
kafka源碼學(xué)習(xí):KafkaApis-LEADER_AND_ISR
作者:小兵
來源:SegmentFault 思否社區(qū)
每當(dāng)controller發(fā)生狀態(tài)變更時(shí),都會(huì)通過調(diào)用sendRequestsToBrokers方法發(fā)送leaderAndIsrRequest請求,本文主要介紹kafka服務(wù)端處理該請求的邏輯和過程。
LEADER_AND_ISR
整體邏輯流程
case ApiKeys.LEADER_AND_ISR => handleLeaderAndIsrRequest(request)在server端收到LEADER_AND_ISR請求后,會(huì)調(diào)用 handleLeaderAndIsrRequest 方法進(jìn)行處理,該方法的處理流程如圖所示:
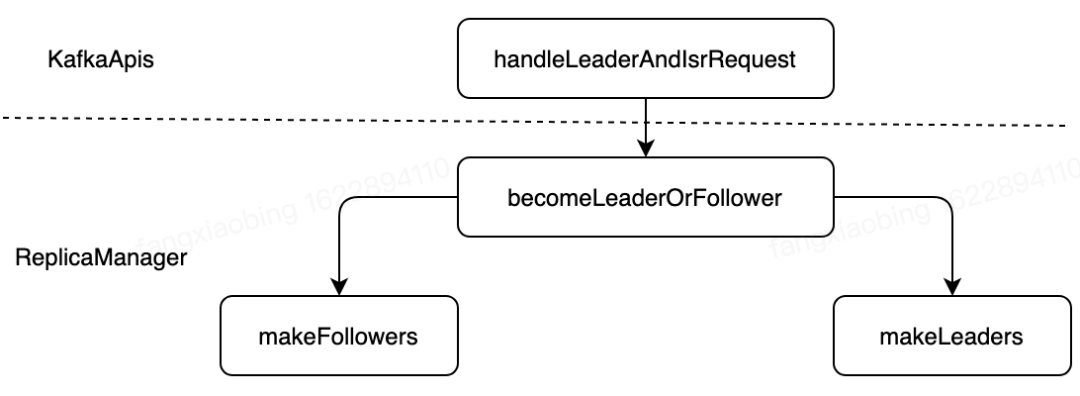
源碼
handleLeaderAndIsrRequest
handleLeaderAndIsrRequest函數(shù)的邏輯結(jié)果主要分為以下幾個(gè)部分:
構(gòu)造callback函數(shù) onLeadershipChange,用來回調(diào)coordinator處理新增的leader或者follower節(jié)點(diǎn)校驗(yàn)請求權(quán)限,如果校驗(yàn)成功調(diào)用 replicaManager.becomeLeaderOrFollower(correlationId, leaderAndIsrRequest, metadataCache, onLeadershipChange)進(jìn)行后續(xù)處理【此處該函數(shù)的主流程】,否則,直接返回錯(cuò)誤碼Errors.CLUSTER_AUTHORIZATION_FAILED.code
def handleLeaderAndIsrRequest(request: RequestChannel.Request) {// ensureTopicExists is only for client facing requests// We can't have the ensureTopicExists check here since the controller sends it as an advisory to all brokers so they// stop serving data to clients for the topic being deletedval correlationId = request.header.correlationIdval leaderAndIsrRequest = request.body.asInstanceOf[LeaderAndIsrRequest]try {def onLeadershipChange(updatedLeaders: Iterable[Partition], updatedFollowers: Iterable[Partition]) {// for each new leader or follower, call coordinator to handle consumer group migration.// this callback is invoked under the replica state change lock to ensure proper order of// leadership changesupdatedLeaders.foreach { partition =>if (partition.topic == Topic.GroupMetadataTopicName)coordinator.handleGroupImmigration(partition.partitionId)}updatedFollowers.foreach { partition =>if (partition.topic == Topic.GroupMetadataTopicName)coordinator.handleGroupEmigration(partition.partitionId)}}val leaderAndIsrResponse =if (authorize(request.session, ClusterAction, Resource.ClusterResource)) {val result = replicaManager.becomeLeaderOrFollower(correlationId, leaderAndIsrRequest, metadataCache, onLeadershipChange)new LeaderAndIsrResponse(result.errorCode, result.responseMap.mapValues(new JShort(_)).asJava)} else {val result = leaderAndIsrRequest.partitionStates.asScala.keys.map((_, new JShort(Errors.CLUSTER_AUTHORIZATION_FAILED.code))).toMapnew LeaderAndIsrResponse(Errors.CLUSTER_AUTHORIZATION_FAILED.code, result.asJava)}requestChannel.sendResponse(new Response(request, leaderAndIsrResponse))} catch {case e: KafkaStorageException =>fatal("Disk error during leadership change.", e)Runtime.getRuntime.halt(1)}}
becomeLeaderOrFollower
ReplicaManager的主要工作有以下幾個(gè)部分,具體代碼位置見中文注釋:
校驗(yàn)controller epoch是否合規(guī),只處理比自己epoch大且本地有副本的tp的請求 調(diào)用 makeLeaders和makeFollowers方法構(gòu)造新增的leader partition和follower partition【此處為主要邏輯,后面小結(jié)詳細(xì)介紹】如果是第一次收到請求,啟動(dòng)定時(shí)更新hw的線程 停掉空的Fetcher線程 調(diào)用回調(diào)函數(shù),coordinator處理新增的leader partition和follower partition
def becomeLeaderOrFollower(correlationId: Int,leaderAndISRRequest: LeaderAndIsrRequest,metadataCache: MetadataCache,onLeadershipChange: (Iterable[Partition], Iterable[Partition]) => Unit): BecomeLeaderOrFollowerResult = {leaderAndISRRequest.partitionStates.asScala.foreach { case (topicPartition, stateInfo) =>stateChangeLogger.trace("Broker %d received LeaderAndIsr request %s correlation id %d from controller %d epoch %d for partition [%s,%d]".format(localBrokerId, stateInfo, correlationId,leaderAndISRRequest.controllerId, leaderAndISRRequest.controllerEpoch, topicPartition.topic, topicPartition.partition))}//主要代碼,構(gòu)造返回結(jié)果replicaStateChangeLock synchronized {val responseMap = new mutable.HashMap[TopicPartition, Short]//如果controller epoch不正確,直接返回Errors.STALE_CONTROLLER_EPOCH.code錯(cuò)誤碼if (leaderAndISRRequest.controllerEpoch < controllerEpoch) {stateChangeLogger.warn(("Broker %d ignoring LeaderAndIsr request from controller %d with correlation id %d since " +"its controller epoch %d is old. Latest known controller epoch is %d").format(localBrokerId, leaderAndISRRequest.controllerId,correlationId, leaderAndISRRequest.controllerEpoch, controllerEpoch))BecomeLeaderOrFollowerResult(responseMap, Errors.STALE_CONTROLLER_EPOCH.code)} else {val controllerId = leaderAndISRRequest.controllerIdcontrollerEpoch = leaderAndISRRequest.controllerEpoch// First check partition's leader epoch//校驗(yàn)所有的partition信息,分為以下3種情況://1. 本地不包含該partition,返回Errors.UNKNOWN_TOPIC_OR_PARTITION.code//2. 本地包含該partition,controller epoch比本地epoch大,信息正確//3. controller epoch比本地epoch小,返回Errors.STALE_CONTROLLER_EPOCH.codeval partitionState = new mutable.HashMap[Partition, PartitionState]()leaderAndISRRequest.partitionStates.asScala.foreach { case (topicPartition, stateInfo) =>val partition = getOrCreatePartition(topicPartition)val partitionLeaderEpoch = partition.getLeaderEpoch// If the leader epoch is valid record the epoch of the controller that made the leadership decision.// This is useful while updating the isr to maintain the decision maker controller's epoch in the zookeeper pathif (partitionLeaderEpoch < stateInfo.leaderEpoch) {if(stateInfo.replicas.contains(localBrokerId))partitionState.put(partition, stateInfo)else {stateChangeLogger.warn(("Broker %d ignoring LeaderAndIsr request from controller %d with correlation id %d " +"epoch %d for partition [%s,%d] as itself is not in assigned replica list %s").format(localBrokerId, controllerId, correlationId, leaderAndISRRequest.controllerEpoch,topicPartition.topic, topicPartition.partition, stateInfo.replicas.asScala.mkString(",")))responseMap.put(topicPartition, Errors.UNKNOWN_TOPIC_OR_PARTITION.code)}} else {// Otherwise record the error code in responsestateChangeLogger.warn(("Broker %d ignoring LeaderAndIsr request from controller %d with correlation id %d " +"epoch %d for partition [%s,%d] since its associated leader epoch %d is not higher than the current leader epoch %d").format(localBrokerId, controllerId, correlationId, leaderAndISRRequest.controllerEpoch,topicPartition.topic, topicPartition.partition, stateInfo.leaderEpoch, partitionLeaderEpoch))responseMap.put(topicPartition, Errors.STALE_CONTROLLER_EPOCH.code)}}//處理leader&follower副本,構(gòu)造partitionsBecomeLeader和partitionsBecomeFollower供callback處理(coordinator處理)val partitionsTobeLeader = partitionState.filter { case (_, stateInfo) =>stateInfo.leader == localBrokerId}val partitionsToBeFollower = partitionState -- partitionsTobeLeader.keysval partitionsBecomeLeader = if (partitionsTobeLeader.nonEmpty)// 主要調(diào)用makeLeaders(controllerId, controllerEpoch, partitionsTobeLeader, correlationId, responseMap)elseSet.empty[Partition]val partitionsBecomeFollower = if (partitionsToBeFollower.nonEmpty)// 主要調(diào)用makeFollowers(controllerId, controllerEpoch, partitionsToBeFollower, correlationId, responseMap, metadataCache)elseSet.empty[Partition]// we initialize highwatermark thread after the first leaderisrrequest. This ensures that all the partitions// have been completely populated before starting the checkpointing there by avoiding weird race conditions// 在第一次收到收到請求后,就會(huì)啟動(dòng)Scheduler,定時(shí)更新hw checkpointif (!hwThreadInitialized) {startHighWaterMarksCheckPointThread()hwThreadInitialized = true}// 因?yàn)樯厦娓铝嗽畔ⅲ颂帣z查停掉不必要的Fetcher線程replicaFetcherManager.shutdownIdleFetcherThreads()// 回調(diào)onLeadershipChange(partitionsBecomeLeader, partitionsBecomeFollower)BecomeLeaderOrFollowerResult(responseMap, Errors.NONE.code)}}}
makeLeaders
停止這些partition的follower線程 更新這些partition的metadata cache 構(gòu)造新增leader集合
private def makeLeaders(controllerId: Int,epoch: Int,partitionState: Map[Partition, PartitionState],correlationId: Int,responseMap: mutable.Map[TopicPartition, Short]): Set[Partition] = {// 構(gòu)造becomeLeaderOrFollower需要的返回結(jié)果for (partition <- partitionState.keys)responseMap.put(partition.topicPartition, Errors.NONE.code)val partitionsToMakeLeaders: mutable.Set[Partition] = mutable.Set()try {// First stop fetchers for all the partitions// 停止Fetcher線程replicaFetcherManager.removeFetcherForPartitions(partitionState.keySet.map(_.topicPartition))// Update the partition information to be the leader// 構(gòu)造新增leader partition集合partitionState.foreach{ case (partition, partitionStateInfo) =>if (partition.makeLeader(controllerId, partitionStateInfo, correlationId))partitionsToMakeLeaders += partitionelsestateChangeLogger.info(("Broker %d skipped the become-leader state change after marking its partition as leader with correlation id %d from " +"controller %d epoch %d for partition %s since it is already the leader for the partition.").format(localBrokerId, correlationId, controllerId, epoch, partition.topicPartition))}}} catch {case e: Throwable =>partitionState.keys.foreach { partition =>val errorMsg = ("Error on broker %d while processing LeaderAndIsr request correlationId %d received from controller %d" +" epoch %d for partition %s").format(localBrokerId, correlationId, controllerId, epoch, partition.topicPartition)stateChangeLogger.error(errorMsg, e)}// Re-throw the exception for it to be caught in KafkaApisthrow e}partitionsToMakeLeaders}
partition.makeLeader(controllerId, partitionStateInfo, correlationId)會(huì)進(jìn)行元信息的處理,并更新hw,此方法會(huì)調(diào)用maybeIncrementLeaderHW函數(shù),該函數(shù)會(huì)嘗試追趕hw:如果其他副本落后leader不太遠(yuǎn),并且比之前的hw大,會(huì)延緩hw增長速度,盡可能讓其他副本進(jìn)隊(duì)。
def makeLeader(controllerId: Int, partitionStateInfo: PartitionState, correlationId: Int): Boolean = {val (leaderHWIncremented, isNewLeader) = inWriteLock(leaderIsrUpdateLock) {val allReplicas = partitionStateInfo.replicas.asScala.map(_.toInt)// record the epoch of the controller that made the leadership decision. This is useful while updating the isr// to maintain the decision maker controller's epoch in the zookeeper pathcontrollerEpoch = partitionStateInfo.controllerEpoch// add replicas that are new// 構(gòu)造新ISRallReplicas.foreach(replica => getOrCreateReplica(replica))val newInSyncReplicas = partitionStateInfo.isr.asScala.map(r => getOrCreateReplica(r)).toSet// remove assigned replicas that have been removed by the controller// 移除所有不在新ISR中的副本(assignedReplicas.map(_.brokerId) -- allReplicas).foreach(removeReplica)inSyncReplicas = newInSyncReplicasleaderEpoch = partitionStateInfo.leaderEpochzkVersion = partitionStateInfo.zkVersion//是否第一次成為該partition的leaderval isNewLeader =if (leaderReplicaIdOpt.isDefined && leaderReplicaIdOpt.get == localBrokerId) {false} else {leaderReplicaIdOpt = Some(localBrokerId)true}val leaderReplica = getReplica().getval curLeaderLogEndOffset = leaderReplica.logEndOffset.messageOffsetval curTimeMs = time.milliseconds// initialize lastCaughtUpTime of replicas as well as their lastFetchTimeMs and lastFetchLeaderLogEndOffset.//新leader初始化(assignedReplicas - leaderReplica).foreach { replica =>val lastCaughtUpTimeMs = if (inSyncReplicas.contains(replica)) curTimeMs else 0Lreplica.resetLastCaughtUpTime(curLeaderLogEndOffset, curTimeMs, lastCaughtUpTimeMs)}// we may need to increment high watermark since ISR could be down to 1if (isNewLeader) {// construct the high watermark metadata for the new leader replicaleaderReplica.convertHWToLocalOffsetMetadata()// reset log end offset for remote replicasassignedReplicas.filter(_.brokerId != localBrokerId).foreach(_.updateLogReadResult(LogReadResult.UnknownLogReadResult))}// 嘗試追趕hw,如果其他副本落后leader不太遠(yuǎn),并且比之前的hw大,會(huì)延緩hw增長速度,盡可能讓其他副本進(jìn)隊(duì)(maybeIncrementLeaderHW(leaderReplica), isNewLeader)}// some delayed operations may be unblocked after HW changed// hw更新后會(huì)處理一些requestif (leaderHWIncremented)tryCompleteDelayedRequests()isNewLeader}
makeFollowers
處理新增的follower partition
從leaderpartition集合中移除這些partition
標(biāo)記為follower,阻止producer請求
移除Fetcher線程
根據(jù)hw truncate這些partition的本地日志
清理producer和fetch請求
如果沒有宕機(jī),從新的leader fetch數(shù)據(jù)
private def makeFollowers(controllerId: Int,epoch: Int,partitionState: Map[Partition, PartitionState],correlationId: Int,responseMap: mutable.Map[TopicPartition, Short],metadataCache: MetadataCache) : Set[Partition] = {partitionState.keys.foreach { partition =>stateChangeLogger.trace(("Broker %d handling LeaderAndIsr request correlationId %d from controller %d epoch %d " +"starting the become-follower transition for partition %s").format(localBrokerId, correlationId, controllerId, epoch, partition.topicPartition))}// 構(gòu)造becomeLeaderOrFollower需要的返回結(jié)果for (partition <- partitionState.keys)responseMap.put(partition.topicPartition, Errors.NONE.code)val partitionsToMakeFollower: mutable.Set[Partition] = mutable.Set()try {// TODO: Delete leaders from LeaderAndIsrRequestpartitionState.foreach{ case (partition, partitionStateInfo) =>val newLeaderBrokerId = partitionStateInfo.leadermetadataCache.getAliveBrokers.find(_.id == newLeaderBrokerId) match {// Only change partition state when the leader is availablecase Some(_) =>// 構(gòu)造返回結(jié)果if (partition.makeFollower(controllerId, partitionStateInfo, correlationId))partitionsToMakeFollower += partitionelsestateChangeLogger.info(("Broker %d skipped the become-follower state change after marking its partition as follower with correlation id %d from " +"controller %d epoch %d for partition %s since the new leader %d is the same as the old leader").format(localBrokerId, correlationId, controllerId, partitionStateInfo.controllerEpoch,partition.topicPartition, newLeaderBrokerId))case None =>// The leader broker should always be present in the metadata cache.// If not, we should record the error message and abort the transition process for this partitionstateChangeLogger.error(("Broker %d received LeaderAndIsrRequest with correlation id %d from controller" +" %d epoch %d for partition %s but cannot become follower since the new leader %d is unavailable.").format(localBrokerId, correlationId, controllerId, partitionStateInfo.controllerEpoch,partition.topicPartition, newLeaderBrokerId))// Create the local replica even if the leader is unavailable. This is required to ensure that we include// the partition's high watermark in the checkpoint file (see KAFKA-1647)partition.getOrCreateReplica()}}//移除Fetcher線程replicaFetcherManager.removeFetcherForPartitions(partitionsToMakeFollower.map(_.topicPartition))//根據(jù)新hw進(jìn)行truncatelogManager.truncateTo(partitionsToMakeFollower.map { partition =>(partition.topicPartition, partition.getOrCreateReplica().highWatermark.messageOffset)}.toMap)//hw更新,嘗試處理請求partitionsToMakeFollower.foreach { partition =>val topicPartitionOperationKey = new TopicPartitionOperationKey(partition.topicPartition)tryCompleteDelayedProduce(topicPartitionOperationKey)tryCompleteDelayedFetch(topicPartitionOperationKey)}if (isShuttingDown.get()) {partitionsToMakeFollower.foreach { partition =>stateChangeLogger.trace(("Broker %d skipped the adding-fetcher step of the become-follower state change with correlation id %d from " +"controller %d epoch %d for partition %s since it is shutting down").format(localBrokerId, correlationId,controllerId, epoch, partition.topicPartition))}}else {// we do not need to check if the leader exists again since this has been done at the beginning of this process// 重置fetch位置,加入Fetcherval partitionsToMakeFollowerWithLeaderAndOffset = partitionsToMakeFollower.map(partition =>partition.topicPartition -> BrokerAndInitialOffset(metadataCache.getAliveBrokers.find(_.id == partition.leaderReplicaIdOpt.get).get.getBrokerEndPoint(config.interBrokerListenerName),partition.getReplica().get.logEndOffset.messageOffset)).toMapreplicaFetcherManager.addFetcherForPartitions(partitionsToMakeFollowerWithLeaderAndOffset)}} catch {case e: Throwable =>val errorMsg = ("Error on broker %d while processing LeaderAndIsr request with correlationId %d received from controller %d " +"epoch %d").format(localBrokerId, correlationId, controllerId, epoch)stateChangeLogger.error(errorMsg, e)// Re-throw the exception for it to be caught in KafkaApisthrow e}partitionsToMakeFollower}
原文鏈接:https://fxbing.github.io/2021/06/05/kafka源碼學(xué)習(xí):KafkaApis-LEADER-AND-ISR/
本文源碼基于kafka 0.10.2版本
