
Pandarallel 一個(gè)能讓你的Pandas計(jì)算火力拉滿的工具
沒有使用 |
|
使用了 |
|

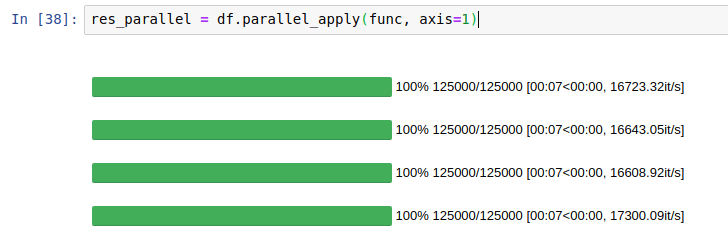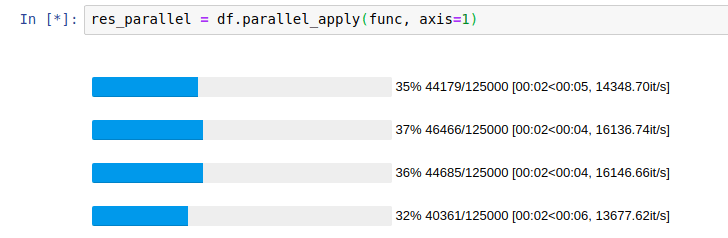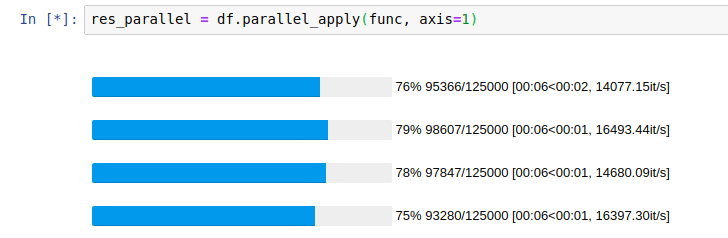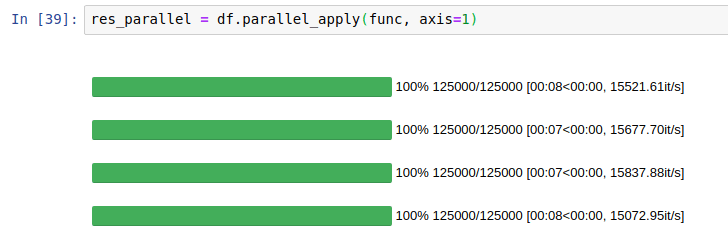
眾所周知,由于GIL的存在,Python單進(jìn)程中的所有操作都是在一個(gè)CPU核上進(jìn)行的,所以為了提高運(yùn)行速度,我們一般會(huì)采用多進(jìn)程的方式。而多進(jìn)程無非就是以下幾種方案:
multiprocessing
concurrent.futures.ProcessPoolExecutor()
joblib
ppserver
celery
這些方案對(duì)于普通Pandas玩家來說都不是特別友好,怎樣才能算作一個(gè)友好的并行處理方案?
那就是原來的邏輯我基本不用變,僅修改需要計(jì)算的那行就能完成我們目標(biāo)的方案,而 pandarallel 就是一個(gè)這樣友好的工具。
沒有并行計(jì)算(原始pandas)
pandarallel
df.apply(func)
df.parallel_apply(func)
df.applymap(func)
df.parallel_applymap(func)
df.groupby(args).apply(func)
df.groupby(args).parallel_apply(func)
df.groupby(args1).col_name.rolling(args2).apply(func)
df.groupby(args1).col_name.rolling(args2).parallel_apply(func)
df.groupby(args1).col_name.expanding(args2).apply(func)
df.groupby(args1).col_name.expanding(args2).parallel_apply(func)
series.map(func)
series.parallel_map(func)
series.apply(func)
series.parallel_apply(func)
series.rolling(args).apply(func)
series.rolling(args).parallel_apply(func)
可以看到,在 pandarallel 的世界里,你只需要替換原有的 pandas 處理語句就能實(shí)現(xiàn)多CPU并行計(jì)算。非常方便、非常nice.
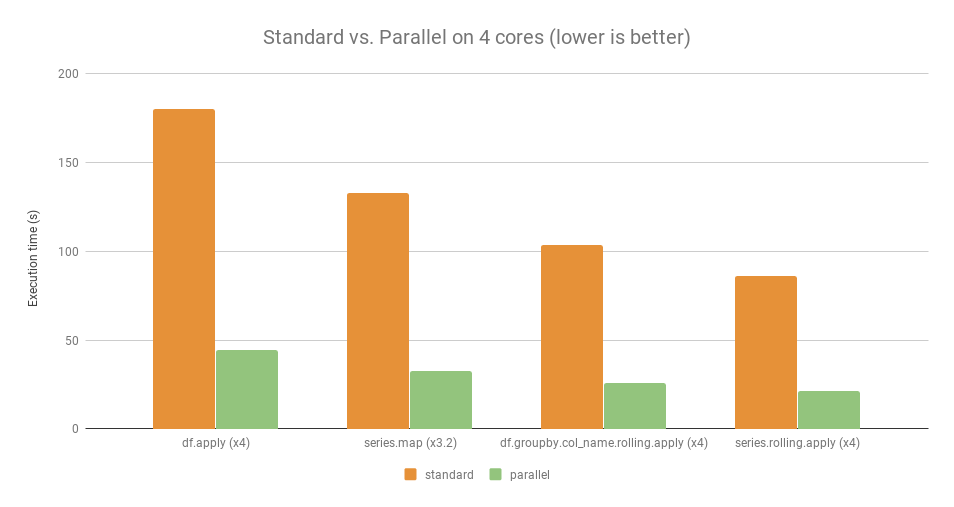
在4核CPU的性能測(cè)試上,它比原始語句快了接近4倍。測(cè)試條件(OS: Linux Ubuntu 16.04,Hardware: Intel Core i7 @ 3.40 GHz - 4 cores),這就是我所說的,它把CPU充分利用了起來。
下面就給大家介紹這個(gè)模塊怎么用,其實(shí)非常簡單,任何代碼只需要加幾行代碼就能實(shí)現(xiàn)質(zhì)的飛躍。
1.準(zhǔn)備
開始之前,你要確保Python和pip已經(jīng)成功安裝在電腦上,如果沒有,可以訪問這篇文章:超詳細(xì)Python安裝指南 進(jìn)行安裝。
(可選1) 如果你用Python的目的是數(shù)據(jù)分析,可以直接安裝Anaconda:Python數(shù)據(jù)分析與挖掘好幫手—Anaconda,它內(nèi)置了Python和pip.
(可選2) 此外,推薦大家用VSCode編輯器,它有許多的優(yōu)點(diǎn):Python 編程的最好搭檔—VSCode 詳細(xì)指南。
請(qǐng)選擇以下任一種方式輸入命令安裝依賴:
1. Windows 環(huán)境 打開 Cmd (開始-運(yùn)行-CMD)。
2. MacOS 環(huán)境 打開 Terminal (command+空格輸入Terminal)。
3. 如果你用的是 VSCode編輯器 或 Pycharm,可以直接使用界面下方的Terminal.
pip install pandarallel對(duì)于windows用戶,有一個(gè)不好的消息是,它只能在Windows的linux子系統(tǒng)上運(yùn)行(WSL),你可以在微軟官網(wǎng)上找到安裝教程:
https://docs.microsoft.com/zh-cn/windows/wsl/about
2.使用Pandarallel
使用前,需要對(duì)Pandarallel進(jìn)行初始化:
from pandarallel import pandarallel
pandarallel.initialize()這樣才能調(diào)用并行計(jì)算的API,不過 initialize 中有一個(gè)重要參數(shù)需要說明,那就是 nb_workers ,它將指定并行計(jì)算的Worker數(shù),如果沒有設(shè)置,所有CPU的核都會(huì)用上。
Pandarallel一共支持8種Pandas操作,下面是一個(gè)apply方法的例子。
import pandas as pd
import time
import math
import numpy as np
from pandarallel import pandarallel
# 初始化
pandarallel.initialize()
df_size = int(5e6)
df = pd.DataFrame(dict(a=np.random.randint(1, 8, df_size),
b=np.random.rand(df_size)))
def func(x):
return math.sin(x.a**2) + math.sin(x.b**2)
# 正常處理
res = df.apply(func, axis=1)
# 并行處理
res_parallel = df.parallel_apply(func, axis=1)
# 查看結(jié)果是否相同
res.equals(res_parallel)其他方法使用上也是類似的,在原始的函數(shù)名稱前加上 parallel_,比如 DataFrame.groupby.apply:
import pandas as pd
import time
import math
import numpy as np
from pandarallel import pandarallel
# 初始化
pandarallel.initialize()
df_size = int(3e7)
df = pd.DataFrame(dict(a=np.random.randint(1, 1000, df_size),
b=np.random.rand(df_size)))
def func(df):
dum = 0
for item in df.b:
dum += math.log10(math.sqrt(math.exp(item**2)))
return dum / len(df.b)
# 正常處理
res = df.groupby("a").apply(func)
# 并行處理
res_parallel = df.groupby("a").parallel_apply(func)
res.equals(res_parallel)又比如 DataFrame.groupby.rolling.apply:
import pandas as pd
import time
import math
import numpy as np
from pandarallel import pandarallel
# 初始化
pandarallel.initialize()
df_size = int(1e6)
df = pd.DataFrame(dict(a=np.random.randint(1, 300, df_size),
b=np.random.rand(df_size)))
def func(x):
return x.iloc[0] + x.iloc[1] ** 2 + x.iloc[2] ** 3 + x.iloc[3] ** 4
# 正常處理
res = df.groupby('a').b.rolling(4).apply(func, raw=False)
# 并行處理
res_parallel = df.groupby('a').b.rolling(4).parallel_apply(func, raw=False)
res.equals(res_parallel)案例都是類似的,這里就直接列出表格,不浪費(fèi)大家寶貴的時(shí)間去閱讀一些重復(fù)的例子了:
沒有并行計(jì)算(原始pandas)
pandarallel
df.apply(func)
df.parallel_apply(func)
df.applymap(func)
df.parallel_applymap(func)
df.groupby(args).apply(func)
df.groupby(args).parallel_apply(func)
df.groupby(args1).col_name.rolling(args2).apply(func)
df.groupby(args1).col_name.rolling(args2).parallel_apply(func)
df.groupby(args1).col_name.expanding(args2).apply(func)
df.groupby(args1).col_name.expanding(args2).parallel_apply(func)
series.map(func)
series.parallel_map(func)
series.apply(func)
series.parallel_apply(func)
series.rolling(args).apply(func)
series.rolling(args).parallel_apply(func)
3.注意事項(xiàng)
1. 我有 8 個(gè) CPU,但 parallel_apply 只能加快大約4倍的計(jì)算速度。為什么?
答:正如我前面所言,Python中每個(gè)進(jìn)程占用一個(gè)核,Pandarallel 最多只能加快到你所擁有的核心的總數(shù),一個(gè) 4 核的超線程 CPU 將向操作系統(tǒng)顯示 8 個(gè) CPU,但實(shí)際上只有 4 個(gè)核心,因此最多加快4倍。
2. 并行化是有成本的(實(shí)例化新進(jìn)程,通過共享內(nèi)存發(fā)送數(shù)據(jù),...),所以只有當(dāng)并行化的計(jì)算量足夠大時(shí),并行化才是有意義的。對(duì)于很少量的數(shù)據(jù),使用 Pandarallel 并不總是值得的。
我們的文章到此就結(jié)束啦,如果你喜歡今天的Python 實(shí)戰(zhàn)教程,請(qǐng)持續(xù)關(guān)注Python實(shí)用寶典。
相關(guān)閱讀: