。
在我們的演示項目中,已經(jīng)有了 可用的基準測試 我們可以用一個命令運行它們。
go test -bench=. -test.benchmem ./rand/
goos: darwin
goarch: amd64
pkg: gitlab.com/steveazz/blog/go-performance-tools-cheat-sheet/rand
cpu: Intel(R) Core(TM) i7-6820HQ CPU @ 2.70GHz
BenchmarkHitCount100-8 3020 367016 ns/op 269861 B/op 3600 allocs/op
BenchmarkHitCount1000-8 326 3737517 ns/op 2696308 B/op 36005 allocs/op
BenchmarkHitCount100000-8 3 370797178 ns/op 269406189 B/op 3600563 allocs/op
BenchmarkHitCount1000000-8 1 3857843580 ns/op 2697160640 B/op 36006111 allocs/op
PASS
ok gitlab.com/steveazz/blog/go-performance-tools-cheat-sheet/rand 8.828s
注意: -test.benchmem 是一個可選的標志,用于顯示內(nèi)存分配。
仔細看一下每一欄的含義:
BenchmarkHitCount100-8 3020 367016 ns/op 269861 B/op 3600 allocs/op
^------------------^ ^ ^ ^ ^ ^
| | | | | |
名稱 CPU數(shù)量 總運行次數(shù) 每次操作的納秒數(shù) 每次操作的字節(jié)數(shù) 每次操作的內(nèi)存分配數(shù)
比較基準測試(Benchmarks)
Go 創(chuàng)建了 perf 它提供了 benchstat 這樣你就可以一起比較benchmark輸出,它將給你展示出它們之間的差異。
例如,讓我們比較一下 main 和 best 分支.
# 運行 `main` 分支的基準測試
git checkout main
go test -bench=. -test.benchmem -count=5 ./rand/ > old.txt
# 運行 `best` 分支的基準測試
git checkout best
go test -bench=. -test.benchmem -count=5 ./rand/ > new.txt
# 比較兩個基準測試結(jié)果
benchstat old.txt new.txt
name old time/op new time/op delta
HitCount100-8 366μs ± 0% 103μs ± 0% -71.89% (p=0.008 n=5+5)
HitCount1000-8 3.66ms ± 0% 1.06ms ± 5% -71.13% (p=0.008 n=5+5)
HitCount100000-8 367ms ± 0% 104ms ± 1% -71.70% (p=0.008 n=5+5)
HitCount1000000-8 3.66s ± 0% 1.03s ± 1% -71.84% (p=0.016 n=4+5)
name old alloc/op new alloc/op delta
HitCount100-8 270kB ± 0% 53kB ± 0% -80.36% (p=0.008 n=5+5)
HitCount1000-8 2.70MB ± 0% 0.53MB ± 0% -80.39% (p=0.008 n=5+5)
HitCount100000-8 270MB ± 0% 53MB ± 0% -80.38% (p=0.008 n=5+5)
HitCount1000000-8 2.70GB ± 0% 0.53GB ± 0% -80.39% (p=0.016 n=4+5)
name old allocs/op new allocs/op delta
HitCount100-8 3.60k ± 0% 1.50k ± 0% -58.33% (p=0.008 n=5+5)
HitCount1000-8 36.0k ± 0% 15.0k ± 0% -58.34% (p=0.008 n=5+5)
HitCount100000-8 3.60M ± 0% 1.50M ± 0% -58.34% (p=0.008 n=5+5)
HitCount1000000-8 36.0M ± 0% 15.0M ± 0% -58.34% (p=0.008 n=5+5)
注意,我們傳遞了 -count 標志來多次運行基準測試,這樣它就可以得到運行的平均值。
pprof
Go有自己的剖析器,它可以讓你更好地了解CPU時間花在哪里,或者應(yīng)用程序在哪里分配內(nèi)存。Go在一段時間內(nèi)對這些進行采樣,例如,它將在X秒內(nèi)每隔X納秒查看CPU/內(nèi)存的使用情況。
生成剖析文件(Profiles)
Benchmarks
你可以使用我們在演示項目中的基準來生成剖析文件。
CPU:
go test -bench=. -cpuprofile cpu.prof ./rand/
Memory:
go test -bench=. -memprofile mem.prof ./rand/
net/http/pprof package
如果你正在編寫一個webserver,你可以導入 net/http/pprof 它將在DefaultServeMux上暴露/debug/pprof HTTP端點,就像我們在 示例應(yīng)用 中做的那樣。
確保你的應(yīng)用程序不是空閑著它需要正在運行或接收請求,以便剖析器能夠?qū)φ{(diào)用進行采樣,否則你可能會因為應(yīng)用程序是空閑的而最終得到一個空的剖析文件。
# CPU剖析文件
curl http://127.0.0.1:8080/debug/pprof/profile > /tmp/cpu.prof
# 堆剖析文件
curl http://127.0.0.1:8080/debug/pprof/heap > /tmp/heap.prof
# 內(nèi)存分配剖析文件
curl http://127.0.0.1:8080/debug/pprof/allocs > /tmp/allocs.prof
如果你訪問/debug/pprof,它將給出所有可用的端點的列表和它們的含義。
runtime/pprof 包
這與 net/http/pprof 類似,將它添加到你的應(yīng)用程序中,但不是為所有的項目添加,你可以指定一個特定的代碼路徑,在那個路徑生成剖析文件。當你只對你的應(yīng)用程序的某一部分感興趣,并且你只想對應(yīng)用程序的那一部分進行采樣時,這就很有用。要閱讀如何使用它,請查看 go的參考文檔 。
你也可以用這個來 給應(yīng)用加上標簽 這可以幫助你更好地了解概況。
閱讀剖析文件(Profiles)
現(xiàn)在我們知道了如何生成剖析文件,讓我們看看如何讀取它們以了解我們的應(yīng)用程序正在做什么。
我們將使用的命令是 go tool pprof。
調(diào)用圖
例如,為了使用我們在演示程序中 registered 的/debug/pprof端點,我們可以直接傳入HTTP端點。
# 打開新的瀏覽器窗口,查看30秒后的調(diào)用圖。
go tool pprof -http :9402 http://127.0.0.1:8080/debug/pprof/profile
另一個選擇是使用 curl 下載剖析文件,然后使用 go tool命令,這對于從沒有暴露在公共互聯(lián)網(wǎng)上的生產(chǎn)端點獲取剖析文件可能很有用。
# 在服務(wù)器上查看。
curl http://127.0.0.1:8080/debug/pprof/profile > /tmp/cpu.prof
# 在你從服務(wù)器上得到它之后,在本地查看。
go tool pprof -http :9402 /tmp/cpu.prof
注意,在所有的命令中,我們都傳遞了-http標志,這是可選的,因為在默認情況下,這將打開CLI界面。
下面你可以看到我們的演示應(yīng)用程序調(diào)用圖。為了更好地理解它的含義,你應(yīng)該閱讀 解釋調(diào)用圖 。
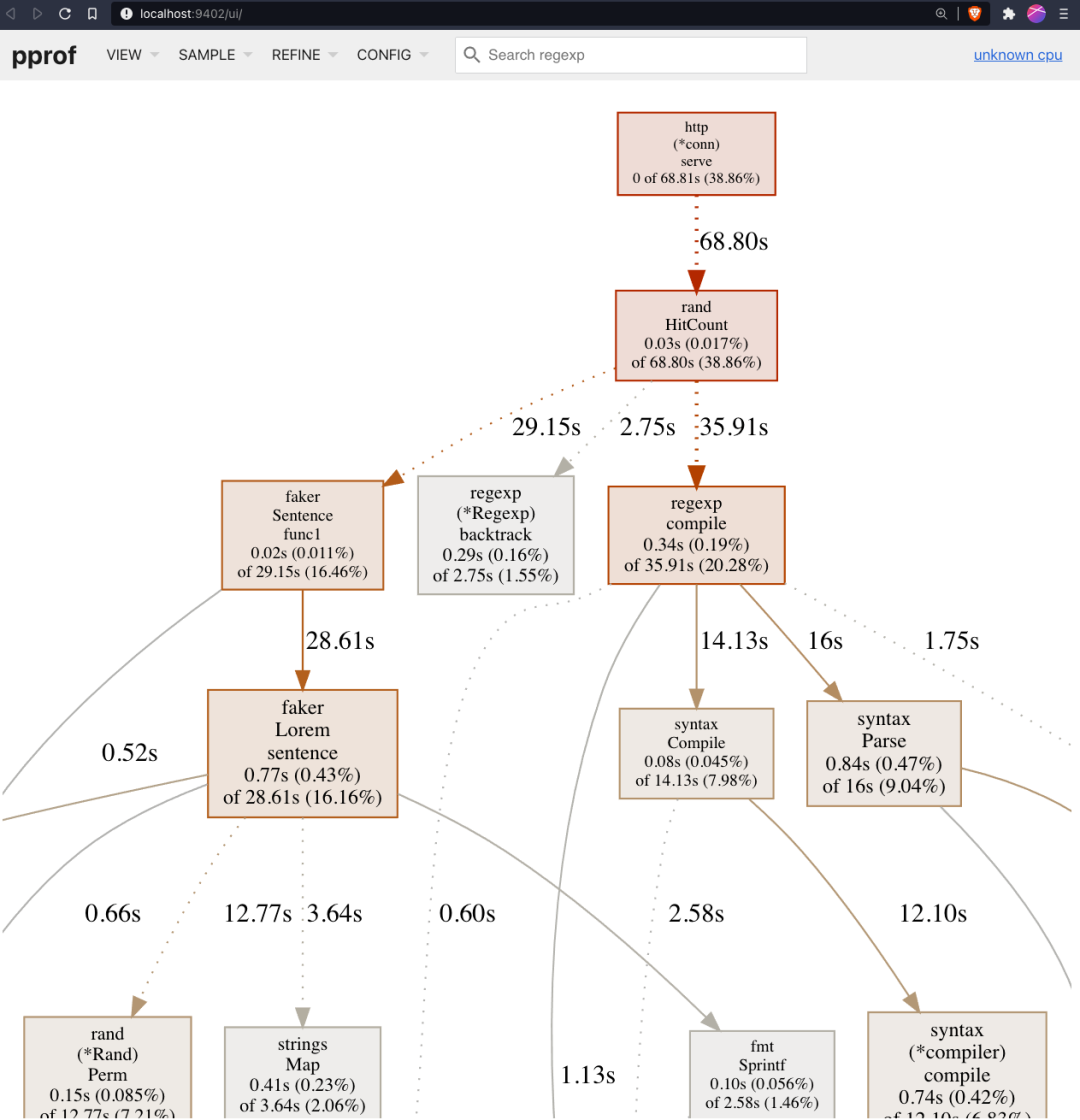
我們的演示應(yīng)用程序的調(diào)用圖的示例
火焰圖
調(diào)用圖對于查看程序正在調(diào)用的內(nèi)容很有用,也可以幫助你了解應(yīng)用程序正在花費的時間。了解CPU時間或內(nèi)存分配去向的另一種方法是使用火焰圖。
使用同一個演示程序,讓我們再次運行 go tool pprof:
# 來自HTTP端點
go tool pprof -http :9402 http://127.0.0.1:8080/debug/pprof/profile
# 來自本地的剖析文件
go tool pprof -http :9402 /tmp/cpu.prof
然而,這一次我們將使用頂部導航欄,前往 View> Flame Graph
然后你應(yīng)該看到類似下面的東西:
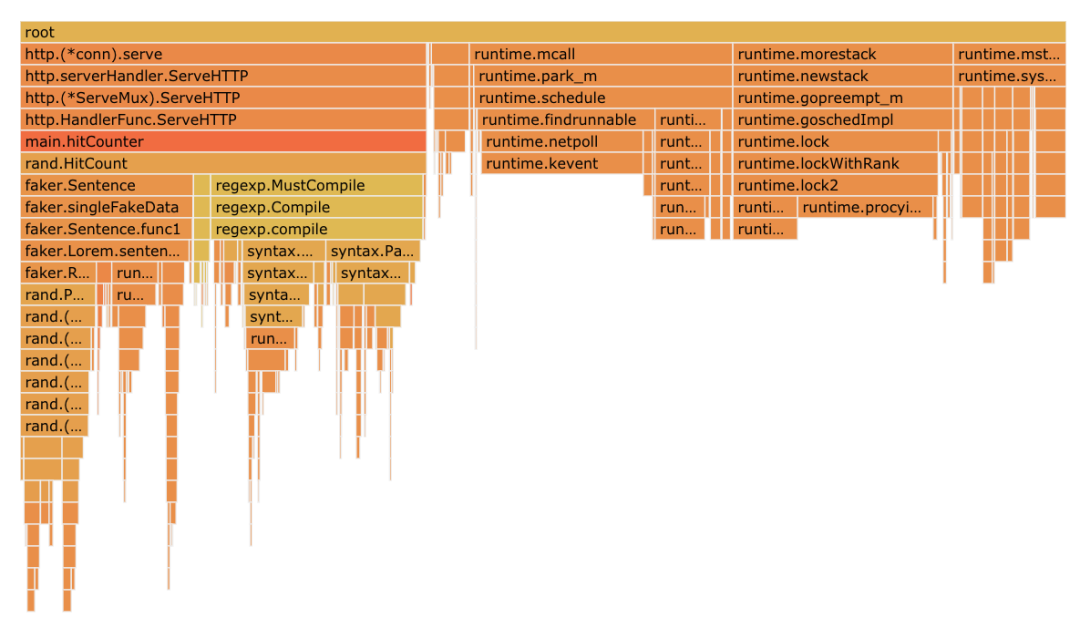
為了讓你更好地了解如何閱讀火焰圖,你可以查看一下 什么是火焰圖,怎么去讀火焰圖(RubyConf2017上的議題)
你也可以使用 speedscope 這是一個與語言無關(guān)的應(yīng)用程序,可以從剖析文件中生成火焰圖,它比Go提供的互動性更強一些。
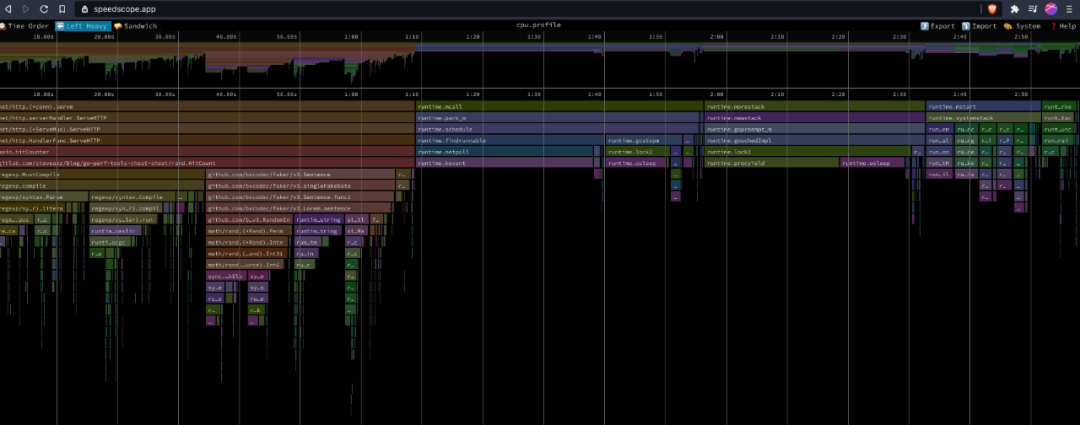
比較剖析文件(Profiles)
go tool pprof 也允許你使用 比較剖析文件 來顯示1個剖析文件和另一個剖析文件之間的差異。
再次使用我們的演示項目,我們可以為 "main" 和 "best" 分支生成剖析文件。
# 運行 `main` 分支,生成剖析文件。
curl http://127.0.0.1:8080/debug/pprof/profile > /tmp/main.prof
# 運行 `best` 分支,生成剖析文件。
curl http://127.0.0.1:8080/debug/pprof/profile > /tmp/best.prof
# 比較剖析文件。
go tool pprof -http :9402 --diff_base=/tmp/main.prof /tmp/best.prof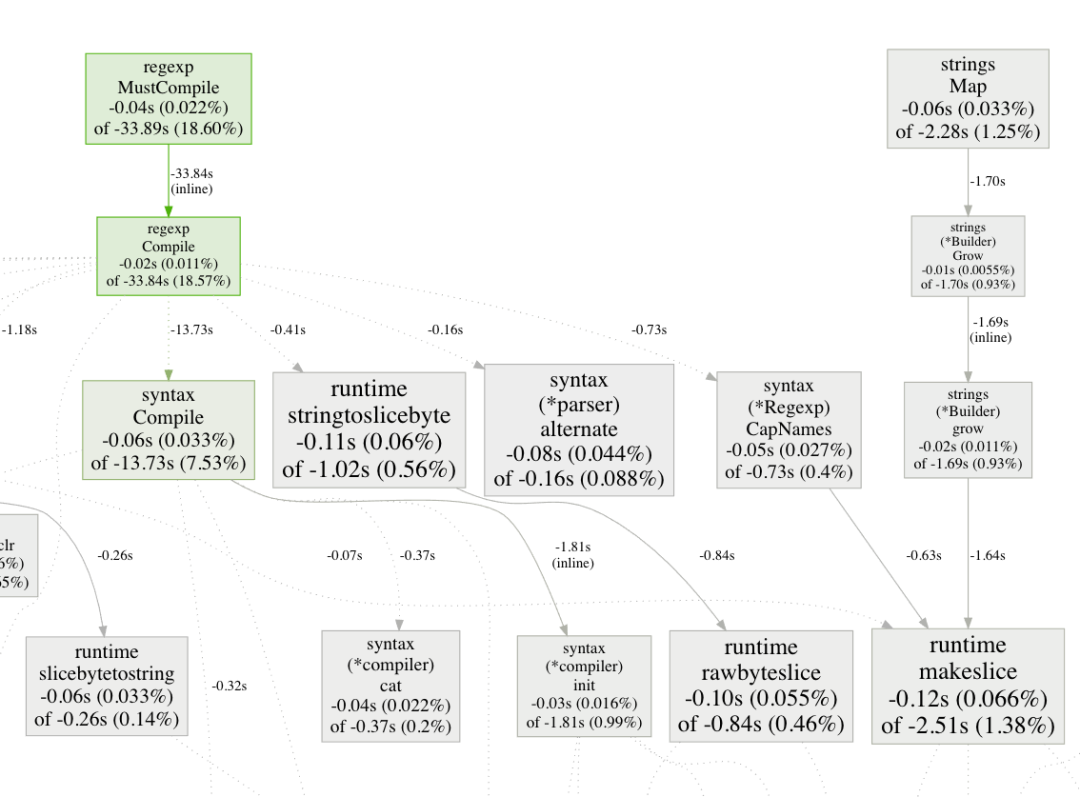
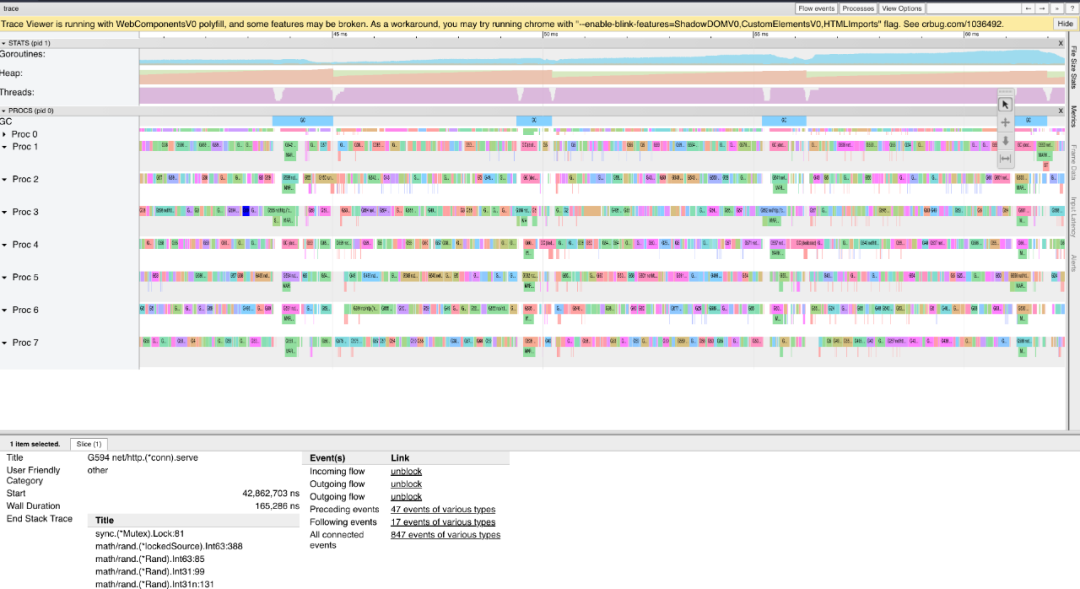
追蹤(Traces)
我們需要經(jīng)歷的最后一個工具是CPU追蹤器。這可以讓你準確地了解在程序執(zhí)行過程中發(fā)生了什么。它可以告訴你哪些核心是閑置的,哪些核心是忙碌的。如果你正在調(diào)試一些沒有達到預期性能的并發(fā)代碼,這就非常好用。
再次使用我們的演示程序,讓我們使用net/http/pprof添加的debug/pprof/trace端點來獲得CPU跟蹤。
curl http://127.0.0.1:8080/debug/pprof/trace > /tmp/best.trace
go tool trace /tmp/best.trace
關(guān)于追蹤器的更詳細的解釋可以在 go程序員學院博客 上找到。
資源
Go高性能研究 go-perf百科 Go工具實戰(zhàn) pprof++ 追蹤(trace)設(shè)計文檔 如何用Go編寫基準測試
別忘了還有 Gopher China 2021 大會在文末等著你哦~
想和各位技術(shù)大佬們同臺見面嘛?
那就趕快點擊下方「閱讀原文」報名參加呀!