
基于遷移學(xué)習(xí)的狗狗分類器
點擊上方“小白學(xué)視覺”,選擇加"星標(biāo)"或“置頂”
重磅干貨,第一時間送達

你以前聽說過深度學(xué)習(xí)這個詞嗎? 或者你剛剛開始學(xué)習(xí)它?
在本文中,我將引導(dǎo)您構(gòu)建自己的狗狗分類器。在這個項目的最后:
您的代碼將接受任何用戶提供的圖像作為輸入
如果一只狗在圖像中被檢測到,它將提供對該狗狗品種的預(yù)測
我會讓它盡可能的簡單~
實現(xiàn)步驟如下:
步驟0:導(dǎo)入數(shù)據(jù)集
步驟1:圖像預(yù)處理
步驟2:選擇遷移學(xué)習(xí)的模式
步驟3:更改預(yù)訓(xùn)練模型的分類器
步驟4:編寫訓(xùn)練算法
步驟5:訓(xùn)練模型
步驟6:測試模型
步驟7:測試你自己的圖片
步驟0:導(dǎo)入數(shù)據(jù)集
你可以從下列網(wǎng)址下載你自己的數(shù)據(jù)集:https://www.kaggle.com/c/dog-breed-identification
然后解壓縮文件!
由于圖像處理在本地機器上需要大量的時間和資源,因此我將使用 colab 的 GPU 來訓(xùn)練我的模型。所以,如果你沒有自己的 GPU,也可以切換到 colab 來跟進。
導(dǎo)入必要的庫始終是一個良好的開始,下面代碼展示了我們訓(xùn)練所需要的庫。
#Importing Librariesimport numpy as npimport pandas as pdimport matplotlib.pyplot as pltfrom PIL import Imagefrom PIL import ImageFileimport cv2# importing Pytorch model librariesimport torchimport torchvision.models as modelsimport torchvision.transforms as transformsfrom torchvision import datasetsimport torch.nn as nnimport torch.nn.functional as Fimport torch.optim as optim
在下列代碼的圓括號的雙引號中輸入 dog_images 的路徑。
dog_files = np.array(glob("/data/dog_images/*/*/*"))# print number of images in each datasetprint('There are %d total dog images.' % len(dog_files))
Output : There are 8351 total dog images.步驟1:圖像預(yù)處理
首先,您需要將訓(xùn)練、驗證和測試集數(shù)據(jù)的目錄加載到一些變量中。
#Loading images data into the memory and storing them into the variablesdata_dir = '/content/dogImages'train_dir = data_dir + '/train'valid_dir = data_dir + '/valid'test_dir = data_dir + '/test'
然后需要對加載的圖像進行一些變換,這就是所謂的數(shù)據(jù)預(yù)處理。
為什么有這個必要?
您的圖像必須與網(wǎng)絡(luò)的輸入大小匹配。如果您需要調(diào)整圖像的大小以匹配網(wǎng)絡(luò),那么您可以將數(shù)據(jù)重新縮放或裁剪到所需的大小
數(shù)據(jù)增強也使您能夠訓(xùn)練網(wǎng)絡(luò)不受圖像數(shù)據(jù)扭曲的影響。為此,我會隨機裁剪和調(diào)整圖像的大小
數(shù)據(jù)歸一化也是一個重要步驟,確保每個輸入?yún)?shù)(本例中為像素)具有類似屬性的數(shù)據(jù),這使得訓(xùn)練網(wǎng)絡(luò)時的收斂速度更快
#Applying Data Augmentation and Normalization on imagestrain_transforms = transforms.Compose([transforms.RandomRotation(30),transforms.RandomResizedCrop(224),transforms.RandomHorizontalFlip(),transforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.406],[0.229, 0.224, 0.225])])valid_transforms = transforms.Compose([transforms.Resize(256),transforms.CenterCrop(224),transforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.406],[0.229, 0.224, 0.225])])test_transforms = transforms.Compose([transforms.Resize(255),transforms.CenterCrop(224),transforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.406],[0.229, 0.224, 0.225])])
將圖像存儲到數(shù)據(jù)加載器中
現(xiàn)在我們需要將訓(xùn)練、驗證和測試目錄加載到數(shù)據(jù)加載器中。這將使我們能夠?qū)?shù)據(jù)分成小批量。
我們將數(shù)據(jù)以key-value的格式進行存儲,這將有助于以后調(diào)用它們。
# TODO: Load the datasets with ImageFoldertrain_data = datasets.ImageFolder(train_dir, transform=train_transforms)valid_data = datasets.ImageFolder(valid_dir,transform=valid_transforms)test_data = datasets.ImageFolder(test_dir, transform=test_transforms)# TODO: Using the image datasets and the trainforms, define the dataloaderstrainloader = torch.utils.data.DataLoader(train_data, batch_size=20, shuffle=True)testloader = torch.utils.data.DataLoader(test_data, batch_size=20,shuffle=False)validloader = torch.utils.data.DataLoader(valid_data, batch_size=20,shuffle=False)loaders_transfer = {'train':trainloader,'valid':validloader,'test':testloader}data_transfer = {'train':trainloader}
步驟2:選擇遷移學(xué)習(xí)的模式
什么是預(yù)訓(xùn)練模型,我們?yōu)槭裁匆褂盟?/span>
預(yù)訓(xùn)練模型是別人為解決類似問題而創(chuàng)建的模型。
與其從零開始構(gòu)建模型來解決類似的問題,不如使用經(jīng)過其他問題訓(xùn)練的模型作為起點
一個預(yù)訓(xùn)練模型在應(yīng)用程序中可能不是100% 準(zhǔn)確,但是它節(jié)省了重新發(fā)明輪子所需的巨大努力
遷移學(xué)習(xí)可以利用在一個問題上學(xué)到的特性,并在一個新的、類似的問題上利用它們。例如,一個已經(jīng)學(xué)會識別小浣熊的模型的特征可能有助于開始訓(xùn)練一個用于識別貓咪的模型
你可以選擇幾個事先訓(xùn)練過的模特進行模特訓(xùn)練。例如 Densenet,Resnet,VGG 模型。我將使用 VGG-16進行模型訓(xùn)練。
#Loading vgg11 into the variable model_transfermodel_transfer = models.vgg11(pretrained=True)
步驟3:更改預(yù)訓(xùn)練模型的分類器
將采取以下步驟來改變預(yù)訓(xùn)練分類器:
從以前訓(xùn)練過的模型中取出網(wǎng)絡(luò)層
凍結(jié)它們,以避免在以后的訓(xùn)練回合中破壞它們所包含的任何信息
在凍結(jié)層上添加一些新的、可訓(xùn)練的圖層。他們將學(xué)習(xí)在新的數(shù)據(jù)集上將舊的特性轉(zhuǎn)化為預(yù)測
在你的數(shù)據(jù)集上訓(xùn)練新的網(wǎng)絡(luò)層
由于特征已經(jīng)學(xué)會了預(yù)訓(xùn)練的模型,所以將凍結(jié)他們在訓(xùn)練期間對狗狗的形象。我們只會改變分類器的尺寸,只會訓(xùn)練它。
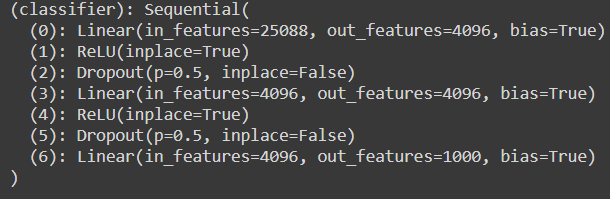
原來的分類器層有25088個維度,但是為了匹配我們的預(yù)處理圖像大小,我們需要更改為4096。
要在 GPU 上訓(xùn)練模型,我們需要使用以下命令將其移動到 GPU-RAM 上。
#Freezing the parametersfor param in model_transfer.features.parameters():param.requires_grad = False#Changing the classifier layermodel_transfer.classifier[6] = nn.Linear(4096,133,bias=True)#Moving the model to GPU-RAM spaceif use_cuda:model_transfer = model_transfer.cuda()print(model_transfer)
現(xiàn)在我們需要選擇一個損失函數(shù)和優(yōu)化器。
利用損失函數(shù)計算模型預(yù)測值與實際圖像的誤差。如果你的預(yù)測完全錯誤,你的損失函數(shù)將輸出更高的數(shù)字。如果它們非常好,那么輸出的數(shù)字就會更低。本文將使用交叉熵損失。
優(yōu)化器是用來改變神經(jīng)網(wǎng)絡(luò)屬性的算法或方法,比如權(quán)重和學(xué)習(xí)速度,以減少損失。本文將使用 SGD 優(yōu)化器。
0.001的學(xué)習(xí)率對于訓(xùn)練是有好處的,但是你也可以用其他的學(xué)習(xí)率進行實驗。鼓勵大家多多嘗試不同的參數(shù)~
### Loading the Loss-Functioncriterion_transfer = nn.CrossEntropyLoss()### Loading the optimizeroptimizer_transfer = optim.SGD(model_transfer.parameters(), lr=0.001, momentum=0.9)
步驟4:編寫訓(xùn)練算法
接下來我們將編寫訓(xùn)練函數(shù)。
我用它編寫了驗證代碼行。所以在訓(xùn)練模型時,我們會同時得到兩種損失。
每次Loss減少時,我也會存儲這個模型。這樣我就不必在以后每次打開一個新實例時都要訓(xùn)練它。
def train(n_epochs, loaders, model, optimizer, criterion, use_cuda, save_path):"""returns trained model"""# initialize tracker for minimum validation lossvalid_loss_min = np.inf #---> Max Value (As the loss decreases and becomes less than this value it gets saved)for epoch in range(1, n_epochs+1):#Initializing training variablestrain_loss = 0.0valid_loss = 0.0# Start training the modelmodel.train()for batch_idx, (data, target) in enumerate(loaders['train']):# move to GPU's memory space (if available)if use_cuda:data, target = data.cuda(), target.cuda()model.to('cuda')optimizer.zero_grad()output = model(data)loss = criterion(output,target)loss.backward()optimizer.step()train_loss = train_loss + ((1 / (batch_idx + 1)) * (loss.data - train_loss))# validate the model #model.eval()for batch_idx, (data, target) in enumerate(loaders['valid']):accuracy=0# move to GPU's memory space (if available)if use_cuda:data, target = data.cuda(), target.cuda()## Update the validation losslogps = model(data)loss = criterion(logps, target)valid_loss += ((1 / (batch_idx + 1)) * (loss.data - valid_loss))# print both training and validation lossesprint('Epoch: {} \tTraining Loss: {:.6f} \tValidation Loss: {:.6f}'.format(epoch,train_loss,valid_loss))if valid_loss <= valid_loss_min:print('Validation loss decreased ({:.6f} --> {:.6f}). Saving model ...'.format(valid_loss_min,valid_loss))#Saving the modeltorch.save(model.state_dict(), 'model_transfer.pt')valid_loss_min = valid_loss# return the trained modelreturn model
步驟5:訓(xùn)練模型
現(xiàn)在,我將開始通過在函數(shù)中提供參數(shù)來訓(xùn)練模型。我將訓(xùn)練10個epoch。
# train the modelmodel_transfer = train(10, loaders_transfer, model_transfer, optimizer_transfer, criterion_transfer, use_cuda, 'model_transfer.pt')# load the model that got the best validation accuracymodel_transfer.load_state_dict(torch.load('model_transfer.pt'))
OUTPUT:Epoch: 1 Training Loss: 2.443815 Validation Loss: 0.801671Validation loss decreased (inf --> 0.801671). Saving model ...Epoch: 2 Training Loss: 1.440627 Validation Loss: 0.591050Validation loss decreased (0.801671 --> 0.591050). Saving model ...Epoch: 3 Training Loss: 1.310158 Validation Loss: 0.560950Validation loss decreased (0.591050 --> 0.560950). Saving model ...Epoch: 4 Training Loss: 1.200572 Validation Loss: 0.566340Epoch: 5 Training Loss: 1.160727 Validation Loss: 0.530196Validation loss decreased (0.560950 --> 0.530196). Saving model ...Epoch: 6 Training Loss: 1.088659 Validation Loss: 0.560774Epoch: 7 Training Loss: 1.060936 Validation Loss: 0.503829Validation loss decreased (0.530196 --> 0.503829). Saving model ...Epoch: 8 Training Loss: 1.010044 Validation Loss: 0.500608Validation loss decreased (0.503829 --> 0.500608). Saving model ...Epoch: 9 Training Loss: 1.054875 Validation Loss: 0.497319Validation loss decreased (0.500608 --> 0.497319). Saving model ...Epoch: 10 Training Loss: 1.000547 Validation Loss: 0.545735<All keys matched successfully>
步驟6:測試模型
現(xiàn)在我將在模型以前從未見過的新圖像上測試模型,并計算預(yù)測的準(zhǔn)確性。
def test(loaders, model, criterion, use_cuda):# Initializing the variablestest_loss = 0.correct = 0.total = 0.model.eval() #So that it doesn't change the model parameters during testingfor batch_idx, (data, target) in enumerate(loaders['test']):# move to GPU's memory spave if availableif use_cuda:data, target = data.cuda(), target.cuda()# Passing the data to the model (Forward Pass)output = model(data)loss = criterion(output, target) #Test Losstest_loss = test_loss + ((1 / (batch_idx + 1)) * (loss.data - test_loss))# Output probabilities to the predicted classpred = output.data.max(1, keepdim=True)[1]# Comparing the predicted class to outputcorrect += np.sum(np.squeeze(pred.eq(target.data.view_as(pred))).cpu().numpy())total += data.size(0)print('Test Loss: {:.6f}\n'.format(test_loss))print('\nTest Accuracy: %2d%% (%2d/%2d)' % (100. * correct / total, correct, total))test(loaders_transfer, model_transfer, criterion_transfer, use_cuda)
我已經(jīng)訓(xùn)練了它10個 epoch,得到了83% 的準(zhǔn)確率。并且,得到以下輸出!
Output:Test Loss: 0.542430 Test Accuracy: 83% (700/836)
如何提高這個模型的準(zhǔn)確性?
通過訓(xùn)練更多的 epoch(比較訓(xùn)練和驗證損失)
通過改變學(xué)習(xí)率(比如0.01,0.05,0.1)
通過改變預(yù)訓(xùn)練模型(像稠密網(wǎng)絡(luò),但需要更多的訓(xùn)練時間)
通過對圖像的進一步預(yù)處理
步驟7:測試你自己的圖片
現(xiàn)在你已經(jīng)訓(xùn)練和測試了你的模型。現(xiàn)在,這是最令人興奮的部分。你能走到這一步真是太好了。
1.將要測試和保存的新圖像加載到內(nèi)存中
#Loading the new image directorydog_files_short = np.array(glob("/content/my_dogs/*"))#Loading the modelmodel_transfer.load_state_dict(torch.load('model_transfer.pt'))
2. 現(xiàn)在我們必須對圖像進行預(yù)處理,并通過測試我們訓(xùn)練好的模型來預(yù)測類
def predict_breed_transfer(img_path):#Preprocessing the input imagetransform = transforms.Compose([transforms.Resize(255),transforms.CenterCrop(224),transforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.406],[0.229, 0.224, 0.225])])img = Image.open(img_path)img = transform(img)[:3,:,:].unsqueeze(0)if use_cuda:img = img.cuda()model_transfer.to('cuda')# Passing throught the modelmodel_transfer.eval()# Checking the name of class by passing the indexclass_names = [item[4:].replace("_", " ") for item in data_transfer['train'].dataset.classes]idx = torch.argmax(model_transfer(img))return class_names[idx]output = model_transfer(img)# Probabilities to classpred = output.data.max(1, keepdim=True)[1]return pred
3. 現(xiàn)在,通過將圖像路徑作為參數(shù)傳遞給這個函數(shù),我們可以預(yù)測狗狗的品種。
我已經(jīng)傳遞了下面的圖像,并得到了下列輸出。

Output:Norwegian buhund
總結(jié)
這只是一個開始,你可以用這個模型做更多的事情。你可以通過部署它來創(chuàng)建一個應(yīng)用程序。我嘗試從零開始創(chuàng)建自己的模型,沒有使用遷移學(xué)習(xí),但測試的準(zhǔn)確率不超過13% 。你也可以嘗試一下,因為這有助于理解概念。

交流群
歡迎加入公眾號讀者群一起和同行交流,目前有SLAM、三維視覺、傳感器、自動駕駛、計算攝影、檢測、分割、識別、醫(yī)學(xué)影像、GAN、算法競賽等微信群(以后會逐漸細分),請掃描下面微信號加群,備注:”昵稱+學(xué)校/公司+研究方向“,例如:”張三?+?上海交大?+?視覺SLAM“。請按照格式備注,否則不予通過。添加成功后會根據(jù)研究方向邀請進入相關(guān)微信群。請勿在群內(nèi)發(fā)送廣告,否則會請出群,謝謝理解~