機(jī)器學(xué)習(xí)入門, scikit-learn 構(gòu)建模型萬能模板!
來源:https://zhuanlan.zhihu.com/p/88729124
用Python建立機(jī)器學(xué)習(xí)模型,得益于Python生態(tài)下的包共享機(jī)制,機(jī)器模型構(gòu)建的過程其實(shí)已經(jīng)變得非常簡單了,很多聽起來牛逼的算法,其實(shí)根本不需要自己實(shí)現(xiàn),甚至都不需要知道這些算法的具體原理。
你只需要兩步就能構(gòu)建起自己的機(jī)器學(xué)習(xí)模型:
明確你需要解決的問題是什么類型,以及知道解決該類型問題所對應(yīng)的算法。 從skicit-learn中調(diào)用相應(yīng)的算法構(gòu)建模型即可。是的!在機(jī)器學(xué)習(xí)領(lǐng)域,如果你只是抱著體驗(yàn)機(jī)器學(xué)習(xí)的心態(tài),實(shí)現(xiàn)起來就是這么簡單。
第一步很好解決
常見的問題類型只有三種:分類、回歸、聚類。而明確具體問題對應(yīng)的類型也很簡單。比如,如果你需要通過輸入數(shù)據(jù)得到一個(gè)類別變量,那就是分類問題。分成兩類就是二分類問題,分成兩類以上就是多分類問題。常見的有:判別一個(gè)郵件是否是垃圾郵件、根據(jù)圖片分辯圖片里的是貓還是狗等等。
如果你需要通過輸入數(shù)據(jù)得到一個(gè)具體的連續(xù)數(shù)值,那就是回歸問題。比如:預(yù)測某個(gè)區(qū)域的房價(jià)等。
常用的分類和回歸算法算法有:SVM (支持向量機(jī)) 、xgboost、, KNN、LR算法、SGD (隨機(jī)梯度下降算法)、Bayes (貝葉斯估計(jì))以及隨機(jī)森林等。這些算法大多都既可以解分類問題,又可以解回歸問題。
如果你的數(shù)據(jù)集并沒有對應(yīng)的屬性標(biāo)簽,你要做的,是發(fā)掘這組樣本在空間的分布, 比如分析哪些樣本靠的更近,哪些樣本之間離得很遠(yuǎn), 這就是屬于聚類問題。常用的聚類算法有k-means算法。
在本文中,我們主要解決第二步:通過skicit-learn構(gòu)建模型。告訴你你一套讓你簡單到想笑的通用模型構(gòu)建模板。只要scikit-learn實(shí)現(xiàn)的算法,都可以通過這種方式快速調(diào)用。牢記這三個(gè)萬能模板,你就能輕松構(gòu)建起自己的機(jī)器學(xué)習(xí)模型。
預(yù)備工作
在介紹萬能模板之前,為了能夠更深刻地理解這三個(gè)模板,我們加載一個(gè)Iris(鳶尾花)數(shù)據(jù)集來作為應(yīng)用萬能模板的小例子,Iris數(shù)據(jù)集在前邊的文章中已經(jīng)提到過多次了,這里不再贅述。它是一個(gè)典型的多分類問題。加載步驟如下:
1、加載數(shù)據(jù)集
因?yàn)樵嫉臄?shù)據(jù)集中包含很多空值,而且類別特征用英文名表示各個(gè)花的名字,也需要我們轉(zhuǎn)換成數(shù)字。
在scikit-learn下的datasets子包里,也自帶了一個(gè)Iris數(shù)據(jù)集,這個(gè)數(shù)據(jù)集和原始數(shù)據(jù)集的區(qū)別就是scikit-learn已經(jīng)幫我們提前處理好了空值等問題,可以直接輸入模型用來訓(xùn)練。所以為了方便起見,我們直接使用scikit-learn的數(shù)據(jù)集。加載方法如下:
from?sklearn.datasets?import?load_iris
data?=?load_iris()
x?=?data.data
y?=?data.target
x值如下,可以看到scikit-learn把數(shù)據(jù)集經(jīng)過去除空值處理放在了array里,所以x是一個(gè)(150,4)的數(shù)組,保存了150個(gè)數(shù)據(jù)的4個(gè)特征:
array([[5.1, 3.5, 1.4, 0.2], [4.9, 3. , 1.4, 0.2], [4.7, 3.2, 1.3, 0.2], [4.6, 3.1, 1.5, 0.2], [5. , 3.6, 1.4, 0.2], [5.4, 3.9, 1.7, 0.4], [4.6, 3.4, 1.4, 0.3], [5. , 3.4, 1.5, 0.2], [4.4, 2.9, 1.4, 0.2], [4.9, 3.1, 1.5, 0.1], [5.4, 3.7, 1.5, 0.2], [4.8, 3.4, 1.6, 0.2], [4.8, 3. , 1.4, 0.1], [4.3, 3. , 1.1, 0.1], …………
y值如下,共有150行,其中0、1、2分別代表三類花:
array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2])
2、數(shù)據(jù)集拆分
數(shù)據(jù)集拆分是為了驗(yàn)證模型在訓(xùn)練集和測試集是否過擬合,使用train_test_split的目的是保證從數(shù)據(jù)集中均勻拆分出測試集。這里,簡單把10%的數(shù)據(jù)集拿出來用作測試集。
from?sklearn.model_selection?import?train_test_split
train_x,test_x,train_y,test_y?=?train_test_split(x,y,test_size=0.1,random_state=0)
萬能模板V1.0版
助你快速構(gòu)建一個(gè)基本的算法模型

不同的算法只是改變了名字,以及模型的參數(shù)不同而已。
有了這個(gè)萬能模板,接下來就是簡單的復(fù)制粘貼改名字了:
而且在scikit-learn中,每個(gè)包的位置都是有規(guī)律的,比如:隨機(jī)森林就是在集成學(xué)習(xí)文件夾下。
模板1.0應(yīng)用案例
1、構(gòu)建SVM分類模型
通過查閱資料,我們知道svm算法在scikit-learn.svm.SVC下,所以:
算法位置填入: svm算法名填入: SVC()模型名自己起,這里我們就叫 svm_model
套用模板得到程序如下:
#?svm分類器
from?sklearn.svm?import?SVC
from?sklearn.metrics?import?accuracy_score
svm_model?=?SVC()
svm_model.fit(train_x,train_y)
pred1?=?svm_model.predict(train_x)
accuracy1?=?accuracy_score(train_y,pred1)
print('在訓(xùn)練集上的精確度:?%.4f'%accuracy1)
pred2?=?svm_model.predict(test_x)
accuracy2?=?accuracy_score(test_y,pred2)
print('在測試集上的精確度:?%.4f'%accuracy2)
輸出:
在訓(xùn)練集上的精確度: 0.9810
在測試集上的精確度: 0.9778
2、構(gòu)建LR分類模型
同理,找到LR算法在sklearn.linear_model.LogisticRegression下,所以:
算法位置填入: linear_model算法名填入: LogisticRegression模型名叫做:lr_model。
程序如下:
套用模板得到程序如下:
#?LogisticRegression分類器
from?sklearn.linear_model?import?LogisticRegression
from?sklearn.metrics?import?accuracy_score?#評分函數(shù)用精確度評估
lr_model?=?LogisticRegression()
lr_model.fit(train_x,train_y)
pred1?=?lr_model.predict(train_x)
accuracy1?=?accuracy_score(train_y,pred1)
print('在訓(xùn)練集上的精確度:?%.4f'%accuracy1)
pred2?=?lr_model.predict(test_x)
accuracy2?=?accuracy_score(test_y,pred2)
print('在測試集上的精確度:?%.4f'%accuracy2)
輸出:
在訓(xùn)練集上的精確度: 0.9429
在測試集上的精確度: 0.8889
3、構(gòu)建隨機(jī)森林分類模型
隨機(jī)森林算法在sklearn.ensemble.RandomForestClassifier?下,好了,現(xiàn)在你應(yīng)該可以自己寫了,這個(gè)作為本文的一個(gè)小測試,歡迎在評論區(qū)寫下你的答案。
萬能模板V2.0版
加入交叉驗(yàn)證,讓算法模型評估更加科學(xué)
在1.0版的模板中,當(dāng)你多次運(yùn)行同一個(gè)程序就會(huì)發(fā)現(xiàn):每次運(yùn)行得到的精確度并不相同,而是在一定范圍內(nèi)浮動(dòng),這是因?yàn)閿?shù)據(jù)輸入模型之前會(huì)進(jìn)行選擇,每次訓(xùn)練時(shí)數(shù)據(jù)輸入模型的順序都不一樣。所以即使是同一個(gè)程序,模型最后的表現(xiàn)也會(huì)有好有壞。
更糟糕的是,有些情況下,在訓(xùn)練集上,通過調(diào)整參數(shù)設(shè)置使模型的性能達(dá)到了最佳狀態(tài),但在測試集上卻可能出現(xiàn)過擬合的情況。這個(gè)時(shí)候,我們在訓(xùn)練集上得到的評分不能有效反映出模型的泛化性能。
為了解決上述兩個(gè)問題,還應(yīng)該在訓(xùn)練集上劃分出驗(yàn)證集(validation set)并結(jié)合交叉驗(yàn)證來解決。首先,在訓(xùn)練集中劃分出不參與訓(xùn)練的驗(yàn)證集,只是在模型訓(xùn)練完成以后對模型進(jìn)行評估,接著再在測試集上進(jìn)行最后的評估。
但這樣大大減少了可用于模型學(xué)習(xí)的樣本數(shù)量,所以還需要采用交叉驗(yàn)證的方式多訓(xùn)練幾次。比如說最常用的k-折交叉驗(yàn)證如下圖所示,它主要是將訓(xùn)練集劃分為 k 個(gè)較小的集合。然后將k-1份訓(xùn)練子集作為訓(xùn)練集訓(xùn)練模型,將剩余的 1 份訓(xùn)練集子集作為驗(yàn)證集用于模型驗(yàn)證。這樣需要訓(xùn)練k次,最后在訓(xùn)練集上的評估得分取所有訓(xùn)練結(jié)果評估得分的平均值。
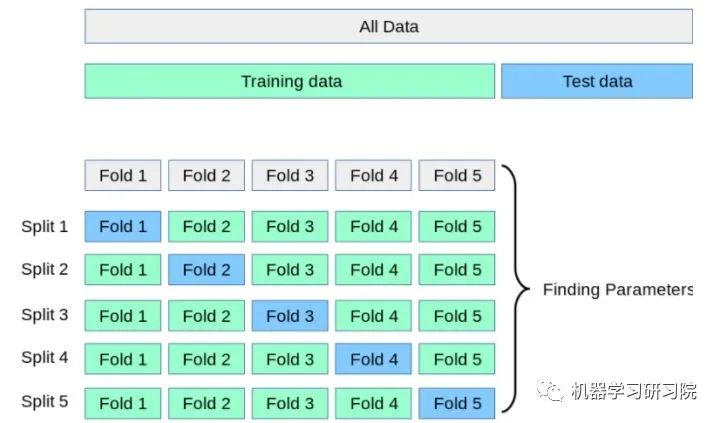
這樣一方面可以讓訓(xùn)練集的所有數(shù)據(jù)都參與訓(xùn)練,另一方面也通過多次計(jì)算得到了一個(gè)比較有代表性的得分。唯一的缺點(diǎn)就是計(jì)算代價(jià)很高,增加了k倍的計(jì)算量。
原理就是這樣,但理想很豐滿,現(xiàn)實(shí)很骨干。在自己實(shí)現(xiàn)的時(shí)候卻有一個(gè)很大的難題擺在面前:怎么能夠把訓(xùn)練集均勻地劃分為K份?
這個(gè)問題不用思考太多,既然別忘了,我們現(xiàn)在是站在巨人的肩膀上,scikit-learn已經(jīng)將優(yōu)秀的數(shù)學(xué)家所想到的均勻拆分方法和程序員的智慧融合在了cross_val_score()?這個(gè)函數(shù)里了,只需要調(diào)用該函數(shù)即可,不需要自己想什么拆分算法,也不用寫for循環(huán)進(jìn)行循環(huán)訓(xùn)練。
萬能模板2.0如下:

把模型、數(shù)據(jù)、劃分驗(yàn)證集的個(gè)數(shù)一股腦輸入函數(shù),函數(shù)會(huì)自動(dòng)執(zhí)行上邊所說的過程。
在求精確度的時(shí)候,我們可以簡單地輸出平均精確度:
#?輸出精確度的平均值
#?print("訓(xùn)練集上的精確度:?%0.2f?"?%?scores1.mean())
但是既然我們進(jìn)行了交叉驗(yàn)證,做了這么多計(jì)算量,單求一個(gè)平均值還是有點(diǎn)浪費(fèi)了,可以利用下邊代碼捎帶求出精確度的置信度:
#?輸出精確度的平均值和置信度區(qū)間
print("訓(xùn)練集上的平均精確度:?%0.2f?(+/-?%0.2f)"?%?(scores2.mean(),?scores2.std()?*?2))
模板2.0應(yīng)用案例:
1、構(gòu)建SVM分類模型
程序如下:
### svm分類器
from sklearn.model_selection import cross_val_score
from sklearn.svm import SVC
svm_model = SVC()
svm_model.fit(train_x,train_y)
scores1 = cross_val_score(svm_model,train_x,train_y,cv=5, scoring='accuracy')
# 輸出精確度的平均值和置信度區(qū)間
print("訓(xùn)練集上的精確度: %0.2f (+/- %0.2f)" % (scores1.mean(), scores1.std() * 2))
scores2 = cross_val_score(svm_model,test_x,test_y,cv=5, scoring='accuracy')
# 輸出精確度的平均值和置信度區(qū)間
print("測試集上的平均精確度: %0.2f (+/- %0.2f)" % (scores2.mean(), scores2.std() * 2))
print(scores1)
print(scores2)
輸出:
訓(xùn)練集上的精確度: 0.97 (+/- 0.08)
測試集上的平均精確度: 0.91 (+/- 0.10)
[1. 1. 1. 0.9047619 0.94736842]
[1. 0.88888889 0.88888889 0.875 0.875 ]
2、構(gòu)建LR分類模型
#?LogisticRegression分類器
from?sklearn.model_selection?import?cross_val_score
from?sklearn.linear_model?import?LogisticRegression
lr_model?=?LogisticRegression()
lr_model.fit(train_x,train_y)
scores1?=?cross_val_score(lr_model,train_x,train_y,cv=5,?scoring='accuracy')
#?輸出精確度的平均值和置信度區(qū)間
print("訓(xùn)練集上的精確度:?%0.2f?(+/-?%0.2f)"?%?(scores1.mean(),?scores1.std()?*?2))
scores2?=?cross_val_score(lr_model,test_x,test_y,cv=5,?scoring='accuracy')
#?輸出精確度的平均值和置信度區(qū)間
print("測試集上的平均精確度:?%0.2f?(+/-?%0.2f)"?%?(scores2.mean(),?scores2.std()?*?2))
print(scores1)
print(scores2)
輸出:
訓(xùn)練集上的精確度: 0.94 (+/- 0.07)
測試集上的平均精確度: 0.84 (+/- 0.14)
[0.90909091 1. 0.95238095 0.9047619 0.94736842]
[0.90909091 0.88888889 0.88888889 0.75 0.75 ]
隨機(jī)森林依舊留作小測試。
注:?如果想要一次性評估多個(gè)指標(biāo),也可以使用可以一次性輸入多個(gè)評估指標(biāo)的?cross_validate()函數(shù)。
三、萬能模板V3.0版
調(diào)參讓算法表現(xiàn)更上一層樓
以上都是通過算法的默認(rèn)參數(shù)來訓(xùn)練模型的,不同的數(shù)據(jù)集適用的參數(shù)難免會(huì)不一樣,自己設(shè)計(jì)算法是設(shè)計(jì)不來的,只能調(diào)調(diào)參這樣子,調(diào)參,是廣大算法工程師最后的尊嚴(yán)。再說,若是做算法不調(diào)參,豈不是辱沒了算法工程師在江湖上大名鼎鼎的“煉丹工程師”的名聲?
scikit-learn對于不同的算法也提供了不同的參數(shù)可以自己調(diào)節(jié)。如果細(xì)說起來,又能寫好幾篇文章,本文目的是構(gòu)建一個(gè)萬能算法框架構(gòu)建模板,所以,這里只介紹一下一個(gè)通用的自動(dòng)化調(diào)參方法,至于更細(xì)節(jié)的每個(gè)算法對應(yīng)參數(shù)的含義以及手動(dòng)調(diào)參方法,會(huì)在以后的文章中結(jié)合實(shí)例具體慢慢介紹。
首先要明確的是,scikit-learn提供了算法().get_params()方法來查看每個(gè)算法可以調(diào)整的參數(shù),比如說,我們想查看SVM分類器算法可以調(diào)整的參數(shù),可以:
SVC().get_params()
輸出的就是SVM算法可以調(diào)節(jié)的參數(shù)以及系統(tǒng)默認(rèn)的參數(shù)值。每個(gè)參數(shù)的具體含義會(huì)在以后的文章中介紹。
{'C': 1.0,
'cache_size': 200,
'class_weight': None,
'coef0': 0.0,
'decision_function_shape': 'ovr',
'degree': 3,
'gamma': 'auto',
'kernel': 'rbf',
'max_iter': -1,
'probability': False,
'random_state': None,
'shrinking': True,
'tol': 0.001,
'verbose': False}
接著,就可以引出我們的V3.0版萬能模板了。

參數(shù)的形式如下:

程序就會(huì)按照順序測試這幾個(gè)參數(shù)的組合效果,根本不需要自己辛辛苦苦實(shí)現(xiàn)。寫到這里,感謝各為大佬編寫了scikit-learn這么方便的機(jī)器學(xué)習(xí)包。忽然就想到了一句話:哪有什么歲月靜好,只是因?yàn)橛腥颂婺阖?fù)重前行。
看到這里,可能有人會(huì)有疑惑:為什么要采用列表、字典、列表三層嵌套的方式呢?params直接是字典的形式不行嗎?答案是:行,但是不好。
讓我們先算一個(gè)小的數(shù)學(xué)題:假如我們要調(diào)節(jié)n個(gè)參數(shù),每個(gè)參數(shù)有4個(gè)備選值。那么程序就會(huì)訓(xùn)練??。當(dāng)n為10的時(shí)候,?,這是一個(gè)對于計(jì)算機(jī)來說龐大的計(jì)算量。而當(dāng)我們將這10個(gè)參數(shù)拆分成5組,每次只調(diào)節(jié)兩個(gè)參數(shù),其他參數(shù)采用默認(rèn)值,那么計(jì)算量就是??,計(jì)算量會(huì)大大減少。
列表的作用這是如此,保證了每次只調(diào)節(jié)列表中的一個(gè)字典中的參數(shù)。
運(yùn)行之后,best_model就是我們得到的最優(yōu)模型,可以利用這個(gè)模型進(jìn)行預(yù)測。
當(dāng)然,best_model?還有好多好用的屬性:
best_model.cv_results_:可以查看不同參數(shù)情況下的評價(jià)結(jié)果。best_model.param_?:得到該模型的最優(yōu)參數(shù)best_model.best_score_:?得到該模型的最后評分結(jié)果
模板3.0應(yīng)用案例
實(shí)現(xiàn)SVM分類器
###1、svm分類器
from?sklearn.model_selection?import?cross_val_score,GridSearchCV
from?sklearn.svm?import?SVC
svm_model?=?SVC()
params?=?[
????????{'kernel':?['linear'],?'C':?[1,?10,?100,?100]},
????????{'kernel':?['poly'],?'C':?[1],?'degree':?[2,?3]},
????????{'kernel':?['rbf'],?'C':?[1,?10,?100,?100],?'gamma':[1,?0.1,?0.01,?0.001]}
????????]
best_model?=?GridSearchCV(svm_model,?param_grid=params,cv?=?5,scoring?=?'accuracy')
best_model.fit(train_x,train_y)
1)查看最優(yōu)得分:
best_model.best_score_
輸出:
0.9714285714285714
2)查看最優(yōu)參數(shù):
best_model.best_params_?
輸出:
{'C': 1, 'kernel': 'linear'}
3)查看最優(yōu)模型的所有參數(shù):
best_model.best_estimator_?
這個(gè)函數(shù)會(huì)顯示出沒有調(diào)參的參數(shù),便于整體查看模型的參數(shù)。
4)查看每個(gè)參數(shù)的交叉驗(yàn)證結(jié)果:
best_model.cv_results_
注:
1、以前版本是best_model.grid_scores_,現(xiàn)在已經(jīng)移除
2、這個(gè)函數(shù)輸出很多數(shù)據(jù),不方便查看,一般不用
在實(shí)際使用中,如果計(jì)算資源夠用,一般采用第三種萬能公式。如果,為了節(jié)約計(jì)算資源盡快算出結(jié)果,也會(huì)采用以后介紹的手動(dòng)調(diào)參方式。
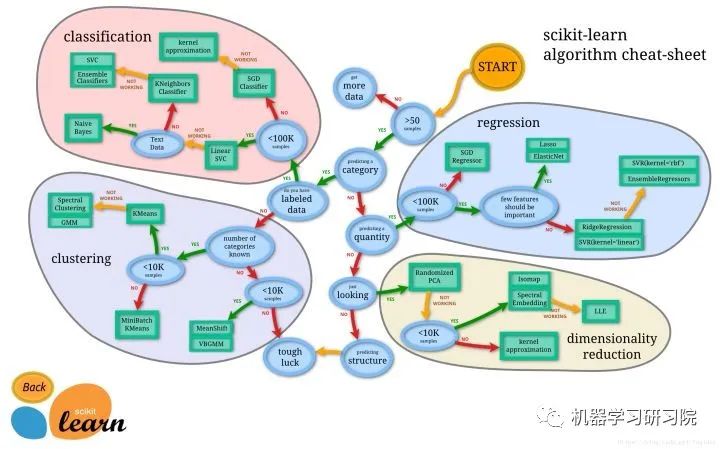
當(dāng)然,本文為了說明萬能模板的使用方法,在Iris數(shù)據(jù)集上將所有算法都實(shí)現(xiàn)了一遍,在實(shí)際應(yīng)用中,如果項(xiàng)目時(shí)間緊急,根據(jù)自己的需求和數(shù)據(jù)量級選擇一個(gè)合適的算法使用即可。具體怎么選擇,scikit-learn官方非常貼心地畫了一個(gè)圖,供大家根據(jù)數(shù)據(jù)量和算法類型選擇合適的模型,這副圖建議收藏: