
原來(lái)Kafka源碼也在用二分搜索!
? 點(diǎn)擊上方“JavaEdge”,關(guān)注公眾號(hào)
Kafka的索引組件使用二分搜索,而且社區(qū)還針對(duì)Kafka自身特點(diǎn)對(duì)其改良。

1 索引架構(gòu)


如下幾個(gè)類都位于該包下:
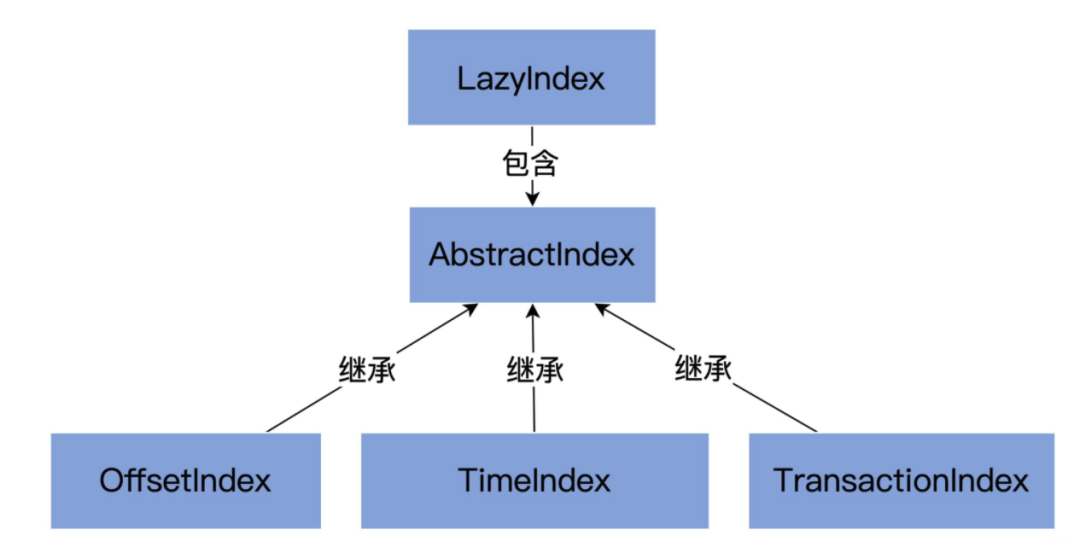
AbstractIndex.scala
最頂層抽象類:封裝了索引類型的公共操作LazyIndex.scala
定義了AbstractIndex上的一個(gè)包裝類,實(shí)現(xiàn)索引項(xiàng)延遲加載,該類只為提高性能OffsetIndex.scala
偏移索引,保存<位移值,文件物理磁盤(pán)位置>對(duì)。TimeIndex.scala
時(shí)間戳索引,保存<時(shí)間戳,位移值>對(duì)。TransactionIndex.scala
事務(wù)索引,為已中止事務(wù)(Aborted Transcation)保存重要元數(shù)據(jù)。只有啟用Kafka事務(wù)特性后,該索引才可能出現(xiàn)
2 AbstractIndex代碼結(jié)構(gòu)
2.1 類定義


2.2 屬性
索引文件(file)
每個(gè)索引對(duì)象在磁盤(pán)上都對(duì)應(yīng)一個(gè)索引文件。該字段是var型,說(shuō)明它可被修改。難道索引對(duì)象還能動(dòng)態(tài)更換底層索引文件?是的。1.1.0版本后,Kafka允許遷移底層的日志路徑,所以,索引文件自然要是可以更換的起始位移值(baseOffset)
索引對(duì)象對(duì)應(yīng)日志段對(duì)象的起始位移值。查看Kafka日志路徑,日志文件和索引文件都是成組出現(xiàn)。比如若日志文件是00000000000000000123.log,一定還有一組索引文件00000000000000000123.index、00000000000000000123.timeindex等。這里的“123”就是這組文件的起始位移值,即baseOffset
索引文件最大字節(jié)數(shù)(maxIndexSize)
控制索引文件的最大長(zhǎng)度。Kafka源碼傳入該參數(shù)的值是Broker端參數(shù)segment.index.bytes值,即10MB。所以默認(rèn)下所有Kafka索引文件大小都是10MB。
索引文件打開(kāi)方式(writable)
“True”:以“讀寫(xiě)”方式打開(kāi),“False”:以“只讀”方式打開(kāi)。
每個(gè)繼承AbstractIndex的子類負(fù)責(zé)定義具體的索引項(xiàng)結(jié)構(gòu),基于此架構(gòu)設(shè)計(jì),AbstractIndex定義抽象方法entrySize表示不同索引項(xiàng)的大小

// OffsetIndexoverride def entrySize = 8// TimeIndexoverride def entrySize = 12
為什么選擇8、12?
在OffsetIndex中,位移值4字節(jié),物理磁盤(pán)位置4字節(jié),所以共8字節(jié)。但位移值不是長(zhǎng)整型嗎,不是應(yīng)該8字節(jié)?。
其實(shí)AbstractIndex已保存baseOffset,這里的位移值,實(shí)際上是相對(duì)于baseOffset的相對(duì)位移值,即
真實(shí)位移值?-?baseOffset使用相對(duì)位移值能有效節(jié)省磁盤(pán)空間。
而B(niǎo)roker端參數(shù)log.segment.bytes是整型,這說(shuō)明Kafka中每個(gè)日志段文件的大小不會(huì)超過(guò)2^32,即4GB,這說(shuō)明同一個(gè)日志段文件上的?位移值 -?baseOffset?一定在整數(shù)范圍內(nèi)。因此,源碼只需4字節(jié)保存。
同理,TimeIndex中的時(shí)間戳類型是長(zhǎng)整型,占8字節(jié),位移依然使用相對(duì)位移值,占用4個(gè)字節(jié),因此共需12字節(jié)。
3 Kafka的索引底層實(shí)現(xiàn)原理
內(nèi)存映射文件,即Java中的MappedByteBuffer。
內(nèi)存映射文件的主要優(yōu)勢(shì)在于,它有很高的I/O性能,特別是對(duì)于索引這樣的小文件來(lái)說(shuō),由于文件內(nèi)存被直接映射到一段虛擬內(nèi)存上,訪問(wèn)內(nèi)存映射文件的速度要快于普通的讀寫(xiě)文件速度。
在Linux的這段映射的內(nèi)存區(qū)域就是內(nèi)核的頁(yè)緩存(Page Cache)。里面的數(shù)據(jù)無(wú)需重復(fù)拷貝到用戶態(tài)空間,避免了大量不必要的時(shí)間、空間消耗。
在AbstractIndex中,這個(gè)MappedByteBuffer就是名為mmap的變量。接下來(lái),我用注釋的方式,帶你深入了解下這個(gè)mmap的主要流程。
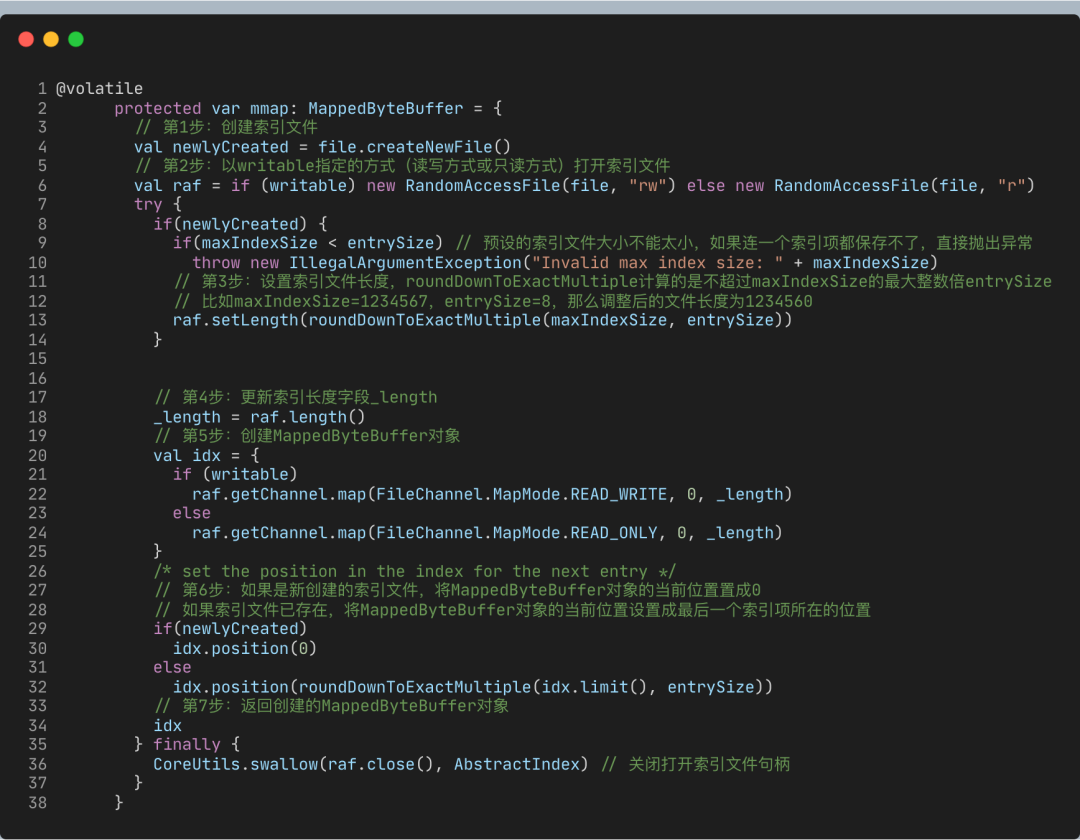
這些代碼最主要的作用就是創(chuàng)建mmap對(duì)象。要知道,AbstractIndex其他大部分的操作都是和mmap相關(guān)。
案例:
計(jì)算索引對(duì)象中當(dāng)前有多少個(gè)索引項(xiàng)
protected var _entries: Int = mmap.position() / entrySize
計(jì)算索引文件最多能容納多少個(gè)索引項(xiàng)
private[this] var _maxEntries: Int = mmap.limit() / entrySize
再進(jìn)一步,有了這兩個(gè)變量,我們就能夠很容易地編寫(xiě)一個(gè)方法,來(lái)判斷當(dāng)前索引文件是否已經(jīng)寫(xiě)滿:
def isFull: Boolean = _entries >= _maxEntries
AbstractIndex最重要的就是這個(gè)mmap變量。事實(shí)上,AbstractIndex繼承類實(shí)現(xiàn)添加索引項(xiàng)的主要邏輯,也就是向mmap中添加對(duì)應(yīng)的字段。
寫(xiě)入索引項(xiàng)
下面這段代碼是OffsetIndex的append方法,用于向索引文件中寫(xiě)入新索引項(xiàng)。
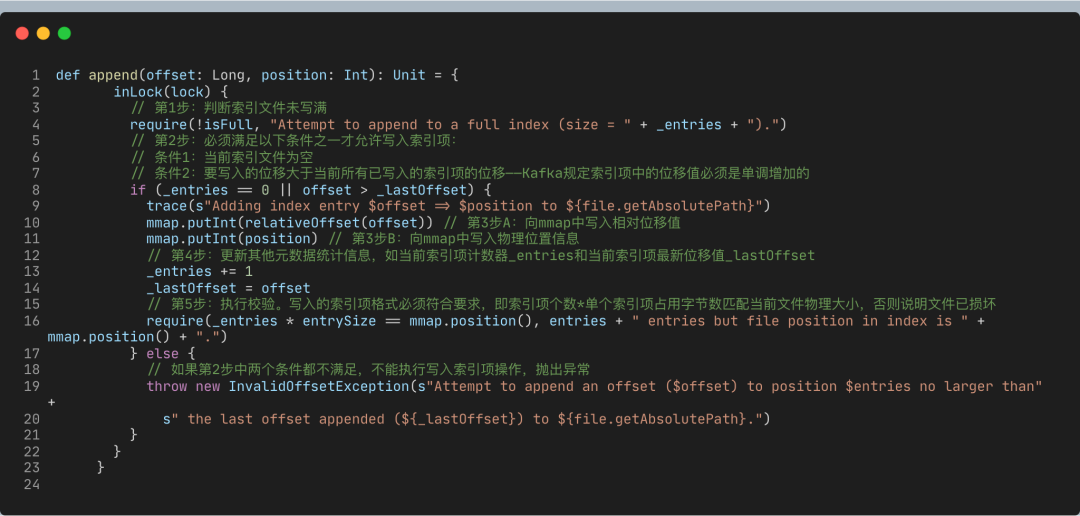

append方法的執(zhí)行流程

查找索引項(xiàng)
索引項(xiàng)的寫(xiě)入邏輯并不復(fù)雜,難點(diǎn)在于如何查找索引項(xiàng)。AbstractIndex定義了抽象方法parseEntry用于查找給定的索引項(xiàng),如下所示:
protected def parseEntry(buffer: ByteBuffer, n: Int): IndexEntry“n”表示要查找給定ByteBuffer中保存的第n個(gè)索引項(xiàng)(在Kafka中也稱第n個(gè)槽)。IndexEntry是源碼定義的一個(gè)接口,里面有兩個(gè)方法:indexKey和indexValue,分別返回不同類型索引的
OffsetIndex實(shí)現(xiàn)parseEntry的邏輯如下:
override protected def parseEntry(buffer: ByteBuffer, n: Int): OffsetPosition = {OffsetPosition(baseOffset + relativeOffset(buffer, n), physical(buffer, n))}
OffsetPosition是實(shí)現(xiàn)IndexEntry的實(shí)現(xiàn)類,Key就是之前說(shuō)的位移值,而Value就是物理磁盤(pán)位置值。所以,這里你能看到代碼調(diào)用了relativeOffset(buffer, n) + baseOffset計(jì)算出絕對(duì)位移值,之后調(diào)用physical(buffer, n)計(jì)算物理磁盤(pán)位置,最后將它們封裝到一起作為一個(gè)獨(dú)立的索引項(xiàng)返回。
我建議你去看下relativeOffset和physical方法的實(shí)現(xiàn),看看它們是如何計(jì)算相對(duì)位移值和物理磁盤(pán)位置信息的。
有了parseEntry方法,我們就能夠根據(jù)給定的n來(lái)查找索引項(xiàng)了。但是,這里還有個(gè)問(wèn)題需要解決,那就是,我們?nèi)绾未_定要找的索引項(xiàng)在第n個(gè)槽中呢?其實(shí)本質(zhì)上,這是一個(gè)算法問(wèn)題,也就是如何從一組已排序的數(shù)中快速定位符合條件的那個(gè)數(shù)。
4 二分查找算法
到目前為止,從已排序數(shù)組中尋找某個(gè)數(shù)字最快速的算法就是二分查找了,它能做到O(lgN)的時(shí)間復(fù)雜度。Kafka的索引組件就應(yīng)用了二分查找算法。
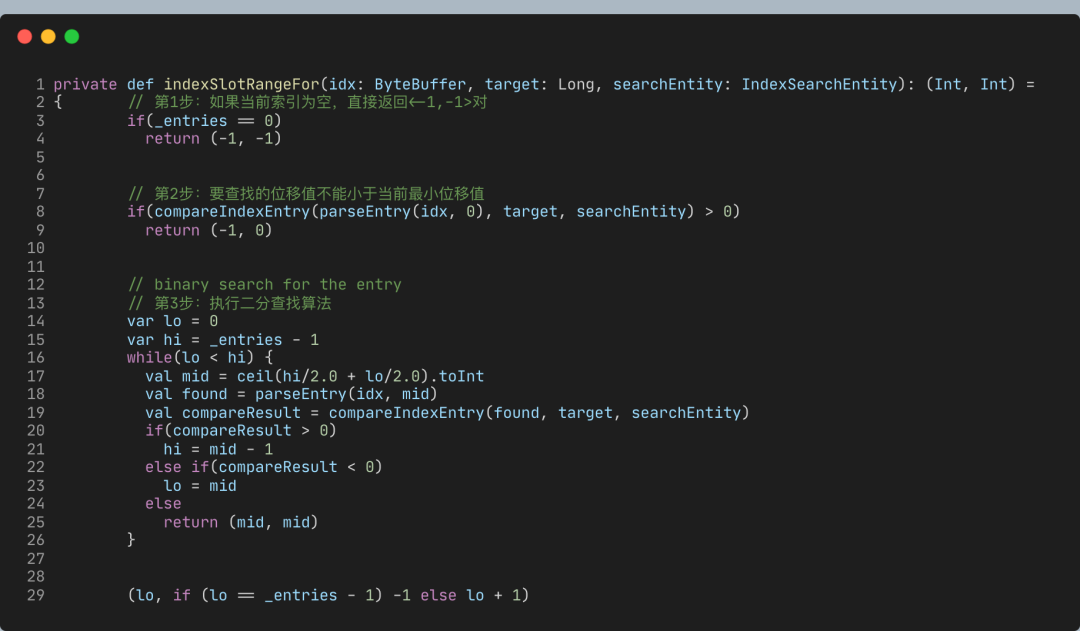
Kafka索引應(yīng)用二分查找算法快速定位待查找索引項(xiàng)位置,之后調(diào)用parseEntry來(lái)讀取索引項(xiàng)。不過(guò),這真的就是無(wú)懈可擊的解決方案了嗎?
改進(jìn)版
顯然不是!我前面說(shuō)過(guò)了,大多數(shù)操作系統(tǒng)使用頁(yè)緩存來(lái)實(shí)現(xiàn)內(nèi)存映射,而目前幾乎所有的操作系統(tǒng)都使用LRU(Least Recently Used)或類似于LRU的機(jī)制來(lái)管理頁(yè)緩存。
Kafka寫(xiě)入索引文件的方式是在文件末尾追加寫(xiě)入,而幾乎所有的索引查詢都集中在索引的尾部。這么來(lái)看的話,LRU機(jī)制是非常適合Kafka的索引訪問(wèn)場(chǎng)景的。
但,這里有個(gè)問(wèn)題是,當(dāng)Kafka在查詢索引的時(shí)候,原版的二分查找算法并沒(méi)有考慮到緩存的問(wèn)題,因此很可能會(huì)導(dǎo)致一些不必要的缺頁(yè)中斷(Page Fault)。此時(shí),Kafka線程會(huì)被阻塞,等待對(duì)應(yīng)的索引項(xiàng)從物理磁盤(pán)中讀出并放入到頁(yè)緩存中。
下面我舉個(gè)例子來(lái)說(shuō)明一下這個(gè)情況。假設(shè)Kafka的某個(gè)索引占用了操作系統(tǒng)頁(yè)緩存13個(gè)頁(yè)(Page),如果待查找的位移值位于最后一個(gè)頁(yè)上,也就是Page 12,那么標(biāo)準(zhǔn)的二分查找算法會(huì)依次讀取頁(yè)號(hào)0、6、9、11和12,具體的推演流程如下所示:
通常來(lái)說(shuō),一個(gè)頁(yè)上保存了成百上千的索引項(xiàng)數(shù)據(jù)。隨著索引文件不斷被寫(xiě)入,Page #12不斷地被填充新的索引項(xiàng)。如果此時(shí)索引查詢方都來(lái)自ISR副本或Lag很小的消費(fèi)者,那么這些查詢大多集中在對(duì)Page #12的查詢,因此,Page #0、6、9、11、12一定經(jīng)常性地被源碼訪問(wèn)。也就是說(shuō),這些頁(yè)一定保存在頁(yè)緩存上。后面當(dāng)新的索引項(xiàng)填滿了Page #12,頁(yè)緩存就會(huì)申請(qǐng)一個(gè)新的Page來(lái)保存索引項(xiàng),即Page #13。
現(xiàn)在,最新索引項(xiàng)保存在Page #13中。如果要查找最新索引項(xiàng),原版二分查找算法將會(huì)依次訪問(wèn)Page #0、7、10、12和13。此時(shí),問(wèn)題來(lái)了:Page 7和10已經(jīng)很久沒(méi)有被訪問(wèn)過(guò)了,它們大概率不在頁(yè)緩存中,因此,一旦索引開(kāi)始征用Page #13,就會(huì)發(fā)生Page Fault,等待那些冷頁(yè)數(shù)據(jù)從磁盤(pán)中加載到頁(yè)緩存。根據(jù)國(guó)外用戶的測(cè)試,這種加載過(guò)程可能長(zhǎng)達(dá)1秒。
顯然,這是一個(gè)普遍的問(wèn)題,即每當(dāng)索引文件占用Page數(shù)發(fā)生變化時(shí),就會(huì)強(qiáng)行變更二分查找的搜索路徑,從而出現(xiàn)不在頁(yè)緩存的冷數(shù)據(jù)必須要加載到頁(yè)緩存的情形,而這種加載過(guò)程是非常耗時(shí)的。
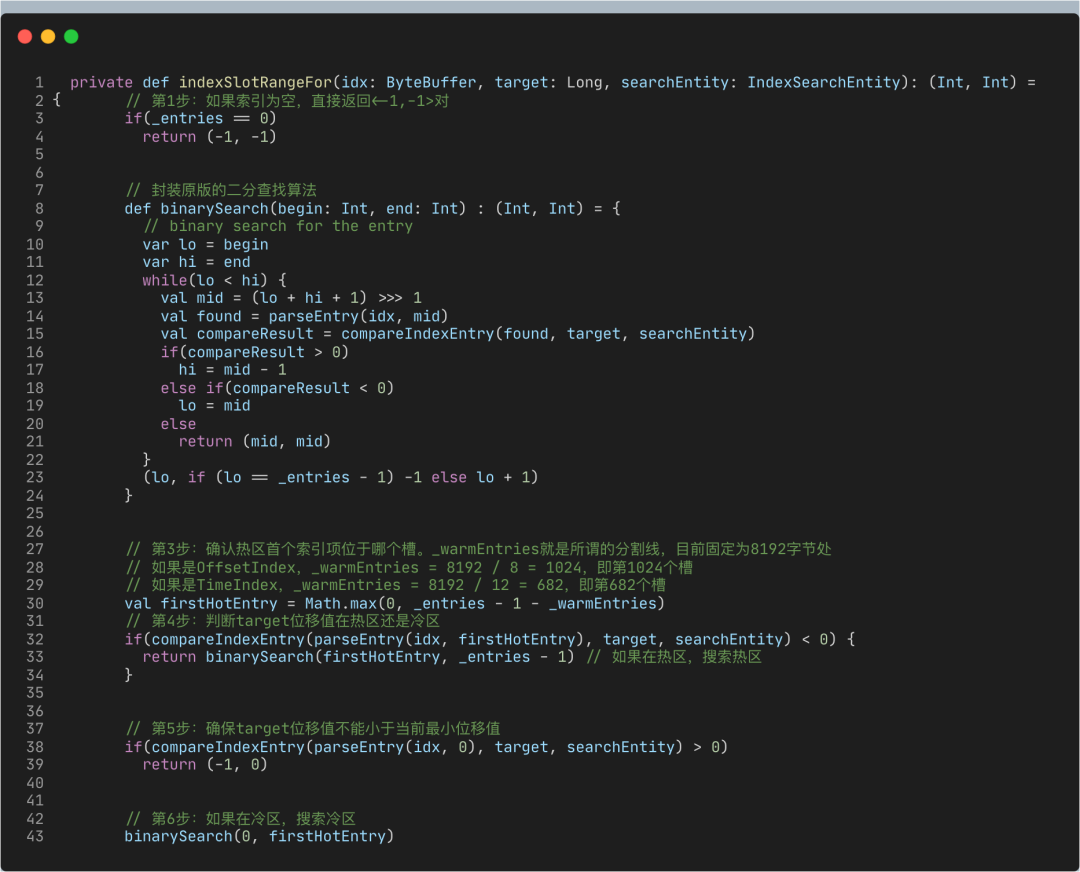
基于這個(gè)問(wèn)題,社區(qū)提出了改進(jìn)版的二分查找策略,也就是緩存友好的搜索算法。總體的思路是,代碼將所有索引項(xiàng)分成兩個(gè)部分:熱區(qū)(Warm Area)和冷區(qū)(Cold Area),然后分別在這兩個(gè)區(qū)域內(nèi)執(zhí)行二分查找算法,如下圖所示:
乍一看,該算法并沒(méi)有什么高大上的改進(jìn),僅僅是把搜尋區(qū)域分成了冷、熱兩個(gè)區(qū)域,然后有條件地在不同區(qū)域執(zhí)行普通的二分查找算法罷了。實(shí)際上,這個(gè)改進(jìn)版算法提供了一個(gè)重要的保證:它能保證那些經(jīng)常需要被訪問(wèn)的Page組合是固定的。
想想剛才的例子,同樣是查詢最熱的那部分?jǐn)?shù)據(jù),一旦索引占用了更多的Page,要遍歷的Page組合就會(huì)發(fā)生變化。這是導(dǎo)致性能下降的主要原因。
這個(gè)改進(jìn)版算法的最大好處在于,查詢最熱那部分?jǐn)?shù)據(jù)所遍歷的Page永遠(yuǎn)是固定的,因此大概率在頁(yè)緩存中,從而避免無(wú)意義的Page Fault。
下面我們來(lái)看實(shí)際的代碼。我用注釋的方式解釋了改進(jìn)版算法的實(shí)現(xiàn)邏輯。一旦你了解了冷區(qū)熱區(qū)的分割原理,剩下的就不難了。
5 總結(jié)
AbstractIndex是Kafka所有類型索引的抽象父類,里面的mmap變量是實(shí)現(xiàn)索引機(jī)制的核心,你一定要掌握它。
改進(jìn)版二分查找算法:社區(qū)在標(biāo)準(zhǔn)原版的基礎(chǔ)上,對(duì)二分查找算法根據(jù)實(shí)際訪問(wèn)場(chǎng)景做了定制化的改進(jìn)。你需要特別關(guān)注改進(jìn)版在提升緩存性能方面做了哪些努力。改進(jìn)版能夠有效地提升頁(yè)緩存的使用率,從而在整體上降低物理I/O,緩解系統(tǒng)負(fù)載瓶頸。你最好能夠從索引這個(gè)維度去思考社區(qū)在這方面所做的工作。
實(shí)際上,無(wú)論是AbstractIndex還是它使用的二分查找算法,它們都屬于Kafka索引共性的東西,即所有Kafka索引都具備這些特點(diǎn)或特性。
往期推薦

目前交流群已有?800+人,旨在促進(jìn)技術(shù)交流,可關(guān)注公眾號(hào)添加筆者微信邀請(qǐng)進(jìn)群
喜歡文章,點(diǎn)個(gè)“在看、點(diǎn)贊、分享”素質(zhì)三連支持一下~