
【NLP】基于機器學習的文本分類!
本文主要基于機器學習的方法,介紹了特征提取+分類模型在文本分類中的應(yīng)用。具體目錄如下:

https://tianchi.aliyun.com/competition/entrance/531810/information(阿里天池-零基礎(chǔ)入門NLP賽事)
二、文本表示方法
在機器學習算法的訓練過程中,假設(shè)給定個樣本,每個樣本有個特征,這樣就組成了的樣本矩陣。在計算機視覺中可以把圖片的像素看作特征,每張圖片都可以視為的特征圖,然后用一個三維矩陣帶入計算。
2.1 One-hot
句子1:我 愛 北 京 天 安 門
句子2:我 喜 歡 上 海
首先對句子中的所有字進行索引
{'我': 1, '愛': 2, '北': 3, '京': 4, '天': 5, '安': 6, '門': 7, '喜': 8, '歡': 9, '上': 10, '海': 11}
一共11個字,因此每個字可以轉(zhuǎn)換為一個11維的稀疏向量:
我:[1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
愛:[0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0]
...
海:[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1]
2.2 Bags of Words
句子1:我 愛 北 京 天 安 門
句子2:我 喜 歡 上 海
直接統(tǒng)計每個字出現(xiàn)的次數(shù),并進行賦值:
句子1:我 愛 北 京 天 安 門
轉(zhuǎn)換為 [1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0]
句子2:我 喜 歡 上 海
轉(zhuǎn)換為 [1, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1]
可以利用sklearn的CountVectorizer來實現(xiàn)這一步驟。
from sklearn.feature_extraction.text import CountVectorizercorpus = ['This is the first document.','This document is the second document.','And this is the third one.','Is this the first document?',]vectorizer = CountVectorizer()vectorizer.fit_transform(corpus).toarray()
輸出為:
[[0, 1, 1, 1, 0, 0, 1, 0, 1],
[0, 2, 0, 1, 0, 1, 1, 0, 1],
[1, 0, 0, 1, 1, 0, 1, 1, 1],
[0, 1, 1, 1, 0, 0, 1, 0, 1]]
2.3 N-gram
N-gram與Count Vectors類似,不過加入了相鄰單詞組合為新的單詞,并進行計數(shù)。如果N取值為2,則句子1和句子2就變?yōu)椋?/span>
句子1:我愛 愛北 北京 京天 天安 安門
句子2:我喜 喜歡 歡上 上海
2.4 TF-IDF


三、基于機器學習的文本分類
接下來我們將研究文本表示對算法精度的影響,對比同一分類算法在不同文本表示下的算法精度,通過本地構(gòu)建驗證集計算F1得分。
3.1 導(dǎo)入相關(guān)的包
import pandas as pdimport numpy as npfrom sklearn.feature_extraction.text import CountVectorizerfrom sklearn.feature_extraction.text import TfidfVectorizerfrom sklearn.linear_model import RidgeClassifierimport matplotlib.pyplot as pltfrom sklearn.metrics import f1_score
3.2 讀取數(shù)據(jù)
train_df = pd.read_csv('./data/train_set.csv', sep='\t', nrows=15000)
3.3 文本分類對比
3.3.1 Count Vectors + RidgeClassifier
vectorizer = CountVectorizer(max_features=3000)train_test = vectorizer.fit_transform(train_df['text'])clf = RidgeClassifier()clf.fit(train_test[:10000], train_df['label'].values[:10000])val_pred = clf.predict(train_test[10000:])print(f1_score(train_df['label'].values[10000:], val_pred, average='macro'))
輸出為.
3.3.2 TF-IDF + RidgeClassifier
tfidf = TfidfVectorizer(ngram_range=(1,3), max_features=3000)train_test = tfidf.fit_transform(train_df['text'])clf = RidgeClassifier()clf.fit(train_test[:10000], train_df['label'].values[:10000])val_pred = clf.predict(train_test[10000:])print(f1_score(train_df['label'].values[10000:], val_pred, average='macro'))
輸出為.
四、研究參數(shù)對模型的影響
4.1 正則化參數(shù)對模型的影響
取大小為5000的樣本,保持其他參數(shù)不變,令從0.15增加至1.5,畫出關(guān)于和的圖像
sample = train_df[0:5000]n = int(2*len(sample)/3)tfidf = TfidfVectorizer(ngram_range=(2,3), max_features=2500)train_test = tfidf.fit_transform(sample['text'])train_x = train_test[:n]train_y = sample['label'].values[:n]test_x = train_test[n:]test_y = sample['label'].values[n:]f1 = []for i in range(10):clf = RidgeClassifier(alpha = 0.15*(i+1), solver = 'sag')clf.fit(train_x, train_y)val_pred = clf.predict(test_x)f1.append(f1_score(test_y, val_pred, average='macro'))plt.plot([0.15*(i+1) for i in range(10)], f1)plt.xlabel('alpha')plt.ylabel('f1_score')plt.show()
結(jié)果如下:
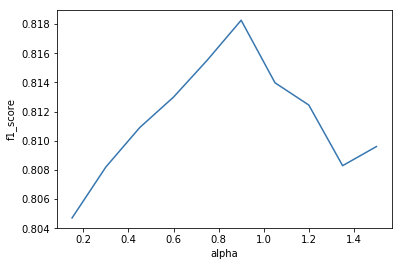
可以看出不宜取的過大,也不宜過小。越小模型的擬合能力越強,泛化能力越弱,越大模型的擬合能力越差,泛化能力越強。
4.2 max_features對模型的影響
分別取max_features的值為1000、2000、3000、4000,研究max_features對模型精度的影響
f1 = []features = [1000,2000,3000,4000]for i in range(4):tfidf = TfidfVectorizer(ngram_range=(2,3), max_features=features[i])train_test = tfidf.fit_transform(sample['text'])train_x = train_test[:n]train_y = sample['label'].values[:n]test_x = train_test[n:]test_y = sample['label'].values[n:]clf = RidgeClassifier(alpha = 0.1*(i+1), solver = 'sag')train_y)val_pred = clf.predict(test_x)val_pred, average='macro'))f1)plt.xlabel('max_features')plt.ylabel('f1_score')plt.show()
結(jié)果如下:
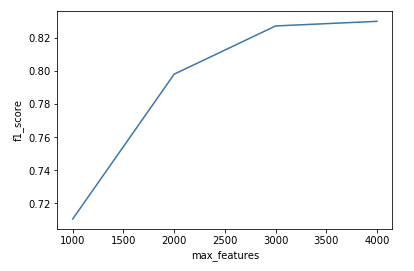
可以看出max_features越大模型的精度越高,但是當max_features超過某個數(shù)之后,再增加max_features的值對模型精度的影響就不是很顯著了。
4.3 ngram_range對模型的影響
n-gram提取詞語字符數(shù)的下邊界和上邊界,考慮到中文的用詞習慣,ngram_range可以在(1,4)之間選取
f1 = []tfidf = TfidfVectorizer(ngram_range=(1,1), max_features=2000)train_test = tfidf.fit_transform(sample['text'])train_x = train_test[:n]train_y = sample['label'].values[:n]test_x = train_test[n:]test_y = sample['label'].values[n:]clf = RidgeClassifier(alpha = 0.1*(i+1), solver = 'sag')clf.fit(train_x, train_y)val_pred = clf.predict(test_x)f1.append(f1_score(test_y, val_pred, average='macro'))tfidf = TfidfVectorizer(ngram_range=(2,2), max_features=2000)train_test = tfidf.fit_transform(sample['text'])train_x = train_test[:n]train_y = sample['label'].values[:n]test_x = train_test[n:]test_y = sample['label'].values[n:]clf = RidgeClassifier(alpha = 0.1*(i+1), solver = 'sag')clf.fit(train_x, train_y)val_pred = clf.predict(test_x)f1.append(f1_score(test_y, val_pred, average='macro'))tfidf = TfidfVectorizer(ngram_range=(3,3), max_features=2000)train_test = tfidf.fit_transform(sample['text'])train_x = train_test[:n]train_y = sample['label'].values[:n]test_x = train_test[n:]test_y = sample['label'].values[n:]clf = RidgeClassifier(alpha = 0.1*(i+1), solver = 'sag')clf.fit(train_x, train_y)val_pred = clf.predict(test_x)f1.append(f1_score(test_y, val_pred, average='macro'))tfidf = TfidfVectorizer(ngram_range=(1,3), max_features=2000)train_test = tfidf.fit_transform(sample['text'])train_x = train_test[:n]train_y = sample['label'].values[:n]test_x = train_test[n:]test_y = sample['label'].values[n:]clf = RidgeClassifier(alpha = 0.1*(i+1), solver = 'sag')clf.fit(train_x, train_y)val_pred = clf.predict(test_x)f1.append(f1_score(test_y, val_pred, average='macro'))
輸出如下

ngram_range取(1,3)的效果較好。
五、考慮其他分類模型
5.1 LogisticRegression
LogisticRegression的目標函數(shù)為:
from sklearn import linear_modeltfidf = TfidfVectorizer(ngram_range=(1,3), max_features=5000)train_test = tfidf.fit_transform(train_df['text']) # 詞向量 15000*max_featuresreg = linear_model.LogisticRegression(penalty='l2', C=1.0,solver='liblinear')reg.fit(train_test[:10000], train_df['label'].values[:10000])val_pred = reg.predict(train_test[10000:])print('預(yù)測結(jié)果中各類新聞數(shù)目')print(pd.Series(val_pred).value_counts())print('\n F1 score為')print(f1_score(train_df['label'].values[10000:], val_pred, average='macro'))
輸出為0.846470490043.
5.2 SGDClassifier
SGDClassifier使用mini-batch來做梯度下降,在處理大數(shù)據(jù)的情況下收斂更快
tfidf = TfidfVectorizer(ngram_range=(1,3), max_features=5000)train_test = tfidf.fit_transform(train_df['text']) # 詞向量 15000*max_featuresreg = linear_model.SGDClassifier(loss="log", penalty='l2', alpha=0.0001,l1_ratio=0.15)reg.fit(train_test[:10000], train_df['label'].values[:10000])val_pred = reg.predict(train_test[10000:])print('預(yù)測結(jié)果中各類新聞數(shù)目')print(pd.Series(val_pred).value_counts())print('\n F1 score為')print(f1_score(train_df['label'].values[10000:], val_pred, average='macro'))
輸出為0.847267047346
5.3 SVM
from sklearn import svmtfidf = TfidfVectorizer(ngram_range=(1,3), max_features=5000)train_test = tfidf.fit_transform(train_df['text']) # 詞向量 15000*max_featuresreg = svm.SVC(C=1.0, kernel='linear', degree=3, gamma='auto',decision_function_shape='ovr')reg.fit(train_test[:10000], train_df['label'].values[:10000])val_pred = reg.predict(train_test[10000:])print('預(yù)測結(jié)果中各類新聞數(shù)目')print(pd.Series(val_pred).value_counts())print('\n F1 score為')print(f1_score(train_df['label'].values[10000:], val_pred, average='macro'))
輸出為0.884240695943.
對比幾種機器學習算法可以看出,在相同的TF-IDF特征提取方法基礎(chǔ)上,用SVM得到的分類效果最好。
往期精彩回顧
獲取一折本站知識星球優(yōu)惠券,復(fù)制鏈接直接打開:
https://t.zsxq.com/662nyZF
本站qq群1003271085。
加入微信群請掃碼進群(如果是博士或者準備讀博士請說明):