
Go 開源說第四期(下):go-zero緩存管理最佳實踐
本文有『Go開源說』第四期 go-zero 直播內(nèi)容修改整理而成,視頻內(nèi)容較長,拆分成上下篇,本文內(nèi)容有所刪減和重構。
大家好,很高興來到“GO開源說” 跟大家分享開源項目背后的一些故事、設計思想以及使用方法,今天分享的項目是 go-zero,一個集成了各種工程實踐的 web 和 rpc 框架。我是Kevin,go-zero 作者,我的 github id 是 kev wan。
go-zero 概覽
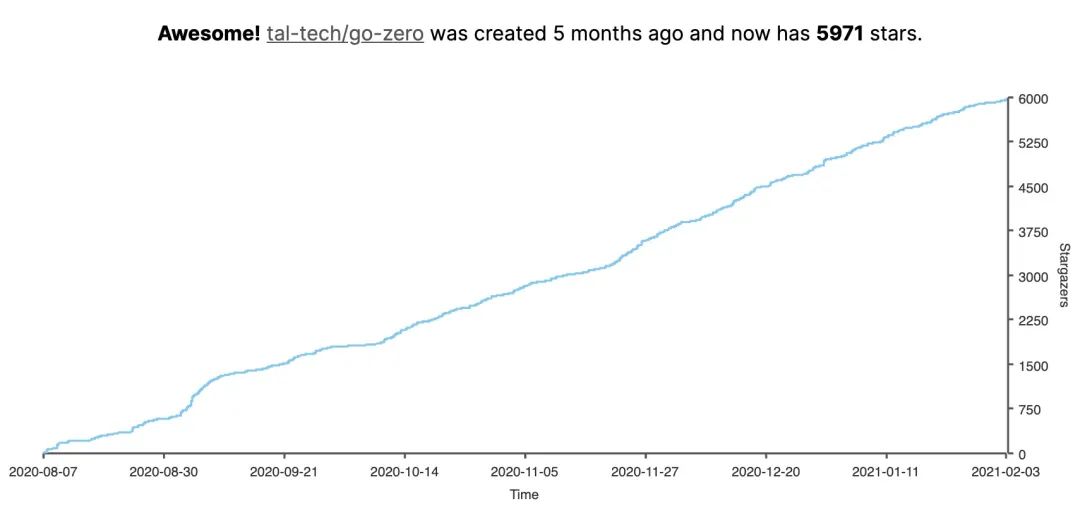
go-zero 雖然是20年8月7號才開源,但是已經(jīng)經(jīng)過線上大規(guī)模檢驗了,也是我近20年工程經(jīng)驗的積累,開源后得到社區(qū)的積極反饋,在5個多月的時間里,獲得了5.9k star。多次登頂github Go語言日榜、周榜、月榜榜首,并獲得了gitee最有價值項目(GVP),開源中國年度最佳人氣項目。同時微信社區(qū)極為活躍,3000+人的社區(qū)群,go-zero愛好者們一起交流go-zero使用心得和討論使用過程中的問題。
go-zero 如何自動管理緩存?
緩存設計原理
我們對緩存是只刪除,不做更新,一旦DB里數(shù)據(jù)出現(xiàn)修改,我們就會直接刪除對應的緩存,而不是去更新。
我們看看刪除緩存的順序怎樣才是正確的。
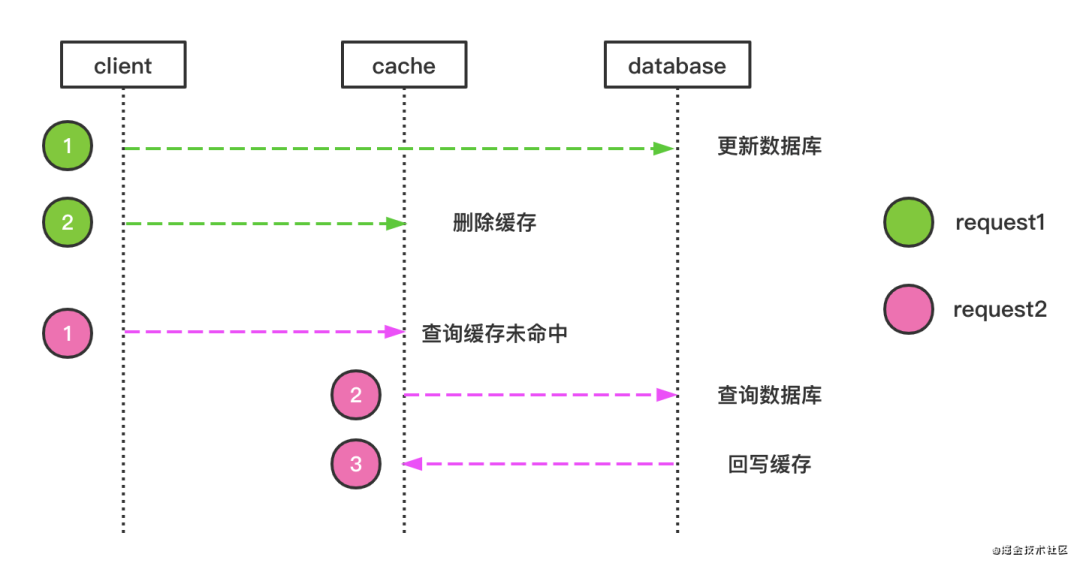
先刪除緩存,再更新DB
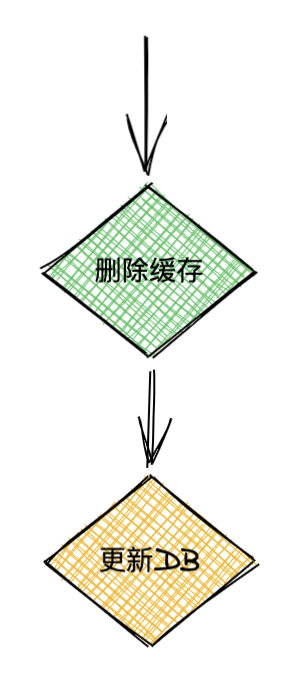
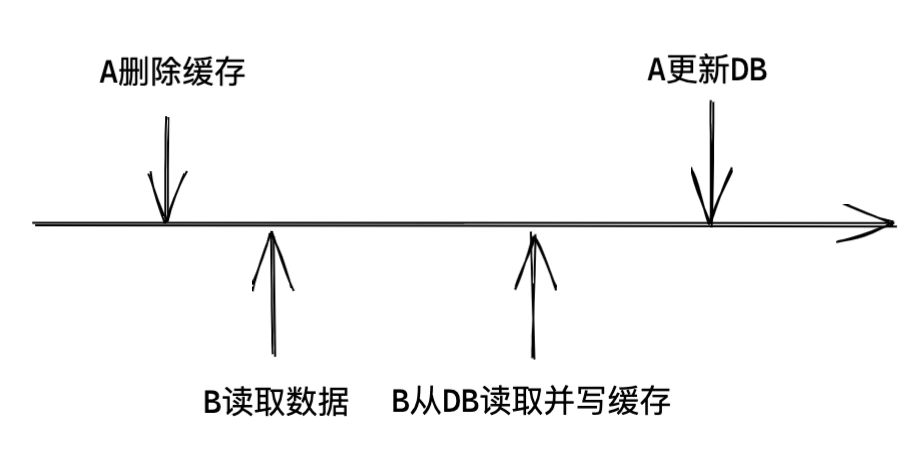
我們看兩個并發(fā)請求的情況,A請求需要更新數(shù)據(jù),先刪除了緩存,然后B請求來讀取數(shù)據(jù),此時緩存沒有數(shù)據(jù),就會從DB加載數(shù)據(jù)并寫回緩存,然后A更新了DB,那么此時緩存內(nèi)的數(shù)據(jù)就會一直是臟數(shù)據(jù),知道緩存過期或者有新的更新數(shù)據(jù)的請求。如圖
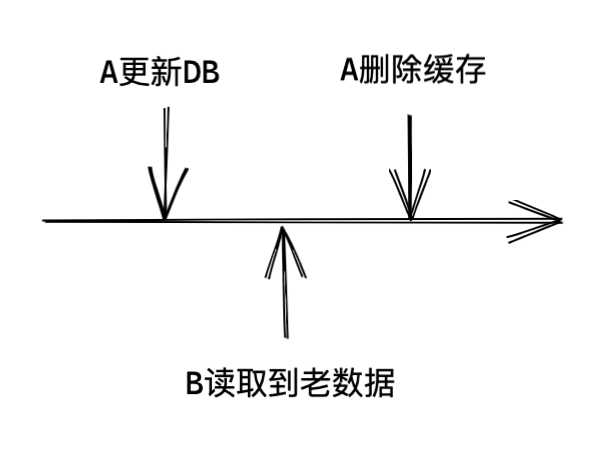
先更新DB,再刪除緩存
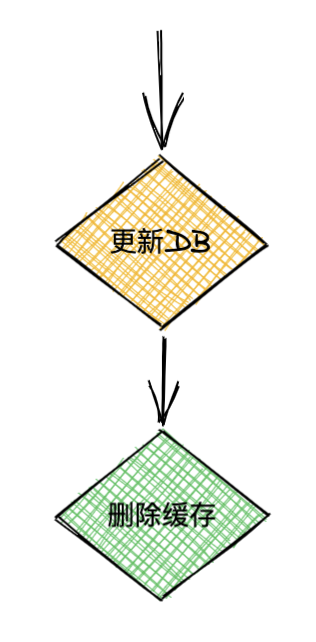
A請求先更新DB,然后B請求來讀取數(shù)據(jù),此時返回的是老數(shù)據(jù),此時可以認為是A請求還沒更新完,最終一致性,可以接受,然后A刪除了緩存,后續(xù)請求都會拿到最新數(shù)據(jù),如圖
讓我們再來看一下正常的請求流程:
第一個請求更新DB,并刪除了緩存 第二個請求讀取緩存,沒有數(shù)據(jù),就從DB讀取數(shù)據(jù),并回寫到緩存里 后續(xù)讀請求都可以直接從緩存讀取
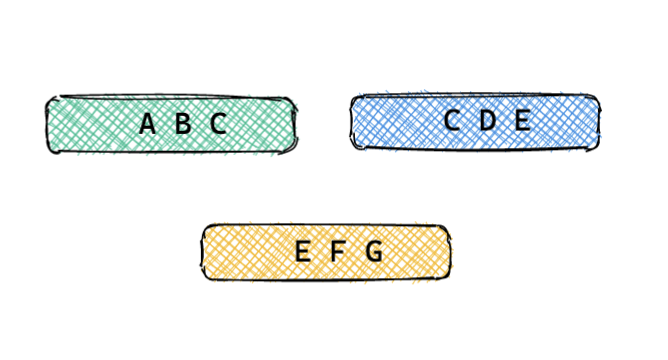
我們再看一下DB查詢有哪些情況,假設行記錄里有ABCDEFG七列數(shù)據(jù):
只查詢部分列數(shù)據(jù)的請求,比如請求其中的ABC,CDE或者EFG等,如圖
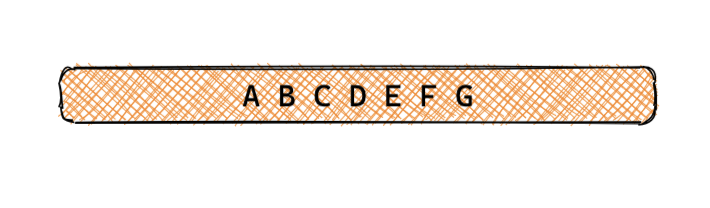
查詢單條完整行記錄,如圖
查詢多條行記錄的部分或全部列,如圖
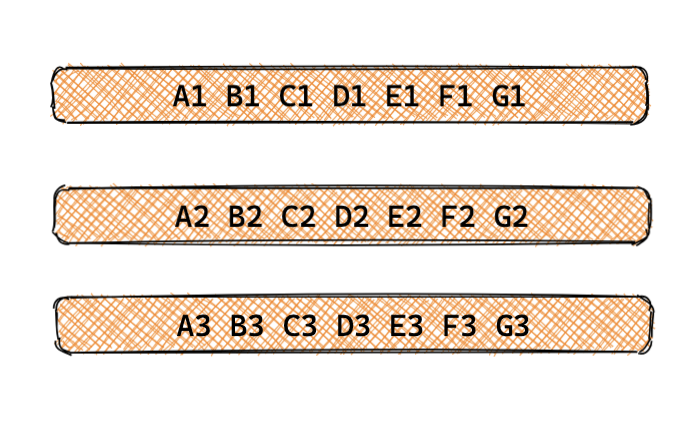
對于上面三種情況,首先,我們不用部分查詢,因為部分查詢沒法緩存,一旦緩存了,數(shù)據(jù)有更新,沒法定位到有哪些數(shù)據(jù)需要刪除;其次,對于多行的查詢,根據(jù)實際場景和需要,我們會在業(yè)務層建立對應的從查詢條件到主鍵的映射;而對于單行完整記錄的查詢,go-zero 內(nèi)置了完整的緩存管理方式。所以核心原則是:go-zero 緩存的一定是完整的行記錄。
下面我們來詳細介紹 go-zero 內(nèi)置的三種場景的緩存處理方式:
基于主鍵的緩存
PRIMARY?KEY?(`id`)這種相對來講是最容易處理的緩存,只需要在
redis里用primary key作為key來緩存行記錄即可。基于唯一索引的緩存
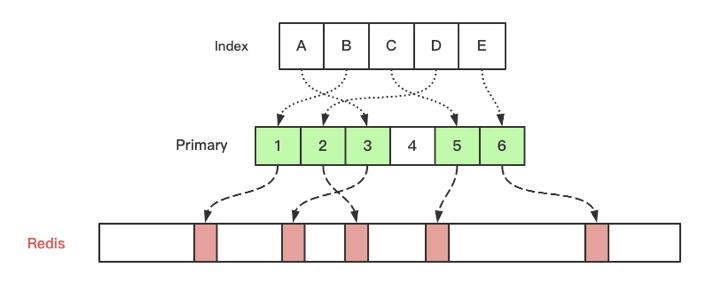
img 在做基于索引的緩存設計的時候我借鑒了
database索引的設計方法,在database設計里,如果通過索引去查數(shù)據(jù)時,引擎會先在索引->主鍵的tree里面查找到主鍵,然后再通過主鍵去查詢行記錄,就是引入了一個間接層去解決索引到行記錄的對應問題。在 go-zero 的緩存設計里也是同樣的原理。基于索引的緩存又分為單列唯一索引和多列唯一索引:
但是對于 go-zero 來說,單列和多列只是生成緩存
key的方式不同而已,背后的控制邏輯是一樣的。然后 go-zero 內(nèi)置的緩存管理就比較好的控制了數(shù)據(jù)一致性問題,同時也內(nèi)置防止了緩存的擊穿、穿透、雪崩問題(這些在 gopherchina 大會上分享的時候仔細講過,見后續(xù) gopherchina 分享視頻)。另外,go-zero 內(nèi)置了緩存訪問量、訪問命中率統(tǒng)計,如下所示:
dbcache(sqlc)?-?qpm:?5057,?hit_ratio:?99.7%,?hit:?5044,?miss:?13,?db_fails:?0可以看到比較詳細的統(tǒng)計信息,便于我們來分析緩存的使用情況,對于緩存命中率極低或者請求量極小的情況,我們就可以去掉緩存了,這樣也可以降低成本。
單列唯一索引如下:
UNIQUE?KEY?`product_idx`?(`product`)多列唯一索引如下:
UNIQUE?KEY?`vendor_product_idx`?(`vendor`,?`product`)
緩存代碼解讀
1. 基于主鍵的緩存邏輯
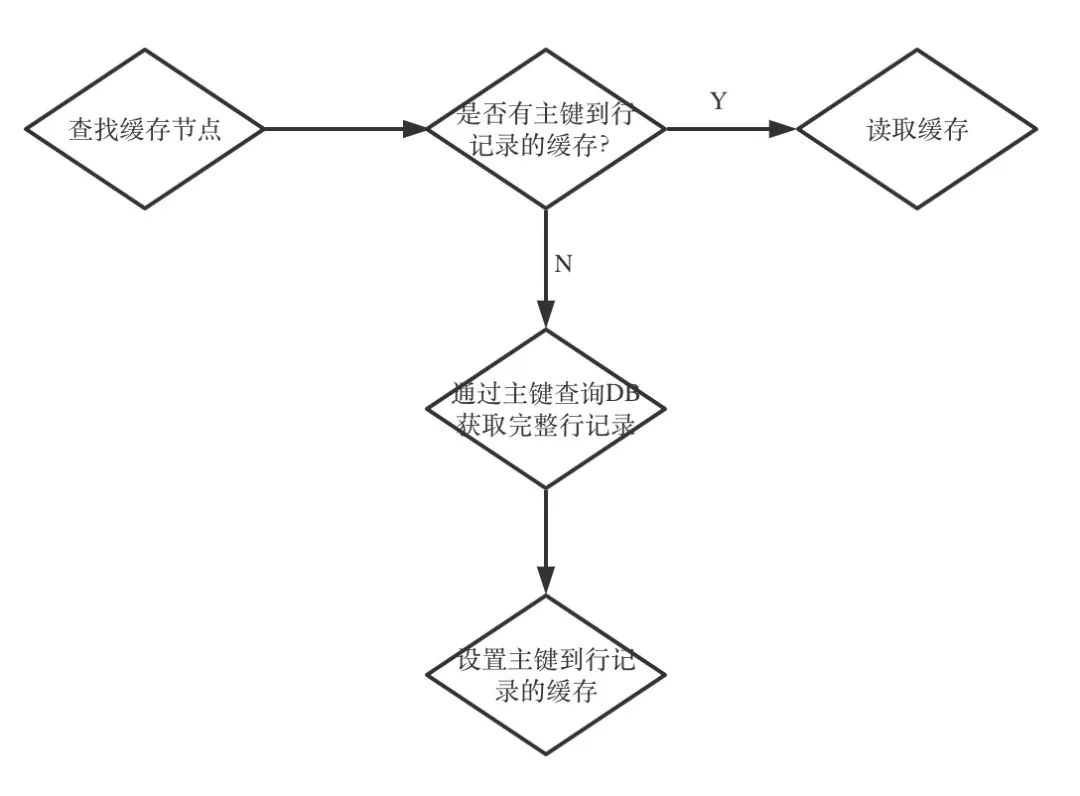
具體實現(xiàn)代碼如下:
func?(cc?CachedConn)?QueryRow(v?interface{},?key?string,?query?QueryFn)?error?{
?return?cc.cache.Take(v,?key,?func(v?interface{})?error?{
??return?query(cc.db,?v)
?})
}
這里的 Take 方法是先從緩存里去通過 key 拿數(shù)據(jù),如果拿到就直接返回,如果拿不到,那么就通過 query 方法去 DB 讀取完整行記錄并寫回緩存,然后再返回數(shù)據(jù)。整個邏輯還是比較簡單易懂的。
我們詳細看看 Take 的實現(xiàn):
func?(c?cacheNode)?Take(v?interface{},?key?string,?query?func(v?interface{})?error)?error?{
?return?c.doTake(v,?key,?query,?func(v?interface{})?error?{
??return?c.SetCache(key,?v)
?})
}
Take 的邏輯如下:
用 key從緩存里查找數(shù)據(jù)如果找到,則返回數(shù)據(jù) 如果找不到,用 query方法去讀取數(shù)據(jù)讀到后調(diào)用 c.SetCache(key, v)設置緩存
其中的 doTake 代碼和解釋如下:
//?v?-?需要讀取的數(shù)據(jù)對象
//?key?-?緩存key
//?query?-?用來從DB讀取完整數(shù)據(jù)的方法
//?cacheVal?-?用來寫緩存的方法
func?(c?cacheNode)?doTake(v?interface{},?key?string,?query?func(v?interface{})?error,
?cacheVal?func(v?interface{})?error)?error?{
??//?用barrier來防止緩存擊穿,確保一個進程內(nèi)只有一個請求去加載key對應的數(shù)據(jù)
?val,?fresh,?err?:=?c.barrier.DoEx(key,?func()?(interface{},?error)?{
????//?從cache里讀取數(shù)據(jù)
??if?err?:=?c.doGetCache(key,?v);?err?!=?nil?{
??????//?如果是預先放進來的placeholder(用來防止緩存穿透)的,那么就返回預設的errNotFound
??????//?如果是未知錯誤,那么就直接返回,因為我們不能放棄緩存出錯而直接把所有請求去請求DB,
??????//?這樣在高并發(fā)的場景下會把DB打掛掉的
???if?err?==?errPlaceholder?{
????return?nil,?c.errNotFound
???}?else?if?err?!=?c.errNotFound?{
????//?why?we?just?return?the?error?instead?of?query?from?db,
????//?because?we?don't?allow?the?disaster?pass?to?the?DBs.
????//?fail?fast,?in?case?we?bring?down?the?dbs.
????return?nil,?err
???}
??????//?請求DB
??????//?如果返回的error是errNotFound,那么我們就需要在緩存里設置placeholder,防止緩存穿透
???if?err?=?query(v);?err?==?c.errNotFound?{
????if?err?=?c.setCacheWithNotFound(key);?err?!=?nil?{
?????logx.Error(err)
????}
????return?nil,?c.errNotFound
???}?else?if?err?!=?nil?{
????????//?統(tǒng)計DB失敗
????c.stat.IncrementDbFails()
????return?nil,?err
???}
??????//?把數(shù)據(jù)寫入緩存
???if?err?=?cacheVal(v);?err?!=?nil?{
????logx.Error(err)
???}
??}
????
????//?返回json序列化的數(shù)據(jù)
??return?jsonx.Marshal(v)
?})
?if?err?!=?nil?{
??return?err
?}
?if?fresh?{
??return?nil
?}
?//?got?the?result?from?previous?ongoing?query
?c.stat.IncrementTotal()
?c.stat.IncrementHit()
??//?把數(shù)據(jù)寫入到傳入的v對象里
?return?jsonx.Unmarshal(val.([]byte),?v)
}
2. 基于唯一索引的緩存邏輯
因為這塊比較復雜,所以我用不同顏色標識出來了響應的代碼塊和邏輯,block 2 其實跟基于主鍵的緩存是一樣的,這里主要講 block 1 的邏輯。
代碼塊的 block 1 部分分為兩種情況:
通過索引能夠從緩存里找到主鍵
此時就直接用主鍵走
block 2的邏輯了,后續(xù)同上面基于主鍵的緩存邏輯通過索引無法從緩存里找到主鍵
通過索引從DB里查詢完整行記錄,如有 error,返回查到完整行記錄后,會把主鍵到完整行記錄的緩存和索引到主鍵的緩存同時寫到 redis里返回所需的行記錄數(shù)據(jù) 右側(cè)代碼是個實際使用索引緩存的示例
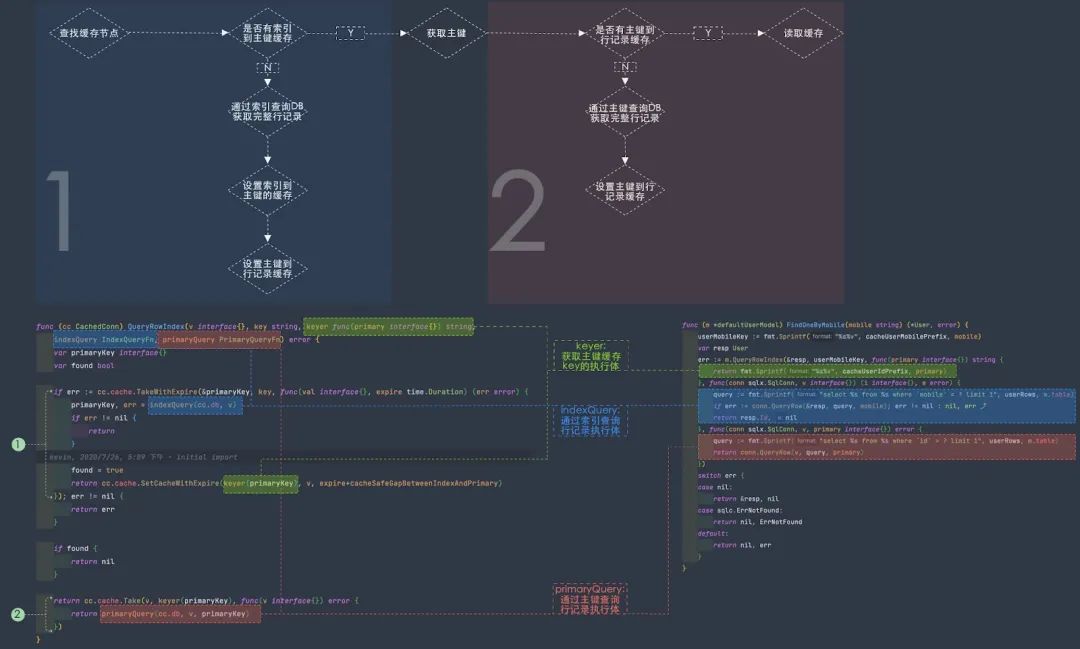
所有上面這些緩存的自動管理代碼都是可以通過 goctl 自動生成的,我們團隊內(nèi)部 CRUD 和緩存基本都是通過 goctl 自動生成的,可以節(jié)省大量開發(fā)時間,并且緩存代碼本身也是非常容易出錯的,即使有很好的代碼經(jīng)驗,也很難每次完全寫對,所以我們推薦盡可能使用自動的緩存代碼生成工具去避免錯誤。
go-zero 服務治理 + go-zero 最佳實踐(待續(xù))
如果你想要更好的了解 go-zero 項目,歡迎前往官方網(wǎng)站上學習具體的示例。
也可以掃碼加入微信群,我們有3000+人的活躍社區(qū)共同成長!
視頻回放地址
https://www.bilibili.com/video/BV1Jy4y127Xu
項目地址
https://github.com/tal-tech/go-zero
演講PPT:
https://github.com/gocn/opentalk/tree/main/PhaseFour_go-zero
歡迎使用 go-zero 并 star 支持我們!